
Abstract
Synchronization in parallel programs is a major performance bottleneck. Shared data is protected by locks and a lot of time is spent in the competition arising at the lock hand-off. In this period of time, a large amount of traffic is targeted to the line holding the lock variable. In order to be serialized, the requests to the same cache line can either be bounced (NACKed) or buffered in the coherence controller. In this paper we focus on systems whose coherence controllers buffer requests.
During lock hand-off only the requests from the winning processor contribute to the computation progress, because the winning processor is the only one that will advance the work. This key observation leads us to propose a hardware mechanism named Request Bypass, which allows requests from the winning processor to bypass the requests buffered in the home coherence controller keeping the lock line. The mechanism does not require compiler or programmer support nor ISA or coherence protocol changes.
By simulating a 32 processor system we show that Request Bypass reduces execution time and lock stall time up to 35% and 75%, respectively. The programs limited by synchronization benefit the most from Request Bypass.
This work was partly funded by grants TIN2004-07739-C02-01/02 (Spanish Ministry of Education/Science and European RDF) and the Diputación General de Aragón.
Chapter PDF
Similar content being viewed by others
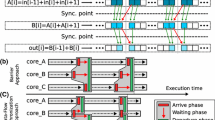


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
References
Mellor-Crummey, J., Scott, M.: Algorithms for scalable synchronization on shared memory multiprocessors. ACM Trans. on Computer Systems 9(1), 21–65 (1991)
Michael, M., Scott, M.: Implementation of atomic primitives on distributed shared memory multiprocessors. In: Proc. 1st HPCA, pp. 221–231 (1995)
Anderson, T.: The performance implications of spin-waiting alternatives for shared-memory multiprocessors. In: Proc. ICPP, vol. II, pp. 170–174 (1989)
Anderson, T.: The performance of spin lock alternatives for shared-memory multiprocessors. IEEE Trans. on Parallel and Distributed Systems 1(1), 6–16 (1990)
Goodman, J., Vernon, M., Woest, P.: Efficient synchronization primitives for large-scale cache-coherent shared-memory multiprocessors. In: Proc. 3th ASPLOS, pp. 64–75 (1989)
Kagi, A.: Mechanisms for Efficient Shared-Memory, Lock-Based Synchronization. PhD thesis, University of Wisconsin. Madison (1999)
Kagi, A., Burger, D., Goodman, J.: Efficient synchronization: let them eat QOLB. In: Proc. 24th ISCA, pp. 170–180 (1997)
Graunke, G., Thakkar, S.: Synchronization algorithms for shared memory multiprocessors. IEEE Computer 23(6), 60–69 (1990)
Magnusson, P., Landin, A., Hagersten, E.: Queue locks on cache coherent multiprocessors. In: Proc. 8th ISPP, pp. 165–171 (1994)
Rajwar, R., Kagi, A., Goodman, J.: Improving the throughput of synchronization by insertion of delays. In: Proc. 6th HPCA (2000)
Rajwar, R., Kagi, A., Goodman, J.: Inferential queueing and speculative push for reducing critical communication latencies. In: Proc. 17th ICS, pp. 273–284 (2003)
Kuskin, J., et al.: The stanford FLASH multiprocessor. In: Proc. 21th ISCA, pp. 302–313 (1994)
Laudon, J., Lenoski, D.: The SGI Origin: A CC-NUMA highly scalable server. In: Proc. 24th ISCA (1997)
Barroso, L., et al.: Piranha: A scalable architecture based on single-chip multiprocessing. In: Proc. 27th ISCA, pp. 282–293 (2000)
Gharachorloo, K., et al.: Architecture and design of ALPHASERVER GS320. In: Proc. 9th ASPLOS, pp. 13–24 (2000)
James, D., Laundrie, A., Gjessing, S., Sohni, G.: Distributed directory scheme: Scalable coherence interface. IEEE Computer 23(6) (1990)
Chaudhuri, M., Heinrich, M.: The impact of negative acknowledgments in shared memory scientific applications. IEEE Trans. on Parallel and Distributed Systems 15(2), 134–152 (2004)
Pai, V., Ranganathan, P., Adve, S.: RSIM: An execution-driven simulator for ILP-based shared-memory multiprocessors and uniprocessors. In: WCAE-3 (1997)
Pai, V., Ranganathan, P., Adve, S.: RSIM reference manual version 1.0. Technical report 9705, Dept. of Electrical and Computer Engineering, Rice University (1997)
Gharachorloo, K., Gupta, A., Hennessy, J.: Two techniques to enhance the performance of memory consistency models. In: Proc. ICPP, pp. 355–364 (1991)
Woo, S., et al.: The SPLASH-2 programs: Characterization and methodological considerations. In: Proc. 22th ISCA, pp. 24–36 (1995)
Heinrich, M., Chaudhuri, M.: Ocean warning: Avoid drowing. Computer Architecture News 31(3), 30–32 (2003)
de Dios, A., Sahelices, B., Ibáñez, P., Viñals, V., Llaberí, J.M.: Speeding-up synchronizations in DSM multiprocessors. Tech. rep. DIIS RR-06-07, University of Zaragoza, Spain (2006)
Lenoski, D., et al.: The stanford DASH multiprocessor. IEEE Computer 25(3), 63–79 (1992)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2006 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
de Dios, A., Sahelices, B., Ibáñez, P., Viñals, V., Llabería, J.M. (2006). Speeding-Up Synchronizations in DSM Multiprocessors. In: Nagel, W.E., Walter, W.V., Lehner, W. (eds) Euro-Par 2006 Parallel Processing. Euro-Par 2006. Lecture Notes in Computer Science, vol 4128. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11823285_49
Download citation
DOI: https://doi.org/10.1007/11823285_49
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-37783-2
Online ISBN: 978-3-540-37784-9
eBook Packages: Computer ScienceComputer Science (R0)