
Abstract
The low contrast and irregular cell shapes in microscopy images cause difficulties to obtain the accurate cell segmentation. We propose pyramid-based fully convolutional networks (FCN) to segment cells in a cascaded refinement manner. The higher-level FCNs generate coarse cell segmentation masks, attacking the challenge of low contrast between cell inner regions and the background. The lower-level FCNs generate segmentation masks focusing more on cell details, attacking the challenge of irregular cell shapes. The FCNs in the pyramid are trained in a cascaded way such that the residual error between the ground truth and upper-level segmentation is propagated to the lower-level and draws the attention of the lower-level FCNs to find the cell details missed from the upper-levels. The fine cell details from lower-level FCNs are gradually fused into the coarse segmentation from upper-level FCNs so as to obtain a final precise cell segmentation mask. On the ISBI cell segmentation challenge dataset and a newly collected dataset with high-quality ground truth, our method outperforms the state-of-the-art methods.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
- Fully Convolutional Network (FCNs)
- Irregular Cell Shape
- Detailed Cell
- Laplacian Pyramid
- Gaussian Pyramid
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
Cell segmentation in microscopy images, as a cornerstone of many cell image analysis tasks, has been researched for years [12]. There are still a few unsolved major challenges: (1) the contrast between cells and their background is low in the microscopy images (e.g., in Fig. 1(a), the appearance of the inner region of the cell is quite similar to its surrounding culturing medium); and (2) cells exhibit irregular shapes during their growth process (e.g., Fig. 1(b)), yielding difficulties to segment the precise boundaries of cells.

1.1 Related Work
Recently, deep learning has demonstrated its superior performance on object segmentation in images. Long et al. [2] proposed a fully convolutional network for semantic segmentation, which is modified from the Alexnet [3] (a seminal convolutional neural network for large-scale image classification). He et al. [4] proposed a Mask R-CNN approach that detects objects in an image while simultaneously generating a segmentation mask for each object. Ronneberger et al. [1] proposed a U-Net that consists of convolutional layers and deconvolutional layers with skip connection techniques. The U-Net won the ISBI cell segmentation challenge in Phase Contrast Microscopy Images in 2015. When checking the failure cases of U-Net, we found the two challenges (low contrast and irregular shapes) are the major causes, as shown in Fig. 1.

Receptive field of each level.
1.2 Motivation
There are some research studies about combining the Laplacian pyramid with deep neural networks. Ghiasi et al. [7] describes a multi-resolution reconstruction architecture for semantic segmentation which uses skip connections between different levels of a pyramid. Denton et al. [6] deploys the Laplacian Pyramid for a generative image model to generate images in a coarse-to-fine fashion. In a pyramid of gradually downsized images, the receptive field (red rectangles in Fig. 2) analyzes the image content at different scales. The top-level receptive field perceives objects at the global level, which could attack the low contrast challenge, and the bottom-level receptive field perceives more on fine object details which could attack the irregular shape challenge. This motivated us to design a series of fully convolutional networks (FCN) to extract information from different sizes of image regions, which can enable us to compute a precise cell segmentation mask in a coarse-to-fine manner.
1.3 Our Proposal
We propose a pyramid-based fully convolutional network approach to segment cells in a cascaded refinement manner. The higher-level FCNs generate coarse cell segmentation masks, attacking the challenge of low contrast between cell inner regions and background. The lower-level FCNs generate segmentation masks focusing more on cell details, attacking the challenge of irregular cell shapes. There are a few novelties on the proposed method: (1) The input to the series of FCNs is a Gaussian pyramid, but fusing the output from FCNs is achieved in a way similar to the sequential image reconstruction in the Laplacian pyramid so the fine details on cells can be gradually collected into the final cell segmentation mask; (2) The FCNs in the pyramid are trained in a cascaded way. The highest level FCN is first trained to achieve the coarse mask. Then, the residual error (difference between the coarse mask and ground truth) is propagated to the lower-level FCNs, so the lower-level FCNs try to find cell details missed by the upper-level; and (3) At each level of the pyramid, we derive a residual mask to reflect different types of segmentation errors from the upper-level FCN, which draws the attention of the FCN at the current level.

A typical FCN architecture.
2 Preliminaries
2.1 Fully Convolutional Networks (FCN)
The fully convolutional neural network only contains convolutional layers to generate the segmentation mask from the input image, as shown in Fig. 3. The fully convolutional neural network does not require a fixed-size input. The objective function could be pixel-wise such as the cross-entropy or mask-wise such as the dice-coefficient.
2.2 Gaussian Pyramid and Laplacian Pyramid
Let I be the original image, the Gaussian pyramid is denoted as \(\mathcal {G}(I) =\{I_1, \dots , I_k, \dots , I_K\}\), where K is the number of levels in the pyramid. \(I_1\) is the original image I and \(I_k\) at level k is downsized from the previous image \(I_{k-1}\). The Laplacian pyramid [5] is denoted as \(\mathcal {L}(I) = \{l_1, \dots ,l_k,\dots ,l_{K-1},I_K\}\), representing a set of difference images (except the smallest level). The \(I_K\) from Gaussian pyramid \(\mathcal {G}(I)\) and Laplacian pyramid \(\mathcal {L}(I)\) are the same, which is a downsized image with the smallest scale. \(l_k\) at level k of Laplacian pyramid is a difference image so that the image \(I_k\) in Gaussian pyramid can be reconstructed by Eq. 1:
where \(u(\cdot )\) is an up-sampling function, and \(d(\cdot )\) is a down-sampling function. After down-sampling and up-sampling in Eq. 2, the image \(I_k\) is blurred and smoothed, thus some content information is lost, which is recorded in the difference image \(l_k\). In the Laplacian pyramid, the original image can be sequentially reconstructed from level K to level 1 by applying Eq. 1 recursively.
3 Methodology
3.1 Pyramid-Based FCNs
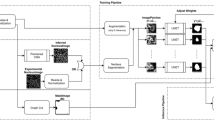
Given the original input image \(I_1\), we build a Gaussian pyramid \(\mathcal {G}(I) = \{I_1,\dots ,\) \(I_k,\dots ,I_K \}\). Figure 4 demonstrates our work-flow using K = 3 as an example. At each level k, there is a fully convolutional network (\(FCN_k\)) which segments image \(I_k\) into mask image \(M_k\). The FCNs will be trained sequentially following the coarse-to-fine fashion (to be described in Sect. 3.2) rather than independently.

Overview of the framework. This is an example of a pyramid with 3 levels. Each level is separated by the pink dashed line. Each fully convolutional network (FCN) has the input \(I_k\) on the left and the output \(M_k\) on the right. The up-sampled map is denoted by \('\). We use \(\oplus \) symbol to represent the combination by Eq. 3.
To fuse the segmentation results from all levels in the pyramid, we propose a recursive method similar to the reconstruction procedure in the Laplacian pyramid. First, the segmentation mask \(M_K\) at the top/smallest level K is up-sampled to \(M'_K\) whose size matches the image size at level \(K-1\) (i.e., \(M'_K=u(M_K)\)). Then, mask \(M'_K\) is combined with mask \(M_{K-1}\) at level \(K-1\) by an alpha-fusion (Eq. 3), with the combination result denoted as \(T_{K-1}\). The second iteration is to up-sample \(T_{K-1}\) and combine it with mask \(M_{K-2}\). The recursive combination procedure stops until reaching the level 1.
where \(\alpha \) (\(0<\alpha <1\)) is a parameter learned from cross-validation.
Using a 3-level pyramid as an example, Fig. 5 demonstrates the effect of our cascaded-trained FCNs and recursive segmentation fusion. \(M_3, M_2, M_1\) represent the probability maps (soft segmentation, \(M_{k,i}\) is the probability of pixel i being a cell pixel, i.e., \(M_{k,i}\in [0,1]\)) generated by the fully convolutional networks \(FCN_3, FCN_2, FCN_1\), respectively. \(FCN_3\) is trained to generate a coarse segmentation (\(M_3\)). \(FCN_2\) and \(FCN_1\) are trained to focus more on cell details that are missed in the upper-levels, as shown in \(M_2\) and \(M_1\). Note that, \(M_2\) and \(M_1\) may be imperfect (e.g., the inner regions of cells are missed) but they contain the cell boundary details that are complement to the segmentation of upper-levels. \(M'_3,T_2,T_1\) represent the recursively fused segmentation masks at each level, from which we can observe the segmentation mask is refined gradually. To better visualize the refinement process, we compute the residual mask defined as:

Comparison between the generated mask \(M_k\), the combined mask \(T_k\) and the residual mast \(\hat{M}_k\) for a 3-level pyramid. Red contour: the boundary of ground truth segmentation.
The residual mask at level k (\(\hat{M_k}\)) computes the weighted residual error between the ground truth at level k (\(G_k\)) and the segmentation result from the upper-level (\(u(T_{k+1})\)). There are four classes of pixels in the residual mask: (1) black pixels (\(\hat{M}_{k,i}<0\), i is the pixel location): false positives from the upper level segmentation \(u(T_{k+1})\) (the background pixels that are incorrectly classified in the upper level); (2) white pixels (\(\hat{M}_{k,i}>1\)): false negative from the upper level (the foreground cell pixels that are missed in the upper level); (3) light gray pixels (\(\hat{M}_{k,i}=1\)): the correctly classified cell pixels in the upper level; and (4) dark gray (\(\hat{M}_{k,i}=0\)): the correctly classified cell pixels in the upper level.
From the residual masks, we can observe that the lower level FCN focuses more on the mistakes (false positive and false negative) made in the upper level. Thus, the sequentially fused segmentation masks (\(T_k\)) are refined gradually (i.e., the number of black and white pixels in the residual mask decreases gradually). The cascaded refinement is also verified in the following mathematical derivation.
3.2 Objective Function and Optimization
The objective function for level k in a Gaussian pyramid without cascaded refinement is the cross-entropy function:
where i is the pixel location and y denotes the class in segmentation masks (\(y\in \{0,1\}\), representing cell or background). The gradient over \(M_{k,i,y}\) is:
which will be transferred backward in FCN to calculate the gradient over the parameters of the FCN through back-propagation process [11].
In our pyramid based FCNs, the objective function at the top/smallest level is Eq. 5 with k = K. The objective function of lower levels (\(1 \le k<K\)) is:
Since \(T_k\) is the combined mask of \(M_k\) and \(T_{k+1}'\), the gradient over \(M_{k,i,y}\) is:
which will be transferred backward in the FCN for training. The last term \(\alpha \) does not effect the training precess with a proper learning rate. Denote the denominator in Eq. 8 as \(\beta \) for shorthand, when \(T_{k+1,i,y}' > M_{k,i,y}\), we have \(\alpha M_{k,i,y} + (1-\alpha ) T_{k+1,i,y}' > \alpha M_{k,i,y} + (1-\alpha ) M_{k,i,y}\) (i.e., \(\beta > M_{k,i,y}\)), which means our gradient in Eq. 8 is smaller than that in Eq. 6. In other words, when the upper level FCN achieves good segmentation at pixel i, the lower level FCN will pay less attention on pixel i. On the other hand, when \(T_{k+1,i,y}' < M_{k,i,y}\), we have \(\beta < M_{k,i,y}\), which means the gradient in Eq. 8 is increased compared to Eq. 6 without cascaded refinement. In other words, when the upper level FCN does not generate good segmentation on pixel i, the lower level FCN will focus more on pixel i.

Segmentation results on dataset PHC [9]. Red contour: the boundary of ground truth segmentation.
4 Experiments
In this section, we validate our approach on two datasets. The first dataset (PHC) is the phase-contrast dataset “PhC-U373” from the ISBI cell segmentation challenge in 2015 [8, 9]. The dataset contains 34 partially annotated images for training. The images are resized to 512\(\,\times \,\)512. We collect the second dataset (Phase100) consisting of 100 images (512\(\,\times \,\)512) in total. 40 images are used for training. 20 images are used for cross-validation.
Neural Network Structures and Experimental Settings: the fully convolutional network at each level has 11 convolutional layers with batch-normalization on the first 9 layers. The filter size is fixed as 3 for each convolutional layer. The number of kernels in each layer is: 64, 64, 128, 128, 256, 256, 128, 128, 64, 64, 2. Since the input images at different levels have different sizes, the fixed-size receptive field (3\(\,\times \,\)3) extracts image content information from different scales. The learning rate is set as \(10^{-3}\), then divided by 10 when the loss nearly stops decreasing. After obtaining the final probability map (soft segmentation) by cascaded fusing the output from FCNs, we threshold it to get the bitmap. The threshold is 0.47 and the \(\alpha \) in fusion is 0.5, learned from the cross-validation. We use shift, scale and rotation operations for data augmentation.

Sample images in Phase100 dataset and segmentation results.
Evaluation: We perform sensitivity study on the number of pyramid levels (K) and compare our method with three methods: U-Net [1], FCN [2] (a fully convolutional network on the original image without pyramid), and Gaussian (A 3-level Gaussian pyramid is built. For each level of the pyramid, the fully convolutional network is trained independently. Then all the results from different levels are combined by the cascaded fusion as Eq. 3). Figure 6 shows some qualitative results on the comparison. We summarize the sensitivity study and quantitative comparison in Table 1 in terms of three metrics: F-score, IOU (pixel-wise intersection over union, between the segmentation and ground truth) and area-under-curve (the curve of precision vs. recall). The performance of our pyramid-based method increases when the number of pyramid levels increases from K = 2 to K = 3, and slightly drops with more levels. Our method outperforms the U-Net by about 2 % points on the ISBI segmentation challenge phase-contrast dataset (PHC). Our method with cascaded training beats the ‘Gaussian’ method with independent training by a large margin, which validates that in our method the lower level FCNs focus more on mistakes made from upper-level FCNs such that the fused segmentation mask is gradually refined.
When checking the quality of human-labeled ground truth in the ISBI segmentation challenge dataset, we notice that some cell labels are missed (e.g., 2nd row of Fig. 6). We collect a new Phase100 dataset by staining the cells and capturing their images with both phase contrast and fluorescent microscopy, as shown in Fig. 7(a) and (b). The fluorescent image (Fig. 7(b)) shows a high quality soft segmentation without human errors, which can be thresholded to a bitmap (Fig. 7(c)). (Note, for long-term cell monitoring, cells cannot be stained to damage their viability. The staining here is only for the purpose of collecting ground-truth.) The probability maps generated by U-Net and our method are shown in Fig. 7(d) and Fig. 7(e), respectively. The quantitative comparison in the bottom of Table 1 shows that our method outperforms U-Net on the Phase100 dataset. The high quality dataset with soft segmentation ground truth will be publicized along with the codes.
5 Conclusion
In this paper, we present pyramid-based fully convolutional networks (FCN) to attack the challenges in cell segmentation such as low contrast and irregular cell shapes. The accurate segmentation mask is achieved by fusing the segmentation outputs of all FCNs at different levels, in a cascaded refinement manner. The effectiveness of our method is validated on two datasets, which outperforms state-of-the-art methods.
References
Ronneberger, O., Fischer, P., Brox, T.: U-net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: CVPR (2015)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. In: NIPS (2012)
He, K., et al.: Mask R-CNN. In: ICCV (2017)
Burt, P.J., Adelson, E.H.: The Laplacian pyramid as a compact image code. In: Readings in Computer Vision, pp. 671–679 (1987)
Denton, E.L., Chintala, S., Fergus, R.: Deep generative image models using a Laplacian pyramid of adversarial networks. In: NIPS (2015)
Ghiasi, G., Fowlkes, C.C.: Laplacian pyramid reconstruction and refinement for semantic segmentation. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9907, pp. 519–534. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46487-9_32
WWW: Web page of the ISBI cell tracking challenge. http://www.celltrackingchallenge.net
Maka, M., et al.: A benchmark for comparison of cell tracking algorithms. Bioinformatics 30(11), 1609–1617 (2014)
Ciresan, D., et al.: Deep neural networks segment neuronal membranes in electron microscopy images. In: NIPS (2012)
LeCun, Y., et al.: Handwritten digit recognition with a back-propagation network. In: NIPS (1990)
Meijering, E.: Cell segmentation: 50 years down the road [life sciences]. IEEE Sig. Process. Mag. 29(5), 140–145 (2012)
Acknowledgement
This project was supported by NSF CAREER award IIS-1351049 and NSF EPSCoR grant IIA-1355406.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Zhao, T., Yin, Z. (2018). Pyramid-Based Fully Convolutional Networks for Cell Segmentation. In: Frangi, A., Schnabel, J., Davatzikos, C., Alberola-López, C., Fichtinger, G. (eds) Medical Image Computing and Computer Assisted Intervention – MICCAI 2018. MICCAI 2018. Lecture Notes in Computer Science(), vol 11073. Springer, Cham. https://doi.org/10.1007/978-3-030-00937-3_77
Download citation
DOI: https://doi.org/10.1007/978-3-030-00937-3_77
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-00936-6
Online ISBN: 978-3-030-00937-3
eBook Packages: Computer ScienceComputer Science (R0)