
Abstract
In this paper, we propose a novel deep learning framework for hyperspectral image (HSI) spectral-spatial classification. This framework mainly consists of two components: convolutional neural network (CNN) and gated recurrent unit (GRU). CNN is used to automatically extract the high-level spatial features of each band, which are then fed into a fusion network based on GRUs. This fusion network combines feature-level fusion and decision-level fusion together in an end-to-end manner, thus sufficiently fusing the complementary information from different spectral bands. To demonstrate the effectiveness of the proposed method, we compare it with several state-of-the-art deep learning methods on two real HSIs. Experimental results show that the proposed method can achieve better performance than comparison methods.
F. Zhou—Currently working toward the Master degree in the School of Information and Control, Nanjing University of Information Science and Technology.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
- Hyperspectral image classification
- Convolutional neural network
- Gated recurrent unit
- Spectral-spatial fusion
1 Introduction
Hyperspectral image (HSI) can capture both spatial and spectral information of the specific object on the land surface. Such abundant information in HSI can be applied in a variety of fields, such as resource management, military, and urban development. HSI classification which aims at assigning a specific class to each pixel in the scene is a crucial step for the aforementioned applications.
HSI is usually composed of several hundreds of spectral bands spanning from the visible spectrum to infrared spectrum. A substantial number of spectral bands in the HSI reflect different spectral characteristics of the object in the same location. Traditional spectral feature based classifiers include K nearest neighbors (KNN), logistic regression and so on. Due to the high dimensionality of spectral information, most of these methods inevitably suffer from this phenomenon (i.e., curse of dimensionality). To reduce the Hughes phenomenon, support vector machines (SVMs) have been explored for improving the classification performance. SVM-based classifiers often perform better than other supervised classifiers when training samples are limited owing to their low sensitivity to the data with high dimensionality and small sample size.
With the development of hyperspectral sensors, the spatial resolution of HSI is becoming higher and higher. For example, the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) sensor is able to cover hundreds of spectral bands with a spatial resolution of 3.7 m. To further improve the classification performance, many methods consider incorporating the rich spatial information into spectral information [12, 14]. For example, markov random field (MRF) model the joint prior probabilities of each pixel by incorporating its spatial neighbors into the Bayesian classifier as a regularizer [9]. Morphological profile and its extensions are widely used to extract spectral-spatial feature of HSI [1]. Multiple kernel learning designed to improve SVM classifier is a powerful technology to handle heterogeneous fusion of both spectral and spatial features [7].
Recently, deep learning has made promising achievements in spectral-spatial feature extraction for HSI classification [2, 13, 17]. Compared with traditional classification methods, deep learning models can extract the invariant and discriminant features in a hierarchical manner. Chen et al. proposed a deep learning classification framework composed of multilayer stacked autoencoders (SAE) to extract the spectral-spatial feature [3]. Another deep learning network, deep belief network (DBN) was also proposed for HSI classification [4]. Although these two networks can effectively extract deep features for classification, they have to transform the input into a 1-D vector, resulting in the loss of spatial information. Therefore, Yue et al. proposed principal component analysis (PCA) based 2-D convolutional neural network (CNN) [15]. Due to the use of PCA on HSI, 2-D CNN may lose the spectral information. To simultaneously learn the spectral and spatial features, 3-D CNN [2] was proposed to take the original hyperspectral image cube as an input. However, CNN cannot model the dependencies between non-adjacent spectral bands due to its local connection property. To address this issue, long short term memory (LSTM) based classification methods were proposed to learn the dependencies between non-adjacent spectral bands. For examples, spectral-spatial LSTMs (SSLSTMs) [17] utilized LSTM to extract spectral and spatial features, respectively; Bidirectional-convolutional LSTM (Bi-CLSTM) [13] incorporate convolution operator into LSTM to extract spectral and spatial features simultaneously. However, these two methods still exist some issues. On the one hand, as a kind of fully-connected neural networks, spatial LSTM of SSLSTMs is inferior to CNN in extracting spatial feature. Although Bi-CLSTM introduces the convolution operator into LSTM, it has only one convolutional layer which may be not enough to extract high-level spatial feature for classification. On the other hand, in the classification phase, Bi-CLSTM directly concatenate all spatial features in each band into a high-dimensional vector, which increases the computational complexity of the network; SSLSTMs only use the last output of LSTM to classify the hyperspectral pixel, leading to the loss of spectral information.
To address the aforementioned issues, we propose a novel deep learning framework to integrate the superiority of CNN and gated recurrent unit (GRU) [5] in this paper. Similar to [15], CNN is used to extract the spatial features of each spectral band, while GRU is used to construct a fusion network to fuse the spatial features from different spectral bands. Different from LSTM, GRU can effectively alleviate the gradient vanishing problem while modeling long term dependency. Similar to LSTM, GRU can also model the dependencies between different spectral bands, which can be considered as a feature-level fusion process. In the classification stage, each band outputs a classification result and a weighted summation method is used to fuse the results from different bands, which can be considered as a decision-level fusion process. All the fusion weights are learned from data itself in an end-to-end manner.
The remainder of this paper is organized as follows. Section 2 gives the detail of the proposed classification framework. Experiments conducted on real HSIs are shown in Sect. 3. Section 4 concludes this paper.

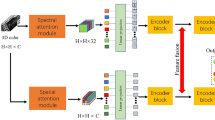
The flowchart of the proposed spectral-spatial classification framework.
2 The Proposed Classification Framework
To begin with, the original hyperspectral image can be defined as a 3-D matrix \(\mathcal {X}\in \mathbf {R}^{{M}\times {N}\times {K}}\), where \({M}\times {N}\) is the spatial size and K is the number of spectral bands. To take both spectral and spatial information into consideration, we use the small sub-cube \({x}\in \mathbf {R}^{{S}\times {S}\times {K}}\) centered at a specific pixel to represent it. Lets assume that we have N training samples \({X}=[{x}_{1},{x}_{2},\ldots ,{x}_{N}]\), where each sample is a sub-cube. The goal of the classification framework is to assign these samples to the corresponding classes, \({Y}=[{y}_{1},{y}_{2},\ldots ,{y}_{N}]\). The flowchart of the proposed method is shown in Fig. 1. Firstly, we train a CNN for HSI classification which aims at learning spatial feature from HSIs, and then mapping raw training samples into the embedding subspace \({Z}=[{z}_{1},{z}_{2},\ldots ,{z}_{N}]\) by the trained CNN. After that, extracted spatial features are fed into GRU to model the dependencies between spectral bands and further fuse spectral information on both feature level and decision level. Finally, we use the weighted summation of all outputs of GRU as the final classification result. In the following subsections, we will introduce the whole process in detail.

The structure of CNN.
2.1 Spatial Feature Extraction Network
A CNN [11], is a class of neural networks that excelled at extracting spatial feature from the image. Different from other fully-connected deep learning models (e.g., SAE, DBN, LSTM), CNN takes the original 2-D image as an input, retaining the spatial structure of the image. To capture the spatial information of HSI, we design the CNN illustrated in Fig. 2. The proposed CNN contains three parts: three convolution layers, three pooling layers, and one softmax layer. Meanwhile, to address the small sample problem, we transform the raw sample into K new samples by splitting the HSI sub-cube across spectral channels, i.e., \({x}_{n}=[{x}_{n1},{x}_{n2},\ldots ,{x}_{nK}]\) where \({x}_{nl}\in \mathbf {R}^{{S}\times {S}\times {1}}\). The newly generated samples share the same label with the raw sample. Followings are detailed introductions of each component of the CNN.
Convolution Layer: Convolution layer is the most important part in the CNN. By stacking multiple convolution layers, CNN can derive the high-level semantic feature of the input image. Let \({f}_{j}\) be the j-th output feature map, \({x}_{i}\) be the i-th input feature map. The \({f}_{j}\) can be formulated as \({f}_{j} = \sum _{i=1}^C \sigma ({x}_{i}*{w}_{j}+{b}_{j})\) where C is the number of input channels, ‘\(*\)’ represents discrete convolution operation, ‘\(\sigma \)’ refers to nonlinear function, and \({w}_{j}\) and \({b}_{j}\) represent the weight and bias of the j-th convolution kernel respectively.
Pooling Layer: The pooling layer mainly reduces the amount of parameters and the computation of the network by reducing the spatial size of the feature map. Specifically, for a \({q}\times {q}\) window, the max pooling operation can be formulated as \({f} = \max \limits _{1\leqslant {i}\leqslant {q},1\leqslant {j}\leqslant {q}}{x}_{ij}\) where \({x}_{ij}\) is the pixel value corresponding to the position (i, j).
Softmax Layer: The softmax layer takes a hidden vector as the input and obtain the classification result. The probability that the pixel belongs to i-th class can be formulated as \({P(Class=i)} = \frac{e^{w_{i}x_{i}}}{\sum _{j=1}^L e^{w_{j}x_{j}}}\) where \({x}_{i}\) and \({x}_{j}\) represent i-th and j-th value of the input respectively, and analogously, \({w}_{i}\) and \({w}_{j}\) represent the weights corresponding to i-th and j-th class respectively. L is the number of classes.
We train the proposed CNN by optimizing the cross entropy function with Adam algorithm [10]. After that, the trained CNN is used to extract spatial feature of each pixel. Specifically, for a given pixel \({x}_{n}\in \mathbf {R}^{{S}\times {S}\times {K}}\), it is firstly split into a sequence across spectral channels i.e., \({x}_{n}=[{x}_{n1},{x}_{n2},\ldots ,{x}_{nK}]\) where \({x}_{nl}\in \mathbf {R}^{{S}\times {S}\times {1}}\) denotes the l-th band value and K is the number of spectral bands. Then, each band is fed into the trained CNN successively to obtain the spatial feature \({z}_{n}\in \mathbf {R}^{d_{z}\times {K}}\) where \(d_{z}\) represents the output dimension of the last pooling layer. Similarly, we apply the trained CNN to all training samples \({X}=[{x}_{1},{x}_{2},\ldots ,{x}_{N}]\) and get spatial features \({Z}=\{{z}_{1},{z}_{2},\ldots ,{z}_{N}|{z}_{n}\in \mathbf {R}^{d_{z}\times {K}}\}\).

The proposed fusion network based on GRUs.
2.2 The Fusion Network
In order to efficiently process the high-dimension spectral information, some LSTM-based methods [13, 17] (e.g., SSLSTMs, Bi-CLSTM) explore the representation of hyperspectral pixels in a sequential manner instead of treating hyperspectral pixels as vectors. However, there still exist some issues. Bi-CLSTM concatenates spatial features from all spectral bands directly, producing high-dimension feature space. Although SSLSTMs prevent it from producing high-dimension feature space via a decision-level fusion, it only uses the last output of LSTM to classify the hyperspectral pixel, resulting in the loss of spectral information. To address these issues, we propose a fusion network based on GRUs. As shown in Fig. 3, the network contains two GRU-based recurrent layers and a weighted summation layer. GRU, which only contains ‘reset’ and ‘update’ gates, is a simplified version of LSTM [8]. It has shown promising results in many sequence-based tasks with long-term dependencies [16]. Besides, compared with LSTM, GRU can effectively reduce the amount of parameters and alleviate the gradient vanishing problem when modeling long term dependency [6]. Therefore, we use GRU rather than LSTM to build a classification network to model long term dependencies between spectral bands. Furthermore, we combine feature-level fusion and decision-level fusion in the proposed fusion network to sufficiently fuse the complementary information from different spectral bands. For feature-level fusion, we fuse spatial features derived from different spectral bands by means of the GRU’s recurrent connection instead of concatenating them directly. For decision-level fusion, we regard each output of GRU as one classification result and fuse them with a weighted summation method, avoiding losing spectral information. The detailed computational procedure of fusion network can be summarized as follows.
We feed the spatial features \({Z}=\{{z}_{1},{z}_{2},\ldots ,{z}_{N}|{z}_{n}\in \mathbf {R}^{d_{z}\times {K}}\}\) derived from Sect. 2.1 into GRU to capture spectral information. For the n-th training sample \({z}_{n}\), it is first split into a sequence \(\{{z}_{n1},{z}_{n2},\ldots ,{z}_{nK}|{z}_{ni}\in \mathbf {R}^{d_{z}}\}\) across spectral channels and then fed into GRU one by one. The i-th output \(h_{i}\) of GRU is calculated by previous output \(h_{i-1}\) and current input \(z_{ni}\), which can be formulated as
where \({\sigma }\) is the logistic sigmoid function, ‘\({\cdot }\)’ denotes matrix multiplication, ‘\({*}\)’ denotes Hadamard product, \(W_{u}\) represents update gate matrix, \(W_{r}\) represents reset gate matrix, and W is a single weight matrix.
After extracting spectral feature by GRU, we can get a series of predicted values \([P_{1},P_{2},\ldots ,P_{K}]\). To make full use of these values, we make weighted summation on them. The final classification result \(P_{final}\) can be obtained by
where \(w_{i}\) represents the weight of \(P_{i}\) and K is the number of spectral bands.
The weights in Eq. (2) and parameters of GRU can be adaptively determined by optimizing the following loss function with Adam algorithm: \({Loss}=-\sum Y\log \sum _{i=1}^K w_{i}P_{i}\) where Y is the real label.
3 Experimental Results
3.1 Datasets and Experiment Setup
We test the proposed deep learning classification framework on two real HSIs, which are widely used to evaluate classification algorithms.

False-color composite images and ground-truth maps of (a)-(b) IP, (c)-(d) KSC.
Indian Pines (IP): The first dataset was acquired by the AVIRIS sensor over the Indian Pine test site in northwestern Indiana, USA, on June 12, 1992 with \(145\times 145\) pixels. It contains 200 spectral bands with the wave-length range from \(0.4-2.5\,\upmu \)m and the spatial resolution is 20 m. The false-color composite image and the ground-truth map are shown in Fig. 4(a)–(b). The available number of samples is 10249 ranging from 20 to 2455 in each class.
Kennedy Space Center (KSC): The second dataset was acquired by the AVIRIS sensor over Kennedy Space Center, Florida, on 23 March 1996. It contains 176 spectral bands. The spatial resolution is 18 m with \(512\times 614\) pixels. For classification purposes, 13 classes representing the various land-cover types that occur in this environment are defined. Figure 4(c)–(d) demonstrate a false-color composite image and the ground truth map.
In order to reduce the effect of random selection, all the algorithms are repeated five times and the average results are reported. Besides, to evaluate the performance of different models for HSI classification, we use the following evaluation indicators: overall accuracy (OA), average accuracy (AA), per-class accuracy, and Kappa coefficient \(\kappa \). OA defines the ratio between the number of correctly classified pixels to the total number of pixels in the test set, AA refers to the average of accuracies in all classes, and \(\kappa \) is the percentage of agreement corrected by the number of agreements that would be expected purely by chance.
To validate the effectiveness of the proposed classification framework, it is compared with several state-of-the-art deep learning methods, including 2-D CNN, 3-D CNN, SSLSTMs, CNN+LSTM and Bi-CLSTM. Specifically, for 2-D CNN and 3-D CNN, we take the same configuration as described in [2]. For SSLSTMs, we utilize the same configuration listed in [17]. For CNN+LSTM, we apply CNN to extract spatial features from each band and then employ LSTM to fuse them. The configuration of CNN is the same as that in [2], and the number of hidden nodes in LSTM is 128. For Bi-CLSTM, we use the same network structure and the parameters described in [13]. Additionally, for IP and KSC datasets, we select \(10\%\) pixels from each class as the training set, and the remaining pixels as the test set.
3.2 Parameter Selection
There are three important influence factors in the proposed method, including the configuration of CNN, the spatial size of input sub-cubes, and the number of hidden nodes in GRU. Firstly, we empirically choose the network parameters listed in Table 1.
Secondly, we fix the number of hidden nodes in GRU and select the optimal spatial size of input sub-cubes from a given set \(\{19\times 19, 23\times 23, 27\times 27, 31\times 31, 35\times 35\}\). Table 2 shows OAs of the proposed method on two HSIs. It can be observed that as the spatial size of input sub-cubes increases, OA will firstly increase and then decrease on both IP and KSC. Therefore, the optimal spatial size is chosen as \({31\times 31}\) for IP and KSC datasets.
Finally, we fix the spatial size of input sub-cubes and search for the optimal number of hidden nodes for GRU from five candidate values \(\{64, 128, 256, 512, 1024\}\). Note that, the number of hidden nodes of second layer in GRU is determined by the number of class of each data. Thus, we only need to choose the number of hidden nodes in the first layer. Table 3 demonstrates the effects of different numbers of hidden nodes on OA of IP and KSC datasets. From this table, we can observe that the proposed method achieves the highest OA when the number of hidden nodes is set to 128.

Classification maps on the IP dataset. (a) 2-D CNN. (b) 3-D CNN. (c) SSLSTMs. (d) CNN+LSTM. (e) Bi-CLSTM. (f) Ours.
3.3 Performance Comparison
The classification maps of the IP dataset obtained by six methods are shown in Fig. 5. Besides, the corresponding accuracy indexes, and the number of training and test samples are presented in Table 4. From these results, we can observe that 2-D CNN achieves the lowest OA among six methods. This is because it only uses the first principal component of all spectral bands, leading to the loss of spectral information. Compared with 2-D CNN, CNN+LSTM improves the classification performance because LSTM can extract the spectral feature from all spectral bands. However, the spectral feature extraction and spatial feature extraction processes are independent, making the trained parameters in CNN+LSTM may be not the optimal ones. Therefore, SSLSTMs which attempts to integrate two well-trained LSTMs designed for spectral and spatial features extraction respectively by decision-level fusion, outperforming CNN+LSTM and 2-D CNN. Nevertheless, LSTM is inferior to CNN in spatial feature extraction. 3-D CNN and Bi-CLSTM can address this issue by using convolution operator to extract spatial feature, and achieve the higher OA, AA, and than SSLSTMs. For 3-D CNN, the sub-cube with specific number of spectral bands is taken as an input of the network, ignoring the relationships between non-adjacent spectral bands. Different from 3-D CNN, Bi-CLSTM can model the correlations across all the spectral bands via recurrent connections. Therefore, compared to 3-D CNN, Bi-CLSTM improves OA from \(95.30\%\) to \(96.78\%\). However, Bi-CLSTM concatenates all spatial features in each band into a high-dimensional vector, which increases the computational complexity of the network. Besides, Bi-CLSTM cannot sufficiently extract high-level semantic feature of the HSI only with one convolution layer. The proposed classification framework combines feature-level fusion and decision-level fusion to incorporate spatial information into spectral information. Furthermore, a 3-layer CNN is used to extract spatial feature in our proposed method. Owing to these, our method can improve OA from \(96.78\%\) to \(98.67\%\) compared with Bi-CLSTM.

Classification maps on the KSC dataset. (a) 2-D CNN. (b) 3-D CNN. (c) SSLSTMs. (d) CNN+LSTM. (e) Bi-CLSTM. (f) Ours.
For KSC dataset, we can draw the similar conclusions from Table 5 and Fig. 6. 3-D CNN, SSLSTMs, and Bi-CLSTM achieve better performance than 2-D CNN and CNN+LSTM. Specifically, OA, AA and \(\kappa \) obtained by SSLSTMs and Bi-CLSTM are higher than 3-D CNN, and Bi-CLSTM obtains better performance than 3-D CNN. Similar to IP dataset, the proposed method achieves the highest OA, AA and \(\kappa \) than other methods.
4 Conclusion
In this paper, we propose a hyperspectral image (HSI) classification method based on convolutional neural network (CNN) and gated recurrent unit (GRU). First, we use CNN to extract spatial feature of each band. Then, GRU is utilized to fuse each band’s spatial feature. The proposed method is compared with several state-of-the-art deep learning methods on two HSIs. Experimental results demonstrate that sufficiently fusing spectral information and spatial information can improve classification performance. We also evaluated the influences of different parameters in the network, including the spatial size of input sub-cubes and the number of hidden nodes.
References
Benediktsson, J.A., Palmason, J.A., Sveinsson, J.R.: Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 43(3), 480–491 (2005)
Chen, Y., Jiang, H., Li, C., Jia, X., Ghamisi, P.: Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 54(10), 6232–6251 (2016)
Chen, Y., Lin, Z., Zhao, X., Wang, G., Gu, Y.: Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 7(6), 2094–2107 (2014)
Chen, Y., Zhao, X., Jia, X.: Spectral-spatial classification of hyperspectral data based on deep belief network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 8(6), 2381–2392 (2015)
Cho, K., et al.: Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078 (2014)
Chung, J., Gulcehre, C., Cho, K., Bengio, Y.: Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555 (2014)
Gu, Y., Chanussot, J., Jia, X., Benediktsson, J.A.: Multiple kernel learning for hyperspectral image classification: a review. IEEE Trans. Geosci. Remote Sens. 55(11), 6547–6565 (2017)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Jackson, Q., Landgrebe, D.A.: Adaptive Bayesian contextual classification based on markov random fields. IEEE Trans. Geosci. Remote Sens. 40(11), 2454–2463 (2002)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
LeCun, Y., Haffner, P., Bottou, L., Bengio, Y.: Object recognition with gradient-based learning. Shape, Contour and Grouping in Computer Vision. LNCS, vol. 1681, pp. 319–345. Springer, Heidelberg (1999). https://doi.org/10.1007/3-540-46805-6_19
Liu, J., Wu, Z., Wei, Z., Xiao, L., Sun, L.: Spatial-spectral kernel sparse representation for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 6(6), 2462–2471 (2013)
Liu, Q., Zhou, F., Hang, R., Yuan, X.: Bidirectional-convolutional lstm based spectral-spatial feature learning for hyperspectral image classification. Remote Sens. 9(12), 1330 (2017)
Sun, L., Wu, Z., Liu, J., Xiao, L., Wei, Z.: Supervised spectral-spatial hyperspectral image classification with weighted markov random fields. IEEE Trans. Geosci. Remote Sens. 53(3), 1490–1503 (2015)
Yue, J., Zhao, W., Mao, S., Liu, H.: Spectral-spatial classification of hyperspectral images using deep convolutional neural networks. Remote Sens. Lett. 6(6), 468–477 (2015)
Zhao, R., Wang, D., Yan, R., Mao, K., Shen, F., Wang, J.: Machine health monitoring using local feature-based gated recurrent unit networks. IEEE Trans. Ind. Electron. 65(2), 1539–1548 (2018)
Zhou, F., Hang, R., Liu, Q., Yuan, X.: Hyperspectral image classification using spectral-spatial LSTMs. In: Yang, J., et al. (eds.) CCCV 2017. CCIS, vol. 771, pp. 577–588. Springer, Singapore (2017). https://doi.org/10.1007/978-981-10-7299-4_48
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China under Grant Numbers: 61532009 and, in part, by the Foundation of Jiangsu Province, China, under Grant 18KJB520032.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Zhou, F., Hang, R., Liu, Q., Yuan, X. (2018). Integrating Convolutional Neural Network and Gated Recurrent Unit for Hyperspectral Image Spectral-Spatial Classification. In: Lai, JH., et al. Pattern Recognition and Computer Vision. PRCV 2018. Lecture Notes in Computer Science(), vol 11259. Springer, Cham. https://doi.org/10.1007/978-3-030-03341-5_34
Download citation
DOI: https://doi.org/10.1007/978-3-030-03341-5_34
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-03340-8
Online ISBN: 978-3-030-03341-5
eBook Packages: Computer ScienceComputer Science (R0)