
Abstract
Pedestrian salient detection aims at identifying person body parts in occluded person images, which is greatly significant in occluded person re-identification. To achieve pedestrian salient detection, we propose a double-line multi-scale fusion (DMF) network, which not only extracts double-line features and retains both high-level and low-level semantic information but also fuses high-level information and low-level information for better complement. CRF is then used to further improve its performance. Finally, our method is used to deal with occluded person images into partial person images to achieve partial person re-identification matching. Experiment results on five benchmark datasets show the superiority of our proposed method, and result on two occluded person re-identification datasets indicate the effectiveness of our proposal on pedestrian salient detection.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Nowadays, video surveillance has been widely used in many security-sensitive places, such as hospital, school, bank, museum, etc and the areas of video surveillance are often non-overlapping. Therefore, person re-identification (re-id) [1,2,3,4,5] across non-overlapping cameras was proposed and widely studied. However, person re-id has encountered many challenges, the most serious one of which is occlusion.
As we know, in crowed public places, there are always some pedestrians occluded by some objects, e.g. cars, trees, garbage cans. So occluded person re-id is needed for actual pedestrian applications. In occluded person re-id, one of the hardest problems is how to deal with occluded person images because pedestrian images detected by most of pedestrian detectors always include occlusions. While the useful information what we need is only the person body parts. These occlusion areas cause interference for person re-id and bring more redundant information in matching process, which leads to the dropping performance of re-id. As shown in Fig. 1, among the works related with occluded person re-id [6, 7], Zheng [7] used partial person images to match the full-body person images by the framework combining a local-to-local matching model with a global-to-local matching model and achieved effective results. However, in the practical situation, there are no suitable detectors to detect the occlusions for occlusions with diverse characteristics, such as colors, sizes, shapes, and positions. The partial person images are gained by manually cropping, which brings operational trouble and time waste (See Fig. 1). Differed from the idea of detecting occlusions, we consider detecting the useful information needed in occluded person images, that is, the person body parts.

Illustration of partial person re-id solving occlusions. (a): occluded person images detected by existing pedestrian detector; (b): partial person images after manually crop ping; (c): full-body person images which partial person re-id searches for.
Referring to other works on detecting human body parts, most of works aim to detect or cluster specific local part regions, such as head, shoulder, arm, leg and foot of persons. For occluded images, since either the occlusion or non-occluded body parts are always irregular, it is difficult to get a definite boundaries between body and occlusions using methods with detecting bounding boxes, which results in poor cutting. Differed from other works, we used a deep learning based saliency detection framework to detect person body parts and obtain partial person regions. There are two main reasons using saliency detection framework: Firstly, the saliency detection methods are able to separate the foreground and the background of an image in the pixel level, which leads to higher definition. It can better find the boundaries between the regions of person body parts and the regions of backgrounds or noise areas. Second, the deep learning based saliency detection network has ability to learn semantic information, which helps the framework distinguish the semantics of the parts that we need to acquire, namely the person body parts regions (Fig. 2).

Illustration of partial person re-id solving occlusions. (a): occluded person images detected by existing pedestrian detector; (b): partial person images after manually crop ping; (c): full-body person images which partial person re-id searches for.
Although saliency detection methods have been studied excellently, few works make initial attempts to solve occluded person re-id. Due to the poor quality of most person re-id benchmark datasets, there are higher requirements for the extracted features of saliency detection being proposed, that is, the information of images needs to be carefully preserved as far as possible. This paper proposes a double-line multi-scale fusion (DMF) network, which not only extracts richer features by double-line block and multi-scale fusion block but further improves the feature fusion process to make the high-level and low-level information better complemented. Besides, a fully-connected CRF [8] is used after DMF network for further improvement. After using the saliency detection network proposed in this paper to preprocess the occluded person images, we can obtain masks of occluded person images and crop the interesting regions in occluded person images into partial person images so as to achieve partial person re-id. In summary, this paper makes three main contributions.
-
It is a new attempt that saliency detection is used in occluded person re-id problem, which is used to detect the person body parts on the pixel-level and then crop occluded person images into partial person images.
-
To reach complementation of high-level and lower-level information, we propose a double-line multi-scale fusion (DMF) network consisting of the double-line feature extraction block and multi-scale feature fusion block. The former makes information diverse and the latter makes information from different scales fusing and complemented.
-
Experiments on five heterogeneous benchmark datasets show high performance of our approach compared with other state-of-art methods. Besides, our approach is used in two banchmask occluded person re-id datasets to deal with occluded person images.
2 Proposed Method
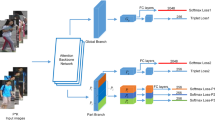
We propose a double-line multi-scale fusion (DMF) network for saliency detection, which is based on the VGG-16 [9] network, as shown in Fig. 3. The DMF network includes two main components: the double-line feature extraction block and multi-scale feature fusion block. To make extracted features more diverse, the double-line block calculates the difference of the feature after average pooling and then we connect it with the original feature in order to get richer information. The multi-scale fusion block aims to combine high-level information with lower-level information to reduce the loss of details on the ground floor. Finally, features form the based network VGG-16 and double-line multi-scale fusion are connected and put into softmax loss to obtain predicted masks. We also use a fully-connected CRF [8] as a post-processing step. This saliency detection can be used in the process of dealing with occluded person images in occluded person re-id.

Illustration of partial person re-id solving occlusions. (a): occluded person images detected by existing pedestrian detector; (b): partial person images after manually crop ping; (c): full-body person images which partial person re-id searches for.
2.1 Double-Line Feature Extraction
For saliency detection, it is greatly important that extracted features have ability to distinguish the foreground and the background, so we need to extract richer features to do determination. In this paper, we adopt a structure similar to feature pyramid [10]. Our network first used VGG-16 as basic network to extract features, in which all the convolution layers are divided into five convolution blocks and output features from each convolution block. This way aims to retain information from each floor and increase the diversity of features. In addition, the more important ways to increase the feature diversity is the double-line feature extraction part. As shown in Fig. 3(a), this structure of this part consists of a convolutional layer and an average pooling layer, which has two outputs. One output \(X_i^{conv}\) is the feature \(X_i\) through the convolutional layer, and the other \(X_i^{conv}-X_i^{pool}\) is similar to pooling residual structure, which means the difference (D-value) between \(X_i\) and \(X_i\) after average pooling. Then the double-line output is connected in series as final output. In this process, the pooling residual structure can offer other abundant information because average pooling has the effect to smooth images and the difference between original images and smoothing images can embody some outstanding information, which we desire to grasp.
Let \(X_i (i={1,2,3,4,5})\) denote output features after each convolution block of VGG-16 network, and \(X_i^{conv}\) and \(X_i^{pool}\) are feature \(X_i\) through the convolutional layer and the average pooling layer, respectively. The result of double-line feature extraction block can be expressed as:
After double-line feature extraction, features are merged with the deconvolution upsampling of the next block as the final double-line output, and then enter the multi-scale feature fusion block. The concrete fusion operation will be explained in the next section.
2.2 Multi-scale Feature Fusion
Actually, if we only grasp high-level features, the output would lose plenty of important details in low-level feature floor, leading to poor saliency detection. Considering the above condition, we use a multi-scale feature fusion structure to fuse high-level and low-level features until all the feature floors are fused together. In order to make unified fusion size between upper and lower layer, we do the deconvolution upsampling for high-level floor and then add to low-level double-line features, respectively. After fusing, we use a convolution layer to smooth the fusion results. In this way, our final output features greatly incorporate all high-level semantic information and low-level semantic information. The concrete structure is shown in Fig. 3(b). In the paper [11], the high-level low-level features are directly concated to lower level features, which only retains multiple levels of information. While our network further lets these information be merged to achieve a complementary effect so that the final output features both focus on large objects and details or small objects, achieving stronger saliency detection.
The operation of feature fusion is mathematically that sum the corresponding pixel points of deconvoluted high-level feature maps and the last double-line features, which is formulated as
where \(X_i^{fus}\) is output features after one multi-scale feature fusion block corresponding to the \(i_{th}\) convolution block. Finally, features including information from five convolutional floors are connected with global futures form the based VGG-16 network, and then are used in the calculation of softmax loss and fully-connected CRF post-processing.
2.3 DMF in Occluded Person Re-id
DMF network can better combine high-level semantics information and low-level semantic information, and use VGG-16 network as basic network, which has ability to identify the different object categories. Therefore, DMF network can successfully achieve fine pedestrian salient detection and we use it to distinguish salient person body parts and backgrounds or noise information from occlusions. After DMF salient detection, occluded person images are cropped into partial person images according to predicted salient regions. The process is shown in Algorithm 1.

3 Experiment
3.1 Datasets
We evaluate the proposed method on five public benchmark datasets: MSRA-B [12], ECSSD [13], PASCAL-S [14], HKU-IS [15], DUT-OMRON [16]. Besides, we use our method on two occluded person re-id datasets Occluded REID dataset [17] and Partial REID dataset [7] to verify the effectiveness in occluded person re-id.
MSRA-B has been widely used for salient object detection, which contains 5000 images and corresponding pixel-wise ground truth.
ECSSD contains 1000 complex and natural images with complex structure acquired from the internet.
PASCAL-S contains 850 natural images with both pixel-wise saliency ground truth which are chosen from the validation set of the PASCAL VOC 2010 segmentation dataset.
HKU-IS is large-scale dataset containing 4447 images, which is split into 2500 training images, 500 validation images and the remaining test images.
DUT-OMRON includes 5168 challenging images, each of which has one or more salient objects.
Partial REID dataset is the first for partial person re-id [7], which includes 900 images of 60 people, with 5 full-body images, 5 partial images and 5 occluded images per person.
Occluded REID dataset consists of 2000 images of 200 persons. Each one has 5 full-body images and 5 occluded images with different types of severe occlusions. All of images with different viewpoints and backgrounds.
3.2 Experiment Setting
Methods for Comparison. To evaluate the superiority of our method, we compare our method with several recent state-of-the-art methods: Geodesic Saliency (GS) [18], Manifold Ranking (MR) [16], optimized WeightedContrast (wCtr*) [19], Background based Single-layer Cellular Automata (BSCA) [20], Local Estimation and Global Search (LEGS) [21], Multi-Context (MC) [22], Multiscale Deep Features (MDF) [15] and Deep Contrast Learning (DCL) [23]. Among these methods, LEGS, MC, MDF and DCL are the recent saliency detection methods based on deep learning.
Evaluation Metrics. Max F-measure (\(F_\beta \)) and mean absolute error (MAE) score are used to evaluate the performance. Max \(F_\beta \) is computed from the PR curve, which is defined as
MAE score means the average pixel-wise absolute difference between predicted mask P and its corresponding ground truth L, which is computed as
where P̂ and L̂ are the continuous saliency map and the ground truth that are normalized to [0, 1]. W and H is the width and height of the input image.
Parameter Setting. Our method is easily implemented in Pytorch, which is initialized with the pretrained weights of VGG-16 [9]. We randomly take 2500 images of MSRA-B dataset as training data and select 2000 images of the remaining images as testing data. The other datasets are all regarded as testing data. All the input images are resized to \(352 \times 352\) for training and test. The experiments are conducted with the initial learning rate of \(10^{-6}\), batch size = 40 and parameter of evaluation metrics \(\beta ^{2}\) is 0.3. Parameters of fully-connected CRF follow as [8].
Compared with State-of-the-Art. We compare our approach with several recent state-of-the-art methods in terms of max \(F_\beta \) and MAE score on five benchmark datasets, which is shown in Table 1. We collect eight methods including (A) non-deep learning ones and (B) deep learning ones. It can be seen that our method presents the best performance in the whole and largely outperforms non-deep learning methods because deep neural network has ability to learn and update the model automatically. Besides, our method surpasses the \(2^{nd}\) best method on ECSSD, PASCAL-S, HKU-IS and DUT-OMRON in almost max \(F_\beta \) and MAE score, which indicates our model can be directly applied in practical application due to good generalization.
Used on Occluded Person Re-identification. We do the visual comparison among our approach and the compared methods in Table 1 on two occluded person re-id datasets, Occluded REID dataset and Partial REID dataset, and process occluded person images into partial person images according to Algorithm 1, Sect. 2.3. Experimental result is shown in Fig. 4, which can be easily seen that our proposed method can not only highlight the most relevant regions, person body parts but also find the exact boundary to obtain better partial person images. Therefore, our proposed method is able to apply to pedestrian salient detection in occluded person re-id.
3.3 Experiment Results
3.4 Time Costing
We measure the speed of deep learning salient detection methods by computing the average time of obtaining a saliency map of one image. Table 2 shows the comparison between five deep leaning based methods: LEGS [21], MC [22], MDF [15], DCL [23] and our method, using a Titan GPU. Our method takes the least time to achieve salient detection and is 4 to 50 times faster than other methods, which illustrates the superiority of our method in terms of computing speed.

Visual comparison with eight existing methods and examples of cropping mask to obtain partial person images. As can be seen, our proposal produces more accuracy and coherent salient maps than all other methods.
4 Conclusion
In this paper, we make the first attempt to deal with occluded person images in occluded person re-id by pedestrian salient detection. To fine detect person body parts, the double-line multi-scale fusion (DMF) network is proposed to get more semantic information by double-line feature extraction and multi-scale fusion by fusing high-level and low-level information from high floor to low floor. We finally used a full-connected CRF as post-processing step after DMF network. Experimental results on benchmarks about salient detection and on occluded person re-id datasets both show the effectiveness and superiority of our method.
This project is supported by the Natural Science Foundation of China (61573387) and Guangdong Project (2017B030306018).
References
Wang, G.C., Lai, J.H., Xie, X.H.: P2SNeT: can an image match a video for person re-identification in an end-to-end way? IEEE TCSVT (2017)
Chen, Y.C., Zhu, X.T., Zheng, W.S., Lai, J.H.: Person re-identification by camera correlation aware feature augmentation. IEEE Trans. Pattern Anal. Mach. Intell. 40(2), 392–408 (2018)
Chen, S.Z., Guo, C.C., Lai, J.H.: Deep ranking for person re-identification via joint representation learning. IEEE Trans. Image Process. 25(5), 2353–2367 (2016)
Shi, S.C., Guo, C.C., Lai, J.H., Chen, S.Z., Hu, X.J.: Person re-identification with multi-level adaptive correspondence models. Neurocomputing 168, 550–559 (2015)
Guo, C.C., Chen, S.Z., Lai, J.H., Hu, X.J., Shi, S.C.: Multi-shot person re-identification with automatic ambiguity inference and removal. In: 22nd International Conference on Pattern Recognition, ICPR 2014, Stockholm, Sweden, 24–28 August 2014, pp. 3540–3545 (2014)
Zhuo, J.X., Chen, Z.Y., Lai, J.H., Wang, G.C.: Occluded person re-identification. arXiv preprint arXiv:1804.02792 (2018)
Zheng, W.S., Li, X., Xiang, T., Liao, S.C., Lai, J.H., Gong, S.G.: Partial person re-identification. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 4678–4686 (2015)
Krähenbühl, P., Koltun, V.: Efficient inference in fully connected CRFs with Gaussian edge potentials. In: Advances in Neural Information Processing Systems 24: 25th Annual Conference on Neural Information Processing Systems 2011. Proceedings of a Meeting Held 12–14 December 2011, Granada, Spain, pp. 109–117 (2011)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. CoRR, vol. abs/1409.1556 (2014)
Lin, T.Y., Dollár, P., Girshick, R., He, K.M., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017, pp. 936–944 (2017)
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015, Part III. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Liu, T., et al.: Learning to detect a salient object. IEEE Trans. Pattern Anal. Mach. Intell. 33(2), 353–367 (2011)
Yan, Q., Xu, L., Shi, J.P., Jia, J.Y.: Hierarchical saliency detection. In: 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013, pp. 1155–1162 (2013)
Li, Y., Hou, X.D., Koch, C., Rehg, J.M., Yuille, A.L.: The secrets of salient object segmentation. In: 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014, pp. 280–287 (2014)
Li, G.B., Yu, Y.Z.: Visual saliency based on multiscale deep features. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015, pp. 5455–5463 (2015)
Yang, C., Zhang, L.H., Lu, H.C., Ruan, X., Yang, M.H.: Saliency detection via graph-based manifold ranking. In: 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013, pp. 3166–3173 (2013)
Luo, Z.M., Mishra, A., Achkar, A., Eichel, J., Li, S.Z., Jodoin, P.M.: Non-local deep features for salient object detection. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21–26, 2017, pp. 6593–6601 (2017)
Wei, Y., Wen, F., Zhu, W., Sun, J.: Geodesic saliency using background priors. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) ECCV 2012, Part III. LNCS, vol. 7574, pp. 29–42. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-33712-3_3
Zhu, W.J., Liang, S., Wei, Y.C., Sun, J.: Saliency optimization from robust background detection. In: 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014, pp. 2814–2821 (2014)
Liu, H., Tao, S.N., Li, Z.Y.: Saliency detection via global-object-seed-guided cellular automata. In: 2016 IEEE International Conference on Image Processing, ICIP 2016, Phoenix, AZ, USA, 25–28 September 2016, pp. 2772–2776 (2016)
Wang, L.J., Lu, H.C., Ruan, X., Yang, M.H.: Deep networks for saliency detection via local estimation and global search. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015, pp. 3183–3192 (2015)
Zhao, R., Ouyang, W.L., Li, H.H., Wang, X.G.: Saliency detection by multi-context deep learning. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015, pp. 1265–1274 (2015)
Li, G.B., Yu, Y.Z.: Deep contrast learning for salient object detection. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016, pp. 478–487 (2016)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Zhuo, J., Lai, J. (2018). Double-Line Multi-scale Fusion Pedestrian Saliency Detection. In: Lai, JH., et al. Pattern Recognition and Computer Vision. PRCV 2018. Lecture Notes in Computer Science(), vol 11256. Springer, Cham. https://doi.org/10.1007/978-3-030-03398-9_13
Download citation
DOI: https://doi.org/10.1007/978-3-030-03398-9_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-03397-2
Online ISBN: 978-3-030-03398-9
eBook Packages: Computer ScienceComputer Science (R0)