
Abstract
Estimating depth from a single image is a very challenging and exciting topic in computer vision with implications in several application domains. Recently proposed deep learning approaches achieve outstanding results by tackling it as an image reconstruction task and exploiting geometry constraints (e.g., epipolar geometry) to obtain supervisory signals for training. Inspired by these works and compelling results achieved by Generative Adversarial Network (GAN) on image reconstruction and generation tasks, in this paper we propose to cast unsupervised monocular depth estimation within a GAN paradigm. The generator network learns to infer depth from the reference image to generate a warped target image. At training time, the discriminator network learns to distinguish between fake images generated by the generator and target frames acquired with a stereo rig. To the best of our knowledge, our proposal is the first successful attempt to tackle monocular depth estimation with a GAN paradigm and the extensive evaluation on CityScapes and KITTI datasets confirm that it enables to improve traditional approaches. Additionally, we highlight a major issue with data deployed by a standard evaluation protocol widely used in this field and fix this problem using a more reliable dataset recently made available by the KITTI evaluation benchmark.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


1 Introduction
Accurate depth estimation is of paramount importance for many computer vision tasks and for this purpose active sensors, such as LIDARs or Time of Flight sensors, are being extensively deployed in most practical applications. Nonetheless, passive depth sensors based on conventional cameras have notable advantages compared to active sensors. Thus, a significant amount of literature aims at tackling depth estimation with standard imaging sensors. Most approaches reply on multiple images acquired from different viewpoints to infer depth through binocular stereo, multi-view stereo, structure from motion and so on. Despite their effectiveness, all of them rely on the availability of multiple acquisitions of the sensed environment (e.g., binocular stereo requires two synchronized images) (Fig. 1).

Estimated depth maps from single image. On top, frame from KITTI 2015 dataset, on bottom (a) detail from reference image (red rectangle), (b) depth predicted by Godard et al. [13] and (c) by our GAN architecture. (Color figure online)
Monocular depth estimation represents an appealing alternative to overcome such constraint and recent works in this field achieved excellent results leveraging machine learning [6, 13, 21, 24]. Early works tackled this problem in a supervised manner [6, 21, 24] by training on a large amount of images with pixel-level depth labels. However, is well known that gathering labeled data is not trivial and particularly expensive when dealing with depth measurements [11, 12, 30, 38]. More recent methods [13, 54] aim to overcome this issue casting monocular depth estimation as an image reconstruction problem. In [54] inferring camera ego-motion in image sequences and in [13] leveraging a stereo setup. In both cases, difficult to source labeled depth data are not required at all for training. The second method yields much better results outperforming even supervised methods [6, 21, 24] by a large margin.
Recently, Generative Adversarial Networks (GANs) [14] proved to be very effective when dealing with high-level tasks such as image synthesis, style transfer and more. In this framework, two architectures are trained to solve competitive tasks. The first one, referred to as generator, produces a new image from a given input (e.g., a synthetic frame from noise, an image with a transferred style, etc.) while the second one called discriminator is trained to distinguish between real images and those generated by the first network. The two models play a min-max game, with the generator trained to produce outputs good enough to fool the discriminator and this latter network trained to not being fooled by the generator.
Considering the methodology adopted by state-of-the-art methods for unsupervised monocular depth estimation and the intrinsic ability of GANs to detect inconsistencies in images, in this paper we propose to infer depth from monocular images by means of a GAN architecture. Given a stereo pair, at training time, our generator learns to produce meaningful depth representations, with respect to left and right image, by exploiting the epipolar constraint to align the two images. The warped images and the real ones are then forwarded to the discriminator, trained to distinguish between the two cases. The rationale behind our idea is that a generator producing accurate depth maps will also lead to better reconstructed images, harder to be distinguished from original unwarped inputs. At the same time, for the discriminator will be harder to be fooled, pushing the generator to build more realistic warped images and thus more accurate depth predictions.
In this paper, we report extensive experimental results on the KITTI 2015 dataset, which provides a large amount of unlabeled stereo images and thus it is ideal for unsupervised training. Moreover, we highlight and fix inconsistencies in the commonly adapted split of Eigen [6], replacing Velodyne measurements with more accurate labels recently made available on KITTI [40]. Therefore, our contribution is threefold:
-
Our framework represents, to the best of our knowledge, the first method to tackle monocular depth estimation within a GAN paradigm
-
It outperforms traditional methods
-
We propose a more reliable evaluation protocol for the split of Eigen et al. [6].
2 Related Work
Depth estimation from images has a long history in computer vision. Most popular techniques rely on synchronized image pairs [39], multiple acquisitions from different viewpoints [9], at different time frames [35] or in presence of illumination changes [45]. Although certainly relevant to our work, these methods are not able to infer depth from a single image while recent methods casting depth prediction as a learning task and applications of GANs to other fields are strictly related to our proposal.
Learning-Based Stereo. Traditional binocular stereo algorithms perform a subset of steps as defined in [39]. The matching cost computation phase is common to all approaches, encoding an initial similarity score between pixels on reference image, typically the left, and matching candidates on the target. The seminal work by Zbontar and LeCun [50, 51] computes matching costs using a CNN trained on image patches and deploys such strategy inside a well-established stereo pipeline [15] achieving outstanding results. In a follow-up work, Luo et al. [25] obtained more accurate matching representation casting the correspondence search as a multi-class classification problem. A significant departure from this strategy is represented by DispNet [29], a deep architecture aimed at regressing per-pixel disparity assignments after an end-to-end training. These latter methods require a large amount of labeled images (i.e., stereo pairs with ground-truth disparity) for training [29]. Other works proposed novel CNN-based architectures inspired by traditional stereo pipeline as GC-Net [18] and CLR [31].
Supervised Monocular Depth Estimation. Single image depth estimation is an ill-posed problem due to the lack of geometric constraints and thus it represents a much more challenging task compared to depth from stereo. Saxena et al. [37] proposed Make3D, a patch-based model estimating 3D location and orientation of local planes by means of a MRF framework. This technique suffers in presence of thin structures and lack of global context information often useful to obtain consistent depth estimations. Liu et al. [24] trained a CNN to tackle monocular depth estimation, while Ladicky et al. [21] exploited semantic information to obtain more accurate depth predictions. In [17] Karsch et al. achieved more consistent predictions at testing time by copying entire depth images from a training set. Eigen et al. [6] proposed a multi-scale CNN trained in supervised manner to infer depth from a single image. Differently from [24], whose network was trained to compute more robust data terms and pairwise terms, this approach directly infers the final depth map from the input image. Following [6] other works enabled more accurate estimations by means of CRF regularization [23], casting the problem as a classification task [2], designing more robust loss functions [22] or using scene priors for plane normals estimation [43]. Luo et al. [26] formulated monocular depth estimation as a stereo matching problem in which the right view is generated by a view-synthesis network based on Deep 3D [46]. Fu et al. [8] proposed a very effective depth discretization strategy and a novel ordinal regression loss achieving state-of-the-art results on different challenging benchmarks. Kumar et al. [4] demonstrated that recurrent neural networks (RNNs) can learn spatio-temporally accurate monocular depth prediction from video sequences. Atapour et al. [1] take advantage of style transfer and adversarial training on synthetic data to predict depth maps from real-world color images. Lastly, Ummenhofer et al. [41] proposed DeMoN, a deep model to infer both depth and ego-motion from a pair of subsequent frames acquired by a single camera. As for deep stereo models all these techniques require a large amount of labeled data at training time to learn meaningful depth representation from a single image.

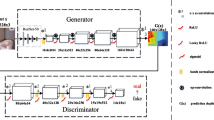
Proposed adversarial model. Given a single input frame, depth maps are produced by a Generator (blue) and used to warp images. Discriminator (gray) process both raw and warped images, trying to classify the former as real and the latter as fake. The generator is pushed to improve depth prediction to provide a more realistic warping to fool the discriminator. At the same time the discriminator learns to improve its ability to perform this task. (Color figure online)
Unsupervised Monocular Depth Estimation. Pertinent to our proposal are some recent works concerned with view synthesis. Flynn et al. [7] proposed DeepStereo, a deep architecture trained on images acquired by multiple cameras in unsupervised manner to generate novel view points. Deep3D by Xie et al. [46] generates corresponding target view from an input reference image in the context of binocular stereo, by learning a distribution over all possible disparities for each pixel on the source frame and training their model with a reconstruction loss. Similarly, Garg et al. [10] trained a network for monocular depth estimation using a reconstruction loss over a stereo pair. To make their model fully differentiable they used Taylor approximation to make their loss linear, resulting in a more challenging objective to optimize. Godard et al. [13] overcome this problem by using a bilinear sampling [16] to generate images from depth prediction. At training time, this model learns to predict depth for both images in a stereo pair thus enabling to enforce a left-right consistency constraint as supervisory signal. A simple post-processing step allows to refine depth prediction. This approach was extended by including additional temporal information [52] and by training with semi-supervised data [20, 48]. While previous method requires rectified stereo pairs for training, Zhou et al. [54] proposed to train a model to infer depth from unconstrained video sequences by computing a reconstruction loss between subsequent frames and predicting, at the same time, the relative pose between them. This strategy removes the requirement of stereo pairs for training but produces a less accurate depth estimation. Wang et al. [42] proposed a simple normalization strategy that circumvent problems in the scale sensitivity of the depth regularization terms employed during training and empirically demonstrated that the incorporation of a differentiable implementation of Direct Visual Odometry (DVO) improves previous monocular depth performance [54]. Mahjourian et al. [27] used a novel approximate ICP based loss to jointly learn depth and camera motion for rigid scenes, while Yin et al. [47] proposed a learning framework for jointly training monocular depth, optical flow and camera motion from video. [52]. Concurrently with our work, Poggi et al. [32] deployed a thin model for depth estimation on CPU and proposed a trinocular paradigm [33] to improve unsupervised approaches based on stereo supervision, while Ramirez et al. [49] proposed a semi-superised framework for joint depth and semantic estimation.
Generative Adversarial Networks. GANs [14] recently gained popularity by enabling to cast computer vision problems as a competitive task between two networks. Such methodology achieved impressive performance for image generalization [5, 34], editing [55] and representation learning [28, 34] tasks. More recent applications include text-to-image [36, 53] and image-to-image [56] translations.
3 Method Overview
In this section we describe our adversarial framework for unsupervised monocular depth estimation. State-of-the-art approaches rely on single network to accomplish this task. In contrast, at the core of our strategy there is a novel loss function based on a two players min-max game between two adversarial networks, as shown in Fig. 2. This is done by using both a generative and a discriminative model competing on two different tasks, each one aimed at prevailing the other. This section discusses the geometry of the problem and how it is used to take advantages of 2D photometric constraints with a generative adversarial approach in a totally unsupervised manner. We refer to our framework as MonoGAN.
3.1 Generator Model for Monocular Depth Estimation
The main goal of our framework is to estimate an accurate depth map from a single image without relying on hard to find ground-truth depth labels for training. For this purpose, we can model this problem as a domain transfer task: given an input image x, we want to obtain a new representation \(y = G(x)\) in the depth domain. In other contexts, GAN models have been successfully deployed for image-to-image translation [56]. For our purpose a generator network, depicted in blue in Fig. 2, is trained to learn a transfer function \(G: \mathcal {I} \rightarrow \mathcal {D}\) mapping an input image from \(\mathcal {I}\) to \(\mathcal {D}\), respectively, the RGB and the depth domain. To do so, it is common practice to train the generator with loss signals enforcing structure consistency across the two domains to preserve object shapes, spatial consistency, etc. Similarly, this can be done for our specific goal by exploiting view synthesis. That is, projecting RGB images into 3D domain according to estimated depth and then back-projecting to new synthesized view for which we need a real image to compare with. To make it possible, for each training sample at least two images from different points of view are required to enable the image reconstruction process described so far. In literature, this strategy is used by other unsupervised techniques for monocular depth estimation, exploiting both unconstrained sequences [54] or stereo imagery [13]. In this latter case, given two images \(i^l\) and \(i^r\) acquired by a stereo setup, the generator estimates inverse depth (i.e., disparity) \({d}^l\) used to obtain a synthesized image \(\tilde{i}^l\) by warping \({i}^r\) with bilinear sampler function [16] being it fully differentiable and thus enabling end-to-end training. If \({d}^l\) is accurate, shapes and structures are preserved after warping, while an inaccurate estimation would lead to distortion artifacts as shown on the right of Fig. 3. This process is totally unsupervised with respect to the \(\mathcal {D}\) domain and thus it does not require at all ground-truth labels at training time. Moreover, by estimating a second output \({d}^r\), representing the inverse mapping from \({i}^l\) to \({i}^r\), allows to use additional supervisory signals by enforcing consistency in the \(\mathcal {D}\) domain (i.e., Left-Right consistency constraint).
3.2 Discriminator Model
To successfully accomplish domain transfer, GANs rely on a second network trained to distinguish images produced by the generator from those belonging to the target domain, respectively fake and real samples. We follow the same principle using the gray model in Fig. 2, but acting differently from other approaches. In particular, to discriminate synthesized images from real ones we need a large amount of samples in the target domain. While for traditional domain transfer applications this does not represent an issue (requiring images without annotation), this becomes a limitation when depth is the target domain being ground-truth label difficult to source in this circumstance. To overcome this limitation, we train a discriminator to work on the RGB domain to tell original input images from synthesized ones. Indeed, if estimated disparity by the generator is not accurate, the warping process would reproduce distortion artifacts easily detectable by the discriminator. On the other hand, an accurate depth prediction would lead to a reprojected image harder to be recognized from a real one. Figure 3 shows, on the left, an example of real image and, on the right, a warped one synthesized according to an inaccurate depth estimation. For instance, by looking at the tree, we can easily tell the real image from the warped one. By training the discriminator on this task, the generator is constantly forced to produce more accurate depth maps thus leading to a more realistic reconstructed image in order to fool it. At the same time the discriminator is constantly pushed to improve its ability to tell real images from synthesized ones. Our proposal aims at such virtuous behavior by properly modeling the adversarial contribution of the two networks as described in detail in the next section.

Example of real (top) and warped (bottom) image according to an estimated depth. We can clearly notice how inaccurate predictions lead to warping artifacts on the reprojected frame (e.g., distorted trees) not perceivable elsewhere.
4 Adversarial Formulation
To train the framework outlined so far in end-to-end manner we define an objective function \(\mathcal {L}(G,D)\) sum of two terms, a \(\mathcal {L}_{GAN}\) expressing the min-max game between generator G and discriminator D:
with \(i_0\) and \(i_1\) belonging, respectively, to real images \(\mathcal {I}\) and fake images \(\mathcal {\tilde{I}}\) domains being the latter obtained by bilinear warping according to depth estimated by G and a data term \(\mathcal {L}_{data}\) resulting in:
According to this formulation, generator G and discriminator D are trained to minimize loss functions \(\mathcal {L}_G\) and \(\mathcal {L}_D\):
To give an intuition, G is trained to minimize the loss from data term and the probability that D will classify a warped image \(i_1 \sim \mathcal {\tilde{I}}\) as fake. This second contribution is weighted according to \(\alpha _{adv}\) factor, hyper-parameter of our framework. Consistently, D is trained to classify a raw image \(i_0 \sim \mathcal {I}\) as real and a warped one as fake. Despite our framework processes a transfer from \(\mathcal {I}\) to depth domain \(\mathcal {D}\), we highlight how in the proposed adversarial formulation the discriminator does not process any sample from domain \(\mathcal {D}\), neither fake nor real. Thus it does not require any ground-truth depth map and perfectly fits with an unsupervised monocular depth estimation paradigm.
4.1 Data Term Loss
We define the data term \(\mathcal {L}_{data}\) part of the generator loss function \(\mathcal {L}_G\) as follows:
where the loss consists in the weighted sum of three terms. The first one, namely appearence term, measures the reconstruction error between warped image \(\tilde{I}\) and real one I by means of SSIM [44] and L1 difference of the two
The second term is a smoothness constraint that penalizes large disparity differences between neighboring pixels along the x and y directions unless a strong intensity gradients in the reference image I occurs
Finally, by building the generator to output a second disparity map \(d^r\), we can add the term proposed in [13] as third supervision signal, enforcing left-right consistency between the predicted disparity maps, \(d^l\) and \(d^r\), for left and right images:
Moreover, estimating \(d^r\) also enables to compute the three terms for both images in a training stereo pair.

Analysis of hyper-parameters \(\alpha _{adv}\) and k of our GAN model, on x axis \(\alpha _{adv}\), on y axis an evaluation metric. (a) Abs Rel, (b) Sq Rel and (c) RMSE metrics (lower is better). (d) \(\delta < 1.25\), (e) \(\delta < 1.25^2\), (f) \(\delta < 1.25^3\) metrics (higher is better). Interpolation is used for visualization purpose only. We can notice how our proposal using a weight \(\alpha _{adv}\) of 0.0001 and a step k of 5 achieves the best performance with all metrics.
5 Experimental Results
In this section we assess the performance of our proposal with respect to literature. Firstly, we describe implementation details of our model outlining the architecture of generator and discriminator networks. Then, we describe the training protocols followed during our experiments reporting an exhaustive comparison on KITTI 2015 stereo dataset [30] with state-of-the-art method [13]. This evaluation clearly highlights how the adversarial formulation proposed is beneficial when tackling this unsupervised monocular depth estimation. Moreover, we compare our proposal with other frameworks known in literature, both supervised and unsupervised, on the split of data used by Eigen et al. [6]. In this latter case we provide experimental results on the standard Eigen split as well as on a similar one made of more reliable data. This evaluation highlights once again the effectiveness of our proposal.
5.1 Implementation Details
For our GAN model, we deploy a VGG-based generator as in [13] counting 31 million parameters. We designed the discriminator in a similar way but, since the task of the discriminator is easier compared to the one tackled by the generator, we reduced the amount of feature maps extracted by each layer by a factor of two to obtain a less complex architecture. In fact, it counts about 8 million parameters, bringing the total number of variables of the overall framework to 39 million at training time. At test time, the discriminator is no longer required, restoring the same network configuration of [13] and thus the same computational efficiency.
For a fair comparison, we tune hyper-parameters such as learning rate or weights applied to loss terms to match those in [13], trained with a multi-scale data term while the adversarial contribution is computed at full resolution only. Being the task of D easier compared to depth estimation performed by G, we interleave the updates applied to the two. To this aim we introduce a further hyper-parameter k as the ratio between the number of training iterations performed on G and those on D, in addition to \(\alpha _{adv}\). In other words, discriminator weights are updated only every k updates of the generator. We will report evaluations for different values of parameter k. To jointly train both generator and discriminator we use two instances of Adam optimizer [19], with \(\beta _{1} = 0.9\), \(\beta _{2} = 0.99\) and \(\epsilon =10^{-8}\). The learning rate is the same for both instances: it is set at \(\lambda =10^{-4}\) for the first 30 epochs and then halved each 10 epochs. Number of epochs is set to 50 as for [13]. Training data are extracted from both KITTI raw sequences [30] and CityScapes dataset [3] providing respectively about 29000 and 23000 stereo pairs, these latter samples are cropped to remove lower part of the image frames (depicting a portion of the car used for acquisition) as in [13]. Moreover, as in [13] we perform data augmentation by randomly flipping input images horizontally and applying the following transformations: random gamma correction in [0.8, 1.2], additive brightness in [0.5, 2.0], and color shifts in [0.8, 1.2] for each channel separately. The same procedure is applied before forwarding images to both generator and discriminator.
5.2 Hyper-parameters Analysis
As mentioned before, our GAN model introduces two additional hyper-parameters: the weight \(\alpha _{adv}\) applied to the adversarial loss acting on the generator and the iteration interval k between subsequent updating applied to the discriminator. Figure 4 reports an analysis aimed at finding the best configuration \((\alpha _{adv},k)\). On each plot, we report an evaluation metric used to measure accuracy in the field of monocular depth estimation (e.g., in [13]) as a function of both \(\alpha _{adv}\) and k. Respectively, on top we report from left to right Abs Rel, Sq Rel and RMSE (lower scores are better), on bottom \(\delta < 125\), \(\delta < 125^2\) and \(\delta < 125^3\) (higher scores are better). These results were obtained training MonoGAN on the 29000 KITTI stereo images [30], with \(\alpha _{adv}\) set to 0.01, 0.001 and 0.0001 and k to 1, 5 and 10, for a total of 9 models trained and evaluated in Fig. 4. We can notice how the configuration \(\alpha _{adv}\) = 0.0001 and k = 5 achieves the best performance with all evaluated metrics. According to this analysis we use these hyper-parameters in the next experiments, unless otherwise stated. It is worth to note that despite the much smaller magnitude of \(\alpha _{adv}\) compared to weights \(\alpha _{ap}\), \(\alpha _{ds}\) and \(\alpha _{lr}\) in data term (5), its contribution will affect significantly depth estimation accuracy as reported in the remainder.

Qualitative comparison between (a) reprojected raw Velodyne points as done in the original Eigen split for results reported in Table 2 and (b) reprojected ground-truth labels filtered according to [40], available on the KITTI website, deployed for our additional experiments reported in Table 3. Warmer colors encode closer points.
5.3 Evaluation on KITTI Dataset
Table 1 reports experimental results on the KITTI 2015 stereo dataset. For this evaluation, 200 images with provided ground-truth disparity from KITTI 2015 stereo dataset are used for validation, as proposed in [13]. We report results for different training schedules: running 50 epochs on data from KITTI only (K), from CityScapes only (CS) and 50 epochs on CityScapes followed by 50 on KITTI (CS + K). We compare our proposal to state-of-the-art method for unsupervised monocular depth estimation proposed by Godard et al. [13] reporting for this method the outcome of the evaluation available in the original paper. Table 1 is divided into four main sections, representing four different experiments. In particular, (i) compares MonoGAN with [13] when both trained on K. We can observe how our framework significantly outperforms the competitor on all metrics. Experiment (ii) concerns the two models trained on CityScapes data [3] and evaluated on KITTI stereo images, thus measuring the generalization capability across different environments. In particular, CityScapes and KITTI images differ not only in terms of scene contents but also for the camera setup. We can notice that MonoGAN better generalizes when dealing with different data. In (iii), we train both models on CityScapes first and then on KITTI, showing that MonoGAN better benefits from using different datasets at training time compared to [13] thus confirming the positive trend outlined in the previous experiments. Finally, in (iv) we test the network trained in (iii) refining the results with the same post-processing step described in [13]. It consists in predicting depth for both original and horizontally flipped input image, then taking 5% right-most pixels from the first and 5% left-most from the second, while averaging the two predictions for remaining pixels. With such post-processing, excluding one case out of 6 (i.e., with the RMSE metric) MonoGAN has better or equivalent performance compared to [13]. Overall, the evaluation on KITTI 2015 dataset highlights the effectiveness of the proposed GAN paradigm. In experiments (iii) and (iv), we exploited adversarial loss only during the second part of the training (i.e., on K) thus starting from the same model of [13] trained as in experiment (ii), with the aim to assess how the discriminator improves the performance of a pre-trained model. Moreover, when fine-tuning we find beneficial to change the \(\alpha _{adv}\) weight, similarly to traditional learning rate decimation techniques. In particular, we increased the adversarial weight \(\alpha _{adv}\) from 0.0001 to 0.001 after 150k iterations (out of 181k total).
5.4 Evaluation on Eigen Split
We report additional experiments conducted on the split of data proposed by Eigen et al. in [6]. This validation set is made of 697 depth maps obtained by projecting 3D points inferred by a Velodyne laser into the left image of the acquired stereo pairs in 29 out of 61 scenes. The remaining 32 scenes are used to extract 22600 training samples. We compare to other monocular depth estimation framework following the same protocol proposed in [13] using the same crop dimensions and parameters.
Table 2 reports a detailed comparison of unsupervised methods. On top, we evaluated depth maps up to a maximum distance of 80 m. We can observe how MonoGAN performs on par or better than Godard et al. [13] outperforming it in terms of Sq Rel and RMSE errors and \(\delta < 1.25\), \(\delta < 1.25^{2}\) metrics. On the bottom of the table, we evaluate up to 50 m maximum distance to compare with Garg et al. [10]. This evaluation substantially confirms the previous trend. As for experiments on KITTI 2015 stereo dataset, we find out that increasing by a factor 10 the adversarial weight \(\alpha _{adv}\) from 0.0001 to 0.001 after 150k iterations out of 181k total increases the accuracy of MonoGAN. Apparently, the margin between MonoGAN and [13] is much lower on this evaluation data. However, as already pointed out in [13] and [40], depth data obtained through Velodyne projection are affected by errors introduced by the rotation of the sensor, the motion of the vehicle and surrounding objects and also incorrect depth readings due to occlusion at object boundaries. Therefore, to better assess the performance of our proposal with respect to state-of-the-art we also considered the same split of images with more accurate ground-truth labels made available by Uhrig et al. [40] and now officially distributed as depth ground-truth maps by KITTI benchmark. These maps are obtained by filtering Velodyne data with disparity obtained by the Semi Global Matching algorithm [15] so as to remove outliers from the original measurements. Figure 5 shows a qualitative comparison between depth labels from raw Velodyne data reprojected into the left image, deployed in the original Eigen split, and labels provided by [40], deployed for our additional evaluation. Comparing (a) and (b) to the reference image at the top we can easily notice in (a) several outliers close to the tree trunk border not detectable in (b). Unfortunately, accurate ground-truth maps provided by [40] are not available for 45 images of the original Eigen split. Therefore, the number of testing images is reduced from 697 to 652. However, at the expense of a very small reduction of validation samples (i.e., 6.5%) we get much more reliable ground-truth data according to [40]. With such accurate data, Table 3 reports a comparison between [13] and MonoGAN with and without post-processing, thresholding at 80 and 50 m as for previous experiment on standard Eigen split. From Table 3 we can notice how with all metrics, excluding one case, MonoGAN on this more reliable dataset outperforms [13] confirming the trend already reported in Table 1 on the accurate KITTI 2015 benchmark.
6 Conclusions
In this paper, we proposed to tackle monocular depth estimation as an image generation task by means of a Generative Adversarial Networks paradigm. Exploiting at training time stereo images, the generator learns to infer depth from the reference image and from this data to generate a warped target image. The discriminator is trained to distinguish between real images and fake ones generated by the generator. Extensive experimental results confirm that our proposal outperforms known techniques for unsupervised monocular depth estimation.
References
Atapour-Abarghouei, A., Breckon, T.P.: Real-time monocular depth estimation using synthetic data with domain adaptation via image style transfer. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Cao, Y., Wu, Z., Shen, C.: Estimating depth from monocular images as classification using deep fully convolutional residual networks. IEEE Trans. Circuits Syst. Video Technol. (2017)
Cordts, M., et al.: The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3213–3223 (2016)
Kumar, A.C.S., Bhandarkar, S.M., Mukta, P.: DepthNet: a recurrent neural network architecture for monocular depth prediction. In: 1st International Workshop on Deep Learning for Visual SLAM (CVPR) (2018)
Denton, E.L., Chintala, S., Fergus, R., et al.: Deep generative image models using a Laplacian pyramid of adversarial networks. In: Advances in Neural Information Processing Systems, pp. 1486–1494 (2015)
Eigen, D., Puhrsch, C., Fergus, R.: Depth map prediction from a single image using a multi-scale deep network. In: Advances in Neural Information Processing Systems, pp. 2366–2374 (2014)
Flynn, J., Neulander, I., Philbin, J., Snavely, N.: DeepStereo: learning to predict new views from the world’s imagery. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5515–5524 (2016)
Fu, H., Gong, M., Wang, C., Batmanghelich, K., Tao, D.: Deep ordinal regression network for monocular depth estimation. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Furukawa, Y., Hernández, C., et al.: Multi-view stereo: a tutorial. Found. Trends® Comput. Graph. Vis. 9(1–2), 1–148 (2015)
Garg, R., Carneiro, G., Reid, I., Vijay Kumar, B.G., et al.: Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9912, pp. 740–756. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46484-8_45
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: the KITTI dataset. Int. J. Robot. Res. (IJRR) 32, 1231–1237 (2013)
Geiger, A., Lenz, P., Urtasun, R.: Are we ready for autonomous driving? The KITTI vision benchmark suite. In: 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3354–3361. IEEE (2012)
Godard, C., Mac Aodha, O., Brostow, G.J.: Unsupervised monocular depth estimation with left-right consistency. In: CVPR, vol. 2, p. 7 (2017)
Goodfellow, I., et al.: Generative adversarial nets. In: Advances in Neural Information Processing Systems, pp. 2672–2680 (2014)
Hirschmuller, H.: Accurate and efficient stereo processing by semi-global matching and mutual information. In: 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2005, vol. 2, pp. 807–814. IEEE (2005)
Jaderberg, M., Simonyan, K., Zisserman, A., et al.: Spatial transformer networks. In: Advances in Neural Information Processing Systems, pp. 2017–2025 (2015)
Karsch, K., Liu, C., Kang, S.: Depth transfer: depth extraction from video using non-parametric sampling. IEEE Trans. Pattern Anal. Mach. Intell. 36(11), 2144–2158 (2014)
Kendall, A., et al.: End-to-end learning of geometry and context for deep stereo regression. In: The IEEE International Conference on Computer Vision (ICCV), October 2017
Kingma, D., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Kuznietsov, Y., Stuckler, J., Leibe, B.: Semi-supervised deep learning for monocular depth map prediction. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017
Ladicky, L., Shi, J., Pollefeys, M.: Pulling things out of perspective. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 89–96 (2014)
Laina, I., Rupprecht, C., Belagiannis, V., Tombari, F., Navab, N.: Deeper depth prediction with fully convolutional residual networks. In: 2016 Fourth International Conference on 3D Vision (3DV), pp. 239–248. IEEE (2016)
Li, B., Shen, C., Dai, Y., van den Hengel, A., He, M.: Depth and surface normal estimation from monocular images using regression on deep features and hierarchical CRFs. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1119–1127 (2015)
Liu, F., Shen, C., Lin, G., Reid, I.: Learning depth from single monocular images using deep convolutional neural fields. IEEE Trans. Pattern Anal. Mach. Intell. 38(10), 2024–2039 (2016)
Luo, W., Schwing, A.G., Urtasun, R.: Efficient deep learning for stereo matching. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5695–5703 (2016)
Luo, Y., et al.: Single view stereo matching. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Mahjourian, R., Wicke, M., Angelova, A.: Unsupervised learning of depth and ego-motion from monocular video using 3D geometric constraints. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Mathieu, M.F., Zhao, J.J., Zhao, J., Ramesh, A., Sprechmann, P., LeCun, Y.: Disentangling factors of variation in deep representation using adversarial training. In: Advances in Neural Information Processing Systems, pp. 5040–5048 (2016)
Mayer, N., et al.: A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4040–4048 (2016)
Menze, M., Geiger, A.: Object scene flow for autonomous vehicles. In: Conference on Computer Vision and Pattern Recognition (CVPR) (2015)
Pang, J., Sun, W., Ren, J.S., Yang, C., Yan, Q.: Cascade residual learning: a two-stage convolutional neural network for stereo matching. In: The IEEE International Conference on Computer Vision (ICCV), October 2017
Poggi, M., Aleotti, F., Tosi, F., Mattoccia, S.: Towards real-time unsupervised monocular depth estimation on CPU. In: IEEE/JRS Conference on Intelligent Robots and Systems (IROS) (2018)
Poggi, M., Tosi, F., Mattoccia, S.: Learning monocular depth estimation with unsupervised trinocular assumptions. In: 6th International Conference on 3D Vision (3DV) (2018)
Radford, A., Metz, L., Chintala, S.: Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434 (2015)
Ranftl, R., Vineet, V., Chen, Q., Koltun, V.: Dense monocular depth estimation in complex dynamic scenes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4058–4066 (2016)
Reed, S., Akata, Z., Yan, X., Logeswaran, L., Schiele, B., Lee, H.: Generative adversarial text to image synthesis. arXiv preprint arXiv:1605.05396 (2016)
Saxena, A., Sun, M., Ng, A.Y.: Make3d: learning 3d scene structure from a single still image. IEEE Trans. Pattern Anal. Mach. Intell. 31(5), 824–840 (2009)
Scharstein, D., et al.: High-resolution stereo datasets with subpixel-accurate ground truth. In: Jiang, X., Hornegger, J., Koch, R. (eds.) GCPR 2014. LNCS, vol. 8753, pp. 31–42. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-11752-2_3
Scharstein, D., Szeliski, R.: A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Comput. Vision 47(1–3), 7–42 (2002)
Uhrig, J., Schneider, N., Schneider, L., Franke, U., Brox, T., Geiger, A.: Sparsity invariant CNNs. In: International Conference on 3D Vision (3DV) (2017)
Ummenhofer, B., et al.: Demon: depth and motion network for learning monocular stereo. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol. 5 (2017)
Wang, C., Buenaposada, J.M., Zhu, R., Lucey, S.: Learning depth from monocular videos using direct methods. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Wang, X., Fouhey, D., Gupta, A.: Designing deep networks for surface normal estimation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 539–547 (2015)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13(4), 600–612 (2004)
Woodham, R.J.: Photometric method for determining surface orientation from multiple images. Opt. Eng. 19(1), 191139 (1980)
Xie, J., Girshick, R., Farhadi, A.: Deep3D: fully automatic 2D-to-3D video conversion with deep convolutional neural networks. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9908, pp. 842–857. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46493-0_51
Yin, Z., Shi, J.: GeoNet: unsupervised learning of dense depth, optical flow and camera pose. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Yang, N., Wang, R., Stückler, J., Cremers, D.: Deep virtual stereo odometry: leveraging deep depth prediction for monocular direct sparse odometry. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11212, pp. 835–852. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01237-3_50
Ramirez, P.Z., Poggi, M., Tosi, F., Mattoccia, S., Stefano, L.D.: Geometry meets semantic for semi-supervised monocular depth estimation. In: 14th Asian Conference on Computer Vision (ACCV) (2018)
Zbontar, J., LeCun, Y.: Computing the stereo matching cost with a convolutional neural network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1592–1599 (2015)
Zbontar, J., LeCun, Y.: Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 17(1–32), 2 (2016)
Zhan, H., Garg, R., Weerasekera, C.S., Li, K., Agarwal, H., Reid, I.: Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Zhang, H., et al.: StackGAN: text to photo-realistic image synthesis with stacked generative adversarial networks. In: IEEE International Conference Computer Vision (ICCV), pp. 5907–5915 (2017)
Zhou, T., Brown, M., Snavely, N., Lowe, D.G.: Unsupervised learning of depth and ego-motion from video. In: CVPR, vol. 2, p. 7 (2017)
Zhu, J.-Y., Krähenbühl, P., Shechtman, E., Efros, A.A.: Generative visual manipulation on the natural image manifold. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9909, pp. 597–613. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46454-1_36
Zhu, J.-Y., Park, T., Isola, P., Efros, A.A.:. Unpaired image-to-image translation using cycle-consistent adversarial networks. arXiv preprint arXiv:1703.10593 (2017)
Acknowledgement
We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan X Pascal GPU used for this research.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Aleotti, F., Tosi, F., Poggi, M., Mattoccia, S. (2019). Generative Adversarial Networks for Unsupervised Monocular Depth Prediction. In: Leal-Taixé, L., Roth, S. (eds) Computer Vision – ECCV 2018 Workshops. ECCV 2018. Lecture Notes in Computer Science(), vol 11129. Springer, Cham. https://doi.org/10.1007/978-3-030-11009-3_20
Download citation
DOI: https://doi.org/10.1007/978-3-030-11009-3_20
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-11008-6
Online ISBN: 978-3-030-11009-3
eBook Packages: Computer ScienceComputer Science (R0)