
Abstract
Face detection is one of the first stages of face recognition systems. Thanks to advances in deep neural networks, success has been achieved on many similar image recognition tasks. When videos are available, temporal information can be used for determining the position of the face, avoiding having to detect faces for all frames. Such techniques can be applied in in-the-wild environments where current face detection methods fail to perform robustly. To address these limitations, this work explores an original approach, tracking the nose region initialized based on face quality analysis. A quality score is calculated for assisting the nose tracking initialization, avoiding depending on the first frame, in which may contain degraded data. The nose region, rather than the entire face was chosen due to it being unlikely to be occluded, being mostly invariant to facial expressions, and being visible in a long range of head poses. Experiments performed on the 300 Videos in the Wild and Point and Shoot Challenge datasets indicate nose tracking is a useful approach for in-the-wild scenarios.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


1 Introduction
According to Jain et al. [4], facial recognition is one of the fundamental problems in computer vision. For this reason, robust and efficient face detection needs to be performed for almost all face processing tasks. When working with videos, face tracker can make use of the temporal information, avoiding constant detection. The most common approaches to this are landmark-based [15, 16] unfortunately, they tend to not be robust for in-the-wild scenarios, including profile head poses where half of the landmarks are occluded by the face [11]. At the same time, generic object trackers have been successfully applied to predicting the location of a large range of objects, including faces [7, 8], treating its targets as a rectangular bounding box.
Existing generic tracking methods can be based on the principal component analysis (PCA) [10], sparse representations [5], Haar-like features [18], correlation filters [13], and convolutional neural networks [3]. However, they tend to have poor performance in uncontrolled environments, where deformations, partial occlusions and changes in illumination are common. To this end, Nam and Han [7] proposed MDNet (Multi-Domain Network), designed to learn shared features and classifiers specific to different tracking sequences, achieving state-of-the-art results on the Visual Object Tracking Challenge [6] and the Object Tracking Benchmark [14]. All these approaches rely on accurate bounding box initialization in the first frame.
This paper proposes combining Nam and Han’s generic tracker [7] with a robust initialization step based on a customized face quality score, using the nose region for performing face tracking in unconstrained environments. While the nose composes a smaller region, it has been shown efficient for biometrics [2, 17], it is visible even on profile faces, not easily deformed by facial expression and, due to its nature, also unlikely to be occluded by accessories.
The initialization step selects the best starting frame by maximizing a face quality score. This method allows the tracker to overcome a common limitation in which the reference region may be of poor quality or include large variations in illumination or occlusion, negatively affecting its performance. This work expands on a preliminary study [12] that has evaluated the possibility of this approach. While the initial results were positive, indicating the potential of the selection step, tracking was initialized using ground-truth annotations. This paper explores a completely automated approach, simulating real life scenarios when no ground-truth data is available.
Experiments are performed on the 300VW dataset [11], which includes numerous videos categorized into difficulty levels. Additionally, 100 videos from the PaSC dataset [1] were annotated and used for testing and comparing against face tracking.
2 Nose Tracking in the Wild
This work proposes tracking faces in in-the-wild scenarios solely using the nose region as target. To this end, face quality assessment is adopted for estimating the best frame as reference to initialize tracking. Due to the first frame not necessarily being used for initializing, the nose region needs to be tracked twice: forwards and backwards in time. When the tracker finishes, the frame sequence is reordered.
The adopted face quality assessment method [12] has five main steps:
(1) the face region is first detected using Faster-RCNN [9]; (2) face quality is then estimated based on Abaza et al.’s method: the geometric mean of the contrast, brightness, focus, sharpness, and illumination; (3) nose detection is performed using Faster-RCNN [9]; (4) the yaw head pose angle is estimated using a support vector machine classifier [17], predicting the pose into five classes (−90, −45, 0, 45, 90\(^\circ \)); and (5) facial quality score is then combined with head pose estimation preferring near frontal faces and best face quality for tracking initialization. Frames with no detected face or nose are skipped when assessing the quality and estimating the pose.
After face quality estimation, MDNet [7] is used for tracking and locating the nose region on other frames. It uses a convolutional neural network with five hidden layers and two fully connected layers, sharing all common features during the training phase. MDNet also has multiple specific-domain layers, one for each video used for training, enabling binary classification between foreground and background to be performed.
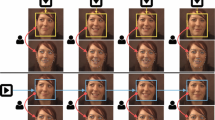
At the test stage, MDNet [7] fine-tunes the pre-trained weights and replaces the specific-domain layers into a single one by using 500 positives and 5,000 negatives samples around the first frame ground truth. Hard negative mining strategy and bounding box regression are also adopted making the predictions more robust to different views, scale, drift and illumination changes. Note that MDNet [7] by itself does not perform the initial detection, it depends on manual initialization. The nose tracking pipeline is shown in Fig. 1, outlining the face quality analysis and visual tracking integration.

Image quality and nose tracker diagram. Red and green lines are the detected and tracker predicted regions, respectively. (Color figure online)
2.1 Experimental Results
Experiments were performed on the 300 Videos in the Wild (300VW) [11] and Point and Shoot Challenge (PaSC) [1] datasets, comparing the nose tracking approach with face tracking. For the latter, the pre-trained MDNet method of Nam and Han [7] was used. In this case, traditional first frame ground-truth initialization was used. This difference allows for comparing the nose tracking strategy with using the entire face region.
Visual tracking performance is evaluated frame by frame using two metrics, the intersection coefficient, also called success rate [6, 14], and precision [6], which measures the distance between the final estimation and the respective ground-truth.
300VW Dataset. The 300VW dataset [11] has 50 training videos and 64 test videos with approximately one minute of duration each, containing 68 annotated landmarks at each frame. This allows for extracting the nose and face regions to be used for evaluating tracking performance. The test videos are subdivided into three degrees of difficulty, containing 31, 19 and 14 videos.
For nose tracking, the nose region of 300VW’s training subset was used in the training stage. Two evaluations were performed when tracking the nose: initializing with the automatic detection and initializing with the manually annotated nose (ground truth), both cases starting the process using the best quality frame. The latter was adopted for allowing a fair comparison against face tracking.
Results obtained in the 64 test videos show nose tracking achieving great accuracy (Fig. 2a), reaching 90.61% when started from the automatic nose detection, and 97.67% of precision when starting from the ground truth nose. Face tracking reached 96.68% precision. The threshold was 20 pixels for all cases, as it is by the visual object tracking challenge [6].
Following a stricter evaluation protocol, the error threshold is reduced to ten pixels. Nose tracking achieves 82.30% when it is started from the automatic nose detection, and 92.09% precision when it is initialized from the ground truth annotation. Face tracking performance decrease to 76.20% precision, showing a better results with the nose when under a strict protocol.

Results on the 300VW dataset.
Despite the superior precision using nose tracking, its intersection coefficient is, in general, inferior when compared to face tracking, as demonstrated in Fig. 2b. Visual analysis indicates the lower rates was caused by the nose tracking prediction being slightly larger than the ground truth annotations, as it is not trivial to separate the nose region from the background, the face. When performing face tracking, the background can be easily discriminated from the target, favoring a correct scale estimation.
When considering the different testing subsets, nose and face tracking achieved similar precision on easy and medium difficulty videos, as shown in the Table 1 (categories 1 and 2). These subsets include variations in illumination and facial expressions, but no occlusion and rarely any head pose changes. Nose tracking initialized from the detection suffers degraded performance when the initial estimation is not perfect, affecting the subsequent tracking step.
The third category contains completely unrestricted environments including occlusion, illumination changes, large head pose variations, and facial expressions. In this scenario nose tracking is superior to the face, reaching 92.75% accuracy when started with the automatic detection, and 97.32% when it uses the ground truth region. The face achieves 91.47% of precision, showing that the proposed approach outperforms face tracking in the most challenging scenarios. These results are summarized on the last column of Table 1.
Figure 3 demonstrates samples of the tracked nose and face regions initialized from the ground-truth annotations and detections. Then the head pose changes, face tracking is lost, but the discriminating features of the nose allow the tracker to locate it.

Results obtained on the most challenging 300VW subset. The blue and green boxes were located by the nose tracker, detected and manually annotated, respectively. Face tracking results are in red. Frames were cropped to aid visualization. (Color figure online)
PaSC Dataset. The Point and Shoot Challenge (PaSC) dataset [1] consists of in-the-wild images and videos with varying degrees of degradation. However, it does not include face or nose region annotations, therefore 100 videos were randomly selected, and every frame was manually annotated to be used for testing. The same 300VW trained model was used for performing the nose tracking experiments on PaSC. Because the nose detection step necessary for face quality analysis failed on most frames, the nose tracker was only initialized using the manual annotations.
In some cases, nose tracking performs visually better than when the face is used, as can be seen in Fig. 4. Favorable nose tracking results are seen, as face tracking does not take account variations in scale and fails to predict the correct size.

Results on a low quality video with variations in scale obtained from PaSC. The blue and red boxes were located by performing nose and face tracking respectively. Frames were cropped to aid visualization. (Color figure online)

Results on the PaSCdataset
In general, face tracking achieved better results compared to the nose PaSC. This is due to the following reasons: The dataset has many low-resolution videos and large variations in scale, which drastically reduces the size of the nose region, rendering nose tracking harder compared to the whole face.
Taking into account the ten pixels error threshold, nose tracking reaches better precision rates (65.30% for the nose and 60.45% for the face). However, this relationship is not preserved as the threshold increases, as shown in Fig. 5a. When measuring the intersection coefficient, face tracking shows greater consistency in such scenarios, as demonstrated the Fig. 5b.
3 Final Remarks
In this work, a nose tracking approach was proposed as an alternative to face tracking in unconstrained environments. In addition, a quality assessment step was integrated into tracking initialization, avoiding depending on starting it using the first frame, which may contain poor illumination, occlusion or extreme head poses. The method was benchmarked on two datasets 300VW [11] and PaSC [1]. Experiments included nose tracking with automatic nose detection and ground truth annotations, comparing the results against face tracking.
It was shown that nose tracking achieves similar precision compared to using the whole face on common scenarios. On difficult, in-the-wild situations the proposed method achieves better precision against the face. Reaching 97.32% when the face reaches 91.47% on the most challenging 300VW [11] subset. These results promote nose tracking as a viable option when head pose variations, occlusions and illumination changes are present. Experiments also indicate that it is not trivial to precisely fit the nose region when tracking, given the similarity of the nose with the background (face) pixels, decreasing the accuracy when there are changes in scale. Experiments performed on 100 manually annotated videos from the PaSC dataset [1] show the difficulty found by nose tracking in videos with large scale variations where the target region is reduced. As future work, a nose detection correction step can be integrated into nose tracking pipeline, reducing the error when large scale variations are present.
References
Beveridge, J.R., et al.: The challenge of face recognition from digital point-and-shoot cameras. In: IEEE BTAS (2013)
Chang, K.I., Bowyer, K.W., Flynn, P.J.: Multiple nose region matching for 3D face recognition under varying facial expression. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 28, 1695 (2006)
Guo, Q., Feng, W., Zhou, C., Huang, R., Wan, L., Wang, S.: Learning dynamic siamese network for visual object tracking. In: International Conference on Computer Vision (ICCV). IEEE (2017)
Jain, A.K., Flynn, P., Ross, A.A.: Handbook of Biometrics. Springer, Heidelberg (2007). https://doi.org/10.1007/978-0-387-71041-9
Jia, X., Lu, H., Yang, M.H.: Visual tracking via adaptive structural local sparse appearance model. In: Computer Vision and Pattern Recognition (CVPR). IEEE (2012)
Kristan, M., et al.: The visual object tracking vot2015 challenge results. In: Proceedings of the IEEE International Conference on Computer Vision Workshops (CVPR Workshops) (2015)
Nam, H., Han, B.: Learning multi-domain convolutional neural networks for visual tracking. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Ranftl, A., Alonso-Fernandez, F., Karlsson, S., Bigun, J.: Real-time AdaBoost cascade face tracker based on likelihood map and optical flow. IET Biometrics 6, 468 (2017)
Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: towards real-time object detection with region proposal networks. In: Advances in Neural Information Processing Systems (NIPS) (2015)
Ross, D.A., Lim, J., Lin, R.S., Yang, M.H.: Incremental learning for robust visual tracking. Int. J. Comput. Vis. (IJCV) 77, 125 (2008)
Shen, J., Zafeiriou, S., Chrysos, G.G., Kossaifi, J., Tzimiropoulos, G., Pantic, M.: The first facial landmark tracking in-the-wild challenge: benchmark and results. In: International Conference on Computer Vision Workshop (ICCV Workshops). IEEE (2015)
Silva, L., Zavan, F., Silva, L., Bellon, O.: Follow that nose: tracking faces based on the nose region and image quality feedback. In: Conference on Graphics, Patterns and Images (SIBGRAPI) (2016)
Valmadre, J., Bertinetto, L., Henriques, J., Vedaldi, A., Torr, P.H.: End-to-end representation learning for correlation filter based tracking. In: Computer Vision and Pattern Recognition (CVPR). IEEE (2017)
Wu, Y., Lim, J., Yang, M.H.: Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 37, 1834 (2015)
Xiao, S., Yan, S., Kassim, A.A.: Facial landmark detection via progressive initialization. In: Proceedings of the IEEE International Conference on Computer Vision Workshops (CVPR Workshops) (2015)
Yang, J., Deng, J., Zhang, K., Liu, Q.: Facial shape tracking via spatio-temporal cascade shape regression. In: Proceedings of the IEEE International Conference on Computer Vision Workshops (CVPR Workshops) (2015)
Zavan, F., Nascimento, A., Silva, L., Bellon, O.: Nosepose: a competitive, landmark-free methodology for head pose estimation in-the-wild. In: Conference on Graphics, Patterns and Images (SIBGRAPI) (2016)
Zhang, K., Zhang, L., Yang, M.-H.: Real-time compressive tracking. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) ECCV 2012. LNCS, vol. 7574, pp. 864–877. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-33712-3_62
Acknowledgements
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
e Silva, L.P., Zavan, F.H.d.B., Bellon, O.R.P., Silva, L. (2019). Nose Based Rigid Face Tracking. In: Vera-Rodriguez, R., Fierrez, J., Morales, A. (eds) Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications. CIARP 2018. Lecture Notes in Computer Science(), vol 11401. Springer, Cham. https://doi.org/10.1007/978-3-030-13469-3_65
Download citation
DOI: https://doi.org/10.1007/978-3-030-13469-3_65
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-13468-6
Online ISBN: 978-3-030-13469-3
eBook Packages: Computer ScienceComputer Science (R0)
