
Abstract
In the world of Human-Computer Interaction, a computer should have the ability to communicate with humans. One of the communication skill that a computer requires is to recognize the emotional state of the human. With the state-of-the-art computing systems along with Graphical Processing Units, a Deep Neural Network can be realized by training on any publicly available dataset and learn the whole emotion estimation into one single network. In a real-time application, the inference of such a network may not need high computational power as training a network does.
Several Single Board Computers (SBC) such as Raspberry Pi is now available with sufficient computational power wherein during inference; small Deep Neural Networks models could perform well enough with acceptable accuracy and processing delay. The paper deals in exploring SBC capabilities for DNN inference, where we prepare a target platform on which real-time camera sensor data is processed to detect face regions and succeed further with recognizing emotions. Several DNN architectures are evaluated on SBC considering processing delay, possible frame rates and classification accuracy on SBC. Finally, a Neural Compute Stick (NCS) such as Intel’s Movidius is used to look at the performance of SBC for Emotion classification.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Communication is of vital importance, whether it is a human or a machine [13]. While machines communicate through bits and bytes, humans can communicate in several ways such as speech, body gestures and facial expressions. Psychologically, emotions could be understood with the subjective experiences accompanied by physiological, behavioral and cognitive changes with reactions. Each emotion is distinctive in producing different patterns in brain activation signals. For example, considering an emotion with surprise, the heart rate in humans may be increased due to being startled, humans could also have our muscles being temporarily tensed and relaxed. The annotation of such signal is a complex task which can be supported by annotation tools and active learning algorithms [12, 20]. In order to capture human emotions facial expressions is one of the methods to identify the existence of emotion, but there is always a possibility to combine speech recognition system to detect emotion or gesture-based emotion detection [7]. Such kind of human emotion detection system requires multimodal data which contains facial expressions, vocal expressions, body gestures, and physiological signals [15].
Thus, a complex system needs to be realized which often requires a high computation power [6, 10, 16]. Machine Learning applications are often dependent on several libraries that utilize multi-core architectures and hence reducing the overall processing time. Several machine learning libraries are officially supported for different architectures. In this paper, Raspberry PI (RPI) is chosen as SBC due to its low cost and low power architectures. Having 64 bit support to RPI would eventually allow us to have more addressing space and also different instruction set that could operate on 64-bit data. Hence there is need of 64-bit Linux operating system with several machine learning libraries supporting inferencing on ARMV8 architecture. Additionally, a DNN needs to be trained to extract features using Convolutional Neural Networks (CNN) for Facial Emotion Recognition (FER) classification on FER 2013 public dataset. Several DNN architectures are evaluated for inference. With the availability of NCS from Intel, evaluation is done for loading the neural network in the NCS using SBC as the host system.
Further sections of the paper are organized as follows: Sect. 2 provides a short literature survey on Emotion Recognition. Emotion Recognition System is described in Sect. 3. In Sect. 4, we discuss on results obtained for evaluating the dataset, feature map outputs, DNN models training and performance evaluation. Further discussion along with a live video output to detect emotions is visualized in Sect. 5. Finally, Sect. 6 concludes the paper with future work.
2 Background
Ekman et al. initially identified the basic emotion theory comprising of emotions that are constant across the cultures, and they are identified through facial expressions [3]. Fasel et al. have made an extensive survey on automatic facial expressions [4]. A framework for Facial expression analysis are discussed which consists of (1) Face Acquisition (2) Facial Feature Extraction and (3) Facial Expression Classification. Several methods that are available for each of these categories are well explained.
Haar-like features were proposed by Viola Jones for detecting faces [21]. Training of such a classifier takes more time because of the large dataset typically around 5000 faces and 35000 non-faces, but once trained, an inference of the face region is fast enough and also computation friendly when compared to several other methods such as deep convolution networks. Haar cascade methods are widely used in object detection [17].
An Emotion Recognition is proposed by Baveye et al. which is based on video dataset that is annotated version of 30 movies along the valence and arousal axis [2]. They use machine learning algorithms that are based on CNN, Support Vector Machines (SVM) for Regression and also a combination of both known as Transfer Learning. With the availability of powerful embedded systems, researchers are up in identifying the performance of CNN on embedded systems. Pena et al. have presented the benchmarking for networks namely GoogLeNet [18], AlexNet [8], Network in Network [24], CIFAR10 [11] on target devices RPI, Intel Joule 570X and also using a NCS [14].
A framework using deep cascaded multi-task is proposed by Zhang et al. where the model develops an inherent correlation and eventually boost the network performance [25]. The design consists of three cascaded CNN networks, where predictions are carried out in a coarse-to-fine manner. These networks are trained using WIDERFACE [23] dataset for face detection and Annotated Facial Landmarks in the Wild (AFLW) benchmarking for face alignment. Although this multi-task cascaded CNN is complex, it has proven to meet the real-time performance as well. Weighted Mixture Deep Neural Network (WMDNN) is used by fusing the weights from two different CNN, while the first DNN uses a VGG16 network that is trained on the ImageNet database and the other uses a shallow CNN [22].
With all the advancement in CNN’s and DNN’s, it is clear that the objective of using these networks are tending towards real-time processing using devices such as the Internet of Things (IoT), SBC, etc., Since these devices are low powered, additional add-on devices are being designed for processing huge DNN networks. Research is towards optimizing the hardware to make CNN’s being used on low power hardware chips. Andri et al. provide a hardware accelerator specifically optimized for binary weighted CNN’s [1]. The usage of CNN’s during training addresses the need for removing extensive computations by limiting to binary weights, resulting in reduced bandwidth and storage.
3 Emotion Recognition System
Emotion Recognition System consists of three phases:
-
Face Detection
-
Emotion Feature Extraction
-
Emotion Classifier.
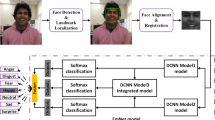
During the Face Recognition phase, a bounding box of the detected face is obtained first. To obtain a bounding box, two approaches have been used, Multi-Task Cascaded convolutional Neural Network (MTCNN) and Haar Cascade method. Once the bounding box is acquired in the image, the face region is cropped and resized to DNN input size, i.e., \(48\times 48\) pixels. Since a DNN of multiple layers is used, Emotion Feature Extraction and Emotion Classifier are combined, and the output of the Emotion Recognition DNN is the classifier output which has the probability estimation of emotions.
3.1 Deep Neural Networks
FER 2013 Database. As part of ICML challenge in 2013 [5], facial expression recognition database was introduced that was created using a search engine provided by Google, which is part of “In the wild” methodology of creating the database. The dataset was prepared by Pierre Luc Carrier and Aron Courville. In total, there are 35,887 images provided in the CSV file with the data columns consisting of Emotion Type, 1-D Grayscale image of dimension \(48\times 48\) and Image to be used for Training, Public (Validation) or Private (Testing) respectively.
Figure 1 shows the dataset distribution for 7 Emotions. We see an imbalanced dataset distribution for all the emotions. For example, Disgust emotion has the least number of data samples while Happy emotion has significantly more data samples. Overall, the distribution with other emotions except Disgust and Happy seems to be reasonably distributed.

FER2013 dataset distribution for 7 emotions
Models. The input images are of size \(48\times 48\) pixels that are single channel as they are grayscale. The DNN model consists of several CNN layers, Pooling layers, and Fully Connected (FC) layers. The kernel filter size plays a crucial role in computation complexity, and hence its size should be as minimal as possible. By using cascading of convolutional layers, it facilitates the model to learn more features but also keep the filter size minimal. We use Keras [9] as a machine learning API that uses TensorFlow [19] for model definition and training. A summary of models along with the number of parameters required for training is shown in Table 1.
To begin with, the model is designed to have a low number of features so that it gets trained to features such as lines and edges, and slowly the feature size keeps increasing. As an example, Fig. 2 shows the DNN architecture for all variants of ER DNN models. The input to the network is a \(48\times 48\) grayscale image, a convolution layer with kernel size \(3\times 3\) is used along with Rectilinear Unit Function (ReLU) Activation, Max pooling of \(2\times 2\) size is used and padding as ‘same’. The final block is a fully connected layer that has two 1024 Unit Dense layers, and the last layer of the model output is the classification output of 7 different classes that consist the probability estimate of each emotion class.

Emotion Recognition DNN Model: Feature extraction and classification based on CNN
4 Results
4.1 Dataset Validation Results
Model evaluation and Model selection are the two factors that could be considered for dataset validation. The model selection consists of hyper-parameter tuning for a specific class of models such as neural networks, linear models, etc., and model evaluation finds the estimate of the predictive power for a specific model which is unbiased.
Figure 3 shows the 10-Fold cross-validation result for the neural network model shown in Fig. 2 which is an 11-CNN layer network. The mean value of the accuracy was 67.05%. As the standard deviation was 0.006 (0.6%), the test error that occurs during inference would be ±0.6%.

Training and Validation results for 10-Fold cross validation

Feature Map Outputs at several layers for ermodel_cls7_conv3
4.2 Feature Map Output
The feature maps that the DNN was trained can be visualized as shown in Fig. 4. To get these visualizations, an image of emotion “Happy” was given as input to ermodel_cls7_conv3 network model which successfully classified the image as “Happy”. For convolutional layers, the feature maps are the outputs of ReLU activation; the maps are shown in the figure represents a color map distribution of ReLU output for convolutional layer 1, 2 and 3. The ReLU functions activity could be visualized in the graph where a minimum value of zero is indicated with navy blue color and maximum value with yellow color. We could see that the DNN first learns to detect edges and slowly adapts to learn more detailed features.
4.3 DNN Models Training
Emotion Recognition models were trained using FER2013 dataset. There were five network models each configured with an increasing size of convolution layers as shown in Table 1. The model name can be interpreted as ermodel - Emotion Recognition Model with cls7 as number of emotion classifications and convX representing X layers of convolution in the model. A summary of training results for those networks is shown in Table 2. The accuracy for ermodel_cls7_conv11 for Test dataset was 69% with train accuracy of 95.28% and is the highest among all the networks with 4,317,543 parameter count. ermodel_cls_conv8 has the lowest parameters to be trained, i.e., 2,826,759, having an accuracy of 90.73% and 67.9% on the Training dataset and Test dataset respectively.
4.4 SBC Performance Measurements
To evaluate the ER models inference time on NCS, NCSDK provides a profiler tool which is used to measure the inference time required by NCS. Table 3 provides the summary of the mvNCProfile tool output.
All the trained models for emotion recognition was used on RPI 3B+ hardware for detecting emotions through a live feed from camera interface. Different hardware configurations were used to evaluate four parameters:
-
CPU Load: This metric is used to evaluate the RPI CPU in executing the DNN network for inference, and any I/O operations involving frame read from the camera, loading the DNN to NCS, etc.
-
DNN Load Time: This metric is used to evaluate the initialization time of the application that involves loading of DNN libraries and also the Emotion Recognition model.
-
Frame Rate: This metric is a measure of RPI capability to process the live feed images from the camera in one second.
-
Processing Time: This metric provides the measure of time taken to process a single image captured from camera which includes reading the camera image, face region detection (RPI/NCS), emotion recognition inference (RPI/NCS) and displaying emotion graph in the Application GUI.
Figure 5(a)–(d) shows the plot of the above metrics. ER model inference is carried out using NCS and RPI, Face detection using Haar Cascade method is done using RPI, but while using MTCNN both RPI and also NCS (dual) are used.

Performance parameters measured on RPI and NCS
5 Discussion
As there are several configurations in which the ER could be run successfully for detecting emotions, some of the configurations come with the price of cost and computation. In case of total price being the limitation, then ER system could be completely run on RPI and in this case, using Haar Cascade method for face detection would be the best solution as it gives 4.5 fps with a detection rate of 222 ms. To get an excellent fps and a detection rate of 100 ms then using NCS would be more appropriate. Again in this configuration, Haar Cascade on RPI and ER on NCS has given a frame rate of 8 fps. Although the ermodel_cls7_conv3 gives good frame rate, it would be better to use ermodel_cls7_conv8 or ermodel_cls7_conv11, as it has shown better accuracy in detecting emotions during live video feed testing. Furthermore, ermodel_cls7_conv8 has less number of trained parameters and hence lower computation power and processing time. Furthermore, with the DNN models completely running on NCS, has a very low CPU usage, has not only stable processing time and loading time but also independent of ER models with a stable frame rate between 5 to 6 fps. The overall system with this configuration would be expensive to realize as it requires more NCS devices and could also lead to communication overhead.
Figure 6 shows the ER graph for Angry, Fear, Happy, Sad, Surprise and Neutral. Two different subjects were asked to enact several emotions and the ER Application was configured to use Haar Cascade method for face detection and ermodel_cls7_conv11 as ER model. Even though Disgust emotion was enacted, the ER model was not able to classify it to the right class. This is due to the model not being trained with sufficient images for Disgust class.

ER Application showing ER graph of six basic emotions
6 Conclusion
Emotion Recognition System was realized on a SBC that could run on low power requirements. The system is used to recognize emotions through a live video interface that could successfully detect face regions and also predict the emotions. The work carried out required a Linux Operating system supporting ARMV8 on RPI so that the libraries required for DNN inference could be loaded successfully into SBC. Furthermore, the application used as a graphical user interface to display camera feed and emotion graph was designed using multi-threading concepts and hence utilizing the SBC multi-core architecture. By using CNN, several DNN architectures was realized to extract the features from the desired FER dataset. The CNN feature maps reveal the learned features in several CNN layers that were used for the classifier which was a simple MLP.
The choice of RPI for an SBC has proven to have sufficient CPU computation power for running the DNN algorithms. Results show that multiple DNN algorithms such as MTCNN and ER could perform well enough with a frame rate of around 2 fps on RPI. Given the fact that the change in emotions is not that instant in real-world applications, the frame rates achieved for all the configurations and ER DNN models are within the acceptable range. Furthermore, the best test accuracy achieved for FER2013 dataset was around 69% for ermodel_cls7_conv11 ER model. The 10-Fold CV result for the model was with mean accuracy \(67.05\%\pm 0.6\%\) which indicates that the model is quite stable.
References
Andri, R., Cavigelli, L., Rossi, D., Benini, L.: Yoda NN: an architecture for ultralow power binary-weight CNN acceleration. IEEE Trans. Comput.-Aided Des. Integr. Circ. Syst. 37(1), 48–60 (2018). https://doi.org/10.1109/TCAD.2017.2682138. http://ieeexplore.ieee.org/document/7878541/
Baveye, Y., Dellandrea, E., Chamaret, C., Chen, L.: Deep learning vs. kernel methods: performance for emotion prediction in videos. In: 2015 International Conference on Affective Computing and Intelligent Interaction, ACII 2015, pp. 77–83. IEEE, September 2015. https://doi.org/10.1109/ACII.2015.7344554. http://ieeexplore.ieee.org/document/7344554/
Ekman, P., Friesen, W.V.: Constants across cultures in the face and emotion. J. Pers. Soc. Psychol. 17(2), 124–129 (1971). https://doi.org/10.1037/h0030377
Fasel, B., Luettin, J.: Automatic facial expression analysis: a survey. Pattern Recognit. 36(1), 259–275 (2003)
Goodfellow, I.J., et al.: Challenges in representation learning: a report on three machine learning contests. Neural Netw. 64, 59–63 (2015). https://doi.org/10.1016/j.neunet.2014.09.005
Kächele, M., Glodek, M., Zharkov, D., Meudt, S., Schwenker, F.: Fusion of audio-visual features using hierarchical classifier systems for the recognition of affective states and the state of depression. Depression 1(1) (2014)
Kächele, M., Schels, M., Meudt, S., Palm, G., Schwenker, F.: Revisiting the emotiw challenge: how wild is it really? J. Multimodal User Interfaces 10(2), 151–162 (2016)
Kalash, M., Rochan, M., Mohammed, N., Bruce, N.D., Wang, Y., Iqbal, F.: Malware classification with deep convolutional neural networks. In: 2018 9th IFIP International Conference on New Technologies, Mobility and Security, NTMS 2018 - Proceedings, January 2018, pp. 1–5 (2018). https://doi.org/10.1109/NTMS.2018.8328749
Keras: The Python Deep Learning Library. https://keras.io/. Accessed 08 Dec 2018
Kindsvater, D., Meudt, S., Schwenker, F.: Fusion architectures for multimodal cognitive load recognition. In: Schwenker, F., Scherer, S. (eds.) MPRSS 2016. LNCS (LNAI), vol. 10183, pp. 36–47. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-59259-6_4
Krizhevsky, A., Hinton, G.E.: Convolutional deep belief networks on CIFAR-10, pp. 1–9 (2010, unpublished manuscript)
Meudt, S., Bigalke, L., Schwenker, F.: Atlas-annotation tool using partially supervised learning and multi-view co-learning in human-computer-interaction scenarios. In: 2012 11th International Conference on Information Science, Signal Processing and their Applications (ISSPA), pp. 1309–1312. IEEE (2012)
Meudt, S., et al.: Going further in affective computing: how emotion recognition can improve adaptive user interaction. In: Esposito, A., Jain, L.C. (eds.) Toward Robotic Socially Believable Behaving Systems - Volume I. ISRL, vol. 105, pp. 73–103. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-31056-5_6
Pena, D., Forembski, A., Xu, X., Moloney, D.: Benchmarking of CNNs for low-cost, low-power robotics applications. In: RSS 2017 Workshop: New Frontier for Deep Learning in Robotics, pp. 1–5 (2017)
Schwenker, F., et al.: Multimodal affect recognition in the context of human-computer interaction for companion-systems. In: Biundo, S., Wendemuth, A. (eds.) Companion Technology. CT, pp. 387–408. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-43665-4_19
Siegert, I., et al.: Multi-modal information processing incompanion-systems: a ticket purchase system. In: Biundo, S., Wendemuth, A. (eds.) Companion Technology. CT, pp. 493–500. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-43665-4_25
Soo, S.: Object detection using Haar-cascade Classifier. Inst. Comput. Sci. Univ. Tartu 2(3), 1–12 (2014)
Szegedy, C., et al.: Going deeper with convolutions. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, vol. 07, pp. 1–9, 12 June 2015. https://doi.org/10.1109/CVPR.2015.7298594
TensorFlow: An Open Source Machine Learning Framework for Everyone. https://www.tensorflow.org/. Accessed 08 Dec 2018
Thiam, P., Meudt, S., Palm, G., Schwenker, F.: A temporal dependency based multi-modal active learning approach for audiovisual event detection. Neural Process. Lett. 48(2), 709–732 (2018)
Viola, P., Jones, M.: Rapid object detection using a boosted cascade of simple features. In: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, vol. 1, pp. I-511–I-518. IEEE Computer Society (2001). https://doi.org/10.1109/CVPR.2001.990517. http://ieeexplore.ieee.org/document/990517/
Yang, B., Cao, J., Ni, R., Zhang, Y.: Facial expression recognition using weighted mixture deep neural network based on double-channel facial images. IEEE Access 6, 4630–4640 (2017). https://doi.org/10.1109/ACCESS.2017.2784096
Yang, S., Luo, P., Loy, C.C., Tang, X.: WIDER FACE: a face detection benchmark. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5525–5533. IEEE, June 2016. https://doi.org/10.1109/CVPR.2016.596. http://ieeexplore.ieee.org/document/7780965/
Yoshioka, T., et al.: The NTT CHiME-3 system: advances in speech enhancement and recognition for mobile multi-microphone devices. In: 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), pp. 436–443. IEEE, December 2015. https://doi.org/10.1109/ASRU.2015.7404828. http://ieeexplore.ieee.org/document/7404828/
Zhang, K., Zhang, Z., Li, Z., Qiao, Y.: Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 23(10), 1499–1503 (2016). https://doi.org/10.1109/LSP.2016.2603342. http://ieeexplore.ieee.org/document/7553523/
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Srinivasan, V., Meudt, S., Schwenker, F. (2019). Deep Learning Algorithms for Emotion Recognition on Low Power Single Board Computers. In: Schwenker, F., Scherer, S. (eds) Multimodal Pattern Recognition of Social Signals in Human-Computer-Interaction. MPRSS 2018. Lecture Notes in Computer Science(), vol 11377. Springer, Cham. https://doi.org/10.1007/978-3-030-20984-1_6
Download citation
DOI: https://doi.org/10.1007/978-3-030-20984-1_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-20983-4
Online ISBN: 978-3-030-20984-1
eBook Packages: Computer ScienceComputer Science (R0)
