
Abstract
Adult-child reading interactions can produce efficient childhood learning outcomes when formal methods of adult-initiated prompting and dialog are employed. In order to quantify instances of such prompting, child development researchers often manually code speech recordings or transcripts taken from adult-child readings, which can be a laborious process. For researchers, it would therefore be valuable to have the capacity to automatically capture quantitative measures of communication from adult-child reading interactions. This paper introduces SoundCount, a new open-source utility for extracting descriptive features from recordings of speech during communication between an adult and child reading an eBook together. In a simple web-based framework, SoundCount consolidates functionalities for speech analysis and quantification in the context of dyadic reading interactions, specifically providing measures related to word count and speaker differentiation. Our preliminary results demonstrate the functional feasibility of SoundCount, and our technical discussion will enable readers to use SoundCount in their own research. Given the technical viability of SoundCount, future work will include the implementation of additional measures for the system, new features such as automated audio segmentation based on speaker, and a test of the efficacy of real-time feedback systems based on speech measures.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Evidence suggests that children learn more efficiently from story reading when an adult such as a parent or teacher actively engages the child in dialogue about the story [1, 2]. The formalized technique of dialogic reading involves adult-child reading scenarios in which a child practices vocabulary while receiving real-time feedback from the adult [3]. Researchers have typically employed manual human coding methods to quantify instances of such “dialogic questioning”, which can be a laborious activity [4]. For researchers, it would therefore be valuable to have the capacity to automatically capture quantitative measures of communication during adult-child reading interactions. Specifically, a measure of the proportion of speech by the adult, as well as by the child, could provide valuable information regarding reciprocal communication even without analysis of the semantic content [5]. In addition, information such as the number of vocalizations or the number of words that occur during a reading—both from the adult and child—as well as the change in the number of vocalizations or words over time would allow researchers to design protocols aimed at optimizing adult-child communication during reading in order to improve learning outcomes for young children.
Mobile computing devices such as tablets, smartphones, and e-readers are now commonly used for reading and education and have shown increased acceptance over time. Teaching through the use of electronic books (eBooks) has shown evidence of significantly enhanced learning among children [6], although researchers do recommend limiting screen time exposure especially before bedtime [7]. Some of the strengths of eBooks over traditional books include the ability of eBooks to (a) define unfamiliar words directly within the application, (b) display story text in other languages, (c) dynamically adapt the story text the reader, such as according to reading ability, (d) prompt interaction and communication, such as between a child and an educator or parent, to optimize learning outcomes, and (e) automatically capture process and performance measures to track performance and learning.
In the current work, we designed a tool for child development researchers who wish to automatically capture quantitative measures of speech from adult-child communication during eBook readings. SoundCount, the proposed speech recognition system, is an open-source utility for extracting descriptive features from recordings of speech during communication between an adult and child reading an eBook together [8]. While commercial speech-to-text services, such as those available by Google Cloud and Microsoft Azure, offer a vast range of functionality, SoundCount was designed to produce a simple set of measures in the specific context of dyadic reading, thus helping researchers to better understand and track learning outcomes in children.
2 System Design
2.1 System Overview
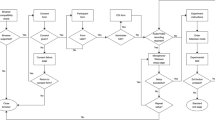
SoundCount used Python (version 3.6.6) as the principal programming language and was built using several established support frameworks. SoundCount uses Flask [9] as a simple Hypertext Transfer Protocol (HTTP) server to receive audio files via HTTP POST requests. For speech recognition, Python’s SpeechRecognition library was selected for its support of multiple recognition engines. Using this library, transcripts of users’ speech is produced from an audio file, from which a word count approximation is easily computed. Additionally, SoundCount also leverages Python’s Natural Language Toolkit (NLTK) [10] part-of-speech tagger, specifically the Averaged Perceptron Tagger, to identify and label part-of-speech meta-information from the transcript. The overall software architecture of SoundCount is given in Fig. 1. Using a persistent model—trained previously on data from [11]—an analysis of the speech is conducted which attempts to identify gender, age, and the language dialect of the speaker. Finally, SoundCount reports the duration of the speech in the audio recording. All results are returned in a single JavaScript Object Notation (JSON)-encoded object.

SoundCount software architecture overview
2.2 System Architecture
From a high-level perspective, SoundCount was designed as a web service operating as a daemon process. By interfacing with client applications via standard HTTP methods, client applications would remain modular and non-dependent on various frameworks, such as packages for recording/analyzing audio, user interface toolkits, and/or operating systems. This design pattern gave SoundCount deployment flexibility as well, where the daemon application receiving each HTTP request over a network interface might reside on the localhost machine via a loopback address, a computer on a small wireless network such as a home or office, or as a process accessible via an Internet client. In this way the application’s scope is not be limited to a single user/machine, and the daemon can easily scale on demand; each client interface needs only to specify a host and port number. The daemon could run on dedicated hardware. For example, a website might act as an interface to the daemon process for its users, or multiple instances of the daemon could spawn on different ports with a load balancing mechanism. For test cases described in the current work, a standalone C♯ GUI application was created to interface with SoundCount on a standard PC running Microsoft Windows 7 (see Fig. 2). The daemon process was developed on machines running Ubuntu 16.04 and macOS High Sierra.

Frontend GUI developed for testing SoundCount.
Because most speech recognizers support the Waveform Audio (.wav) format, we used this format exclusively in the current work. Planned future development will add support for additional formats. For example, Python’s PyDub library can be used to convert MPEG Layer 3 (.mp3), and other proprietary formats on demand to .wav files, and most recognizers support popular formats. Received audio files are not preprocessed upon receipt; the data is temporarily stored to disk and renamed using a randomly generated Universally Unique Identifier (UUID) to avoid filename collisions. The Flask server checks that the HTTP POST requests does contain a “file” field which corresponds to the audio file and responds with an error if the field is absent.
The abbreviated code listing below presents the behavior of the server-side post() method used by SoundCount to process client requests. Lines 11–19 receive and parse the client request and save the audio data as a file identified by the “tempfile” variable. Lines 22 and 23 perform speech recognition and run the audio through the voice analyzer, respectively. Both of these functions return dict() types so the payload’s meta information is updated in place. Line 27 uses Python’s built-in len() function to estimate word count, and line 28 uses NTLK’s Averaged Perceptron Tagger to tag the list of words. The duration of the file is calculated using the audio’s frame count divided by the frame-rate; this is done on line 29. Finally, the temp file is removed, and the complete payload is returned. Flask coverts Python’s dict() type into a serialized JSON string for convenient parsing on the client-side.

The aptly named SpeechRecognition library was selected for its ability to query application program interfaces (APIs) such as Google Cloud, Bing, Houndify, and an offline recognizer called Sphinx. To simplify SoundCount’s configuration, an environment.py file provides a Python dictionary of user-configured credentials for paid services. The environment file also specifies a host/port combination on which the daemon shall listen for requests. In the current work, we opted for the offline recognizer, Sphinx, which has strong runtime performance and a word error rate of about 14% [12]. Note that word error rate is impacted by word identification in addition to word count. While a word error rate of this size would be too large for reliable speech content analysis (i.e., understanding the exact phrase spoken), it is adequate in the current work given the priority placed on measuring speech duration and frequency. The SpeechRecognition library recognizer outputs a string of text that is tokenized into a list of string natural lexemes. NLTK’s Perceptron tagger receives the lexemes as input to tag a part-of-speech field. The role of NTLK in SoundCount was to resolve ambiguity surrounding certain language complexities. For example, the word can’t may appear in a transcript as one word but is actually a contraction of two words and could be counted as such. Similarly, right-handed may appear as one word, but could be regarded as a combination of two instead. SoundCount’s policy for handling such edge cases is to base its word count on the number of parts-of-speech recognized, rather than on the possible decomposition of words containing hyphens and apostrophes.
In addition to identifying the parts of speech, SoundCount attempts to label the gender, dialect, and age of the speaker. This exploratory component of SoundCount leverages an existing open-source (MIT license) project called Voice-Analyzer to capture preliminary metrics. Voice-Analyzer uses SciPy’s DecisionTreeClassifier to classify audio samples, and reports reasonable accuracy (e.g., nearly 90% in the prediction of both age and gender), albeit from a relatively homogeneous training set (88% of the training data were male, 85% were adult, and 49% had an American dialect) [11]. Also, because many speech-to-text machine learning models employ artificial neural network models for temporal data processing through convolution, a decision tree approach may result in a less robust predictor for these labels. Nonetheless, SoundCount supports serialized objects (sometimes referred to as pickled objects) should models improve in the future.
Finally, all of the metadata associated with a client-provided audio recording are packaged into a Python dictionary. The dictionary structure is serialized into a JSON object and returned via Flask, completing the HTTP POST request. Each JSON object includes (a) a “status” field with a value of either success or failure, (b) a “count” field containing the part-of-speech count, and (c) a nested object “meta” containing a list of words with part-of-speech, gender, age, dialect, and the duration of the audio, such as that shown in the following example:

3 Results and Discussion
Although the primary contribution of this work is the development of a novel utility that brings together disparate functionalities and resources for speech quantification, we tested a key element of SoundCount’s data output. Using the novel GUI (Fig. 2) to capture speech, data were collected from four adult volunteers (two males and two females; mean age = 38.25) to gauge the word-count estimation error of SoundCount. Subjects were asked to read from randomly selected sections of an online article while their speech was recorded by a laptop microphone. All phrases were read in English and ranged in length from 1–34 words. This was repeated 10 times for each subject, producing 40 data points for error analysis. Audio recordings were sent to SoundCount via the post method detailed in Table 1, and a JSON object containing speech analysis results was returned to the client. Using the actual number of words spoken by the subject and the number of words reported by SoundCount, we computed the Mean squared error (MSE), Root-mean-square error (RMSE), and Pearson correlation coefficient for each subject. Using the comparatively simple Sphinx model [13], RMSE were quite low and the Pearson correlation values were large (i.e., >.50; [14]). Moreover, SoundCount correctly predicted the speaker’s gender and language in each test case. While this small sample cannot be used to make inferences about system performance within naturalistic settings, it does provide evidence of the feasibility of SoundCount and demonstrate that the system operates well within relatively constrained settings.
4 Conclusion
SoundCount is a new open-source utility for extracting descriptive features from recordings of speech during communication between an adult and child reading interaction. By automatically quantifying speech measures spoken during dyadic interactions, SoundCount will help researchers who have typically hand-coded such information and will facilitate the development of sophisticated systems that utilize speech data in an adaptive manner.
While our current work demonstrates the feasibility of SoundCount for its intended function, planned future work will address some of the current limitations of the tool. First, SoundCount currently functions under the assumption that audio segmentation is performed on the client-side and that audio files contain the voice of only one speaker at a time; because a major aim of SoundCount is to seamlessly quantify the proportion of speech by speaker, future work will investigate automatic segmentation of audio recordings based on speaker profile. Indeed, work is currently under way to develop an automatic segmentation component of the SoundCount speech processing algorithm. This segmentation step will produce an array of audio segments that will be iteratively processed using the current capabilities. Second, SoundCount performs reliably when the speaker’s voice is captured clearly by the microphone and is not currently enabled to handle cases in which two or more speakers may be speaking at the same time or if there is significant background noise. Third, the current work’s frontend testbed did not implement a buffer to read and seek audio data from despite our frameworks supported this input method. Finally, the data is not explicitly validated as an audio file type. Future development will implement these checks in order to produce a more robust system.
Our preliminary results demonstrate the functional feasibility of SoundCount, and our technical discussion will enable readers to use SoundCount in their own research. Given the technical viability of SoundCount, future work will include the implementation of additional measures for the system as well as a test of the efficacy of real-time feedback systems based on speech measures. Upcoming future work with SoundCount will test the validity of data acquisition in the context of adult-child reading interactions, and our team is actively working to add new metrics to SoundCount based on the requirements of child development researchers. For instance, we intend to use vocal intonation to interpret the sentiment of users’ speech, which could provide a useful indication of user engagement within the reading interaction.
References
Hargrave, A.C., Sénéchal, M.: A book reading intervention with preschool children who have limited vocabularies: the benefits of regular reading and dialogic reading. Early Child. Res. Q. 15(1), 75–90 (2000). https://doi.org/10.1016/S0885-2006(99)00038-1
Fleury, V.P., Schwartz, I.S.: A modified dialogic reading intervention for preschool children with autism spectrum disorder. Top. Early Child. Spec. Educ. 37(1), 16–28 (2017). https://doi.org/10.1177/0271121416637597
Zevenbergen, A.A., Whitehurst, G.J.: Dialogic reading: a shared picture book reading intervention for preschoolers. Read. Books Child. Parents Teach. 177–200 (2003). https://doi.org/10.4324/9781410607355
Whitehurst, G.J., et al.: Accelerating language development through picture book reading. Dev. Psychol. 24(4), 552 (1988). https://doi.org/10.1037/0012-1649.24.4.552
Harbison, A.L., Woynaroski, T.G., Tapp, J., Wade, J.W., Warlaumont, A.S., Yoder, P.J.: A new measure of child vocal reciprocity in children with autism spectrum disorder. Autism Res. 11(6), 903–915 (2018). https://doi.org/10.1002/aur.1942
Union, C.D., Union, L.W., Green, T.D.: The use of eReaders in the classroom and at home to help third-grade students improve their reading and English/language arts standardized test scores. TechTrends 59(5), 71–84 (2015). https://doi.org/10.1007/s11528-015-0893-3
Dube, N., Khan, K., Loehr, S., Chu, Y., Veugelers, P.: The use of entertainment and communication technologies before sleep could affect sleep and weight status: a population-based study among children. Int. J. Behav. Nutr. Phys. Act. 14(1), 97 (2017). https://doi.org/10.1186/s12966-017-0547-2
SoundCount (2018). https://github.com/vanities/SoundCount. Accessed 20 Jan 2019
Ronacher, A.: Welcome—flask (a Python microframework), p. 38 (2010). http://flask.pocoo.org/. Accessed 02 Feb 2015
Bird, S., Loper, E.: NLTK: the natural language toolkit. In: Proceedings of the ACL 2004 on Interactive poster and demonstration sessions, p. 31 (2004). https://doi.org/10.3115/1219044.1219075
Voice-Analyzer (2018). https://github.com/lreynolds18/Voice-Analyzer. Accessed 20 Jan 2019
Huggins-Daines, D., et al.: A free, real-time continuous speech recognition system for hand-held devices. In: IEEE International Conference on Acoustics, Speech and Signal Processing Proceedings, ICASSP 2006, vol. 1, p. I (2006). https://doi.org/10.1109/icassp.2006.1659988
PocketSphinx (2018). https://github.com/cmusphinx/pocketsphinx. Accessed 20 Jan 2019
Ellis, P.D.: The Essential Guide to Effect Sizes: Statistical Power, Meta-analysis, and the Interpretation of Research Results. Cambridge University Press, Cambridge (2010)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Schmidt, M. et al. (2019). A Simple Web Utility for Automatic Speech Quantification in Dyadic Reading Interactions. In: Zaphiris, P., Ioannou, A. (eds) Learning and Collaboration Technologies. Ubiquitous and Virtual Environments for Learning and Collaboration. HCII 2019. Lecture Notes in Computer Science(), vol 11591. Springer, Cham. https://doi.org/10.1007/978-3-030-21817-1_10
Download citation
DOI: https://doi.org/10.1007/978-3-030-21817-1_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-21816-4
Online ISBN: 978-3-030-21817-1
eBook Packages: Computer ScienceComputer Science (R0)