
Abstract
Block-based compressed sensing (CS) recovery aims to reconstruct the high quality image from only a small number of observations in a block-wise manner. However, when the sampling rate is very low and the existence of additive noise, there are usually some block artifacts and detail blurs which degrades the reconstructed quality. In this paper, we propose an efficient method which takes both the advantages of deep learning (DL) framework and iterative approaches. First, a deep multi-layer perceptron (DMLP) is constructed to obtain the initial reconstructed image. Then, an efficient iterative approach is applied to keep the consistence and smoothness between the adjacent blocks. The proposed method demonstrates its efficacy on benchmark datasets.
Similar content being viewed by others

Keywords
1 Introduction
In block compressive sensing (BCS) [5], an image \(\mathbf {X}\) is divided into a certain number of image blocks with size \(B \times B\). For the ith block,
where \(\varvec{\varPhi }_{B} \in R^{M_{B}\times B^{2}}\) represents the sensing matrix, \(\mathbf {y}_{i} \in R^{M_{B}}\) is the observed vector for the ith block, \(\mathbf {x}_{i} \in R^{B^{2}}\) denotes the ith vectorized block and \(\mathbf {n}_{i}\) denotes the additive noise.
Given \(\varvec{\varPhi }_{B}\), designing efficient approaches to recover \(\mathbf {x}_{i}\) from \(\mathbf {y}_{i}\) is very critical. It is well-known that most of existing BCS are based on the iterative approaches [2,3,4, 6]. To further improve the quality of the reconstructed image, more comprehensive models, such as the bilevel optimization model [10], multi-objective optimization models [11] and sparsity-enhanced models [2, 6] are proposed. Although proper modeling could contribute a bit in achieving very competitive results, these models are usually not easy to solve, which requires different iterative approaches, e.g. iterative thresholding shrinkage methods, gradient-based methods or some evolutionary algorithms. To obtain the satisfactory results, it is often the case that more number of iterations are preferred, increasing the computational complexity. Moreover, the initial solution is also very important, which is currently obtained either by random initialization or by the least squares (LS) method. When the sampling rate (SR) is small (less than 20%), which makes the problem seriously ill-posed, these methods may not guide the iterative algorithm to converge to a high quality solution fast enough.
In this paper, we propose an efficient method which takes both the advantages of deep learning framework and the iterative approaches. First, a deep multi-layer perceptron (DMLP) is trained to find the mapping between BCS measurements and the original imagery blocks. Then, an efficient iterative approach is applied on the whole image to further reduce the block artifacts between the adjacent blocks. The proposed method is compared with several state-of-the-art competitors on the benchmark database and demonstrates its efficacy. The rest of our paper is organized as follows. Section 2 introduces our proposed BCS reconstruction approach, the experimental studies are presented in Sect. 3, and the conclusion is finally made in Sect. 4.
2 The Proposed Method
2.1 Deep MLP
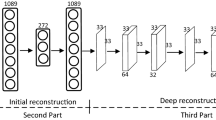
Following the suggestions in [1], the structure of deep MLP (DMLP) is shown in Fig. 1, which consists of give layers.

Structure of the proposed DMLP

Flowchart of our proposed approach
For the input layer, the number of neurons is set equal to the length of vectorized image block, \(B^{2}\). The connection weights between the input layer and the sensing layer construct the sensing matrix, where the signal \(\mathbf {x}_{i} \in R^{B^{2}}\) is mapped to \(\mathbf {y}_{i} \in R^{M_{B}}\) (\(M_{B} \ll B^{2}\)). There are two reconstruction layers that perform recovery of \(\mathbf {x}_{i}\) from \(\mathbf {y}_{i}\) and each followed by an activation function in terms of rectified linear units (ReLU) [7]. The length of the reconstruction layer is usually determined by \(B^{2} \times T\), where T denotes the redundancy parameter for reconstruction. The output layer has the same size with input layer, which denotes the reconstructed signal, \(\hat{\mathbf {x}}_{i}\). In overall, the mathematical expression of the DMLP can be written as:
where \(\cdot \) denotes the product between matrix and vector and \(ReLU(\mathbf {x})=max(\mathbf {0},\mathbf {x})\) is the activation function based on an element-wise comparison.
2.2 Smoothed Projected Landweber Algorithm
Landweber iteration algorithm is a classical approach to solve the ill-posed linear inverse problems. The projected version converts the original signal into a sparse or compressive domain where the sparsity could be enhanced, so it could be intuitively applied in CS image reconstruction. Considering removing the block artifacts, the procedure of BCS combined with smoothed projected Landweber (SPL) algorithm is given in Algorithm 1, where \(\varvec{\varPsi }\) denotes the sparse basis Dual-tree Discrete Wavelet Transform (DDWT) [6] applied in our method.

2.3 The Flowchart of Our Approach
As presented in Fig. 2, the proposed method is composed of two stages: at first, we establish an end-to-end deep neural network based on MLP and obtain the reconstructed image block by block based on inference. In the second stage, the reconstructed image in the first stage is used as the initial solution, \({\mathbf {x}}^{(0)}\), the SPL iteration method is applied to get the ultimately recovered image.
3 Experimental Studies
3.1 Parameter Settings
In our experiment, we randomly choose 5,000,000 image blocks from 50,000 images in LabelME database [8]. The learning rate is set to 0.005, the batch size is 16 with a block size \(16\times 16\) and the redundancy parameter R is equal to 8. All the training images for DMLP are converted into grayscale images.
3.2 Numerical and Visual Results
In Table 1, the peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) [9] for 10 test images when SR is equal to 0.1, 0.125, 0.15 and 0.175 are given and each image is tested for 20 times. For simplicity, we fixed the overlap equal to 8 in all the simulations. It is demonstrated that our proposed method could achieve significantly higher PSNR and SSIM. In comparison to the DL-based method, the proposed approach could have a maximum 0.9dB gain in PSNR and the improvement is more significant when the SR is smaller. Our method utilizes the powerful regression ability of DNN in the first stage and have a very good estimated initial solution for the iterative process in the second stage especially under a very low SR.
3.3 Computational Time
To evaluate the efficiency of our proposed method, the computational time for different methods with and without overlap between the adjacent blocks is recorded in Table 2. BCS-DNN only needs the fast inference, which is able to be completed in around 3 s. In our method, the initial solution obtained by DNN is usually near-optimal, which largely reduces the iterative times. So, its computational time is comparative to BCS-DNN and could achieve a higher reconstruction quality.
4 Conclusion
In this paper, we proposed an efficient CS recover method. At first, a DMLP is built where the recovered image block is obtained based on the inference from the learned regression parameters and its input measurements. Then, SPL is applied on the whole image to further reduce the block artifacts and improve the pixel consistence and smoothness between the adjacent blocks. Experimental results demonstrate that our method could not only achieve competitive numerical results but also outperform the compared methods in visual quality.
References
Adler, A., Boublil, D., Elad, M., Zibulevsky, M.: A deep learning approach to block-based compressed sensing of images. arXiv preprint arXiv:1606.01519 (2016)
Chen, C., Tramel, E.W., Fowler, J.E.: Compressed-sensing recovery of images and video using multihypothesis predictions. In: 2011 Conference Record of the Forty Fifth Asilomar Conference on Signals, Systems and Computers (ASILOMAR), pp. 1193–1198. IEEE (2011)
Fowler, J.E., Mun, S., Tramel, E.W.: Multiscale block compressed sensing with smoothed projected landweber reconstruction. In: 2011 European Signal Processing Conference, pp. 564–568 (2011)
Fowler, J.E., Mun, S., Tramel, E.W., et al.: Block-based compressed sensing of images and video. Found. Trends Sig. Process. 4(4), 297–416 (2012)
Gan, L.: Block compressed sensing of natural images. In: 2007 15th International Conference on Digital Signal Processing, pp. 403–406, July 2007. https://doi.org/10.1109/ICDSP.2007.4288604
Mun, S., Fowler, J.E.: Block compressed sensing of images using directional transforms. In: 2010 Data Compression Conference. pp. 547–547, March 2010. https://doi.org/10.1109/DCC.2010.90
Nair, V., Hinton, G.E.: Rectified linear units improve restricted Boltzmann machines. In: International Conference on Machine Learning, pp. 807–814 (2010)
Russell, B.C., Torralba, A., Murphy, K.P., Freeman, W.T.: Labelme: a database and web-based tool for image annotation. Int. J. Comput. Vision 77(1–3), 157–173 (2008)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13(4), 600–612 (2004)
Zhou, Y., Kwong, S., Guo, H., Gao, W., Wang, X.: Bilevel optimization of block compressive sensing with perceptually nonlocal similarity. Inf. Sci. 360, 1–20 (2016). https://doi.org/10.1016/j.ins.2016.03.027
Zhou, Y., Kwong, S., Guo, H., Zhang, X., Zhang, Q.: A two-phase evolutionary approach for compressive sensing reconstruction. IEEE Trans. Cybern. 47(9), 2651–2663 (2017)
Acknowledgment
This work is supported in part by the Natural Science Foundation of China under Grant 61702336, in part by Shenzhen Emerging Industries of the Strategic Basic Research Project JCYJ20170302154254147, and in part by Natural Science Foundation of SZU (grant No. 2018068).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Lin, J., Zhou, Y., Kang, J. (2019). Low-Sampling Imagery Data Recovery by Deep Learning Inference and Iterative Approach. In: Douligeris, C., Karagiannis, D., Apostolou, D. (eds) Knowledge Science, Engineering and Management. KSEM 2019. Lecture Notes in Computer Science(), vol 11775. Springer, Cham. https://doi.org/10.1007/978-3-030-29551-6_44
Download citation
DOI: https://doi.org/10.1007/978-3-030-29551-6_44
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-29550-9
Online ISBN: 978-3-030-29551-6
eBook Packages: Computer ScienceComputer Science (R0)