
Abstract
In this work we discuss the action classification performance obtained with a baseline assessment of the MoCA dataset: a multimodal, synchronised dataset including Motion Capture data and multi-view video sequences of upper body actions in a cooking scenario. To this purpose, we setup a classification pipeline to manipulate the two data type. For the MoCap, we employ a representation based on the use of 3D+t histograms modelling the space-time evolution of an action, classified using a classical Support Vector Machine with a linear kernel. As for the videos, we learn the representation using a variant of the Inception 3D model, followed by a Single Layer Perceptron as a classifier. Discussing the experimental analysis will be the opportunity to observe the diversity of MoCap and video data at work in two scenarios of uneven complexity, i.e. on streams of data describing regular repetitions of the same action, or when actions are part of a more complex and structured activity where actions influence each other.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Classifying actions from visual data is paramount for a number of applications, ranging from robotics and human-machine interaction, to industry and entertainment. Over the last decades, research activities rode the wave of technological advances in the visual devices, comfortably bouncing from the use of one specific data source to another. Videos and Motion Capture devices are undoubtedly two backbones of the research in recent years, and the numerous surveys published so far on action understanding topics, e.g. [2, 5, 11] just to name a few, report detailed discussions on the peculiarities of the two. While stating which data source may be considered the best choice from a general standpoint is not trivial, it may be speculated that videos and skeleton data can be considered as complementary information carriers, characterized by uneven amount of signal-to-noise ratios. On one hand, Motion Capture data can provide precise but sparse 3D representations of actions; on the other, videos are more rich but also harder to analyse and affected by perspective projection issues.
In this paper, we discuss the action classification performance obtained with a baseline assessment of the MoCA (MultimOdal Cooking Actions) dataset, with specific focus of the effect of data sources. To this purpose, we setup a classification pipeline that, starting from the same “data portions” (provided by data annotation), is suitably instantiated to manipulate Motion Capture or video data. For the first, we employ a representation based on the use of 3D+t histograms modelling the space-time evolution of an action, classified using a classical Support Vector Machine with a linear kernel. As for the latter, we learn the representation using a variant of the Inception 3D model [1], followed by a Single Layer Perceptron as a classifier.
Exploiting the MoCA dataset, we compare the classification of upper-body cooking actions in two scenarios of different complexity: (i) on streams of data describing regular repetitions of the same action, (ii) when actions are part of a more complex and structured activity, and thus, although performed more naturally, are influenced by other actions occurring in the temporal neighborhood.
The reminder of the paper is organized as follow. In Sect. 2 we introduce the dataset and its characteristics, followed by Sects. 3 and 4 where we present the methodologies of representation and classification for, respectively, Motion Capture and video data. Sect. 5 discusses the experimental assessment, while Sect. 6 is left to conclusions.
2 The MoCA Dataset
The MoCA (MultimOdal Cooking Actions) dataset [10] is a multimodal, synchronised dataset in which we collect Motion Capture (henceforth referred to as MoCap) data and video sequences acquired from multiple views of upper body actions in a cooking scenarioFootnote 1. It has been collected with the specific purpose of investigating view-invariant action properties in both biological and artificial systems, and in this sense it may be of interest for multiple research communities in the cognitive and computational domains. Beside addressing classical action recognition tasks, the dataset enables research on different nuances of action understanding, from the segmentation of action primitives robust across different sensors and viewpoints, to the detection of action classes depending on their dynamic evolution or the goal.

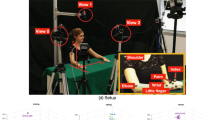
A visualization of the acquisition setting. (a) An overall image of the setup, (b) a detailed view of the markers of the right arm of the volunteer, (c) sample trajectories, color coded with respect to the marker, for one entire unsegmented sequence of action Mixing in a bowl (with 17 instances). Sample frames of the corresponding video acquisitions are reported in (d) View 0, (e) View 1 and (f) View 2.
We report in Table 1 the list of 20 cooking actions included in the dataset. The range of actions presents significant diversity in terms of motion granularity, since actions may involve the movement of fingers, hands or the entire arms. Also, they may involve the use of one or two arm(s) of the volunteer, and possibly the use of tools might require application of a variety of forces.
The acquisition setting (see Fig. 1(a)) included a motion capture system composed by six VICON infrared cameras, each one equipped with an infrared strobe capturing the light emitted by six reflective markers placed on relevant joints of the right arm of the actor: shoulder, elbow, wrist, palm, index finger and little finger (Fig. 1(b)). Markers were calibrated in order to share the same coordinate system and the final trajectories were recorded synchronously at a rate of 100 Hz/s. An example of the acquired trajectories for the action Mixing in a bowl is reported in Fig. 1(c). For what concerns the video data, three identical high resolution IP cameras were employed. The cameras observe the scene from three different viewpoints: a lateral view (View 0), an egocentric view (View 1; obtained with a camera mounted slightly above the subject’s head), and a frontal view (View 2). Figure 1, bottom row, reports sample frames for the action Mixing in a bowl acquired from V0, V1, and V2.
For each action a training and a test sequence is available, containing an average of 25 repetitions of the action. Furthermore, acquisitions of more structured activities – we called scenes – are included, in which the actions are performed in sequence for a final, more complex goal of action recognition in more structured activities.
The dataset is accompanied by an annotation, which comprises the segmentation of single action instances in terms of time instants in the MoCap reference frame. A function then allows mapping the time instants to the corresponding frame in the video sequences (acquired at 30 fps). In addition, functionalities to load, segment, and visualize the data are also provided.

Example of 3D+t histograms for 3 different actions. Above: sample frames to show the evolution of actions. Middle: histograms of action positions. Below: histograms of instantaneous velocities. All histograms refer to the palm joint.
3 MoCap Data Analysis
Methods for action representation from MoCap data are mostly based on the geometrical relationships among joints and their orientation in space [8], often aggregating information from different joints or body parts [7, 15]. It is worth notice that in general the amount of markers needed to succeed in a classification task strongly depends on the granularity of the action itself, and if in some cases the sparsity of the MoCap may represent a problem, in others it helps to focus on the essential yet relevant action units.
Considering the variability of the actions included in our dataset, we compose action descriptors combining different joints and their variations over time. More specifically, we represent the space-time evolution of action instances from Motion Capture data using 3D+t equally-binned histograms, collected by partitioning the volume of positions and instantaneous velocities (i.e. the displacements between two time-adjacent positions) of actions. Histograms are built using 4 out of the 6 joints available. In detail, after a visual inspection of the trajectories (see an example in Fig. 1(c)), we selected the most descriptive joints, i.e. elbow (E), wrist (W), palm (P) and index finger (I).
Following this procedure, for each action instance \(\mathbf {x}\), we collected a total of 8 vectorial descriptors, i.e. \(H_j^f(\mathbf {x})\) where \(j \in \{E, W, P, I\}\) denotes the joint, while \(f \in \{s, v\}\) represents the feature (space or velocity) used to build the histogram.
In the experiments, we will consider different histograms aggregations:
-
\(H^f(\mathbf {x}) = [H_E^f(\mathbf {x}) H_W^f(\mathbf {x}) H_P^f(\mathbf {x}) H_I^f(\mathbf {x})]\), i.e. concatenating the histograms of all joints for a certain feature. The length is 6084 for space-based histograms, and 8788 for velocity-based descriptors. These options will allow us to explore the representation capability of space and velocity features, if employed independently.
-
\(H(\mathbf {x}) = [H^s(\mathbf {x}) H^v(\mathbf {x})]\), i.e. concatenating the histograms at the previous point (final length 14872), to fully exploit the potential of the representation.
In Fig. 2 we report a visualisation of the histograms we obtained for 3 different actions, i.e. Eating, Mixing, and Rolling. It can be noticed how, despite the apparent simplicity of the representation, meaningful peculiarities of each action can be appropriately encoded.
As for the actual action classification, we trained a multi-class Support Vector Machine with a linear kernelFootnote 2, which is known to be suitable when employing histograms (see e.g. [3]).
4 Multi-view Video Analysis
The availability of pre-trained models enabled, in the last years, a diffusion and solid assessment of deep architectures for image understanding tasks. The same could not be said for the analysis of dynamic information until very recently due to lack of datasets of appropriate size. Despite the significant improvements that deep architectures provide with respect to state-of-art [5, 13], only very recent datasets made available to the research community [6] opened the possibility of fully exploring the potential of pre-trained models when applied to different temporal tasks or datasets.
Taking inspiration from the above, in order to analyse the video streams, we used learnt intermediate level features from a pre-trained neural network, and employed this learnt representation as input to a multi-class classification architecture. To learn the representation we consider a variant of the Inception 3D or I3D model [1], derived from the InceptionV1 [12]. It is a two-stream Inflated 3D ConvNets model, originally including two streams, RGB and Optical flow, jointly combined with a late fusion model. Conversely, we use only the flow stream of the network, also less prone to overfitting. The model is pre-trained on ImageNet dataset [4] and on Kinetics-400 [6]. Once trained, the network may be seen as a multi- resolution representation of image sequences.
Figure 3 summarizes the actual network we incorporate in our work, including both the feature extractor derived from the pre-trained I3D network and the classifier. For a given multi-class classification task, segmented video clips of the actions are used as inputs to the recognition pipeline. From them, the optical flow is extracted, using the TV-L1 algorithm [14], and fed to the trained Inception 3D model, from which we derive the activations of learnt intermediate spatio-temporal features (a matrix of size {8,7,7,832}). The point of extraction of the features was found empirically as one tolerant to changes in the specific classification dataset.
As for the classifier, we considered the Single Layered Perceptron (SLP), a single fully connected neural network layer, without non-linear activation. The features learnt from the optical flow are flattened, and after a random dropout they are fed into the SLP layer, followed by a batch normalization layer, to promote regularization of the solution.

SpatioTemporal 3D Convolutional Neural Network derived by using a section of the Inception 3D [1] as a feature extractor followed by a flattening layer and a single fully connected layer as a classifier. Batch Normalization and Dropout layers are not shown.
5 Experimental Evaluations
In this section we thoroughly discuss the experiments we performed on the MoCA dataset. The analysis has the potential of being a baseline for the dataset, but at the same time allows us to unfold the effects of data sources and their nature on the classification results.

Confusion matrices corresponding to the classifiers. Left column: MoCap data considering, from top, space only, velocity only, and the combination of the two. Right column: video data using, from top, View 0, View 1, or View 2.
5.1 Cooking Actions Recognition: An Assessment
We start the discussion on the experimental analysis by reporting the results we obtained on the recognition tasks of visual data streams with each stream describing repetitions of the same action (i.e. using the test sequence acquired similarly to the training, where the volunteer repeats a certain action for, on average, 25 times, see Sect. 2). In both the classification pipelines (i.e. based on MoCap and video data) the models are learnt on the training sequences and evaluated on the test sequences. As for the SVMs, parameters have been selected with K-fold Cross Validation (K = 5) coupled with a grid-search approach.
We report in Table 2 the average classification accuracies and standard deviations obtained for different combinations of the MoCap histograms, and for the different views for the video data. As expected, the MoCap data, when fully exploited, leads to the best results, slightly superior but comparable to the performance obtained with the videos, which are influenced by the viewpoint. As a reference, we mention that a state-of-art method for action recognition from skeleton data [9], based on the aggregation of displacement vectors describing the joints configuration over time, provides an accuracy of 0.98.
A closer look to the accuracies of each action reveals uneven performances. To comment on this, we report in Fig. 4 the confusion matrices for all the cases we considered. At first glance, it is easy to confirm what was already argued from the accuracy in the table, i.e. the confusion matrices for the classification of videos, regardless the specific viewpoint, and for the MoCap data when the full descriptor is employed, are very close to being diagonal. Meanwhile, the remaining two cases, especially the one corresponding to the use of velocity only, display a higher variance of the results. In fact, in the majority of cases the performance of the full descriptor is higher than both spatial and velocity based representations, or comparable to the best of the two. The remaining failures can be attributed to the simplicity of the classifier. A deeper investigation on the misclassified examples also reveal that the misclassified actions are different when looking at the space or at the velocity, as expected. As for the videos, in case of all viewpoints, two actions, i.e. Beating Eggs and Mincing with a mezzaluna tend to be misclassified most often.
Comparing the performance of the two classification pipelines, we observe that videos, carrying richer and more redundant information, perform better on more structured and complex actions, like Cutting the bread and Salting, where the skeleton data are too poor. On the other hand, if an action is too simple – meaning its dynamic is not enough informative – as in the case of Reaching, the MoCap fails to convey the appropriate amount of information, while the videos compensate with the appearance the lack in dynamic evidences. In case the action is characterized by a high frequency or is spatially circumscribed, as Beating eggs, the video data provides noisier representations, thus the sparser but precise measures of the MoCap perform better.
5.2 Classifying Action Sequences
As observed in the previous section, the regularity of the movements that the volunteer attains when performing repeatedly the very same task favours the overall uniformity of the replicas, thus facilitating the classification despite the apparent diversity of action complexity. Conversely, the execution of an action when part of a mixed sequence – i.e. when appearing as an element of a more structured activity – is highly influenced by the context, the other movements occurring in the sequence, and their goal. To quantitatively assess such complexity, we consider the sequences of the MoCA dataset we called scenes, in which the actor simulates the preparation of a meal in a more natural way, and apply the same trained models we adopted in the previous experiments. Table 3 reports a brief description of the activity represented with the scene sequences, the number of actions and the accuracies obtained using the MoCap data with full descriptor, and the 3 video sequences. A dramatic gap with respect to the results obtained on actions repetitions can be observed, proving the strong influence of the contextual actions on the classification of each sub-part.
We propose in Table 4 a closer look to the actions involved in the scenes, reporting the number of instances and how many of them have been correctly classified. In a further column we highlight the number of samples for which the classification of the corresponding video clips was deterred due to the short length of the segmented clips, lower than the minimum required by the model.
Two main observations are in order. The first refers to the fact the complexity of the scenes does not influence a particular type of actions – e.g. repetitive or sporadic actions – but rather affects the classification task in general. Actions like Reaching and Transporting an object are certainly characterised by a high variability in space – depending on the starting and ending point of an action – and in velocity, influenced by the weight of the specific object to be moved. The latter aspect affects more in general the manipulation of objects, a type of action that in the scenes has been in some cases instantiated slightly differently than in the training and test sequence (e.g. in the action grating a piece of cheese is used instead of a carrot). It is interesting to note that when attenuating the complexity of the classification task the performance are only partially influenced. To this purpose, we evaluated the classification results considering a lower number of actions classes – more specifically considering only the ones actually present in one of the scenes: while the accuracy of the MoCap increases to the 0.70, the videos presents, on average, an accuracy of 0.25. This clearly shows that the problem of the scene classification is inherently complex.
A second main observation is related to the fact the two sources of data show complementary abilities, in the sense that when an action instance is recognised this happens with just one of the two. This suggests that a multimodal approach may be beneficial to solve ambiguities.
6 Discussion
In this work we discussed the action classification performance obtained with a baseline assessment of the MoCA dataset, a multimodal synchronised dataset including Motion Capture data and multi-view video sequences of upper body actions in a cooking scenario. We instantiated two classification pipelines to manipulate the two data modalities. For the MoCap, we employed 3D+t histograms modelling the space-time evolution of an action, classified using a classical Support Vector Machine with a linear kernel. As for the videos, we learned the representation using a variant of the Inception 3D model, followed by a Single Layer Perceptron as a classifier. We experimentally evaluated the classification on streams of visual data describing regular repetitions of the same action, or when actions are part of a more complex and structured activity where actions influence each other. The critical discussion on the results we obtained highlighted the diversity of MoCap and video data at work, showing they provide equally relevant and complementary abilities to characterize actions. Our future efforts on the dataset will be aimed at exploiting this complementarity with inherently multi-modal action representations.
Notes
- 1.
The dataset is available for download at https://github.com/nicolettanoceti/CookingDataset.
- 2.
We employed the LinearSVC implementation available in Python.
References
Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: CVPR 2017, pp. 4724–4733 (2017)
Cheng, G., Wan, Y., Saudagar, A.N., Namuduri, K., Buckles, B.P.: Advances in human action recognition: a survey. arXiv preprint arXiv:1501.05964 (2015)
Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In: CVPR 2005, vol. 1, pp. 886–893. IEEE Computer Society (2005)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: a large-scale hierarchical image database. In: CVPR 2009, pp. 248–255. IEEE (2009)
Herath, S., Harandi, M., Porikli, F.: Going deeper into action recognition: a survey. Image Vis. Comput. 60, 4–21 (2017)
Kay, W., et al.: The kinetics human action video dataset. arXiv preprint arXiv:1705.06950 (2017)
Kulić, D., Takano, W., Nakamura, Y.: Incremental learning, clustering and hierarchy formation of whole body motion patterns using adaptive hidden markov chains. Int. J. Robot. Res. 27(7), 761–784 (2008)
Lillo, I., Carlos Niebles, J., Soto, A.: A hierarchical pose-based approach to complex action understanding using dictionaries of actionlets and motion poselets. In: CVPR 2016, pp. 1981–1990 (2016)
Luvizon, D.C., Tabia, H., Picard, D.: Learning features combination for human action recognition from skeleton sequences. Pattern Recogn. Lett. 99, 13–20 (2017)
Malafronte, D., Goyal, G., Vignolo, A., Odone, F., Noceti, N.: Investigating the use of space-time primitives to understand human movements. In: Battiato, S., Gallo, G., Schettini, R., Stanco, F. (eds.) ICIAP 2017. LNCS, vol. 10484, pp. 40–50. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-68560-1_4
Poppe, R.: A survey on vision-based human action recognition. Image Vis. Comput. 28(6), 976–990 (2010)
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the inception architecture for computer vision, pp. 2818–2826 (2016)
Tran, D., Bourdev, L., Fergus, R., Torresani, L., Paluri, M.: Learning spatiotemporal features with 3D convolutional networks. In: ICCV 2015, pp. 4489–4497 (2015)
Zach, C., Pock, T., Bischof, H.: A duality based approach for realtime TV-L1 optical flow. In: Hamprecht, F.A., Schnörr, C., Jähne, B. (eds.) DAGM 2007. LNCS, vol. 4713, pp. 214–223. Springer, Heidelberg (2007). https://doi.org/10.1007/978-3-540-74936-3_22
Zinnen, A., Blanke, U., Schiele, B.: An analysis of sensor-oriented vs. model-based activity recognition. In: 2009 International Symposium on Wearable Computers, pp. 93–100. IEEE (2009)
Acknowledgements
The authors would like to express their gratitude to Alessandra Sciutti, Francesco Rea and Alessia Vignolo, for their help in acquiring the dataset and the helpful discussions over the entire course of this research.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Nicora, E., Goyal, G., Noceti, N., Odone, F. (2019). The Effects of Data Sources: A Baseline Evaluation of the MoCA Dataset. In: Ricci, E., Rota Bulò, S., Snoek, C., Lanz, O., Messelodi, S., Sebe, N. (eds) Image Analysis and Processing – ICIAP 2019. ICIAP 2019. Lecture Notes in Computer Science(), vol 11751. Springer, Cham. https://doi.org/10.1007/978-3-030-30642-7_49
Download citation
DOI: https://doi.org/10.1007/978-3-030-30642-7_49
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-30641-0
Online ISBN: 978-3-030-30642-7
eBook Packages: Computer ScienceComputer Science (R0)
