
Abstract
In this paper, we propose using a convolutional neural network (CNN) in the recognition of Arabic handwritten literal amounts. Deep convolutional neural networks have achieved an excellent performance in various computer vision and document recognition tasks, and have received increased attention in the few last years. The domain of handwriting in the Arabic script specially poses a different type of technical challenges. In this work we focus on the recognition of handwritten Arabic literal amount with a limited lexicon. Our experimental results demonstrate the high performance of the proposed CNN recognition system compared to traditional methods.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


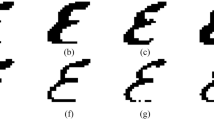
Keywords
- Deep learning
- Convolutional neural network
- Literal amount recognition
- Arabic handwriting recognition
- Arabic word recognition
1 Introduction
Machine simulation of human functions has been a very challenging research field. Human reading is one of the most important subjects of this field which has become an intensive research area. Document recognition still presents several challenges to the researchers, especially the recognition of Arabic handwriting. It is important not only for Arabic speaking countries who represent over than seven billion people all over the world, but also for some non-Arabic speaking countries, such as Farsi, Curds, Persians, and Urdu-speakers who use the Arabic characters in writing although the pronunciation is different. Arabic handwriting recognition has an importance in many applications, such as office automation, cheque verification, students’ grade reports, and several data entry applications.
There has been less research in the recognition of Arabic handwritten texts compared to the recognition of texts in other scripts, such as Latin, Chinese and Japanese text. The domain of handwriting recognition in the Arabic script presents many technical challenges and obstacles due to its special characteristics, structure and variability in writing styles, where the Arabic script is written from right to left in a cursive way. The shape of an Arabic character depends on its position in the word so it is context sensitive and this makes every letter takes up to four different shapes: isolated, at the beginning, in the middle, and at the end. Also some of the Arabic letters have dots associated with them. These diacritical dots can be located above or below the character but not the two simultaneously. Also, the same character may appear differently in its various forms. Moreover, the great similarity between some of the handwritten characters makes the classification of these characters more difficult.
In this work, we focus on Arabic handwritten literal amount recognition. The special and complex nature of the Arabic handwriting adds to the difficulty of this problem. Practically speaking, Arabic literal amount recognition is the least addressed task in Arabic handwritten recognition. It has larger vocabulary than its counterpart problems in other languages, and it has larger amount of variations in writing similar amounts due to complex grammatical rules of Arabic language. Table 1 shows the 50 word classes in the vocabulary of the problem under consideration in this paper. The table gives a real sample of each word class and its closest meaning in English.
The problem of handwritten recognition can be generally solved using one of two different approaches: the first is a traditional handcrafted approach that depends on hand-designed features applied to a classifier or a combination of classifiers (as in the classical approach to machine learning). The second approach is based on deep learning. Deep learning is a new application of machine learning for learning representation of data and models hierarchical abstractions in input data with the help of multiple layers. Deep learning techniques have achieved an excellent performance in computer vision, image recognition, speech recognition and natural language processing, and has acquired a reputation for solving many computer vision problems. Its application to the field of handwriting recognition has been shown to provide significantly better results than traditional methods.
In this work, we propose a new solution for Arabic handwritten literal amount recognition using deep learning techniques. To the best of our knowledge, there are no reported methods in the literature on applying deep learning to Arabic handwritten literal amounts recognition; all existing methods are based on the classical, hand-crafted features approach. As such, our contribution is that the relevant features are learned by a CNN, which leads to significantly better recognition results. In the context of Arabic handwritten character and digit recognition, there are a number of works based on convolutional neural network and deep learning [1, 2, 3]. These works deal with the individual characters not the whole word as we do in our work here, which makes our problem more challenging.
The organization of the paper is as follows. Section 2 presents an overview and related work, In Sect. 3 we present the proposed deep learning approach. Section 4 discusses the experimental results and analysis. Section 5 provides conclusions and future work.
2 Related Work
A number of papers have been done in the field of Arabic handwritten recognition in general and Arabic handwritten literal amount recognition in particular. The notable ones are mentioned below.
Farah et al. [6,7,8] introduce a number of different works in the field of Arabic handwritten word and literal amount recognition using perceptual high-level features and structural holistic classifier employing holistic features and decision fusion and contextual information. Younis [3] presents a deep neural network for the handwritten Arabic character recognition problem that uses convolutional neural network (CNN) models. They apply the Deep CNN for the AIA9k and the AHDB databases. El-Sawy et al. [2] present a deep learning technique that is applied to recognizing Arabic handwritten digits. Mudhsh and Almodfer [4] present a system for Arabic handwritten alphanumeric character recognition using a very deep neural network. He proposes alphanumeric VGG net for Arabic handwritten alphanumeric character recognition. Alphanumeric VGG net is constructed by thirteen convolutional layers, two max-pooling layers, and three fully-connected layers.
In our previous work [5], we have developed a system for recognition of Arabic handwritten literal amounts depending on the extraction of the structural holistic features from the handwritten literal. In our classification system we used four different classifiers. The results of these classifiers are taken independently. We have tested our system using the standard Arabic Handwritten Database AHDB [9].
3 Proposed CNN Structure
Our proposed deep learning approach to this problem is based on convolutional neural networks (CNNs). The proposed CNN structure, see Fig. 1, consists of seventeen- layer network, beginning with an image input layer of size 60 by 80 by 1 for height, width, and the channel size, which represents the gray-scale image of the input. After that comes the convolutional layers, and in between exist the batch normalization layer, ReLU layer and max pooling layer, respectively. The first convolutional layer has 8 filters of size 3 × 3. The second consists of 16 filters of size 3 × 3. The third convolutional layer has 32 filters of size 3 × 3. The batch normalization layer is responsible for normalizing the activations and gradients propagating through the network making network training easier. The max pooling layer has a size of 2 × 2 and stride of 2. The last three layers are a fully connected layer, a softmax layer and the classification layer. The fully connected layer combines all the features learned by the previous layers to identify the input patterns. Its output size parameter is set to the number of classes in the target data, which is 50 corresponding to the 50 classes. The softmax layer normalizes the output of the fully connected layer producing positive numbers that sum to one, which can then be used as classification probabilities by the classification layer. The final classification layer uses these probabilities for each input to assign the input to one of the mutually exclusive classes and compute the loss. The proposed CNN is implemented in MatlabR2018a deep learning toolbox.

Proposed structure for our CNN network.
4 Experimental Results and Analysis
In this section, we report the results obtained by applying our proposed recognition system. The AHDB [9] standard dataset is used (see the samples in Fig. 1). It consists of 50 different Arabic literal amounts (classes) which have been written by 100 different writers. It includes 4971 samples with 100 samples for every class, except the class of the word “gher” which has only 71 samples. 80% samples are chosen in random for training, and the remaining 20% are used as an independent test set. This random division of training and test samples is made in equal manner for each class to keep the class balance of the data. Network training is implemented using the Matlab deep learning toolbox. The training function used has several training options. We begin training the network with all default training options, getting an accuracy of 82.7%. We note that there is some significant overfitting, and this was rather expected due to the relatively small number of the used dataset samples. In our trials, we have tuned the training hyperparameters in order to increase the network accuracy and decrease overfitting. For example, when we increase the L2 regularization to 0.1, while fixing the rest of the hyperparameters, the test accuracy increases to 90.04%. Then setting the values for the learning rate drop factor and the learning rate drop period to 0.8 and 20, respectively, an accuracy of 92.56% is now obtained at the same L2 regularization of 0.1. We have also experimented with several values of the L2 regularization parameter: 0.09, 0.06, 0.04, and obtained the respective accuracies of 91.75%, 91.55%, and 93.96%. Then we set the L2 regularization to 0.05, and at this point the accuracy becomes 94.87%. All the previous trials were for 50 epochs of training. When we increase the number of epochs to 100, 300, and 500 (without making any changes to the other parameters), the test accuracies become 95.67%, 95.98%, and 96.58%, respectively. We also note that reducing the number or the size of filters in the network convolutional layers at the same training parameters results in a decrease in the test accuracy. As such, the best result of test accuracy was 96.58% as shown in the curves in Fig. 2.

Training/test curves of the proposed CNN as implemented in Matlab 2018 deep learning toolbox. Blue curve indicates accuracy on training set, while black curve indicates accuracy on the independent test set as training progresses. (Color figure online)
Through the analysis of the obtained results of our proposed system, we draw several remarks. There are twenty five classes of the total fifty class having a recognition result of 100%. Despite of the difficulty of some of the samples of these classes, they are correctly classified. Also there are 34 samples from different classes of total 994 test samples are misclassified, see the individual recognition rates of these classes in Table 2. See Fig. 3 for samples that are challenging, yet well-classified by our proposed CNN.

Some examples of challenging test samples, yet well classified by the proposed CNN.
There are some factors that have affected the results we have obtained. For example, some samples in the database are badly and poorly written, see the samples in Fig. 4. This may result in errors in the recognition. The results are expected to improve if more examples are used for network training. However, the data we used was the only public-domain dataset that was available to us. So we try to overcome this problem and increase the number of training samples by creating new training data from the original training data using data augmentation. We apply two augmentation methods based on random rotations and translations to our training dataset. Then the augmented data is used to train our CNN at the same hyperparameters we eventually used before. On testing the trained network with the same test data, the accuracy is expectedly increased to 97.8% (see Fig. 5).

Some test samples that were misclassified by the proposed CNN.

Training/test curves of the proposed CNN using augmented dataset as implemented in Matlab 2018 deep learning toolbox. Blue curve indicates accuracy on training set, while black curve indicates accuracy on the independent test set as training progresses. (Color figure online)
We also compare our proposed method to other existing methods based on the classical non-deep learning methods (see Table 3) as applied to the same training and test datasets. All the other classifiers have hand-crafted features, for details please refer to [5]. Clearly the proposed deep CNN has significantly better results.
5 Conclusions
In this paper we have presented a deep CNN network for the recognition of Arabic handwritten literal amounts. In spite of the practical importance of this problem, to the best of our knowledge, this paper is the first to address this problem using a deep learning approach. Our experimental results have demonstrated a solid and high performance of 97.8%, when compared to the previous results of classical methods employing hand-crafted features. Our future work is directed to increasing the size of the available data. Since the database we used was the only public-domain dataset that was available to us, we intend to collect our own data to increase the data size for better CNN training and testing.
References
Alani, A.A.: Arabic handwritten digit recognition based on restricted Boltzmann machine and convolutional neural networks. MDPI Inf. 8(4), 142 (2017)
El-Sawy, A., Loey, M., El-Bakry, H.: Arabic handwritten characters recognition using convolutional neural network. WSEAS Trans. Comput. Res. 5(1), 11–19 (2017)
Younis, K.S.: Arabic handwritten character recognition based on deep convolutional neural networks. Jordan J. Comput. Inf. Technol. (JJCIT) 3(3), 186–200 (2017)
Mudhsh, M.A., Almodfer, R.: Arabic handwritten alphanumeric character recognition using very deep neural network. MDBI Inf. 8(3), 105 (2017)
El-Melegy, M.T., Abdelbaset, A.A.: Global features for offline recognition of handwritten Arabic literal amounts. In: ITI 5th International Conference on Information and Communications Technology, December 2007
Azizi, N., Farah, N., Khadir, M.T., Sellami, M.: Arabic handwritten word recognition using classifiers selection and features extraction/selection. In: Recent Advances in Intelligent Information Systems, pp. 735–742 (2009). ISBN 978-83-60434-59-8
Farah, N., Meslati, L.S., Sellami, M.: Classifiers combination and syntax analysis for Arabic literal amount recognition. Eng. Appl. Artif. Intell. 19(1), 29–39 (2006)
Farah, N., Meslati, L.S., Sellami, M.: Decision fusion and contextual information for Arabic words recognition for computing and informatics. Comput. Inform. 24, 463–479 (2005)
Al-Ma’adeed, S., Elliman, D., Higgins, C.A.: A data base for Arabic handwritten text recognition research. Int. Arab J. Inf. Technol. 1(1), 117–121 (2004)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
El-Melegy, M., Abdelbaset, A., Abdel-Hakim, A., El-Sayed, G. (2019). Recognition of Arabic Handwritten Literal Amounts Using Deep Convolutional Neural Networks. In: Morales, A., Fierrez, J., Sánchez, J., Ribeiro, B. (eds) Pattern Recognition and Image Analysis. IbPRIA 2019. Lecture Notes in Computer Science(), vol 11868. Springer, Cham. https://doi.org/10.1007/978-3-030-31321-0_15
Download citation
DOI: https://doi.org/10.1007/978-3-030-31321-0_15
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-31320-3
Online ISBN: 978-3-030-31321-0
eBook Packages: Computer ScienceComputer Science (R0)
