
Abstract
Recently many efforts have been made to understand the scenes in images. The interactions between human and objects are usually of great significance to scene understanding. In this paper, we focus on the task of detecting human-object interactions (HOI), which is to detect triplets \(<\!human, verb, object\!>\) in challenging daily images. We propose a novel model which introduces a semantic stream and a new form of loss function. Our intuition is that the semantic information of object classes is beneficial to HOI detection. Semantic information is extracted by embedding the category information of objects with pre-trained BERT model. On the other hand, we find that the HOI task suffers severely from extreme imbalance between positive and negative samples. We propose a weighted focal loss (WFL) to tackle this problem. The results show that our method achieves a gain of 5% compared with our baseline.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In the task of general object detection, many efficient frameworks and novel methods have been proposed in recent years. Most previous detection work focused on object instances individually, while the latest researches further considered the relationships between objects. For scene understanding and world cognition, machine vision is expected to learn to mine and establish the connections between objects. Moreover, the interaction between human and objects is a kind of relationship, which contains more effective information and is of more significance in practice.
As a subtask of visual relationship detection, human-object interactions (HOI) aims to detect all interaction triplets \(<\! human, verb, object\!>\). The HOI detection task attempts to bridge the gap between object detection and image understanding. Besides, it also makes sense to other high-level vision tasks, such as image captioning [1, 2] and visual question answering (VQA) [3], etc.
In this paper, we introduce a semantic stream and propose a weighted focal loss to assist in the detection of human-object interactions. Our core idea is that the semantic information embedded in the category labels of objects is of great benefit to HOI detection. On the other hand, we find that HOI task suffers from extreme imbalance between positive and negative samples. Therefore, we put forward a weighted focal loss based on focal loss in [4] to tackle this problem.
We validate the effectiveness of our model on Verbs in COCO (V-COCO) dataset [5]. Our results show that both semantic stream and weighted focal loss contribute a lot to the task, and our model achieves a gain of 5% compared to the baseline iCAN [6].
2 Related Work
Object Detection. Both one-stage [7, 8] and two-stage [9,10,11] object detection frameworks have improved by a wide margin in the last few years. Faster R-CNN, a typical representative of two-stage object detection, utilizes Region Proposal Network and ROI pooling operation to improve the efficiency and accuracy of object detection. In our work, Faster R-CNN framework is used to detect persons and objects in images. With these detected bounding boxes, human-object interactions can be inferred for each pair of person and object instances.
Visual Relationship Detection. Recently, a series of work has focused on the detection of visual relationships [12,13,14]. Visual relationship detection aims to detect objects and the relationships between these objects simultaneously. The relationships include spatial relationships, preposition terms, verbs and actions. Nevertheless, limited data samples and large numbers of relationship types lead to the difficulty of the task. Therefore, some methods were proposed to use language priors to assist in the detection of visual relationships, which is instructive for our work. In comparison to visual relationship detection, our task merely concentrates on the interactions between human and objects. The interactions between human and objects are more fine-grained, therefore resulting in new challenges.
Human-Object Interactions. Human-object interactions are similar to visual relationships, but face the challenge of more specific interaction types (e.g., hold, carry, cut, hit). This challenge demands a more intrinsic understanding of the image.
Recently, many papers have put forward rather effective methods to tackle this problem. Chao et al. [15] believed that spatial locations between human and objects are of great help to the detection of human-object interactions. A CNN-based interaction pattern was proposed to extract the spatial features between these two bounding boxes. Gkioxari et al. [16] introduced an action-specific density map to predict the locations of target objects. Then an interaction branch was proposed to predict the score for each action based on human and object appearances. Gao et al. [6] put forward an instance-level attention module to learn the contextual information around persons and objects.
Based on these progresses in the HOI detection, our work focuses on different aspects. Since the HOI detection evaluation does not require the correct classification of object categories, most work does not take the category information of objects into account. However, it is evident that the category information of objects is beneficial for the HOI detection. In addition, each pair of human and objects needs to be considered in the HOI task. However, most human-object pairs are not interactive at all. There are only one or two interactions among 26 interactions in the interactive pairs of a single image. Therefore, we are confronted with a problem of extreme imbalance between positive and negative samples. To solve above problems, we use semantic word embedding to utilize the category information and a weighted focal loss to tackle the imbalance.
3 Method
3.1 Algorithm Overview
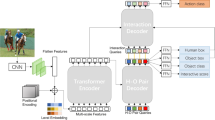
To detect a human-object interaction, all the persons and objects in the image have to be detected firstly (denoted as \(b_h\) and \(b_o\) respectively). In this work, we choose Faster R-CNN to carry out object detection. Then the interactions between human and objects will be identified through the semantic stream, the visual stream and the spatial stream.

Results of human-object interaction. Given an input image, our method detects the human and object instances and the interactions between them.
Training. Since each person can perform several interactions with an object, human-object interaction detection is a multi-label classification task. For instance, a person can ‘hold’ and ‘hit’ a baseball bat simultaneously. Therefore, we have to predict the interaction score \(s^a\) for each interaction by applying binary sigmoid classifiers. Accordingly, binary sigmoid cross-entropy is applied in this task.
Inference. Different from training, the object detection outputs a confidence score for all human and object bounding boxes (denoted as \(s_h\) and \(s_o\) respectively) during inference. Besides, the interaction score predicted by our algorithm is denoted as \(s^a\). Consequently, the final HOI score \(S^a_{h,o}\) for human-object pair \((b_h, b_o)\) is represented as:
For those interaction categories that are irrelevant to objects (e.g., walk, run, smile), the form of the final HOI score is updated as:

Overview of semantic inference network. Our proposed model mainly consists of three streams: (1) a semantic stream utilizing semantic information embedded in categories of objects. (2) a visual stream that extract visual appearance of human and objects. (3) a spatial stream to encode the spatial relationship between human and object bounding boxes. Then the features from three streams are fused together to make final predictions.
3.2 Semantic Stream
It is clear that the category information of objects can assist in the detection of human-object interactions. For example, a person can ‘eat’ bananas but cannot ‘ride’ bananas. On the other hand, different categories of objects may share similar semantic meanings, thus resulting in similar preference of interactions. For example, bananas and apples are both likely to link with the interaction ‘eat’.
However, the implicit semantic information is hard to discover solely based on visual appearance. In order to solve this problem, a semantic stream was introduced to utilize the category information of objects. More specifically, the pre-trained BERT model, which has an excellent performance in the field of natural language processing (NLP), was used to embed the category information. The 768-D feature vectors generated by the BERT are followed by a fully connected layer to get the feature encodings \(f_{Se}\) of human and objects. Due to the excellence of BERT model, we can explore the implicit semantic information between similar categories of objects. The utilization of semantic knowledge will contribute a lot to the ultimate performance of our model.
3.3 Visual Stream
For visual stream, a human module and a object module are used to extract visual appearance features separately. In this work, we choose ResNet-50 as our backbone, and the RoI pooled features are further fed into a global average pooling layer to get the visual appearance features. Furthermore, the contextual information around human and object bounding boxes is of great help as well. Both the human module and the object module are iCAN modules in [6], which performs instance-level channel attention and position attention to extract the contextual visual features. Consequently, the contextual features are concatenated with the original visual appearance features to generate the final visual features \(f_H\) and \(f_O\).
3.4 Spatial Stream
Even though the semantic stream can utilize semantic information and the visual stream can provide abundant visual appearance information to predict interactions, CNN faces the problem of translation invariance. That is to say, it is hard for CNN to learn the spatial relationships between persons and objects. Nevertheless, it is evident that the relative position is beneficial for the HOI detection.
The interaction pattern in [15] is used to encode the spatial relationship in our model, which is represented by a two-channel binary image. As only the spatial relationship are focused, pixel values are neglected to exploit information of bounding box locations. More specifically, the first channel has value 1 where the pixel is inside the human bounding box and value 0 elsewhere, while the second channel has value 1 where the pixel is inside the object bounding box and value 0 elsewhere. Then, a 2-layer CNN is applied to extract spatial features \(f_{Sp}\), which are further fused with another two streams to constitute the final features.
3.5 Weighted Focal Loss
Since the above three streams extract different aspects of information, the above features generated by each stream are concatenated to obtain a better prediction performance. As stated in Sect. 3.1, our task is a multi-label classification problem. Given a human-object pair, binary sigmoid classifiers predict the score of every interaction category. The interaction is considered positive if the score exceeds the threshold.
In general, there are several persons and objects in an image. Each bounding box of person and object forms a human-object pair. Then, it needs to predict the interaction scores for all human-object pairs. However, most human-object pairs do not interact at all. In addition, even in those interactive samples, only one or few interactions are positive among 26 categories. Therefore, the number of positive samples is much smaller than the number of negative samples. Under such circumstances, the model is actually facing the problem of extremely imbalanced samples. As there are too many negative samples, the loss of negative samples is considerably large, even though the loss of each negative sample is small. In contrast, the loss of positive samples has an insignificant effect on the total loss, which has no benefit to the convergence of the model.
In existing models, binary cross entropy (CE) is selected as the loss. The normal binary cross entropy loss can be represented as:
In formula 3, p is the score of prediction and y is the ground truth label.
Considering the imbalance problem, we use focal loss in [4] which introduces a weighted factor \(\alpha \) and a modulating factor \(\gamma \). \(\alpha \) increases the significance of minority class and decreases the significance of majority class, while \(\gamma \) reduces the loss of easy samples.
Besides, there exists some interactions that are similar with others. For example, ‘hold’ and ‘carry’ interactions are similar in semantic stream, visual stream and spatial stream. To some extent, it is hard to distinguish them. However, usually only one of these two interactions occurs in a human-object pair. It is probable that our model outputs positive predictions for both interactions when one interaction occurs, resulting in a false prediction. Besides, it is hard for the convergent model to rectify this type of hard samples, which in turn will affect the precision of major samples which have already been well-recognized. To reduce the impact of this type of false prediction, we introduce a penalty term for hard samples based on focal loss, so that the loss of these hard samples has less significance. The weighted focal loss can be represented as:
The parameters are set to \(\alpha =0.25, \gamma =2, \theta =0.8, \beta =0.5\) in our work.
4 Datasets and Evaluation Metrics
We use V-COCO (Verbs in COCO) dataset to evaluate the performance of our model. V-COCO is a subset of MS COCO that only has images with human-object interactions. There are 5400 images including 8431 person instances in the trainval set, and 4946 images including 7768 person instances in the test set. V-COCO is annotated with 26 different interactions, and each person has 2.9 interactions simultaneously on average.
There are two types of Average Precision (AP) metrics in HOI detection. The first one is the AP of the triplet \(<\! human, verb, object\!>\), which is called average role AP. A triplet is judged as true positive if: (i) the detected bounding boxes of human and objects both have the Intersection of Union (IoU) higher than 0.5 with the ground truth, and (ii) the predicted interaction is consistent with the ground truth interaction. The second evaluation metric is the AP of the pair \(<human, verb>\), which is called average agent AP. Agent AP has no demand for localizing the object.
In V-COCO, there are three different types of interactions among 26 interactions. Five interactions (point, run, stand, smile, walk) are not interacted with any objects, therefore only evaluated with agent AP. Three interactions (cut, hit, eat) are annotated with different types of objects. For instance, ‘eat’ + ‘spoon’ which includes the instrument means eat with a spoon, and ‘eat’ + ‘apple’ which includes the object means eat an apple. Other interactions are interacted with objects and annotated with one type of objects.
5 Experiments
5.1 Implementation Details
Our network was based on Faster R-CNN from Detectron [11] with a ResNet-50 backbone. The Faster R-CNN model pre-trained on ImageNet is used to detect human and objects. Only human bounding boxes with score higher than 0.8 and object bounding boxes with score higher than 0.4 are reserved for subsequent implementation.
In the semantic stream, the category information is embedded to semantic features by the BERT module, which is an excellent NLP model developed by Google. For each human-object pair, the pre-trained BERT model by [17] can output a 768-D embedding feature of human and object categories. Then a fully connected layer is applied to get a 1024-D feature \(f_{Se} \).
In the visual stream, the iCAN modules in [6] are responsible for extracting the visual appearance features. More specifically, a \(7 \times 7\) feature of human or object regions extracted by RoI pooling is fed into a global average pooling (GAP) to obtain a 2048-D feature \(f_{inst}\). Channel attention operation and position attention operation are followed to extract a 1024-D contextual visual features \(f_{context}\). Finally, the output of human/object iCAN module is the concatenation of visual appearance feature \(f_{inst}\) and contextual visual features \(f_{context}\), which can be represented as \(f_H\) and \(f_O\) respectively.
In the spatial stream, given a \(64 \times 64 \times 2\) interaction pattern, a 2-layer CNN is applied to extract a 5408-D spatial feature \(f_{Sp}\). Finally, the features from three streams are concatenated together to make the final predictions.
We train our model on V-COCO trainval set with a learning rate 0.001, a momentum of 0.9, a weight decay of 0.0005, and a 0.96 factor for reducing the learning rate. It takes 14 h to train on a single NVIDIA TITAN Xp and 1 h to test on V-COCO test set.
5.2 Qualitative Analysis
Our model has been tested on V-COCO dataset. The detection results of human-object interactions are displayed in Figs. 3 and 4. Different colors represent different bounding boxes of human and objects. The color of the interaction results represents which bounding box is interacted with. Figure 3 shows that our network can detect \(<\!human, verb, object\!>\) triplets in a wide range of scenes. Figure 4 shows that multiple interactions between human and objects can be detected correctly at the same time.

Results of HOI detections in simple scenes. Our model can detect human-object interactions in a wide range of scenes. (Color figure online)

Results of HOI detections in complex scenes. Our model can detect multiple human-object interactions simultaneously. (Color figure online)
5.3 Quantitative Analysis
As stated in Sect. 4, we mainly use \(\mathrm AP_{agent}\) and \(\mathrm AP_{role}\) to evaluate our model. Our model is based on iCAN [6] and our reimplementation result is shown in Table 1. It has an \(\mathrm AP_{agent}\) of 65.32 and \(\mathrm AP_{role}\) of 44.67. By utilizing semantic information and weighted focal loss, our model makes an improvement of 1.59 points in \(\mathrm AP_{agent}\) and 2.13 points in \(\mathrm AP_{role}\). As \(\mathrm AP_{role}\) is the more concerned target, it can be observed that our method gains an improvement of 5% relatively.
It can be observed from the experimental results that the categories with significant decline are ‘sit’ and ‘eat’, while the categories with significant improvement are ‘hold’, ‘look’, ‘ski’, ‘drink’ and ‘read’, where a float more than 5% is considered to be a significant change. The decline of ‘sit’ suggests that our network is more concerned with obvious interactions of limbs, and the bounding box is not sufficient to provide detailed posture information. Because of the ambiguity and indistinguishability of some interactions, there can be a trade-off between ‘eat’ and other subtle actions such as ‘drink’ and ‘look’. Eventually, our model achieved performance improvements of most categories, with a relatively small cost.
5.4 Ablation Analysis
We evaluate the effectiveness of semantic stream and weighted focal loss in Tables 2 and 3.
With vs. Without Semantic Stream. We use BERT model to embed the category information into a 768-D semantic feature. Table 2 shows that utilizing semantic features contributes a lot to the performance of human-object interactions detection.
Binary Cross Entropy vs. Focal Loss vs. Weighted Focal Loss. Table 3 proves that our weighted focal loss can make progress by solving the problem of imbalanced samples and hard samples. The weighted focal loss performs better than focal loss because it reduces the loss of hard samples which might mislead our model.
6 Conclusions
In order to understand the image scenes and mine the visual relationship better, we propose Semantic Inference Network for human-object interaction detection, which implements a semantic stream to introduce the category information and a weighted focal loss to tackle the imbalance between positive and negative samples. Our method gains a boost of 5% than the baseline. The ablation experiments have validated the effectiveness of our semantic stream and weighted focal loss.
References
Li, Y., Ouyang, W., Zhou, B., Wang, K., Wang, X.: Scene graph generation from objects, phrases and region captions. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1261–1270 (2017)
Xu, D., Zhu, Y., Choy, C.B., Fei-Fei, L.: Scene graph generation by iterative message passing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5410–5419 (2017)
Anderson, P., et al.: Bottom-up and top-down attention for image captioning and visual question answering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6077–6086 (2018)
Lin, T.-Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2980–2988 (2017)
Gupta, S., Malik, J.: Visual semantic role labeling. Computer Science (2015)
Gao, C., Zou, Y., Huang, J.-B.: iCAN: instance-centric attention network for human-object interaction detection. In: British Machine Vision Conference (2018)
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: unified, real-time object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 779–788 (2016)
Liu, W., et al.: SSD: single shot multibox detector. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9905, pp. 21–37. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46448-0_2
Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: towards real-time object detection with region proposal networks. In: Advances in Neural Information Processing Systems, pp. 91–99 (2015)
He, K., Gkioxari, G., Dollár, P., Girshick, P.: Mask R-CNN. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2961–2969 (2017)
Girshick, R., Radosavovic, I., Dollár, P., He, K., Gkioxari, G.: Detectron (2018)
Dai, B., Zhang, Y., Lin, D.: Detecting visual relationships with deep relational networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3076–3086 (2017)
Zhuang, B., Liu, L., Shen, C., Reid, C.: Towards context-aware interaction recognition for visual relationship detection. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 589–598 (2017)
Liang, K., Guo, Y., Chang, H., Chen, X.: Visual relationship detection with deep structural ranking. In: Thirty-Second AAAI Conference on Artificial Intelligence (2018)
Chao, Y.W., Liu, Y., Liu, Y., Zeng, H., Deng, J.: Learning to detect human-object interactions. In: 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 381–389. IEEE (2018)
Gkioxari, G., Girshick, R., Dollár, P., He, K.: Detecting and recognizing human-object interactions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8359–8367 (2018)
Xiao, H.: Bert-as-service (2018). https://github.com/hanxiao/bert-as-service
Acknowledgement
This research is supported by The National Key Basic Research and Development Program of China (No. 2016YFB0100900) and National Natural Science Foundation of China (No. 61773231).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Liu, H., Mo, L., Ma, H. (2019). Semantic Inference Network for Human-Object Interaction Detection. In: Zhao, Y., Barnes, N., Chen, B., Westermann, R., Kong, X., Lin, C. (eds) Image and Graphics. ICIG 2019. Lecture Notes in Computer Science(), vol 11901. Springer, Cham. https://doi.org/10.1007/978-3-030-34120-6_42
Download citation
DOI: https://doi.org/10.1007/978-3-030-34120-6_42
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-34119-0
Online ISBN: 978-3-030-34120-6
eBook Packages: Computer ScienceComputer Science (R0)
