
Abstract
Image classification has become an important area of research in remote sensing. In this paper, the algorithms Artificial Neural Network (ANN) and Extreme Gradient Boosting (XGBoost) are used to classify compact polarimetric (CP) RISAT-1 cFRS mode data for land cover categorisation over Mumbai region. After preprocessing, Raney decomposition technique was applied to obtain the R, G, B channels of the image. Hyperparameter tuning of ANN was also performed to get the optimal parameters for the classification. Comparative analysis showed that both the algorithms showed almost equal performance on the data in terms of accuracy. However, there was only 1% of the increment found in both the train and test the accuracy of XGBoost classifier. ANN method required tuning, and thus it requires more time for computation while XGBoost algorithm works well without any tuning and thus, XGBoost outperforms the image classification task for CP RISAT-1 data than ANN.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Recently, Compact Polarimetry (CP) is an important topic of research among researchers due to its potentiality and advantages over single, dual, as well as quad-pol data [14]. It’s wide swath coverage and half transmitted power requirement is an added advantage [21]. So far it has proven its potentiality in various applications, one among them is the land cover (LC) classification which serves as a bases to different applications such as in hydrology, disaster management, agriculture monitoring, etc. On the other hand, machine learning is a powerful and popular tool, not only in the field of computer, and data science but also in the field of remote sensing. Due to its self-learning property, it can easily handle the complexity of SAR data and help to gain more information from the imagery. In remote sensing, it is commonly used for image segmentation and classification. PolSAR image classification is generally performed using (1) statistical model [15, 25], (2) scattering mechanism [15, 24, 27], or (3) through image processing [23, 26]. Also, several studies are done using some combinations of the above three classification approaches [15, 20].
Recently, there has been an addition in machine learning techniques to classify Polarimetric data, among which many advanced classifiers based on neural network had been excellent performers [5]. The most popular among them is an artificial neural network. There are also many complex neural network architecture that has increased the classification accuracy. However, besides the improvement in the accuracy, their complexity leads to time consumption. This ultimately makes them impractical to process the entire image (huge amount of data). Therefore, an efficient classifier would be the one with high accuracy and low time consuming in the practical use.
2 Why Artificial Neural Network and XGBoost?
2.1 Artificial Neural Network
Artificial neural network is a distribution free approach to image classification [7]. Many researchers so far have proven artificial neural network to be a powerful as well as self-adaptive method of pattern recognition as compared to traditional linear models [11, 13]. From early 1990’s, artificial neural networks are being applied to analyze the remotely sensing images with promising results [1]. The advantage of using ANN is
-
1.
Its ability to learn complex functional relationships between input and output training data. It does this by employing a nonlinear response function, iterating in the network [16].
-
2.
Generalization capability in the noisy environment makes it more robust in the presence of imprecise or missing data [10].
-
3.
Ability to make use of a priori knowledge along with the realistic physical parameters for the analysis [6, 8].
Thus, ANN perform tasks more accurately than any other statistical classification techniques, particularly on the complex feature space (having different statistical distribution) [2, 22]. Comparatively, many studies have proved that ANN can classify remotely sensed data more precisely than supervised maximum likelihood classifier [3, 4, 9, 12, 19].
2.2 XGBoost (Extreme Gradient Boosting) [18]
XGBoost algorithm has become a dominating algorithm in the field of applied machine learning. It is used over other gradient boosting machines (GBMs) due to its fast execution speed and model performance. It can be run on c++, command line interface, Python, R, Julia, Java, and other JVM languages like scala. Figure 1 shows the special features of XGBoost that has improved the algorithm over other GBM frameworks.

Features in XGBoost for optimization [17]
XGBoost includes parallel computation to construct trees using all the CPUs during training. Instead of traditional stopping criteria (i.e. criterion first), it make use of ‘max_depth’ parameter, and starts tree pruning from backward direction. This significantly improves the computational performance and speed of XGBoost over other GBM frameworks. Next, it can automatically learns best missing value depending on training loss, and thus, can handle different types of sparsity patterns in the input data more efficiently. In one study [17] compared various machine learning algorithms like random forest, logistic regression, standard gradient boosting along with XGBoost algorithm and found XGBoost to be most efficient of all the algorithms used in comparison. Both the classifiers have their potential in image classification and thus, in this paper a comparative study was made on RISAT-1 data between popular ANN and XGBoost for the LC classification of PolSAR data.
3 Study Area and Data Sources
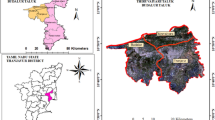
The study is focused on Mumbai and its surrounding area, in Maharashtra, India. It’s center is located at \(19^{\circ }13'14.99"N \) latitude and \(72^{\circ }55'58.03"E \) longitude. The major land features in this region are forest, mangrove forest, agriculture/fallow land, saltpans, urban, and water body. For this study, we have tried to covered all the major land cover classes for the level-1 classification of the study area and accuracy assessment of the obtained results is performed. Sensor specifications are provided in Table 1.
4 Methodology
SAR data provides high resolution images containing the scattering information, along with it is associated noise with salt and pepper texture, which may be the result of interference of transmit and receive channels during data acquisition or may be due to some sensor error. So, it is the basic requirement of any SAR imagery to be preprocessed before classification. Thus, RISAT-1 imagery was first preprocessed & converted into coherency matrix. Next refined LEE filter with 5X5 window size was used for speckle removal and then 7:10 multilook was applied to convert the pixels in square pixels. After that, coherency matrix was decomposed into three scattering mechanism double, volume and odd bounce using Raney Decomposition [21]. Using double bounce band as red, volume as green and odd as blue band, an RGB image as shown in Fig. 2 was generated and selected machine learning techniques were applied for further segmentation and classification. Both the algorithms are supervised learning algorithms and thus ground truth data is required for training. Google Earth provided detailed level-1 information of land features and is sufficient for land cover classification and thus ground truth data (total of 46392 pixels) was prepared manually from google earth based on knowledge. Figure 3 shows the google earth image overlaid with ground truth pixels taken for training and testing the algorithms. Out of 46392 sample pixels 80% (37113 pixels) were randomly selected for training and remaining 20% (9279 pixels) were kept to test the performance of both the algorithms. The train-test size was chosen based on experiment and literature survey. Ground truth data was kept common for both the algorithms and both training and testing pixels were kept non overlapping to each other. The algorithms were implemented in python using tensorflow and keras libraries and ANN was tuned to find the optimal hyperparameters for the network with respect to our study. Finally, land cover maps were prepared with six LC classes (i.e. water body, urban, forest, saltpans, fallow, and mangrove forest). There may be other classes in the image, however, for initial investigation we have considered these six classes only. The classified maps were visually compared and accuracy assessment of each class was performed.
5 Results and Discussion
5.1 Training, Testing and Algorithm Tuning
There were seven hyperparameters to train the ANN with one hidden layer. One can manually search for these parameters or can employ advanced search methods like GridSearchCV or RandomSearchCV method. In this paper we have used GridSearchCV method for tuning the network for four kernel initializers namely ‘random uniform’, ‘uniform’, ‘Orthogonal’, ‘glorot normal’; two batch sizes (128,256); two optimizers namely ‘sgd’, ‘adam’. Three activation techniques viz. ‘relu’, ‘tanh’, ‘sigmoid’ were used to check their potentiality for 100 epochs and 20 nodes (based on initial experiments) in both the input and the hidden layers. Generally, there is no thumb rule to choose number of epochs to train the classifier. The best way to choose epochs is to plot the accuracy vs epochs graph and select the saturation point for the accuracy. So we initially tested the algorithm for 50, and 100 epochs using 10-fold cross validation and through the analysis we decided to use 100 epochs for further training. Optimal parameters found through GridSearchCV is shown in Table 2. Figure 4 demonstrates one of the parameter combinations comparison obtained through GridSearchCV method. These parameters were used to train ANN.

Raney RGB (Color figure online)

Ground truth image

GridSearchCV comparing parameters with batch size 128, 100 epochs and 20 neurons
5.2 Accuracy Assessment
The models were evaluated using k-fold cross validation technique with the default ten cross validation folds. K-fold cv accuracy of XGBoost algorithm was found better than ANN and thus supports the superiority of XGBoost classifier (in terms of accuracy) than ANN on the given dataset. Accuracy of each class is shown in Fig. 5. It indicated that urban, water and fallow classes showed same number of correctly classified pixels in both the classifiers. Also, an increment in mangroves, & forest class and decrement in saltpans category was observed for XGBoost classifier. ANN achieved 91.92% of the training accuracy and 91.62% of the testing accuracy. Next the same train and test dataset were used for XGBoost. XGBoost achieved 92.25%, and 92.08% accuracy respectively. The classified images are shown in the Figs. 6 and 7. The algorithms were trained on high computational GPU then also ANN took almost 15 hrs to complete the tuning process of selected parameters through GridSearchCV method, while XGBoost algorithm took not more than 30 min to complete the entire classification process. XGBoost did not require external parameter tuning and gave almost equivalent results in terms of accuracy on the same data for ANN and thus was comparatively faster. XGBoost outperformed the comparative analysis.

Accuracy assessment

ANN

XGBoost
6 Conclusion
PolSAR image classification is a very tedious task due to the complexity associated with the data. One can make use of polarimetric features using suitable decomposition techniques to make them more interpretable, and to construct RGB image. Machine learning has good potentiality to handle the complex data and thus is very helpful in classification of PolSAR data. In the present study hybrid polarimetric SAR data RISAT-1 has been used and Raney decomposition was applied in order to generate red, green and blue channels for the image. Gdal library was used in python, to create RGB image. Two supervised machine learning algorithms were used to classify the data and their accuracy assessment has been performed. Artificial Neural Network required tuning to find the optimal parameters for classification, on the other hand XGBoost algorithm did not require any tuning. Comparison showed that XGBoost is comparatively fast (due to parallel computations using all CPU’s), and equivalently efficient algorithm than ANN and both gave more or less similar accuracy on both train and test datasets. The reason behind no requirement of XGBoost algorithm is that it takes care of the regularization parameter during the construction of the algorithm. It is an ensemble of boosting trees which works on weak classifiers. It means that it combines the output of various weak classifiers and only those classes are passed to next weak classifier which are incorrectly classified and further decision tree approach is applied on the passed inputs, this process is self repeated until all the input pixels are covered followed by majority voting. All these steps are automatically performed during the training phase and thus less tuning is needed. This makes it an ensemble of various weak classifiers(decision trees, like in random forest). The approach is similar to random forest but it uses gradient descent method to optimize the algorithm and thus it is found to be more efficient than ANN for this particular study.
References
Atkinson, P.M., Tatnall, A.: Introduction neural networks in remote sensing. Int. J. Remote Sens. 18(4), 699–709 (1997)
Benediktsson, J.A., Swain, P.H., Ersoy, O.K.: Conjugate-gradient neural networks in classification of multisource and very-high-dimensional remote sensing data. Int. J. Remote Sens. 14(15), 2883–2903 (1993)
Chiuderi, A.: Multisource and multitemporal data in land cover classification tasks: the advantage offered by neural networks. In: 1997 IEEE International Geoscience and Remote Sensing. Remote Sensing-A Scientific Vision for Sustainable Development 1997, IGARSS 1997, vol. 4, pp. 1663–1665. IEEE (1997)
Civco, D.L.: Artificial neural networks for land-cover classification and mapping. Int. J. Geogr. Inf. Sci. 7(2), 173–186 (1993)
Dong, H., Xu, X., Wang, L., Pu, F.: Gaofen-3 PolSAR image classification via XGBoost and polarimetric spatial information. Sensors 18(2), 611 (2018)
Foody, G.M.: Land cover classification by an artificial neural network with ancillary information. Int. J. Geogr. Inf. Syst. 9(5), 527–542 (1995)
Foody, G.M., McCulloch, M.B., Yates, W.B.: Classification of remotely sensed data by an artificial neural network: issues related to training data. Photogram. Eng. Remote Sens. 61(4), 391–401 (1995)
Foody, G.: Using prior knowledge in artificial neural network classification with a minimal training set. Remote Sens. 16(2), 301–312 (1995)
Gopal, S., Woodcock, C.E., Strahler, A.H.: Fuzzy neural network classification of global land cover from a 1 AVHRR data set. Remote Sens. Environ. 67(2), 230–243 (1999)
Hewitson, B.C., Crane, R.G.: Neural Nets: Applications in Geography: Applications for Geography, vol. 29. Springer, Berlin (1994). https://doi.org/10.1007/978-94-011-1122-5
Jiang, D., Yang, X., Clinton, N., Wang, N.: An artificial neural network model for estimating crop yields using remotely sensed information. Int. J. Remote Sens. 25(9), 1723–1732 (2004)
Kavzoglu, T., Mather, P.M.: Pruning artificial neural networks: an example using land cover classification of multi-sensor images. Int. J. Remote Sens. 20(14), 2787–2803 (1999)
Keiner, L.E., Yan, X.H.: A neural network model for estimating sea surface chlorophyll and sediments from thematic mapper imagery. Remote Sens. Environ. 66(2), 153–165 (1998). https://doi.org/10.1016/S0034-4257(98)00054-6. http://www.sciencedirect.com/science/article/pii/S0034425798000546
Kumar, V., Rao, Y.: Comparative analysis of RISAT-1 and simulated RADARSAT-2 hybrid polarimetric SAR data for different land features. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 8 (2014)
Lee, J.S., Grunes, M.R., Ainsworth, T.L., Du, L.J., Schuler, D.L., Cloude, S.R.: Unsupervised classification using polarimetric decomposition and the complex Wishart classifier. IEEE Trans. Geosci. Remote Sens. 37(5), 2249–2258 (1999)
Lek, S., Guégan, J.F.: Artificial neural networks as a tool in ecological modelling, an introduction. Ecol. Model. 120(2–3), 65–73 (1999)
Morde, V.: XGBoost Algorithm: Long May She Reign! https://towardsdatascience.com/https-medium-com-vishalmorde-xgboost-algorithm-long-she-may-rein-edd9f99be63d. Accessed 20 Aug 2019
Norbert: Docker-Course-XGBoost (2019). https://github.com/ParrotPrediction/docker-course-xgboost. Accessed 5 May 2019
Paola, J.D., Schowengerdt, R.A.: A detailed comparison of backpropagation neural network and maximum-likelihood classifiers for urban land use classification. IEEE Trans. Geosci. Remote Sens. 33(4), 981–996 (1995)
Pottier, E.: Unsupervised classification scheme of Polsar images based on the complex Wishart distribution and H/A/\(\alpha \) polarimetric decomposition theorems. In: Proceedings of 3rd European Conference on Synthetic Aperture Radar, EUSAR 2000 (2000)
Raney, R.K.: Hybrid-polarity SAR architecture. IEEE Trans. Geosci. Remote Sens. 45(11), 3397–3404 (2007)
Schalkoff, R.J.: Pattern Recognition. Wiley, Hoboken (1992)
Tan, C.P., Lim, K.S., Ewe, H.T.: Image processing in polarimetric SAR images using a hybrid entropy decomposition and maximum likelihood (EDML). In: 2007 5th International Symposium on Image and Signal Processing and Analysis, pp. 418–422. IEEE (2007)
Van Zyl, J.J.: Unsupervised classification of scattering behavior using radar polarimetry data. IEEE Trans. Geosci. Remote Sens. 27(1), 36–45 (1989)
Wu, Y., Ji, K., Yu, W., Su, Y.: Region-based classification of polarimetric SAR images using Wishart MRF. IEEE Geosci. Remote Sens. Lett. 5(4), 668–672 (2008)
Ye, Z., Lu, C.C.: Wavelet-based unsupervised SAR image segmentation using hidden Markov tree models. In: Object Recognition Supported by User Interaction for Service Robots, vol. 2, pp. 729–732. IEEE (2002)
Zou, T., Yang, W., Dai, D., Sun, H.: Polarimetric SAR image classification using multifeatures combination and extremely randomized clustering forests. EURASIP J. Adv. Signal Process. 2010, 4 (2010)
Acknowledgement
Authors of this paper are thankful to SAC, Ahmedabad, for providing RISAT-1 dataset for the research. The research is a part of funded project “Land-Cover Classification of Polarimetric SAR Image/Data for Agricultural and Urban Region” by SAC, Ahmedabad under the grant “EPSA/3.1.1/2017”. The authors have no conflict of interest regarding the publication of the research.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Memon, N., Patel, S.B., Patel, D.P. (2019). Comparative Analysis of Artificial Neural Network and XGBoost Algorithm for PolSAR Image Classification. In: Deka, B., Maji, P., Mitra, S., Bhattacharyya, D., Bora, P., Pal, S. (eds) Pattern Recognition and Machine Intelligence. PReMI 2019. Lecture Notes in Computer Science(), vol 11941. Springer, Cham. https://doi.org/10.1007/978-3-030-34869-4_49
Download citation
DOI: https://doi.org/10.1007/978-3-030-34869-4_49
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-34868-7
Online ISBN: 978-3-030-34869-4
eBook Packages: Computer ScienceComputer Science (R0)
