
Abstract
Learning from the non-stationary imbalanced data stream is a serious challenge to the machine learning community. There is a significant number of works addressing the issue of classifying non-stationary data stream, but most of them do not take into consideration that the real-life data streams may exhibit high and changing class imbalance ratio, which may complicate the classification task. This work attempts to connect two important, yet rarely combined, research trends in data analysis, i.e., non-stationary data stream classification and imbalanced data classification. We propose a novel framework for training base classifiers and preparing the dynamic selection dataset (DSEL) to integrate data preprocessing and dynamic ensemble selection (DES) methods for imbalanced data stream classification. The proposed approach has been evaluated on the basis of computer experiments carried out on 72 artificially generated data streams with various imbalance ratios, levels of label noise and types of concept drift. In addition, we consider six variations of preprocessing methods and four DES methods. Experimentation results showed that dynamic ensemble selection, even without the use of any data preprocessing, can outperform a naive combination of the whole pool generated with the use of preprocessing methods. Combining DES with preprocessing further improves the obtained results.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
This work is an attempt to connect two of the important research directions, i.e., data stream classification employing ensemble approach [12] as well as data analysis with imbalanced data distribution [11]. Although the real data streams may be characterized by high class imbalance ratio, which could further inhibit the classification task, there are not many state-of–art methods which take this fact into account. There are only a few works that distinguish the differences between imbalanced data stream classification problem and a scenario where the prior knowledge about the entire data set is given. This divergence is a result of the lack of knowledge about the class distribution and it is notably present in the initial stages of the data stream classification. Additionally, during designing classifiers for streaming data we have to take into consideration a few important issues, which are usually ignored by the traditional classifier learning algorithms:
-
Limited computational resources as memory and time are available.
-
Usually short time limit to make a decision for each incoming sample.
-
Possibility of concept drift appearance, i.e., changes in data distribution.
-
Impossibility or delay in data labeling.
One of the very promising directions of the stream data analysis is classifier ensemble, where a plethora of methods have been proposed, but this approach still remains the focus of intense research and its high flexibility and accuracy in many real-life decision problems brought its popularity. Nevertheless, obtaining high-quality classifier ensemble depends on addressing the most important problems on how to ensure a high diversity of the ensemble and how to produce the final decision of the pool of individual models [20].
Kuncheva analysed different approaches of applying ensemble techniques to data stream classification [13] and distinguished the following basic strategies of their adaptation to new incoming data:
-
Dynamic combiners, where base models are trained in advance, but the classifier ensemble is changing the combination rule (e.g., changing weights for weighted voting or aggregation).
-
Updating training data – recent training examples are used to online-update base classifiers (e.g. in on-line bagging or its further generalizations [2]).
-
Updating base classifiers.
-
Update the classifier ensemble line-up, e.g., by replacing the worst performing base classifiers by a new classifier trained on the newest data.
In this work we focus on the last strategy, precisely on the classifier (or classifier ensemble) selection methods. They employ the idea of overproduce-and-select, where for a given classification task we have more classifiers at our disposal than we are going to use, but for each sample being recognized the local competencies of individual models should be detected. Basically, there are two approaches:
-
Static selection, where a feature space is divided into several partitions and for each of them one classification model is assigned. The decision about the new instance is made by a classifier assigned to a partition where the example belongs to.
-
Dynamic Selection, in where the features space is not partitioned in advance, but during the classification of a given example, the competencies of each available classification model are evaluated and the final decision is made according to the most competent classifier. One of the important variation of this domain is Dynamic Ensemble Selection (DES), which is recognized as very promising direction in classifier ensemble learning [6]. DES uses the notion of competence to select the best models to classify a given test instance. Usually, the competence of a base classifier is estimated on the basis of its immediate vicinity, called the local region of competence. It is formed using a set of labeled samples from either the training or validation set, which is called the dynamic selection dataset (dsel).
This work is focusing on dynamic ensemble selection used to mitigate the difficulties related to skewed class distribution embedded in non-stationary data streams using data preprocessing approach. In a nutshell, the main contributions of this work are as follows:
-
Presentation of several strategies used for forming dynamic selection dataset (dsel), i.e., set of neighbouring examples of a recognizing sample.
-
Proposition of a novel framework for training base classifiers and preparing dsel for using the dynamic selection process during imbalanced data stream classification.
-
Experimental evaluation of the discussed approaches on the basis of diverse data streams and a detailed comparison with the state-of-art method.
2 Dynamic Ensemble Selection and Data Preprocessing
Let us shortly discuss some of the most popular and recent approaches to DES. Woloszynski and Kurzynski proposed Randomized Reference Classifier [19], which produces supports for each class that are realizations of random variables with the beta probability distributions. Lysiak et al. [15] discussed how to enhance the selection step using diversity measures. Cruz et al. proposed META-DES.Oracle [5], which employs meta-learning over multiple datasets and feature selection to improve the selection process. Zyblewski et al. [21] proposed the Minority Driven Ensemble algorithm, which employs dynamic classifier selection approach to exploit local data characteristics and combat with data imbalance.
In this paper, we consider four different DES strategies. Two of those strategies (KNOR A-Eliminate and KNORA-Union) are based on oracle information, while DES-KNN and DES-Clustering select classifiers on the basis of their local competence but they also take into consideration an ensemble diversity. Let’s briefly describe the methods we used during experiments.
-
KNORA-Eliminate (KNORA-E) [10] selects only the local oracles - classifiers which can correctly classify all samples within the local region of competence. If no classifier is selected, the size of competence region is reduced by removing the farthest neighbor,
-
KNORA-Union (KNORA-U) [10] makes the decision based on weighted voting, where the weight assigned to each base classifier equals to the number of correctly classified samples in the competence region,
-
DES-KNN [18] ranks the base models in decreasing order of accuracy and increasing order of diversity and select the most accurate and diverse ones to form the ensemble.
-
DES-Clustering [18] uses the K-means algorithm for defining the region of competence, then the most accurate and diverse classifiers ale selected for the ensemble.
As we mentioned above, this work deals with DES application to imbalanced data classification. One of the most promising direction of imbalanced data analysis is data preprocessing. Such methods focus on changing the data distribution by reducing the number of majority class objects (undersampling) or generating new minority class objects (oversampling), e.g., Random under-sampling (rus) [1] removes random instances from the majority class, while Random over-sampling (ros) replicates minority class examples. Nevertheless, theses methods have the serious disadvantages, as rus may remove biased samples, what may deteriorate the classification performance, while ros may increase the likelihood of overfitting. Therefore methods which are able to generate synthetic minority examples have been developed. Chawla et al. proposed SMOTE [4], which generates new instances from existing minority samples using its nearest neighbors. Regular SMOTE does not impose any rule in selecting existing instances. SVM SMOTE [16] uses an SVM classifier to find support vectors and generate new samples based on them. Borderline SMOTE [8] selects only those existing instances of which at least half of the neighbors are from the same class. Borderline-1 SMOTE select neighbors from the same class as the existing sample and Borderline-2 SMOTE considers neighbors from any class. Safe-level SMOTE [3] samples minority instances along the same line with different weight degree, computed by using nearest neighbour minority instances. ADASYN [9] is similar to SMOTE but the number of generated samples is proportional to the number of samples which are not from the same class as the selected existing instance in a given neighborhood.
3 The Proposed Framework
To deal with the imbalanced data streams classification we propose the following framework for classifier ensemble forming and preparing the dynamic selection dataset (dsel) for the dynamic selection process.
Let’s assume that the data stream consists of fixed-size data chunks \(\mathcal {DS}_{k}\), where k is the chunk index and \(\varPsi _k\) denotes the classifier trained on the basis of the kth chunk. Each based model \(\varPsi _k\) learns from the \(T_k\) training set which is obtained by preprocessing \(\mathcal {DS}_k\). dsel\(_k\) denotes dynamic selection dataset for the kth data chunk and it is considered as previously preprocessed \(\mathcal {DS}_{k-1}\). On the beginning each new trained classifier (one per each incoming chunk) is added to the ensemble until the maximum size of the ensemble (ES) is achieved. Then if new model is added, we evaluate each classifier in the ensemble (according to bac score) and the worst one is removed. Additionally, at each step we remove from the ensemble all models which bac scores are lower than a given threshold \(\alpha \). Pruning process is performed before adding kth classifier to the ensemble. The concept behind the proposed framework is presented in Fig. 1 and the pseudocode is shown in Algorithm 1.

The framework for training base classifiers and to prepare a dsel for dynamic selection process. Here, \(T_k\) is the training data produced by preprocessing (Preproc) data chunk \(DS_k\) and \(\varPsi _k\) is the base classifier trained on the kth data chunk. E denotes the classifier pool.
In the beginning the classifier pool E is empty. We train our first classifier (\(\varPsi _0\)) on the preprocessed zero chunk (steps 4, 5 and 6). When the first chunk arrives, we use (\(\varPsi _0\)) to classify it and then we use it to train our second model (steps 8, 9 and 10). We also store the \(T_1\) training set as the DSEL for future (step 12). Then, with the arrival of each chunk, the following steps are performed:
-
In step 14, we use previously stored training set as DSEL for the dynamic selection process to create the list of ensembles for classifying each test instance in \(DS_k\).
-
In step 15, we use the ensembles selected by DES method to classify instances the current data chunk.
-
In step 16, based on the current chunk, we evaluate bac scores of all models in the ensemble in order to use this information for pruning in the next steps.
-
In steps 17 and 18, we remove from the ensemble all models with bac scores lower than a given threshold \(\alpha \).
-
In steps 19 and 20, we remove the worst rated base model in the ensemble.
-
In steps 21, 22 and 23 we use the data preprocessing method on the current chunk to generate training set \(T_k\), on the basis of which we train a new classifier and add it to the pool E.
-
Finally, in step 24, we store the current training set \(T_k\) in order to use it as DSEL when the next chunk arrives.

4 Experimental Evaluation
The goal of experiments is to show how the combination of dynamic ensemble selection methods and preprocessing perform in terms of classifying imbalanced data streams with various imbalance ratios and different types of concept drift.
4.1 Experimental Setup
As the experimental protocol test and train framework [12] was used, i.e., every classification model is trained on a recent data chunk, but it is evaluated on the basis of the following one. Evaluation of the proposed framework was based on the balanced accuracy measure (bac) according to scikit-learn implementation [17], which for the binary case is equal to the arithmetic mean of sensitivity (the true positive rate) and specificity (the true negative rate) and geometric mean measure (G-mean) according to imbalanced-learn implementation [14] defined as \(g=\sqrt{a^+a^-}\), where \(a^+\) denotes sensitivity and \(a^-\) denotes specificity. As the base classifier we used classification and regression tree (cart). For ensemble pruning (see line 18 in Algorithm 1) we used \(\alpha =0.55\), i.e., all base classifiers which bac scores are lower than \(\alpha \) were removed from ensemble. The choice of this value was motivated to get the classifiers a slightly better than the random ones. The maximum size of the classifier pool was \(ES=20\).
Experiments were implemented in Python programming language and may be repeated according to source code published on GithubFootnote 1.
Performance of the naive aggregation of the whole classifier pool (Naive) and the dynamic ensemble methods (KNORA-E, KNORA-U, DES-KNN and DES-Clustering) is evaluated depending on the data preprocessing methods that they were coupled with. Neighborhood size for des methods is \(k=7\).
Six preprocessing methods chosen for the experiments are: SMOTE, SVM-SMOTE, two variants of Borderline-SMOTE (B1-SMOTE and B2-SMOTE), Safe-level SMOTE (SL-SMOTE) and ADASYN. We also check how the ensemble methods behave without the use of any data preprocessing.
The proposed framework was evaluated using  artificially generated data streams. Each stream is composed of one hundred thousand instances divided into
artificially generated data streams. Each stream is composed of one hundred thousand instances divided into  chunks of
chunks of  objects described by
objects described by  features, and contains five concept drifts. The base concepts were generated according to procedure of creating the Madelon [7] synthetic classification dataset, the used stream generator is available at GithubFootnote 2. Each combination was generated three times, based on the determined seeds. The variety of streams was ensured by generating three streams for each combination of the following parameters:
features, and contains five concept drifts. The base concepts were generated according to procedure of creating the Madelon [7] synthetic classification dataset, the used stream generator is available at GithubFootnote 2. Each combination was generated three times, based on the determined seeds. The variety of streams was ensured by generating three streams for each combination of the following parameters:
-
the imbalance ratio—successively
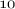 ,
, 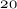 ,
,  and
and  % of the minority class.
% of the minority class. -
the level of label noise—successively
 ,
,  and
and  %.
%. -
the type of concept drift—sudden or incremental.
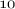 ,
, 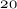 ,
,  and
and  % of the minority class.
% of the minority class. ,
,  and
and  %.
%.The results of experiments for two measures: bac (a) and G-mean (b) for different ir values and drift types are presented in Figs. 2 and 3. The radar charts present how each data preprocessing technique influenced the performance of a given DES method and are followed by the classification results for the best performing dynamic selection methods coupled with the most effective data preprocessing techniques. Presented methods were selected based on the statistical evaluation and are compared to the aggregation of probabilities of the whole classifier pool and to the results obtained only with the use of dynamic selection or preprocessing. The Figs. 2 and 3 show results related to different imbalance ratios and drift types. The complete statistical evaluation of all methods, which was the basis for all figures shown, is available on GithubFootnote 3 in PDF format.

Comparison of different sampling approaches for different classifier ensembles with respect to performance measures (BAC and G-mean) for imbalance ratio 1 : 9, 2 : 8 and 3 : 7.
During evaluation of the proposed framework in the case of different types (sudden or incremental) of concept drift, we focus on the streams with high imbalance ratios (i.e., 1 : 9 and 2 : 8), typical for the real-life decision tasks. The comparison is shown in Fig. 3.
4.2 Lessons Learned
Based on the statistical analysis, which is available in its entirety on Github (see footnote 3) repository, we can see that for the 1 : 9 imbalance ratio, according to bac, DES-KNN was the best performing method without the use of any preprocessing. In cases where we coupled DES with preprocessing methods, KNORA-U performed best except for the use of SL-SMOTE, where it was not statistically better than DES-KNN. According to G-mean for 1 : 9 ir DES-KNN was statistically the best dynamic ensemble selection method. For the Borderline2-SMOTE preprocessing method, both DES-KNN and KNORA-U performed statistically similar. The best preprocessing methods were SVM-SMOTE and Borderline2-SMOTE.

Comparison of different sampling approaches for different classifier ensembles with respect to performance measures (BAC and G-mean) for imbalance ratio 4 : 6 and for sudden drift and incremental drift.
For the 2 : 8 ir, both in terms of bac and G-mean, KNORA-U performed the best when paired with any preprocessing method. In case of not using any data preprocessing, DES-KNN was statistically the best. As for preprocessing techniques, in most cases the SVM-SMOTE was statistically significant, Borderline2-SMOTE performed the best for naive aggregation of the whole classifier pool.
For the 3 : 7 imbalance ratio, again, KNORA-U turned out to be statistically the best DES method. Only exception (according to G-mean) was the case when we do not use preprocessing, then DES-KNN works best. Best performing data preprocessing method for DES, according to both measures, was the SVM-SMOTE. Borderline2-SMOTE again performed the best for naive aggregation.
In case of 4 : 6 ir according to both bac and G-mean KNORA-U was the statistically significant DES method in every case. Borderline2-SMOTE worked best for naive aggregation and in the remaining cases SVM-SMOTE was statistically the best preprocessing method.
For sudden drift, in terms of both measures, DES-KNN was statistically the best without the use of any preprocessing method and KNORA-U was statistically leading when paired with every oversampling method. Borderline2-SMOTE was the best for naive aggregation and for KNORA-U according to G-mean, for the rest of DES methods SVM-SMOTE performed the best.
Finally, for incremental drift, according to bac, DES-KNN performed statistically the best without the use of preprocessing and for the SL-SMOTE while KNORA-U was the best for other oversampling techniques. SVM-SMOTE was the best preprocessing method for KNORA-E, DES-KNN and DES-Clustering and Borderline2-SMOTE performed the best coupled with naive aggregation and KNORA-U. According to G-mean, KNORA-U was statistically leading DES method for Borderline2-SMOTE and ADASYN while DES-KNN was statistically significant for all other preprocessing techniques. SVM-SMOTE worked best with KNORA-E and DES-KNN, Borderline2-SMOTE proved to be statistically significant for naive aggregation, KNORA-U and DES-Clustering.
In general, the order of the presented approaches in terms of performance, starting with the worst, is as follows: (1) naive aggregation without the use of any preprocessing methods \(\rightarrow \) (2) naive aggregation combined with preprocessing \(\rightarrow \) (3) dynamic ensemble selection methods without preprocessing \(\rightarrow \) (4) DES methods coupled with preprocessing methods. The lower the imbalance ratio, the smaller the differences between approaches, but the order is maintained. The conducted experiments showed that the best performing DES method among the considered strategies across all tested imbalance ratios is the KNORA-U, which uses the weighted voting scheme. As the KNORA-Union method selects all base models that are able to correctly classify at least one instance in the local region of competence and then it combines them based on the weighted voting, where the number of votes is equal to the number of correctly recognized samples, it allows us to select both accurate and diverse ensemble. As both of these characteristics are determinants of a good classifier ensemble model, they may be the reason for high results of this DES method. Worth mentioning is also the DES-KNN, which is doing well for high imbalance ratios, especially for the \(10\%\) of minority class and for incremental drift in terms of G-mean. DES-KNN performs the best for high IR (10 and \(20\%\) of minority class) in case of not using any preprocessing method. The worst performing DES method, for low IR (30 and \(40\%\)) worse even than naive aggregation, was KNORA-E. This may be due to the fact, that the local oracles are found only for regions of competence with a significantly reduced size, which negatively affects the performance.
Based on the results achieved by DES-KNN and DES-Clustering methods we may suspect that the K-Nearest Neighbors technique is better suited for defining the local region of competence in case of imbalanced data streams than the clustering technique. Despite the higher computational cost, KNN allows for more precise estimation of the region of competence which leads to more possible ensemble configurations for classifying new instances.
On the other hand, SVM-SMOTE and Borderline2-SMOTE have proven to be the preferred preprocessing strategies for the used dynamic ensemble selection methods. The combination of KNORA-U or DES-KNN with one of those preprocessing methods always leads to the best classification performance.
5 Conclusions
The main goal of this work was to propose a novel framework for training base classifiers and preparing the dynamic selection dataset (dsel) for the dynamic selection process during imbalanced data stream classification. We proposed the self-updating ensemble model employing data preprocessing techniques. The computer experiments confirmed the effectiveness of the proposed framework and based on the statistical analysis we can conclude that dynamic ensemble methods coupled with data preprocessing techniques are statistically significantly better than the approaches that do not combine both of these concepts.
The results presented in this paper are quite promising therefore they encourage us to continue our work on employing dynamic ensemble selection for imbalanced data stream classification. Future research may consist of analysing different methods of defining the local region of competence (e.g. applying various distance metrics) and the development of a weighted voting combination approach based on the KNORA-Union, specialized in dealing with imbalanced data. Analysing the impact of pruning threshold \(\alpha \) value on the performance of DES methods for the proposed framework might be another idea worth noting.
References
Barandela, R., Valdovinos, R., Sánchez, J.: New applications of ensembles of classifiers. Pattern Anal. Appl. 6(3), 245–256 (2003)
Bifet, A., Holmes, G., Pfahringer, B.: Leveraging bagging for evolving data streams. In: Balcázar, J.L., Bonchi, F., Gionis, A., Sebag, M. (eds.) ECML PKDD 2010. LNCS (LNAI), vol. 6321, pp. 135–150. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-15880-3_15
Bunkhumpornpat, C., Sinapiromsaran, K., Lursinsap, C.: Safe-level-SMOTE: safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In: Theeramunkong, T., Kijsirikul, B., Cercone, N., Ho, T.-B. (eds.) PAKDD 2009. LNCS (LNAI), vol. 5476, pp. 475–482. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-01307-2_43
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P.: SMOTE: synthetic minority over-sampling technique. J. Artif. Int. Res. 16(1), 321–357 (2002)
Cruz, R.M.O., Sabourin, R., Cavalcanti, G.D.C.: META-DES.Oracle: meta-learning and feature selection for dynamic ensemble selection. Inform. Fusion 38, 84–103 (2017)
Cruz, R.M., Sabourin, R., Cavalcanti, G.D.: Dynamic classifier selection: recent advances and perspectives. Inf. Fusion 41(C), 195–216 (2018)
Guyon, I.: Design of experiments of the NIPS 2003 variable selection benchmark. In: NIPS 2003 Workshop on Feature Extraction and Feature Selection (2003)
Han, H., Wang, W.-Y., Mao, B.-H.: Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning. In: Huang, D.-S., Zhang, X.-P., Huang, G.-B. (eds.) ICIC 2005. LNCS, vol. 3644, pp. 878–887. Springer, Heidelberg (2005). https://doi.org/10.1007/11538059_91
He, H., Bai, Y., Garcia, E.A., Li, S.: ADASYN: adaptive synthetic sampling approach for imbalanced learning. In: 2008 IEEE International Joint Conference on Neural Networks, IEEE World Congress on Computational Intelligence, pp. 1322–1328 (2008)
Ko, A.H., Sabourin, R., Britto Jr., A.S.: From dynamic classifier selection to dynamic ensemble selection. Pattern Recogn. 41(5), 1718–1731 (2008)
Krawczyk, B.: Learning from imbalanced data: open challenges and future directions. Prog. Artif. Intell. 5(4), 221–232 (2016). https://doi.org/10.1007/s13748-016-0094-0
Krawczyk, B., Minku, L.L., Gama, J., Stefanowski, J., Woźniak, M.: Ensemble learning for data stream analysis: a survey. Inform. Fusion 37, 132–156 (2017)
Kuncheva, L.I.: Classifier ensembles for changing environments. In: Roli, F., Kittler, J., Windeatt, T. (eds.) MCS 2004. LNCS, vol. 3077, pp. 1–15. Springer, Heidelberg (2004). https://doi.org/10.1007/978-3-540-25966-4_1
Lemaître, G., Nogueira, F., Aridas, C.K.: Imbalanced-learn: a Python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Learn. Res. 18(17), 1–5 (2017)
Lysiak, R., Kurzynski, M., Woloszynski, T.: Optimal selection of ensemble classifiers using measures of competence and diversity of base classifiers. Neurocomputing 126, 29–35 (2014)
Nguyen, H.M., Cooper, E.W., Kamei, K.: Borderline over-sampling for imbalanced data classification. IJKESDP 3, 4–21 (2011)
Pedregosa, F., et al.: Scikit-learn: machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011)
Soares, R.G.F., Santana, A., Canuto, A.M.P., de Souto, M.C.P.: Using accuracy and diversity to select classifiers to build ensembles. In: The 2006 IEEE International Joint Conference on Neural Network Proceedings, pp. 1310–1316, July 2006
Woloszynski, T., Kurzynski, M.: A probabilistic model of classifier competence for dynamic ensemble selection. Pattern Recogn. 44(10–11), 2656–2668 (2011)
Woźniak, M., Graña, M., Corchado, E.: A survey of multiple classifier systems as hybrid systems. Inform. Fusion 16, 3–17 (2014)
Zyblewski, P., Ksieniewicz, P., Woźniak, M.: Classifier selection for highly imbalanced data streams with minority driven ensemble. In: Rutkowski, L., Scherer, R., Korytkowski, M., Pedrycz, W., Tadeusiewicz, R., Zurada, J.M. (eds.) ICAISC 2019. LNCS (LNAI), vol. 11508, pp. 626–635. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-20912-4_57
Acknowledgment
This work was supported by the Polish National Science Centre under the grant No. 2017/27/B/ST6/01325 as well as by the statutory funds of the Department of Systems and Computer Networks, Faculty of Electronics, Wroclaw University of Science and Technology.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Zyblewski, P., Sabourin, R., Woźniak, M. (2020). Data Preprocessing and Dynamic Ensemble Selection for Imbalanced Data Stream Classification. In: Cellier, P., Driessens, K. (eds) Machine Learning and Knowledge Discovery in Databases. ECML PKDD 2019. Communications in Computer and Information Science, vol 1168. Springer, Cham. https://doi.org/10.1007/978-3-030-43887-6_30
Download citation
DOI: https://doi.org/10.1007/978-3-030-43887-6_30
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-43886-9
Online ISBN: 978-3-030-43887-6
eBook Packages: Computer ScienceComputer Science (R0)
