
Abstract
The algebraic group model, introduced by Fuchsbauer, Kiltz and Loss (CRYPTO ’18), is a substantial relaxation of the generic group model capturing algorithms that may exploit the representation of the underlying group. This idealized yet realistic model was shown useful for reasoning about cryptographic assumptions and security properties defined via computational problems. However, it does not generally capture assumptions and properties defined via decisional problems. As such problems play a key role in the foundations and applications of cryptography, this leaves a significant gap between the restrictive generic group model and the standard model.
We put forward the notion of algebraic distinguishers, strengthening the algebraic group model by enabling it to capture decisional problems. Within our framework we then reveal new insights on the algebraic interplay between a wide variety of decisional assumptions. These include the decisional Diffie-Hellman assumption, the family of Linear assumptions in multilinear groups, and the family of Uber assumptions in bilinear groups.
Our main technical results establish that, from an algebraic perspective, these decisional assumptions are in fact all polynomially equivalent to either the most basic discrete logarithm assumption or to its higher-order variant, the q-discrete logarithm assumption. On the one hand, these results increase the confidence in these strong decisional assumptions, while on the other hand, they enable to direct cryptanalytic efforts towards either extracting discrete logarithms or significantly deviating from standard algebraic techniques.
L. Rotem and G. Segev—Supported by the European Union’s Horizon 2020 Framework Program (H2020) via an ERC Grant (Grant No. 714253).
L. Rotem—Supported by the Adams Fellowship Program of the Israel Academy of Sciences and Humanities.
You have full access to this open access chapter, Download conference paper PDF
1 Introduction
One of the most successful and influential idealized models in cryptography is the generic group model [Nec94, BL96, Sho97, Mau05], most often used to analyze the security of group-based cryptographic assumptions and constructions. The generic group model captures group-based computations that do not exploit any specific property of the representation of the underlying group, by withholding from algorithms the concrete representations of group elements. At a high level, the access of generic algorithms to group elements is mediated by an oracle, and is restricted to the abstract group operation and to checking equalities among group elements throughout the computation. On the one hand, the generic group model captures a wide and natural class of algorithms, and a proof of security in this model means that a successful adversary must step outside this class. This enables, in particular, to direct candidate constructions and cryptanalytic efforts away from generic impossibility or hardness results. On the other hand, however, the assumption that adversaries are completely oblivious to the representation of the group and its elements is often unrealistic to some extent (see for example [FKL18, JS13] and the discussion therein).
The Algebraic Group Model. With this gap in mind, Fuchsbauer, Kiltz and Loss [FKL18] elegantly introduced the algebraic group model, as an intermediary model between the generic group model and the standard model.Footnote 1 Roughly speaking, an algebraic algorithm may use the representation of group elements in any arbitrary manner, but whenever it outputs a group element, it must supply together with it an “algebraic explanation” for how it came up with this element. Informally, this explanation is a representation of the outputted element, in the basis of all group elements that the algorithm has received so far.
Fuchsbauer et al. showed that though a considerable weakening of the generic group model, the algebraic group model provides a very advantageous framework for proving security reductions which are unknown to hold in the standard model. For example, within the algebraic group model, they reduced the security of very useful cryptographic schemes such as the BLS signature scheme [BLS01] and Groth’s zero-knowledge SNARK [Gro16], to the hardness of very simple variants of the discrete logarithm problem. Follow-up works have continued to exemplify the usefulness of the model, by providing security reductions from the hardness of a large class of computational Diffie-Hellman-like problems to the hardness of the discrete logarithm problem [MTT19]; and from the unforgeability of blind Schnorr signatures [Sch91, Sch01] and variants thereof to the hardness of simple computational problems in cyclic groups [FPS20]. Moreover, the recent work of Agrikola, Hofheinz and Kastner [AHK20] provided a standard-model implementation of (a relaxation of) the algebraic group model.
Computational vs. Decisional Problems. One commonality which is shared by all of the aforesaid results, is that they all deal with assumptions and security properties that are defined via computational problems (i.e., search problems in which an algorithm is required to output group elements). This should come as no surprise: Algorithms for decisional problems are challenged with outputting a decision bit, and do not, generally speaking, output any group elements. As Fuchsbauer et al. point out, this means that such algorithms (to which we refer as distinguishers) are vacuously algebraic, and that in principal, decisional problems are not captured within the algebraic group model. Fuchsbauer et al. posed the important open problem of whether or not their approach can be extended to capture decisional algebraic problems and algebraic distinguishers, as these play key roles in the foundations and applications of cryptography. Developing such a model will enable to analyze the security of indistinguishability-based cryptographic problems and constructions while enjoying the key advantages of the algebraic group model.
1.1 Our Contributions
Algebraic Distinguishers. We put forward a generalized framework that captures algebraic distinguishers within the algebraic group model. Following Fuchsbauer et al. [FKL18], our framework fits the intuition according to which the algebraic group model “lies in between the standard model and the generic group model”. Concretely, our notion of algebraic distinguishers allows such algorithms to rely on the explicit representation of group elements in any arbitrary manner, while still requiring that they “explain” their decision via an “algebraic witness”.
In our framework this witness corresponds to a non-trivial equality relation satisfied by a subset of the group elements which the algebraic distinguisher has received or has computed throughout its execution. We carefully formulate an additional requirement regarding this witness in order to guarantee its non-triviality and usefulness: Loosely speaking, we ask that whenever the algebraic distinguisher can tell two distributions apart, then this witness serves as a “good differentiator” between these two distributions. Our requirement is a rather mild one (much stronger requirements hold in the generic group model), and it is sufficient for proving highly non-trivial reductions, as discussed below. Our notion of algebraic distinguishers is formulated in a general manner, allowing for flexibility and versatility in its applications (e.g., it can be used to reason about the indistinguishability of hybrid distributions that are introduced within proofs of security and are not part of the original formulation of the problem under consideration – as we demonstrate, for example, in Sect. 5). We refer the reader to Sect. 1.2 for a high-level description of our framework.
From Discrete Logarithms to Decisional Uber Assumptions. Within our framework we reveal new insights on the algebraic interplay between a wide variety of decisional assumptions. These include the seemingly modest decisional Diffie-Hellman assumption and the family of Linear assumptions [Sha07], as well as the seemingly substantially stronger family of decisional Uber assumptions [BBG05, Boy08].
Our main technical results show that, from an algebraic perspective, these decisional assumptions are in fact all polynomially equivalent to either the most basic discrete logarithm assumption (in the case of the decisional Diffie-Hellman and Linear assumptions) or to its generalized higher-order variant, the q-discrete logarithm assumption (in the case of the entire family of decisional Uber assumptions). We refer the reader to Sect. 1.2 for a high-level description of our results and for informal theorem statements.
Interpreting Our Framework and Results. Prior to our work, these decisional assumptions that we consider were simply known to unconditionally hold in the generic group model, without any indication of a non-trivial interplay among them. Moreover, prior to our work, the algebraic group model enabled to reason only about computational problems, whereas our framework enables both to reason about decisional problems and to reduce their algebraic hardness to that of computational problems. In this light, the contributions of our framework and technical results can be interpreted in the following, somewhat equivalent, manners:
-
From the perspective of designing cryptographic schemes, our equivalence between the algebraic hardness of extracting discrete logarithms and that of seemingly much stronger assumptions increases the confidence in such stronger assumptions.
-
From the perspective of cryptanalytic efforts, the introduction of the family of Uber assumptions [BBG05, Boy08] enabled directing nearly all such efforts towards a specific and well-defined family of decisional assumptions. Our results show that these efforts either can be significantly further directed towards extracting discrete logarithms, or should deviate from all algebraic techniques that are captured within our framework.
1.2 Overview of Our Framework and Results
In this section we provide a high-level overview of our framework and technical results. We start by reviewing our definition of algebraic distinguishers, and the intuition behind it, in more detail. For a formal exposition and discussion of the definition, see Sect. 3.
A First Attempt. As a first attempt of defining algebraic distinguishers, consider demanding that whenever an algebraic distinguisher accepts (i.e., outputs 1), it should output a “decision” vector \(\vec {w}\) such that \(\prod _{i} {g_i}^{w_i} = 1\), where \(g_1,g_2,\ldots \) are the group elements that the distinguisher has observed, and 1 is the unity of the group. This is inspired by the approach of Fuchsbauer et al. who adapted from the generic group model the restriction of producing new group elements only as combinations of previously observed elements. The above requirement couples this restriction with another constraint posed on algorithms in the generic group model: The fact that essentially the only useful information on which generic algorithms can base their decisions is the equality pattern among the group elements that they have observed. Put differently, the basic algebraic information which can lead a generic distinguisher to accept (or to reject), is a non-trivial equality relation among the group elements that it has observed. Thus, the vector \(\vec {w}\) captures the zero test induced by this relation.
Of course, such a zero test can always be produced by setting \(\vec {w}\) to be the all-zeros vector, and so we need to add some non-triviality requirement. A possible route is demanding that whenever an algebraic algorithm accepts, the vector \(\vec {w}\) has to be non-zero (i.e., \(\vec {w}\ne \vec {0}\)). Such a demand, however, seems unrealistic since a distinguisher can always accept even without “having knowledge” of such a non-zero vector \(\vec {w}\). Moreover, it is not enough to ask that \(\vec {w}\ne \vec {0}\). Consider, for example, the decisional Diffie-Hellman problem in which the distinguisher is asked to distinguish between a tuple of the form \((g, g^x,g^y,g^{x\cdot y})\) and a tuple of the form \((g, g^x,g^y,g^z)\) for a uniform choice of x, y and z. In this case, a vector \(\vec {w}\) whose any of the last three entries is 0, cannot be used in order to distinguish between the distributions, since when projected onto the support of such a vector \(\vec {w}\), the two distributions coincide.
Our Definition. In light of the above discussion, our definition of algebraic distinguishers is somewhat more subtle. Informally, it asks that if an algebraic distinguisher \(\mathsf{A}\) runs in time t and distinguishes between two distributions \(D_0\) and \(D_1\) with advantage \(\epsilon \), then there exists some bit \(b\in \{0,1\}\) such that the following holds: On input drawn from \(D_b\), the distinguisher \(\mathsf{A}\) outputs a “good” vector \(\vec {w}\) with probability at least \(\epsilon /t^2\) (this is in addition to the requirement that \(\prod _{i} {g_i}^{w_i} = 1\) with probability 1). We define a “good” vector \(\vec {w}\) to be such that \(D_0\) and \(D_1\) remain distinct even when projected onto the support of \(\vec {w}\). Informally, by projecting a distribution onto the support of \(\vec {w}\), we mean “erasing” all group elements whose corresponding entry in \(\vec {w}\) is 0 (See Sect. 3.2 for a formal definition of this operation). This requirement (and even stronger forms thereof) indeed holds in the generic group model (as we discuss in Sect. 3.3), implying that our definition of the algebraic group model in fact lies between the generic group model and the standard one. We remark that even stronger requirements might be justifiable, and refer the reader to Sect. 3.2.
In groups which are equipped with a k-linear map, a distinguisher has additional algebraic power: It can infer information from equalities in the target group as well. Whereas in the generic group model, equalities in the source group induce linear polynomials in the exponent, equalities in the target group induce polynomials of degree up to k. We capture this fact by allowing the distinguisher to output a “degree k zero test” as its algebraic witness, and refer the reader to Sect. 5.1 and to the full version of this paper [RS20] for the formal definition.
The Algebraic Hardness of the Decisional Uber Assumption in Bilinear Groups. In the setting of bilinear groups, Boneh, Boyen and Goh [BBG05] and Boyen [Boy08] introduced the Uber family of decisional assumptions. Each assumption in the family is parameterized by two tuples of m-variate polynomials \(\vec {r} = (r_1,\ldots , r_t)\) and \(\vec {s} = (s_1,\ldots ,s_t)\) and an m-variate polynomial f. Roughly, the assumption states that given a generator g of the source group, and given the group elements \(g^{r_1(x_1,\ldots ,x_m)},\ldots , g^{r_t(x_1,\ldots ,x_m)}\) and \(e(g,g)^{s_1(x_1,\ldots ,x_m)},\ldots , e(g,g)^{s_t(x_1,\ldots ,x_m)}\), it is infeasible to distinguish between \(e(g,g)^{f(x_1,\ldots ,x_m)}\) and a uniformly-random element in the target group for a uniform choice of \(x_1,\ldots ,x_m\). Boneh et al. proved that as long as \(\vec {r}\), \(\vec {s}\) and f do not admit a trivial solution, the \((\vec {r}, \vec {s}, f)\)-Uber problem is hard in the generic group model.
Within our framework, we reduce the hardness of the \((\vec {r}, \vec {s}, f)\)-Uber problem to the hardness of the q-discrete logarithm problem in the source group, where in the q-discrete logarithm problem an adversary needs to retrieve a secret exponent x given \((g, g^x,\ldots , g^{x^q})\), and q is polynomial in the number of polynomials in \(\vec {r}\) and in \(\vec {s}\) and in the their degree.
Theorem 1.1
(Informal). Let \((\vec {r}, \vec {s}, f)\) represent m-variate polynomials which do not admit a trivial solution to the \((\vec {r}, \vec {s}, f)\)-Uber problem, and let \(\mathsf{A}\) be an algebraic algorithm for the \((\vec {r}, \vec {s}, f)\)-Uber problem relative to a source group \(\mathbb {G}\) and a target group \(\mathbb {G}_T\). Then, there exists an algorithm \(\mathsf{B}\) for the q-Discrete Logarithm problem in \(\mathbb {G}\), whose running time and success probability are polynomially-related to those of \(\mathsf{A}\).
The proof of Theorem 1.1 consists of two parts. First, inspired by the work of Ghadafi and Groth [GG17], we consider an intermediate variant of the Uber assumption which is univariate, in the sense that it involves only a single secret exponent x (instead of m secret exponents \(x_1,\ldots ,x_m\)). We observe that the work of Ghadafi and Groth immediately implies that for any triplet \((\vec {r},\vec {s}, f)\), the existence of a successful algebraic distinguisher for the \((\vec {r},\vec {s}, f)\)-Uber assumption implies the existence of a successful algebraic distinguisher for the univariate variant as well.
In the second (and main) part of the proof, we reduce within our framework the hardness of this univariate variant to that of the q-discrete logarithm problem. Technical details omitted, the main idea is to embed the secret exponent x of the q-discrete logarithm challenge as the secret exponent used to generate the input in the univariate Uber assumption. This is where the parameter q comes into play; since the polynomials \((\vec {r},\vec {s}, f)\) may be of high degree, generating the input to the univariate Uber assumption may require knowledge of group elements of the form \(g^{x^i}\) for different values of i. As discussed above, a successful algebraic distinguisher for univariate Uber assumption returns a zero test as an algebraic witness for its decision. We observe that if \((\vec {r}, \vec {s}, f)\) do not admit a trivial solution to the \((\vec {r}, \vec {s}, f)\)-Uber problem, this witness induces a non-zero univariate polynomial with one of its roots being x. Consequently, we can retrieve x by finding the roots of this polynomial (for example, by using the Berlekamp-Rabin algorithm [Ber70, Rab80]) and searching for the root which is consistent with the input to the q-discrete logarithm problem.
The Algebraic Hardness of the Decisional \(\mathbf{k} \)-Linear Problem in \(\mathbf{k} \)-Linear Groups. In the Decisional k-Linear problem introduced by Shacham [Sha07], a distinguisher is given an input of the form \((g, g^{\alpha _1}, \ldots , g^{\alpha _k}, g^\beta , g^{\alpha _1 \cdot r_1}, \ldots , g^{\alpha _k \cdot r_k})\) and needs to distinguish between the group element \(g^{\beta \cdot \sum _{i=1}^{k} r_i}\) and a uniformly random group element \(g^z\). Observe that this family of assumptions generalizes the Decisional Diffie-Hellman assumption (which corresponds to \(k=1\)) and the Decisional Linear assumption [BBS04] (which corresponds to \(k=2\)). Seemingly, this family forms a hierarchy; for any k, the k-Linear assumption implies the \((k+1)\)-Linear assumption. As for the other direction, Shacham proved that in a generic group equipped with a \((k+1)\)-linear map the \((k+1)\)-Linear assumption holds, even though it is easy to break the k-Linear assumption. Within our algebraic framework, we prove a more refined relation among the different assumptions in the family: For k-linear groups, we show an equivalence between the k-Linear problem in the source group and the discrete logarithm in the source group.
Theorem 1.2
(Informal). Let \(\mathsf{A}\) be an algebraic algorithm for the k-Linear problem relative to a group \(\mathbb {G}\) equipped with a k-linear map. Then, there exists an algorithm \(\mathsf{B}\) for Discrete Logarithm assumption in \(\mathbb {G}\), whose running time and success probability are polynomially-related to those of \(\mathsf{A}\).
An immediate corollary of Theorem 1.2 is an equivalence (within our framework) between the Decisional Diffie-Hellman assumption and the discrete logarithm assumption in groups without a bilinear map (see Sect. 3.2 for our model which captures such groups); and an equivalence between the Decisional Linear assumption and the discrete logarithm assumption in bilinear groups (without a trilinear map – see Sect. 5.1 for definition of such groups in our model). We refer the reader to the full version of this paper [RS20] for the formal statement and proof of Theorem 1.2. For concreteness, we now provide a more detailed account of the proof outline for Theorem 1.2 for the simple case of \(k=1\).
Warm-Up: From Decisional Diffie-Hellman to Discrete Logarithms. Consider an algebraic distinguisher \(\mathsf{D}\) which runs in time t and has advantage \(\epsilon \) in breaking the Decisional Diffie-Hellman assumption in a group \(\mathbb {G}\). As discussed above, this means that on input of the form \((g,g^x, g^y, g^{x\cdot y + b\cdot z})\) for some \(b\in \{0,1\}\) and a uniform choice of x, y and z, \(\mathsf{D}\) outputs a vector \(\vec {w} = (w_0,w_1,w_2,w_3)\) such that:
-
1.
\(g^{w_0} \cdot g^{w_1 \cdot x} \cdot g^{w_2 \cdot y }\cdot g^{w_3 \cdot (x\cdot y + b \cdot z)} = 1\); and
-
2.
There exists \(\sigma \in \{0,1\}\) such that if \(b = \sigma \), then with probability at least \(\epsilon /t^2\) it holds that \(w_1, w_2\) and \(w_3\) are all non-zero.
These facts can be used to construct an algorithm \(\mathsf{A}\) breaking the discrete logarithm problem in \(\mathbb {G}\). For concreteness and brevity, in this overview we focus on the case in which \(\sigma = 0\).Footnote 2 The adversary \(\mathsf{A}\) receives as input a group element \(\mathbf{R} := g^r\) and embeds it as part of the input to \(\mathsf{D}\): With probability 1/2, it embeds r instead of x by sampling y on its own and invoking \(\mathsf{D}\) on \((g, \mathbf{R}, g^y, \mathbf{R}^{y})\); and with probability 1/2 it embeds r instead of y. Suppose that \(\mathsf{D}\) returns a vector \(\vec {w}\) for which \(0 \not \in \{w_1,w_2,w_3\}\) (which, according to condition 2 above, happens with probability at least \(\epsilon /t^2\)). We can rewrite the first condition in additive notation to deduce the bilinear bivariate equation \(w_0 + w_1\cdot x + w_2 \cdot y + w_3 \cdot x \cdot y = 0\). If r was embedded to replace x then \(\mathsf{A}\), knowing y, can solve the equation for x and output the correct discrete logarithm r. This works as long as the coefficient of x in this equation is non-zero; i.e., as long as \(w_1 + w_3 \cdot y \ne 0\). But whenever \(0 \not \in \{w_1,w_2,w_3\}\), this can only happen if \(y = -w_1/w_3\). Hence, if r was embedded to replace y, \(\mathsf{A}\) may simply return \(-w_1/w_3\) in order to output the correct discrete logarithm r.
1.3 Additional Related Work
Beullens and Wee [BW19] have put forth the Knowledge of Orthogonality Assumption (KOALA), which is similar in spirit to our extension of the algebraic group model. The assumption deals with the problem of distinguishing between vectors of group elements whose exponents are uniformly drawn from some linear subspace V and vectors of independently (and uniformly) sampled group elements. Roughly speaking, KOALA holds if for any probabilistic polynomial-time algorithm which can distinguish between the two afore-described distributions, there exists an extractor which outputs a vector from the orthogonal complement \(V^\perp \). Though similar in spirit, our model significantly generalizes KOALA. First, our model supports interactive security games, whereas KOALA considers a non-interactive game. In interactive games, our model also accounts for the entire view of the adversary, which may extend beyond just vectors of group elements. Second, and more importantly, KOALA seems to be tailored to prove the security of concrete obfuscation schemes, and hence only deals with the pseudorandomness of very specific distributions. In contrast, even when restricted to non-interactive games, our model can be used to reason about the ability to distinguish between any two distributions over group elements.
More generally speaking, these aforesaid differences between our model and KOALA precisely exemplify the motivation of the our work. Over the years, various knowledge assumptions in cyclic groups have been introduced in order to reason about the security of different constructions. The algebraic group model provides a unified framework for capturing computational knowledge assumptions. The motivation behind the introduction of our model is to capture in a similar manner decisional knowledge assumptions, such as KOALA, as well.
In a recent and independent work, Bauer, Fuchsbauer and Loss [BFL20] have considered (among other things) the computational variant of the Uber problem of Boneh, Boyen and Goh [BBG05, Boy08] in bilinear groups. Concretely, Bauer et al. reduced this variant to the q-Discrete Logarithm problem within the algebraic group model of Fuchsbauer et al. [FKL18], where q is the maximum (total) degree of the challenge polynomials in the instance of the Uber problem. Our result regarding the Uber problem (Theorem 1.1) differs from theirs in that we consider the decisional variant of the Uber problem within our decisional algebraic group model. Both our work and theirs utilize a similar technique of embedding randomizations of the secret exponent of the q-Discrete Logarithm instance into the secret exponents of the Uber problem instance (the concrete randomizations, however, are different). This is in contrast to our proof of Theorem 1.2, which employs a different technique.
1.4 Paper Organization
The remainder of this paper is organized as follows. First, in Sect. 2 we review the basic notation and definitions underlying the algebraic group model. In Sect. 3 we present our generalized framework capturing algebraic distinguishers, and as a warm-up, Sect. 4 includes a proof of the equivalence within our framework of the decisional Diffie-Hellman problem and the discrete logarithm problem. In Sect. 5 we extend our framework to bilinear groups, and prove our hardness result for the Uber family of decisional problems in such groups. In the full version of this paper [RS20], we generalize our framework to multilinear groups, and prove our hardness result for the decisional k-Linear problem in k-linear groups.
2 Preliminaries
In this section we briefly review the basic notions and definitions underlying the algebraic-group model [FKL18]. Throughout this work, for a distribution X we denote by \(x \leftarrow X\) the process of sampling a value x from the distribution X. Similarly, for a set \(\mathcal {X}\) we denote by \(x \leftarrow \mathcal {X}\) the process of sampling a value x from the uniform distribution over \(\mathcal {X}\). For an integer \(n \in \mathbb {N}\), we use the notation [n] to denote the set \(\{1,\ldots ,n\}\).
Game-Based Security Definitions. Notions of security within the algebraic-group model are formalized using “security games”, following the classic framework of Bellare and Rogaway [BR06]. A game \(\mathbf{G}\) is parameterized by a set par of public parameters, and is comprised of an adversary \(\mathsf{A}\) interacting with a challenger via oracle access. Such a game is described by a main procedure and possibly additional oracle procedures, which describe the manner in which the challenger replies to oracle queries issued by the adversary. We denote by \(\mathbf{G}_{par}\) a game \(\mathbf{G}\) with public parameters par, and we denote by \(\mathbf{G}_{par}^{\mathsf{A}}\) the output of \(\mathbf{G}_{par}\) when executed with an adversary \(\mathsf{A}\) (note that \(\mathbf{G}_{par}^{\mathsf{A}}\) is a random variable defined over the randomness of both \(\mathsf{A}\) and the challenger). We denote by \(\mathbf {Time}^{\mathbf{G}_{par}}_{\mathsf{A}}\) the worst-case running time of \(\mathbf{G}_{par}\) when executed with an adversary \(\mathsf{A}\). An adversary \(\mathsf{A}\) participating in a game \(\mathbf{G}_{par}\) is said to win whenever \(\mathbf{G}_{par}^{\mathsf{A}} = 1\), and the advantage of \(\mathsf{A}\) in \(\mathbf{G}_{par}\) is defined as \(\mathbf {Adv}_{\mathsf{A}}^{\mathbf{G}_{par}} {\mathop {=}\limits ^{\mathsf{def}}} \Pr \left[ \mathbf{G}_{par}^{\mathsf{A}} = 1 \right] \).
All security games in this paper are algebraic, which means that their public parameters consist of a description \({\mathcal {G}} = (\mathbb {G}, p, g)\) of a cyclic group \(\mathbb {G}\) of prime order p generated by the generator g (generally speaking, one can consider definitions in which par may include additional parameters, but this will not be necessary for our purposes). In actual instantiation of cryptographic primitives that rely on cyclic groups, such a description \({\mathcal {G}}\) is usually generated via a group-generation algorithm \(\mathsf{GroupGen}(1^\lambda )\), where \(\lambda \in \mathbb {N}\) is the security parameter that determines the bit-length of the prime p. However, we will abstract this fact away in the paper, since our reductions hold for fixing of the security parameter or of the underlying group.
Similarly to Fuchsbauer et al. we use boldface upper-case letters (e.g., \(\mathbf {Z}\)) to denote elements of the group \(\mathbb {G}\) in algebraic games, in order to distinguish them from other variables in the game. Figure 1 exemplifies the notion of an algebraic game by describing the games associated with the Discrete Logarithm problem and the q-Discrete Logarithm problem that we consider in Sects. 4 and 5, respectively.

Examples of algebraic games relative to a cyclic group \(\mathcal {G} = (\mathbb {G}, p, g)\) and an adversary \(\mathsf{A}\). The game \(\mathbf{DLOG}_{\mathcal {G}}^{\mathsf{A}}\) (on the left) captures the Discrete Logarithm problem, and the game q-\(\mathbf{DLOG}_{\mathcal {G}}^{\mathsf{A}}\) (on the right) captures the q-Discrete Logarithm problem (note that setting \(q=1\) corresponds to the Discrete Logarithm problem).
Algebraic Algorithms. Fuchsbauer et al. [FKL18] presented the following notion of algebraic algorithms. In order to differentiate their notion from our extension which captures algorithms in decisional security games as well, we will refer to algorithms that satisfy their definition as computationally-algebraic ones. Roughly speaking, an algorithm \(\mathsf{A}\) is computationally algebraic if whenever it outputs a group element \(\mathbf{Z}\), it also outputs a representation of this element in the basis comprised of all group elements \(\mathsf{A}\) has observed so far.
Definition 2.1
([FKL18]). Let \({\mathcal {G}} = (\mathbb {G},p ,g)\) be a description of a cyclic group. An algorithm \(\mathsf{A}\) participating in an algebraic game with parameters \({\mathcal {G}}\) is said to be computationally algebraic if whenever \(\mathsf{A}\) outputs a group element \(\mathbf{Z} \in \mathbb {G}\), it also outputs a vector \(\vec {z} = (z_0, \ldots , z_k) \in \mathbb {Z}^{k+1}_p\) such that \(\mathbf{Z} = \prod _{i=0}^{k} \mathbf{X}_i^{z_i}\), where \(\mathbf{X}_1,\ldots , \mathbf{X}_k\) are the group elements that \(\mathsf{A}\) has received so far in the game and \(\mathbf{X}_0 = g\).
3 Our Framework: Algebraic Distinguishers
In this section we present our framework, extending that of Fuchsbauer et al. [FKL18] to consider algebraic distinguishers. We start by defining decisional algebraic games; then move on to present and discuss our notion of (fully-)algebraic algorithms, which covers in particular algebraic distinguishers; and finally, we observe that every generic algorithm is also an algebraic one within our framework.
3.1 Decisional Algebraic Games
The game-based definitions presented in Sect. 2 are suitable for computational games, which are aimed at capturing the hardness of computational problems (e.g., the computational Diffie-Hellman problem) and computational security properties of cryptographic primitives (e.g., unforgeability of signature schemes).
Decisional games on the other hand are aimed at capturing decisional cryptographic problems (e.g., the decisional Diffie-Hellman problem) and indistinguishability based security properties of cryptographic primitives (e.g., semantic security of an encryption scheme). At the end of a decisional game, the adversary outputs either the acceptance symbol \(\mathsf{Acc}\), in which case the output of the game is 1, or the rejection symbol \(\mathsf{Rej}\), in which case the output of the game is 0. The advantage of an adversary \(\mathsf{A}\) in distinguishing between two decisional games \(\mathbf{G}_{par}\) and \(\mathbf{G'}_{par'}\) is defined as
Typically, a decisional security definition will be obtained by a single decisional game \(\mathbf{G}\) with an additional parameter bit b, where the adversary needs to distinguish between the cases \(b = 0\) and \(b = 1\). For brevity, we will refer to the advantage of an adversary \(\mathsf{A}\) in distinguishing between \(\mathbf{G}_{par, 0}\) and \(\mathbf{G}_{par, 1}\) simply as the advantage of \(\mathsf{A}\) in \(\mathsf{G}_{par}\), and we will use the notation \(\mathbf {Adv}_{\mathsf{A}}^{\mathbf{G}_{par}} {\mathop {=}\limits ^{\mathsf{def}}} \mathbf {Adv}_{\mathsf{A}}^{\mathbf{G}_{par,0}, \mathbf{G}_{par,1}}\). The running time of \(\mathbf{G}_{par}^{\mathsf{A}}\) is defined as the maximum of the running times of \(\mathbf{G}_{par, 0}^{\mathsf{A}}\) and of \(\mathbf{G}_{par,1}^{\mathsf{A}}\).
Figure 2 exemplifies the notion of a decisional algebraic game by presenting the game associated with the Decisional Diffie-Hellman problem that we consider in Sect. 4. As discussed in Sect. 2, recall that we use boldface upper-case letters (e.g., \(\mathbf {Z}\)) to denote elements of the underlying group \(\mathbb {G}\) in order to distinguish them from other variables in the game.

An example of a decisional algebraic game relative to a cyclic group \({\mathcal {G}} = (\mathbb {G}, p, g)\) and an adversary \(\mathsf{A}\). The game \(\mathbf{DDH}_{{\mathcal {G}},b}^{\mathsf{A}}\) captures the Decisional Diffie-Hellman problem.
3.2 Extending the Notion of Algebraic Algorithms
In order to define (fully-)algebraic algorithms, we first introduce some additional notation. For an algebraic game \(\mathbf{G}\), a group description \({\mathcal {G}} = (\mathbb {G}, p, g)\) and an algorithm \(\mathsf{A}\), we use \(\mathsf{View}_{\mathsf{A}}^{\mathbf{G}_{\mathcal {G}}}\) to denote the random variable which is the view of \(\mathsf{A}\) in the game \(\mathbf{G}_{\mathcal {G}}\). As is standard, the view of \(\mathsf{A}\) consists of its randomness, its input, and all incoming messages that it receives throughout the game (if any such messages exist). Moreover, for an additional fixed vector \(\vec {w}\) of elements in \(\mathbb {Z}_p\), we denote by \(\left[ \mathsf{View}_{\mathsf{A}}^{\mathbf{G}_{\mathcal {G}}}\right] _{supp(\vec {w})}\) the random variable obtained from \(\mathsf{View}_{\mathsf{A}}^{\mathbf{G}_{\mathcal {G}}}\) by omitting all group elements whose corresponding entry in \(\vec {w}\) is 0 (where the ith group element observed by \(\mathsf{A}\) is naturally associated with the ith entry of \(\vec {w}\)). That is, for a fixed vector \(\vec {w}\) of k group elements, the distribution associated with \(\left[ \mathsf{View}_{\mathsf{A}}^{\mathbf{G}_{\mathcal {G}}}\right] _{supp(\vec {w})}\) is defined by first sampling a view V according to \(\mathsf{View}_{\mathsf{A}}^{\mathbf{G}_{\mathcal {G}}}\); and then for each \(i \in [\min \{k,m\}]\) for which \(w_i = 0\), replacing the ith group element in V with the unique erasure symbol \(\bot \), where m is the number of group elements in V. Hence, fixing \(\vec {w}\), the random variable \(\left[ \mathsf{View}_{\mathsf{A}}^{\mathbf{G}_{\mathcal {G}}}\right] _{supp(\vec {w})}\) is defined over the randomness of \(\mathsf{A}\) and of the challenger in \(\mathbf{G}_{\mathcal {G}}\). For two random variables \(X_1\) and \(X_2\), we use the notation \(X_1 \not \equiv X_2\) to indicate that \(X_1\) and \(X_2\) are not identically distributed.
Definition 3.1
Let \({\mathcal {G}} = (\mathbb {G},p ,g)\) be a description of a cyclic group. An algorithm \(\mathsf{A}\) participating in an algebraic game with parameters \({\mathcal {G}}\) is said to be algebraic if it is computationally-algebraic (per Definition 2.1) and in addition, whenever \(\mathsf{A}\) outputs either the \(\mathsf{Acc}\) or the \(\mathsf{Rej}\) symbols, it also outputs a vector \(\vec {w}\) of elements in \(\mathbb {Z}_p\) such that the following conditions hold:
-
1.
\(\prod _{i=0}^{k} \mathbf{X}_i^{w_i} = 1_{\mathbb {G}}\), where \(\mathbf{X}_1,\ldots , \mathbf{X}_k\) are the group elements that \(\mathsf{A}\) has received so far in the game, \(\mathbf{X}_0 = g\) and \(1_{\mathbb {G}}\) is the identity element of \(\mathbb {G}\).
-
2.
For any two decisional algebraic games \(\mathbf{G}\) and \(\mathbf{G'}\), there exists \(\mathbf{H} \in \{ \mathbf{G}, \mathbf{G'} \}\) such that
$$\begin{aligned} \Pr _{\vec {w}} \left[ \left[ \mathsf{View}_{\mathsf{A}}^{\mathbf{G}_{\mathcal {G}}}\right] _{supp(\vec {w})} \not \equiv \left[ \mathsf{View}_{\mathsf{A}}^{\mathbf{G'}_{\mathcal {G}}}\right] _{supp(\vec {w})} \right] \ge \frac{\epsilon }{t^2}, \end{aligned}$$where \(\epsilon = \mathbf {Adv}_{\mathsf{A}}^{\mathbf{G}_{\mathcal {G}}, \mathbf{G'}_{\mathcal {G}}}\), \(t = \mathbf {Time}^{\mathbf{H}_{\mathcal {G}}}_{\mathsf{A}}\) and the probability is taken over the choice of \(\vec {w}\) induced by a random execution of \(\mathbf{H}_{\mathcal {G}}\) with \(\mathsf{A}\).
We clarify that the probability in the second condition of Definition 3.1 is over the choice of vector \(\vec {w}\) in a random execution of \(\mathbf{H}_{\mathcal {G}}\) with \(\mathsf{A}\); meaning, it is taken over the randomness of \(\mathsf{A}\) and of the challenger in \(\mathbf{H}_{\mathcal {G}}\). The event inside the probability means that for the chosen \(\vec {w}\), the random variable \(\left[ \mathsf{View}_{\mathsf{A}}^{\mathbf{G}_{\mathcal {G}}}\right] _{supp(\vec {w})}\) is distributed differently than the random variable \(\left[ \mathsf{View}_{\mathsf{A}}^{\mathbf{G'}_{\mathcal {G}}}\right] _{supp(\vec {w})}\).
Intuitively, whenever an algebraic algorithm accepts or rejects in an algebraic game, it also produces a zero test, defined by the vector \(\vec {w}\), which is passed by the group elements that the algorithm has observed during the game. Of course, such a zero test can always be produced by simply setting the vector \(\vec {w}\) to be the all zeros vector.
One possible way to mend this situation is by requiring that whenever an algebraic algorithm accepts (by outputting the symbol Acc), the vector \(\vec {w}\) which it outputs has to be non-zero. Alas, this approach suffers from two caveats. Firstly, this requirement is unrealistic, as an algorithm can always accept even without “having knowledge” of such a non-zero vector \(\vec {w}\). Concretely, following Fuchsbauer et al. [FKL18], we aim to have a definition which distills some fundamental algebraic principle from many hardness results in the generic group model; while simultaneously getting rid of the unrealistic assumption that algorithms are oblivious to the concrete representation of group elements. Secondly, the intuition behind Definition 3.1 is that the vector \(\vec {w}\) serves as a “witness” which explains the adversary’s decision and differentiates between the two games (just like the vector \(\vec {z}\) in the definition of Fuchsbauer et al. – Definition 2.1 – serves as a witness which explains how the algorithm has come up with the group element \(\mathbf{Z}\)). Therefore, it is not enough to ask that \(\vec {w}\ne \vec {0}\), since even then it might be that the joint distribution of the group elements in the support of \(\vec {w}\) is identical in both games, rendering the zero test associated with \(\vec {w}\) useless in distinguishing between them.
The second condition in Definition 3.1 accommodates these two lines of reasoning. It is descriptive of generic group algorithms (see Sect. 3.3 for further details; this also sheds light as to where the term \(t^2\) comes from), and it makes sure that the views of the adversary in both games remain different even when projected onto the support of \(\vec {w}\). Theoretically speaking, it still might be the case that the zero test associated \(\vec {w}\) passes with equal probabilities in both games,Footnote 3 but we are not aware of a natural construction or assumption for which this is the case, and in particular for the applications of the model presented in this paper the second condition of Definition 3.1 is sufficient. Hence, we opted not to strengthen our definition beyond that. We do believe however, that if one finds an application for which it is necessary to require that the zero test associated \(\vec {w}\) passes with distinct probabilities in both games, then such a strengthening of the definition is justifiable.
3.3 Generic Algorithms Are Algebraic
Our definition of algebraic algorithms fits the intuition provided by Fuchsbauer et al. [FKL18] according to which the algebraic group model “lies in between the standard model and the generic group model”. Informally, the generic group model captures algorithms that do not exploit the representation of the underlying group in any way, and as such, they should perform identically among all groups which are isomorphic to each other.
This intuition is typically formalized by withholding the group description from the generic algorithm and supplying it only with the group order p. The concrete representation of group elements is then replaced with some representation-independent handle (a random label in Shoup’s model [Sho97] and an opaque “pointer” in Maurer’s model [Mau05]). Group operations are performed via queries to an oracle which curates the “true values” behind the handles.
Fuchsbauer et al. observed that any generic algorithm for a computational problem is an algebraic algorithm according to their framework (recall Sect. 2). Here, we show that our framework enables in addition to capture generic algorithms for decisional problems, thus providing a unified framework for relaxing the somewhat too-strict generic group model. This is captured by the following informal proposition.
Proposition 3.2
Let \({\mathcal {G}} = (\mathbb {G}, p, g)\) be a description of cyclic group, and let \(\mathbf{G}_0\) and \(\mathbf{G}_1\) be decisional algebraic games. Let \(\mathsf{A}_{\mathsf{gen}}\) be a generic algorithm that distinguishes between \(\mathbf{G}_0\) and \(\mathbf{G}_1\) with advantage \(\epsilon = \epsilon (p)\) in time \(t = t(p)\). Then, there exists an algebraic algorithm \(\mathsf{A}_{\mathsf{alg}}\) such that \(\mathbf {Adv}_{\mathsf{A}_{\mathsf{Alg}}}^{\mathbf{G}_{0,\mathcal {G}}, \mathbf{G}_{1,\mathcal {G}}} \approx \epsilon \) and \(\mathsf{A}_{\mathsf{Alg}}\) runs in time \(\approx t\).
The proof of Proposition 3.2 is based on the fact that the algebraic algorithm \(\mathsf{A}_{\mathsf{alg}}\) can run the generic algorithm \(\mathsf{A}_{\mathsf{gen}}\) and return the same output, while simulating the generic group oracle to \(\mathsf{A}_{\mathsf{gen}}\). This simulation relies on the following two well-established observations resulting from the fact that \(\mathsf{A}_{\mathsf{gen}}\) is a generic algorithm:
-
1.
For any group element \(\mathbf{Y}\) which \(\mathsf{A}_{\mathsf{gen}}\) computes throughout the game, \(\mathsf{A}_{\mathsf{alg}}\) can produce a representation of \(\mathbf{Y}\) as \(\prod _{i} \mathbf{X}_i^{v_i}\), where \(\{\mathbf{X}_i\}_{i}\) are the group elements which \(\mathsf{A}_{\mathsf{gen}}\) has observed so far and \(\{v_i\}_{i}\) are values in \(\mathbb {Z}_p\) known to \(\mathsf{A}_{\mathsf{alg}}\).
-
2.
Since the access that \(\mathsf{A}_{\mathsf{gen}}\) has to the group is representation independent, the only useful information it acquires throughout the game is the equality pattern among the group elements that it receives or produces during the game. Hence, in order to distinguish between \(\mathbf{G}_0\) and \(\mathbf{G}_1\) with advantage \(\epsilon \), there must exist an equality relation which occurs in one game with probability which is greater by at least \(\epsilon \) than the probability that this equality relation occurs in the other game. In particular, such an equality relation occurs with probability at least \(\epsilon \).
Once \(\mathsf{A}_{\mathsf{gen}}\) terminates, \(\mathsf{A}_{\mathsf{alg}}\) can choose at random one pair of elements out of all pairs of equal elements that arose throughout the computation, allowing repetition (that is, \(\mathsf{A}_{\mathsf{alg}}\) may chose the same element twice, so there is always at least one pair of equal elements). Let the representation of these two equal elements be \(\prod _{i} \mathbf{X}_i^{v_i}\) and \(\prod _{i} \mathbf{X}_i^{v'_i}\). The vector \(\vec {w}\) which \(\mathsf{A}_{\mathsf{alg}}\) outputs together with its decision symbol is then defined by \(w_i = v_i - v'_i\) for each i. The fact that the two group elements are equal guarantees that \(\prod _{i}\mathbf{X}_i^{w_i}= 1_{\mathbb {G}}\) (this guarantees the first requirement of Definition 3.1). Moreover, there exists a bit \(b\in \{0,1\}\), such that with probability at least \(\epsilon \) the list of elements produced by \(\mathsf{A}_{\mathsf{gen}}\) in \(\mathbf{G}_b\) includes a pair \(\prod _{i} \mathbf{X}_i^{v_i}\) and \(\prod _{i} \mathbf{X}_i^{v'_i}\) such that \(\left[ \mathsf{View}_{\mathsf{A}_{\mathsf{alg}}}^{\mathbf{G}_{0,\mathcal {G}}}\right] _{supp(\vec {w})} \not \equiv \left[ \mathsf{View}_{\mathsf{A}_{\mathsf{alg}}}^{\mathbf{G}_{1,\mathcal {G}}}\right] _{supp(\vec {w})} \) (for \(\vec {w} = \vec {v} - \vec {v'}\)). This is due to the fact that there exists \(b\in \{0,1\}\) for which some equality has to arise \(\mathbf{G}_b\) with probability which is greater by \(\epsilon \) than in \(\mathbf{G}_{1-b}\). Finally, conditioned on such a pair being present in the list of elements produced by \(\mathsf{A}_{\mathsf{gen}}\), the probability that \(\mathsf{A_{alg}}\) chooses it is at least \(1/t^2\), since \(\mathsf{A}_{\mathsf{gen}}\) produces at most t group elements; meaning there are at most \(t^2\) pairs of elements (this guarantees the second requirement of Definition 3.1).
4 Warm-Up: The Algebraic Equivalence of DDH and DLog
As a first example for the usefulness of our new framework, we show that the hardness of the Decisional Diffie-Hellman problem with respect to algebraic distinguishers is implied by that of the Discrete Logarithm problem. Recall that the Discrete Logarithm and Decisional Diffie-Hellman problems are defined via the computational algebraic game \(\mathbf{DLOG}_{\mathcal {G}}\) and the decisional algebraic game \(\mathbf{DDH}_{\mathcal {G}}\) described in Figs. 1 and 2, respectively. We prove the following theorem:
Theorem 4.1
Let \({\mathcal {G}} = (\mathbb {G}, p, g)\) be a description of a cyclic group. For any algebraic algorithm \(\mathsf{A}\) there exists an algorithm \(\mathsf{B}\) such that \(\mathbf {Adv}_{\mathsf{B}}^{\mathbf{DLOG}_{\mathcal {G}}} \ge \epsilon /(4\cdot t^2)\) and \(\mathbf {Time}_{\mathsf{B}}^{\mathbf{DLOG}_{\mathcal {G}}} \le t + \mathsf {poly}(\log p)\), where \(\epsilon = \mathbf {Adv}_{\mathsf{A}}^{\mathbf{DDH}_{{\mathcal {G}}}}\) and \(t=\mathbf {Time}_{\mathsf{A}}^{\mathbf{DDH}_{{\mathcal {G}}}}\).
Note that Theorem 4.1 implies an equivalence between the algebraic hardness of the Decisional Diffie-Hellman problem and the hardness of the Discrete Logarithm problem. Informally, given as input (in addition to \({\mathcal {G}}\)) a triplet of group elements \((\mathbf{X, Y, Z})\) and (black-box) access to an algorithm \(\mathsf{A}_\mathbf{DLOG}\) breaking the Discrete Log problem, an algebraic distinguisher \(\mathsf{A}_\mathbf{DDH}\) can be defined as follows. First, it invokes \(\mathsf{A}_\mathbf{DLOG}\) on \(\mathbf{X}\) to retrieve its potential discrete logarithm x, and then checks whether \(\mathbf{Z} = \mathbf{Y}^{x}\). If so, it accepts and outputs the vector \(\vec {w} = (x, -1,-x,1)\), and if not (or if \(\mathsf{A}_\mathbf{DLOG}\) fails), it rejects and outputs \(\vec {w}= \vec {0}\). This straightforward algorithm satisfies our two requirements specified in Definition 3.1 (note that a similar algorithm that outputs the vector \(\vec {w} = (0, 0,-x,1)\) instead of the vector \(\vec {w} = (x, -1,-x,1)\) would satisfy our first requirement but not our second one).
Proof of Theorem 4.1. Let \(\mathsf{A}\) be an algebraic algorithm participating in the game \(\mathbf{DDH}_{{\mathcal {G}},b}\) for \(b\in \{0,1\}\). We construct an algorithm \(\mathsf{B}\) participating in \(\mathbf{DLOG}_{\mathcal {G}}\).

Let \(\epsilon := \mathbf {Adv}_{\mathsf{A}}^{\mathbf{DDH}_{{\mathcal {G}}}}\) and \(t := \mathbf {Time}_{\mathsf{A}}^{\mathbf{DDH}_{{\mathcal {G}}}}\). By our definition of an algebraic algorithm, there exists a bit \(b^*\in \{0,1\}\) such that
where the probability is taken over the choice of \(\vec {w}\) induced by a random execution of \({\mathbf{DDH}_{{\mathcal {G}},b^*}}\) with \(\mathsf{A}\). Say that the vector \(\vec {w}\) outputted by \(\mathsf{A}\) is good if \(0 \not \in \{w_1,w_2,w_3\}\), where \(w_1,w_2,w_3\) are the entries of \(\vec {w}\) which correspond to the three group elements that \(\mathsf{A}\) receives as inputs. The predicate inside the probability is satisfied if and only if \(\vec {w}\) is good; hence, \(\Pr \left[ \vec {w} \text { is good} \right] \ge {\epsilon }/{t^2}\) over a random execution of \({\mathbf{DDH}_{{\mathcal {G}},b^*}}\) with \(\mathsf{A}\).
Denote by \(\mathsf{Hit}\) the event in which the bit \(b = b^*\), where b is the bit chosen by \(\mathsf{B}\) in Step 1. Regardless of the value of \(b^*\), it holds that \(\Pr \left[ \mathsf{Hit} \right] = 1/2\), and that  since conditioned on \(\mathsf{Hit} \), \(\mathsf{B}\) perfectly simulates the game \({\mathbf{DDH}_{{\mathcal {G}},b^*}}\) to \(\mathsf{A}\). Consider two cases:
since conditioned on \(\mathsf{Hit} \), \(\mathsf{B}\) perfectly simulates the game \({\mathbf{DDH}_{{\mathcal {G}},b^*}}\) to \(\mathsf{A}\). Consider two cases:
-
1.
If \(b^*= 0\): In this case, when \(\vec {w}\) is good and \(\mathsf{Hit}\) occurs, the linear equation \(X \cdot w_1 +w_0 + w_2 \cdot y + w_3 \cdot z = 0\) in the indeterminate X has a unique solution \(X = x^*\) and this is the output of \(\mathsf{B}\). Moreover, by the requirement \(g^{w_0} \cdot \mathbf{X}^{w_1} \cdot \mathbf{Y}^{w_2} \cdot \mathbf{Z}^{w_3} = 1_{\mathbb {G}}\), it holds that \(g^{x^*} = \mathbf{X}\). Therefore,

-
2.
If \(b^*= 1\): Let C be the random variable describing the bit c sampled by \(\mathsf{B}\) in Step 3(b), and let \(\mathsf{E}\) denote the event in which \(w_1 + w_3 \cdot \widetilde{y} = 0\) in an execution of \({\mathbf{DDH}_{{\mathcal {G}},1}}\) with \(\mathsf{A}\), where \(g^{\widetilde{y}}\) is the group element given as the second input to \(\mathsf{A}\) in the game. On the one hand, when \(\vec {w}\) is good and \(\overline{\mathsf{E}}\) and \(\mathsf{Hit}\) occur, the linear equation \(X \cdot (w_1 + w_3\cdot \widetilde{y}) +w_0 + w_2 \cdot \widetilde{y} + w_3 \cdot z = 0\) in the indeterminate X has a unique solution \(X = x^*\). Moreover, conditioned also on \(C =0\), this is the output of \(\mathsf{B}\), and by the requirement \(g^{w_0} \cdot \widetilde{\mathbf{X}}^{w_1} \cdot \widetilde{\mathbf{Y}}^{w_2} \cdot \mathbf{Z}^{w_3} = 1_{\mathbb {G}}\), it holds that \(g^{x^*} = \mathbf{X}\). Hence,
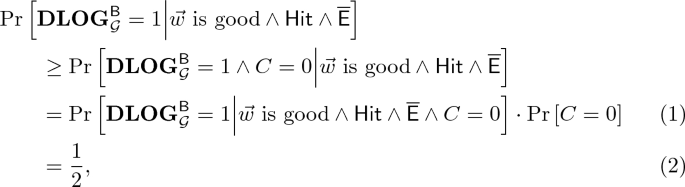
where (1) follows from the fact that the bits b and c that \(\mathsf{B}\) samples are chosen independently, and since the view of \(\mathsf{A}\) as invoked by \(\mathsf{B}\) is independent of the bit c, and hence the events \(\mathsf{E}\) and \(\vec {w}\) is good are independent of the event \(C =0\). On the other hand, when \(\vec {w}\) is good, the linear equation \(X \cdot w_3 + w_1 = 0\) in the indeterminate X has a unique solution \(X = x^*\). Moreover, conditioned on \(\mathsf{Hit}\) and on \(C=1\), this \(x^*\) is the output of \(\mathsf{B}\), and conditioned on \(\mathsf{E}\), it also holds that \(g^{x^*} = \mathbf{X}\). It follows that,
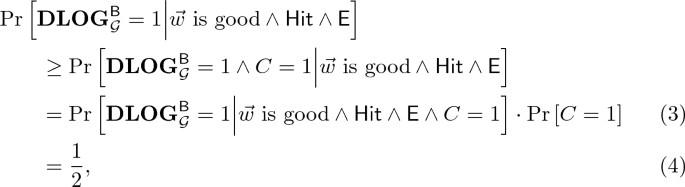
where (3) holds for the same reasons as (1). Putting (2) and (4) together,
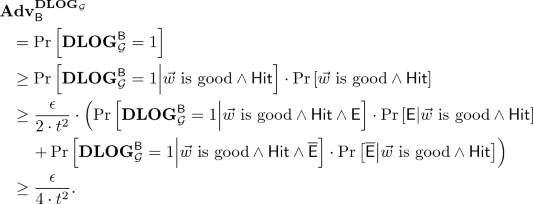
This concludes the proof of Theorem 4.1.

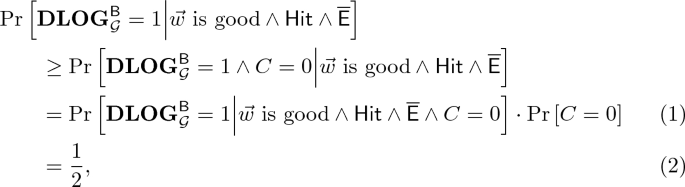
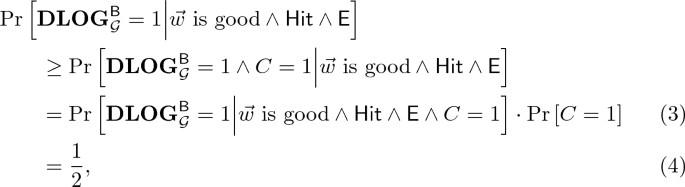
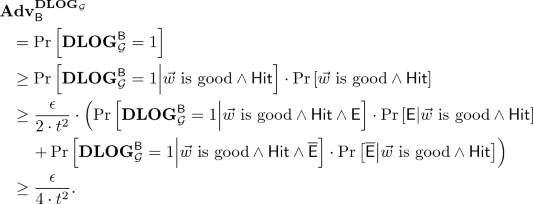
\(\square \)
5 The Algebraic Hardness of the Uber Family of Decisional Problems
In this section we prove that the hardness of the Uber family of decisional problems in bilinear groups [BBG05, Boy08] with respect to algebraic distinguishers is equivalent to that of the computational q-discrete logarithm problem, for an appropriate choice of q, in the source group (we formally define these assumptions in Sect. 5.2).
5.1 Algebraic Algorithms in Bilinear Groups
Before presenting our main theorem for this section, we first need to extend our framework to bilinear groups. We focus on symmetric bilinear groups for ease of presentation, but the definitions in this section easily generalize to capture asymmetric pairings as well. An algebraic game which is defined with respect to a symmetric bilinear group is parameterized by a group description of the form \({\mathcal {G}} = (\mathbb {G}, \mathbb {G}_T, p, g, e)\), where \(\mathbb {G}\) and \(\mathbb {G}_T\) are both cyclic groups of order p, g is a generator of \(\mathbb {G}\), and \(e : \mathbb {G} \times \mathbb {G} \rightarrow \mathbb {G}_T\) is a non-degenerate bilinear map. We will often use the notation \(g_T : = e(g,g)\).
Mizuide et al. [MTT19] extended the definition of Fuchsbauer et al. [FKL18] of computationally-algebraic algorithms to the setting of symmetric bilinear groups. We start by reviewing their definition (with slight notational modifications).
Definition 5.1
Let \({\mathcal {G}} = (\mathbb {G}, \mathbb {G}_T, p, g, e)\) be a description of a symmetric bilinear group. An algorithm \(\mathsf{A}\) participating in an algebraic game with parameters \({\mathcal {G}}\) is said to be computationally-algebraic if:
-
1.
Whenever \(\mathsf{A}\) outputs a group element \(\mathbf{Z} \in \mathbb {G}\), it also outputs a vector \(\vec {z}\) of elements in \(\mathbb {Z}_p\) such that \(\mathbf{Z} = \prod _{i=0}^{k} \mathbf{X}_i^{z_i}\), where \(\mathbf{X}_1,\ldots , \mathbf{X}_k\) are the elements of \(\mathbb {G}\) that \(\mathsf{A}\) has received so far in the game and \(\mathbf{X}_0 = g\).
-
2.
Whenever \(\mathsf{A}\) outputs a group element \(\mathbf{V} \in \mathbb {G}_T\), it also outputs vectors \(\vec {v}\) and \(\vec {v'}\) of elements in \(\mathbb {Z}_p\) such that \(\mathbf{V} = \prod _{0 \le i \le j \le k} e\left( \mathbf{X}_i, \mathbf{X}_j\right) ^{v_{k\cdot i + j}} \cdot \prod _{i=1}^{\ell } \mathbf{Y}_i^{v'_i}\), where \(\mathbf{X}_1,\ldots , \mathbf{X}_k\) are the elements of \(\mathbb {G}\) and \(\mathbf{Y}_1,\ldots , \mathbf{Y}_\ell \) are the elements of \(\mathbb {G}_T\) that \(\mathsf{A}\) has received so far in the game and \(\mathbf{X}_0 = g\).
Before defining fully-algebraic algorithms in bilinear groups, we introduce some additional notation. The random variable \(\mathsf{View}_{\mathsf{A}}^{\mathbf{G}_{\mathcal {G}}}\) is defined analogously to its definition in Sect. 3.2. For vectors \(\vec {v}\) and \(\vec {v'}\), we denote by \(\left[ \mathsf{View}_{\mathsf{A}}^{\mathbf{G}_{\mathcal {G}}}\right] _{supp(\vec {v}, \vec {v'})}\) the random variable obtained from \(\mathsf{View}_{\mathsf{A}}^{\mathbf{G}_{\mathcal {G}}}\) by:
-
1.
Omitting each element of \(\mathbb {G}\) for which all of the corresponding entries in \(\vec {v}\) are 0. That is, we omit the ith element of \(\mathbb {G}\) that \(\mathsf{A}\) observes if for all \(j\ge i\) it holds that \(v_{k\cdot i + j} = 0\) and for all \(0 \le j < i\) it holds that \(v_{k\cdot j + i} = 0\) (where k is the number of elements of \(\mathbb {G}\) that \(\mathsf{A}\) observes in the game).
-
2.
Omitting all elements of \(\mathbb {G}_T\) whose corresponding entry in \(\vec {v'}\) is 0 (where the ith element of \(\mathbb {G}_T\) observed by \(\mathsf{A}\) is naturally associated with the ith entry of \(\vec {v'}\)).
Definition 5.2
Let \({\mathcal {G}} = (\mathbb {G}, \mathbb {G}_T, p, g, e)\) be a description of a symmetric bilinear group. An algorithm \(\mathsf{A}\) participating in an algebraic game with parameters \({\mathcal {G}}\) is said to be algebraic if it is computationally-algebraic (per Definition 5.1) and in addition, whenever \(\mathsf{A}\) outputs either the \(\mathsf{Acc}\) or the \(\mathsf{Rej}\) symbols, it also outputs a pair \((\vec {v},\vec {v'})\) of vectors of elements in \(\mathbb {Z}_p\) such that the following conditions hold:
-
1.
\(\prod _{0 \le i \le j \le k} e\left( \mathbf{X}_i, \mathbf{X}_j\right) ^{v_{k\cdot i + j}} \cdot \prod _{i=1}^{\ell } \mathbf{Y}_i^{v'_i} = 1_{\mathbb {G}_T}\), where \(\mathbf{X}_1,\ldots , \mathbf{X}_k\) are the elements of \(\mathbb {G}\) and \(\mathbf{Y}_1,\ldots , \mathbf{Y}_\ell \) are the elements of \(\mathbb {G}_T\) that \(\mathsf{A}\) has received so far in the game, and \(1_{\mathbb {G}_T}\) is the identity element in \(\mathbb {G}_T\).
-
2.
For any two decisional algebraic games \(\mathbf{G}\) and \(\mathbf{G'}\), there exists \(\mathbf{H} \in \{ \mathbf{G}, \mathbf{G'} \}\) such that
$$\begin{aligned} \Pr _{\left( \vec {v},\vec {v'}\right) } \left[ \left[ \mathsf{View}_{\mathsf{A}}^{\mathbf{G}_{\mathcal {G}}}\right] _{supp(\vec {v},\vec {v'})} \not \equiv \left[ \mathsf{View}_{\mathsf{A}}^{\mathbf{G'}_{\mathcal {G}}}\right] _{supp(\vec {v},\vec {v'})} \right] \ge \frac{\epsilon }{t^2}, \end{aligned}$$where \(\epsilon = \mathbf {Adv}_{\mathsf{A}}^{\mathbf{G}_{\mathcal {G}}, \mathbf{G'}_{\mathcal {G}}}\), \(t = \mathbf {Time}^{\mathbf{H}_{\mathcal {G}}}_{\mathsf{A}}\) , and the probability is taken over the choice of \(\left( \vec {v},\vec {v'}\right) \) induced by a random execution of \(\mathbf{H}_{\mathcal {G}}\) with \(\mathsf{A}\).
5.2 Algebraic Equivalence of the Uber and q-DLOG Problems
Before presenting the main reduction of this section, we first define the q-discrete logarithm problem and the Uber family of decisional problems [BBG05, Boy08]. The q-discrete logarithm problem is a parameterized generalization of the discrete logarithm problem, in which the adversary receives \(\left( g^{x^i}\right) _{i\in \{0,\ldots ,q\}}\) and needs to compute x. The “Uber assumption” is a family of decisional assumptions in bilinear maps: It is parameterized by two tuples of m-variate polynomials \(\vec {r} = (r_1,\ldots , r_t)\) and \(\vec {s} = (s_1,\ldots ,s_t)\) and an m-variate polynomial f; each choice of \(\vec {r}, \vec {s}\) and f yields a specific assumption. Roughly, the assumption states that given \(g^{r_1(x_1,\ldots ,x_m)},\ldots , g^{r_t(x_1,\ldots ,x_m)}\) and \(g_T^{s_1(x_1,\ldots ,x_m)},\ldots , g_T^{s_t(x_1,\ldots ,x_m)}\), it is difficult to distinguish between \(g_T^{f(x_1,\ldots ,x_m)}\) and a uniformly-random element in \(\mathbb {G}_T\) for a uniform choice of \(x_1,\ldots ,x_m\) in \(\mathbb {Z}_p\). Both assumptions are formally defined via the algebraic games q -DLOG and \((\vec {r},\vec {s}, f)\) -UBER in Fig. 3.

The game q-\(\mathbf{DLOG}_{\mathcal {G}}^{\mathsf{A}}\) (on the left) captures the q-Discrete Logarithm assumption; and the game \((\vec {r},\vec {s}, f)\)-UBER\(_{{\mathcal {G}},b}^{\mathsf{A}}\) (on the right) defines the Uber assumption of Boneh, Boyen and Goh [BBG05] parameterized by a triplet \((\vec {r},\vec {s},f)\) where \(\vec {r}\) and \(\vec {s}\) are vectors of m-variate polynomials and f is an m-variate polynomial. The notation \(\vec {\mathbf{X}} := g^{\vec {r}(x_1,\ldots ,x_m)}\) is a shorthand for \(\vec {\mathbf{X}}: = (g^{r_1(x_1,\ldots ,x_m)},\ldots ,g^{r_t(x_1,\ldots ,x_m)})\) and the notation \(\vec {\mathbf{Y}}:= g_T^{\vec {s}(x_1,\ldots ,x_m)}\) is defined similarly. Both games are defined relative to a bilinear group \({\mathcal {G}} = (\mathbb {G},\mathbb {G}_T, p, g, e)\) and an adversary \(\mathsf{A}\). The q-\(\mathbf{DLOG}\) game in bilinear groups is the same as the game defined in Sect. 2, when considering the discrete logarithm to the source group.
Note that there are choices of \(\vec {r}, \vec {s}\) and f for which the \((\vec {r},\vec {s}, f)\)-UBER game can be easily won. If given access to \(g^{\vec {r}(X_1,\ldots , X_m)}\) and to \(g_T^{\vec {s}(X_1,\ldots ,X_m)}\), one can obtain \(g_T^{f(X_1,\ldots ,X_m)}\) through a sequence of group operations and bilinear map operations (where \(X_i\) is a indeterminate replacing \(x_i\)), then one can distinguish between the case where \(b = 0\) and the case where \(b = 1\) by comparing \(g_T^{f(X_1,\ldots ,X_m)}\) to \(\mathbf{Z}\). To rule out such trivial attacks, Boneh et al. introduced the following definition.
Definition 5.3
Let \(p \in \mathbb {N}\) be a prime, let \(t,m \in \mathbb {N}\), let \(\vec {r},\vec {s} \in \left( \mathbb {F}_p[X_1,\ldots ,X_m]\right) ^t\) be t-tuples of polynomials such that \(r_1 = s_1 = 1\), and let \(f\in \mathbb {F}[X_1,\ldots ,X_m]\) be a polynomial. We say that f is dependent on \((\vec {r},\vec {s})\) if there exist integers \(\{\alpha _{i,j}\}_{0\le i \le j \le t}\) and \(\{\beta _{k} \}_{k\in [t]}\) such that
If f is not dependent on \((\vec {r},\vec {s})\), we say that it is independent of \((\vec {r},\vec {s})\).
Observe, that we can only hope to reduce \((\vec {r},\vec {s}, f)\)-UBER to q -DLOG for triplets \((\vec {r},\vec {s}, f)\) such that f is independent of \((\vec {r},\vec {s})\). The following theorem, which is the main result of this section, states that such a reduction in fact applies to any such triplet \((\vec {r},\vec {s}, f)\).
Theorem 5.4
Let \({\mathcal {G}} = (\mathbb {G}, \mathbb {G}_T, p, g, e)\) be a description of a symmetric bilinear group, let \(t,m \in \mathbb {N}\), let \(\vec {r},\vec {s} \in \left( \mathbb {F}_p[X_1,\ldots ,X_m]\right) ^t\) be t-tuples of polynomials of degree at most d, and let \(f\in \mathbb {F}[X_1,\ldots ,X_m]\) be a polynomial of degree at most d which is independent of \((\vec {r}, \vec {s})\). Then, for any algebraic algorithm \(\mathsf{A}\) there exists an algebraic algorithm \(\mathsf{B}\) such that \(\mathbf {Adv}_{\mathsf{B}}^{q\mathbf{\text {-}DLOG}_{\mathcal {G}}} \ge \epsilon /(4\cdot T^2) - {d\cdot (t^2 +t +2)}/(8\cdot p)\) and \(\mathbf {Time}_{\mathsf{B}}^{q\mathbf{\text {-}DLOG}_{\mathcal {G}}} \le T + \mathsf {poly}(m,t,d,\log p)\), where \(q = d\cdot (t^2+t+2)/2\), \(\epsilon = \mathbf {Adv}_{\mathsf{A}}^{{(\vec {r},\vec {s}, f)\text {-}{} \mathbf{UBER}}_{{\mathcal {G}}}}\) and \(T = \mathbf {Time}_{\mathsf{A}}^{{(\vec {r},\vec {s}, f)\text {-}\mathbf{UBER}}_{{\mathcal {G}}}}\).
As a first step towards proving Theorem 5.4, we define an intermediate assumption which we call the “Randomized Univariate Uber Assumption”. This assumption is obtained from \((\vec {r},\vec {s}, f)\)-UBER by the following modification: Instead of sampling \(x_1,\ldots , x_m\) uniformly at random from \(\mathbb {Z}_p\), the challenger samples a single \(x \leftarrow \mathbb {Z}_p\) alongside m random polynomials \(c_1,\ldots , c_m\), and sets \(x_i := c_i(x)\). The Randomized Univariate Uber assumption is formalized via the game \((\vec {r},\vec {s}, f)\)-RUU described in Fig. 4.

The game \((\vec {r},\vec {s}, f)\)-RUU\(_{{\mathcal {G}},b}^{\mathsf{A}}\) which captures our Randomized Univariate Uber assumption. The assumption is parameterized by a triplet \((\vec {r},\vec {s},f)\) where \(\vec {r}\) and \(\vec {s}\) are vectors of m-variate polynomials and f is an m-variate polynomial. The game is defined relative to a bilinear group \({\mathcal {G}} = (\mathbb {G},\mathbb {G}_T, p, g, e)\) and an adversary \(\mathsf{A}\).
The following lemma follows from the work of Ghadafi and Groth [GG17], and reduces the security of the Uber assumption to that of the Randomized Univariate Uber assumption.
Lemma 5.5
([GG17]). Let \({\mathcal {G}} = (\mathbb {G}, \mathbb {G}_T, p, g, e)\) be a description of a symmetric bilinear group, let \(t,m \in \mathbb {N}\), let \(\vec {r},\vec {s} \in \left( \mathbb {F}_p[X_1,\ldots ,X_m]\right) ^t\) be t-tuples of polynomials of degree at most d, and let \(f\in \mathbb {F}[X_1,\ldots ,X_m]\) be a polynomial which is independent of \((\vec {r}, \vec {s})\). Then, the following holds:
-
1.
For any algebraic algorithm \(\mathsf{A}\) there exists an algebraic algorithm \(\mathsf{B}\) such that
$$\begin{aligned} \mathbf {Adv}_{\mathsf{B}}^{{(\vec {r},\vec {s}, f)\text {-}\mathbf{RUU}}_{\mathcal {G}}} = \mathbf {Adv}_{\mathsf{A}}^{{(\vec {r},\vec {s}, f)\text {-}{} \mathbf{UBER}}_{{\mathcal {G}}}} \end{aligned}$$and
$$\begin{aligned} \mathbf {Time}_{\mathsf{B}}^{{(\vec {r},\vec {s}, f)\text {-}\mathbf{RUU}}_{\mathcal {G}}} \le \mathbf {Time}_{\mathsf{A}}^{{(\vec {r},\vec {s}, f)\text {-}{} \mathbf{UBER}}_{{\mathcal {G}}}} + \mathsf {poly}(m,t, \log p). \end{aligned}$$ -
2.
With probability at least \(1-d\cdot (t^2+t+2)/(2\cdot p)\) over the choice of \(c_1,\ldots , c_m\), the univariate polynomial \(f(\vec {c}(X))\) is independent of \((\vec {r'},\vec {s'})\), where \(\vec {c}(X) = (c_1(X),\ldots ,c_m(X))\), \(\vec {r'} = (r_1(\vec {c}(X)), \ldots , r_t(\vec {c}(X)))\) and \(\vec {s'} = (s_1(\vec {c}(X)), \ldots , s_t(\vec {c}(X)))\).
We note that there are some small technical differences between the theorem proven by Ghadafi and Groth and Lemma 5.5. Ghadafi and Groth deal with a computational variant of the Uber assumption, in which the adversary can choose the polynomial f.Footnote 4 Additionally, they do not consider algebraic adversaries. We stress, however, that their reduction readily applies to imply Lemma 5.5.Footnote 5
The main part of the proof of Theorem 5.4 is consists of the following lemma which reduces the security of the randomized univariate Uber assumption (against algebraic adversaries) to the security of the q-DLOG assumption. Together with Lemma 5.5, this immediately implies Theorem 5.4.
Lemma 5.6
Let \({\mathcal {G}} = (\mathbb {G}, \mathbb {G}_T, p, g, e)\) be a description of a symmetric bilinear group, let \(t,m \in \mathbb {N}\), let \(\vec {r},\vec {s} \in \left( \mathbb {F}_p[X_1,\ldots ,X_m]\right) ^t\) be t-tuples of polynomials of degree at most d, and let \(f\in \mathbb {F}[X_1,\ldots ,X_m]\) be a polynomial of degree at most d which is independent of \((\vec {r}, \vec {s})\). Then, for any algebraic algorithm \(\mathsf{A}\) there exists an algebraic algorithm \(\mathsf{B}\) such that \(\mathbf {Adv}_{\mathsf{B}}^{q\mathbf{\text {-}DLOG}_{\mathcal {G}}} \ge \epsilon /(4\cdot T^2) - {d\cdot (t^2 +t +2)}/(8\cdot p)\) and \(\mathbf {Time}_{\mathsf{B}}^{q\mathbf{\text {-}DLOG}_{\mathcal {G}}} \le T + \mathsf {poly}(d,t,\log p)\), where \(q = d\cdot (t^2+t+2)/2\), \(\epsilon = \mathbf {Adv}_{\mathsf{B}}^{{(\vec {r},\vec {s}, f)\text {-}{} \mathbf{RUU}}_{\mathcal {G}}}\) and \(T = \mathbf {Time}_{\mathsf{B}}^{{(\vec {r},\vec {s}, f)\text {-}\mathbf{RUU}}_{\mathcal {G}}}\).
The proof of Lemma 5.6 can be found in the full version of this paper [RS20].
Notes
- 1.
- 2.
In the full reduction (Sect. 4), we consider two attacks, one per each possible value of \(\sigma \), and the adversary \(\mathsf{A}\) chooses which one of them to execute uniformly at random.
- 3.
Consider for example a decisional game \(\mathbf{G}_{{\mathcal {G}},b}\) in which if \(b=0\), then the adversary \(\mathsf{A}\) receives as input the tuple \((\mathbf{X}, \mathbf{X}^a, \mathbf{Y}, \mathbf{Y}^a)\) for some distinct fixed \(\mathbf{X}\) and \(\mathbf{Y}\) and a randomly chosen a, and if \(b=1\) then \(\mathsf{A}\) receives as input the tuple \((\mathbf{Y}, \mathbf{Y}^a, \mathbf{X}, \mathbf{X}^a)\). On the one hand, the witness \(\vec {w}=(a,-1,a,-1)\) satisfies both of the conditions of Definition 3.1. On the other hand, it is always the case that \(\mathbf{X}^{w_1}\cdot \left( \mathbf{X}^{a}\right) ^{w_2}\cdot \mathbf{Y}^{w_3}\cdot \left( \mathbf{Y}^{a}\right) ^{w_4} = 1_{\mathbb {G}} = \mathbf{Y}^{w_1}\cdot \left( \mathbf{Y}^{a}\right) ^{w_2}\cdot \mathbf{X}^{w_3}\cdot \left( \mathbf{X}^{a}\right) ^{w_4} \), and hence the zero test induced by \(\vec {w}\) is not actually helpful in distinguishing \(\mathbf{G}_{{\mathcal {G}},0}\) from \(\mathbf{G}_{{\mathcal {G}},1}\).
- 4.
In fact, in their work the adversary can choose a rational (partial) function instead of a polynomial.
- 5.
Concretely, in their proof the adversary \(\mathsf{B}\) simply forwards its input to \(\mathsf{A}\) (without the vector \(\vec {c}\) of sampled polynomials); hence, \(\mathsf{B}\) can simply output the same vector \(\vec {w}\) that is returned by \(\mathsf{A}\).
References
Agrikola, T., Hofheinz, D., Kastner, J.: On instantiating the algebraic group model from falsifiable assumptions. In: Canteaut, A., Ishai, Y. (eds.) EUROCRYPT 2020. LNCS, vol. 12106, pp. 96–126. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-45724-2_4
Boneh, D., Boyen, X., Goh, E.-J.: Hierarchical identity based encryption with constant size ciphertext. In: Cramer, R. (ed.) EUROCRYPT 2005. LNCS, vol. 3494, pp. 440–456. Springer, Heidelberg (2005). https://doi.org/10.1007/11426639_26
Boneh, D., Boyen, X., Shacham, H.: Short group signatures. In: Franklin, M. (ed.) CRYPTO 2004. LNCS, vol. 3152, pp. 41–55. Springer, Heidelberg (2004). https://doi.org/10.1007/978-3-540-28628-8_3
Berlekamp, E.R.: Factoring polynomials over large finite fields. Math. Comput. 24(111), 713–735 (1970)
Bauer, B., Fuchsbauer, G., Loss, J.: A classification of computational assumptions in the algebraic group model. In: Micciancio, D., Ristenpart, T. (eds.) CRYPTO 2020. LNCS, vol. 12171, pp. 121–151. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-56880-1_5
Boneh, D., Lipton, R.J.: Algorithms for black-box fields and their application to cryptography. In: Koblitz, N. (ed.) CRYPTO 1996. LNCS, vol. 1109, pp. 283–297. Springer, Heidelberg (1996). https://doi.org/10.1007/3-540-68697-5_22
Boneh, D., Lynn, B., Shacham, H.: Short signatures from the weil pairing. In: Boyd, C. (ed.) ASIACRYPT 2001. LNCS, vol. 2248, pp. 514–532. Springer, Heidelberg (2001). https://doi.org/10.1007/3-540-45682-1_30
Boyen, X.: The uber-assumption family – a unified complexity framework for bilinear groups. In: Galbraith, S.D., Paterson, K.G. (eds.) Pairing 2008. LNCS, vol. 5209, pp. 39–56. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-85538-5_3
Bellare, M., Rogaway, P.: The security of triple encryption and a framework for code-based game-playing proofs. In: Vaudenay, S. (ed.) EUROCRYPT 2006. LNCS, vol. 4004, pp. 409–426. Springer, Heidelberg (2006). https://doi.org/10.1007/11761679_25
Boneh, D., Venkatesan, R.: Breaking RSA may not be equivalent to factoring. In: Nyberg, K. (ed.) EUROCRYPT 1998. LNCS, vol. 1403, pp. 59–71. Springer, Heidelberg (1998). https://doi.org/10.1007/BFb0054117
Beullens, W., Wee, H.: Obfuscating simple functionalities from knowledge assumptions. In: Lin, D., Sako, K. (eds.) PKC 2019. LNCS, vol. 11443, pp. 254–283. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-17259-6_9
Fuchsbauer, G., Kiltz, E., Loss, J.: The algebraic group model and its applications. In: Shacham, H., Boldyreva, A. (eds.) CRYPTO 2018. LNCS, vol. 10992, pp. 33–62. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-96881-0_2
Fuchsbauer, G., Plouviez, A., Seurin, Y.: Blind Schnorr signatures and signed ElGamal encryption in the algebraic group model. In: Canteaut, A., Ishai, Y. (eds.) EUROCRYPT 2020. LNCS, vol. 12106, pp. 63–95. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-45724-2_3
Ghadafi, E., Groth, J.: Towards a classification of non-interactive computational assumptions in cyclic groups. In: Takagi, T., Peyrin, T. (eds.) ASIACRYPT 2017. LNCS, vol. 10625, pp. 66–96. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-70697-9_3
Groth, J.: On the size of pairing-based non-interactive arguments. In: Fischlin, M., Coron, J.-S. (eds.) EUROCRYPT 2016. LNCS, vol. 9666, pp. 305–326. Springer, Heidelberg (2016). https://doi.org/10.1007/978-3-662-49896-5_11
Jager, T., Schwenk, J.: On the analysis of cryptographic assumptions in the generic ring model. J. Cryptol. 26(2), 225–245 (2013). https://doi.org/10.1007/s00145-012-9120-y
Maurer, U.: Abstract models of computation in cryptography. In: Smart, N.P. (ed.) Cryptography and Coding 2005. LNCS, vol. 3796, pp. 1–12. Springer, Heidelberg (2005). https://doi.org/10.1007/11586821_1
Mizuide, T., Takayasu, A., Takagi, T.: Tight reductions for Diffie-Hellman variants in the algebraic group model. In: Matsui, M. (ed.) CT-RSA 2019. LNCS, vol. 11405, pp. 169–188. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-12612-4_9
Nechaev, V.I.: Complexity of a determinate algorithm for the discrete logarithm. Math. Notes 55(2), 91–101 (1994). https://doi.org/10.1007/BF02113297
Paillier, P., Vergnaud, D.: Discrete-log-based signatures may not be equivalent to discrete log. In: Roy, B. (ed.) ASIACRYPT 2005. LNCS, vol. 3788, pp. 1–20. Springer, Heidelberg (2005). https://doi.org/10.1007/11593447_1
Rabin, M.O.: Probabilistic algorithms in finite fields. SIAM J. Comput. 9(2), 273–280 (1980)
Rotem, L., Segev, G.: Algebraic distinguishers: from discrete logarithms to decisional uber assumptions. Cryptology ePrint Archive, Report 2020/1144 (2020)
Schnorr, C.P.: Efficient signature generation by smart cards. J. Cryptol. 4(3), 161–174 (1991). https://doi.org/10.1007/BF00196725
Schnorr, C.P.: Security of blind discrete log signatures against interactive attacks. In: Qing, S., Okamoto, T., Zhou, J. (eds.) ICICS 2001. LNCS, vol. 2229, pp. 1–12. Springer, Heidelberg (2001). https://doi.org/10.1007/3-540-45600-7_1
Shacham, H.: A Cramer-Shoup encryption scheme from the linear assumption and from progressively weaker linear variants. Cryptology ePrint Archive, Report 2007/074 (2007)
Shoup, V.: Lower bounds for discrete logarithms and related problems. In: Fumy, W. (ed.) EUROCRYPT 1997. LNCS, vol. 1233, pp. 256–266. Springer, Heidelberg (1997). https://doi.org/10.1007/3-540-69053-0_18
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 International Association for Cryptologic Research
About this paper

Cite this paper
Rotem, L., Segev, G. (2020). Algebraic Distinguishers: From Discrete Logarithms to Decisional Uber Assumptions. In: Pass, R., Pietrzak, K. (eds) Theory of Cryptography. TCC 2020. Lecture Notes in Computer Science(), vol 12552. Springer, Cham. https://doi.org/10.1007/978-3-030-64381-2_13
Download citation
DOI: https://doi.org/10.1007/978-3-030-64381-2_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-64380-5
Online ISBN: 978-3-030-64381-2
eBook Packages: Computer ScienceComputer Science (R0)
