
Abstract
Vector commitments with subvector openings (SVC) [Lai-Malavolta, Boneh-Bunz-Fisch; CRYPTO’19] allow one to open a committed vector at a set of positions with an opening of size independent of both the vector’s length and the number of opened positions.
We continue the study of SVC with two goals in mind: improving their efficiency and making them more suitable to decentralized settings. We address both problems by proposing a new notion for VC that we call incremental aggregation and that allows one to merge openings in a succinct way an unbounded number of times. We show two applications of this property. The first one is immediate and is a method to generate openings in a distributed way. The second application is an algorithm for faster generation of openings via preprocessing.
We then proceed to realize SVC with incremental aggregation. We provide two constructions in groups of unknown order that, similarly to that of Boneh et al. (which supports aggregating only once), have constant-size public parameters, commitments and openings. As an additional feature, for the first construction we propose efficient arguments of knowledge of subvector openings which immediately yields a keyless proof of storage with compact proofs.
Finally, we address a problem closely related to that of SVC: storing a file efficiently in completely decentralized networks. We introduce and construct verifiable decentralized storage (VDS), a cryptographic primitive that allows to check the integrity of a file stored by a network of nodes in a distributed and decentralized way. Our VDS constructions rely on our new vector commitment techniques.
M. Campanelli—Work done while author was at IMDEA Software Institute.
A full version of this paper can be found at https://ia.cr/2020/149.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



1 Introduction
Commitment schemes are one of the most fundamental cryptographic primitives. They have two basic properties. Hiding guarantees that a commitment reveals no information about the underlying message. Binding instead ensures that one cannot change its mind about the committed message; namely, it is not possible to open a commitment to two distinct values \(m \ne m'\).
Vector commitments (VC) [LY10, CF13] are a special class of commitment schemes in which one can commit to a vector \(\vec v\) of length n and to later open the commitment at any position \(i \in [n]\). The distinguishing feature of VCs is that both the commitment and an opening for a position i have size independent of n. In terms of security, VCs should be position binding, i.e., one cannot open a commitment at position i to two distinct values \(v_i \ne v'_i\).
VCs were formalized by Catalano and Fiore [CF13] who proposed two realizations based on the CDH assumption in bilinear groups and the RSA assumption respectively. Both schemes have constant-size commitments and openings but suffer from large public parameters that are \(O(n^{2})\) and O(n) for the CDH- and RSA-based scheme respectively. Noteworthy is that Merkle trees [Mer88] are VCs with \(O(\log n)\)-size openings.
Two recent works [BBF19, LM19] proposed new constructions of vector commitments that enjoy a new property called subvector openings (also called batch openings in [BBF19]). A VC with subvector openings (called SVC, for short) allows one to open a commitment at a collection of positions \(I = \{i_1, \ldots , i_m\}\) with a constant-size proof, namely of size independent of the vector’s length n and the subvector length m. This property has been shown useful for reducing communication complexity in several applications, such as PCP/IOP-based succinct arguments [LM19, BBF19] and keyless Proofs of Retrievability (PoR) [Fis18].
In this work we continue the study of VCs with subvector openings with two main goals: (1) improving their efficiency, and (2) enabling their use in decentralized systems.
With respect to efficiency, although the most attractive feature of SVCs is the constant size of their opening proofs, a drawback of all constructions is that generating each opening takes at least time O(n) (i.e., as much as committing). This is costly and may harm the use of SVCs in applications such as the ones mentioned above.
When it comes to decentralization, VCs have been proposed as a solution for integrity of a distributed ledger (e.g., blockchains in the account model [BBF19]): the commitment is a succinct representation of the ledger, and a user responsible for the i-th entry can hold the corresponding opening and use it to prove validity of \(v_i\). In this case, though, it is not obvious how to create a succinct subvector opening for, say, m positions held by different users each responsible only of its own position/s in the vector. We elaborate more on the motivation around this problem in Sect. 1.2.
1.1 A New Notion for SVCs: Incremental Aggregation
To address these concerns, we define and investigate a new property of vector commitments with subvector openings called incremental aggregation. In a nutshell, aggregation means that different subvector openings (say, for sets of positions I and J) can be merged together into a single concise (i.e., constant-size) opening (for positions \(I \cup J\)). This operation must be doable without knowing the entire committed vector. Moreover, aggregation is incremental if aggregated proofs can be further aggregated (e.g., two openings for \(I \cup J\) and K can be merged into one for \(I \cup J \cup K\), and so on an unbounded number of times) and disaggregated (i.e., given an opening for set I one can create one for any \(K \subset I\)).
While a form of aggregation is already present in the VC of Boneh et al. [BBF19], in [BBF19] this can be performed only once. In contrast, we define (and construct) the first VC schemes where openings can be aggregated an unbounded number of times. This incremental property is key to address efficiency and decentralized applications of SVCs, as we detail below.
Incremental Aggregation for Efficiency. To overcome the barrier of generating each opening in linear timeFootnote 1
 , we propose an alternative preprocessing-based method. The idea is to precompute at commitment time an auxiliary information consisting of n/B openings, one for each batch of B positions of the vector. Next, to generate an opening for an arbitrary subset of m positions, one uses the incremental aggregation property in order to disaggregate the relevant subsets of precomputed openings, and then further aggregate for the m positions. Concretely, with this method, in our construction we can do the preprocessing in time
, we propose an alternative preprocessing-based method. The idea is to precompute at commitment time an auxiliary information consisting of n/B openings, one for each batch of B positions of the vector. Next, to generate an opening for an arbitrary subset of m positions, one uses the incremental aggregation property in order to disaggregate the relevant subsets of precomputed openings, and then further aggregate for the m positions. Concretely, with this method, in our construction we can do the preprocessing in time
 and generate an opening for m positions in time roughly
and generate an opening for m positions in time roughly
 .
.
With the VC of [BBF19], a limited version of this approach is also viable: one precomputes an opening for each bit of the vector in
 time; and then, at opening time, one uses their one-hop aggregation to aggregate relevant openings in time roughly
time; and then, at opening time, one uses their one-hop aggregation to aggregate relevant openings in time roughly
 . This however comes with a huge drawback: one must store one opening (of size
. This however comes with a huge drawback: one must store one opening (of size
 where
where
 is the security parameter) for every bit of the vector, which causes a prohibitive storage overhead, i.e.,
is the security parameter) for every bit of the vector, which causes a prohibitive storage overhead, i.e.,
 bits in addition to storing the vector \(\vec v\) itself.
bits in addition to storing the vector \(\vec v\) itself.
With incremental aggregation, we can instead tune the chunk size B to obtain flexible time-memory tradeoffs. For example, with \(B=\sqrt{n}\) one can use
 bits of storage to get \(O_\lambda (m \sqrt{n} \log n)\) opening time. Or, by setting
bits of storage to get \(O_\lambda (m \sqrt{n} \log n)\) opening time. Or, by setting
 as the size of one opening, we can obtain a storage overhead of exactly n bits and opening time \(O_\lambda (m \log n)\).
as the size of one opening, we can obtain a storage overhead of exactly n bits and opening time \(O_\lambda (m \log n)\).
Incremental Aggregation for Decentralization. Essentially, by its definition, incremental aggregation enables generating subvector openings in a distributed fashion. Consider a scenario where different parties each hold an opening of some subvector; using aggregation they can create an opening for the union of their subvectors, moreover the incremental property allows them to perform this operation in a non-coordinated and asynchronous manner, i.e. without the need of a central aggregator. We found this application of incrementally aggregatable SVCs to decentralized systems worth exploring in more detail. To fully address this application, we propose a new cryptographic primitive called verifiable decentralized storage which we discuss in Sect. 1.2.
Constructing VCs With Incremental Aggregation. Turning to realizing SVC schemes with our new incremental aggregation property, we propose two SVC constructions that work in hidden-order groups [DK02] (instantiatable using classical RSA groups, class groups [BH01] or the recently proposed groups from Hyperelliptic Curves [DG20]).
Our first SVC has constant-size public parameters and constant-size subvector openings, and its security relies on the Strong RSA assumption and an argument of knowledge in the generic group model. Asymptotically, its efficiency is similar to the SVC of Boneh et al. [BBF19], but concretely we outperform [BBF19]. We implement our new SVC and show it can obtain very fast opening times thanks to the preprocessing method described earlier: opening time reduces by several orders of magnitude for various choices of vector and opening sizes, allowing us to obtain practical opening times—of the order of seconds—that would be impossible without preprocessing—of the order of hundred of seconds. In a file of 1 Mibit (\(2^{20}\) bits), preprocessing reduces the time to open 2048 bits from one hour to less than 5 s!
For the second construction, we show how to modify the RSA-based SVC of [LM19] (which in turn extends the one of [CF13] to support subvector openings) in order to make it with constant-size parameters and to achieve incremental aggregation. Compared to the first construction, it is more efficient and based on more standard assumptions, in the standard model.
Efficient Arguments of Knowledge of Subvector Opening. As an additional result, we propose efficient arguments of knowledge (AoK) with constant-size proofs for our first VC. In particular, we can prove knowledge of the subvector that opens a commitment at a public set of positions. An immediate application of this AoK is a keyless proof of storage (PoS) protocol with compact proofs. PoS allows a client to verify that a server is storing intactly a file via a short-communication challenge-response protocol. A PoS is said keyless if no secret key is needed by clients (e.g., mutually distrustful verifiers in a blockchain) and the server may even be one of these clients. With our AoK we can obtain openings of fixed size, as short as 2KB, which is 40x shorter than those based on Merkle trees in a representative setting without relying on SNARKs (that would be unfeasible in terms of time and memory). For lack of space, these AoK results appear in the full version.
1.2 Verifiable Decentralized Storage (VDS)
We now turn our attention to the problem of preserving storage integrity in a highly decentralized context which some of the distributed features of our VCs (i.e. incremental aggregation) can help us address. We are interested in studying the security of the emerging trend of decentralized and open alternatives to traditional cloud storage and hosting services: decentralized storage networks (DSNs). Filecoin (built on top of IPFS), Storj, Dat, Freenet and general-purpose blockchains like EthereumFootnote 2 are some emerging projects in this space.
Background on DSNs. Abstracting from the details of each system, a DSN consists of participants called nodes. These can be either storage providers (aka storage nodes) or simple client nodes. Akin to centralized cloud storage, a client can outsourceFootnote 3 the storage of large data. However, a key difference with DSN is that storage is provided by, and distributed across, a collection of nodes that can enter and leave the system at will. To make these systems viable it is important to tackle certain basic security questions. DSNs can have some reward mechanism to economically incentivize storage nodes. This means, for example, that there are economic incentives to fake storing a file. A further challenge for security (and for obtaining it efficiently) is that these systems are open and decentralized: anyone can enter the system (and participate as either a service provider or a consumer) and the system works without any central management or trusted parties.
In this work we focus on the basic problem of ensuring that the storage nodes of the DSN are doing their job properly, namely: How can any client node check that the whole DSN is storing correctly its data (in a distributed fashion)?
While this question is well studied in the centralized setting where the storage provider is a single server, for decentralized systems the situation is less satisfactory.
The Problem of Verifiable Decentralized Storage in DSNs. Consider a client who outsources the storage of a large file F, consisting of blocks \((F_1, \ldots , F_{N})\), to a collection of storage nodes. A storage node can store a portion of F and the network is assumed to be designed in order to self-coordinate so that the whole F is stored, and to be fault-resistant (e.g., by having the same data block stored on multiple nodes). Once the file is stored, clients can request to the network to retrieve or modify a data block \(F_i\) (or more), as well as to append (resp. delete) blocks to (resp. from) the file.
In this scenario, our goal is to formalize a cryptographic primitive that can provide clients with the guarantee of integrity of the outsourced data and its modifications. The basic idea of VDS is that: (i) the client retains a short digest \(\delta _{F}\) that “uniquely” points to the file F; (ii) any operation performed by the network, a retrieval or a file modification, can be proven by generating a short certificate that is publicly verifiable given \(\delta _{F}\).
This problem is similar in scope to the one addressed by authenticated data structures (ADS) [Tam03]. But while ADS is centralized, VDS is not. In VDS nodes act as storage in a distributed and uncoordinated fashion. This is more challenging as VDS needs to preserve some basic properties of the DSN:
Highly Local. The file is stored across multiple nodes and no node is required to hold the entire F: in VDS every node should function with only its own local view of the system, which should be much smaller than the whole F. Another challenge is dynamic files: in VDS both the digest and the local view must be locally updatable, possibly with the help of a short and publicly verifiable update advice from the node holding the modified data blocks.
Decentralized Keyless Clients. In a decentralized system the notion of a client who outsources the storage of a file is blurry. It may for example be a set of mutually distrustful parties (even the entire DSN), or a collection of storage nodes themselves that decide to make some data available to the network. This comes with two implications:
-
1.
VDS must work without any secret key on the clients side, so that everyone in the network can delegate and verify storage. This keyless setting captures not only clients requiring no coordination, but also a stronger security model. Here the attacker may control both the storage node and the client, yet it must not be able to cheat when proving correctness of its storage. The latter is crucial in DSNs with economic rewards for well-behaving nodesFootnote 4.
-
2.
In VDS a file F exists as long as some storage nodes provide its storage and a pointer to the file is known to the network through its digest. When a file F is modified into \(F'\) and its digest \(\delta _{F}\) is updated into \(\delta _{F'}\), both versions of the file may coexist. Forks are possible and it is left to each client (or the application) to choose which digest to track: the old one, the new one, or both.
Non-Coordinated Certificates Generation. There are multiple ways in which data retrieval queries can be answered in a DSN. In some cases (e.g., Freenet [CSWH01] or the original Gnutella protocol), data retrieval is also answered in a peer-to-peer non-coordinated fashion. When a query for blocks \(i_1, \ldots , i_{m}\) propagates through the network, every storage node replies with the blocks that it owns and these answers are aggregated and propagated in the network until they reach the client who asked for them. To accommodate arbitrary aggregation strategies, in VDS we consider the incremental aggregation of query certificates in an arbitrary and bandwidth-efficient fashion. For example, short certificates for file blocks \(F_i\) and \(F_j\) should be mergeable into a short certificate for \((F_i, F_j)\) and this aggregation process should be carried on and on. Noteworthy that having certificates that stay short after each aggregation keeps the communication overhead of the VDS integrity mechanism at a minimum.Footnote 5
A New Cryptographic Primitive: VDS. To address the problem described above, we put forward the definition of a new cryptographic primitive called verifiable decentralized storage (VDS). In a nutshell, VDS is a collection of algorithms that can be used by clients and storage nodes to maintain the system. The basic ideas are the following: every file F is associated to a succinct digest \(\delta _{F}\); a storage node can answer and certify retrieval queries for subportions of F that it stores, as well as to push updates of F that enable anyone else to update the digest accordingly. Moreover, certified retrieval results can be arbitrarily aggregated. With respect to security, VDS guarantees that malicious storage nodes (even a full coalition of them) cannot create certificates for falsified data blocks that pass verification. For efficiency, the key property of VDS is that digests and every certificate are at most \(O(\log |F|)\), and that every node in the system works with storage and running time that depends at most logarithmically in F’s size. We discuss our definition of VDS in Section 5.
Constructing VDS. We propose two constructions of VDS in hidden-order groups. Both our VDS schemes are obtained by extending our first and second SVC scheme respectively, in order to handle updates and to ensure that all such update operations can be performed locally. We show crucial use of the new properties of our constructions: subvector openings, incremental aggregation and disaggregation, and arguments of knowledge for sub-vector commitments (the latter for the first scheme only).
Our two VDS schemes are based on the Strong RSA [BP97] and Strong distinct-prime-product root [LM19], and Low Order [BBF18] assumptions and have similar performances. The second scheme has the interesting property that the storage node can perform and propagate updates by running in time that is independent of even its total local storage.
Finally, we note that VDS shares similarities with the notion of updatable VCs [CF13] extended with incrementally aggregatable subvector openings. There are two main differences. First, in VDS updates can be applied with the help of a short advice created by the party who created the update, whereas in updatable VC this is possible having only the update’s description. The second difference is that in VDS the public parameters must be short, otherwise nodes could not afford storing them. This is not necessarily the case in VCs and in fact, to the best of our knowledge, there exists no VC construction with short parameters that is updatable (according to the updatability notion of [CF13]) and has incrementally aggregatable subvector openings. We believe this is an interesting open problem.
1.3 Concurrent Work
In very recent concurrent works, Gorbunov et al. [GRWZ20] and Tomescu et al. [TAB+20] study similar problems related to aggregation properties of vector commitments. In [TAB+20], Tomescu et al. study a vector commitment scheme based on the Kate et al. polynomial commitment [KZG10]: they show how it can be made both updatable and aggregatable, and propose an efficient Stateless Cryptocurrency based on it. In Pointproofs [GRWZ20] they propose the notion of Cross-Commitment Aggregation, which enables aggregating opening proofs for different commitments, and show how this notion is relevant to blockchain applications. The VC schemes in both [TAB+20] and [GRWZ20] work in bilinear groups and have linear-size public parameters. Also, these constructions do not support incremental aggregation or disaggregation. In contrast, our VCs work in hidden-order groups, which likely makes them concretely less efficient, but they have constant-size parameters, and they support incremental aggregation and disaggregation. Finally, we note that by using techniques similar to [GRWZ20] we can extend our constructions to support cross-commitment aggregation; we leave formalizing this extension for future work.
1.4 Preliminaries
In the paper we use rather standard cryptographic notation and definitions that for completeness are recalled in the full version. More specific to this paper we denote by
 the set of all prime integers less than
the set of all prime integers less than
 .
.
Groups of Unknown Order and Computational Assumptions. Our constructions use a group
 of unknown (aka hidden) order [DK02], in which the Low Order assumption [BBF18] and the Strong RSA assumption [BP97] hold. We let \(\mathsf {Ggen}(1^{\lambda })\) be a probabilistic algorithm that generates such a group \(\mathbb {G}\) with order in a specific range \([\mathsf {ord}_{min},\mathsf {ord}_{max}]\) such that
of unknown (aka hidden) order [DK02], in which the Low Order assumption [BBF18] and the Strong RSA assumption [BP97] hold. We let \(\mathsf {Ggen}(1^{\lambda })\) be a probabilistic algorithm that generates such a group \(\mathbb {G}\) with order in a specific range \([\mathsf {ord}_{min},\mathsf {ord}_{max}]\) such that
 . As discussed in [BBF18, BBF19, LM19], two concrete instantiations of \(\mathbb {G}\) are class groups [BH01] and the quotient group \(\mathbb {Z}_N^*/\{1,-1\}\) of an RSA group [Wes18]. See the full version for the formal definitions of the assumptions and for a recall of Shamir’s trick [Sha83] that we use extensively in our constructions.
. As discussed in [BBF18, BBF19, LM19], two concrete instantiations of \(\mathbb {G}\) are class groups [BH01] and the quotient group \(\mathbb {Z}_N^*/\{1,-1\}\) of an RSA group [Wes18]. See the full version for the formal definitions of the assumptions and for a recall of Shamir’s trick [Sha83] that we use extensively in our constructions.
2 Vector Commitments with Incremental Aggregation
In this section, we recall vector commitments with subvector openings [CF13, LM19, BBF19] and then we formally define our new incremental aggregation property.
2.1 Vector Commitments with Subvector Openings
In our work we consider the generalization of vector commitments proposed by Lai and Malavolta [LM19] called VCs with subvector openingsFootnote 6 (we call them SVCs for brevity) in which one can open the commitment to an ordered collection of positions with a short proof. Below is a brief recap of their definition.
Let \(\mathcal {M}\) be a set,
 be a positive integer and \(I =\{i_1, \ldots , i_{|I|}\} \subseteq [n]\) be an ordered index set. The I-subvector of a vector \(\vec v \in \mathcal {M}^{n}\) is \(\vec v_{I} :=(v_{i_1}, \ldots , v_{i_{|I|}})\). Let \(I, J \subseteq [n]\) be two sets, and let \(\vec v_I, \vec v_{J}\) be two subvectors of some \(\vec v \in \mathcal {M}^{n}\). The ordered union of \(\vec v_I\) and \(\vec v_{J}\) is the subvector \(\vec v_{I \cup J}\), where \(I \cup J\) is the ordered union of I and J.
be a positive integer and \(I =\{i_1, \ldots , i_{|I|}\} \subseteq [n]\) be an ordered index set. The I-subvector of a vector \(\vec v \in \mathcal {M}^{n}\) is \(\vec v_{I} :=(v_{i_1}, \ldots , v_{i_{|I|}})\). Let \(I, J \subseteq [n]\) be two sets, and let \(\vec v_I, \vec v_{J}\) be two subvectors of some \(\vec v \in \mathcal {M}^{n}\). The ordered union of \(\vec v_I\) and \(\vec v_{J}\) is the subvector \(\vec v_{I \cup J}\), where \(I \cup J\) is the ordered union of I and J.
A vector commitment scheme with subvector openings (SVC) is a tuple of algorithms \(\mathsf{VC}= (\mathsf{VC.Setup}, \mathsf{VC.Com}, \mathsf{VC.Open}, \mathsf{VC.Ver})\) that work as follows. The probabilistic setup algorithm,
 , which given the security parameter
, which given the security parameter
 and description of a message space \(\mathcal {M}\) for the vector components, outputs a common reference string
and description of a message space \(\mathcal {M}\) for the vector components, outputs a common reference string
 ; the committing algorithm,
; the committing algorithm,
 , which on input
, which on input
 and a vector \(\vec v \in \mathcal {M}^{n}\), outputs a commitment C and an auxiliary information \(\mathsf{aux}\); the opening algorithm,
and a vector \(\vec v \in \mathcal {M}^{n}\), outputs a commitment C and an auxiliary information \(\mathsf{aux}\); the opening algorithm,
 which on input the CRS
which on input the CRS
 , a vector \(\vec y \in \mathcal {M}^{m}\), an ordered index set
, a vector \(\vec y \in \mathcal {M}^{m}\), an ordered index set
 and auxiliary information \(\mathsf{aux}\), outputs a proof \(\pi _I\) that \(\vec y\) is the I-subvector of the committed message; the verification algorithm,
and auxiliary information \(\mathsf{aux}\), outputs a proof \(\pi _I\) that \(\vec y\) is the I-subvector of the committed message; the verification algorithm,
 , which on input the CRS
, which on input the CRS
 , a commitment C, an ordered set of indices
, a commitment C, an ordered set of indices
 , a vector \(\vec y \in \mathcal {M}^{m}\) and a proof \(\pi _I\), accepts (i.e., it outputs 1) only if \(\pi _I\) is a valid proof that C was created to a vector \(\vec v = (v_1,\ldots ,v_n)\) such that \(\vec y = \vec v_I\). We require three properties from a vector commitment: correctness (verification acts as expected on honestly generated commitments and openings); position binding (no adversary can produce two valid openings for different subvectors); conciseness (if its commitments and openings are of size independent of \(|\vec v|\)).
, a vector \(\vec y \in \mathcal {M}^{m}\) and a proof \(\pi _I\), accepts (i.e., it outputs 1) only if \(\pi _I\) is a valid proof that C was created to a vector \(\vec v = (v_1,\ldots ,v_n)\) such that \(\vec y = \vec v_I\). We require three properties from a vector commitment: correctness (verification acts as expected on honestly generated commitments and openings); position binding (no adversary can produce two valid openings for different subvectors); conciseness (if its commitments and openings are of size independent of \(|\vec v|\)).
Vector Commitments with Specializable Universal CRS. The notion of VCs defined above slightly generalizes the previous ones in which the generation of public parameters (aka common reference string) depends on a bound n on the length of the committed vectors. In contrast, in our notion \(\mathsf{VC.Setup}\) is length-independent. To highlight this property, we also call this primitive vector commitments with universal CRS.
Here we formalize a class of VC schemes that lies in between VCs with universal CRS (as defined above) and VCs with length-specific CRS (as defined in [CF13]). Inspired by the recent work of Groth et al. [GKM+18], we call these schemes VCs with Specializable (Universal) CRS. In a nutshell, these are schemes in which the algorithms \(\mathsf{VC.Com}, \mathsf{VC.Open}\) and \(\mathsf{VC.Ver}\) work on input a length-specific CRS
 . However, this
. However, this
 is generated in two steps: (i) a length-independent, probabilistic setup
is generated in two steps: (i) a length-independent, probabilistic setup
 , and (ii) a length-dependent, deterministic specialization
, and (ii) a length-dependent, deterministic specialization
 . The advantage of this model is that, being \(\mathsf{VC.Specialize}\) deterministic, it can be executed by anyone, and it allows to re-use the same
. The advantage of this model is that, being \(\mathsf{VC.Specialize}\) deterministic, it can be executed by anyone, and it allows to re-use the same
 for multiple vectors lengths.
for multiple vectors lengths.
See the full version for the formal definition of VCs with specializable CRS.
2.2 Incrementally Aggregatable Subvector Openings
In a nutshell, aggregation means that different proofs of different subvector openings can be merged together into a single short proof which can be created without knowing the entire committed vector. Moreover, this aggregation is composable, namely aggregated proofs can be further aggregated. Following a terminology similar to that of aggregate signatures, we call this property incremental aggregation (but can also be called multi-hop aggregation). In addition to aggregating openings, we also consider the possibility to “disaggregate” them, namely from an opening of positions in the set I one can create an opening for positions in a set \(K \subset I\).
We stress on the two main requirements that make aggregation and disaggregation non-trivial: all openings must remain short (independently of the number of positions that are being opened), and aggregation (resp. disaggregation) must be computable locally, i.e., without knowing the whole committed vector. Without such requirements, one could achieve this property by simply concatenating openings of single positions.
Definition 2.1
(Aggregatable Subvector Openings). A vector commitment scheme \(\mathsf{VC}\) with subvector openings is called aggregatable if there exists algorithms \(\mathsf{VC.Agg}\), \(\mathsf{VC.Disagg}\) working as follows:
-
 takes as input triples \((I, \vec v_I, \pi _I), (J, \vec v_J, \pi _J) \) where I and J are sets of indices, \(\vec v_{I} \in \mathcal {M}^{|I|}\) and \(\vec v_{J} \in \mathcal {M}^{|J|}\) are subvectors, and \(\pi _I\) and \(\pi _J\) are opening proofs. It outputs a proof \(\pi _K\) that is supposed to prove opening of values in positions \(K = I \cup J\).
takes as input triples \((I, \vec v_I, \pi _I), (J, \vec v_J, \pi _J) \) where I and J are sets of indices, \(\vec v_{I} \in \mathcal {M}^{|I|}\) and \(\vec v_{J} \in \mathcal {M}^{|J|}\) are subvectors, and \(\pi _I\) and \(\pi _J\) are opening proofs. It outputs a proof \(\pi _K\) that is supposed to prove opening of values in positions \(K = I \cup J\). -
 takes as input a triple \((I, \vec v_I, \pi _I)\) and a set of indices \(K \subset I\), and it outputs a proof \(\pi _K\) that is supposed to prove opening of values in positions K.
takes as input a triple \((I, \vec v_I, \pi _I)\) and a set of indices \(K \subset I\), and it outputs a proof \(\pi _K\) that is supposed to prove opening of values in positions K.
 takes as input triples
takes as input triples  takes as input a triple
takes as input a triple The aggregation algorithm \(\mathsf{VC.Agg}\) must guarantee the following two properties:
Aggregation Correctness. Aggregation is (perfectly) correct if for all
 , all honestly generated
, all honestly generated
 , any commitment C and triple \((I, \vec v_I, \pi _I)\) s.t.
, any commitment C and triple \((I, \vec v_I, \pi _I)\) s.t.
 , the following two properties hold:
, the following two properties hold:
-
1.
for any triple \((J, \vec v_J, \pi _J)\) such that
 ,
, 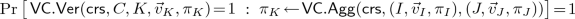
where \(K=I \cup J\) and \(\vec v_{K}\) is the ordered union \(\vec v_{I \cup J}\) of \(\vec v_{I}\) and \(\vec v_J\);
-
2.
for any subset of indices \(K \subset I\),
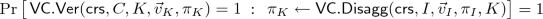
where \(\vec v_{K} = (v_{i_{l}})_{i_l \in K}\), for \(\vec v_{I} = (v_{i_1}, \ldots , v_{i_{|I|}})\).
 ,
, 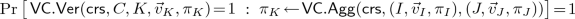
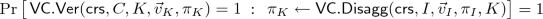
Aggregation Conciseness. There exists a fixed polynomial \(p(\cdot )\) in the security parameter such that all openings produced by \(\mathsf{VC.Agg}\) and \(\mathsf{VC.Disagg}\) have length bounded by
 .
.
We remark that the notion of specializable CRS can apply to aggregatable VCs as well. In this case, we let \(\mathsf{VC.Agg}^{\star }\) (resp. \(\mathsf{VC.Disagg}^{\star }\)) be the algorithm that works on input the specialized
 instead of
instead of
 .
.
3 Applications of Incremental Aggregation
We discuss two general applications of the SVC incremental aggregation property.
One application is generating subvector openings in a distributed and decentralized way. Namely, assume a set of parties hold each an opening of some subvector. Then it is possible to create a (concise) opening for the union of their subvectors by using the \(\mathsf{VC.Agg}\) algorithm. Moreover, the incremental (aka multi-hop) aggregation allows these users to perform this operation in an arbitrary order, hence no coordination or a central aggregator party are needed. This application is particularly useful in our extension to verifiable decentralized storage.
The second application is to generate openings in a faster way via preprocessing. As we mentioned in the introduction, this technique is useful in the scenario where a user commits to a vector and then must generate openings for various subvectors, which is for example the use case when the VC is used for proofs of retrievability and IOPs [BBF19].
So, here the goal is to achieve a method for computing subvector openings in time sub-linear in the total size of the vector, which is the barrier in all existing constructions. To obtain this speedup, the basic idea is to (A) compute and store openings for all the positions at commitment time, and then (B) use the aggregation property to create an opening for a specific set of positions. In order to obtain efficiency using this approach it is important that both steps (A) and (B) can be computed efficiently. In particular, step (A) is challenging since typically computing one opening takes linear time, hence computing all of them would take quadratic time.
In this section, we show how steps (A) and (B) can benefit from disaggregation and aggregation respectively. As a preliminary for this technique, we begin by describing two generic extensions of (incremental) aggregation (resp. disaggregation) that support many inputs (resp. outputs). Then we show how these extended algorithms can be used for committing and opening with preprocessing.
3.1 Divide-and-Conquer Extensions of Aggregation and Disaggregation
We discuss how the incremental property of our aggregation and disaggregation can be used to define two extended versions of these algorithms. The first one is an algorithm that can aggregate many openings for different sets of positions into a single opening for their union. The second one does the opposite, namely it disaggregates one opening for a set I into many openings for partitions of I.
Aggregating Many Openings. We consider the problem of aggregating several openings for sets of positions \(I_1, \ldots , I_m\) into a single opening for \(\bigcup _{j=1}^{m} I_{j}\). Our syntax in Definition 2.1 only considers pairwise aggregation. This can be used to handle many aggregations by executing the pairwise aggregation in a sequential (or arbitrary order) fashion. Sequential aggregation might however be costly since it would require executing \(\mathsf{VC.Agg}\) on increasingly growing sets. If \(f_a(k)\) is the complexity of \(\mathsf{VC.Agg}\) on two sets of total size k, then the complexity of the sequential method is \(\sum _{j=2}^{m} f(\sum _{l=1}^{j-1} |I_{l}|+|I_j|)\), which for example is quadratic in m, for \(f_a(k) = \varTheta (k)\).
In Fig. 1, we show an algorithm, \(\mathsf{VC.AggManyToOne}\), that is a nearly optimal solution for aggregating m openings based on a divide-and-conquer methodology. Assuming for simplicity that all \(I_j\)’s have size bounded by some s, then the complexity of \(\mathsf{VC.AggManyToOne}\) is given by the recurrence relation \(T(m) = 2T\left( \frac{m}{2}\right) + f_a(s \cdot m)\), which solves to \(\varTheta (s \cdot m \log m)\) if \(f_a(n) \in \varTheta (n)\), or to \(\varTheta (s \cdot m \log (s m) \log m)\) if \(f_a(n) \in \varTheta (n \log n)\).

Extensions of aggregation and disaggregation
Disaggregating from One to Many Openings. We consider the problem that is dual to the one above, namely how to disaggregate an opening for a set I into several openings for sets \(I_1, \ldots , I_m\) that form a partition of I. Our syntax in Definition 2.1 only considers disaggregation from I to one subset K of I. Similarly to aggregation, disaggregating from one set to many subsets can be trivially obtained via a sequential application of \(\mathsf{VC.Disagg}\) on all pairs \((I, I_j)\). This however can be costly if the number of partitions approaches the size of I, e.g., if we want to disaggregate to all the elements of I.
In Fig. 1, we show a divide-and-conquer algorithm, \(\mathsf{VC.DisaggOneToMany}\), for disaggregating an opening for a set I of size m into \(m' = m/B\) openings, each for a partition of size B. For simplicity, we assume that m is a power of 2, and \(B \mid m\). Let \(f_d(|I|)\) be the complexity of \(\mathsf{VC.Disagg}\). The complexity of \(\mathsf{VC.DisaggOneToMany}\) is given by the recurrence relation \(T(m) = 2T\left( \frac{m}{2}\right) + 2 f_d(m/2)\), which solves to \(\varTheta (m \log (m/B))\) if \(f_d(n) \in \varTheta (n)\), or to \(\varTheta ( m \log m \log (m/B))\) if \(f_d(n) \in \varTheta (n \log n)\).
3.2 Committing and Opening with Precomputation
We present a construction of committing and opening algorithms (denoted \(\mathsf{VC.PPCom}\) and \(\mathsf{VC.FastOpen}\) respectively) that works generically for any SVC with incremental aggregation and that, by relying on preprocessing, can achieve fast opening time.
Our preprocessing method works with a flexible choice of a parameter B that allows for different time-memory tradeoffs. In a nutshell, ranging from 1 to n, a larger B reduces memory but increases opening time while a smaller B (e.g., \(B=1\)) requires larger storage overhead but gives the fastest opening time.
Let B be an integer that divides n, and let \(n' = n/B.\) The core of our idea is that, during the commitment stage, one can create openings for \(n' = n/B\) subvectors of \(\vec v\) that cover the whole vector (e.g., B contiguous positions). Let \(\pi _{P_1}, \ldots , \pi _{P_{n'}}\) be such openings; these elements are stored as advice information.
Next, in the opening phase, in order to compute the opening for a subvector \(\vec v_{I}\) of m positions, one should: (i) fetch the subset of openings \(\pi _{P_j}\) such that, for some S, \(I \subseteq \cup _{j \in S} P_j\), (ii) possibly disaggregate some of them and then aggregate in order to compute \(\pi _{I}\).
The two algorithms \(\mathsf{VC.PPCom}\) and \(\mathsf{VC.FastOpen}\) are described in detail in Fig. 2.

Generic algorithms for committing and opening with precomputation.
In terms of auxiliary storage, in addition to the vector \(\vec v\) itself, one needs at most
 bits, where
bits, where
 is the polynomial bounding the conciseness of the SVC scheme. In terms of time complexity, \(\mathsf{VC.PPCom}\) requires one execution of \(\mathsf{VC.Com}\), one execution of \(\mathsf{VC.Open}\), and one execution of \(\mathsf{VC.DisaggOneToMany}\), which in turn depends on the complexity of \(\mathsf{VC.Disagg}\); \(\mathsf{VC.FastOpen}\) requires to perform (at most) |S| disaggregations (each with a set \(|I_j|\) such that their sum is |I|)Footnote 7, and one execution of \(\mathsf{VC.AggManyToOne}\) on |S| openings. Note that \(\mathsf{VC.FastOpen}\)’s running time depends only on the size m of the set I and size B of the buckets \(P_j\), and thus offers various tradeoffs by adjusting B.
is the polynomial bounding the conciseness of the SVC scheme. In terms of time complexity, \(\mathsf{VC.PPCom}\) requires one execution of \(\mathsf{VC.Com}\), one execution of \(\mathsf{VC.Open}\), and one execution of \(\mathsf{VC.DisaggOneToMany}\), which in turn depends on the complexity of \(\mathsf{VC.Disagg}\); \(\mathsf{VC.FastOpen}\) requires to perform (at most) |S| disaggregations (each with a set \(|I_j|\) such that their sum is |I|)Footnote 7, and one execution of \(\mathsf{VC.AggManyToOne}\) on |S| openings. Note that \(\mathsf{VC.FastOpen}\)’s running time depends only on the size m of the set I and size B of the buckets \(P_j\), and thus offers various tradeoffs by adjusting B.
More specific running times depend on the complexity of the algorithms \(\mathsf{VC.Com}\), \(\mathsf{VC.Open}\), \(\mathsf{VC.Agg}\), and \(\mathsf{VC.Disagg}\) of the given SVC scheme. See Sect. 4.3 and the full version for these results for our constructions.
4 Our Realizations of Incrementally Aggregatable SVCs
In this section we describe our new SVC realizations.
4.1 Our First SVC Construction
An overview of our techniques. The basic idea underlying our VC can be described as a generic construction from any accumulator with union proofs. Consider a vector of bits \(\vec v = (v_1, \dots , v_n) \in \{0, 1\}^n\). In order to commit to this vector we produce two accumulators, \(\mathsf {Acc}_0\) and \(\mathsf {Acc}_1\), on two partitions of the set \(S = \{1, \dots , n \}\). Each accumulator \(\mathsf {Acc}_b\) compresses the set of positions i such that \(v_i = b\). In other words, \(\mathsf {Acc}_b\) compresses the set \(S_{=b} :=\{ i \in S : v_i = b \}\) with \(b \in \{0, 1\}\). In order to open to bit b at position i, one can create an accumulator membership proof for the statement \(i \in \tilde{S}_b\) where we denote by \(\tilde{S}_b\) the alleged set of positions that have value b.
However, if the commitment to \(\vec v\) is simply the pair of accumulators \((\mathsf {Acc}_0, \mathsf {Acc}_1)\) we do not achieve position binding as an adversary could for example include the same element i in both accumulators. To solve this issue we set the commitment to be the pair of accumulators plus a succinct non-interactive proof \(\pi _S\) that the two sets \(\tilde{S}_0, \tilde{S}_1\) they compress constitute together a partition of S. Notably, this proof \(\pi _S\) guarantees that each index i is in either \(\tilde{S}_0\) or \(\tilde{S}_1\), and thus prevents an adversary from also opening the position i to the complement bit \(1-b\).
The construction described above could be instantiated with any accumulator scheme that admits an efficient and succinct proof of union. We, though, directly present an efficient construction based on RSA accumulators [Bd94, BP97, CL02, Lip12, BBF19] as this is efficient and has some nice extra properties like aggregation and constant-size parameters. Also, part of our technical contribution to construct this VC scheme is the construction of efficient and succinct protocols for proving the union of two RSA accumulators built with different generators.
Succinct AoK Protocols for Union of RSA Accumulators. Let
 be a hidden order group as generated by \(\mathsf {Ggen}\), and let
be a hidden order group as generated by \(\mathsf {Ggen}\), and let
 be three honestly sampled random generators. We propose a succinct argument of knowledge for the following relation
be three honestly sampled random generators. We propose a succinct argument of knowledge for the following relation

Our protocol (described in Fig. 3) is inspired by a similar protocol of Boneh et al. [BBF19], \(\mathsf {PoDDH}\), for a similar relation in which there is only one generator (i.e., \(g_1=g_2=g_3\), namely for DDH tuples \((g^{a}, g^{b}, g^{a b})\)). Their protocol has a proof consisting of 3 groups elements and 2 integers of
 bits.
bits.
As we argue later \(\mathsf {PoProd_2}\) is still sufficient for our construction, i.e., for the goal of proving that \(C = g_3^{c}\) is an accumulator to a set that is the union of sets represented by two accumulators \(A = g_1^a\) and \(B= g_2^b\) respectively. The idea is to invoke \(\mathsf {PoProd_2}\) on (Y, C) with \(Y = A \cdot B\).

\(\mathsf {PoProd_2}\) protocol
To prove the security of our protocol we rely on the adaptive root assumption and, in a non-black-box way, on the knowledge extractability of the \(\mathsf {PoKRep}\) and \(\mathsf {PoKE}^*\) protocols from [BBF19]. The latter is proven in the generic group model for hidden order groups (where also the adaptive root assumption holds), therefore we state the following theorem.
Theorem 4.1
The \(\mathsf {PoProd_2}\) protocol is an argument of knowledge for \(R_{\mathsf {PoProd_2}}\) in the generic group model.
For space reasons the full proof is in the full version. The basic intuition is to use the extractors of \(\mathsf {PoKRep}\) and \(\mathsf {PoKE}^*\) to extract (a, b, c) such that \(Y= g_1^{a} g_2^{b} \wedge C = g_3^{a \cdot b}\). Then \(c = a \cdot b\) comes from the fact that \(\ell \) is randomly chosen, which makes the equality \(r_c = r_a \cdot r_b \mod \ell \) happen with negligible probability if \(c \ne a \cdot b\).
In the full version we also give a protocol \(\mathsf {PoProd}\) that proves \(g_1^a = A \wedge g_2^b = B\) instead of \(g_1^a g_2^b = Y\) (i.e., a version of \(\mathsf {PoDDH}\) with different generators). Despite being conceptually simpler, it is slightly less efficient than \(\mathsf {PoProd_2}\), and thus we use the latter in our VC construction.
Hash to prime function and non-interactive \(\mathsf {PoProd_2}\). Our protocols can be made non-interactive by applying the Fiat-Shamir transform. For this we need an hash function that can be modeled as a random oracle and that maps arbitrary strings to prime numbers, i.e., \(\mathsf{H}_{\mathsf {prime}}: \{0,1\}^* \rightarrow \mathsf {Primes}(2 \lambda )\)Footnote 8. A simple way to achieve such a function is to apply a standard hash function \(\mathsf{H}: \{0,1\}^* \rightarrow \{0,1\}^{2 \lambda }\) to an input \(\vec {y}\) together with a counter i, and if \(p_{y,i} = \mathsf{H}(\vec {y},i)\) is prime then output \(p_{y,i}\), otherwise continue to \(\mathsf{H}(\vec {y},i+1)\) and so on, until a prime is found. Due to the distribution of primes, the expected running time of this method is \(O(\lambda )\), assuming that \(\mathsf{H}\)’s outputs are uniformly distributed. For more discussion on hash-to-prime functions we refer to [GHR99, CMS99, CS99, BBF19, OWB19].
Our First SVC Construction. Now we are ready to describe our SVC scheme. For an intuition we refer the reader to the beginning of this section. Also, we note that while the intuition was given for the case of committing to a vector of bits, our actual VC construction generalizes this idea to vectors where each item is a block of k bits. This is done by creating 2k accumulators, each of them holding sets of indices i for specific positions inside each block \(v_j\).
Notation and Building Blocks
-
Our message space is \(\mathcal {M}= \{0,1\}^k\). Then for a vector \(\vec v \in \mathcal {M}^{n}\), we denote with \(i \in [n]\) the vector’s position, i.e., \(v_{i} \in \mathcal {M}\), and with \(j\in [k]\) the position of its j’th bit. So \(v_{i,j}\) denotes the j-th bit in position i.
-
We make use of a deterministic collision resistant function \(\mathsf {PrimeGen}\) that maps integers to primes. In our construction we do not need its outputs to be random (see e.g., [BBF19] for possible instantiations).
-
As a building block, we use the \(\mathsf {PoProd_2}\) AoK from the previous section.
-
\(\mathsf {PartndPrimeProd}(I,\vec {y}) \rightarrow \left( (a_{I,1}, b_{I,1}),\ldots ,(a_{I,k}, b_{I,k})\right) \): given a set of indices \(I = \{i_1, \ldots , i_{m}\} \subseteq [n]\) and a vector \(\vec y \in \mathcal {M}^{m}\), this function computes
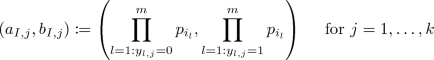
where \(p_i \leftarrow \mathsf {PrimeGen}(i)\) for all i.
Basically, for every bit position \(j \in [k]\), the function computes the products of primes that correspond to, respectively, 0-bits and 1-bits.
In the special case where \(I = [n]\), we omit the set of indices from the notation of the outputs, i.e., \(\mathsf {PartndPrimeProd}([n],\vec {v})\) outputs \(a_{j}\) and \(b_{j}\).
-
\(\mathsf {PrimeProd}(I) \rightarrow u_I\): given a set of indices I, this function outputs the product of all primes corresponding to indices in I. Namely, it returns
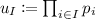 . In the special case \(I=[n]\), we denote the output of \(\mathsf {PrimeProd}([n])\) as \(u_n\).
. In the special case \(I=[n]\), we denote the output of \(\mathsf {PrimeProd}([n])\) as \(u_n\).Notice that by construction, for any I and \(\vec y\), it always holds \(a_{I,j} \cdot b_{I,j} = u_I\).
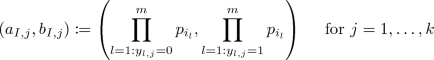
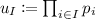 . In the special case
. In the special case SVC Scheme. We describe our SVC scheme and then show its incremental aggregation.
-
 generates a hidden order group
generates a hidden order group
 and samples three generators \(g,g_0,g_1 \leftarrow \mathbb {G}\). It also determines a deterministic collision resistant function \(\mathsf {PrimeGen}\) that maps integers to primes.
and samples three generators \(g,g_0,g_1 \leftarrow \mathbb {G}\). It also determines a deterministic collision resistant function \(\mathsf {PrimeGen}\) that maps integers to primes.Returns

-
 computes \(u_{n} \leftarrow \mathsf {PrimeProd}([n])\) and \(U_n=g^{u_n}\), and returns
computes \(u_{n} \leftarrow \mathsf {PrimeProd}([n])\) and \(U_n=g^{u_n}\), and returns
 . One can think of \(U_{n}\) as an accumulator to the set [n].
. One can think of \(U_{n}\) as an accumulator to the set [n]. -
 does the following:
does the following: -
1.
Compute \(\left( (a_{1}, b_{1}), \ldots ,(a_{k}, b_{k})\right) \leftarrow \mathsf {PartndPrimeProd}([n], \vec v)\); next,
$$\begin{aligned} \text {for all } j \in [k] \text { compute }A_j =g_0^{a_{j}} \text { and } B_j =g_1^{b_{j}} \end{aligned}$$One can think of each \((A_j, B_j)\) as a pair of RSA accumulators for two sets that constitute a partition of [n] done according to the bits of \(v_{1j}, \ldots , v_{nj}\). Namely \(A_j\) and \(B_j\) accumulate the sets \(\{i \in [n]: v_{i,j}=0 \}\) and \(\{i \in [n]: v_{i,j}=1 \}\) respectively.
-
2.
For all \(j \in [k]\), compute
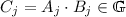 and a proof
and a proof
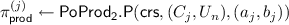 . Such proof ensures that the sets represented by \(A_j\) and \(B_j\) are a partition of the set represented by \(U_n\). Since \(U_n\) is part of the CRS (i.e., it is trusted), this ensures the well-formedness of \(A_j\) and \(B_j\).
. Such proof ensures that the sets represented by \(A_j\) and \(B_j\) are a partition of the set represented by \(U_n\). Since \(U_n\) is part of the CRS (i.e., it is trusted), this ensures the well-formedness of \(A_j\) and \(B_j\).
Return \(C^{\star } :=\left( \left\{ A_1,B_1, \ldots , A_k, B_k \right\} , \left\{ \pi _{\mathsf {prod}}^{(1)},...,\pi _{\mathsf {prod}}^{(k)} \right\} \right) \) and \(\mathsf{aux}^{\star } :=\vec v\).
-
1.
-
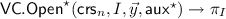 proceeds as follows:
proceeds as follows:-
let \(J = [n] \setminus I\) and compute \(\left( (a_{J, 1}, b_{J, 1}), \ldots ,(a_{J, k}, b_{J, k})\right) \! \leftarrow \!\mathsf {PartndPrimeProd}(J, \vec v_{J})\);
-
for all \(j \in [k]\) compute \( \varGamma _{I,j} :=g_0^{a_{J, j}}\) and \( \varDelta _{I,j} = g_1^{b_{J, j}}\).
Notice that \(a_{J, j} = a_{j,} / a_{I,j}\) and \(b_{J, j} = b_{j,} / b_{I,j}\). Also \( \varGamma _{I,j}\) is a membership witness for the set \(\{i_{l} \in I : y_{l,j}=0\}\) in the accumulator \(A_j\), and similarly for \( \varDelta _{I,j}\).
Return

-
-
 computes \(\left( (a_{I, 1}, b_{I, 1}), \ldots ,(a_{I, k}, b_{I, k})\right) \) using
computes \(\left( (a_{I, 1}, b_{I, 1}), \ldots ,(a_{I, k}, b_{I, k})\right) \) using\(\mathsf {PartndPrimeProd}(I, \vec y)\), and then returns \(b \leftarrow b_{acc} \wedge b_{prod}\) where:
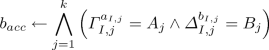 (1)
(1)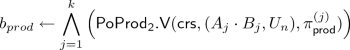 (2)
(2)
 generates a hidden order group
generates a hidden order group
 and samples three generators
and samples three generators 
 computes
computes  . One can think of
. One can think of  does the following:
does the following: 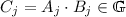 and a proof
and a proof
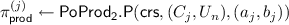 . Such proof ensures that the sets represented by
. Such proof ensures that the sets represented by 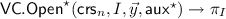 proceeds as follows:
proceeds as follows:
 computes
computes 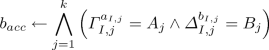
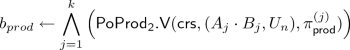
Remark 4.1
For more efficient verification, \(\mathsf{VC.Open}^{\star }\) can be changed to include 2k (non-interactive) proofs of exponentiation \(\mathsf {PoE}\) (which using the PoKCR aggregation from [BBF19] add only k elements of
 ). This reduces the exponentiations cost in \(\mathsf{VC.Ver}^{\star }\). As noted in [BBF19], although the asymptotic complexity is the same, the operations are in \(\mathbb {Z}_{2^{2 \lambda }}\) instead of \(\mathbb {G}\), which concretely makes up an improvement.
). This reduces the exponentiations cost in \(\mathsf{VC.Ver}^{\star }\). As noted in [BBF19], although the asymptotic complexity is the same, the operations are in \(\mathbb {Z}_{2^{2 \lambda }}\) instead of \(\mathbb {G}\), which concretely makes up an improvement.
The correctness of the vector commitment scheme described above is obvious by inspection (assuming correctness of \(\mathsf {PoProd_2}\)).
Incremental Aggregation. We show incremental aggregation of our SVC scheme.
-
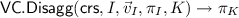 . Let \(L :=I \setminus K\), and \(\vec v_{L}\) be the subvector of \(\vec v_{I}\) at positions in L. Then compute \(\{a_{L,j}, b_{L,j}\}_{j \in [k]} \leftarrow \mathsf {PartndPrimeProd}(L, \vec v_{L})\), and for each \(j \in [k]\) set: \( \varGamma _{K,j} \leftarrow \varGamma _{I,j}^{a_{L, j}}\), \( \varDelta _{K,j} \leftarrow \varDelta _{I,j}^{b_{L, j}}\) and return \(\pi _{K} :=\{\pi _{K,1}, \dots ,\pi _{K,k} \} :=\left\{ ( \varGamma _{K,1}, \varDelta _{K,1}), \dots , ( \varGamma _{K,k}, \varDelta _{K,k})\right\} \)
. Let \(L :=I \setminus K\), and \(\vec v_{L}\) be the subvector of \(\vec v_{I}\) at positions in L. Then compute \(\{a_{L,j}, b_{L,j}\}_{j \in [k]} \leftarrow \mathsf {PartndPrimeProd}(L, \vec v_{L})\), and for each \(j \in [k]\) set: \( \varGamma _{K,j} \leftarrow \varGamma _{I,j}^{a_{L, j}}\), \( \varDelta _{K,j} \leftarrow \varDelta _{I,j}^{b_{L, j}}\) and return \(\pi _{K} :=\{\pi _{K,1}, \dots ,\pi _{K,k} \} :=\left\{ ( \varGamma _{K,1}, \varDelta _{K,1}), \dots , ( \varGamma _{K,k}, \varDelta _{K,k})\right\} \) -
 .
. -
1.
Let \(L :=I \cap J\). If \(L \ne \emptyset \), set
 and compute
and compute
 ; otherwise let \(\pi _{I'} = \pi _{I}\).
; otherwise let \(\pi _{I'} = \pi _{I}\). -
2.
Compute \(\{a_{I', j}, b_{I', j}\}_{j \in [k]} \leftarrow \mathsf {PartndPrimeProd}(I', \vec v_{I'})\) and \(\{a_{J, j}, b_{J, j}\}_{j \in [k]} \leftarrow \mathsf {PartndPrimeProd}(J, \vec v_{J})\).
-
3.
Parse
 ,
,
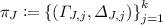 , and for all \(j \in [k]\), compute \( \varGamma _{K, j} \leftarrow \mathbf {ShamirTrick}( \varGamma _{I', j}, \varGamma _{J, j},a_{I', j}, a_{J, j})\) and
, and for all \(j \in [k]\), compute \( \varGamma _{K, j} \leftarrow \mathbf {ShamirTrick}( \varGamma _{I', j}, \varGamma _{J, j},a_{I', j}, a_{J, j})\) and\( \varDelta _{K, j} \leftarrow \mathbf {ShamirTrick}( \varDelta _{I', j}, \varDelta _{J, j},b_{I', j}, b_{J, j})\).
-
1.
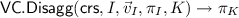 . Let
. Let  .
.  and compute
and compute
 ; otherwise let
; otherwise let  ,
,
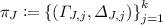 , and for all
, and for all Note that our algorithms above can work directly with the universal CRS
 , and do not need the specialized one
, and do not need the specialized one
 .
.
Aggregation Correctness. The second property of aggregation correctness (the one about \(\mathsf{VC.Disagg}\)) is straightforward by construction:
if we let \(\{a_{K, j}, b_{K,j}\}_{j \in [k]} \leftarrow \mathsf {PartndPrimeProd}(K, \vec v_{K})\), then \(a_{I,j} = a_{L,j} \cdot a_{K,j} \), and thus \(A_j = \varGamma _{I,j}^{a_{I,j}} = \varGamma _{I,j}^{a_{L,j} \cdot a_{K,j}} = \varGamma _{K,j}^{a_{K,j}}\) (and similarly for \( \varDelta _{K,j}\)).
The first property instead follows from the correctness of Shamir’s trick if the integer values provided as input are coprime; however since \(I' \cap J = \emptyset \), \(a_{I', j}\) and \(a_{J,j}\) (resp. \(b_{I', j}\) and \(b_{J,j}\)) are coprime unless a collision occurs in \(\mathsf {PrimeGen}\).
Security. The security of our SVC scheme, i.e., position binding, can be reduced to the Strong RSA and Low Order assumptions in the hidden order group
 used in the construction and to the knowledge extractability of \(\mathsf {PoProd_2}\).
used in the construction and to the knowledge extractability of \(\mathsf {PoProd_2}\).
A bit more in detail the steps of the proof are as follows. Let an adversary to the position binding output \((C, I, \vec y, \pi , \vec y', \pi ')\). First from knowledge extractability of \(\mathsf {PoProd_2}\) it comes that \(A_j B_j = g_1^{a_{j}} g_2^{b_{j}}\) and \(g^{a_{j} b_{j}} = U_{n} = g^{u_n}\). However, this does not necessarily means that \(a_{j} b_{j} = u_n\) over the integers and to prove it we need the Low Order assumptions, under which it holds. Afterwards we prove that since \(A_j B_j = g_1^{a_{j}} g_2^{b_{j}}\) no different proofs \(\pi ,\pi '\) for the same positions can pass the verification under the strong RSA assumption, which is the core of our proof. The main caveat of the proof is that instead of knowing that \(A_j = g_1^{a_{j}}\) and \(B_j = g_2^{b_{j}}\) we know only that \(A_j B_j = g_1^{a_{j}} g_2^{b_{j}}\). The former case would directly reduce to RSA Accumulator’s security (strong RSA assumption). For this we first need to prove an intermediate lemma which shows that specifically for our case \(A_j B_j = g_1^{a_{j}} g_2^{b_{j}}\) is enough, since the choice of the primes \(p_i\) in the exponent is restricted to a polynomially bounded set.
For lack of space, the proof is in the full version. For an intuition we refer to the overview given at the beginning of this section.
Theorem 4.2
(Position-Binding). Let \(\mathsf {Ggen}\) be the generator of hidden order groups where the Strong RSA and Low Order assumptions hold, and let \(\mathsf {PoProd_2}\) be an argument of knowledge for \(R_{\mathsf {PoProd_2}}\). Then the subVector Commitment scheme defined above is position binding.
On Concrete Instantiation. Our SVC construction is described generically from a hidden order group \(\mathbb {G}\), an AoK \(\mathsf {PoProd_2}\), and a mapping to primes \(\mathsf {PrimeGen}\). The concrete scheme we analyze is the one where \(\mathsf {PoProd_2}\) is instantiated with the non-interactive version of the \(\mathsf {PoProd_2}\) protocol described in Sect. 4.1. The non-interactive version needs a hash-to-prime function \(\mathsf{H}_{\mathsf {prime}}\). We note that the same function can be used to instantiate \(\mathsf {PrimeGen}\), though for the sake of \(\mathsf {PrimeGen}\) we do not need its randomness properties. One can choose a different mapping to primes for \(\mathsf {PrimeGen}\) and even just a bijective mapping (which is inherently collision resistant) would be enough: this is actually the instantiation we consider in our efficiency analysis. Finally, see Sect. 1.4 for a discussion on possible instantiations of \(\mathbb {G}\).
We note that by using the specific \(\mathsf {PoProd_2}\) protocol given in Sect. 4.1 we are assuming adversaries that are generic with respect to the group
 . Therefore, our SVC is ultimately position binding in the generic group model.
. Therefore, our SVC is ultimately position binding in the generic group model.
4.2 Our Second SVC Construction
In this section we propose another SVC scheme with constant-size parameters and incremental aggregation. This scheme builds on the SVC of [LM19] based on the RSA assumption, which in turn extends the VC of [CF13] to support subvector openings. Our technical contribution is twofold. First, we show that the SVC of [CF13, LM19] can be modified in order to have public parameters and verification time independent of the vector’s length. Second, we propose new algorithms for (incremental) aggregation and disaggregation for this SVC.
Our Second SVC Construction. Let us start by giving a brief overview of the [CF13] VC scheme and of the basic idea to turn it into one with succinct parameters and verification time. In brief, in [CF13] a commitment to a vector \(\vec v\) is \(C=S_1^{v_1} \cdots S_{n}^{v_{n}}\), where each \(S_i:=g^{\prod _{j \in [n]\setminus \{i\}} e_j}\) with
 a random generator and \(e_j\) being distinct prime numbers (which can be deterministically generated using a suitable map-to-primes). The opening for position i is an element \(\varLambda _{i}\) such that \(\varLambda _{i}^{e_i} \cdot S_{i}^{v_i} = C\) and the key idea is that such \(\varLambda _i\) is an \(e_i\)-th root that can be publicly computed as long as one does it for the correct position i and value \(v_i\). Also, as it can be seen, the element \(S_i\) is necessary to verify an opening of position i, and thus \((S_1, \ldots , S_n)\) were included in the public parameters. Catalano and Fiore observed that one can remove the \(S_i\)-s from
a random generator and \(e_j\) being distinct prime numbers (which can be deterministically generated using a suitable map-to-primes). The opening for position i is an element \(\varLambda _{i}\) such that \(\varLambda _{i}^{e_i} \cdot S_{i}^{v_i} = C\) and the key idea is that such \(\varLambda _i\) is an \(e_i\)-th root that can be publicly computed as long as one does it for the correct position i and value \(v_i\). Also, as it can be seen, the element \(S_i\) is necessary to verify an opening of position i, and thus \((S_1, \ldots , S_n)\) were included in the public parameters. Catalano and Fiore observed that one can remove the \(S_i\)-s from
 if the verifier opts for recomputing \(S_i\) at verification time at the price of linear-time verification. Our goal though is to obtain constant-size parameters and constant-time verification. To do that we let the prover compute \(S_i\) and include it in the opening for position i. To prevent adversaries from providing false \(S_i\)’s, we store in the public parameters \(U_n = g^{\prod _{i \in [n]}e_i}\) (i.e., an accumulator to all positions) so that the verifier can verify the correctness of \(S_i\) in constant-time by checking \(S_i^{e_i} = U_{n}\). This technique easily generalizes to subvector openings.
if the verifier opts for recomputing \(S_i\) at verification time at the price of linear-time verification. Our goal though is to obtain constant-size parameters and constant-time verification. To do that we let the prover compute \(S_i\) and include it in the opening for position i. To prevent adversaries from providing false \(S_i\)’s, we store in the public parameters \(U_n = g^{\prod _{i \in [n]}e_i}\) (i.e., an accumulator to all positions) so that the verifier can verify the correctness of \(S_i\) in constant-time by checking \(S_i^{e_i} = U_{n}\). This technique easily generalizes to subvector openings.
In the following, we describe the scheme in details and then propose our incremental aggregation algorithms. To simplify our exposition, we use the following notation: for a set of indices \(I \subseteq [n]\), \(e_{I} :=\prod _{i \in I} e_i\) denotes the product of all primes corresponding to the elements of I, and \(S_I :=g^{\prod _{i \in [n] \setminus I} e_i} = g^{e_{[n]\setminus I}} = U_{n}^{1/e_I}\) (which is a generalization of the former \(S_i\)), where, we recall, the \(e_i\)’s are defined from the
 .
.
-
 generates a hidden order group
generates a hidden order group
 and samples a generator
and samples a generator 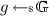 . It also determines a deterministic collision resistant function \(\mathsf {PrimeGen}\) that maps integers to primes.
. It also determines a deterministic collision resistant function \(\mathsf {PrimeGen}\) that maps integers to primes.Returns
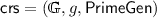
-
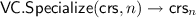 computes n primes of \((\ell +1)\) bits \(e_1, \dots , e_n\), \(e_i \leftarrow \mathsf {PrimeGen}(i)\) for each \(i \in [n]\), and \(U_n = g^{e_{[n]}}\) and returns
computes n primes of \((\ell +1)\) bits \(e_1, \dots , e_n\), \(e_i \leftarrow \mathsf {PrimeGen}(i)\) for each \(i \in [n]\), and \(U_n = g^{e_{[n]}}\) and returns
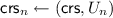 . One can think of \(U_{n}\) as an accumulator to the set [n].
. One can think of \(U_{n}\) as an accumulator to the set [n]. -
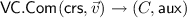 Computes for each \(i \in [n]\), \(S_i \leftarrow g^{e_{[n] \setminus \{i\}} }\) and then \(C \leftarrow S_1^{v_1} \dots S_n^{v_n}\) and \(\mathsf{aux}\leftarrow (v_1, \dots , v_n)\).
Computes for each \(i \in [n]\), \(S_i \leftarrow g^{e_{[n] \setminus \{i\}} }\) and then \(C \leftarrow S_1^{v_1} \dots S_n^{v_n}\) and \(\mathsf{aux}\leftarrow (v_1, \dots , v_n)\). -
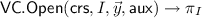 Computes for each \(j \in [n] \setminus I\), \(S_j^{1/e_I} \leftarrow g^{e_{[n] \setminus (I \cup \{j\} )} }\) and \(S_I \leftarrow g^{e_{[n] \setminus I} } \) and then $$\varLambda _I \leftarrow \prod _{j=1,j \notin I}^n \left( S_j^{1/e_I} \right) ^{y_j} = \left( \prod _{j=1,j \notin I}^n S_j^{y_j} \right) ^{1/e_I}$$
Computes for each \(j \in [n] \setminus I\), \(S_j^{1/e_I} \leftarrow g^{e_{[n] \setminus (I \cup \{j\} )} }\) and \(S_I \leftarrow g^{e_{[n] \setminus I} } \) and then $$\varLambda _I \leftarrow \prod _{j=1,j \notin I}^n \left( S_j^{1/e_I} \right) ^{y_j} = \left( \prod _{j=1,j \notin I}^n S_j^{y_j} \right) ^{1/e_I}$$Returns \(\pi _I :=(S_I,\varLambda _I)\)
-
 Parse \(\pi _I :=(S_I, \varLambda _I)\), and compute \(S_i = S_I^{e_{I \setminus \{i\}}} = U_n^{1/e_i}\) for every \(i \in I\). Return 1 (accept) if both the following checks hold, and 0 (reject) otherwise: $$S_I^{e_I} = U_n \; \wedge \; C = \varLambda _I^{e_I} \prod _{i \in I} S_i^{y_i}$$
Parse \(\pi _I :=(S_I, \varLambda _I)\), and compute \(S_i = S_I^{e_{I \setminus \{i\}}} = U_n^{1/e_i}\) for every \(i \in I\). Return 1 (accept) if both the following checks hold, and 0 (reject) otherwise: $$S_I^{e_I} = U_n \; \wedge \; C = \varLambda _I^{e_I} \prod _{i \in I} S_i^{y_i}$$The correctness of the above construction holds essentially the same as the one of the SVC of [CF13, LM19] with the addition of the \(S_{I}\) elements of the openings, whose correctness can be seen by inspection (and is the same as for RSA accumulators).
 generates a hidden order group
generates a hidden order group
 and samples a generator
and samples a generator 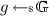 . It also determines a deterministic collision resistant function
. It also determines a deterministic collision resistant function 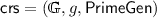
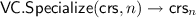 computes n primes of
computes n primes of 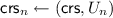 . One can think of
. One can think of 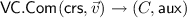 Computes for each
Computes for each 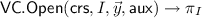 Computes for each
Computes for each  Parse
Parse Incremental Aggregation. Let us now show that the SVC above has incremental aggregation. Note that our algorithms also implicitly show that the RSA-based SVC of [LM19] is incrementally aggregatable.
-
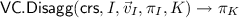 Parse \(\pi _I :=(S_I, \varLambda _I)\). First compute \(S_{K}\) from \(S_I\), \(S_{K} \leftarrow S_{I}^{e_{I \setminus K}}\), and then, for every \(j \in I \setminus K\), \(\chi _{j} = S_{K}^{1/e_j}\), e.g., by computing \(\chi _{j} \leftarrow S_{I}^{e_{I \setminus (K \cup \{j\})} }\). Return \(\pi _K :=(S_{K}, \varLambda _{K})\) where $$\varLambda _{K} \leftarrow \varLambda _I^{e_{I \setminus K}} \cdot \prod _{j \in I \setminus K} \chi _j^{v_j}$$
Parse \(\pi _I :=(S_I, \varLambda _I)\). First compute \(S_{K}\) from \(S_I\), \(S_{K} \leftarrow S_{I}^{e_{I \setminus K}}\), and then, for every \(j \in I \setminus K\), \(\chi _{j} = S_{K}^{1/e_j}\), e.g., by computing \(\chi _{j} \leftarrow S_{I}^{e_{I \setminus (K \cup \{j\})} }\). Return \(\pi _K :=(S_{K}, \varLambda _{K})\) where $$\varLambda _{K} \leftarrow \varLambda _I^{e_{I \setminus K}} \cdot \prod _{j \in I \setminus K} \chi _j^{v_j}$$ -
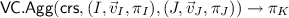 Parse \(\pi _I :=(S_I, \varLambda _I)\) and similarly \(\pi _{J}\). Also, let \(K = I \cup J\), and assume for simplicity that \(I \cap J = \emptyset \) (if this is not the case, one could simply disaggregate \(\pi _I\) (or \(\pi _J\)) to \(\pi _{I \setminus J}\) (or \(\pi _{J \setminus I}\))).
Parse \(\pi _I :=(S_I, \varLambda _I)\) and similarly \(\pi _{J}\). Also, let \(K = I \cup J\), and assume for simplicity that \(I \cap J = \emptyset \) (if this is not the case, one could simply disaggregate \(\pi _I\) (or \(\pi _J\)) to \(\pi _{I \setminus J}\) (or \(\pi _{J \setminus I}\))).First, compute \(S_K \leftarrow \mathbf {ShamirTrick}(S_I, S_J, e_I, e_J)\). Next, compute \(\phi _j \leftarrow S_K^{e_{J \setminus \{j\}}} = S_I^{1/e_j}\) for every \(j \in J\), and similarly \(\psi _i \leftarrow S_K^{e_{I \setminus \{i\}}} = S_J^{1/e_i}\) for every \(i \in I\). Then compute
$$ \rho _I \leftarrow \frac{\varLambda _I}{\prod _{j \in J } \phi _j^{v_j}} \quad \quad \text { and } \quad \quad \sigma _J \leftarrow \frac{\varLambda _J}{\prod _{i \in I } \psi _i^{v_i}} $$Return \(\pi _{K} :=(S_{K}, \varLambda _{K})\) where \(\varLambda _{K} \leftarrow \mathbf {ShamirTrick}(\rho _I, \sigma _J, e_I, e_J) \).
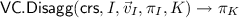 Parse
Parse 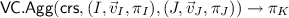 Parse
Parse Aggregation Correctness. It follows from the correctness of Shamir’s trick and by construction. The details are in the full version
Security. For the security of the above SVC scheme we observe that the difference with the corresponding [LM19] lies in the generation of \(S_i\)’s. In [LM19] they are generated in the trusted setup phase, thus they are considered “well-formed” in the security proof. In our case, the \(S_i\)’s are reconstructed during verification time from the \(S_I\) that comes in the opening \(\pi _I\) which can (possibly) be generated in an adversarial way. However, in the verification it is checked that \(S_I^{e_I} = U\), where \(U = g^{e_{[n]}}\) is computed in the trusted setup. So under the Low Order assumption we get that \(S_I\) has the correct form, \(S_I = g^{ e_{[n]}/e_I } = g^{e_{[n] \setminus I}}\), with overwhelming probability. Except for this change, the rest reduces to the position binding of the [LM19] SVC. The proof of the theorem is in the full version.
Theorem 4.3
(Position-Binding). Let \(\mathsf {Ggen}\) be the generator of hidden order groups where the Low Order assumption holds and the [LM19] SVC is position binding. Then the SVC scheme defined above is position binding.
As showed in [LM19], their SVC is position binding under the strong Distinct-Prime-Product Root assumption in the standard model. We conclude that the above SVC is position binding in hidden order groups where the Low Order and the Strong Distinct-Prime-Product Root assumptions hold.
4.3 Comparison with Related Work
We compare our two SVC schemes with the recent scheme proposed by Boneh et al. [BBF19] and the one by Lai and Malavolta [LM19], which extends [CF13] to support subvector openings.Footnote 9 We present a detailed comparison in Table 1, considering to work with vectors of length \(N\) of \(\ell \)-bit elements and security parameter
 . In particular we consider an instantiation of our first SVC with \(k=1\) (and thus \(n = N\cdot \ell \)). A detailed efficiency analysis of our schemes is in the full version.
. In particular we consider an instantiation of our first SVC with \(k=1\) (and thus \(n = N\cdot \ell \)). A detailed efficiency analysis of our schemes is in the full version.
Setup Model. [BBF19] works with a fully universal CRS, whereas our schemes have both a universal CRS with deterministic specialization, which however, in comparison to [CF13, LM19], outputs constant-size parameters instead of linear.
Aggregation. The VC of [BBF19] supports aggregation only on openings created by \(\mathsf{VC.Open}\) (i.e., it is one-hop) and does not have disaggregatable proofs (unless in a different model where one works linearly in the length of the vector or knows the full vector). In contrast, we show the first schemes that satisfy incremental aggregation (also, our second one immediately yields a method for the incremental aggregation of [LM19]). As we mention later, incremental aggregation can be very useful to precompute openings for a certain number of vector blocks allowing for interesting time-space tradeoffs that can speedup the running time of \(\mathsf{VC.Open}\).
Efficiency. From the table, one can see that our first SVC has: slightly worse commitments size than all the other schemes, computational asymptotic performances similar to [BBF19], and opening size slightly better than [BBF19]. Our second SVC is the most efficient among the schemes with constant-size parameters; in particular, it has faster asymptotics than our first SVC and [BBF19] for having a smaller logarithmic factor (e.g., \(\log (N- m)\) vs. \(\log (\ell N)\)), which is due to the avoidance of using one prime per bit of the vector. In some cases, [CF13, LM19] is slightly better, but this is essentially a benefit of the linear-size parameters, namely the improvement is due to having the \(S_i\)’s elements already precomputed.
When considering applications in which a user creates the commitment to a vector and (at some later points in time) is requested to produce openings for various subvectors, our incremental aggregation property leads to use preprocessing to achieve more favorable time and memory costs. In a nutshell, the idea of preprocessing is that one can precompute and store information that allows to speedup the generation of openings, in particular by making opening time less dependent on the total length of the vector. Our method in Sect. 3.2 works generically for any SVC that has incremental aggregation. A similar preprocessing solution can also be designed for the SVC of [BBF19] by using its one-hop aggregation; we provide a detailed description of the method in the full version. The preprocessing for [BBF19] however has no flexibility in choosing how much auxiliary storage can be used, and one must store (a portion of) a non-membership witness for every bit of the vector.
Even in the simplest case of \(B=1\) (shown in Table 1) both our SVCs save a factor \(\ell \) in storage, which concretely turns into \(3\times \) less storage.
Furthermore we support flexible choices of B thus allowing to tune the amount of auxiliary storage. For instance, we can choose \(B=\sqrt{N}\) so as to get
 bits of storage, and opening time about \(O(\ell m \log n (\sqrt{n} + \log m))\) and \(O(m (\sqrt{n} + \log ^2 m ))\) in the first and second scheme respectively. Our flexibility may also allow one to choose the buckets size B and their distribution according to applications-dependent heuristics; investigating its benefit may be an interesting direction for future work.
bits of storage, and opening time about \(O(\ell m \log n (\sqrt{n} + \log m))\) and \(O(m (\sqrt{n} + \log ^2 m ))\) in the first and second scheme respectively. Our flexibility may also allow one to choose the buckets size B and their distribution according to applications-dependent heuristics; investigating its benefit may be an interesting direction for future work.
 ’ we mean O(x) group operations in
’ we mean O(x) group operations in
 ;
;
 denotes the bit length of an element of
denotes the bit length of an element of
 . An alternative algorithm for \(\mathsf{VC.Open}\) in [LM19] costs \(O(\ell \cdot (N- m) \cdot \log (N- m))\). Our precomputation is for \(B=1\).
. An alternative algorithm for \(\mathsf{VC.Open}\) in [LM19] costs \(O(\ell \cdot (N- m) \cdot \log (N- m))\). Our precomputation is for \(B=1\).4.4 Experimental Evaluation
We have implemented in Rust our first SVC scheme of Sect. 4.1 (with and without preprocessing) and the recent SVC of [BBF19] (referred as BBF in what follows). Here we discuss an experimental evaluation of these schemes.Footnote 10 Below is a summary of the comparison, details of the experiments are in the full version.
-
Our SVC construction is faster in opening and verification than BBF (up to \(2.5\times \) and \(2.3\times \) faster respectively), but at the cost of a slower commitment stage (up to \(6\times \) slower). These differences tend to flatten for larger vectors and opening sizes.
-
Our SVC construction with preprocessing allows for extremely fast opening times compared to non-preprocessing constructions. Namely, it can reduce the running time by several orders of magnitude for various choices of vector and opening sizes, allowing to obtain practical opening times—of the order of seconds—that would be impossible without preprocessing—of the order of hundred of seconds. In a file of 1 Mibit (\(2^{20}\) bits), preprocessing reduces the time to open 2048 bits from one hour to less than 5 s! This efficient opening, however, comes at the cost of a one-time preprocessing (during commitment) and higher storage requirements. We discuss how to mitigate these space requirements by trading for opening time and/or communication complexity later in this section. We stress that it is thanks to the incremental aggregation property of our construction that allows these tradeoffs (they are not possible in BBF with preprocessing).
-
Although our SVC construction with preprocessing has an expensive commitment stage, this tends to be amortized throughout very few openingsFootnote 11, as few as 30 (see full version for more details). These effects are particularly significant over a higher number of openings: over 1000 openings our SVC construction with preprocessing has an amortized cost of less than 6 s, while our SVC construction and BBF have amortized openings above 90 s.
Time/Storage Tradeoffs. Our construction allows for some tradeoffs between running times and storage by selecting larger precomputed chunks or by committing to hashed blocks of the file. See the full version for a detailed discussion.
5 Verifiable Decentralized Storage
In this section we introduce verifiable decentralized storage (VDS). We recall that in VDS there are two types of parties (called nodes): the generic client nodes and the more specialized storage nodes (a storage node can also act as a client node). We refer the reader to Sect. 1.2 for a discussion on the motivation and requirements of VDS.
5.1 Syntax
Here we introduce the syntax of VDS. A VDS scheme is defined by a collection of algorithms that are to be executed by either storage nodes or client nodes. The only exception is the \(\mathsf {Bootstrap}\) algorithm that is used to bootstrap the entire system and is assumed to be executed by a trusted party, or to be implemented in a distributed fashion (which is easy if it is public coin).
The syntax of VDS reflects its goal: guaranteeing data integrity in a highly dynamic and decentralized setting (the file can change and expand/shrink often and no single node stores it all). In VDS we create both parameters and an initial commitment for an empty file at the beginning (through the probabilistic \(\mathsf {Bootstrap}\) algorithm, which requires a trusted execution). From then on this commitment is changed through incremental updates (of arbitrary size). Updating is divided in two parts. A node can carry out an update and “push” it to all the other nodes, i.e. providing auxiliary information (that we call “update hint”) other nodes can use to update their local certificates (if affected by the change) and a new digestFootnote 12. These operations are done respectively through \(\mathsf {StrgNode}.\mathsf {PushUpdate}\) and \(\mathsf {StrgNode}.\mathsf {ApplyUpdate}\). Opening and verifying are where VC (with incremental aggregation) and VDS share the same mechanism. To respond to a query, a storage node can produce (possibly partial) proofs of opening via the \(\mathsf {StrgNode}.\mathsf {Retrieve}\) algorithm. If these proofs need to be aggregated, any node can use algorithm \(\mathsf {AggregateCertificates}\). Anyone can verify a proof through \(\mathsf {ClntNode}.\mathsf {VerRetrieve}\).
Some more details about our notation follow. In VDS we model the files to be stored as vectors in some message space \(\mathcal {M}\) (e.g., \(\mathcal {M}=\{0, 1\}\) or \(\{0, 1\}^{\ell }\)), i.e., \(\mathsf {F}= (\mathsf {F}_1, \ldots , \mathsf {F}_{N})\). Given a file \(\mathsf {F}\), we define a portion of it as a pair \((I, \mathsf {F}_{I})\) where \(\mathsf {F}_{I}\) is essentially the I-subvector of \(\mathsf {F}\). We denote input (resp. output) states by \(\mathsf {st}\) (resp. \(\mathsf {st}'\)). Update operations \(\mathsf {op}\) are modifications, additions or deletions, i.e. \(\mathsf {op}\in \{\mathsf {mod}, \mathsf {add}, \mathsf {del}\}\), and \(\varDelta \) denotes the update description, e.g., which positions to change and the new values. We denote by \(\varUpsilon _{\varDelta }\) the update hint that whoever is producing the update can share with other nodes to generate a new digest from the changes. The output bit b marks acceptance/rejection. For a query Q, we mark by \(\pi _Q\) a certificate vouching for a response \(\mathsf {F}_Q\).
Definition 5.1
(Verifiable Decentralized Storage).
Algorithm to bootstrap the system:
-
 which outputs a digest and storage node’s local state for an empty file. All the algorithms below implicitly take the public parameters \(\mathsf {pp}\) as input.
which outputs a digest and storage node’s local state for an empty file. All the algorithms below implicitly take the public parameters \(\mathsf {pp}\) as input.
 which outputs a digest and storage node’s local state for an empty file. All the algorithms below implicitly take the public parameters
which outputs a digest and storage node’s local state for an empty file. All the algorithms below implicitly take the public parameters The algorithms for storage nodes are:
-
\(\mathsf {StrgNode}.\mathsf {AddStorage}(\delta , n, \mathsf {st}, I, \mathsf {F}_I, Q, \mathsf {F}_Q, \pi _Q ) \rightarrow (\mathsf {st}', J, \mathsf {F}_{J})\) by which a storage node can extend its storage from \((I, \mathsf {F}_I)\) to \((J, \mathsf {F}_{J}) :=(I, \mathsf {F}_I) \cup (Q, \mathsf {F}_Q)\). Note: this allows anyone holding a valid certificate for a file portion \(\mathsf {F}_{Q}\) to become a storage node of such portion.
-
\(\mathsf {StrgNode}.\mathsf {RmvStorage}(\delta , n, \mathsf {st}, I, \mathsf {F}_I, K) \rightarrow (\mathsf {st}', J, \mathsf {F}_{J})\) by which a storage node can shrink its local storage to \((J, \mathsf {F}_{J})\).
-
\(\mathsf {StrgNode}.\mathsf {PushUpdate}(\delta , n, \mathsf {st}, I, \mathsf {F}_I, \mathsf {op}, \varDelta ) \rightarrow (\delta ', n', \mathsf {st}', J, \mathsf {F}'_{J}, \varUpsilon _{\varDelta })\) which allows a storage node to perform an update on \((I, \mathsf {F}_I)\) generating a corresponding new digest, length and local view, along with hint \(\varUpsilon _{\varDelta }\) others can use to update their own digests/local view.
-
\(\mathsf {StrgNode}.\mathsf {ApplyUpdate}(\delta , n, \mathsf {st}, I, \mathsf {F}_I, \mathsf {op}, \varDelta , \varUpsilon _{\varDelta }) \rightarrow (b, \delta ', n', \mathsf {st}', J, \mathsf {F}'_J)\) which allows a storage node to incorporate changes in a file pushed by another node.
-
\(\mathsf {StrgNode}.\mathsf {Retrieve}(\delta , n, \mathsf {st}, I, \mathsf {F}_I, Q) \rightarrow (\mathsf {F}_Q, \pi _Q)\) which allows a storage node to respond to a query and to create a certificate vouching for the correctness of the returned blocks.
The algorithms for clients nodes are:
-
\(\mathsf {ClntNode}.\mathsf {ApplyUpdate}(\delta , \mathsf {op}, \varDelta , \varUpsilon _{\varDelta }) \rightarrow (b, \delta ')\) which updates a digest by hint \(\varUpsilon _{\varDelta }\).
-
\(\mathsf {ClntNode}.\mathsf {VerRetrieve}(\delta , Q, \mathsf {F}_Q, \pi _Q) \rightarrow b\) which verifies a response to a query.
-
\(\mathsf {AggregateCertificates}(\delta ,(I, \mathsf {F}_{I}, \pi _{I}), (J, \mathsf {F}_J, \pi _J)) \rightarrow \pi _{K}\) which aggregates two certificates \(\pi _I\) and \(\pi _J\) into a single certificate \(\pi _{K}\) (with \(K :=I \cup J\)). In a running VDS, any node can aggregate two (or more) incoming certified data blocks into a single certified data block.
Remark 5.1
(On CreateFrom). For completeness, our VDS syntax also includes the functionalities \((\mathsf {StrgNode}.\mathsf {CreateFrom}, \mathsf {ClntNode}.\mathsf {GetCreate})\) that allow a storage node to initialize storage (and corresponding digest) for a new file that is a subset of an existing one, and a client node to verify such resulting digest. Although this feature can be interesting in some application scenarios, we still see it as an extra feature that may or may not be satisfied by a VDS construction. We refer to the full version for more discussion and a detailed description of this functionality.
5.2 Correctness and Efficiency of VDS
Intuitively, we say that a VDS scheme is efficient if running VDS has a “small” overhead in terms of the storage required by all the nodes and the bandwidth to transmit certificates. More formally, a VDS scheme is said efficient if there is a fixed polynomial \(p(\cdot )\) such that
 (with
(with
 the security parameter and n the length of the file) is a bound for all certificates and advices generated by the VDS algorithms as well as for digests \(\delta \) and the local state \(\mathsf {st}\) of storage nodes. Note that combining this bound with the requirement that all algorithms are polynomial time in their input, we also get that no VDS algorithm can run linearly in the size of the file (except in the trivial case that the file is processed in one shot, e.g., in the first \(\mathsf {StrgNode}.\mathsf {AddStorage}\)).
the security parameter and n the length of the file) is a bound for all certificates and advices generated by the VDS algorithms as well as for digests \(\delta \) and the local state \(\mathsf {st}\) of storage nodes. Note that combining this bound with the requirement that all algorithms are polynomial time in their input, we also get that no VDS algorithm can run linearly in the size of the file (except in the trivial case that the file is processed in one shot, e.g., in the first \(\mathsf {StrgNode}.\mathsf {AddStorage}\)).
Efficiency essentially models that running VDS is cost-effective for all the nodes in the sense that it does not require them to store significantly more data than they would have to store without. Notice that by requiring certificates to have a fixed size implies that they do not grow with aggregation.
For correctness, intuitively speaking, we want that for any (valid) evolution of the system in which the VDS algorithms are honestly executed we get that any storage node storing a portion of a file \(\mathsf {F}\) can successfully convince a client holding a digest of \(\mathsf {F}\) about retrieval of any portion of \(\mathsf {F}\). And such (intuitive notion of) correctness is also preserved when updates, aggregations, or creations of new files are done.
Turning this intuition into a formal correctness definition turned out to be nontrivial. This is due to the distributed nature of this primitive and the fact that there could be many possible ways in which, at the time of answering a retrieval query, a storage node may have reached its state starting from the empty node state. The basic idea of our definition is that an empty node is “valid”, and then any “valid” storage node that runs \(\mathsf {StrgNode}.\mathsf {PushUpdate}\) “transfers” such validity to both itself and to other nodes that apply such update. A bit more precisely, we model “validity” as the ability to correctly certify retrievals of any subsets of the stored portion. A formal correctness definition follows. To begin with, we define the notion of validity for the view of a storage node.
Definition 5.2
(Validity of storage node’s view). Let \(\mathsf {pp}\) be public parameters as generated by \(\mathsf {Bootstrap}\). We say that a local view \((\delta , n, \mathsf {st}, I, \mathsf {F}_I)\) of a storage node is valid if \(\forall Q \subseteq I\): \(\mathsf {ClntNode}.\mathsf {VerRetrieve}(\delta , Q, \mathsf {F}_Q, \pi _Q) = 1\), where \((\mathsf {F}_{Q}, \pi _Q) \leftarrow \mathsf {StrgNode}.\mathsf {Retrieve}(\delta , n, \mathsf {st}, I, \mathsf {F}_{I}, Q)\)
Remark 5.2
By Definition 5.2 the output of a bootstrapping algorithm
 is always such that
is always such that  is valid. This provides a “base case” for Definition 5.4.
is valid. This provides a “base case” for Definition 5.4.
Second, we define the notion of admissible update, which intuitively models when a given update can be meaningfully processed, locally, by a storage node.
Definition 5.3
(Admissible Update). An update \((\mathsf {op}, \varDelta )\) is admissible for \((n, I, \mathsf {F}_I)\) if:
-
for \(\mathsf {op}= \mathsf {mod}\), \( K \subseteq I\) and \(|\mathsf {F}'_{K}| = |K|\), where \(\varDelta :=(K,\mathsf {F}'_K)\).
-
for \(\mathsf {op}= \mathsf {add}\), \(K \cap I = \emptyset \) and \(|\mathsf {F}'_{K}| = |K|\) and \(K = \{n+1, n+2, \ldots , n+|K|\}\), where \(\varDelta :=(K,\mathsf {F}'_K)\).
-
for \(\mathsf {op}= \mathsf {del}\), \(K \subseteq I\) and \(K = \{n-|K|+1, \dots , n\}\), where \(\varDelta :=K\).
In words, the above definition formalizes that: to push a modification at positions K, the storage node must store those positions; to push an addition, the new positions K must extend the currently stored length of the file; to push a deletion of position K, the storage node must store data of the positions to be deleted and those positions must also be the last |K| positions of the currently stored file (i.e., the file length is reduced).
Definition 5.4
(Correctness of VDS). A VDS scheme \(\mathsf {VDS}\) is correct if for all honestly generated parameters
 and any storage node’s local view \((\delta , n, \mathsf {st}, I, \mathsf {F}_I)\) that is valid, the following conditions hold.
and any storage node’s local view \((\delta , n, \mathsf {st}, I, \mathsf {F}_I)\) that is valid, the following conditions hold.
Update Correctness. For any update \((\mathsf {op}, \varDelta )\) that is admissible for \((n, I, \mathsf {F}_{I})\) and for any \((\delta ', n', \mathsf {st}', J, \mathsf {F}'_{J}, \varUpsilon _{\varDelta }) \leftarrow \mathsf {StrgNode}.\mathsf {PushUpdate}( \delta , n, \mathsf {st}, I, \mathsf {F}_I, \mathsf {op}, \varDelta )\):
-
1.
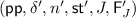 is valid;
is valid; -
2.
for any valid \((\delta , n, \mathsf {st}_s, I_s, \mathsf {F}_{I_s})\), if \((b_s, \delta _s', n', \mathsf {st}_s', I'_s, \mathsf {F}_s') \! \leftarrow \) \(\mathsf {StrgNode}.\mathsf {ApplyUpdate}(\delta , n, \mathsf {st}_s, I_s, \mathsf {F}_{I_s}, \mathsf {op}, \varDelta , \varUpsilon _{\varDelta })\) then we have: \(b_{s} = 1\), \(\delta _s' = \delta '\), \(n_s' = n'\), and \((\delta _s', n_{s}', \mathsf {st}_s', I_s', \mathsf {F}_s')\) is valid;
-
3.
if \((b_c, \delta _c') \leftarrow \mathsf {ClntNode}.\mathsf {ApplyUpdate}(\delta , \mathsf {op}, \varDelta , \varUpsilon _{\varDelta }) \), then \(\delta _c' = \delta '\) and \(b_c=1\).
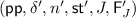 is valid;
is valid;Add-Storage Correctness. For any \((Q,\mathsf {F}_Q,\pi _Q)\) such that \(\mathsf {ClntNode}.\mathsf {VerRetrieve}(\delta , Q, \mathsf {F}_Q, \pi _Q) = 1\), if \((\mathsf {st}', J, \mathsf {F}_{J}) \leftarrow \mathsf {StrgNode}.\mathsf {AddStorage}\) \((\delta , \mathsf {st}, I, \mathsf {F}, Q, \mathsf {F}_Q, \pi _Q )\) then \((\delta , n, \mathsf {st}', J, \mathsf {F}_J)\) is valid.
Remove-Storage Correctness. For any \(K \subseteq I\),if \((\mathsf {st}', J, \mathsf {F}_{J}) \leftarrow \mathsf {StrgNode}.\mathsf {RmvStorage}(\delta , \mathsf {st}, I, \mathsf {F}, K )\) then \((\delta , n, \mathsf {st}', J, \mathsf {F}_J)\) is valid.
Create Correctness. For any \(J \subseteq I\), if \((\delta ', n', \mathsf {st}', J, \mathsf {F}_J, \varUpsilon _J)\) is output of \( \mathsf {StrgNode}.\mathsf {CreateFrom}(\delta , n, \mathsf {st}, I, \mathsf {F}_I, J)\) and \((b, \delta '') \leftarrow \mathsf {ClntNode}.\mathsf {GetCreate}(\delta , J,\) \( \varUpsilon _J)\), then \(b=1\), \(n' = |J|\), \(\delta '' = \delta '\) and \((\mathsf {pp}, \delta ', n', \mathsf {st}', J, \mathsf {F}_J)\) is valid.
Aggregate Correctness. For any pair of triples \((I, \mathsf {F}_I, \pi _I)\) and \((J, \mathsf {F}_J, \pi _J)\) such that \(\mathsf {ClntNode}.\mathsf {VerRetrieve}(\delta , I, \mathsf {F}_I, \pi _I) = 1\) and \(\mathsf {ClntNode}.\mathsf {VerRetrieve}(\delta , J,\) \( \mathsf {F}_J, \pi _J) = 1\), if \(\pi _K \leftarrow \mathsf {AggregateCertificates}((I, \mathsf {F}_I, \pi _I), (J, \mathsf {F}_J, \pi _J))\) and (K, \( \mathsf {F}_K) :=(I, \mathsf {F}_I) \cup (J, \mathsf {F}_J)\), then \(\mathsf {ClntNode}.\mathsf {VerRetrieve}(\delta , K, \mathsf {F}_K, \pi _K)=1\).
Remark 5.3
(Relation with Updatable VCs). Our notion of VDS is very close to the notion of updatable VCs [CF13] extended to support subvector openings and incremental aggregation. On a syntactical level, in comparison to updatable VCs, our VDS notion makes more evident the decentralized nature of the primitive, which is reflected in the definition of our algorithms where for example it is clear that no one ever needs to store/know the entire file. One major difference is that in VDS the public parameters must necessarily be short since no node can run linearly in the size of the file (nor it can afford such storage), whereas in VCs this may not be necessarily the case. Another difference is that in updatable VCs [CF13] updates can be received without any hint, which is instead the case in VDS. Finally, it is interesting to note that, as of today, there exists no VC scheme that is updatable, incrementally aggregatable and with subvector openings, that enjoys short parameters and has the required short verification time. So, in a way, our two VDS realizations show how to bypass this barrier of updatable VC by moving to a slightly different (and practically motivated) model.
5.3 Security of VDS
In this section we discuss the security definition of VDS schemes. For lack of space a formal definition is in the full version. Intuitively speaking, we require that a malicious storage node (or a coalition of them) cannot convince a client of a false data block in a retrieval query. To formalize this, we let the adversary fully choose a history of the VDS system that starts from the empty state and consists of a sequence of steps, where each step is either an update (addition, deletion, modification) or a creation (from an existing file) and is accompanied by an advice. A client’s digest \(\delta \) is updated following such history and using the adversarial advices, and similarly one gets a file \(\mathsf {F}\) corresponding to such digest. At this point, the adversary’s goal is to provide a tuple \((Q, \pi _Q, \mathsf {F}^{*}_{Q})\) that is accepted by a client with digest \(\delta \) but where \(\mathsf {F}^{*}_{Q} \ne \mathsf {F}_{Q}\).
VDS Proof of Storage. As an additional security mechanism we consider the possibility to ensure a client that a given file is stored by the network at a certain point of time without having to retrieve it. To this end, we extend the VDS notion to provide a proof of storage mechanism in the form of a proof of retrievability (PoR) [JK07] or a proof of data possession (PDP) [ABC+07]. Our proof of storage model for VDS is such that proofs are publicly verifiable given the file’s digest. Also, in order to support the decentralized and open nature of DSNs, the entire proof mechanism should not use any secret, and proofs should be generatable in a distributed fashion (this is a main distinguishing feature compared to existing PoRs/PDPs) while staying compact. The formalization of this property is in the full version.
5.4 Realizing VDS
We show two realizations of VDS in hidden-order groups, summarized below.
Theorem 5.1
(\(\mathsf {VDS}_1\)). Under the strong RSA assumption in a hidden-order group
 , there exists a VDS scheme \(\mathsf {VDS}_1\) in which, for a file \(\mathsf {F}\): a digest \(\delta _{F}\) is
, there exists a VDS scheme \(\mathsf {VDS}_1\) in which, for a file \(\mathsf {F}\): a digest \(\delta _{F}\) is
 bits-long; a storage node holding \((I, \mathsf {F}_I)\) keeps a state \(\mathsf {st}_{I}\) of
bits-long; a storage node holding \((I, \mathsf {F}_I)\) keeps a state \(\mathsf {st}_{I}\) of
 bits, answers retrieval of portion Q with a certificate of
bits, answers retrieval of portion Q with a certificate of
 bits in time \(O(\ell \cdot (|I| - |Q|) \log | \mathsf {F}|)\), and pushes an update \(\varDelta \) in time \(O(\ell \cdot |I| \log |\mathsf {F}|)\) for \(\mathsf {op}=\mathsf {mod}\), \(O(\ell \cdot |\varDelta | \log |\mathsf {F}|)\) for \(\mathsf {op}=\mathsf {add}\), and \(O(\ell \cdot (|I| - |\varDelta |) \log |\mathsf {F}|)\) for \(\mathsf {op}=\mathsf {del}\); a client verifies a query for positions in Q (resp. an update \(\varDelta \)) in time \(O(\ell \cdot |Q| \log |F| )\) (resp. \(O(\ell \cdot |\varDelta | \log |F| )\)).
bits in time \(O(\ell \cdot (|I| - |Q|) \log | \mathsf {F}|)\), and pushes an update \(\varDelta \) in time \(O(\ell \cdot |I| \log |\mathsf {F}|)\) for \(\mathsf {op}=\mathsf {mod}\), \(O(\ell \cdot |\varDelta | \log |\mathsf {F}|)\) for \(\mathsf {op}=\mathsf {add}\), and \(O(\ell \cdot (|I| - |\varDelta |) \log |\mathsf {F}|)\) for \(\mathsf {op}=\mathsf {del}\); a client verifies a query for positions in Q (resp. an update \(\varDelta \)) in time \(O(\ell \cdot |Q| \log |F| )\) (resp. \(O(\ell \cdot |\varDelta | \log |F| )\)).
Theorem 5.2
(\(\mathsf {VDS}_2\)). Under the strong distinct-prime-product root and the Low Order assumptions in a hidden-order group
 , there exists a VDS scheme \(\mathsf {VDS}_2\) in which, for a file \(\mathsf {F}\): a digest \(\delta _{F}\) is
, there exists a VDS scheme \(\mathsf {VDS}_2\) in which, for a file \(\mathsf {F}\): a digest \(\delta _{F}\) is
 bits-long; a storage node holding \((I, \mathsf {F}_I)\) keeps a state \(\mathsf {st}_{I}\) of
bits-long; a storage node holding \((I, \mathsf {F}_I)\) keeps a state \(\mathsf {st}_{I}\) of
 bits, answers retrieval of portion Q with a certificate of
bits, answers retrieval of portion Q with a certificate of
 bits in time \(O(\ell \cdot (|I| - |Q|) \log ( | I | - |Q|))\), and pushes an update \(\varDelta \) in time \(O(\ell \cdot |\varDelta | \log |\varDelta |)\) for \(\mathsf {op}=\mathsf {mod},\mathsf {add}\), and \(O(\ell \cdot (|I| + |\varDelta | \log |\varDelta |))\) for \(\mathsf {op}=\mathsf {del}\); a client verifies a query for positions in Q (resp. an update \(\varDelta \)) in time \(O(\ell \cdot |Q| \log |Q| )\) (resp. \(O(\ell \cdot |\varDelta | \log |\varDelta | )\)).
bits in time \(O(\ell \cdot (|I| - |Q|) \log ( | I | - |Q|))\), and pushes an update \(\varDelta \) in time \(O(\ell \cdot |\varDelta | \log |\varDelta |)\) for \(\mathsf {op}=\mathsf {mod},\mathsf {add}\), and \(O(\ell \cdot (|I| + |\varDelta | \log |\varDelta |))\) for \(\mathsf {op}=\mathsf {del}\); a client verifies a query for positions in Q (resp. an update \(\varDelta \)) in time \(O(\ell \cdot |Q| \log |Q| )\) (resp. \(O(\ell \cdot |\varDelta | \log |\varDelta | )\)).
In terms of assumptions, \(\mathsf {VDS}_1\) is based on a weaker assumption than \(\mathsf {VDS}_2\) (although the assumptions are equivalent when
 is instantiated with RSA groups).
is instantiated with RSA groups).
In terms of performances, as one can see, \(\mathsf {VDS}_1\) and \(\mathsf {VDS}_2\) do similarly, with \(\mathsf {VDS}_2\) being slightly more efficient. In \(\mathsf {VDS}_1\) the complexity of all operations includes a factor \(\alpha = \log |\mathsf {F}|\), whereas in \(\mathsf {VDS}_2\) operations are affected by a factor logarithmic only in the number of positions involved in the given operation (e.g., how many are updated), which is typically much smaller than the entire file. Also, \(\mathsf {VDS}_2\) has the interesting feature that storage nodes can add and modify values in time which depends only on the update size but not on the size of the local storage.
Finally, \(\mathsf {VDS}_1\) has the additional feature of being compatible with our succinct arguments of knowledge, which enable the \(\mathsf {StrgNode}.\mathsf {CreateFrom}\) functionality and compact Proofs of Data Possession (see next section for an intuition and the full version for the details).
The main ideas of the two constructions are described in the following paragraphs; full constructions are in the full version.
Our First VDS Construction. Our first VDS \(\mathsf {VDS}_1\) is obtained by extending the techniques used for our SVC of Sect. 4.1.
Let us assume for a moment that a digest for file \(\mathsf {F}\) is a commitment to \(\mathsf {F}\). Then, a storage node holding a portion \((I, \mathsf {F}_I)\) keeps as local state \(\mathsf {st}_I = \pi _I = ( \varGamma _{I}, \varDelta _{I})\), and this clearly enables it to certify retrieval queries for any portion \(Q \subseteq I\) by using disaggregation in order to create \(\pi _{Q}\) from \(\pi _{I}\). Moreover, such certificates of retrieval queries can be arbitrarily aggregated over the network.
In order to support updates, the main obstacle is that our commitment cannot be publicly updated without knowing the entire vector due to the presence of the AoK of union of \(\mathsf {Acc}_0\) and \(\mathsf {Acc}_1\). To solve this, we exploit the fact that in the VDS security model the digest provided by the adversary must be compatible with the claimed history of changes. So we can remove the AoK. Then, updating the digest boils down to updating the two RSA accumulators \((\mathsf {Acc}_0, \mathsf {Acc}_1)\) appropriately. For instance, changing the i-th bit from 0 to 1 requires to remove \(p_i\) from \(\mathsf {Acc}_0\) (i.e., \(\mathsf {Acc}_0' = \mathsf {Acc}_0^{1/p_i}\) computable through \(\pi _{I}\)) and adding it to \(\mathsf {Acc}_1\) (i.e., \(\mathsf {Acc}_1' = \mathsf {Acc}_1^{p_i}\)). This can be performed by a storage node holding positions in the set I such that \(i \in I\), and verified by anyone having previous and new digest. As we show in the full description of the scheme, by using similar ideas other storage nodes holding other positions, say J, can also update their local state \(\mathsf {st}_{J}\) accordingly.
Finally, in this VDS we take advantage of our efficient AoK protocols to support two additional features. The first one is a compact proof of data possession by which the storage node can convince a verifier that it stores a certain subset of positions without sending the data at those positions. The second one is what we call “CreateFrom”: a storage node holding a prefix \(\mathsf {F}'\) of \(\mathsf {F}\) can publish a new digest \(\delta _{\mathsf {F}'}\) corresponding to \(\mathsf {F}'\) as a new file, and to convince any client about its correctness without the need for them to know neither \(\mathsf {F}'\) nor \(\mathsf {F}\).
Our Second VDS Construction. Our second scheme \(\mathsf {VDS}_2\) is obtained by modifying our second SVC scheme from Sect. 4.2 and makes key use of its aggregation/disaggregation properties.
As in our first VDS scheme, a storage node holding \((I, \mathsf {F}_I)\) keeps an opening \(\pi _{I}\) as local state, and uses our disaggregation and aggregation methods to certify retrieval queries for \(Q \subset I\).
Let us now turn to how we can support updates. Let us consider an update on a subset K of the vector. First, the commitment is updatable as \(C' \leftarrow C \cdot \prod _{i \in K} S_i^{\mathsf {F}_i'-\mathsf {F}_i}\). To update the opening proof, which we recall is \(\pi _I :=(S_I,\varLambda _I)\), we note that the \(\varLambda _I\)-part is updatable without the need of hint as \(\varLambda _I' \leftarrow \varLambda _I \cdot \left( \prod _{j \in K \setminus I} S_j^{1/\prod _{i \in I } e_i} \right) ^{\mathsf {F}_j' - \mathsf {F}_j}\). This part works as in [CF13] with some additional techniques that let a node do this in time \(O(|I| + |K| \log |K|)\) and without having to store all the \(S_j\) values. The \(S_I\)-part resembles an RSA accumulator witness as observed in Sect. 4.2, and thus we can use techniques similar to those of our first VDS construction to update it. That is, upon update on K, \(S_K\) is sufficient for any node to update \(S_I\) (more details are in the full version).
A remaining problem is that the SVC scheme works with a specialized CRS, \(U_n = g^{e_{[n]}}\), which depends on the vector’s length. In the SVC schemes, this CRS is generated (deterministically) only once, but in VDS the vector’s length evolves according to the updates, i.e., for each addition or deletion \(U_n\) should also be updated. To solve this problem, in our \(\mathsf {VDS}_2\) scheme we make \(U_n\) part of the digest together with C, and each node is responsible to verifiably update \(U_n\). Technically, \(U_n\) is an RSA accumulator to the vector positions, and thus it can be updated by using techniques similar to our first scheme.
Notes
- 1.
We use the notation \(O_\lambda (\cdot )\) to include the factor depending on the security parameter \(\lambda \). Writing “\(O_\lambda (t)\)” essentially means “O(t) cryptographic operations”.
- 2.
filecoin.io, storj.io, datproject.org, freenetproject.org, ethereum.org.
- 3.
We point out that in systems like Filecoin some nodes do not effectively outsource anything. Yet they participate (for economic rewards) verifying that others are actually storing for some third party node.
- 4.
Since in a decentralized system a storage node may also be a client, an attacker could “delegate storage to itself” and use the client’s secret key to cheat in the proof in order to steal rewards (akin to the so-called “generation attack” in Filecoin [Lab17]).
- 5.
- 6.
- 7.
Note that for \(B=1\) the disaggregation step can be skipped.
- 8.
As pointed out in [BBF18], although for the interactive version of such protocols the prime can be of size \(\lambda \), the non-interactive version requires at least a double-sized prime \(2 \lambda \), as an explicit square root attack was presented.
- 9.
We refer to [BBF19] to see how these schemes compare with Merkle trees.
- 10.
We did not include BBF with precomputation in our experimental evaluation because this scheme has worse performances than our preprocessing construction in terms of both required storage and running time. We elaborate on this in the full version.
- 11.
Amortized opening time roughly represents how computationally expensive a scheme is “in total” throughout all its operations. Amortized opening time for m openings is the cost of one commitment plus the cost of m openings, all averaged over the m openings.
- 12.
One can also see this update hint as a certificate to check that a new digest is consistent with some changes. This issue does not arise in our context at all but the \(\mathsf {Bootstrap}\) algorithms are deterministic.
References
Ateniese, R.C., et al.: Provable data possession at untrusted stores. In: Ning, P., De Capitani di Vimercati, S., Syverson, P.F. (eds.) ACM CCS 2007, pp. 598–609. ACM Press, October 2007
Boneh, D., Bünz, B., Fisch, B.: A Survey of Two Verifiable Delay Functions. Cryptology ePrint Archive, Report 2018/712 (2018). https://eprint.iacr.org/2018/712
Boneh, D., Bünz, B., Fisch, B.: Batching techniques for accumulators with applications to IOPs and stateless blockchains. In: Boldyreva, A., Micciancio, D. (eds.) CRYPTO 2019. LNCS, vol. 11692, pp. 561–586. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-26948-7_20
Benaloh, J., de Mare, M.: One-way accumulators: a decentralized alternative to digital signatures (Extended Abstract). In: Helleseth, T. (ed.) EUROCRYPT 1993. LNCS, vol. 765, pp. 274–285. Springer, Heidelberg (1994). https://doi.org/10.1007/3-540-48285-7_24
Brogle, K., Goldberg, S., Reyzin, L.: Sequential aggregate signatures with lazy verification from trapdoor permutations (Extended Abstract). In: Wang, X., Sako, K. (eds.) ASIACRYPT 2012. LNCS, vol. 7658, pp. 644–662. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-34961-4_39
Buchmann, J., Hamdy, S.: A Survey on IQ Cryptography (2001)
Barić, N., Pfitzmann, B.: Collision-free accumulators and fail-stop signature schemes without trees. In: Fumy, W. (ed.) EUROCRYPT 1997. LNCS, vol. 1233, pp. 480–494. Springer, Heidelberg (1997). https://doi.org/10.1007/3-540-69053-0_33
Catalano, D., Fiore, D.: Vector commitments and their applications. In: Kurosawa, K., Hanaoka, G. (eds.) PKC 2013. LNCS, vol. 7778, pp. 55–72. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-36362-7_5
Camenisch, J., Lysyanskaya, A.: Dynamic accumulators and application to efficient revocation of anonymous credentials. In: Yung, M. (ed.) CRYPTO 2002. LNCS, vol. 2442, pp. 61–76. Springer, Heidelberg (2002). https://doi.org/10.1007/3-540-45708-9_5
Cachin, C., Micali, S., Stadler, M.: Computationally private information retrieval with polylogarithmic communication. In: Stern, J. (ed.) EUROCRYPT 1999. LNCS, vol. 1592, pp. 402–414. Springer, Heidelberg (1999). https://doi.org/10.1007/3-540-48910-X_28
Cramer, R., Shoup, V.: Signature schemes based on the strong RSA assumption. In: Motiwalla, J., Tsudik, G. (eds.) ACM CCS 1999, pp. 46–51. ACM Press, November 1999
Clarke, I., Sandberg, O., Wiley, B., Hong, T.W.: Freenet: a distributed anonymous information storage and retrieval system. In: Federrath, H. (ed.) Designing Privacy Enhancing Technologies. LNCS, vol. 2009, pp. 46–66. Springer, Heidelberg (2001). https://doi.org/10.1007/3-540-44702-4_4
Dobson, S., Galbraith, S.D.: Trustless Groups of Unknown Order with Hyperelliptic Curves. Cryptology ePrint Archive, Report 2020/196 (2020). https://eprint.iacr.org/2020/196
Damgård, I., Koprowski, M.: Generic lower bounds for root extraction and signature schemes in general groups. In: Knudsen, L.R. (ed.) EUROCRYPT 2002. LNCS, vol. 2332, pp. 256–271. Springer, Heidelberg (2002). https://doi.org/10.1007/3-540-46035-7_17
Fisch, B.: PoReps: Proofs of Space on Useful Data. Cryptology ePrint Archive, Report 2018/678 (2018). https://eprint.iacr.org/2018/678
Gennaro, R., Halevi, S., Rabin, T.: Secure hash-and-sign signatures without the random oracle. In: Stern, J. (ed.) EUROCRYPT 1999. LNCS, vol. 1592, pp. 123–139. Springer, Heidelberg (1999). https://doi.org/10.1007/3-540-48910-X_9
Groth, J., Kohlweiss, M., Maller, M., Meiklejohn, S., Miers, I.: Updatable and universal common reference strings with applications to zk-SNARKs. In: Shacham, H., Boldyreva, A. (eds.) CRYPTO 2018. LNCS, vol. 10993, pp. 698–728. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-96878-0_24
Gorbunov, S., Reyzin, L., Wee, H., Zhang, Z.: Pointproofs: Aggregating Proofs for Multiple Vector Commitments. Cryptology ePrint Archive, Report 2020/419 (2020). https://eprint.iacr.org/2020/419
Juels, A., Kaliski Jr, B.S.: PORs: proofs of retrievability for large files. In: Ning, P., De Capitani di Vimercati, S., Syverson, P.F. (eds.) ACM CCS 2007, pp. 584–597. ACM Press, October 2007
Kate, A., Zaverucha, G.M., Goldberg, I.: Constant-size commitments to polynomials and their applications. In: Abe, M. (ed.) ASIACRYPT 2010. LNCS, vol. 6477, pp. 177–194. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-17373-8_11
Labs, P.: Filecoin: A Decentralized Storage Network (2017). https://filecoin.io/filecoin.pdf
Lipmaa, H.: Secure accumulators from Euclidean rings without trusted setup. In: Bao, F., Samarati, P., Zhou, J. (eds.) ACNS 2012. LNCS, vol. 7341, pp. 224–240. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-31284-7_14
Lai, R.W.F., Malavolta, G.: Subvector commitments with application to succinct arguments. In: Boldyreva, A., Micciancio, D. (eds.) CRYPTO 2019. LNCS, vol. 11692, pp. 530–560. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-26948-7_19
Lysyanskaya, A., Micali, S., Reyzin, L., Shacham, H.: Sequential aggregate signatures from trapdoor permutations. In: Cachin, C., Camenisch, J.L. (eds.) EUROCRYPT 2004. LNCS, vol. 3027, pp. 74–90. Springer, Heidelberg (2004). https://doi.org/10.1007/978-3-540-24676-3_5
Libert, B., Ramanna, S.C., Yung, M.: Functional commitment schemes: from polynomial commitments to pairing-based accumulators from simple assumptions. In: Chatzigiannakis, I., Mitzenmacher, M., Rabani, Y., Sangiorgi, D. (eds.) ICALP 2016, LIPIcs, vol. 55, pp. 30:1–30:14. Schloss Dagstuhl, July 2016
Libert, B., Yung, M.: Concise mercurial vector commitments and independent zero-knowledge sets with short proofs. In: Micciancio, D. (ed.) TCC 2010. LNCS, vol. 5978, pp. 499–517. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-11799-2_30
Merkle, R.C.: A digital signature based on a conventional encryption function. In: Pomerance, C. (ed.) CRYPTO 1987. LNCS, vol. 293, pp. 369–378. Springer, Heidelberg (1988). https://doi.org/10.1007/3-540-48184-2_32
Ozdemir, A., Wahby, R.S., Boneh, D.: Scaling Verifiable Computation Using Efficient Set Accumulators. Cryptology ePrint Archive, Report 2019/1494 (2019). https://eprint.iacr.org/2019/1494
Shamir, A.: On the generation of cryptographically strong pseudorandom sequences. ACM Trans. Comput. Syst. 1(1), 38–44 (1983)
Tomescu, A., Abraham, I., Buterin, V., Drake, J., Feist, D., Khovratovich, D.: Aggregatable Subvector Commitments for Stateless Cryptocurrencies. Cryptology ePrint Archive, Report 2020/527 (2020). https://eprint.iacr.org/2020/527
Tamassia, R.: Authenticated data structures. In: Di Battista, G., Zwick, U. (eds.) ESA 2003. LNCS, vol. 2832, pp. 2–5. Springer, Heidelberg (2003). https://doi.org/10.1007/978-3-540-39658-1_2
Wesolowski, B.: Efficient verifiable delay functions. Cryptology ePrint Archive, Report 2018/623 (2018). https://eprint.iacr.org/2018/623
Acknowledgements
We thank Ben Fisch for valuable clarifications about the notions of Proof of Retrievable Commitment and Proof of Replication, and Justin Drake for pointing out the need (due to the attack discussed in [BBF18]) of using a hash function mapping into \(\mathsf {Primes}(2 \lambda )\) in the Fiat-Shamir transformation when making our succinct arguments of knowledge non-interactive.
Research leading to these results has been partially supported by the Spanish Government under projects SCUM (ref. RTI2018-102043-B-I00), CRYPTOEPIC (refs. ERC2018-092822, EUR2019-103816), and SECURITAS (ref. RED2018-102321-T), by the Madrid Regional Government under project BLOQUES (ref. S2018/TCS-4339), and by research gifts from Protocol Labs.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 International Association for Cryptologic Research
About this paper

Cite this paper
Campanelli, M., Fiore, D., Greco, N., Kolonelos, D., Nizzardo, L. (2020). Incrementally Aggregatable Vector Commitments and Applications to Verifiable Decentralized Storage. In: Moriai, S., Wang, H. (eds) Advances in Cryptology – ASIACRYPT 2020. ASIACRYPT 2020. Lecture Notes in Computer Science(), vol 12492. Springer, Cham. https://doi.org/10.1007/978-3-030-64834-3_1
Download citation
DOI: https://doi.org/10.1007/978-3-030-64834-3_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-64833-6
Online ISBN: 978-3-030-64834-3
eBook Packages: Computer ScienceComputer Science (R0)
