
Abstract
In this paper, we prove that the nonce-based enhanced hash-then-mask MAC (\(\mathsf {nEHtM}\)) is secure up to \(2^{\frac{3n}{4}}\) MAC queries and \(2^n\) verification queries (ignoring logarithmic factors) as long as the number of faulty queries \(\mu \) is below \(2^\frac{3n}{8}\), significantly improving the previous bound by Dutta et al. Even when \(\mu \) goes beyond \(2^{\frac{3n}{8}}\), \(\mathsf {nEHtM}\) enjoys graceful degradation of security.
The second result is to prove the security of PRF-based \(\mathsf {nEHtM}\); when \(\mathsf {nEHtM}\) is based on an n-to-s bit random function for a fixed size s such that \(1\le s\le n\), it is proved to be secure up to any number of MAC queries and \(2^s\) verification queries, if (1) \(s=n\) and \(\mu <2^{\frac{n}{2}}\) or (2) \(\frac{n}{2}<s<2^{n-s}\) and \(\mu <\max \{2^{\frac{s}{2}},2^{n-s}\}\), or (3) \(s\le \frac{n}{2}\) and \(\mu <2^{\frac{n}{2}}\). This result leads to the security proof of truncated \(\mathsf {nEHtM}\) that returns only s bits of the original tag since a truncated permutation can be seen as a pseudorandom function. In particular, when \(s\le \frac{2n}{3}\), the truncated \(\mathsf {nEHtM}\) is secure up to \(2^{n-\frac{s}{2}}\) MAC queries and \(2^s\) verification queries as long as \(\mu <\min \{2^{\frac{n}{2}},2^{n-s}\}\). For example, when \(s=\frac{n}{2}\) (resp. \(s=\frac{n}{4}\)), the truncated \(\mathsf {nEHtM}\) is secure up to \(2^{\frac{3n}{4}}\) (resp. \(2^{\frac{7n}{8}}\)) MAC queries. So truncation might provide better provable security than the original \(\mathsf {nEHtM}\) with respect to the number of MAC queries.
Jooyoung Lee was supported by a National Research Foundation of Korea (NRF) grant funded by the Korean government (Ministry of Science and ICT), No. NRF-2017R1E1A1A03070248.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
- Message authentication codes
- Beyond-birthday-bound security
- Mirror theory
- Graceful degradation
- Truncation
1 Introduction
MACs. A message authentication code (MAC) is typically built from a block cipher, e.g., \(\mathsf {CBC}\)-\(\mathsf {MAC}\) [4], \(\mathsf {PMAC}\) [6], \(\mathsf {OMAC}\) [16], or from a cryptographic hash function, e.g., \(\mathsf {HMAC}\) [2]. At a high level, many of these constructions follow the well-established UHF-then-PRF design paradigm: a message is first mapped onto a short string through a universal hash function (UHF), and then encrypted through a fixed-input-length PRF to obtain a short tag. This method is simple, in particular, being deterministic and stateless, yet its security caps at the so-called birthday bound; any collision at the output of the UHF, which translates into a tag collision, is usually enough to break the security of the scheme. However, the birthday bound security might not be enough, in particular, when the MAC construction is instantiated with a lightweight block cipher such as \(\mathsf {PRESENT}\) [7], \(\mathsf {LED}\) [14] and \(\mathsf {GIFT}\) [1] operating on small blocks. Better security bounds can be obtained by incorporating in the tag computation a nonce (a value that never repeats), e.g. in Wegman-Carter type MACs [5, 9, 29, 31] or a random value [3, 11, 17, 18, 24]. The focus of this paper is put on nonce-based MACs.
Nonce-Misuse Resistant MACs. The Wegman-Carter MAC (based on a pseudorandom function) guarantees a strong security bound when nonces are never reused. However, only a single nonce repetition can completely break its security [20]. The problem is that it might be challenging to maintain the uniqueness of the nonce in certain environments, for example, when a nonce is chosen randomly from a small set, or when the state of the MAC is reset due to some fault in its implementation. For this reason, there has been a considerable amount of research on the construction of (nonce-based) MACs that provide security under nonce misuse [9, 10, 12, 23, 26].
In this line of research, Cogliati and Seurin [9] proposed \(\mathsf {EWCDM}\), and then Datta et al. [10] made a slight modification to it, dubbed \(\mathsf {DWCDM}\), in order to reduce the number of block cipher keys. Both constructions provide beyond-birthday-bound security in a nonce respecting settings, and secure up to the birthday bound even in a nonce misuse setting. Mennink and Neves [23] also proved the PRF-security of \(\mathsf {EWCDM}\) up to \(2^n/(67n)\) queries in a nonce respecting setting (without considering verification queries). However, their security degrades to the birthday bound as soon as only a single nonce is misused.
Recently, Dutta et al. [12] proposed a new construction of MACs, which is called nonce-based Enhanced Hash-then-Mask (\(\mathsf {nEHtM}\)). They proved that \(\mathsf {nEHtM}\) is secure up to \(2^\frac{2n}{3}\) MAC queries and \(2^n\) verification queries in a nonce respecting setting. Moreover, \(\mathsf {nEHtM}\) enjoys graceful degradation of security in a nonce misuse setting. More precisely, with respect to the number of faulty nonces \(\mu \), their bound on the forging advantage includes \(\mu q/2^n\) and \(\mu v/2^n\) terms, where q and v denote the number of MAC queries and the number of verification queries, respectively. So the threshold number of MAC queries and verification queries linearly decreases as the number of faulty queries increases in a logarithmic scale.
Our Results. In this paper, we revisit the \(\mathsf {nEHtM}\) construction; when \(\mathsf {nEHtM}\) is based on a universal hash function H and a block cipher E, the tag for an \((n-1)\)-bit nonce N and a message M is defined as
using a hash key \(K_h\) and a block cipher key K (see Fig. 1).

\(\mathsf {nEHtM}\) based on a universal hash function H and a block cipher E.
We prove that \(\mathsf {nEHtM}\) is secure up to \(2^{\frac{3n}{4}}\) MAC queries and \(2^n\) verification queries (ignoring logarithmic factors) as long as the number of faulty queries \(\mu \) is below \(2^\frac{3n}{8}\), significantly improving the previous bound by Dutta et al. Even when \(\mu \) goes beyond \(2^{\frac{3n}{8}}\), \(\mathsf {nEHtM}\) enjoys graceful degradation of security. It is known that there is a forging attack on \(\mathsf {nEHtM}\) using \(2^\frac{n}{2}\) faulty queries [12], which means that \(\mu \) cannot go beyond \(2^\frac{n}{2}\). Figure 2 compares our new bound to the previous one given in [12].
The second result is to prove the security of PRF-based \(\mathsf {nEHtM}\). When the structure of \(\mathsf {nEHtM}\) was first proposed in [24], it was based on independent pseudorandom functions using random IVs instead of nonces. Its security has been proved up to \(2^{\frac{2n}{3}}\) MAC queries, and later Dutta et al. [11] tightly proved its 3n/4-bit security with a matching attack. In this work, we study its security in a nonce respecting/misuse setting. More precisely, when \(\mathsf {nEHtM}\) is based on a single n-to-s bit random function (with domain separation) for a fixed size s such that \(1\le s\le n\), it is proved to be secure up to any number of MAC queries and \(2^s\) verification queries, if (1) \(s=n\) and \(\mu <2^{\frac{n}{2}}\) or (2) \(\frac{n}{2}<s<2^{n-s}\) and \(\mu <\max \{2^{\frac{s}{2}},2^{n-s}\}\), or (3) \(s\le \frac{n}{2}\) and \(\mu <2^{\frac{n}{2}}\). This result leads to the security proof of truncated \(\mathsf {nEHtM}\) that returns only s bits of the original tag since a truncated permutation can be seen as a pseudorandom function. In particular, when \(s\le \frac{2n}{3}\), the truncated \(\mathsf {nEHtM}\) is secure up to \(2^{n-\frac{s}{2}}\) MAC queries and \(2^s\) verification queries as long as \(\mu <\min \{2^{\frac{n}{2}},2^{n-s}\}\). For example, when \(s=\frac{n}{2}\) (resp. \(s=\frac{n}{4}\)), the truncated \(\mathsf {nEHtM}\) is secure up to \(2^{\frac{3n}{4}}\) (resp. \(2^{\frac{7n}{8}}\)) MAC queries. So truncation might provide better provable security than the original \(\mathsf {nEHtM}\) with respect to the number of MAC queries.
Proof Technique. The main tool of our security proof is Mirror theory [27, 28] that systematically estimates the number of solutions to a system of equations. However, we cannot directly apply Mirror theory to our problem in a black box manner; the original theory requires that \(\xi ^2_{max}q\le 2^n\), where \(\xi _{max}\) and q denote the maximum component size and the number of edges, respectively, when a system of equations is represented by a graph. Unfortunately, this restriction does not hold in our graph, possibly containing large components. Furthermore, our system includes non-equations corresponding to verification queries. For this reason, we need to refine and generalize Mirror theory. More precisely, we decompose our graph into four subgraphs - the union of the components containing at least one trail of length three, the union of “stars”, the set of isolated edges, and the set of isolated vertices. For a subgraph whose components are small, we sharply estimate the number of solutions to the subgraph, while we probabilistically upper bound the number of larger components.
Recently, deterministic double-block hash-then-sum MACs have been proved to be tightly secure up \(\frac{3n}{4}\) queries [21, 22], while the security proof of nonce-based constructions turn out to be even more challenging since (faulty) nonces can be adaptively chosen by an adversary.
Comparison. Table 1 compares \(\mathsf {nEHtM}\) with existing beyond-birthday-bound MACs based on a block cipher E and a \(\delta \)-AXU-hash function H. “Nonce” indicates that whether it is nonce-based MAC or not. “# Keys” gives the total number of hash and block cipher keys. The number of queries and the maximum message length (in block) are denoted q and \(\ell \), respectively. Security is evaluated by assuming \(\delta \approx \frac{\ell }{2^n}\) and \(v = 0\). We always have the trivial bound \(\mu <q\). We see that \(\mathsf {nEHtM}\) is the first (nonce-based) MAC construction based on a block cipher that provides \(\frac{3n}{4}\)-bit provable security.

Comparison of the security bounds (in terms of the threshold number of MAC queries and verification queries) as functions of \(\mu \). The solid lines (resp. dashed lines) represent our bounds (resp. the previous bounds in [12]). In (b), we used parameter L satisfying \(\mu ^{2L}=L^L\cdot 2^{(L-1)n}\) for each \(\mu \) (see Theorem 2).
2 Preliminaries
Notation. In all of the following, we fix a positive integer n such that \(n\ge 3\). We denote \(0^n\) (i.e., n-bit string of all zeros) by \(\mathbf {0}\). The set \(\{0,1\}^n\) is sometimes regarded as a set of integers \(\{0,1,\ldots ,2^n-1\}\) by converting an n-bit string \(a_{n-1}\cdots a_1a_0\in \{0,1\}^n\) to an integer \(a_{n-1}2^{n-1}+\cdots + a_12+a_0\). We also identify \(\{0,1\}^n\) with a finite field \(\mathbf {GF}(2^n)\) with \(2^n\) elements. For a positive integer q, we write \([q]=\{1,\ldots ,q\}\).
Given a non-empty set \(\mathcal {X}\), \(x\mathrel {\leftarrow _{\$}}\mathcal {X}\) denotes that x is chosen uniformly at random from \(\mathcal {X}\). The set of all functions from \(\mathcal {X}\) to \(\mathcal {Y}\) is denoted \(\mathsf {Func}(\mathcal {X},\mathcal {Y})\), and the set of all permutations of \(\mathcal {X}\) is denoted \(\mathsf {Perm}(\mathcal {X})\). The set of all permutations of \(\{0,1\}^n\) is simply denoted \(\mathsf {Perm}(n)\). The set of all sequences that consist of b pairwise distinct elements of \(\mathcal {X}\) is denoted \(\mathcal {X}^{*b}\). For integers \(1\le b\le a\), we will write \((a)_b=a(a-1)\cdots (a-b+1)\) and \((a)_0=1\) by convention. If \(|\mathcal {X}|=a\), then \((a)_b\) becomes the size of \(\mathcal {X}^{*b}\).
When two sets \(\mathcal {X}\) and \(\mathcal {Y}\) are disjoint, their (disjoint) union is denoted \(\mathcal {X}\sqcup \mathcal {Y}\). For a set \(\mathcal {X}\subset \{0,1\}^n\) and \(\lambda \in \{0,1\}^n\), we will write \(\mathcal {X}\mathbin {\oplus }\lambda =\{x\mathbin {\oplus }\lambda : x\in \mathcal {X}\}\). For a graph \(\mathcal {G}=(\mathcal {V},\mathcal {E})\), we will interchangeably write \(\left| {\mathcal {V}} \right| \) and \(\left| {\mathcal {G}} \right| \) for the number of vertices of \(\mathcal {G}\).
Almost Xor Universal Hash Functions. Let \(\delta >0\), and let \(H:\mathcal {K}_h\times \mathcal {M}\rightarrow \mathcal {X}\) be a keyed function for three non-empty sets \(\mathcal {K}_h\), \(\mathcal {M}\), and \(\mathcal {X}\). H is said to be \(\delta \)-almost XOR universal (AXU) if for any distinct \(M, M'\in \mathcal {M}\) and \(X \in \mathcal {X}\),
For a positive integer q, fix \(M_1,\ldots ,M_q\in \mathcal {M}\). For a random key \(K_h\in \mathcal {K}_h\), let \(X_i = H_{K_h}(M_i)\) for \(i=1,\dots , q\). Then we can define an equivalence relation \(\sim \) on [q]: for \(\alpha \), \(\beta \in [q]\), \(\alpha \sim \beta \) if and only if \(X_\alpha =X_\beta \). For some nonnegative integer r, let \(\mathcal {P}_1,\dots ,\mathcal {P}_r\) denote the equivalence classes of [q] with respect to \(\sim \) such that \(p_i\mathrel {\mathop =^\mathrm{def}}\left| {\mathcal {P}_i} \right| \ge 2\) for \(i=1,\ldots ,r\). Jha and Nandi [19] proved the following lemma, which is also useful in our security proof.
Lemma 1
Let \(p_i\), \(i=1\ldots , r\), be the random variables as defined above. Then we have
where the expectation is taken over the uniform distribution of \(K_h\in \mathcal {K}_h\).
Proof
Let c denote the random variable that counts the number of “X-colliding” pairs. More precisely,
Then it is easy to show that
Furthermore, we have \(\mathsf {Ex}[c] \le {q\atopwithdelims ()2} \delta \), which completes the proof. \(\square \)
PRFs and PRPs. Let \(F:\mathcal {K}\times \mathcal {X}\rightarrow \mathcal {Y}\) be a keyed function with key space \(\mathcal {K}\), domain \(\mathcal {X}\), and range \(\mathcal {Y}\), where \(\mathcal {X}\) is a subset of \(\{0,1\}^*\). We will denote \(F_K(X)\) for F(K, X). A (q, t, l)-distinguisher against F is an algorithm \(\mathcal {A}\) with oracle access to a function from \(\mathcal {X}\) to \(\mathcal {Y}\), making at most q oracle queries, each of length at most l in blocks, running in time at most t, and outputting a single bit. The advantage of \(\mathcal {A}\) in breaking the PRF-security of F, i.e., in distinguishing F from a uniformly randomly chosen function \(R\mathrel {\leftarrow _{\$}}\mathsf {Func}(\mathcal {X},\mathcal {Y})\), is defined as
When \(\mathcal {X}=\mathcal {Y}\) and \(F(K,\cdot )\) is a permutation for each \(K\in \mathcal {K}\), the PRP-security of F is defined as
For \(\mathsf {atk}\in \{\mathsf {prf},\mathsf {prp}\}\), we define \(\mathsf {Adv}^{\mathsf {atk}}_F(q,t,l)\) as the maximum of \(\mathsf {Adv}^{\mathsf {atk}}_F(\mathcal {A})\) over all (q, t, l)-distinguishers against F. We will consider PRP-security only for a block cipher whose input size is fixed (e.g., \(\mathcal {X}=\{0,1\}^n\)); in this case, we will simply drop the parameter l. On the other hand, when we consider information theoretic security, we will drop the parameter t.
Nonce-based MACs. Given four non-empty sets \(\mathcal {K}\), \(\mathcal {N}\), \(\mathcal {M}\), and \(\mathcal {T}\), a nonce-based keyed function with key space \(\mathcal {K}\), nonce space \(\mathcal {N}\), message space \(\mathcal {M}\) and tag space \(\mathcal {T}\) is simply a function \(F:\mathcal {K}\times \mathcal {N}\times \mathcal {M}\rightarrow \mathcal {T}\). Stated otherwise, it is a keyed function whose domain is a cartesian product \(\mathcal {N}\times \mathcal {M}\). We denote \(F_K(N,M)\) for F(K, N, M).
For \(K\in \mathcal {K}\), let \(\mathsf {Auth}_K\) be the MAC oracle which takes as input a pair \((N,M)\in \mathcal {N}\times \mathcal {M}\) and returns \(F_K(N,M)\), and let \(\mathsf {Ver}_K\) be the verification oracle which takes as input a triple \((N,M,T)\in \mathcal {N}\times \mathcal {M}\times \mathcal {T}\) and returns 1 (“accept”) if \(F_K(N,M)=T\), and 0 (“reject”) otherwise. We assume that an adversary makes queries to the two oracles \(\mathsf {Auth}_K\) and \(\mathsf {Ver}_K\) for a secret key \(K\in \mathcal {K}\). A MAC query (N, M) made by an adversary is called a faulty query if the adversary has already queried to the MAC oracle with the same nonce but with a different message.
A \((\mu ,q,v,t)\)-adversary against the nonce-based MAC-security of F is an adversary \(\mathcal {A}\) with oracle access to \(\mathsf {Auth}_K\) and \(\mathsf {Ver}_K\), making at most q MAC queries to its first oracle with at most \(\mu \) faulty queries and at most v verification queries to its second oracle, and running in time at most t. We say that \(\mathcal {A}\) forges if any of its queries to \(\mathsf {Ver}_K\) returns 1. The advantage of \(\mathcal {A}\) against the nonce-based MAC-security of F is defined as
where the probability is also taken over the random coins of \(\mathcal {A}\), if any. The adversary is not allowed to ask a verification query (N, M, T) if a previous query (N, M) to \(\mathsf {Auth}_K\) returned T. When \(\mu =0\), we say that \(\mathcal {A}\) is nonce-respecting, otherwise \(\mathcal {A}\) is said nonce-misusing. However, the adversary is allowed to repeat nonces in its verification queries.
We define \(\mathsf {Adv}^{\mathsf {mac}}_F(\mu , q, v, t)\) as the maximum of \(\mathsf {Adv}^{\mathsf {mac}}_F(\mathcal {A})\) over all \((\mu , q, v, t)\)-adversaries. When we consider information theoretic security, we will drop the parameter t.
Nonce-based Enhanced Hash-then-Mask MACs. Let
be a keyed function. Given a block cipher
one can define the \(\mathsf {nEHtM}\) MAC with key space \(\mathcal {K}_h\times \mathcal {K}\), nonce space \(\{0,1\}^{n-1}\), message space \(\mathcal {M}\) and tag space \(\{0,1\}^n\): for a key \((K_h, K)\in \mathcal {K}_h\times \mathcal {K}\), a nonce \(N\in \{0,1\}^{n-1}\), a message \(M\in \mathcal {M}\), the tag is computed as follows:
More generally, the underlying block cipher can be replaced by a compression function \(E: \mathcal {K}\times \{0,1\}^n \longrightarrow \{0,1\}^m\) for some \(m<n\).
Expectation Method. Consider the \(\mathsf {nEHtM}\) construction based on H and E using keys \((K_h,K)\). Suppose that a distinguisher \(\mathcal {A}\) adaptively makes q MAC queries and v verification queries to either \((\mathsf {Auth}_{K_h,K},\mathsf {Ver}_{K_h,K})\) for a random secret key \((K_h,K)\in \mathcal {K}_h\times \mathcal {K}\) (in the real world) or \((\mathsf {Rand},\mathsf {Rej})\) (in the ideal world), where \(\mathsf {Rand}\) returns an independent random value (instantiating a truly random function) and \(\mathsf {Rej}\) always return 0 for every verification query. Furthermore, \(\mathcal {A}\) records all the queries in
where either \(\mathsf {Auth}_{K_h,K}(N_i,M_i)=T_i\) or \(\mathsf {Rand}(N_i,M_i)=T_i\) for \(i=1,\ldots ,q\), and either \(\mathsf {Ver}_{K_h,K}(N'_i,M'_i,T'_i)=b'_i\) or \(\mathsf {Rej}(N'_i,M'_i,T'_i)=b'_i(=0)\) for \(i=1,\ldots ,v\), according to the world that \(\mathcal {A}\) interacts with.
At the end of the interaction, we will provide the distinguisher \(\mathcal {A}\) with the hash key \(K_h\) for free. In the ideal world, a dummy key \(K_h\) will be selected uniformly at random from \(\mathcal {K}_h\), and given to \(\mathcal {A}\). This will not degrade the adversarial distinguishing advantage since the distinguisher is free to ignore this additional information.
We will call
the transcript of the attack; it contains all the information that \(\mathcal {A}\) has obtained at the end of the attack. When we consider an information theoretic distinguisher, we can assume that the distinguisher is deterministic without making any redundant query.
A transcript \(\tau \) is called attainable if the probability to obtain this transcript in the ideal world is non-zero. Note that any key \(K_h\in \mathcal {K}_h\) and any sequence of tags \((T_1,\ldots ,T_q)\in (\{0,1\}^n)^q\) uniquely determine an attainable transcript containing them, and each attainable transcript appears in the ideal world with the same probability, namely \(1/N^q\). We denote \(\varGamma \) the set of attainable transcripts. We also denote \(\mathsf {T}_{\mathsf {re}}\) (resp. \(\mathsf {T}_{\mathsf {id}}\)) the probability distribution of the transcript \(\tau \) induced by the real world (resp. the ideal world). By extension, we use the same notation to denote a random variable distributed according to each distribution.
In this setting, it is obvious that \(\mathcal {A}\)’s distinguishing advantage upper bounds \(\mathcal {A}\)’s forging probability and when \(v=0\), we can derive PRF-security of the of \(\mathsf {nEHtM}\). In order to upper bound the distinguishing advantage, we will use Patarin’s coefficient-H technique; we partition the set of attainable transcripts \(\varGamma \) into a set of “good” transcripts \(\varGamma _{\mathsf {good}}\) such that the probabilities to obtain some transcript \(\tau \in \varGamma _{\mathsf {good}}\) are close in the real world and the ideal world, and a set \(\varGamma _{\mathsf {bad}}\) of “bad” transcripts such that the probability to obtain any \(\tau \in \varGamma _{\mathsf {bad}}\) is small in the ideal world. The lower bound in the ratio of the probabilities to obtain a good transcript in both worlds will be given as a function of \(\tau \), and we will take its expectation. This refinement is called the expectation method, first introduced in [15], summarized in the following theorem.
Lemma 2
Fix a forging adversary \(\mathcal {A}\). Let \(\varGamma =\varGamma _{\mathsf {good}}\sqcup \varGamma _{\mathsf {bad}}\) be a partition of the set of attainable transcripts, where there exists a non-negative function \(\varepsilon _1(\tau )\) such that for any \(\tau \in \varGamma _{\mathsf {good}}\),
and there exists \(\varepsilon _2\) such that \(\Pr [ \mathsf {T}_\mathrm{id} \in \varGamma _{\mathsf {bad}}]\le \varepsilon _2\). Then one has
where the expectation is taken over the distribution \(\mathsf {T}_{\mathsf {id}}\) in the ideal world.
Proof
Since the distinguisher’s output is a (deterministic) function of the transcript, its distinguishing advantage is upper bounded by the statistical distance between \( \mathsf {T}_\mathrm{id} \) and \( \mathsf {T}_\mathrm{re} \). So we have
Moreover we have:
\(\square \)
3 Extended Mirror Theory
The goal of this section is to lower bound the number of solutions to a certain type of system of equations and non-equations. For simplicity of notation, we will denote \(N=2^n\) throughout this section.
We will represent a system of equations and non-equations by a graph. Each vertex corresponds to an n-bit distinct unknowns. We will assume that the number of vertices is at most N/4, and by abuse of notation, identify the vertices with the values assigned to them. We distinguish two types of edges, namely, \(=\)-labeled edges and \(\ne \)-labeled edges that correspond to equations and non-equations, respectively. Each of the edge is additionally labeled by an element in \(\{0,1\}^n\). So, if two vertices P and Q are adjacent by an edge with label \((\lambda ,=)\) (resp. \((\lambda ,\ne )\)) for some \(\lambda \in \{0,1\}^n\), then it would mean that \(P \mathbin {\oplus } Q = \lambda \) (resp. \(P \mathbin {\oplus } Q \ne \lambda \)).
Consider a graph \(\mathcal {G}= (\mathcal {V}, \mathcal {E}^= \sqcup \mathcal {E}^{\ne })\), where \(\mathcal {E}^=\) and \(\mathcal {E}^{\ne }\) denote the set of \(=\)-labeled edges and the set of \(\ne \)-labeled edges, respectively. Then \(\mathcal {G}\) can be seen as a superposition of two subgraphs \(\mathcal {G}^=\mathrel {\mathop =^\mathrm{def}}(\mathcal {V}, \mathcal {E}^=)\) and \(\mathcal {G}^{\ne } \mathrel {\mathop =^\mathrm{def}}(\mathcal {V}, \mathcal {E}^{\ne })\). Let \(P\overset{\lambda }{-}Q\) denote a \((\lambda , =)\)-labeled edge in \(\mathcal {G}^=\). For \(\ell >0\) and a trailFootnote 1
in \(\mathcal {G}^=\), its label is defined as
In this work, we will focus on a graph \(\mathcal {G}=(\mathcal {V}, \mathcal {E}^= \sqcup \mathcal {E}^{\ne })\) with certain properties, as listed below.
-
1.
\(\mathcal {G}^=\) contains no cycle.
-
2.
\(\lambda (\mathcal {L}) \ne \mathbf {0}\) for any trail \(\mathcal {L}\) in \(\mathcal {G}^=\).
-
3.
If P and Q are connected with a \((\lambda , \ne )\)-labeled edge, then they are not connected by a \(\lambda \)-labeled trail in \(\mathcal {G}^=\).
Any graph \(\mathcal {G}\) satisfying the above properties will be called a nice graph. Given a nice graph \(\mathcal {G}=(\mathcal {V}, \mathcal {E}^= \sqcup \mathcal {E}^{\ne })\), an assignment of distinct values to the vertices in \(\mathcal {V}\) satisfying all the equations in \(\mathcal {E}^=\) and all the non-equations in \(\mathcal {E}^{\ne }\) is called a solution to \(\mathcal {G}\). We remark that if we assign any value to a vertex P, then \(=\)-labeled edges determine the values of all the other vertices in the component containing P in \(\mathcal {G}^=\), where the assignment is unique since \(\mathcal {G}^=\) contains no cycle, and the values in the same component are all distinct since \(\lambda (\mathcal {L})\ne \mathbf {0}\) for any trail \(\mathcal {L}\). Furthermore, any non-equation between two vertices in the same component will be redundant due to the third property above.
The number of possible assignments of distinct values to the vertices in \(\mathcal {V}\) is \((N)_{|\mathcal {V}|}\). One might expect that when such an assignment is chosen uniformly at random, it would satisfy all the equations and non-equations in \(\mathcal {G}\) with probability close to \(1/N^q\), where q denotes the number of \(=\)-labeled edges (i.e., equations) in \(\mathcal {G}^=\). Indeed, we can prove that the number of solutions to \(\mathcal {G}\) is close to \(\frac{(N)_{|\mathcal {V}|}}{N^q}\) up to a certain error (that can be negligible according to the parameters). We begin with a simple bound that holds for any type of graphs.
In the following lemma, we partition the set of vertices \(\mathcal {V}\) into two disjoint sets, denoted \(\mathcal {V}_{\mathsf {kn}}\) and \(\mathcal {V}_{\mathsf {uk}}\), respectively, and fix an assignment of distinct values to the vertices in \(\mathcal {V}_{\mathsf {kn}}\). Subject to this assignment, the number of possible assignments of distinct values to the vertices in \(\mathcal {V}_{\mathsf {uk}}\) can be lower bounded (in a way that the entire assignment becomes a solution to \(\mathcal {G}\)).
Lemma 3
For a positive integer q and a nonnegative integer v, let \(\mathcal {G}= (\mathcal {V}, \mathcal {E}^= \sqcup \mathcal {E}^{\ne })\) be a nice graph such that \(|\mathcal {E}^=|=q\) and \(|\mathcal {E}^{\ne }|=v\). Suppose that
-
1.
\(\mathcal {V}\) is partitioned into two subsets, denoted \(\mathcal {V}_{\mathsf {kn}}\) and \(\mathcal {V}_{\mathsf {uk}}\);
-
2.
there is no \(=\)-labeled edge that is incident to a vertex in \(\mathcal {V}_{\mathsf {kn}}\);
-
3.
there is no \(\ne \)-labeled edge connecting two vertices in \(\mathcal {V}_{\mathsf {kn}}\).
Suppose that \(\mathcal {G}^=_{\mathsf {uk}} = (\mathcal {V}_{\mathsf {uk}},\mathcal {E}^=)\) is decomposed into k components \(\mathcal {C}_1,\ldots ,\mathcal {C}_k\) for some k. Given a fixed assignment of distinct values to the vertices in \(\mathcal {V}_{\mathsf {kn}}\), the number of solutions to \(\mathcal {G}\), denoted \(h(\mathcal {G})\), satisfies
If every component of the graph contains exactly two vertices, then we can improve the bound as follows.
Lemma 4
For a positive integer q and a nonnegative integer v, let \(\mathcal {G}= (\mathcal {V}, \mathcal {E}^= \sqcup \mathcal {E}^{\ne })\) be a nice graph such that \(|\mathcal {E}^=|=q\) and \(|\mathcal {E}^{\ne }|=v\). Suppose that
-
1.
\(\mathcal {V}\) is partitioned into two subsets, denoted \(\mathcal {V}_{\mathsf {kn}}\) and \(\mathcal {V}_{\mathsf {uk}}\);
-
2.
there is no \(=\)-labeled edge that is incident to a vertex in \(\mathcal {V}_{\mathsf {kn}}\);
-
3.
there is no \(\ne \)-labeled edge connecting two vertices in \(\mathcal {V}_{\mathsf {kn}}\).
Suppose that \(\mathcal {G}^=_{\mathsf {uk}} = (\mathcal {V}_{\mathsf {uk}},\mathcal {E}^=)\) is decomposed into q components of size two. Given a fixed assignment of distinct values to the vertices in \(\mathcal {V}_{\mathsf {kn}}\), the number of solutions to \(\mathcal {G}\), denoted \(h(\mathcal {G})\), satisfies
The proof of Lemma 3 and 4 will be deferred to the full version due to the space limit. Finally, we consider a graph containing no \(=\)-labeled edges. So \(\mathcal {G}^=\) consists only of isolated vertices.
Lemma 5
For a nonnegative integer v, let \(\mathcal {G}= (\mathcal {V},\mathcal {E}^{\ne })\) be a nice graph such that \(|\mathcal {E}^{\ne }|=v\). Suppose that
-
1.
\(\mathcal {V}\) is partitioned into two subsets, denoted \(\mathcal {V}_{\mathsf {kn}}\) and \(\mathcal {V}_{\mathsf {uk}}\);
-
2.
there is no \(\ne \)-labeled edge connecting two vertices in \(\mathcal {V}_{\mathsf {kn}}\).
Given a fixed assignment of distinct values to the vertices in \(\mathcal {V}_{\mathsf {kn}}\), the number of solutions to \(\mathcal {G}\), denoted \(h(\mathcal {G})\), satisfies
Proof
The number of possible assignments of distinct values outside \(\mathcal {V}_{\mathsf {kn}}\) to the vertices in \(\mathcal {V}_{\mathsf {uk}}\) is \((N - \left| {\mathcal {V}_{\mathsf {kn}}} \right| )_{\left| {\mathcal {V}_{\mathsf {uk}}} \right| }\). Among these assignments, at most \((N - \left| {\mathcal {V}_{\mathsf {kn}}} \right| )_{\left| {\mathcal {V}_{\mathsf {uk}}} \right| -1}\) assignments violate any fixed \(\ne \)-labeled edge. Therefore, we have
which means
\(\square \)
Given an arbitrary nice graph \(\mathcal {G}\), we will decompose \(\mathcal {G}^=\) into four subgraphs, denoted \(\mathcal {G}^=_3\), \(\mathcal {G}^=_2\), \(\mathcal {G}^=_1\) and \(\mathcal {G}^=_0\), respectively, where
-
\(\mathcal {G}^=_3=(\mathcal {V}_3,\mathcal {E}^=_3)\) is the union of components containing at least one trail of length three;
-
\(\mathcal {G}^=_2=(\mathcal {V}_2,\mathcal {E}^=_2)\) is the union of components containing at least one trail of length two (i.e., stars), but not a trail of length three;
-
\(\mathcal {G}^=_1=(\mathcal {V}_1,\mathcal {E}^=_1)\) is the union of components of size two (i.e., trails of length one);
-
\(\mathcal {G}^=_0=(\mathcal {V}_0,\mathcal {E}^=_0)\) is the set of isolated vertices.
For \(i=0, 1, 2, 3\), let \(\mathcal {E}^{\ne }_i\) denote the set of \(\ne \)-labeled edges connecting a vertex in \(\mathcal {V}_i\) and one in \(\bigsqcup _{j = i}^3 \mathcal {V}_j\), and let
In order to lower bound the number of solutions to \(\mathcal {G}\), we will first lower bound the number of solutions to \(\mathcal {G}_3\) and \(\mathcal {G}_2\) using Lemma 3, and then \(\mathcal {G}_1\) and \(\mathcal {G}_0\) (\(=\mathcal {G}\)) using Lemma 4 and Lemma 5, respectively. In the following theorem, \(\mathcal {G}_3\) and \(\mathcal {G}_2\) can be any partition of the components containing trails of length two, but the current partition will be used later in our security proof.
Theorem 1
For positive integers q and v, let \(\mathcal {G}= (\mathcal {V}, \mathcal {E}^= \sqcup \mathcal {E}^{\ne })\) be a nice graph such that \(|\mathcal {E}^=|=q\) and \(|\mathcal {E}^{\ne }|=v\). With the notations defined as above, assume that \(\mathcal {G}^=_2\) is decomposed into k components \(\mathcal {C}_1,\ldots ,\mathcal {C}_k\) for some k. Then the number of solutions to \(\mathcal {G}\), denoted \(h^*(\mathcal {G})\), satisfies
provided that \(q \le 2^{n - 3}\).
4 Security of \(\mathsf {nEHtM}\) Based on a Block Cipher
In this section, we consider \(\mathsf {nEHtM}[H,E]\) based on an \((n - 1)\)-bit \(\delta \)-AXU hash function H and an n-bit block cipher E. A message M with an \((n -1)\)-bit nonce N is encrypted as
by a hash key \(K_h\) and a block cipher key K (see Sect. 2).
Up to the PRP-security of E, the keyed permutation \(E_{K}\) can be replaced by a truly random permutation \(\pi \). The goal of this section is to prove the security of \(\mathsf {nEHtM}[H,\pi ]\) using Theorem 1. As a result, we have the following theorem.
Theorem 2
Let \(\delta >0\), and let \(H:\mathcal {K}\times \mathcal {M}\rightarrow \{0,1\}^n\) be a \(\delta \)-almost universal hash function. For positive integers \(\mu \), q, v, and L such that \(q + v \le 2^{n-3}\), we have
where
Note that \(\varepsilon \) contains all the negligible terms, not dominating the entire bound.
Interpretation. Setting \(\delta \le \frac{\ell }{2^n}\) for a constant \(\ell \) and \(L=n\), we have
4.1 Graph Representation of Transcripts
Suppose that an adversary \(\mathcal {A}\) makes q MAC queries using at most \(\mu \) faulty nonces, and makes v verification queries. Throughout the security proof, we will assume that
Let
denote the list of MAC queries and the list of verification queries, respectively. Note that \(\mathcal {A}\) is given \(K_h\) for free at the end of the attack. Then, from the transcript
one can fix \(X_i \mathrel {\mathop =^\mathrm{def}}H_{K_h}(M_i) \mathbin {\oplus } N_i\) for \(i = 1, \ldots , q\), and \(X'_j \mathrel {\mathop =^\mathrm{def}}H_{K_h}(M'_j) \mathbin {\oplus } N'_j\) for \(j = 1, \dots , v\).
The core of the security proof is to estimate the number of possible ways of fixing evaluations of \(\pi \) in a way that \(\pi (0 \mathbin {\Vert }N_i) \mathbin {\oplus } \pi (1 \mathbin {\Vert }X_i) = T_i\) for \(i=1, \dots , q\), and \(\pi (0 \mathbin {\Vert }N'_{j}) \mathbin {\oplus } \pi (1 \mathbin {\Vert }X'_{j}) \ne T'_j\) for \(j = 1, \dots , v\). We will identify \(\left\{ {\pi (0 \mathbin {\Vert }N_i)} \right\} \cup \left\{ {\pi (0 \mathbin {\Vert }N'_j)} \right\} \) with a set of unknowns
where \(q_1 \le q\), since there might be collisions between nonces. Similarly, we identify \(\left\{ {\pi (1 \mathbin {\Vert }X_i)} \right\} \cup \left\{ {\pi (1 \mathbin {\Vert }X'_j)} \right\} \) with a set of unknowns
for some \(q_2 \le q\).
For \(i=1, \dots , q\), let \(\pi (0 \mathbin {\Vert }N_i) = P_j \in \mathcal {P}\) and let \(\pi (1 \mathbin {\Vert }X_i) = Q_k \in \mathcal {Q}\). Then \(P_j\) and \(Q_k\) are connected with a \((T_i, =)\)-labeled edge. Similarly, for \(i = 1, \dots ,v\), \(P_j\) and \(Q_k\) are connected with a \((T'_i, \ne )\)-labeled edge if \(\pi (0 \mathbin {\Vert }N'_i) = P_j\) and \(\pi (1 \mathbin {\Vert }X'_i) = Q_k\). In this way, we obtain a graph on \(\mathcal {V}\mathrel {\mathop =^\mathrm{def}}\mathcal {P}\sqcup \mathcal {Q}\), called the transcript graph of \(\tau \) and denoted \(\mathcal {G}_{\tau }\). By definition, \(\mathcal {G}_{\tau }\) has no isolated vertices. Furthermore, \(\mathcal {G}_{\tau }\) is a bipartite graph with independent sets \(\mathcal {P}\) and \(\mathcal {Q}\).
4.2 Bad Transcripts
For fixed positive numbers \(L_1\) and \(L_2\), a transcript \(\tau = \left( {K_h, \tau _m, \tau _v } \right) \) is defined as bad if one of the following conditions holds.
-
\(\mathsf {bad}_1 \Leftrightarrow \) there exists \((i,j) \in [q]^{*2}\) such that \(N_i = N_k\) for some \(k(\ne i)\), \(N_j = N_l\) for some \(l(\ne j)\) and \(X_i = X_j\).
-
\(\mathsf {bad}_2 \Leftrightarrow \mathsf {bad}_{2a} \vee \mathsf {bad}_{2b} \vee \mathsf {bad}_{2c} \vee \mathsf {bad}_{2d} \vee \mathsf {bad}_{2e}\), where
-
\(\mathsf {bad}_{2a} \Leftrightarrow \) there exists \(i \in [q]\) such that \(T_i = \mathbf {0}\);
-
\(\mathsf {bad}_{2b} \Leftrightarrow \) there exists \((i, j) \in [q]^{*2}\) such that \(N_{i} = N_{j}\) and \(T_{i} = T_{j}\);
-
\(\mathsf {bad}_{2c} \Leftrightarrow \) there exists \((i, j) \in [q]^{*2}\) such that \(X_{i} = X_{j}\) and \(T_{i} = T_{j}\);
-
\(\mathsf {bad}_{2d} \Leftrightarrow \) there exists \((i, j, k) \in [q]^{*3}\) such that \(X_{i} = X_{j}\), \(N_j = N_k\) and \(T_i \mathbin {\oplus } T_j \mathbin {\oplus } T_k = \mathbf {0}\);
-
\(\mathsf {bad}_{2e} \Leftrightarrow \) there exists \((i, j, k, l) \in [q]^{*4}\) such that \(X_{i} = X_{j}\), \(N_j = N_k\), \(X_k = X_l\) and \(T_i \mathbin {\oplus } T_j \mathbin {\oplus } T_k \mathbin {\oplus } T_l = \mathbf {0}\).
-
-
\(\mathsf {bad}_3 \Leftrightarrow \mathsf {bad}_{3a} \vee \mathsf {bad}_{3b}\), where
-
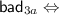 there exist \(i \in [q]\) and \(j \in [v]\) such that \(N_i = N_j'\), \(X_i = X_j'\) and \(T_i = T_j'\);
there exist \(i \in [q]\) and \(j \in [v]\) such that \(N_i = N_j'\), \(X_i = X_j'\) and \(T_i = T_j'\); -
 there exist \((i, j, k) \in [q]^{*3}\) and \(l \in [v]\) such that \(X_i = X_j\), \(N_j = N_k\), \(X_k = X'_l\), \(N'_l = N_i\), and \(T_i \mathbin {\oplus } T_j \mathbin {\oplus } T_k \mathbin {\oplus } T'_l = \mathbf {0}\).
there exist \((i, j, k) \in [q]^{*3}\) and \(l \in [v]\) such that \(X_i = X_j\), \(N_j = N_k\), \(X_k = X'_l\), \(N'_l = N_i\), and \(T_i \mathbin {\oplus } T_j \mathbin {\oplus } T_k \mathbin {\oplus } T'_l = \mathbf {0}\).
-
-
 .
. -
\(\mathsf {bad}_5 \Leftrightarrow \left| {\left\{ {i \in [q]: X_i = X_j \text { for some } j \text { such that }j\ne i} \right\} } \right| \ge L_2\).
 there exist
there exist  there exist
there exist  .
.If a transcript \(\tau \) is not bad, then it will be called a good transcript. For a good transcript \(\tau \), we observe that
-
1.
\(\mathcal {G}_{\tau }^=\), being a bipartite graph, contains no cycle without \(\mathsf {bad}_1\);
-
2.
\(\mathcal {G}_{\tau }^=\) contains no trail \(\mathcal {L}\) such that \(\lambda (\mathcal {L}) = \mathbf {0}\) without \(\mathsf {bad}_1 \vee \mathsf {bad}_2\);
-
3.
if two vertices are connected by a \(\lambda \)-labeled trail in \(\mathcal {G}^=\), then they cannot be connected with a \((\lambda , \ne )\)-labeled edge without \(\mathsf {bad}_1 \vee \mathsf {bad}_3\).
Furthermore, we see that \(\mathcal {G}_{\tau }^=\) contains no trail of length 5 without \(\mathsf {bad}_1\). With this observation, we conclude that for a good transcript \(\tau \),
-
1.
the transcript graph \(\mathcal {G}_{\tau }\) is nice (as defined in Sect. 3);
-
2.
\(\left| {\mathcal {G}} \right| \le 2(q + v)\le 2^{n-2}\).
These properties allow us to use Theorem 1 later. The following lemma upper bounds the probability of bad transcripts in the ideal world.
Lemma 6
With the notations defined as above, it holds that
Proof
In order to analyze \(\mathsf {bad}_{3b}\) later, we need to define a certain auxiliary event, which is parameterized by a positive number \(L_3\); let
for \(T \in \{0,1\}^n\), and let
-\(\mathsf {aux}\Leftrightarrow \) there exists \(T^*\in \{0,1\}^n\) such that \(\left| {I_{T^*}} \right| > L_3\).
-
1.
For fixed \(T\in \{0,1\}^n\) and \(i\in [q]\), suppose that \(i\in I_{T}\). It means that the i-th query is faulty, and that \(T_{i}\mathbin {\oplus }T_{j}=T\) for any (previous) j-th query such that \(N_{i} = N_{j}\), which happens with probability at most \(\mu /2^n\). Therefore we have
$$\begin{aligned} \Pr \left[ {\mathsf {aux}} \right] \le 2^n\left( {\begin{array}{c}\mu \\ L_3\end{array}}\right) \left( {\frac{\mu }{2^n}} \right) ^{L_3} \le 2^n \left( {\frac{e\mu ^2}{L_3 2^n}} \right) ^{L_3}. \end{aligned}$$ -
2.
The number of queries using any repeated nonce is at most \(2\mu \). So the number of pairs \((i, j) \in [q]^{*2}\) such that \(N_{i} = N_{k}\) for some \(k(\ne i)\) and \(N_{j} = N_{k'}\) for some \(k'(\ne j)\) is at most \(4\mu ^2\). For each of such pairs, say (i, j), the probability that \(X_{i}=X_{j}\) is at most \(\delta \). Therefore, we have
$$\Pr [\mathsf {bad}_1] \le 4\mu ^2\delta .$$ -
3.
The probability that \(T_i = \mathbf {0}\) for some \(i \in [q]\) is \(\frac{q}{2^n}\); namely,
$$\Pr [\mathsf {bad}_{2a}]\le \frac{q}{2^n}.$$ -
4.
By symmetry, we can assume that \(i<j\), which means that \(N_j\) is a faulty nonce. For each MAC query using a faulty nonce, there are at most \(\mu \) other queries using the same nonce. So the number of pairs (i, j) such that \(i<j\) and \(N_i=N_j\) is at most \(\mu ^2\). For each of such pairs (i, j), the probability that \(T_{i} = T_{j}\) is \(\frac{1}{2^n}\). Therefore, we have
$$\Pr \left[ {\mathsf {bad}_{2b}} \right] \le \frac{\mu ^2}{2^n}.$$Similarly, we can show that
$$\Pr \left[ {\mathsf {bad}_{2c}} \right] \le \frac{q^2\delta }{2^n}.$$ -
5.
Consider the case that \(i>\max \{j,k\}\). On the i-th query, the number of pairs \((j,k)\in [q]^{*2}\) such that \(N_j = N_k\) is at most \(2\mu ^2\). For each such pair (j, k), the probability that \(T_i \mathbin {\oplus } T_j \mathbin {\oplus } T_k = \mathbf {0}\) and \(X_{i} = X_{j}\) is \(\frac{\delta }{2^n}\). By similar arguments for the other cases (i.e., \(j>\max \{i,k\}\) and \(k>\max \{i,j\}\)), we see
$$\Pr \left[ {\mathsf {bad}_{2d}} \right] \le \frac{4\mu ^2q \delta }{2^n}.$$ -
6.
Consider the case that \(k>\max \{i,j,l\}\) and the k-th query makes \(\mathsf {bad}_{2e}\). For each \(Z\in \mathcal {K}_h\), let
$$\begin{aligned} \mathcal {I}_Z&\mathrel {\mathop =^\mathrm{def}}\left\{ {(i, j) \in [l-1]^{*2}: H_Z(M_i) \mathbin {\oplus } H_Z(M_j) = N_i \mathbin {\oplus } N_j} \right\} , \\ \mathcal {J}_Z&\mathrel {\mathop =^\mathrm{def}}\left\{ {l \in [l-1]: H_Z(M_k) \mathbin {\oplus } H_Z(M_l) = N_k \mathbin {\oplus } N_l} \right\} . \end{aligned}$$Since H is \(\delta \)-almost XOR universal, we have \(\sum _{Z \in \mathcal {K}_h} |\mathcal {I}_Z| \le q^2 \delta |\mathcal {K}_h|\) and \(\sum _{Z \in \mathcal {K}_h} |\mathcal {J}_Z| \le q \delta |\mathcal {K}_h|\). Then the probability that the k-th query completes a trail of length 4 satisfying \(T_i \mathbin {\oplus } T_j \mathbin {\oplus } T_k \mathbin {\oplus } T_l = \mathbf {0}\) is upper bounded by
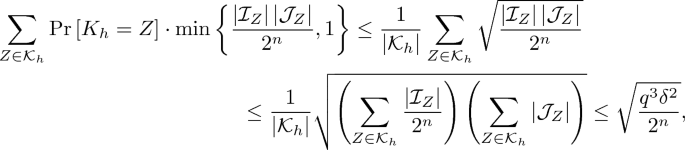
where the last inequality follows from the Cauchy-Schwarz inequality. Since the k-th query makes an inner edge of the trail, it should be a faulty query. Therefore this case happens with probability at most
$$\begin{aligned} \mu \sqrt{\frac{q^3\delta ^2}{2^n}}. \end{aligned}$$(1)Next, consider the case that \(l>\max \{i,j,k\}\) and the l-th query makes \(\mathsf {bad}_{2e}\). For each \(Z\in \mathcal {K}_h\), let
$$\begin{aligned} \mathcal {R}&\mathrel {\mathop =^\mathrm{def}}\left\{ {i \in [l - 1]: N_i = N_j \text { for some } j \in [l-1] \text { such that } j \ne i} \right\} , \\ \mathcal {I}'_Z&\mathrel {\mathop =^\mathrm{def}}\left\{ {(i, j) \in \left( {[l-1] \times \mathcal {R}} \right) : i \ne j \text { and } H_Z(M_i) \mathbin {\oplus } H_Z(M_j) = N_i \mathbin {\oplus } N_j} \right\} , \\ \mathcal {J}'_Z&\mathrel {\mathop =^\mathrm{def}}\left\{ {k \in \mathcal {R}: H_Z(M_k) \mathbin {\oplus } H_Z(M_l) = N_k \mathbin {\oplus } N_l} \right\} . \end{aligned}$$Since \(\left| {\mathcal {R}} \right| \le 2\mu \) and H is \(\delta \)-almost XOR universal, we have \(\sum _{Z \in \mathcal {K}_h} |\mathcal {I}'_Z| \le 2\mu q \delta |\mathcal {K}_h|\) and \(\sum _{Z \in \mathcal {K}_h} |\mathcal {J}'_Z| \le 2\mu \delta |\mathcal {K}_h|\). Then the probability that the l-th query completes a trail of length 4 satisfying \(T_i \mathbin {\oplus } T_j \mathbin {\oplus } T_k \mathbin {\oplus } T_l = \mathbf {0}\) is upper bounded by
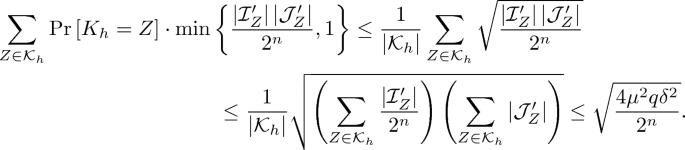
Therefore this case happens with probability at most
$$\begin{aligned} q\sqrt{\frac{4\mu ^2 q\delta ^2}{2^n}}. \end{aligned}$$(2)By symmetry, (1) and (2) cover the other cases (i.e., \(i>\max \{j,k,l\}\) and \(j>\max \{i,k,l\}\)). Therefore we have
$$ \Pr \left[ {\mathsf {bad}_{2e}} \right] \le \mu \sqrt{\frac{q^3 \delta ^2}{2^n}} + q\sqrt{\frac{4\mu ^2 q \delta ^2}{2^n}} = \frac{3\mu q^{\frac{3n}{2}}\delta }{2^{\frac{n}{2}}}. $$ -
7.
When an adversary makes a verification query \((N'_j,M'_j,T'_j)\), there is at most one MAC query \((N_i,M_i,T_i)\) such that \(N_i = N_j'\) and \(T_i =T_j'\) without \(\mathsf {bad}_{2b}\), since there would not be a pair of MAC queries whose nonces and tags are all the same.Footnote 2 For this pair of indices, the probability that \(X_i = X'_j\) is upper bounded by \(v \delta \). Therefore, we have
$$\Pr [\mathsf {bad}_{3a} \mid \lnot \mathsf {bad}_{2b}] \le v \delta .$$ -
8.
Suppose that an adversary makes a verification query \((N'_l,M'_l,T'_l)\), assuming \(\mathsf {bad}_1 \vee \mathsf {aux}\) did not happen. In order for this verification query to complete a cycle of length 4 containing it, there should be only a single MAC query, say \((N_i,M_i,T_i)\), such that \(N_i=N'_l\) since otherwise we have \(\mathsf {bad}_1\). Let \(T=T_i \mathbin {\oplus }T'_l\). Then it should be the case that either \(X_j=X_i\) or \(X_j=X'_l\) for some \(j\in I_T\), which happens with probability at most \(2L_3\delta \). Therefore, we have
$$ \Pr \left[ {\mathsf {bad}_{3b} \wedge \lnot \mathsf {bad}_1 \wedge \lnot \mathsf {aux}} \right] \le 2L_3 v \delta . $$ -
9.
The number of possible choices for j is at most \(2\mu \) since the j-th query uses a repeated nonce. For a fixed \(i\in [q]\), the probability that \(X_i=X_j\) is at most \(\delta \). By Markov inequality, we have
$$\Pr \left[ {\mathsf {bad}_4} \right] \le \frac{2 \mu q \delta }{L_1}.$$ -
10.
By Markov inequality, we have
$$ \Pr \left[ {\mathsf {bad}_5} \right] \le \frac{q^2 \delta }{L_2}. $$
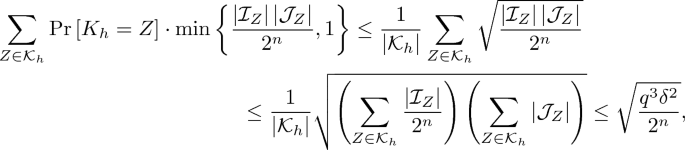
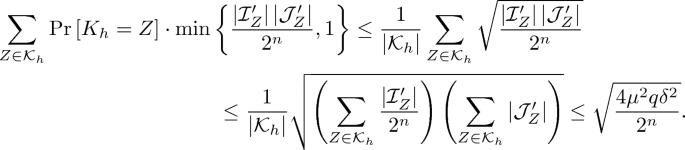
All in all, we have
\(\square \)
4.3 Concluding the Proof Using Mirror Theory
For any good transcript \(\tau \), let \(\mathcal {G}_{\tau }^=\) denote the graph obtained by deleting all \(\ne \)-labeled edges from \(\mathcal {G}_{\tau }\). We can decompose \(\mathcal {G}_{\tau }^=\) into four subgraphs in the same way as we did in Sect. 3, namely,
where \(\mathcal {G}^=_3\) is the union of the components containing at least one trail of length three, \(\mathcal {G}^=_2\) is the union of “stars”, \(\mathcal {G}^=_1\) is the set of isolated edges, and \(\mathcal {G}^=_0\) is the set of isolated vertices. We also decompose \(\mathcal {G}^=_3\) and \(\mathcal {G}^=_2\) into connected components as follows.
for some k and \(k'\). Let \(c_i=|\mathcal {C}_i|\) for \(i=1, \ldots , k\). We will also write \(c =\left| {\mathcal {G}^=_2} \right| (= \sum _{i = 1}^k c_i)\) and \(c' =\left| {\mathcal {G}^=_3} \right| \).
The probability of obtaining \(\tau \) in the real world is computed over the randomness of \(\pi \). By Theorem 1, the number of possible ways of evaluating \(\pi \) at the unknowns in \(\mathcal {V}\) (i.e., \(h^*(\mathcal {G}_{\tau })\)) is lower bounded by
where
Since the probability that \(\pi \) realizes each assignment is exactly \(1/(2^n)_{|\mathcal {V}|}\), and
we have
Upper Bounding c and \(c'\). Each component \(\mathcal {C}'_i\) has a trail of length 3, so without \(\mathsf {bad}_1\), \(\mathcal {V}_3\cap \mathcal {P}\) should contain at least one vertex of degree one (i.e., a leaf of \(\mathcal {C}'_i\)). We fix such a vertex, denoted \(P^*_i\), and its unique neighbor, denoted \(Q^*_i\), for every \(i=1,\ldots ,k'\). Again, without \(\mathsf {bad}_1\), every vertex of \(\mathcal {C}'_i\) except \(P^*_i\) and \(Q^*_i\) should be connected with \(Q^*_i\) by a trail of length 1, 2, or 3. Without \(\mathsf {bad}_4\), the number of vertices in \(\mathcal {V}_3\cap \mathcal {P}\) that are connected with some \(Q^*_i\) by a trail of length 3 is at most \(L_1\). The number of vertices in \(\mathcal {V}_3\cap \mathcal {Q}\) that are connected with some \(Q^*_i\) by a trail of length 2 is at most \(\mu \). Since \(k' \le L_1\), we have
On the other hand, we observe that each edge of \(\mathcal {E}^=_2 \sqcup \mathcal {E}^=_3\) corresponds to either a repeated nonce or a collision on X. Therefore, we have
since \(k + k' \le \mu + L_2\).
Taking the Expectation of \(\varepsilon _1(\tau )\). Connected components \(\mathcal {C}_i\) of \(\mathcal {G}^=_2\) can be classified into two types; a vertex \(P\in \mathcal {P}\) and its adjacent vertices in \(\mathcal {Q}\), called a P-star, and a vertex \(Q\in \mathcal {Q}\) and its adjacent vertices in \(\mathcal {P}\), called a Q-star. By renaming the components, let \(\mathcal {D}_1,\ldots ,\mathcal {D}_r\) denote the Q-stars in \(\mathcal {G}^=_2\), and let \(\mathcal {D}'_1,\ldots ,\mathcal {D}'_s\) denote the P-stars in \(\mathcal {G}^=_2\) for some r and s. Let \(d_i=|\mathcal {D}_i|\) for \(i=1,\ldots ,r\) and let \(d'_i=|\mathcal {D}'_i|\) for \(i=1,\ldots ,s\). When a single nonce is repeatedly used \(d+1\) times for any \(d\ge 1\), the d faulty nonces will make a P-star containing \(d+2\) vertices. Therefore we have
and
Each Q-star \(\mathcal {D}_i\) corresponds to an equivalent class of size \(d_i-1\) (defined in Lemma 1). Therefore we have
Furthermore, by using Lemma 1 with \(p_i = d_i-1\) and a \(\delta \)-AXU hash function \((N,M)\mapsto N\mathbin {\oplus }H_{K_h}(M)\), and since \(d_i\ge 3\) for every \(i=1,\ldots ,r\), we have
By (3), (5), (6), (7) and (8), we have
By (4), (9), Lemma 2 and Lemma 6, and by setting \(L_1 = \frac{\mu }{3}\) and \(L_2 = 2^{n-1} \delta ^{\frac{1}{2}}\), we obtain Theorem 2.
5 Security of \(\mathsf {nEHtM}\) Based on a Pseudorandom Function
In this section, we consider \(\mathsf {nEHtM}[H,F]\) based on an \((n - 1)\)-bit \(\delta \)-AXU hash function H and an n-to-s bit keyed function F, where \(1\le s\le n\). Up to the PRF-security of F, we will replace F by a truly random function \(\rho \), and prove the security of \(\mathsf {nEHtM}[H,\rho ]\).
Graph Representation of Transcripts. Suppose that an adversary \(\mathcal {A}\) makes q MAC queries using at most \(\mu \) faulty nonces, and makes v verification queries, obtaining
as well as \(K_h\) for free at the end of the attack. Once \(K_h\) is fixed, we can also fix \(X_i =H_{K_h}(M_i) \mathbin {\oplus } N_i\) for \(i = 1, \ldots , q\), and \(X'_j =H_{K_h}(M'_j) \mathbin {\oplus } N'_j\) for \(j = 1, \dots , v\). Then, exactly in the same way as we did in Sect. 4, we can define the transcript graph of \(\tau \), denoted \(\mathcal {G}_{\tau }\), and the graph obtained by deleting all \(\ne \)-labeled edges from \(\mathcal {G}_{\tau }\), denoted \(\mathcal {G}_{\tau }^=\).
Bad Transcripts. A transcript \(\tau = \left( {K_h, \tau _m, \tau _v } \right) \) is defined as bad if one of the following conditions holds.
-
\(\mathsf {bad}_1 \Leftrightarrow \) there exists \((i, j) \in [q]^{*2}\) such that \(N_{i} = N_{k}\) for some \(k(\ne i)\), \(N_{j} = N_{k'}\) for some \(k'(\ne j)\), and \(X_{i} = X_{j}\).Footnote 3
-
\(\mathsf {bad}_2 \Leftrightarrow \) there exist \(i \in [q]\) and \(j \in [v]\) such that \(N_i = N'_j\), \(X_i = X'_j\), and \(T_i = T'_j\).
-
\(\mathsf {bad}_3 \Leftrightarrow \) there exist \((i, j, k) \in [q]^{*3}\) and \(l \in [v]\) such that \(X_i=X_j\), \(N_j = N_k\), \(X_k=X'_l\), \(N'_l=N_i\), and \(T_i\mathbin {\oplus }T_j\mathbin {\oplus }T_k\mathbin {\oplus }T'_l=\mathbf {0}\).
If a transcript \(\tau \) is not bad, then it will be called a good transcript. For a good transcript \(\tau \), we observe that
-
1.
\(\mathcal {G}_{\tau }^=\), being a bipartite graph, contains no cycle without \(\mathsf {bad}_1\);
-
2.
if two vertices are connected by a \(\lambda \)-labeled trail in \(\mathcal {G}^=\), then they cannot be connected with a \((\lambda , \ne )\)-labeled edge without \(\mathsf {bad}_1\vee \mathsf {bad}_2\vee \mathsf {bad}_3\).
For a good transcript \(\tau \), the transcript graph \(\mathcal {G}_{\tau }^=\) is decomposed into trees. Due to the second property above, any \(\ne \)-labeled edge connects two different trees.
Upper Bounding the Probability of Bad Events. In order to upper bound the probability of each bad event (in the ideal world), we fix a positive number L, let
for \(T\in \{0,1\}^s\), and then define the following two auxiliary events.
-
\(\mathsf {aux}_1 \Leftrightarrow \) there exists \((i, j) \in [q]^{*2}\) such that \(N_{i} = N_{j}\) and \(T_{i} = T_{j}\).
-
\(\mathsf {aux}_2 \Leftrightarrow \) there exists \(T^*\in \{0,1\}^s\) such that \(\left| {I_{T^*}} \right| >L\).
Events \(\mathsf {aux}_1\), \(\mathsf {aux}_2\), \(\mathsf {bad}_1\), \(\mathsf {bad}_2\) and \(\mathsf {bad}_3\) are similar to \(\mathsf {bad}_{2b}\), \(\mathsf {aux}\), \(\mathsf {bad}_1\), \(\mathsf {bad}_{3a}\) and \(\mathsf {bad}_{3b}\) defined in Sect. 4, respectively (except that the tag size is s bits). So we have
and hence,
Concluding the Proof. For any good transcript \(\tau \), let \(\mathcal {V}\) denote the vertex set of \(\mathcal {G}_{\tau }^=\). Then the number of components of \(\mathcal {G}_{\tau }^=\) is \(|\mathcal {V}|-q\), so the number of solutions to the set of all equations in \(\mathcal {G}_{\tau }^=\) is exactly \(2^{s(|\mathcal {V}|-q)}\). When a single \(\ne \)-labeled edge is replaced by a \(=\)-labeled edge, the resulting graph has \(|\mathcal {V}|-q-1\) components. This means that there are exactly \(2^{s(|\mathcal {V}|-q-1)}\) solutions to \(\mathcal {G}_{\tau }^=\) that violate a single non-equation. Since there are v non-equations, we conclude that the number of solutions to \(\mathcal {G}_{\tau }\) is at least
Since the probability that \(\rho \) realizes each assignment (in the real world) is exactly \(1/2^{s|\mathcal {V}|}\), we have
Since
we have
By (10), (11) and Lemma 2, we obtain following theorem.
Theorem 3
Let \(\delta >0\), and let \(H:\mathcal {K}\times \mathcal {M}\rightarrow \{0,1\}^n\) be a \(\delta \)-almost universal hash function. For positive integers \(\mu \), q, v, and for any \(L>0\), we have
When \(L=\mu +1\), we have \(\Pr \left[ {\mathsf {aux}_2} \right] =0\) since \(\left| {I_T} \right| \le \mu \). Then, by Theorem 3, we have
When \(1\le s\le \frac{1}{\delta 2^s}\), let \(L=\frac{1}{\delta 2^s}\). Assuming \(2 e\mu ^2\delta \le 1\), we have
and hence,
Alternative Bound. Interestingly, we can obtain an alternative bound by slightly modifying the bad events. A transcript \(\tau \) is defined as bad if it satisfies \(\mathsf {bad}_1\) (as defined above), \(\mathsf {bad}'_2\) or \(\mathsf {bad}'_3\), where
-
\(\mathsf {bad}'_2 \Leftrightarrow \) there exist \(i \in [q]\) and \(j \in [v]\) such that \(N_i = N'_j\) and \(X_i = X'_j\).
-
\(\mathsf {bad}'_3 \Leftrightarrow \) there exist \(i \in [q]\) and \(j \in [v]\) such that \(N_i = N_k\) for some \(k(\ne i)\) and \(X_i = X'_j\).
If two vertices are connected by a \(\lambda \)-labeled trail in \(\mathcal {G}^=\), then they cannot be connected with a \((\lambda , \ne )\)-labeled edge without \(\mathsf {bad}'_2\vee \mathsf {bad}'_3\).
-
1.
When an adversary makes a verification query \((N'_j,M'_j,T'_j)\), there are at most \(\mu +1\) MAC queries \((N_i,M_i,T_i)\) such that \(N_i = N_j'\). For each such pair, the probability that \(X_i = X'_j\) is upper bounded by \(\delta \). Therefore, we have
$$\Pr [\mathsf {bad}'_2]\le (\mu +1)v \delta .$$ -
2.
For a verification query \((N'_j,M'_j,T'_j)\) and a query \((N_i,M_i,T_i)\) using any repeated nonce, the probability that \(X_i = X'_j\) is at most \(\delta \). Therefore, we have
$$\Pr [\mathsf {bad}'_3]\le 2\mu v \delta .$$
With this type of bad transcripts, we have the following theorem.
Theorem 4
Let \(\delta >0\), and let \(H:\mathcal {K}\times \mathcal {M}\rightarrow \{0,1\}^n\) be a \(\delta \)-almost universal hash function. For positive integers \(\mu \), q, v, we have
The main difference of Theorem 4 from Theorem 3 is that the tag size s does not affect the number of faulty queries \(\mu \), while this bound contains the term \(\mu v \delta \) (which is not in Theorem 3), so \(\mu \) possibly limits the number of verification queries v.
Interpretation. Given that \(\mathsf {nEHtM}[H,\rho ]\) is secure up to any number of MAC queries and \(2^s\) verification queries, one might wonder how many faulty queries can be allowed. Assuming \(\delta \approx \frac{1}{2^n}\), we observe the following:
-
1.
When \(\frac{n}{2}<s\le \frac{1}{\delta 2^s}\), \(\mathsf {nEHtM}[H,\rho ]\) is secure as long as \(\mu <\max \{2^{\frac{s}{2}},2^{n-s}\}\) by (13) and Theorem 4.
-
2.
When \(s\le \frac{n}{2}\), \(\mathsf {nEHtM}[H,\rho ]\) is secure as long as \(\mu <2^{\frac{n}{2}}\) by Theorem 4.
When \(s=n\), we have
by Theorem 3 with \(L=n(=s)\), which means that \(\mathsf {nEHtM}[H,\rho ]\) is secure when \(\mu <2^{\frac{n}{2}}\) and \(v <\frac{2^n}{n}\).
6 Security of Truncated \(\mathsf {nEHtM}\)
In this section, we analyze how tag truncation affects the security of \(\mathsf {nEHtM}\) when \(\mathsf {nEHtM}\) is based on a block cipher E (which is modeled as a truly random permutation \(\pi \)). We can take two different approaches.
First, we can use Theorem 5 in [8]; let \(F:\mathcal {K}\times \mathcal {N}\times \mathcal {M}\rightarrow \{0,1\}^n\) be a nonce-based MAC with key space \(\mathcal {K}\), nonce space \(\mathcal {N}\), message space \(\mathcal {M}\) and tag space \(\mathcal {T}=\{0,1\}^n\). For any \(1\le s \le n-1\), let \( \mathsf {Tr} _s:\{0,1\}^n \rightarrow \{0,1\}^s\) be a function that takes s bits of the input in any way (e.g., the leftmost s bits of an n-bit input). Let
denote a truncated variant of F that returns only s bits of the original tag. Cogliati et al. [8] proved that
We can combine (14) with Theorem 2. However, the threshold number of MAC queries would not go beyond \(2^{\frac{3n}{4}}\) anyway.
An alternative approach is to use Theorem 3 and 4 by seeing a truncated permutation as a pseudorandom function. In [13, 30], it has been proved that
for a random permutation \(\pi \). Since a \((\mu ,q,v)\)-forging adversary makes at most \(2(q+v)\) calls to the underlying (truncated) block cipher, we have the following theorem.
Theorem 5
Let \(\delta >0\), and let \(H:\mathcal {K}\times \mathcal {M}\rightarrow \{0,1\}^n\) be a \(\delta \)-almost universal hash function. For positive integers \(\mu \), q, v, and for any \(L>0\), we have
where
Interpretation. When \(s\le \frac{2n}{3}\), \(\mathsf {nEHtM}[H,\pi ]_s\) is secure up to \(2^{n-\frac{s}{2}}\) MAC queries and \(2^s\) verification queries as long as \(\mu <\min \{2^{\frac{n}{2}},2^{n-s}\}\) by Theorem 5 (using B). In particular, we observe that
-
1.
when \(s=\frac{n}{2}\), \(\mathsf {nEHtM}[H,\pi ]_s\) is secure up to \(2^{\frac{3n}{4}}\) MAC queries, \(2^s\) verification queries, and \(2^{\frac{n}{2}}\) faulty queries;
-
2.
when \(s=\frac{n}{4}\), \(\mathsf {nEHtM}[H,\pi ]_s\) is secure up to \(2^{\frac{7n}{8}}\) MAC queries, \(2^s\) verification queries, and \(2^{\frac{n}{2}}\) faulty queries.
Notes
- 1.
A trail is a walk in which all edges are distinct.
- 2.
For simplicity of analysis, one can assume that an adversary begins making verification queries after it makes all the MAC queries.
- 3.
It is possible that \(k=j\) and \(k'=i\).
References
Banik, S., Pandey, S.K., Peyrin, T., Sasaki, Yu., Sim, S.M., Todo, Y.: GIFT: a small present. In: Fischer, W., Homma, N. (eds.) CHES 2017. LNCS, vol. 10529, pp. 321–345. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-66787-4_16
Bellare, M., Canetti, R., Krawczyk, H.: Keying hash functions for message authentication. In: Koblitz, N. (ed.) CRYPTO 1996. LNCS, vol. 1109, pp. 1–15. Springer, Heidelberg (1996). https://doi.org/10.1007/3-540-68697-5_1
Bellare, M., Goldreich, O., Krawczyk, H.: Stateless evaluation of pseudorandom functions: security beyond the birthday barrier. In: Wiener, M. (ed.) CRYPTO 1999. LNCS, vol. 1666, pp. 270–287. Springer, Heidelberg (1999). https://doi.org/10.1007/3-540-48405-1_17
Bellare, M., Kilian, J., Rogaway, P.: The security of the cipher block chaining message authentication code. J. Comput. Syst. Sci. 61(3), 362–399 (2000)
Bernstein, D.J.: Stronger security bounds for wegman-carter-shoup authenticators. In: Cramer, R. (ed.) EUROCRYPT 2005. LNCS, vol. 3494, pp. 164–180. Springer, Heidelberg (2005). https://doi.org/10.1007/11426639_10
Black, J., Rogaway, P.: A block-cipher mode of operation for parallelizable message authentication. In: Knudsen, L.R. (ed.) EUROCRYPT 2002. LNCS, vol. 2332, pp. 384–397. Springer, Heidelberg (2002). https://doi.org/10.1007/3-540-46035-7_25
Bogdanov, A., et al.: PRESENT: an ultra-lightweight block cipher. In: Paillier, P., Verbauwhede, I. (eds.) CHES 2007. LNCS, vol. 4727, pp. 450–466. Springer, Heidelberg (2007). https://doi.org/10.1007/978-3-540-74735-2_31
Cogliati, B., Lee, J., Seurin, Y.: New constructions of macs from (tweakable) block ciphers. IACR Trans. Symmetric Cryptol. 2, 27–58 (2017)
Cogliati, B., Seurin, Y.: EWCDM: an efficient, beyond-birthday secure, nonce-misuse resistant MAC. In: Robshaw, M., Katz, J. (eds.) CRYPTO 2016. LNCS, vol. 9814, pp. 121–149. Springer, Heidelberg (2016). https://doi.org/10.1007/978-3-662-53018-4_5
Datta, N., Dutta, A., Nandi, M., Yasuda, K.: Encrypt or decrypt? to make a single-key beyond birthday secure nonce-based MAC. In: Shacham, H., Boldyreva, A. (eds.) CRYPTO 2018. LNCS, vol. 10991, pp. 631–661. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-96884-1_21
Dutta, A., Jha, A., Nandi, M.: Tight Security Analysis of EHtM MAC. IACR Trans. Symmetric Cryptol. 3, 130–150 (2017)
Dutta, A., Nandi, M., Talnikar, S.: Beyond birthday bound secure mac in faulty nonce model. In: Ishai, Y., Rijmen, V. (eds.) EUROCRYPT 2019. LNCS, vol. 11476, pp. 437–466. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-17653-2_15
Gilboa, S., Gueron, S., Morris, B.: How many queries are needed to distinguish a truncated random permutation from a random function? J. Cryptol. 31(1), 162–171 (2017). https://doi.org/10.1007/s00145-017-9253-0
Guo, J., Peyrin, T., Poschmann, A., Robshaw, M.: The LED block cipher. In: Preneel, B., Takagi, T. (eds.) CHES 2011. LNCS, vol. 6917, pp. 326–341. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-23951-9_22
Hoang, V.T., Tessaro, S.: Key-alternating ciphers and key-length extension: exact bounds and multi-user security. In: Robshaw, M., Katz, J. (eds.) CRYPTO 2016. LNCS, vol. 9814, pp. 3–32. Springer, Heidelberg (2016). https://doi.org/10.1007/978-3-662-53018-4_1
Iwata, T., Kurosawa, K.: OMAC: one-key CBC MAC. In: Johansson, T. (ed.) FSE 2003. LNCS, vol. 2887, pp. 129–153. Springer, Heidelberg (2003). https://doi.org/10.1007/978-3-540-39887-5_11
Jaulmes, É., Joux, A., Valette, F.: On the security of randomized CBC-MAC beyond the birthday paradox limit a new construction. In: Daemen, J., Rijmen, V. (eds.) FSE 2002. LNCS, vol. 2365, pp. 237–251. Springer, Heidelberg (2002). https://doi.org/10.1007/3-540-45661-9_19
Jaulmes, É., Lercie, R.: FRMAC, a fast randomized message authentication code. IACR Cryptology ePrint Archive, Report 2004/166 (2004). http://eprint.iacr.org/2004/166
Jha, A., Nandi, M.: Tight Security of Cascaded LRW2. Journal of Cryptology, pages 1–46, 2020
Joux, A.: Authentication failures in NIST Version of GCM. Comments submitted to NIST Modes of Operation Process (2006). http://csrc.nist.gov/groups/ST/toolkit/BCM/documents/comments/800-38_Series-Drafts/GCM/Joux_comments.pdf
Kim, S., Lee, B., Lee, J.: Tight security bounds for double-block hash-then-sum MACs. In: Canteaut, A., Ishai, Y. (eds.) EUROCRYPT 2020. LNCS, vol. 12105, pp. 435–465. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-45721-1_16
Leurent, G., Nandi, M., Sibleyras, F.: Generic attacks against beyond-birthday-bound MACs. In: Shacham, H., Boldyreva, A. (eds.) CRYPTO 2018. LNCS, vol. 10991, pp. 306–336. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-96884-1_11
Mennink, B., Neves, S.: Encrypted davies-meyer and its dual: towards optimal security using mirror theory. In: Katz, J., Shacham, H. (eds.) CRYPTO 2017. LNCS, vol. 10403, pp. 556–583. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-63697-9_19
Minematsu, K.: How to thwart birthday attacks against MACs via small randomness. In: Hong, S., Iwata, T. (eds.) FSE 2010. LNCS, vol. 6147, pp. 230–249. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-13858-4_13
Naito, Y.: Blockcipher-based MACs: beyond the birthday bound without message length. In: Takagi, T., Peyrin, T. (eds.) ASIACRYPT 2017. LNCS, vol. 10626, pp. 446–470. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-70700-6_16
Nandi, M.: Mind the composition: birthday bound attacks on EWCDMD and SoKAC21. In: Canteaut, A., Ishai, Y. (eds.) EUROCRYPT 2020. LNCS, vol. 12105, pp. 203–220. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-45721-1_8
Patarin, J.: Introduction to mirror theory: analysis of systems of linear equalities and linear non equalities for cryptography. IACR Cryptology ePrint Archive, Report 2010/287 (2010). http://eprint.iacr.org/2010/287
Patarin, J.: Mirror theory and cryptography. IACR Cryptology ePrint Archive, Report 2016/702 (2016). http://eprint.iacr.org/2016/702
Shoup, V.: On fast and provably secure message authentication based on universal hashing. In: Koblitz, N. (ed.) CRYPTO 1996. LNCS, vol. 1109, pp. 313–328. Springer, Heidelberg (1996). https://doi.org/10.1007/3-540-68697-5_24
Stam, A.J.: Distance between sampling with and without replacement. Stat. Neerl. 32(2), 81–91 (1978)
Wegman, M.N., Carter, J.L.: New hash functions and their use in authentication and set equality. J. Comput. Syst. Sci. 22(3), 265–279 (1981)
Yasuda, K.: The sum of CBC MACs is a secure PRF. In: Pieprzyk, J. (ed.) CT-RSA 2010. LNCS, vol. 5985, pp. 366–381. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-11925-5_25
Yasuda, K.: A new variant of PMAC: beyond the birthday bound. In: Rogaway, P. (ed.) CRYPTO 2011. LNCS, vol. 6841, pp. 596–609. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-22792-9_34
Zhang, L., Wu, W., Sui, H., Wang, P.: 3kf9: enhancing 3GPP-MAC beyond the birthday bound. In: Wang, X., Sako, K. (eds.) ASIACRYPT 2012. LNCS, vol. 7658, pp. 296–312. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-34961-4_19
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
A Proof of Theorem 1
A Proof of Theorem 1
Proof
For \(i=1, 2, 3\), let \(q_i=|\mathcal {E}_i^=|\) and let \(v_i=|\mathcal {E}_i^{\ne }|\). Then we have \(q=q_1+q_2+q_3\) (with \(q_0 = 0\)) and \(v=v_0+v_1+v_2+v_3\). Note that we interchangeably write \(\left| {\mathcal {G}_i} \right| \), \(\left| {\mathcal {G}^=_i} \right| \) and \(\left| {\mathcal {V}_i} \right| \) for \(i=1, 2, 3\).
Suppose that \(\mathcal {G}^=_3\) is decomposed into \(k'\) components \(\mathcal {C}'_1,\ldots ,\mathcal {C}'_{k'}\) for some \(k'\). Then by Lemma 3, the number of solutions to \(\mathcal {G}_3\), denoted \(h(\mathcal {G}_3)\), satisfies
Again, by Lemma 3, for a fixed solution to \(\mathcal {G}_3\), the number of solutions to \(\mathcal {G}_2\), denoted \(h(\mathcal {G}_2)\), satisfies
By Lemma 4, for a fixed solution to \(\mathcal {G}_2\), the number of solutions to \(\mathcal {G}_1\), denoted \(h(\mathcal {G}_1)\), satisfies
since \(\left| {\mathcal {V}_3} \right| + \left| {\mathcal {V}_2} \right| + 2q_1 \le 2q \le N/4\). By Lemma 5, for a fixed solution to \(\mathcal {G}_1\), the number of solutions to \(\mathcal {G}_0\), denoted \(h(\mathcal {G}_0)\), satisfies
By (15), (16), (17), (18), we have
\(\square \)
Rights and permissions
Copyright information
© 2020 International Association for Cryptologic Research
About this paper

Cite this paper
Choi, W., Lee, B., Lee, Y., Lee, J. (2020). Improved Security Analysis for Nonce-Based Enhanced Hash-then-Mask MACs. In: Moriai, S., Wang, H. (eds) Advances in Cryptology – ASIACRYPT 2020. ASIACRYPT 2020. Lecture Notes in Computer Science(), vol 12491. Springer, Cham. https://doi.org/10.1007/978-3-030-64837-4_23
Download citation
DOI: https://doi.org/10.1007/978-3-030-64837-4_23
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-64836-7
Online ISBN: 978-3-030-64837-4
eBook Packages: Computer ScienceComputer Science (R0)
