
Abstract
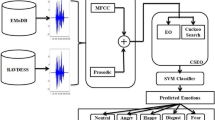
A Speech Emotion Recognition (SER) system can be defined as a collection of methodologies that process and classify speech signals to detect emotions embedded in them [2]. Among the most critical issues to consider in an SER system are: i) definition of the kind of emotions to classify, ii) look for suitable datasets, iii) selection of the proper input features and iv) optimisation of the convenient features. This work will consider four of the well-known dataset in the literature: EmoDB, TESS, SAVEE and RAVDSS. Thus, this study focuses on designing a low-power SER algorithm based on combining one prosodic feature with six spectral features to capture the rhythm and frequency. The proposal compares eleven low-power Classical classification Machine Learning techniques (CML), where the main novelty is optimising the two main parameters of the MFCC spectral feature through the meta-heuristic technique SA: the n_mfcc and the hop_length.
The resulting algorithm could be deployed on low-cost embedded systems with limited computational power like a smart speaker. In addition, the proposed SER algorithm will be validated for four well-known SER datasets. The obtained models for the eleven CML techniques with the optimised MFCC features outperforms clearly (more than a 10%) the baseline models obtained with the not-optimised MFCC for the studied datasets.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Ahsan, M., Kumari, M.: Physical features based speech emotion recognition using predictive classification. Int. J. Comput. Sci. Inf. Technol. 8(2), 63–74 (2016). https://doi.org/10.5121/ijcsit.2016.8205
Akçay, M.B., Oğuz, K.: Speech emotion recognition: emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers. Speech Commun. 116(October 2019), 56–76 (2020). https://doi.org/10.1016/j.specom.2019.12.001
Anagnostopoulos, C.N., Iliou, T., Giannoukos, I.: Features and classifiers for emotion recognition from speech: a survey from 2000 to 2011. Artif. Intell. Rev. 43(2), 155–177 (2012). https://doi.org/10.1007/s10462-012-9368-5
Breiman, L.: Random forests. Mach. Learn. 45(1), 5–32 (2001). https://doi.org/10.1023/A:1010933404324
Burkhardt, F., Paeschke, A., Rolfes, M., Sendlmeier, W., Weiss, B.: A database of German emotional speech. In: 9th European Conference on Speech Communication and Technology, pp. 1517–1520 (2005)
Chang, C.C., Lin, C.J.: LIBSVM: a library for support vector machines. ACM Trans. Intell. Syst. Technol. 2(3) (2011). https://doi.org/10.1145/1961189.1961199
Chatterjee, S., Koniaris, C., Kleijn, W.B.: Auditory model based optimization of MFCCs improves automatic speech recognition performance. In: Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH (January), pp. 2987–2990 (2009)
Dzedzickis, A., Kaklauskas, A., Bucinskas, V.: Human emotion recognition: review of sensors and methods. Sensors (Switzerland) 20(3) (2020). https://doi.org/10.3390/s20030592
Friedman, J.H.: Greedy function approximation: a gradient boosting machine. Ann. Stat. 29(5), 1189–1232 (2001). https://doi.org/10.1214/aos/1013203451
Geurts, P., Ernst, D., Wehenkel, L.: Extremely randomized trees. Mach. Learn. 63(1), 3–42 (2006). https://doi.org/10.1007/s10994-006-6226-1
Haq, S., Jackson, P.J.B.: Speaker-dependent audio-visual emotion recognition. In: Proceedings of the International Conference on Auditory-Visual Speech Processing (AVSP 2008), Norwich, UK (2009)
Haq, S., Jackson, P.J.B.: Machine Audition: Principles, Algorithms and Systems. chap. Multimodal, pp. 398–423. IGI Global, Hershey (2010)
Haq, S., Jackson, P., Edge, J.: Audio-visual feature selection and reduction for emotion classification. Expert Syst. Appl. 39, 7420–7431 (2008)
Hastie, T., Tibshirani, R., Friedman, J.: Springer Series in Statistics The Elements of Statistical Learning Data Mining, Inference, and Prediction. Technical report
Kingma, D.P., Ba, J.L.: Adam: a method for stochastic optimization. In: 3rd International Conference on Learning Representations, ICLR 2015 - Conference Track Proceedings. International Conference on Learning Representations, ICLR (2015)
Klapuri, A., Davy, M.: Signal Processing Methods for Music Transcription. Springer, Heidelberg (2007)
Koolagudi, S.G., Rao, K.S.: Emotion recognition from speech: a review. Int. J. Speech Technol. 15(2), 99–117 (2012). https://doi.org/10.1007/s10772-011-9125-1
Librosa.org: MFCC implementation (2021). https://librosa.org/doc/main/_modules/librosa/feature/spectral.html#mfcc
Livingstone, S.R., Russo, F.A.: The Ryerson audio-visual database of emotional speech and song (RAVDESS): a dynamic, multimodal set of facial and vocal expressions in north American English. PLoS ONE 13(5), e0196391 (2018). https://doi.org/10.1371/journal.pone.0196391
Manning, C.D., Raghavan, P., Schuetze, H.: The Bernoulli model. In: Introduction to Information Retrieval, pp. 234–265 (2009)
Pandey, S.K., Shekhawat, H.S., Prasanna, S.R.: Deep learning techniques for speech emotion recognition: a review. In: 2019 29th International Conference Radioelektronika, RADIOELEKTRONIKA 2019 - Microwave and Radio Electronics Week, MAREW 2019 (2019). https://doi.org/10.1109/RADIOELEK.2019.8733432
Pichora-Fuller, M.K., Dupuis, K.: Toronto emotional speech set (TESS) (2020). https://doi.org/10.5683/SP2/E8H2MF
Rahi, P.K.: Speech emotion recognition systems: review. Int. J. Res. Appl. Sci. Eng. Technol. 8(1), 45–50 (2020). https://doi.org/10.22214/ijraset.2020.1007
Rao, K.S., Koolagudi, S.G., Vempada, R.R.: Emotion recognition from speech using global and local prosodic features. Int. J. Speech Technol. 16(2), 143–160 (2013). https://doi.org/10.1007/s10772-012-9172-2
Rutenbar, R.A.: Simulated annealing algorithms: an overview. IEEE Circuits Dev. Mag. 5(1), 19–26 (1989). https://doi.org/10.1109/101.17235
Sahidullah, M., Saha, G.: Design, analysis and experimental evaluation of block based transformation in MFCC computation for speaker recognition. Speech Commun. 54(4), 543–565 (2012). https://doi.org/10.1016/j.specom.2011.11.004
Väyrynen, E.: Emotion recognition from speech using prosodic features. Ph.D. thesis (2014)
Zeng, Z., Pantic, M., Roisman, G.I., Huang, T.S.: A survey of affect recognition methods: audio, visual, and spontaneous expressions. IEEE Trans. Pattern Anal. Mach. Intell. 31(1), 39–58 (2009). https://doi.org/10.1109/TPAMI.2008.52
Zhu, J., Zou, H., Rosset, S., Hastie, T.: Multi-class AdaBoost*. Technical report (2009)
Acknowledgement
This research has been funded partially by the Spanish Ministry of Economy, Industry and Competitiveness (MINECO) under grant TIN2017-84804-R/PID2020-112726RB-I00.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
de la Cal, E., Gallucci, A., Villar, J.R., Yoshida, K., Koeppen, M. (2021). Simple Meta-optimization of the Feature MFCC for Public Emotional Datasets Classification. In: Sanjurjo González, H., Pastor López, I., García Bringas, P., Quintián, H., Corchado, E. (eds) Hybrid Artificial Intelligent Systems. HAIS 2021. Lecture Notes in Computer Science(), vol 12886. Springer, Cham. https://doi.org/10.1007/978-3-030-86271-8_55
Download citation
DOI: https://doi.org/10.1007/978-3-030-86271-8_55
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-86270-1
Online ISBN: 978-3-030-86271-8
eBook Packages: Computer ScienceComputer Science (R0)