
Abstract
To optimize the performance of some of our systems running on non-uniform memory architecture (NUMA) servers with Arm processors, we have implemented multiple versions of the HMCS lock, an advanced NUMA-aware lock that has been identified in the literature as particularly scalable.
This is a highly non-trivial task because of the many implementation choices for interlocked operations, alignment, and memory barrier placement, affecting not only the lock’s performance but also its correctness. The published HMCS lock does not discuss choices that affect performance, but it does present a choice of barriers. We observe that this choice is wrong, leading to hangs on Kunpeng Arm servers. We repair the barriers and implement the first formally-verified HMCS lock with VSync, an automated formal verification and optimization tool for weak consistency. We explain the barrier bugs in detail and report our experience of barrier optimizations for Arm servers.
This is a preview of subscription content, log in via an institution.
Buying options
Tax calculation will be finalised at checkout
Purchases are for personal use only
Learn about institutional subscriptionsReferences
https://e.huawei.com/uk/products/servers/taishan-server/taishan-2280-v2
Amazon Web Services: AWS Graviton Processor - Enabling the best price performance in Amazon EC2 (2020). https://aws.amazon.com/ec2/graviton
Chabbi, M., Amer, A., Wen, S., Liu, X.: An efficient abortable-locking protocol for multi-level NUMA systems. SIGPLAN Not. 52(8), 61–74 (2017). https://doi.org/10.1145/3155284.3018768
Chabbi, M., Fagan, M.W., Mellor-Crummey, J.M.: High performance locks for multi-level NUMA systems. In: PPoPP 2015, New York, USA, pp. 215–226. ACM (2015). https://doi.org/10.1145/2688500.2688503
Dean, J., Ghemawat, S.: Leveldb (2021). https://github.com/google/leveldb
Defilippi, J.: Introducing AMBA 5 CHI protocol enhancements (2017). https://community.arm.com/developer/ip-products/system/b/soc-design-blog/posts/introducing-new-amba-5-chi-protocol-enhancements
Dice, D., Kogan, A.: Compact NUMA-aware locks. In: EuroSys 2019, New York, USA. ACM (2019). https://doi.org/10.1145/3302424.3303984
Guiroux, H., Lachaize, R., Quéma, V.: Multicore locks: the case is not closed yet. In: USENIX Annual Technical Conference, pp. 649–662 (2016)
Huawei: Huawei unveils industry’s highest-performance ARM-based CPU, January 2019. https://www.huawei.com/en/news/2019/1/huawei-unveils-highest-performance-arm-based-cpu
Kokologiannakis, M., Raad, A., Vafeiadis, V.: Model checking for weakly consistent libraries. In: PLDI 2019, New York, USA, pp. 96–110. ACM (2019). https://doi.org/10.1145/3314221.3314609
Liu, N., Zang, B., Chen, H.: No barrier in the road: a comprehensive study and optimization of ARM barriers. In: PPoPP 2020, New York, USA, pp. 348–361. ACM (2020). https://doi.org/10.1145/3332466.3374535
Mellor-Crummey, J.M., Scott, M.L.: Algorithms for scalable synchronization on shared-memory multiprocessors. ACM Trans. Comput. Syst. 9(1), 21–65 (1991). https://doi.org/10.1145/103727.103729
Oberhauser, J., et al.: VSync: push-button verification and optimization for synchronization primitives on weak memory models. In: ASPLOS 2021, New York, USA. ACM (2021). https://doi.org/10.1145/3445814.3446748
Podkopaev, A., Lahav, O., Vafeiadis, V.: Bridging the gap between programming languages and hardware weak memory models. Proc. ACM Program. Lang. 3(POPL) (2019). https://doi.org/10.1145/3290382
Pulte, C., Flur, S., Deacon, W., French, J., Sarkar, S., Sewell, P.: Simplifying ARM concurrency: multicopy-atomic axiomatic and operational models for ARMv8. Proc. ACM Program. Lang. 2(POPL) (2017). https://doi.org/10.1145/3158107
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendices
A Arm vs. IMM Consistency Model

A subset of the arm consistency model. The key derived relation is ordered-before (
 ), which is irreflexive in consistent graphs.
), which is irreflexive in consistent graphs.

A subset of the IMM consistency model. Key relations are the acyclic relation (
 ) which is acyclic in consistent graphs, as well as synchronizes-with (
) which is acyclic in consistent graphs, as well as synchronizes-with (
 ), extended coherence order (
), extended coherence order (
 ), and happens-before (
), and happens-before (
 ), where
), where
 is irreflexive in consistent graphs.
is irreflexive in consistent graphs.
A standard way to define weak consistency models is through execution graphs. Nodes in these graphs represent events such as reads and writes, and edges specify various relations between these events, e.g., the order in which reads and writes to the same location are committed. Memory models are defined by a) the edges that exist in the graph and b) restrictions on these edges. For brevity, we introduce only the event and edge types of Arm and IMM that are relevant to the bugs we mention in this paper. We consider write events \(\mathbf {W}_{X}( loc , val )\), read events \(\mathbf {R}_{X}( loc , val )\), and fence events \(\mathbf {F}_{X}\), where  is the so called mode of the event, \( loc \) is the shared memory location on which the event operates, and \( val \) is the value written or read in the event. The mode denotes the type of memory barrier (if any) represented by the event: \(\mathbf {rlx}\) indicates that no barrier is present, \(\mathbf {acq}\) represents acquire, \(\mathbf {rel}\) release, and \(\mathbf {sc}\) sequentially consistent barriers. Mode \(\mathbf {rlx}\) is the default mode and omitted.
is the so called mode of the event, \( loc \) is the shared memory location on which the event operates, and \( val \) is the value written or read in the event. The mode denotes the type of memory barrier (if any) represented by the event: \(\mathbf {rlx}\) indicates that no barrier is present, \(\mathbf {acq}\) represents acquire, \(\mathbf {rel}\) release, and \(\mathbf {sc}\) sequentially consistent barriers. Mode \(\mathbf {rlx}\) is the default mode and omitted.
We consider the following types of fundamental edges:
-
 (read from external) edges
(read from external) edges  connect a write event of a thread to a read event of another thread that reads from it.
connect a write event of a thread to a read event of another thread that reads from it. -
 (modification order external) edges
(modification order external) edges  connect write events (writing to the same location) of different threads indicating the order in which they were committed.
connect write events (writing to the same location) of different threads indicating the order in which they were committed. -
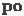 (program order) edges connect events of the same thread in the order in which they are issued by the program.
(program order) edges connect events of the same thread in the order in which they are issued by the program. -
 (control dependency) edges connect a read \(\mathbf {R}_{X}(x, a)\) that influences a condition (e.g., if- or while-condition) evaluation to every event of the same thread that is issued after the condition.
(control dependency) edges connect a read \(\mathbf {R}_{X}(x, a)\) that influences a condition (e.g., if- or while-condition) evaluation to every event of the same thread that is issued after the condition. -
event-type self-loops
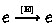 for event type
for event type  connect every event e of type E to itself.
connect every event e of type E to itself.
 (read from external) edges
(read from external) edges  connect a write event of a thread to a read event of another thread that reads from it.
connect a write event of a thread to a read event of another thread that reads from it. (modification order external) edges
(modification order external) edges  connect write events (writing to the same location) of different threads indicating the order in which they were committed.
connect write events (writing to the same location) of different threads indicating the order in which they were committed.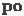 (program order) edges connect events of the same thread in the order in which they are issued by the program.
(program order) edges connect events of the same thread in the order in which they are issued by the program. (control dependency) edges connect a read
(control dependency) edges connect a read 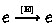 for event type
for event type  connect every event e of type E to itself.
connect every event e of type E to itself.Other edges are derived from these fundamental edges according to the rules of the consistency model (Figs. 15 and 16). For instance, the edge  in Fig. 3(b) implies an
in Fig. 3(b) implies an
 edge
edge  on IMM (with Eq. (16)). Such derived rules are often defined with the composition operator ‘;’, which for arbitrary edge types R and S is defined by
on IMM (with Eq. (16)). Such derived rules are often defined with the composition operator ‘;’, which for arbitrary edge types R and S is defined by

The meaning of barriers is defined by the derived edges they imply; for example, the meaning of \({\mathbf {F_{\mathbf {rel}}}}\) (which maps to the full DMB.ISH fence) on Arm is defined through the
 edge it implies between preceding and subsequent operations (with Eqs. (3) to (5)).
edge it implies between preceding and subsequent operations (with Eqs. (3) to (5)).
In Figs. 15 and 16 we have collected the rules of IMM and Arm consistency that are relevant to our discussion. In [16] it is shown that Arm consistency implies IMM consistency; thus any bug on Arm is also present on IMM, and verification on IMM implies correctness on Arm. The converse is not true, and bugs on IMM are not always bugs on Arm. Indeed, some of the bugs identified by VSync on the HMCS lock on IMM are not bugs on Arm. The key difference relevant to these bugs is that
 edges imply an
edges imply an
 edge on Arm, but do not imply an
edge on Arm, but do not imply an
 edge on IMM. Thus they contribute to
edge on IMM. Thus they contribute to
 cycles but not to
cycles but not to
 cycles.
cycles.
We illustrate the implications at hand of the execution graphs in Fig. 3. In Fig. 3(a), we have an
 edge from Event e to Event a; in Fig. 3(b), we instead have an
edge from Event e to Event a; in Fig. 3(b), we instead have an
 edge from Event e to Event a. Other than those events and the edge between them, the graphs are the same. Thus in both graphs, the following imply
edge from Event e to Event a. Other than those events and the edge between them, the graphs are the same. Thus in both graphs, the following imply
 edges:
edges:
-
 (Eqs. (3) to (5))
(Eqs. (3) to (5)) -
 (Eqs. (1) and (5))
(Eqs. (1) and (5)) -
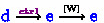 (Eqs. (2), (4) and (5))
(Eqs. (2), (4) and (5))
 (Eqs. (3) to (5))
(Eqs. (3) to (5)) (Eqs. (1) and (5))
(Eqs. (1) and (5))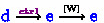 (Eqs. (2), (4) and (5))
(Eqs. (2), (4) and (5))The only edge missing for an
 cycle is
cycle is  . This edge is implied by the
. This edge is implied by the  edge in Fig. 3(a) and the
edge in Fig. 3(a) and the  edge in Fig. 3(b) (with Eqs. (1) and (5)). Note that due to transitivity (Eq. (5)) the cycle
edge in Fig. 3(b) (with Eqs. (1) and (5)). Note that due to transitivity (Eq. (5)) the cycle  implies a reflexive edge
implies a reflexive edge  , which contradicts the irreflexivity of
, which contradicts the irreflexivity of
 (Eq. (6)). Thus both graphs are inconsistent on Arm.
(Eq. (6)). Thus both graphs are inconsistent on Arm.
On IMM, the following imply
 -edges:
-edges:
-
 and
and 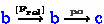 (Eqs. (7), (10) and (11))
(Eqs. (7), (10) and (11)) -
 (Eq. (11))
(Eq. (11)) -
 (Eqs. (8), (9) and (11))
(Eqs. (8), (9) and (11))
 and
and 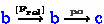 (Eqs. (7), (10) and (11))
(Eqs. (7), (10) and (11)) (Eq. (11))
(Eq. (11)) (Eqs. (8), (9) and (11))
(Eqs. (8), (9) and (11))Analogous to before, only an  is missing for an
is missing for an
 cycle. In Fig. 3(a) this edge is implied by the
cycle. In Fig. 3(a) this edge is implied by the  edge with Eq. (11), and this graph is inconsistent on IMM. But in Fig. 3(b), the
edge with Eq. (11), and this graph is inconsistent on IMM. But in Fig. 3(b), the
 edge does not contribute an
edge does not contribute an
 edge. Indeed, there is no
edge. Indeed, there is no
 cycle in Fig. 3(b), which is consistent on IMM. Unfortunately, two of the bugs detected by VSync on IMM appear only in graphs that look like Fig. 3(b). These bugs therefore only appear on IMM, but can not appear on Arm.
cycle in Fig. 3(b), which is consistent on IMM. Unfortunately, two of the bugs detected by VSync on IMM appear only in graphs that look like Fig. 3(b). These bugs therefore only appear on IMM, but can not appear on Arm.
We proceed to discuss how to fix these bugs on IMM. Consider the third graph (see Fig. 3(c)) which is almost identical to the second (see Fig. 3(b)). We only added a \({\mathbf {F_{\mathbf {acq}}}}\) fence between the  and
and  . Adding this fence does not eliminate the
. Adding this fence does not eliminate the
 -cycle we inferred previously, and this graph is also inconsistent with Arm. On IMM we derive the following edges:
-cycle we inferred previously, and this graph is also inconsistent with Arm. On IMM we derive the following edges:
-
 thus
thus  (Eqs. (13) and (14))
(Eqs. (13) and (14)) -
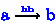 ,
,  and
and  thus
thus  (Eq. (15))
(Eq. (15)) -
 (Eq. (16))
(Eq. (16))
 thus
thus  (Eqs. (13) and (14))
(Eqs. (13) and (14))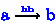 ,
,  and
and  thus
thus  (Eq. (15))
(Eq. (15)) (Eq. (16))
(Eq. (16))As shown in (Fig. 3(d)) we end up with  and thus
and thus  . But the
. But the
 ;
;
 relation is irreflexive (Eq. (17)). We conclude that this graph is inconsistent with IMM. In other words, due to the \({\mathbf {F_{\mathbf {acq}}}}\) fence the execution with the bug cannot occur on IMM.
relation is irreflexive (Eq. (17)). We conclude that this graph is inconsistent with IMM. In other words, due to the \({\mathbf {F_{\mathbf {acq}}}}\) fence the execution with the bug cannot occur on IMM.
B Optimizing Barriers on Atomic Operations
The implicit \(\mathbf {sc}\) barriers on CAS and SWAP in Fig. 2 are not optimal. VSync reports that they are already too strong for IMM, and indeed they can be optimized further for Arm. The exact optimization depends on the variant. Manual analysis shows that when using fences, all barriers on the atomic operations can be removed. When using implicit barriers, release barriers on Lines 17 and 30 are needed to avoid non-termination (with similar bugs as those in Sect. 3.1) and acquire and release barriers are needed on Line 17 resp. Line 55 to ensure that operations in the critical section can not leak out of the lock (resulting in loss of mutual exclusion). The resulting barriers are shown in Table 1. That table also shows a variant that may be more optimal when using interlocked LSE instructions. Unlike load/store-exclusive pairs, on which \(\mathbf {sc}\) implicit barriers do not act like a full barrier (see discussion in Sect. 3.1), LSE interlocked operations have been strengthened in a recent change to Arm specifications to provide the same semantics for \(\mathbf {sc}\) implicit barriers as a DMB.ISH (see Eq. (10)) through the rule

where \( amo \) relates a the read event of an atomic memory operation (such as SWP) to its write event, and \([\mathbf{A} ]\) and \([\mathbf{L} ]\) are event-type self-loops for acquire resp. release events. This contrasts the earlier definition in [17], in which LSE instructions provide the same ordering guarantees as load/store-exclusive pairs.
However, this stronger ordering is not necessary for the HMCS lock, and thus we optimize barriers further by relegating the acquire barrier to a trailing fence. This variant is what is denoted by hmcs-amo in Sect. 5. As demonstrated in Fig. 10, this optimization does not currently improve performance compared to hmcs-vsync (which uses \(\mathbf {sc}\) barriers on atomic operations). Perhaps if LSE operations become more efficient for low-contention cases in the future, these optimizations will become more interesting.
For the sake of completeness we also implement a variant hmcs-armamo which applies the optimization to hmcs-arm, i.e., in which as described in Table 1 all implicit barriers on atomic operations are removed. Performance results (without LSE) are shown in Figs. 17 and 18. While minor improvements can be measured in the microbenchmark, these improvements also do not translate to the larger benchmark.

Performance of AMO-optimizations with fences on microbenchmark

Performance of AMO-optimizations with fences on LevelDB
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Oberhauser, J., Oberhauser, L., Paolillo, A., Behrens, D., Fu, M., Vafeiadis, V. (2021). Verifying and Optimizing the HMCS Lock for Arm Servers. In: Echihabi, K., Meyer, R. (eds) Networked Systems. NETYS 2021. Lecture Notes in Computer Science(), vol 12754. Springer, Cham. https://doi.org/10.1007/978-3-030-91014-3_17
Download citation
DOI: https://doi.org/10.1007/978-3-030-91014-3_17
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-91013-6
Online ISBN: 978-3-030-91014-3
eBook Packages: Computer ScienceComputer Science (R0)