
Abstract
Penetration testing is a central problem in computer security, and recently, the application of machine learning techniques to this topic has gathered momentum. In this paper, we consider the problem of exploiting SQL injection vulnerabilities, and we represent it as a capture-the-flag scenario in which an attacker can submit strings to an input form with the aim of obtaining a flag token representing private information. We then model the attacker as a reinforcement learning agent that interacts with the server to learn an optimal policy leading to an exploit. We compare two agents: a simpler structured agent that relies on significant a priori knowledge and uses high-level actions; and a structureless agent that has limited a priori knowledge and generates SQL statements. The comparison showcases the feasibility of developing agents that rely on less ad-hoc modeling and illustrates a possible direction to develop agents that may have wide applicability.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


Notes
- 1.
- 2.
- 3.
- 4.
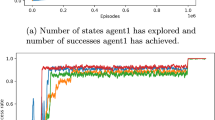
A completely random agent would use an average of 17 actions.
- 5.
\(\circ \) represents the concatenation symbol, space characters and
 a comma character.
a comma character. - 6.
- 7.
- 8.
- 9.
 a comma character.
a comma character.References
Ammanabrolu, P., Tien, E., Hausknecht, M., Riedl, M.O.: How to avoid being eaten by a grue: structured exploration strategies for textual worlds. arXiv preprint arXiv:2006.07409 (2020)
Andrychowicz, M., et al.: Hindsight experience replay. In: Proceedings of the 31st International Conference on Neural Information Processing Systems, pp. 5055–5065 (2017)
Applebaum, A., Miller, D., Strom, B., Korban, C., Wolf, R.: Intelligent, automated red team emulation. In: Proceedings of the 32nd Annual Conference on Computer Security Applications, pp. 363–373 (2016)
Bellemare, M., Srinivasan, S., Ostrovski, G., Schaul, T., Saxton, D., Munos, R.: Unifying count-based exploration and intrinsic motivation. In: Advances in Neural Information Processing Systems, vol. 29, pp. 1471–1479 (2016)
Bland, J.A., Petty, M.D., Whitaker, T.S., Maxwell, K.P., Cantrell, W.A.: Machine learning cyberattack and defense strategies. Comput. Secur. 92, 101738 (2020)
Boddy, M.S., Gohde, J., Haigh, T., Harp, S.A.: Course of action generation for cyber security using classical planning. In: ICAPS, pp. 12–21 (2005)
Brockman, G., et al.: Openai gym (2016)
Cho, K., van Merriënboer, B., Bahdanau, D., Bengio, Y.: On the properties of neural machine translation: encoder-decoder approaches. In: Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, pp. 103–111 (2014)
Chowdary, A., Huang, D., Mahendran, J.S., Romo, D., Deng, Y., Sabur, A.: Autonomous security analysis and penetration testing. In: The 16th International Conference on Mobility, Sensing and Networking (MSN 2020) (2020)
Elderman, R., Pater, L.J., Thie, A.S.: Adversarial reinforcement learning in a cyber security simulation. Ph.D. thesis, Faculty of Science and Engineering (2016)
Erdődi, L., Sommervoll, Å.Å., Zennaro, F.M.: Simulating SQL injection vulnerability exploitation using q-learning reinforcement learning agents. J. Inf. Secur. Appl. 61, 102903 (2021). https://doi.org/10.1016/j.jisa.2021.102903. https://www.sciencedirect.com/science/article/pii/S2214212621001290
Gardiner, J., Nagaraja, S.: On the security of machine learning in malware C&C detection: a survey. ACM Comput. Surv. (CSUR) 49(3), 1–39 (2016)
Ghanem, M.C., Chen, T.M.: Reinforcement learning for efficient network penetration testing. Information 11(1), 6 (2020)
Haarnoja, T., Zhou, A., Abbeel, P., Levine, S.: Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor. In: International Conference on Machine Learning, pp. 1861–1870. PMLR (2018)
He, J., et al.: Deep reinforcement learning with a natural language action space. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1621–1630 (2016)
Hoffmann, J.: Simulated penetration testing: from “Dijkstra” to “Turing Test++”. In: Twenty-Fifth International Conference on Automated Planning and Scheduling (2015)
Jain, V., Fedus, W., Larochelle, H., Precup, D., Bellemare, M.G.: Algorithmic improvements for deep reinforcement learning applied to interactive fiction. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 4328–4336 (2020)
Lattimore, T., Szepesvári, C.: Bandit Algorithms. Cambridge University Press, Cambridge (2020)
Maeda, R., Mimura, M.: Automating post-exploitation with deep reinforcement learning. Comput. Secur. 100, 102108 (2021)
Mnih, V., et al.: Asynchronous methods for deep reinforcement learning. In: International Conference on Machine Learning, pp. 1928–1937. PMLR (2016)
Narasimhan, K., Kulkarni, T.D., Barzilay, R.: Language understanding for text-based games using deep reinforcement learning. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (2015)
Pozdniakov, K., Alonso, E., Stankovic, V., Tam, K., Jones, K.: Smart security audit: reinforcement learning with a deep neural network approximator. In: 2020 International Conference on Cyber Situational Awareness, Data Analytics and Assessment (CyberSA), pp. 1–8. IEEE (2020)
Raff, E., Barker, J., Sylvester, J., Brandon, R., Catanzaro, B., Nicholas, C.K.: Malware detection by eating a whole exe. In: Workshops at the Thirty-Second AAAI Conference on Artificial Intelligence (2018)
Sarraute, C., Buffet, O., Hoffmann, J.: Penetration testing== pomdp solving? In: Workshop on Intelligent Security (Security and Artificial Intelligence) (2011)
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017)
Shone, N., Ngoc, T.N., Phai, V.D., Shi, Q.: A deep learning approach to network intrusion detection. IEEE Trans. Emerg. Top. Comput. Intell. 2(1), 41–50 (2018)
Speicher, P., Steinmetz, M., Hoffmann, J., Backes, M., Künnemann, R.: Towards automated network mitigation analysis. In: Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, pp. 1971–1978 (2019)
Xu, X., Liu, C., Song, D.: SQLNet: generating structured queries from natural language without reinforcement learning. arXiv preprint arXiv:1711.04436 (2017)
Xue, H., Sun, S., Venkataramani, G., Lan, T.: Machine learning-based analysis of program binaries: a comprehensive study. IEEE Access 7, 65889–65912 (2019)
Yuan, X., et al.: Counting to explore and generalize in text-based games. arXiv preprint arXiv:1806.11525 (2018)
Zelinka, M.: Baselines for reinforcement learning in text games. In: 2018 IEEE 30th International Conference on Tools with Artificial Intelligence (ICTAI), pp. 320–327. IEEE (2018)
Zennaro, F.M., Erdodi, L.: Modeling penetration testing with reinforcement learning using capture-the-flag challenges: trade-offs between model-free learning and a priori knowledge. arXiv preprint arXiv:2005.12632 (2020)
Zhong, V., Xiong, C., Socher, R.: Seq2SQL: generating structured queries from natural language using reinforcement learning. arXiv preprint arXiv:1709.00103 (2017)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
A Implementation Details
A Implementation Details
1.1 A.1 Structured Agent
The following is the list of actions available to the structured agent:
-
1.
\(\epsilon \)
-
2.
1’ or 1=1 –
-
3.
1’ or 1=2 –
-
4.
1’ union select NULL –
-
5.
1’ union select NULL, NULL –
-
6.
1’ union select NULL, NULL, NULL –
-
7.
1’ union select account from private –
-
8.
1’ union select account, NULL from private –
-
9.
1’ union select account, NULL, NULL from private –
-
10.
1” or 1=1 –
-
11.
1” or 1=2 –
-
12.
1” union select NULL –
-
13.
1” union select NULL, NULL –
-
14.
1” union select NULL, NULL, NULL –
-
15.
1” union select account from private –
-
16.
1” union select account, NULL from private –
-
17.
1” union select account, NULL, NULL from private –
-
18.
1 or 1=1 –
-
19.
1 or 1=2 –
-
20.
1 union select NULL –
-
21.
1 union select NULL, NULL –
-
22.
1 union select NULL, NULL, NULL –
-
23.
1 union select account from private –
-
24.
1 union select account, NULL from private –
-
25.
1 union select account, NULL, NULL from private –
where \(\epsilon \) denotes an empty string. Actions are partitioned in SQL statements aimed at probing the escape character in the pre-generated SQL statement (action number 2, 3, 10, 11, 18, 19), SQL statements aimed at guessing the number of columns necessary for the SQLi (action number 4, 5, 6, 12, 13, 14, 20, 21, 22), SQL statements attempting a SQLi (action number 7, 8, 9, 15, 16, 17, 23, 24, 25), other actions (action number 1).
1.2 A.2 Structureless Agent
The following are the alphabets at different levels of complexity. For complexity three we use the following alphabet:  where \(\mathtt {a}\) and \(\mathtt {p}\) are aliases for \(\mathtt {account}\) and \(\mathtt {private}\), respectively. For complexity four we use the following alphabet:
where \(\mathtt {a}\) and \(\mathtt {p}\) are aliases for \(\mathtt {account}\) and \(\mathtt {private}\), respectively. For complexity four we use the following alphabet: 
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Del Verme, M., Sommervoll, Å.Å., Erdődi, L., Totaro, S., Zennaro, F.M. (2021). SQL Injections and Reinforcement Learning: An Empirical Evaluation of the Role of Action Structure. In: Tuveri, N., Michalas, A., Brumley, B.B. (eds) Secure IT Systems. NordSec 2021. Lecture Notes in Computer Science(), vol 13115. Springer, Cham. https://doi.org/10.1007/978-3-030-91625-1_6
Download citation
DOI: https://doi.org/10.1007/978-3-030-91625-1_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-91624-4
Online ISBN: 978-3-030-91625-1
eBook Packages: Computer ScienceComputer Science (R0)