
Abstract
During navigation, people tend to associate objects that have outstanding characteristics to useful landmarks. The landmarkness is usually divided into three categories of salience: the visual, the structural, and the semantic. Actually, the roles of visual and structural landmarks have been widely explored at the expense of the semantic salience. Thus, we investigated its significance compared to the two others through an exploratory experiment conducted on the Internet. Specifically, 63 participants were asked to select landmarks along 30 intersections located in Quebec City. Participants were split by gender and familiarity with the study area. Unsurprisingly, the results show that unlike strangers, locals tended to focus on highly semantic landmarks. In addition, we found that women were more influenced by the structural salience than men. Finally, our findings suggest that the side where travelers move compared to the road impacts on the landmark selection process.
Similar content being viewed by others


Keywords
1 Context and Research Goal
Landmarks are usually considered as an organizing concept of human spatial knowledge (cf. Siegel and White 1975), as markers used to find one’s way (cf. Lynch 1960), but also as a specific component of route directions (cf. Tom and Denis 2003). Specifically, individuals who follow an itinerary with landmark-based instructions make less frequent breaks to ensure the route control than those who only rely on street names (Michon and Denis 2001 and Tom et al. 2003). In the same vein, wayfinding directions that contain a minimum set of landmarks are more easily memorized than those without any mention (Daniel et al. 2003). Such landmarks are usually described according to their location or their intrinsic characteristics.
Lovelace et al. (1999) proposed a categorization of landmarks based on their location, namely: (1) off route landmarks, which are considered as global orientation objects, (2) on route landmarks, i.e. objects located along the scheduled itinerary and used by travelers to ensure the route control, (3) potential choice points, which are entities located along an intersection where a turning decision is possible but not scheduled, and finally, (4), choice points, i.e. landmarks located at each intersection where a turn is planned. Sorrows and Hirtle (1999) proposed a typology of landmarks according to their individual attributes: (1) visual landmarks are objects easily distinctive by their visual characteristics (e.g. size, shape, color), (2) structural landmarks are remarkable because of their highly accessible position (e.g. a corner of a major street intersection), and (3), cognitive landmarks, which remain outstanding by their atypical meaning or function (e.g. a church surrounded by several shops). Concretely, a landmark rarely groups these three types of salience at the same time but it can be usually characterized by more than one of them.
Raubal and Winter reused this typology to formalize a model of landmark salience that was applied to the facades of buildings (2002). Similarly, Caduff and Timpf (2008) proposed an analogous model of landmarkness. According to them, three specific types of salience are involved in the process of landmark selection. The first one is the perceptual salience, which is limited to the visual attention in the context of wayfinding. The cognitive salience is the second one. It is linked to the observer’s spatial knowledge. They distinguish the degree of recognition of objects (i.e. the more an object recurs, the more memorized and recognized it will be) from the idiosyncratic relevance of objects (i.e. the personal significance of objects according to the observer’s experience). Finally, like Winter et al. (2005), the contextual salience is the last one mentioned by the authors. Indeed, tasks required during the navigation affect the observer’s visual attention. For instance, a scene that contains a lot of objects requires more resources to extract relevant landmarks. In the same vein, a car driver obviously relies on a visual field more limited than a pedestrian. Thus, both might not necessarily choose the same landmark at the identical decision point.
Several research have been carried out according to those complementary approaches. For instance, Winter (2003) introduced the concept of advance visibility by assuming that buildings highly visible from a long distance catch a significant attention while navigating. He proposed to compute the advance visibility of objects by multiplying their visibility coverage and their orientation, in accordance with the direction of navigation. In parallel, Klippel and Winter (2005) enriched the concept of structural salience. According to them, the landmark candidate should ideally be located along the same direction as the turn, and before the intersection. This assumption was partly supported by Röser et al. (2012a; 2012b). However, research on the semantic salience of landmarks is currently rather limited. Since visual and structural saliencies rely on “easily” measurable criteria, or at least easily identifiable (e.g. size, color, location, etc.), research on the measure of landmarkness clearly focused on these two types of salience. In fact, the semantic salience is harder to estimate because it exclusively refers to the observer’s spatial experience. Indeed, it relies on subjective indicators quite complex to assess. Actually, in the context of automatic landmark detection, giving route instructions that contain idiosyncratic landmarks is not feasible, unless the system accesses the traveler’s spatial knowledge (through a history of check-ins for example). This functionality might be conceivable in the near future since the current version of Google Maps is able to design personal maps based on users’ points of interest. But for now, the alternative consists of providing semantic landmarks collectively recognized at different scales (world, city, or district). Nonetheless, the following issue remains: how to objectively establish that the Starbucks Coffee located at the corner of a given intersection is more recognized than the MacDonald’s that faces it at the opposite corner? Assigning a precise semantic salience score remains tricky, especially when one faces several famous venues. Before the advent of Volunteered Geographic Information (VGI) and Location-based Social Networks (e.g. Swarm), the detection of semantic landmarks was frequently limited to the most significant historical and cultural places and to few limited attributes (e.g. function, explicit signs, etc.).
VGI clearly changed the way of producing and consuming geographic data (Goodchild 2007). Citizens constantly connected to the Internet are now able to easily share - whether deliberately or not - their spatial position on social media. By this way, VGI gives an opportunity to capture the local geographic knowledge (Elwood et al. 2013 and Quesnot and Roche 2015b). In the specific context of landmark detection, Richter and Winter (2011) developed a tool that allows OpenStreetMap (OSM) users to tag landmarks on this platform. However, contributors dot not necessarily realize the usefulness of such approach since landmark-based instructions are not really publicized. An alternative consists in data mining the crowdsourced data that are produced without the will of contributing to any enrichment of spatial component. This kind of approach is in line with Tezuka and Tanaka’s work on landmark extraction from web documents (2005). For instance, Crandall et al. (2009) proposed an interesting solution to detect landmarks by analyzing geotagged photos published on Flickr. However, their solution only extracts global landmarks (i.e. places from where lots of people publish photos) and neglects local landmarks. In addition, Quesnot and Roche (2015a) proposed to identify semantic landmarks by exploiting the check-ins shared on Facebook and Swarm. Unlike Crandall et al.’s approach, this alternative also takes local semantic landmarks into account. Indeed, their selection can be easily modulated according to the distribution of check-ins.
Except the focus on the measure of landmark semantic salience, only few research highlighted the significance of the semantic salience itself (e.g. Nothegger et al. 2004). To our best knowledge, Hamburger and Röser’s research (2014) currently remains the only one that provides explicit empirical findings about the helpfulness of semantic landmarks in a wayfinding context. Unsurprisingly, the authors found that the memorization of the route was better when pictures of well-known landmarks were incorporated inside their virtual environment. Given this empirical finding, one can assume that an individual who travels inside an unfamiliar environment may not rely on the same landmarks as someone who knows the area by heart. By taking this assumption as a starting point, we ask the following research questions: what is the significance of semantic salience compared to both visual and structural saliencies? Does this salience really represent a decisive parameter in the selection of landmarks for strangers? Moreover, is there a meaningful difference in the landmark selection between familiar and unfamiliar individuals? The question of the semantic salience is crucial in the context of landmark selection. The current research attempts to provide additional empirical findings regarding Hamburger and Röser’s work by also focusing on the visual and structural saliencies. Specifically, we first conducted a survey to estimate some structural salience scores according to the turning decision (Sect. 2). We reused those scores through an experiment conducted on the Internet where we asked participants to choose landmarks along 30 different intersections across Quebec City (Sect. 3).
2 Study 1
This study was the starting point of our research. Indeed, one of our goals was to compare the semantic salience with the visual and structural saliencies. Thus, we conducted a survey to establish some structural salience scores of reference. We then reused them in the main experiment that is detailed in the next section.
2.1 Participants
A total of 80 participants joined this survey (39 females and 41 males). We anonymously hired them via the general mailing list of Laval University. The participants’ age varied from 18 to 55 with an average of 28.13 years.
2.2 Material
We used Google Form sheets to design this survey. We relied on an approach similar to the one proposed by Röser et al. (2012a; 2012b). In this way, we inserted two pictures of a cross intersection regarding two fields of view (allocentric and egocentric). We focused on this type of intersection since it remains one of the most commons in North America. We respectively included the allocentric and egocentric sketches (cf. Fig. 1) in the first and second sheets of the form.

Allocentric and egocentric sketches of the cross intersection.
2.3 Procedure
After having specified their gender and their age, the participants were invited to read a brief contextualization of the survey: “Imagine that you are visiting an unfamiliar city. In theory, you would instinctively select landmarks along your route to orient yourself and find your way (to go back to your hotel room for example). The main purpose of this survey is to identify the position of the landmark that you would select on a cross intersection according to a left turn and a right turn”. We first presented the allocentric picture and we asked the participants two questions: “Considering that you are arriving from the bottom of the figure, which place would you choose as a landmark if you were supposed to turn to the left?”. The same question was asked for the right turn. Participants were redirected to the second sheet of the form once they answered the questions about the allocentric picture. We then invited them to answer the same questions about the egocentric sketch.
2.4 Results and Discussion
Regardless of the perspective, buildings located along the same direction as the turn were clearly favored by both males and females (cf. Table 2). This finding is in line with the studies made in the same context (see Klippel and Winter 2005 and Röser et al. 2012a; 2012b). However, one can notice a slight difference between men and women by paying attention to the percentages on Fig. 2 and Table 2. Specifically, women tended to select more buildings located along the ssame direction as the turn for the right turn (92.31 % of women vs 85.37 % of men for the egocentric view) whereas men followed the same trend for the left one (90.24 % of men vs 87.18 % of women regarding the same view). In the same vein, men systematically favored the places located after the intersection when the egocentric view was proposed. Nonetheless, the p values calculated from the Fisher’s exact test do not indicate any association between the gender and the position of the landmark candidate (cf. Table 1). Having said that, the most important finding to notice is the difference between the left turn and the right one. Indeed, the Fisher’s test suggests a weak association between the turn and the position of the landmark according to the intersection (cf. Table 1). More precisely, 56.41 % of the women tended to select the buildings located after the intersection for the left turn whereas only 38.46 % of them chose those buildings for the right one (from an egocentric perspective). The pattern is identical for the men and for both allocentric and egocentric views. More precisely, building E seems to enjoy a greater attention from the participants for the left turn than building F for the right one (egocentric average: 52 % vs 37 %).

Detailed results of the survey: allocentric view (left), egocentric view (center), and average scores (right). The top half refers to the left turn whereas the other half deals with the right one.
Actually, the visibility of buildings A and B (E and F in the egocentric sketch) is somewhat higher when the egocentric perspective is added (cf. Fig. 1). In fact, that is why Röser et al. (2012b) proposed a weight of 0.74 for the places located after the intersection and 0.24 for those located before the intersection. However, building A seems to be more visible than building B in participants’ mind. On the one hand, we argue that they mentally positioned themselves on the right side of the road. Indeed, we do believe that the lines marked on the road in the allocentric sketch induced participants to reason as if they were driving a car. Yet, the side of the road where people drive here in Quebec City is the right one. Since the allocentric picture appeared first, we do think that participants relied on the same pattern for the egocentric one. This distinction was not highlighted by Röser et al. (2012a; 2012b) since the virtual traveler constantly moved in the middle of the road. However, one cannot ignore that individuals usually travel either on the left or on the right side of the road; and that is especially true for pedestrians. On the other hand, the way we drawn the buildings in the egocentric sketch might also had an impact in the participants’ choice of landmarks. Specifically, the results could have been different if E and F were taller than G and H. To sum up, the findings of this survey suggest that the direction of the turn and the side of the road are two factors closely linked to the structural salience. The gender difference highlighted in Table 2 remains slight but is worth to be further investigated. In the end, we argue that the average between the allocentric and egocentric perspectives for both turns is a good compromise for a quantitative characterization of the structural salience.
3 Study 2
We carried out the main experiment once the survey was completely finished. The second study was primarily done to bring empirical evidences about the significance of semantic landmarks in comparison with the visual and structural saliencies. We also wanted to further investigate the influence of both the gender and the side of road effect previously highlighted. In order to achieve these goals, we developed a web application based on the Google Maps API. By using the Google Street View service, the participants of this experiment were able to pick-up landmarks while navigating on the right side of the road.
3.1 Participants
A total of 63 individuals participated in this online experiment. We directly hired them by email. We systematically excluded individuals who were involved in the previous survey. Since our goal was to obtain a group divided by the degree of familiarity with the study area (i.e. Quebec City) and the gender, there were two hiring sessions. We first focused on familiar participants. We only selected individuals who lived at least three years in Quebec City. In the end, we hired 31 individuals (15 females and 16 males). This first sub-group was mainly composed of Laval University graduated students in geomatics, geography, urban planning, and neurosciences. The average age of this group was 26.6 years and the average time spent in Quebec City was 11.1 years. On the other hand, we selected 32 individuals (17 females and 15 males) who live in France and who have never been to Quebec City. This second sub-group was mainly composed of researchers, engineers, and technicians in geomatics, geography, and environment. Their age ranged from 24 to 45, with an average of 28 years. Each participant signed a consent form before participating in this experiment.
3.2 Material
We first determined the method of computation for the three saliencies and for the advance visibility. Afterward, we focused on the design of the experiment.
Visual Salience Score. We decided to compute the visual salience by making a combination of the attributes proposed by Raubal and Winter (2002) and Duckham et al. (2010) (cf. Table 3); namely: the color of the building, its area, its proximity to road, and the presence of noticeable signs. Indeed, these are standard attributes also used in similar research (e.g. Elias 2003).
Specifically, we assigned a score between 0 and 20 to the last two attributes. The proximity to road factor was computed on a GIS (ESRI ArcMap 10.2.2) using OSM Web Map Service as a base map. The score assigned to the color attribute was partially based on Raubal and Winter’s approach for computing the visual salience (2002). However, instead of computing it on the basis of the distance from the [R,G,B] mean score (computed itself from the visual salience score of each landmark located around a decision point), we based it on the distance from the [R,G,B] score of the intersection scene. More precisely, we define the [R,G,B] score of the intersection scene as the color that stands out the most from the vista that includes each potential landmark candidate. We used the Color Thief Javascript API to automatically extract the dominant color of the tiles associated with each intersection and each potential landmark. Afterward, we compared the [R,G,B] means of the dominant colors of both the intersection scene and the landmark candidate. The more the distance between the two means was significant, the higher the color score of the candidate was. In our opinion, computing a visual score through this approach remains sensible. Indeed, since participants virtually traveled inside a set of Google photo panoramas, the color of objects other than the potential landmark candidates (e.g. signboards, trees, parked cars, or walkers) might have interfered in the single visual salience score of the buildings. Similarly, we computed the area score by taking the distance from the average area of the candidates into account. We define the average area as the mean calculated from the areas of all landmark candidates. Note that there were systematically four landmark candidates per intersection (cf. Fig. 3). We also computed areas in square meters on the GIS. In addition, we transferred the color and area scores onto a [0–20] scale. In this way, we were able to compare these scores with the two others (i.e. explicit signs and proximity to road). The global visual salience score GVis was then computed with the advance visibility score (cf. Eq. 1).


Typical route segment.
Advance Visibility Score. We computed the advance visibility score on ArcMap according to Winter’s methodology (2003). Specifically, the visibility coverage was calculated by using the Viewshed command of the 3D Analysis Toolbox. In order to obtain a precise Digital Elevation Model, we combined a Digital Terrain Model at a scale of 1:20 000 with a polygon that contained locations, shapes, and elevations of the buildings of Quebec City. For each intersection, the lines of arriving were drawn according to the virtual route segments followed by the participants (cf. Figs. 3 and 6). Moreover, we took the orientation of the signboards into account in the computation of the orientation scores of the buildings. Indeed, venues perpendicularly oriented to the direction of arriving got an orientation score of 1 when they had an adequately oriented signboard (cf. Fig. 4). The directions were automatically computed by the GIS.

Computation of the orientation score.
Semantic Salience Score. The computation of the semantic salience was done according to the authors’ previous work (cf. Quesnot and Roche 2015a). However, we applied two specific changes. On the one hand, we improved the computation of the uniqueness score by applying a gradation. Thus, venues that belong to different supra-categories (e.g. religious monuments vs shops) got a uniqueness score higher than if they were belonging to the same infra-category (cf. Eqs. 2, 3, and 4).

Indeed, even though a clothing store and a coffee store are different per se, they remain stores. By this way, these two venues are not necessarily easily distinguishable during navigation. On the contrary, a church obviously stands out from the environment if it is surrounded by shops. On the other hand, we multiplied the uniqueness score and the geosocial activity score (i.e. the significance of a place on the social web) instead of summing them. Thus, we argue that the more function of an object stands out, the more its semantic (and visual) salience increases. We also decided to compute the global semantic score GSem according to the advance visibility score. Indeed, we consider the advance visibility as a decisive supra-factor that belongs to the contextual salience rather than the visual one. In the experiment, participants had to move along predetermined paths according to a specific field view. We would not have included the advance visibility score if the participants only had to choose the landmark candidates among a set of static panoramic images (e.g. Nothegger et al. 2004). In the end, we normalized GSem in order to fit on a [0–1] scale (cf. Eq. 5). To conclude, we want to precise that we harvested data from the Foursquare API v2.0 on February 10, 2015 to perform the geosocial activity scores.

Structural Salience Score. The structural score of each potential landmark candidate was computed according to the average scores obtained from the initial survey (cf. Fig. 2). Thus, each structural salience score only varied according to the turns (i.e. left or right). We did not combined the structural score with the advance visibility score since the configuration of the cross intersections was constantly the same at the end of each predetermined route segment.
Intersections, Potential Landmark Candidates, and Their Distribution. We selected 120 potential landmarks across 30 cross intersections located in Quebec City. We determined a route segment for each decision point. Its starting point was usually the intersection that preceded the decision point (cf. Fig. 3). A major concern was to select a strong enough diversity of venues. Our primary goal was to evaluate the significance of the semantic salience according to the familiarity with the area. Thus, we first chose highly recognized local landmarks via the analysis of Foursquare check-ins (cf. Table 4). We then added other places potentially recognizable by strangers such as Subway restaurants. Specifically, we included 22 places that belong to supra-categories memorable for strangers (cf. Table 5). These global landmarks covered 18 intersections. In the end, the visual salience varied from 0.012 to 0.986 with a mean of 0.531 and a standard deviation (SD) of 0.229. The distribution of the semantic salience was less scattered with a variation that went from 0 to 1 with a mean of 0.148 and a SD of 0.181. This low variance might be directly linked to the multiplication of the uniqueness and the geosocial activity scores.

Average salience scores according to their position.
As shown in the fifth figure, position D held the highest average score for both visual and semantic saliencies. On the contrary, position B was the less significant. Also, we can see that the most significant landmarks are located before the intersection. The distribution of the candidates according to their highest and lowest salience scores highlights a link between the semantic and visual saliencies. Indeed, among all candidates, 26 % of them held the highest visual salience score and the highest semantic salience score at the same time (cf. Table 6). In addition, almost half of them gathered the lowest visual and semantic salience scores together. Actually, this relationship seems quite expectable since the major semantic landmarks were essentially buildings that met almost all of the predetermined visual criteria (e.g. restaurants, pubs, hotel, etc.). Having said that, the structural salience was not at all disadvantaged. For instance, 28.3 % of the most significant structural landmarks held the highest visual salience score at the same time. The percentage reached 30 % with the semantic salience. Finally, as highlighted in the sixth table, around three-quarters of the landmarks that have the lowest visual salience score were located after the intersection. Although this asymmetry remains significant, one must keep in mind that 43.4 % of the highly visual landmarks were also located after the intersection. To conclude, position A hosted 30 % of the major semantic landmarks (vs 20 % of the minor ones) and 33.3 % of the minor visual landmarks (vs 16.6 of the major ones). One should take those statistics into account since we also investigate the significance of the side of the road factor.
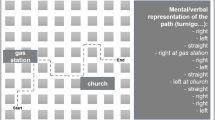
Online Experiment. Once the intersections and potential landmarks selected, we developed a web application that contained three components (cf. Fig. 6). The first one contained buttons located at the top of the webpage. By this way, users were able to manually move from an intersection to another. The second component was an HTML frame inserted at the extreme left of the webpage. This frame held a Google Form that was composed of four pages. The first page included basic information questions (age, familiarity with Quebec City, and time spent there in years). The three other pages contained questions about the landmark selection according to the turn (left or right) for each intersection (10 intersections per page). Finally, the last component was a viewport that contained a navigable Google Street View environment dynamically linked to a reducible window. We included a Google Maps base map inside this window to help participants to follow the route segment associated with each intersection. We used the Google Maps API V2 and the Street View Service to feed this viewport. We also added javascript listeners in order to ensure that participants keep the same field of view and only follow the predetermined route segments. In addition, dialog boxes appeared when users tried to move beyond those segments. We also added markers inside the environment to mark out their extremities.
3.3 Procedure
Walkthrough. After having electronically signed a consent form that explained the purpose of this experiment, participants were directed on a walkthrough page that guided them step by step in the understanding of the application.

Screenshot of the online experiment.
Basic Information. Participants had to specify basic information such as their age, their gender, their familiarity with Quebec City, and the time spent there in years for those who specified that they were familiars with the study area.
Landmark Selections. After having filled out the first sheet of the form, participants had to choose two landmarks between a set of four potential landmark candidates for each intersection. One for the left turn and another one for the right turn. Furthermore, they had to follow a predetermined route segment for each intersection. Additionally, they were also able to go back to the previous intersection and make a change if they had checked the wrong box by mistake.
3.4 Expected Results
First of all, we expect an association between the degree of familiarity and the semantic salience. Indeed, we do believe that locals will favor the main semantic landmarks we chose for this experiment. At the opposite, strangers might rely on either highly visible or highly structural landmarks. Secondly, if the side of the road factor proves to be significant, we expect that position A (see Fig. 5) will grab participants’ attention for the left turn. Finally, given the results of the survey, we do not expect any difference between women and men regarding the selection of structural landmarks.
3.5 Analysis and Results
Model. The analysis of the data collected from the experiment required the usage of a specific advanced model known as the random-parameters logit model. Indeed, using a linear regression was inconceivable since the dependent variable (i.e. the choice of the participant) was not continuous but categorical and unordered. Consequently, we needed to perform a logistic regression; i.e. a regression based on the logit function (cf. Eq. 6). Note that in this case, one do not regress a measured variable but a probability.

Since participants had to make a choice between four distinct places (i.e. alternatives = 4), the binary logit model (i.e. alternatives = 2) and ordered logit models (which suppose that the alternatives can be ordered together) were excluded. Moreover, we faced two types of regressor: case-specific (gender and familiarity) and alternative-specific (salience scores). In this context, a mixed logit model as defined by Cameron and Trivedi (2005, p. 500) - i.e. a combination of the multinomial model and the pure conditional logit model - is usually used (cf. Eq. 7).

However, using this model implies that each observation is independent from the others. Yet, we worked on longitudinal data since each participant was invited to successively select a landmark across 30 intersections. For instance, the fact that the individual i tended to systematically choose the place located at his first right for the right turn needed to be taken into consideration. We attached importance to this parameter since the participants were also able to change their answers during the experiment. In the end, we used the random-parameters logit model because it includes random coefficients that induce correlations between choices (Cameron and Trivedi 2005). According to it, the probability that an individual i choose the alternative j is defined in the following equation:
Computation of the Probabilistic Model. The model was computed in SAS 9.4 using the logistic procedure: we took the characteristics of both the alternatives (i.e. the salience scores) and the individuals (i.e. the gender and the familiarity with Quebec City) into consideration in the first computation. We then focused on the locations of the places and the turns without taking the salience scores and the individual factors into account. This second computation allowed us to (1) analyze where participants tended to choose their landmarks according to the turns, and (2) compare the results of the experiment with those of the first study.
Outputs. The results of the first and second computations are respectively summarized in Tables 7 and 8. In order to facilitate the interpretation, we used the following variable coding for the second computation:
-
SB: the place is located along the same direction as the turn, before the intersection;
-
SA: the place is located along the same direction as the turn, after the intersection;
-
OB: the place is located at the opposite direction of the turn, before the intersection;
-
OA: the place is located at the opposite direction of the turn, after the intersection.
Interpretation of the Estimated Parameters. First of all, one can notice that the coefficients of the salience scores are statistically significant with a confidence interval of 99 % (cf. Table 7). In this case, the estimated parameters should be interpreted with extreme caution. Indeed, since the scores are not computed on the same unit basis, it does not make sense to interpret the parameters relatively together. However, by paying attention to the Wald Chi-Square measure, one can notice that the visual salience is more significant than the semantic salience. In the same vein, the structural salience is less significant than the two others (12.08 vs 20.47 and 26.21). Among the six potential interactions observed, only three of them are significant (cf. Table 7). Firstly, the interaction between the semantic salience score and the familiarity (p\(\,<\,\)0.01) reveals that for equal visual and structural scores, locals are likely to choose the place with the highest semantic salience score. Secondly, the interaction between the structural salience and the gender (p\(\,<\,\)0.02) indicates that for equal visual and semantic scores, women are likely to fit the average structural profile we chose (cf. Fig. 2). Thirdly, this trend is also observed with the locals (p = 0.0411). For instance, given the computed model, the probability that a local woman choose the venue A between the set of potential landmark candidates [A,B,C,D] located along a cross intersection is:

In addition, one can see that each coefficient of Table 8 is statistically significant with the same confidence interval as the salience scores (i.e. 99 %). Specifically, the parameters tell us that the participants were likely to choose the venue located along the same direction as the turn and before the intersection; regardless of the turn. More precisely, the probability of choosing the place located before the intersection and along the same direction as the turn is 0.513 for the left turn and 0.579 for the right one. Also, the probability of selecting the place located after the intersection and still along the same direction as the turn is 0.304 for the left turn and 0.171 for the right one.
To recap, each participant, regardless of the gender and the familiarity with the area, was influenced by the visual, semantic, and structural saliencies. Unlike men, women tended to select landmarks located along the same direction as the turn. We observe the same tendency for the local participants who additionally focused on semantic landmarks.
Model Validity. The 5:1 rule of thumb consists in having at least 5 observations per explanatory variable; and ideally 10. Although this rule is sometimes called into question, following it implies to constitute an ideal sample size of 20 individuals and 30 landmark candidates. Since we worked with three times more individuals (more precisely 63) and four times more landmark candidates (120) than recommended, we estimate that the model and the parameters estimated are sufficiently reliable to draw strong conclusions.
3.6 Discussion
The findings around the semantic salience confirm our expectations. Except the fact that this salience was more significant than the structural one in the experiment (20.47 vs 12.08 Wald Chi-Square), one should notice a significant interaction with locals (p = 0.0007). In other words, locals favored significant semantic landmarks. This finding completes the recent research of Hamburger and Röser (2014). It empirically demonstrates that the semantic salience is clearly involved in the process of landmark selection. Just as the theory suggests (cf. Raubal and Winter 2002 and Caduff and Timpf 2008), this salience is also closely linked to the individual’s knowledge of the environment. Given the distribution of the landmarks (cf. Table 6), the statistics computed from the model reveal that locals focused on semantic landmarks regardless of a low visual salience. Meanwhile, the strangers rather relied on highly visible landmarks. On the other hand, one must keep in mind that we included a higher amount of local landmarks for the purpose of this experiment (cf. Tables 4 and 5). The strength of this interaction would have been lower if we had incorporated more global landmarks. Consequently, we argue that the semantic salience should be computed according to a “localness threshold”. Beyond that limit, the significance of the semantic salience for both locals and strangers might converge.
Unsurprisingly, the visual salience is the most significant score in the computed model. Indeed, wayfinding remains a process closely linked to the visual attention. Obviously, highly visible places easily grab travelers’ attention (Lynch 1960 and Davies and Peebles 2010). On the contrary, the gender difference regarding the structural salience score was unexpected. This finding has not been discovered in previous similar studies (cf. Klippel and Winter 2005 and Röser et al. 2012a; 2012b). However, it does support the global gender difference in spatial ability already highlighted in several research (see Farr et al. 2012 for an overview). In addition, the fact that locals were likely to systematically select the candidates located along the same direction as the turn can be easily explained. In our opinion, they chose to reduce their visual attention to the side of the turn. Thanks to their meaningful environment knowledge, locals were able to select two different landmarks per intersection. At the opposite, strangers rather extended their visual attention to scan each candidate and pick-up the best one for both turns when necessary. In this context, the position of the landmark seems to be less important for strangers. Nevertheless, we acknowledge that the participants had a high degree of freedom during their virtual travel. Therefore, this assumption might be valid for pedestrians but not for car drivers since they cannot look away from the road more than few seconds.
Furthermore, one can see that the positions of the landmark candidates favored during the experiment slightly differ from those of the survey. In the experiment, participants were likely to choose the candidates located before the intersection for both turns. This observation is in line with the conclusions of Röser et al. (2012a; 2012b) and Klippel and Winter (2005). However, it is not really surprising since the most significant landmarks (visual and semantic) were located before the intersection (cf. Fig. 5). Having said that, it remains important to notice that the probability of selecting a landmark candidate located along the same direction as the turn and after the intersection is quite higher for the left turn (almost twice in comparison with the right turn). Once again, this evidence suggests that the side where participants moved compared to the road interfered in their choices. Participants favored position A for the left turn whereas it hosted one-third of the lowest visible landmarks and had an average visual salience score lower than position C (cf. Fig. 5).
As stated in the previous section, each salience score is statistically significant. Thus, the methods used for the computation of the salience scores were relevant. This observation supports the authors’ proposition for the detection of local and global semantic landmarks using geosocial data (cf. Quesnot and Roche 2015a). Also, using the visual contrast between the scene and the places seems to be relevant for computing the visual salience. Since the visual and semantic salience scores were related to the advance visibility, the results also confirm its importance in the context of navigation. Having said that, one concern regarding the experiment needs to be highlighted. Indeed, participants selected landmarks by relying on both 2D (Google Maps base map) and 3D (Google Street View) media at the same time. Yet, individuals tend to adopt different route discourses according to the dimensionality of the supports (see Mast et al. 2010). Despite its optional display, the base map might have affected the participants’ landmark selection.
4 Conclusion
The main purpose of this research was to evaluate the significance of semantic landmarks according to the observer’s knowledge of the environment. The results of the experiment showed that the participants were all influenced by the visual, structural, and semantic saliencies. In addition, locals clearly favored local semantic landmarks. This empirical finding highlights the significance of the semantic salience in the landmark selection process. It also confirms that a semantic landmark should be included inside wayfinding instructions according to the traveler’s spatial knowledge. Unless the place is famous, giving to strangers instructions based on semantic landmarks does not make sense. Surprisingly, the additional findings indicate that women were more influenced by the structural salience than men. In our opinion, this specific gender difference needs to be further investigated. In the context of automatic landmark detection, one should take those results into account for giving relevant wayfinding instructions and saving data consumption at the same time. In this way, geolocated data harvested from social media - especially explicit platial data (cf. Quesnot and Roche 2015b) - should be retrieved for computing meaningful semantic salience scores. At this stage, one of the major concerns is to pick-up either local or global semantic landmarks according to the traveler’s familiarity with the area. Regarding the wayfinding instructions, it appears that the priority should be given to the visual salience for strangers; unless a well-known landmark is located at the decision point. On the other hand, the semantic salience remains more appropriate for locals. Structural salience scores should be applied if there are neither visual nor semantic outstanding landmarks. However, we believe that a qualitative characterization of the structural salience (e.g. “before the intersection”) remains more relevant than a quantitative approach. Nonetheless, this characterization should absolutely take the side where travelers move compared to the road into account. Indeed, the results also suggest that this factor impacted on participants’ selection of landmarks. In the end, it would be interesting to carry out similar studies for different types of intersection since this research only focused on cross intersections.
References
Caduff, D., Timpf, S.: On the assessment of landmark salience for human navigation. Cogn. Process. 9(4), 249–267 (2008)
Cameron, A.C., Trivedi, P.K.: Microeconometrics: Methods and Applications. Cambridge University Press, New York (2005)
Crandall, D.J., Backstrom, L., Huttenlocher, D., Kleinberg, J.: Mapping the world’s photos. In: Proceedings of the WWW 2009 Conference (2009)
Daniel, M.-P., Tom, A., Manghi, E., Denis, M.: Testing the value of route directions through navigational performance. Spat. Cogn. Comput. 3, 269–289 (2003)
Davies, C., Peebles, D.: Spaces or scenes: map-based orientation in urban environments. Spat. Cogn. Comput. 10(2–3), 135–156 (2010)
Duckham, M., Winter, S., Robinson, M.: Including landmarks in routing instructions. J. Location Based Serv. 4(1), 28–52 (2010)
Elias, B.: Extracting landmarks with data mining methods. In: Kuhn, W., Worboys, M.F., Timpf, S. (eds.) COSIT 2003. LNCS, vol. 2825, pp. 375–389. Springer, Heidelberg (2003)
Elwood, S., Goodchild, M.F., Sui, D.S.: Prospects for VGI research and the emerging fourth paradigm. In: Sui, D.S., Elwood, S., Goodchild, M.F. (eds.) Crowdsourcing Geographic Knowledge, pp. 361–375. Springer, Netherlands (2013)
Farr, A.C., Kleinschmidt, T., Yarlagadda, P., Mengersen, K.: Wayfinding: a simple concept, a complex process. Transport Reviews 32(6), 715–743 (2012)
Goodchild, M.F.: Citizens as sensors: the world of volunteered geography. GeoJournal 69(4), 211–221 (2007)
Hamburger, K., Röser, F.: The role of landmark modality and familiarity in human wayfinding. Swiss J. Psychol. 73(4), 205–213 (2014)
Klippel, A., Winter, S.: Structural salience of landmarks for route directions. In: Cohn, A.G., Mark, D.M. (eds.) COSIT 2005. LNCS, vol. 3693, pp. 347–362. Springer, Heidelberg (2005)
Lovelace, K.L., Hegarty, M., Montello, D.R.: Elements of good route directions in familiar and unfamiliar environments. In: Freksa, C., Mark, D.M. (eds.) COSIT 1999. LNCS, vol. 1661, pp. 65–82. Springer, Heidelberg (1999)
Lynch, K.: The Image of the City. MIT Press, Cambridge (1960)
Mast, V., Smeddinck, J., Strotseva, A., Tenbrink, T.: The impact of dimensionality on natural language route directions in unconstrained dialogue. In: Proceedings of the SIGDIAL 2010, pp. 99–102. Association for Computational Linguistics (2010)
Michon, P.E., Denis, M.: When and why are visual landmarks used in giving directions? In: Montello, D.R. (ed.) COSIT 2001. LNCS, vol. 2205, pp. 292–305. Springer, Heidelberg (2001)
Nothegger, C., Winter, S., Raubal, M.: Selection of salient features for route directions. Spat. Cogn. Comput. 4(2), 113–136 (2004)
Quesnot, T., Roche, S.: Measure of landmark semantic salience through geosocial data streams. ISPRS Int. J. Geo-Inf. 4(1), 1–31 (2015a)
Quesnot, T., Roche, S.: Platial or locational data? toward the characterization of social location sharing. In: Proceedings of the 48th Annual Hawaii International Conference on System Sciences, pp. 1973–1982. IEEE Computer Society Press, Washington, DC (2015b)
Raubal, M., Winter, S.: Enriching wayfinding instructions with local landmarks. In: Egenhofer, M., Mark, D.M. (eds.) GIScience 2002. LNCS, vol. 2478, pp. 243–259. Springer, Heidelberg (2002)
Richter, K.F., Winter, S.: Harvesting user-generated content for semantic spatial information: the case of landmarks in OpenStreetMap. In: Proceedings of the Surveying and Spatial Sciences Biennial Conference 2011, Wellington, NZ (2011)
Röser, F., Hamburger, K., Krumnack, A., Knauff, M.: The structural salience of landmarks: results from an on-line study and a virtual environment experiment. J. Spat. Sci. 57(1), 37–50 (2012a)
Röser, F., Krumnack, A., Hamburger, K., Knauff, M.: A four factor model of landmark salience - a new approach. In: Rußwinkel, N., Drewitz, U., Van Rijn, H., (eds.) Proceedings of the 11th International Conference on Cognitive Modeling (ICCM), Berlin, pp. 82–87 (2012b)
Siegel, A.W., White, S.H.: The development of spatial representations of large scale environments. In: Reese, W.H. (ed.) Advances in Child Development and Behavior, vol. 10. Academic Press, New York (1975)
Sorrows, M.E., Hirtle, S.C.: The nature of landmarks for real and electronic spaces. In: Freksa, C., Mark, D.M. (eds.) COSIT 1999. LNCS, vol. 1661, pp. 37–50. Springer, Heidelberg (1999)
Tezuka, T., Tanaka, K.: Landmark extraction: a web mining approach. In: Cohn, A.G., Mark, D.M. (eds.) COSIT 2005. LNCS, vol. 3693, pp. 379–396. Springer, Heidelberg (2005)
Tom, A., Denis, M.: Referring to landmark or street information in route directions: what difference does it make? In: Kuhn, W., Worboys, M.F., Timpf, S. (eds.) COSIT 2003. LNCS, vol. 2825, pp. 362–374. Springer, Heidelberg (2003)
Winter, S.: Route adaptive selection of salient features. In: Kuhn, W., Worboys, M.F., Timpf, S. (eds.) COSIT 2003. LNCS, vol. 2825, pp. 349–361. Springer, Heidelberg (2003)
Winter, S., Raubal, M., Nothegger, C.: Focalizing measures of salience for wayfinding. In: Meng, L., Reichenbacher, T., Zipf, A. (eds.) Map-based Mobile Services, pp. 125–139. Springer, Heidelberg (2005)
Acknowledgments
This research is funded by the Social Sciences and Humanities Research Council of Canada (SSHRC) through the second author’s ordinary grant, and the Geothink.ca project. We would like to thank Hélène Crépeau from the Mathematics and Statistics Department of Laval University for her help in the computation of the logit model in SAS. We also sincerely thank the anonymous reviewers for their insightful comments. They helped us to significantly improve this paper. We finally thank the Ministère de l’Energie et des Ressources Naturelles of the Quebec Province, and the Surveying and Cartography Department of Quebec City for the geographic data used for the 3D analyses.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Quesnot, T., Roche, S. (2015). Quantifying the Significance of Semantic Landmarks in Familiar and Unfamiliar Environments. In: Fabrikant, S., Raubal, M., Bertolotto, M., Davies, C., Freundschuh, S., Bell, S. (eds) Spatial Information Theory. COSIT 2015. Lecture Notes in Computer Science(), vol 9368. Springer, Cham. https://doi.org/10.1007/978-3-319-23374-1_22
Download citation
DOI: https://doi.org/10.1007/978-3-319-23374-1_22
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-23373-4
Online ISBN: 978-3-319-23374-1
eBook Packages: Computer ScienceComputer Science (R0)