
Abstract
Due to its variability, the development of wind power entails several difficulties, including wind speed forecasting. The Long Short-Term Memory (LSTM) is a particular type of recurrent network that can be used to work with sequential data, and previous works showed good empirical results. However, its training algorithm is expensive in terms of computation time. This paper proposes an efficient algorithm to train LSTM, decreasing computation time while maintaining good performance. The proposal is organized in two stages: (i) first to improve the weights output layer; (ii) next, update all weights using the original algorithm with one epoch. We used the proposed method to forecast wind speeds from 1 to 24 h ahead. Results demonstrated that our algorithm outperforms the original training algorithm, improving the efficiency and achieving better or comparable performance in terms of MAPE, MAE and RMSE.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In order to integrate wind into an electric grid it is necessary to estimate how much energy will be generated in the next few hours. Nevertheless, this task is highly complex because wind power depends on wind speed, which has a random nature. It is worth to mention that the prediction errors may increase the operating costs of the electric system, as system operators would need to use peaking generators to compensate for an unexpected interruption of the resource, as well as reducing the reliability of the system [12]. Several models have been proposed in the literature to address the problem of forecasting wind power or wind speed [7]. Among the different alternatives, machine learning models have gained popularity for achieving good results with a smaller number of restrictions in comparison with statistical models [11]. In particular, recurrent neural networks (RNN) [15] have become popular because they propose a network architecture that can process temporal sequences naturally, relating events from different time periods (with memory). However, gradient descent type methods present the vanishing gradient problem [1], which makes difficult the task of relating current events with events of the distant past, i.e., it may hurt long-term memory. An alternative to tackle this problem are Long Short-Term Memory (LSTM) networks [4], a new network architecture that changes the traditional artificial neuron (perceptron) for a memory block formed by gates and cells memories that control the flow of information. This model was compared in [9] to predict the wind speed from 1 to 24 steps ahead. Empirical results showed that LSTM are competitive in terms of accuracy against two neural networks methods. However, its training algorithm demands high computation time due to the complexity of its architecture. In this paper we propose an efficient alternative method to train LSTM; the proposed method divides the training process in two stages: First stage uses ridge regression in order to improve the weights initialization. Next, LSTM is trained to update the weights in a online fashion. The proposal will be evaluated using standard metrics [10] for the wind speed forecasting, of three geographical points of Chile. In these areas it is necessary to provide accurate forecasting in less than one hour. We consider wind speed, wind direction, ambient temperature and relative humidity as input features of the Multivariate time series. Here is the outline of the rest of the paper. In Sect. 2 we describe the LSTM model. Section 3 describes the proposed approach for training the LSTM. Next, we describe the experimental setting on which we tested the method for different data sources in Sect. 4. Finally, the last section is devoted to conclusions and future work.
2 Long Short-Term Memory
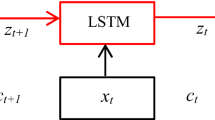
Long Short-Term Memory (LSTM) [4] is a class of recurrent network which replaces the traditional neuron in the hidden layer (perceptron) by a memory block. This block is composed of one or more memory cells and three gates for controlling the information flow passing through the blocks, by using sigmoid activation functions with range [0, 1]. Each memory cell is a self-connected unit called “Constant Error Carousel” (CEC), whose activation is the state of the cell (see Fig. 1).

LSTM architecture with 1 block and 1 cell.
All outputs on each memory block (gates, cells and block) are connected with each input of all blocks, i.e., full-connectivity among hidden units. Let \(net_{in_j}(t)\), \(net_{\varphi _j}(t)\) and \(net_{out_j}(t)\) be the weighted sum of the inputs for the input, forget and output gates, described in Eqs. (1), (3) and (7), respectively, where j indexes memory blocks. Let \(y^{in_j}(t)\), \(y^{\varphi _j}(t)\) and \(y^{out_j}(t)\) be the output on the activation functions (\(f_{in_j}(.)\), \(f_{\varphi _j}(.)\), \(f_{out_j}(.)\), logistic functions with range [0, 1]) for each gate. Let \(net_{c_j^v}(t)\) be the input for the vth CEC associated to the block j and \(s_{c_j^v}(t)\) its state at time t. Let \(y^{c_j^v}\) be the output of the vth memory cell of the jth block and \(S_j\) is the number of cells of the block j. Then, the information flow (forward pass) following the next sequence:
where \(w_{rm}\) is the weight from the unit m to the neuron r; \(y^{m}(t-1)\) is the mth input of the respective unit at time \(t-1\); g(.) and h(.) are hyperbolic tangent activation functions with range \([-2,2]\) and \([-1,1]\) respectively. For a more comprehensive study of this technique, please refer to [3].
The CEC solves the problem of vanishing (or explosion) gradient [1], since the local error back flow remains constant within the CEC (without growing or decreasing), while a new instance or external signal error does not arrive. Its training model is based on a modification of the algorithm BackPropagation Through Time [13] and a version of the Real-Time Recurrent Learning [14]. The main parameters are the block number, the number of cells of each block, and the number of input and output neurons as well. For the training process the following hyperparameters need to be defined: the activation functions, the number of iterations and the learning rate \(\alpha \in [0,1]\). This technique has shown accurate results in classification and forecasting problems. However, this method is computationally expensive. Therefore, its architecture is not scalable [8].
3 An Efficient Training for LSTM
LSTM architecture involves high computation time during the training process to find the optimal weights. And the computational training cost considerably increases when either the number of blocks or the number of cells increases.
To address the above-mentioned problem, we propose a new training method that reduces the computational cost, while maintaining its level of performance. The classical LSTM randomly initializes the weights. However, this point may be far from optimal and subsequently, the training algorithms may take more epochs to converge. To improve this particular drawback, we propose a fast method to find a better starting point in the hypothesis space by evaluating a number of instances, and using these output signals to perform a ridge regression to obtain the output layer weights. Finally, we train the LSTM in an online form.
Algorithm 1 describes our training method. It considers a network of three layers (input-hidden-output), where the hidden layer is composed by memory blocks and the output layer by simple perceptron units. Moreover, T is the length of the training series, \(n_{in}\) is the number of units of the input layer (the number of lags), \(n_h\) is the number of units in the hidden layer, \(n_o\) is the number of units of the output layer. Let Y matrix \(T \times n_o\) with the current outputs associated with each input vector.

The first stage (steps 1 to 3) of the algorithm finds a good starting point for the LSTM. In step 1 all network weights are initialized from a uniform distribution with range \([-0.5;0.5]\). Next, the matrix S, containing all memory cells outputs, is computed. Here each row of this matrix corresponds to the outputs of the units directly connected to the output layer given an input vector \(\mathbf {x}(t) = (x_1(t), \dots , x_{n_{in}}(t))\) as is described in step 2. Thus, the target estimations can be written as:
where \(W_{out}\) is a \((n_{in}+ \sum _{j=1}^{n_h} S_j)\times n_o\) matrix containing the output layer weights. Then, \(W_{out}\) can be estimated by rigde regresion, as shown in step 3, where \(S'\) is the transpose of matrix S and I is the identity matrix. In the second stage, the LSTM network is trained with a set of instances by using incremental learning, i.e., the weights are updated after receiving a new instance. Note that this approach is similar to the way that extreme learning machines (ELM) [5] adjust the weights of the output layer. This approaches is well-known because its interpolation and universal approximation capabilities [6]. In contrast, here we use this fast method just to find a reliable starting point for the network.
4 Experiments and Results
In order to assess our proposal, we use three data sets from different geographic points of Chile: Data 1, code b08, (\(22.54^{\circ }\)S, \(69.08^{\circ }\)W); Data 2, code b21, (\(22.92^{\circ }\)S, \(69.04^{\circ }\)W); and Data 3, code d02, (\(25.1^{\circ }\)S, \(69.96^{\circ }\)W). These data are provided by the Department of Geophysics of the Faculty of Physical and Mathematical Sciences of the University of Chile, commissioned by the Ministry of Energy of the Republic of ChileFootnote 1.
We worked with the hourly time series, with no missing values. The attributes considered for the study are: wind speed at 10 meters height (m / s), wind direction at 10 m height (degrees), temperature at 5 m (\({}^{\circ }\)C), and relative humidity at 5 m height. The series starting at 00:00 on December 1, 2013 to 23:00 on March 31, 2015. Each feature is scaled to \([-1,1]\) using the min-max function.
To evaluate the model accuracy, each available series is divided in \(R=10\) subsets using a 4 months sliding window approach with a shift of 500 points (20 days approximately), as depicted in Fig. 2.

Sliding window approach to evaluate model accuracy.
Then to measure the accuracy of the model, we consider the average over the subsets, computing three standard metrics [10] based on \(e_r(T+h|T) = y_r(T+h) - \hat{y}_r(T+h|T)\):
Here \(y_r(T+h)\) is the unnormalized target at time \(T+h\). T is the index of the last point, and h is the number of steps ahead; \(\hat{y}_r(T+h|T)\) is the target estimation of the model at the time \(T+h\). The forecasting of several steps ahead was made with the multi-stage approach prediction [2]. Table 1 shows the parameters tuned.
The results show that the proposed method achieves a better overall computational time for 10 runs, based in the best model that minimizes MSE for each data set. Table 2 shows the training time of the original algorithm and of our proposal (columns two and three respectively). And the remainder columns exhibit the parameters selected to train the models.
Figure 3 shows that the proposed algorithm achieves a better or comparable performance using MAPE and RMSE. The results for MAE are omitted because they show similar behavior that MAPE, but different scale. There is a important insights from these experiments, we observe that the proposed method outperformed the original model by several steps, especially for the MAPE when forecasting several steps ahead.

Data 1 (top-left), Data 2 (top-right), Data 3 (botton-left)
5 Conclusions and Future Work
This work presents an efficient training algorithm for LSTM networks. We observed that our proposed training method outperforms the original algorithm reducing by 98%, 99% and 92% the computational time for each data set. One can also notice that although our proposal uses a greater number of blocks or cells or lags, it is most efficient. Results suggests that our proposal, besides being efficient, in general achieved a better performance when forecasting several steps ahead. As future work, we would like to research how to increase the forecasting accuracy and evaluating our algorithm against other models derived from LSTM. Another interesting issue is to explore the performance of our proposal in large datasets.
References
Bengio, Y., Simard, P., Frasconi, P.: Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 5(2), 157–166 (1994)
Cheng, H., Tan, P.-N., Gao, J., Scripps, J.: Multistep-ahead time series prediction. In: Ng, W.-K., Kitsuregawa, M., Li, J., Chang, K. (eds.) PAKDD 2006. LNCS (LNAI), vol. 3918, pp. 765–774. Springer, Heidelberg (2006). doi:10.1007/11731139_89
Gers, F.: Long short-term memory in recurrent neural networks. Ph.D. thesis, École Polytechnique Fédérale de Laussanne (2001)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Huang, G., Huang, G.-B., Song, S., You, K.: Trends in extreme learning machines: a review. Neural Netw. 61, 32–48 (2015)
Huang, G.-B., Wang, D.H., Lan, Y.: Extreme learning machines: a survey. Int. J. Mach. Learn. Cybern. 2(2), 107–122 (2011)
Jung, J., Broadwater, R.P.: Current status and future advances for wind speed and power forecasting. Renew. Sustain. Energy Rev. 31, 762–777 (2014)
Krause, B., Lu, L., Murray, I., Renals, S.: On the efficiency of recurrent neural network optimization algorithms. In: NIPS Optimization for Machine Learning Workshop (2015)
López, E., Valle, C., Allende, H.: Recurrent networks for wind speed forecasting. In: IET Seminar Digest (ed.) International Conference on Pattern Recognition Systems, ICPRS 2016, vol. 2016 (2016)
Madsen, H., Pinson, P., Kariniotakis, G., Nielsen, H.A., Nielsen, T.S.: Standardizing the performance evaluation of short-term wind prediction models. Wind Eng. 29(6), 475–489 (2005)
Perera, K.S., Aung, Z., Woon, W.L.: Machine learning techniques for supporting renewable energy generation and integration: a survey. In: Woon, W.L., Aung, Z., Madnick, S. (eds.) DARE 2014. LNCS (LNAI), vol. 8817, pp. 81–96. Springer, Heidelberg (2014). doi:10.1007/978-3-319-13290-7_7
Sideratos, G., Hatziargyriou, N.D.: An advanced statistical method for wind power forecasting. IEEE Trans. Power Syst. 22(1), 258–265 (2007)
Werbos, P.J.: Backpropagation through time: what it does and how to do it. Proc. IEEE 78(10), 1550–1560 (1990)
Williams, R.J., Zipser, D.: A learning algorithm for continually running fully recurrent neural networks. Neural Comput. 1(2), 270–280 (1989)
Zimmermann, H.-G., Tietz, C., Grothmann, R.: Forecasting with recurrent neural networks: 12 tricks. In: Montavon, G., Orr, G.B., Müller, K.-R. (eds.) NN: Tricks of the Trade. LNCS, vol. 7700, pp. 687–707. Springer, Heidelberg (2012). doi:10.1007/978-3-642-35289-8_37
Acknowledgments
This work was supported in part by Research Project DGIP-UTFSM (Chile) 116.24.2 and in part by Basal Project FB 0821 and Basal Project FB0008.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
López, E., Valle, C., Allende, H., Gil, E. (2017). Efficient Training Over Long Short-Term Memory Networks for Wind Speed Forecasting. In: Beltrán-Castañón, C., Nyström, I., Famili, F. (eds) Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications. CIARP 2016. Lecture Notes in Computer Science(), vol 10125. Springer, Cham. https://doi.org/10.1007/978-3-319-52277-7_50
Download citation
DOI: https://doi.org/10.1007/978-3-319-52277-7_50
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-52276-0
Online ISBN: 978-3-319-52277-7
eBook Packages: Computer ScienceComputer Science (R0)
