
Abstract
We propose a novel framework for abnormal event detection in video that is based on deep features extracted with pre-trained convolutional neural networks (CNN). The CNN features are fed into a one-class Support Vector Machines (SVM) classifier in order to learn a model of normality from training data. We compare our approach with several state-of-the-art methods on two benchmark data sets, namely the Avenue data set and the UMN data set. The empirical results indicate that our abnormal event detection framework can reach state-of-the-art results, while running in real-time at 20 frames per second.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Abnormal event detection in video is a challenging task in computer vision, as the definition of what an abnormal event looks like depends very much on the context. For instance, a car driving by on the street is regarded as a normal event, but if the car enters a pedestrian area, this is regarded as an abnormal event. A person jogging on the beach (normal event) versus running outside from a bank (abnormal event) is another example. Although what is considered abnormal depends on the context, we can generally agree that abnormal behaviour should be represented by unexpected events that occur less often than familiar (normal) events. As it is generally impossible to find a sufficiently representative set of anomalies, the use of traditional supervised learning methods is usually ruled out. Hence, most abnormal event detection approaches [1, 4, 11, 13,14,15,16, 25, 27] learn a model of familiarity from a given training video and label events as abnormal if they deviate from the model. We approach abnormal behavior detection in a similar manner, and propose to build a model of normality by using a one-class Support Vector Machines (SVM) [20] classifier. The outliers detected by our approach will be labeled as abnormal events at test time. Although it seems straightforward to apply one-class SVM, related works have adopted different approaches, for example dictionary learning [4, 5, 7, 14, 17] or locality sensitive hashing filters [26]. Nevertheless, we show in this paper that we can achieve state-of-the-art results by using one-class SVM. Before training our normality model, we extract deep features by using convolutional neural networks (CNN) pre-trained on the ILSVRC benchmark [18]. Deep learning models reach impressive performance levels on object recognition from images [3, 9, 21, 23]. Although the features learned by CNN models are not particularly designed for computer vision tasks outside the original purpose, the knowledge embedded in the CNN features is quite general and it can easily be transferred to various tasks, for example to the task of predicting the difficulty of an image [10]. To the best of our knowledge, we are the first to transfer pre-trained CNN features to the task of abnormal behavior detection in video.
We perform abnormal event detection experiments on the Avenue [14] and the UMN [16] data sets in order to compare our approach with several state-of-the-art methods [5, 6, 14, 16, 19, 22, 26]. The empirical results on the Avenue data set indicate that our model is able to surpass the state-of-the-art methods [6, 14] for this data set. As for the UMN data set, we are able to reach state-of-the-art performance on two of the three video scenes. Although we show that we can obtain better performance by employing deeper models [9, 21, 23] for feature extraction, we choose to use the VGG-f model [3] which allows us to process the video in real-time at 20 frames per second on a standard CPU.
We organize the paper as follows. We present related work on abnormal event detection in Sect. 2. We describe our learning framework in Sect. 3. We present the abnormal event detection experiments in Sect. 4. Finally, we draw our conclusions in Sect. 5.
2 Related Work
Abnormal event detection is usually formalized as an outlier detection task [1, 4, 5, 7, 11, 13,14,15,16,17, 22, 25,26,27], in which the general approach is to learn a model of normality from training data and consider the detected outliers as abnormal events. Some abnormal event detection approaches [4, 5, 7, 14, 17] are based on learning a dictionary of normal events, and label the events not represented by the dictionary as abnormal. Other approaches have employed deep features [25] or locality sensitive hashing filters [26] to achieve better results.
Interestingly, there have been some approaches that employ unsupervised steps for abnormal event detection [7, 17, 22, 25]. The approach presented in [7] is to build a model of familiar events from training data and incrementally update the model in an unsupervised manner as new patterns are observed in the test data. In similar fashion, Sun et al. [22] train a Growing Neural Gas model starting from training videos and continue the training process as they analyze the test videos for anomaly detection. Ren et al. [17] use an unsupervised approach, spectral clustering, to build a dictionary of atoms, each representing one type of normal behavior. Their approach requires training videos of normal events to construct the dictionary. Xu et al. [25] use Stacked Denoising Auto-Encoders to learn deep feature representations in a unsupervised way. However, they still employ multiple one-class SVM models to predict the anomaly scores. The approach proposed in [6] is to detect changes on a sequence of data from the video to see which frames are distinguishable from all the previous frames. As the authors want to build an approach independent of temporal ordering, they create shuffles of the data by permuting the frames before running each instance of the change detection. As we employ pre-trained CNN features, our feature extraction step is also unsupervised with respect to the approached task.
3 Method
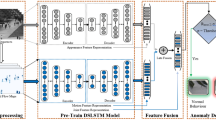
3.1 Feature Extraction
In many computer vision tasks, higher level features, such as the ones learned with convolutional neural networks (CNN) [12] are the most effective. To build our appearance features, we consider a pre-trained CNN architecture able to process the frames as fast as possible, namely VGG-f [3]. Considering that we want our detection framework to work in real-time on a standard desktop computer, not equipped with expensive GPU, the VGG-f [3] is an excellent choice as it can process about 20 frames per second on CPU. We hereby note that better anomaly detection performance can be achieved by employing deeper CNN architectures, such as VGG-verydeep [21], GoogLeNet [23] or ResNet [9].
The VGG-f model is trained on the ILSVRC benchmark [18]. We use the pre-trained CNN model to extract deep features as follows. Given the input video, we resize the frames to \(224 \times 224\) pixels. We then subtract the mean imagine from each frame and provide it as input to the VGG-f model. We remove the fully-connected layers (identified as fc6, fc7 and softmax) and consider the activation maps of the last convolutional layer (conv5) as appearance features. While the fully-connected layers are adapted for object recognition, the last convolutional layer contains valuable appearance and pose information which is more useful for our anomaly detection task. Ideally, we would like to have at least slightly different representations for a person walking versus a person running. Interestingly, Feichtenhofer et al. [8] have also found that the conv5 features are more suitable for action recognition in video, a task closely related to ours.
Finally, we reshape each activation map into an 169 dimensional vector and concatenate the vectors corresponding to the 256 filters of the conv5 layer into a single feature vector of 43264 (\(13 \times 13 \times 256\)) components. The resulted feature vectors are normalized using the \(L_2\)-norm. It is important to note that unlike other approaches [4, 25], we apply the same steps in order to extract features from video, irrespective of the data set.
3.2 Learning Model
We use the one-class SVM approach of Schölkopf et al. [20] to detect abnormal events in video. The training data in our case is composed of a few videos representing only normal events. We consider each video frame as an individual and independent sample, disregarding the temporal relations between video frames. Let \(\mathcal {X} = \{ x_1, x_2, \ldots ,x_n \,|\, x_i \in \mathbb {R}^m\}\) denote the set of training frames. In this formulation, our one-class SVM model will learn to separate a small region capturing most of the normal frames from the rest of feature space, by maximizing the distance from the separating hyperplane to the origin. This results in a binary classification function g which captures regions in the input space where the probability density of normal events lives:
where x is a test frame that needs to be classified either as normal or abnormal, \(x_i \in \mathcal {X}\) is a training frame, k is a kernel function, \(\alpha _i\) are the weights assigned to the support vectors \(x_i\), and \(\rho \) is the distance from the hyperplane to the origin. If we desire a score reflecting the abnormality level of a frame, we can simply remove the (sign) transfer function from Eq. (1). The coefficients \(\alpha _i\) are found as the solution of the dual problem:
where \(\nu \in [0,1]\) is a regularization parameter that controls the percentage of outliers to be excluded by the learned model. As noted by Schölkopf et al. [20], the offset \(\rho \) can be recovered by exploiting that for any \(\alpha _i\) that is not at the lower or upper bound, the corresponding sample \(x_i\) satisfies:
Since we already represent the frames in a high dimensional space (\(m = 43264\)) by extracting CNN features, we no longer have to embed the samples into a higher dimensional space. Hence, we decide to use the linear kernel function in our one-class SVM model, which corresponds to the feature map \(\phi (x) = x\):
4 Experiments
4.1 Data Sets
We show abnormal event detection results on two benchmark data sets.
Avenue. We first consider the Avenue data set [14], which contains 16 training and 21 test videos. In total, there are 15328 frames in the training set and 15324 frames in the test set. Each frame is \(640 \times 360\) pixels. Locations of anomalies are annotated in ground truth pixel-level masks for each frame in the testing videos.
UMN. The UMN Unusual Crowd Activity data set [16] consists of three different crowded scenes, each with 1453, 4144, and 2144 frames, respectively. The resolution of each frame is \(320 \times 240\) pixels. In the normal settings people walk around in the scene, and the abnormal behavior is defined as people running in all directions. As in [5], we use the first 400 frames in each scene for training.
4.2 Evaluation
We employ ROC curves and the corresponding area under the curve (AUC) as the evaluation metric, computed with respect to ground truth frame-level annotations, and, when available (only for the Avenue data set), pixel-level annotations. We define the frame-level and pixel-level AUC as in previous works [5, 6, 14, 15]. At the frame-level, a frame is considered a correct detection if it contains at least one abnormal pixel. At the pixel-level, the corresponding frame is considered as being correctly detected if more than \(40\%\) of truly anomalous pixels are detected. We use the same approach as [6, 14] to compute the pixel-level AUC. The approach consists of resizing each frame to \(160 \times 120\) pixels, and uniformly partitioning each frame to a set of non-overlapping \(10 \times 10\) patches. Corresponding patches in 5 consecutive frames are stacked together to form a spatio-temporal cube, each with resolution \(10 \times 10 \times 5\). We remove the cubes with less than 5 non-zero values as [6, 14]. The frame-level scores produced by our framework are assigned to the remaining spatio-temporal cubes. The results are smoothed with the same filter useb by [6, 14] in order to obtain our final pixel-level detections.
Although many works [5, 7, 14, 15, 25, 26] include the Equal Error Rate (EER) as evaluation metric, we agree with [6] that metrics such as the EER can be misleading in a realistic anomaly detection setting, in which abnormal events are expected to be very rare. Thus, we do not use the EER in our evaluation.
4.3 Implementation Details
We extract deep appearance features from the training and the test video sequences. We consider the pre-trained VGG-f [3] and VGG-verydeep [21] models provided in MatConvNet [24]. To learn a model of normality, we employ the one-class SVM implementation from LibSVM [2]. In all the experiments, we set the regularization parameter of one-class SVM to 0.2, which means that the model will have to single out \(80\%\) of the training frames as normal (the other \(20\%\) are outliers). Setting such a high value for the regularization parameter ensures that our model will not overfit the training data.
In Table 1, we present preliminary results on the Avenue data set to provide empirical evidence in favor of the CNN features that we choose for the subsequent experiments. The results indicate that better performance can be obtained with the conv5 features rather than the fc6 or fc7 features. For the speed evaluation, we measure the time required to extract features and to predict the anomaly scores on a computer with Intel Core i7 2.3 GHz processor and 8 GB of RAM using a single core. We present the number of frames per second (FPS) in Table 1. Although, we are able to report better results with the VGG-verydeep [21] architecture, we choose the shallower VGG-f [3] architecture for the rest of the experiments, as its processing time is about 10 times shorter. Using a single core, our final model is able to process the test videos in real-time at nearly 20 FPS.
4.4 Results on the Avenue Data Set
We first compare our abnormal behavior detection framework based on deep features with two state-of-the-art approaches [6, 14]. The frame-level and pixel-level AUC metrics computed on the Avenue data set are presented in Table 2. Compared to the method of Del Giorno et al. [6], our framework yields an improvement of \(6.3\%\), in terms of frame-level AUC, and an improvement of \(2.5\%\), in terms of pixel-level AUC. We also obtain better results than Lu et al. [14], as our framework gains \(3.7\%\) in terms of frame-level AUC and \(0.6\%\) in terms of pixel-level AUC. Overall, our method is able to surpass the performance of both state-of-the-art methods.

Frame-level anomaly detection scores (between 0 and 1) provided by our framework for test video 4 in the Avenue data set. The video has 947 frames. Ground-truth abnormal events are represented in cyan, and our scores are illustrated in red. Best viewed in color.
Figure 1 illustrates the frame-level anomaly scores, for test video 4 in the Avenue data set, produced by our framework based on VGG-f features and one-class SVM. According to the ground-truth anomaly labels, there are two abnormal events in this video. In Fig. 1, we notice that our scores correlate well to the ground-truth labels, and we can easily identify both abnormal events by setting a threshold of around 0.4, without including any false positive detections.

True positive (top row) versus false positive (bottom row) detections of our framework based on VGG-f features and one-class SVM. Examples are selected from the Avenue data set. Best viewed in color.
We show some examples of true positive and false positive detections in Fig. 2. The true positive abnormal events are a person throwing an object and a person running, while false positive detections are two persons walking synchronously and a person carrying a backpack.

Frame-level anomaly detection scores (between 0 and 1) provided by our framework for the second scene in the UMN data set. The test sequence has 3854 frames. Ground-truth abnormal events are represented in cyan, and our scores are illustrated in red. Best viewed in color.
4.5 Results on the UMN Data Set
On the UMN data set, we compare our framework with several supervised methods [5, 16, 19, 22, 26]. In Table 3, we present the frame-level AUC score for each individual scene, as well as the average score for all the three scenes. On the first scene and the last scene, the performance of our one-class SVM framework based on deep features is on par with the state-of-the-art approaches. For the third scene, we are able to surpass the performance reported by [5, 26]. However, we obtain a much lower performance for the second scene, perhaps due the significant illumination changes in this scene. Our approach yields an overall frame-level AUC of \(97.1\%\), which represents an improvement of \(1.1\%\) over the approach of Mehran et al. [16]. However, the best approach [22] on the UMN data set is nearly \(2.6\%\) better than our approach.

True positive (top row) versus false positive (bottom row) detections of our framework based on VGG-f features and one-class SVM. Examples are selected from the second scene of the UMN data set. Best viewed in color.
As illustrated in Fig. 3, our approach is able to correctly identify the abnormal events in the second scene without any false positives, by applying a threshold of around 0.4. However, our approach does not detect the abnormal events right from the beginning. We believe that the changes in illumination when people enter the room have a negative impact on our approach. These observations are also applicable when we analyze the false positive detections presented in Fig. 4. Indeed, the example in the bottom right corner of Fig. 4 illustrates that our method triggers a false detection when a significant amount of light enters the room as the door opens. The true positive examples in Fig. 4 represent people running around in all directions.
5 Conclusion and Future Work
In this work, we have proposed a novel framework for abnormal event detection in video that is based on extracting deep features from pre-trained CNN models, and on using one-class SVM to learn a model of normality. We have conducted abnormal event detection experiments on two data sets in order to compare our approach with several state-of-the-art approaches [5, 6, 14, 16, 19, 22, 26]. The empirical results indicate that our approach gives better performance than some of these approaches [6, 14, 16], while processing the video online at 20 FPS.
Although our model can reach very good results, it completely disregards motion information and the temporal structure in video. In future work, we aim to improve our performance by including motion features into our framework. One possible approach would be to employ convolutional two-stream networks [8] to extract both motion and appearance features. We also aim to evaluate our framework on other data sets.
References
Antic, B., Ommer, B.: Video parsing for abnormality detection. In: Proceedings of ICCV, pp. 2415–2422 (2011)
Chang, C.C., Lin, C.J.: LibSVM: a library for support vector machines. ACM Trans. Intell. Syst. Technol. 2, 27:1–27:27 (2011). Software available at. http://www.csie.ntu.edu.tw/cjlin/libsvm
Chatfield, K., Simonyan, K., Vedaldi, A., Zisserman, A.: Return of the devil in the details: delving deep into convolutional nets. In: Proceedings of BMVC (2014)
Cheng, K.W., Chen, Y.T., Fang, W.H.: Video anomaly detection and localization using hierarchical feature representation and Gaussian process regression. In: Proceedings of CVPR, pp. 2909–2917 (2015)
Cong, Y., Yuan, J., Liu, J.: Sparse reconstruction cost for abnormal event detection. In: Proceedings of CVPR, pp. 3449–3456 (2011)
Del Giorno, A., Bagnell, J.A., Hebert, M.: A discriminative framework for anomaly detection in large videos. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9909, pp. 334–349. Springer, Cham (2016). doi:10.1007/978-3-319-46454-1_21
Dutta, J.K., Banerjee, B.: Online detection of abnormal events using incremental coding length. In: Proceedings of AAAI, pp. 3755–3761 (2015)
Feichtenhofer, C., Pinz, A., Zisserman, A.: Convolutional two-stream network fusion for video action recognition. In: Proceedings of CVPR, pp. 1933–1941 (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of CVPR, pp. 770–778, June 2016
Ionescu, R.T., Alexe, B., Leordeanu, M., Popescu, M., Papadopoulos, D., Ferrari, V.: How hard can it be? Estimating the difficulty of visual search in an image. In: Proceedings of CVPR, pp. 2157–2166, June 2016
Kim, J., Grauman, K.: Observe locally, infer globally: a space-time MRF for detecting abnormal activities with incremental updates. In: Proceedings of CVPR, pp. 2921–2928 (2009)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. In: Proceedings of NIPS, pp. 1106–1114 (2012)
Li, W., Mahadevan, V., Vasconcelos, N.: Anomaly detection and localization in crowded scenes. IEEE Trans. Pattern Anal. Mach. Intell. 36(1), 18–32 (2014)
Lu, C., Shi, J., Jia, J.: Abnormal event detection at 150 FPS in MATLAB. In: Proceedings of ICCV, pp. 2720–2727 (2013)
Mahadevan, V., Li, W.X., Bhalodia, V., Vasconcelos, N.: Anomaly detection in crowded scenes. In: Proceedings of CVPR, pp. 1975–1981 (2010)
Mehran, R., Oyama, A., Shah, M.: Abnormal crowd behavior detection using social force model. In: Proceedings of CVPR, pp. 935–942 (2009)
Ren, H., Liu, W., Olsen, S.I., Escalera, S., Moeslund, T.B.: Unsupervised behavior-specific dictionary learning for abnormal event detection. In: Proceedings of BMVC, pp. 28.1–28.13 (2015)
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Fei-Fei, L.: ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 115(3), 211–252 (2015)
Saligrama, V., Chen, Z.: Video anomaly detection based on local statistical aggregates. In: Proceedings of CVPR, pp. 2112–2119 (2012)
Schölkopf, B., Platt, J.C., Shawe-Taylor, J.C., Smola, A.J., Williamson, R.C.: Estimating the support of a high-dimensional distribution. Neural Comput. 13(7), 1443–1471 (2001)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: Proceedings of ICLR (2014)
Sun, Q., Liu, H., Harada, T.: Online growing neural gas for anomaly detection in changing surveillance scenes. Pattern Recogn. 64(C), 187–201 (2017)
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In: Proceedings of CVPR, pp. 1–9 (2015)
Vedaldi, A., Lenc, K.: MatConvNet - convolutional neural networks for MATLAB. In: Proceeding of ACMMM (2015)
Xu, D., Ricci, E., Yan, Y., Song, J., Sebe, N.: Learning deep representations of appearance and motion for anomalous event detection. In: Proceedings of BMVC, pp. 8.1–8.12 (2015)
Zhang, Y., Lu, H., Zhang, L., Ruan, X., Sakai, S.: Video anomaly detection based on locality sensitive hashing filters. Pattern Recogn. 59, 302–311 (2016)
Zhao, B., Fei-Fei, L., Xing, E.P.: Online detection of unusual events in videos via dynamic sparse coding. In: Proceedings of CVPR, pp. 3313–3320 (2011)
Acknowledgments
We thank reviewers for their helpful comments. This research is supported by University of Bucharest, Faculty of Mathematics and Computer Science, through the 2017 Mobility Fund, and by SecurifAI through Project P/38/185 funded under the Competitiveness Operational Programme POC-A1-A1.1.1-C-2015.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Smeureanu, S., Ionescu, R.T., Popescu, M., Alexe, B. (2017). Deep Appearance Features for Abnormal Behavior Detection in Video. In: Battiato, S., Gallo, G., Schettini, R., Stanco, F. (eds) Image Analysis and Processing - ICIAP 2017 . ICIAP 2017. Lecture Notes in Computer Science(), vol 10485. Springer, Cham. https://doi.org/10.1007/978-3-319-68548-9_70
Download citation
DOI: https://doi.org/10.1007/978-3-319-68548-9_70
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-68547-2
Online ISBN: 978-3-319-68548-9
eBook Packages: Computer ScienceComputer Science (R0)
