
Abstract
Facial expressions provide important indications about human emotions. The development of an automatic emotion recognition method is a challenging task and has applications in several domains of knowledge, such as behavior prediction, pattern recognition, entertainment, interpersonal relations and human-computer interactions. An automatic approach to emotion recognition based on facial expressions robust to occlusions is proposed and evaluated in this work. Robust Principal Component Analysis is employed to reconstruct the occluded facial expressions. Facial expressions are extracted through different features (Gabor Filters, Local Binary Patterns and Histogram of Oriented Gradients), which are used to recognize the expressions by Support Vector Machine (SVM) and K-Nearest Neighbor (KNN) classifiers. Experiments conducted on three public datasets demonstrate the effectiveness of the proposed methodology.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
- Emotion recognition
- Facial expression
- Occluded images
- Facial features
- Pattern recognition
- Image classification
1 Introduction
Emotions can be expressed by means of different forms, for instance, body gestures, speech, cardiac rhythm, respiration, and facial expressions [16]. Facial expressions allow humans to express emotions in an effective and natural non-verbal communication.
Automatic recognition of human emotion plays an important role for research on affective computing and has been recently investigated in several applications, such as entertainment, human-computer interactions, behavior prediction, security, among others. The universality hypothesis considers that there are seven basic human facial expressions of emotions (anger, disgust, contempt, fear, happiness, sadness and surprise) expressed through similar facial movements independent on culture, age and gender.
The recognition of facial expressions can be classified into two main categories: sequence-based and frame-based. Frame-based approaches identify facial expressions from a single image, whereas sequence-based recognition employs temporal information over several images [16], such as head movement, skin color variation, facial muscle movement, among other factors.
Automatic recognition systems of facial expression commonly involve three major stages: (i) facial detection, (ii) facial expression feature extraction and representation, (iii) and expression recognition [16]. Most of the existing systems do not deal with faces occluded, for instance, by sunglasses, hat, scarf, hands and beard during the training process, which could affect the facial expression recognition accuracy.
As main contribution of this work, a facial expression recognition approach robust to occlusions composed of five main stages is proposed in this work. The first step aims to perform the reconstruction of the facial expression under occlusion based on the Dual Algorithm using Robust Principal Component Analysis (RPCA) principles. The second one involves the automatic detection of facial fiducial points. The third stage extracts three types of features: Gabor Filters, Local Binary Patterns and Histogram of Oriented Gradients. The fourth step performs a dimensionality reduction through Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA). The latter stage is focused on occluded and non-occluded facial expression recognition, using Support Vector Machine (SVM) and K-Nearest Neighbor (KNN) classifiers. The proposed methodology was evaluated on three facial expression databases: Cohn-Kanade (CK+) [10], Japanese Female Facial Expression (JAFFE) [11] and MUG Facial Expression [1] datasets.
Facial occlusions can deteriorate significantly the performance of a facial expression recognition system. Despite being a challenging problem, our methodology was able to achieve high recognition accuracy rates for both occluded and non-occluded images on the evaluated datasets. The results obtained with our method were compared against other approaches available in the literature.
The remainder of the paper is structured as follows. Section 2 describes relevant work related to the topic under investigation. Section 3 presents the methodology proposed in this work, including details on preprocessing, facial expression reconstruction, facial feature extraction, feature reduction and facial expression classification. Experiments conducted on three public datasets are described and discussed in Sect. 4. Finally, conclusions and directions for future research are presented in Sect. 5.
2 Related Work
Some approaches of the literature have explored the problem of emotion recognition under the presence of partial obstruction (sunglasses, shadows, scarves, facial hair, lights), since occlusion is frequent in real-world scenarios.
Bourel et al. [3] proposed a method for facial expression recognition with occlusions of mouth, upper face and left/right half of the face from video frames, based on a localized representation of facial expression features and on data fusion. For tracking and recovering facial fiducial points, an enhanced Kanade-Lucas tracker was used. Independent local spatio-temporal vectors were created from geometrical relations between facial fiducial points. Local rank-weighted KNN classifiers were employed in the classification step. Bourel et al. [4] also presented a technique for facial expression recognition robust to partial facial occlusions and noisy data from image sequences, based on a state-based feature model of spatially-localized facial dynamics, that consists in a scalar quantization of the temporal evolution of geometric facial features.
Towner and Slater [14] described three techniques based on PCA to recover the positions of the upper and lower facial fiducial points. The results showed that more facial expression information is contained in the lower half of the face, being less accurately the reconstruction of that part of the face. Zhang et al. [15] proposed a method robust to occlusions using a Monte Carlo algorithm to extract a set of Gabor based templates from image datasets, then template matching is applied to find the most similar features located within a space around the extracted templates, generating features robust to occlusion. This approach conducted experiments on the Cohn-Kanade (CK) [7] and the Japanese Female Facial Expression (JAFFE) [11] datasets by considering different occluded facial regions, for instance, eyes, mouth, randomized patches of different sizes, and transparent and solid glasses. Results showed that the method is robust to eyes or mouth occlusions, achieving accuracy rates of 95.1% (eye occlusion) and 90.80% (mouth occlusion) for CK dataset; and 80.30% (eye occlusion) and 78.40% (mouth occlusion) for JAFFE dataset. However, by randomly applying occluded patches over faces in both training and testing phases (matched strategy), this approach obtained 75.00% and 48.80% recognition rates for CK and JAFFE databases, respectively.
There are other techniques that focus on reconstructing texture appearance features. Mao et al. [12] proposed an approach to robust facial expression recognition. Initially, occlusions were detected using RPCA algorithm and saliency detection. Occluded regions were filled by RPCA projection and a reweighted AdaBoost algorithm was used for classification. The method was trained and tested on both the Beihang University Facial Expression (BHUFE) and JAFFE databases, performing experiments with hand, hair and sunglasses occlusions separately, achieving accuracy rates of 59.30%, 84.80% and 68.80% respectively.
Jiang and Jia [6] performed several experiments considering eye and mouth occlusions separately, where occluded facial regions were reconstructed through PCA, Probabilistic PCA, RPCA, Dual and Augmented Lagrange Multiplier (ALM) algorithms. Eigenfaces and Fisherfaces algorithms were then used for feature extraction, whereas KNN and SVM classifiers were employed in the classification stage. The accuracy rates for eye and mouth occlusions were not superior to 76.57% and 72.73%, respectively.
Kotsia et al. [8] presented an analysis of partial occlusion effect on facial expression recognition. It was concluded that occlusions on the left/right side of the face did not affect recognition rates, i.e., that both regions contained less discriminant information for facial expression recognition. Furthermore, mouth occlusion caused a higher decrease in facial expression recognition performance than eye occlusion, because mouth occlusion affected more the emotions of anger, fear, happiness and sadness, whereas eye occlusion affected disgust and surprise. Experiments were conducted on Cohn-Kanade [7] and JAFFE [11] databases, using Gabor wavelets and Discriminant Non-negative Matrix Factorization (DNMF) algorithm for feature extraction and SVM classifier.
Zhang et al. [15] also performed an analysis on the effects of occlusions for both matched and mis-matched train and test strategies. Their method did not learn very well the sample patterns to reduce the effect of randomized patch occlusion, which followed the mis-matched strategy, i.e., using non-occluded images for training and partial occluded images for testing. Thus, recognition rates were worse than following the matched strategy. Furthermore, it was concluded that occluded facial expression recognition performance depends on the occluded region size. It was recommend to use the same type of occlusions during training phase as that expected to be present in tested samples.
Moore and Bowden [13] presented an analysis on the effects of head poses and multi-view on facial expression recognition through variations of Local Binary Patterns (LBP) and Local Gabor Binary Patterns (LGBP) for feature extraction. Experiments conducted on the BU3DFE database showed that frontal view was optimal for facial expression recognition. However, some emotions, such as sadness and anger, performed better at non-frontal views.
3 Methodology
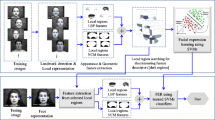
The proposed facial expression recognition methodology with occlusions is described in this section. The main steps of the method are illustrated in Fig. 1 and detailed as follows.

Diagram of the facial expression recognition methodology.
3.1 Preprocessing
The image preprocessing step is fundamental to the expression recognition task, whose main objective is to generate randomized occluded facial expression images with aligned faces, as well as uniform shape and size. This stage is primordial toward the success of facial expression recognition.
Initially, we perform an automatic fiducial point detection over all facial expression image sets with Chehra Face and Eyes Tracking Software [2], which is a fully automatic system that tracks 49 facial landmark points and 10 eye fiducial points. Each facial expression image is aligned according to the left eye and right eye coordinates.
For each image dataset, we scale all images proportionally to the minimum distance between eye coordinates. Facial expression regions are cropped through a proper rectangle. Color images are converted into grayscale images. Finally, randomized black rectangles are applied over different facial expression regions, including bottom left side of the face, bottom right side of the face or bottom side of the face, left eye, right eye and two eyes, to simulate occlusions.
3.2 Facial Expression Reconstruction
The PCA technique is commonly used to reduce high-dimensional feature spaces into more compact descriptors. However, PCA does not operate well under corrupted observations, for instance, variations of facial expressions, occluded faces, image noise, illumination problems, among others. On the other hand, RPCA, an extension of the PCA technique, has demonstrated to be robust to outliers and missing data.
We applied the RPCA algorithm using 150 iterations and \(\lambda \) selected as follows
where m and n are the dimensions of a matrix D.
Following the facial expression reconstruction procedure, all images of testing set are projected onto the space created by RPCA. Thereby, we fill all occluded facial expression regions with the reconstructed faces from both training and testing sets.
Furthermore, a contrast-limit adaptive histogram equalization (CLAHE) is applied over the reconstructed facial expressions regions in order to enhance sharpness and contrast levels of images. This helps to improve the precision of the facial fiducial point detection and accuracy of the occluded facial expression recognition.
3.3 Facial Feature Extraction
Three feature extraction strategies - Gabor Filters, Local Binary Patterns (LBP) and Histogram of Oriented Gradients (HOG) - are used for occluded facial expression recognition.
Gabor wavelet filters are employed to convolve 22 facial expression regions of 15\(\times \)15 pixels. These regions are located around 22 facial fiducial points: six points for the corners and middle of the eyebrows (1–6); eight points for the corners and middle of the borders of the eyes (7–14); four points for the superior and inferior side of the nose (15–18); and four points for the left, right, superior and inferior border of the mouth (19–22). After executing several experiments with different Gabor wavelet parameters, we select to work with a 20 Gabor wavelet kernel set, using 5 scales (\(v=\{0, 1 ,2, 3, 4\}\)) and 4 orientations (\(\mu =\{1, 2, 3, 4\}\)), with \(\sigma = k_{\max } = \pi \), and \(f=\sqrt{2}\). For each convolved region, we divide it into 9 (= 3\(\times \)3) blocks of 5\(\times \)5 pixels. For each of these equivalent blocks, we extracted the mean and standard deviation. These two measures are concatenated to form the feature vector. Hence, the generated feature vector has a length of 7920 (= 2\(\times \)9\(\times \)20\(\times \)22).
LBP is applied over the entire facial expression image for extracting the LBP code for each pixel. After generating an LBP labeled image and performing several experiments, we decide to divide the facial expression image into 63 (= 7\(\times \)9) regions. For each facial expression region, we extracted LBP histograms and concatenated all of them into one with length of 16128 (= 256\(\times \)63). The generated LBP histograms describe local texture and global shape information of the facial expression image.
We extract HOG features using the following parameter set: block size (bs) = 2 \(\times \) 2, cell size (cs) = 8 \(\times \) 8, block overlap (bo) = 1 \(\times \) 1, bin number (bn) = 9, and block normalization (bn) = L2. The HOG feature vector encodes local shape information from regions within an image. The length N of the feature vector for an image I is expressed as
where size(.) is the matrix dimension.
3.4 Feature Reduction
Once the feature vector is obtained, it is simplified by applying feature dimensionality reduction techniques. This process modifies the data representation, such that the new set of features presents a smaller number of dimensions compared to the original representation, while maintaining the most representative features.
Two approaches were considered to perform feature reduction: PCA and PCA+LDA. First, PCA is applied to each feature vector set - Gabor, LBP and HOG - independently, obtaining principal (feature) vectors. Similarly, PCA is applied over the combination of feature vectors. Additionally, LDA is employed over the PCA reduced feature vectors, generating new reduced feature spaces.
3.5 Classification
SVM and KNN classifiers were employed to compare the occluded and non-occluded facial expression recognition rates. This process requires stages for training and testing, such that we selected 80% of image data for training and the remaining 20% for testing.
We established estimation models based on SVM and KNN, which are trained from the reduced training feature vectors. Thus, using reduced testing feature vectors, we performed SVM and KNN multiclass classification based on the trained SVM and KNN models. Afterwards, we obtain the recognition results to assess the accuracy.
Along this process, we used different feature combination sets, considering Gabor, LBP and HOG features, whose dimensionality was reduced before the training and testing stages.
4 Results
Experiments were conducted on three datasets to evaluate the proposed methodology: the Cohn-Kanade (CK+) [10] dataset, the Japanese Female Facial Expression (JAFFE) [11] dataset and the MUG Facial Expression dataset [1].
The CK [10] dataset is available in two versions, such that we used the second one (CK+). The difference between these two versions is that the second one contains posed and non-posed (spontaneous) expressions and different metadata types. The CK+ dataset consists of 593 sequences of labeled face images from 123 subjects, categorized into one of seven facial expressions: anger, disgust, contempt, happy, fear, surprise and sadness. Each image sequence incorporates the neutral expression to generate a facial expression. The CK+ is a comprehensive set that also includes some metadata, such as 68 facial fiducial points [10].
The JAFFE dataset is composed of 213 images performed by 10 Japanese female models, labeled as one of seven facial expressions: anger, disgust, fear, happiness, neutral, sadness and surprise [11].
The MUG dataset is an image sequence collection of 86 subjects performing seven facial expressions as the JAFFE database, without occlusions. The MUG database also offers 80 facial landmarks [1].
For each of the three datasets, we randomly select 80% of samples of each class for the training set, whereas the remaining 20% for the testing set. Moreover, 50% of the training set samples of each class are occluded and a similar procedure is performed to the testing set. We set 20 different randomized images of occluded and non-occluded data to conduct experiments on each dataset.
For each occluded and non-occluded image collection, we perform experiments using each strategy shown in Fig. 1, that is, Gabor Filters, Local Binary Patterns (LBP) and Histogram of Oriented Gradients (HOG) through four proposed classification schemes: PCA+KNN, PCA+LDA+KNN, PCA+SVM and PCA+LDA+SVM. The results are presented in Tables 1 and 2, whose values correspond to the average facial expression recognition accuracy, after executing 20 experiments on both randomized training and testing collections.
From our experiments with occlusions, it is important to state that RPCA was always applied to facial reconstruction independently of the evaluated feature reduction and classification methods. From Table 1, we can observe that the recognition accuracy rate for non-occluded images using Gabor wavelets is generally slightly better than other features, except for the JAFFE database, where HOG is slightly superior. On the other hand, we can see from Table 2 that a recognition rate of occluded collections using LBP and HOG features, independently, is much better than using Gabor filters.
From the experiments on both occluded and non-occluded collections, we can observe that the PCA+LDA approach achieves higher accuracy rate than just using PCA. Furthermore, it is possible to see that, in some cases, there is no significant difference between the non-occluded and occluded facial expression recognition rates using LBP and HOG features. However, when using Gabor filters, there is a difference of approximately 10% between the recognition rates of non-occluded and occluded collections.
High non-occluded facial expression recognition accuracy rates using Gabor filters were achieved due to an accurate fiducial point detection. On the other hand, the results achieved through HOG features for non-occluded and occluded collections were competitive since there was not much image background suppression. This allowed to encode local information, such as shape. Moreover, facial reconstruction for occluded sets influenced positively in the occluded accuracy rate.
It is also important to mention that the results achieved with LBP features are due to the use of PCA approach that allows to select the most relevant features, instead of assigning different weights to each LBP sub-region. We also conducted experiments by combining Gabor, LBP and HOG features, however, the obtained results did not contribute to a significant improvement in terms of recognition accuracy rate.
We compared our method to others available in the literature that apply random partial occlusions to faces in both training and testing phases. Table 3 shows a comparision of the results. There are only few similar works that consider occlusions in the training stage. It can be observed that our method achieves the best results for CK+ and JAFFE datasets, not only for occluded images, but also for non-occluded images.
Table 3 is sorted in descending order by accuracy rate for recognition with occlusion. Some approaches adopt different protocols on the same data and employ specific preprocessing stages to the data, such as alignment or cropping of the images, feature normalization and illumination adjustments. Besides being used to reconstruct occluded facial expressions, it is possible to observe that our method achieves good results for non-occluded images.
We also conducted experiments with the combination of LBP, HOG and Gabor descriptors. For CK+ dataset, the accuracy rate had an improvement in terms of recognition accuracy rate to 90.00% for the occluded images with PCA+LDA+KNN. For JAFFE and MUG datasets, the combination of the descriptors produced results equivalent to the application of each descriptor individually.
5 Conclusions and Future Work
This work described and evaluated an emotion recognition method using facial expressions robust to occlusions. Facial reconstruction was performed by Robust Principal Component Analysis (RPCA). Different features were applied over the reconstructed facial expression images and the resulting feature vector was reduced through a number of techniques, allowing high accuracy rates of facial expression recognition. Experiments were conducted on three public datasets to evaluate the effectiveness of the proposed methodology.
As directions for future work, we intend to investigate new facial fiducial point sets, the use of different features, as well as better facial reconstruction parameters. Additionally, we plan to conduct experiments using dynamic features for facial expression recognition in video scenes.
References
Aifanti, N., Papachristou, C., Delopoulos, A.: The MUG facial expression database. In: 11th International Workshop on Image and Audio Analysis for Multimedia Interactive Services, pp. 1–4, Desenzano del Garda, Italy, April 2010
Asthana, A., Zafeiriou, S., Cheng, S., Pantic, M.: Incremental face alignment in the wild. In: IEEE International Conference on Computer Vision and Pattern Recognition, pp. 1859–1866, June 2014
Bourel, F., Chibelushi, C.C., Low, A.A.: Recognition of facial expressions in the presence of occlusion. In: British Machine Vision Conference, pp. 1–10 (2001)
Bourel, F., Chibelushi, C.C., Low, A.A.: Robust facial expression recognition using a state-based model of spatially-localized facial dynamics. In: 5th IEEE International Conference on Automatic Face and Gesture Recognition, pp. 106–111 (2002)
Cornejo, J.Y.R., Pedrini, H.: Recognition of occluded facial expressions based on centrist features. In: 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1298–1302. IEEE (2016)
Jiang, B., Jia, K.: Research of robust facial expression recognition under facial occlusion condition. In: Zhong, N., Callaghan, V., Ghorbani, A.A., Hu, B. (eds.) AMT 2011. LNCS, vol. 6890, pp. 92–100. Springer, Heidelberg (2011). doi:10.1007/978-3-642-23620-4_13
Kanade, T., Cohn, J., Tian, Y.: Comprehensive database for facial expression analysis. In: Fourth IEEE International Conference on Automatic Face and Gesture Recognition, pp. 46–53, Grenoble, France (2000)
Kotsia, I., Buciu, I., Pitas, I.: An analysis of facial expression recognition under partial facial image occlusion. Image Vis. Comput. 26(7), 1052–1067 (2008)
Liu, S., Zhang, Y., Liu, K.: Facial expression recognition under random block occlusion based on maximum likelihood estimation sparse representation. In: International Joint Conference on Neural Networks, pp. 1285–1290, July 2014
Lucey, P., Cohn, J., Kanade, T., Saragih, J., Ambadar, Z., Matthews, I.: The extended cohn-kande dataset (CK+): a complete facial expression dataset for action unit and emotion-specified expression. In: Third IEEE Workshop on Computer Vision and Pattern Recognition for Human Communicative Behavior Analysis, San Francisco, CA, USA, June 2010
Lyons, M., Kamachi, M., Gyoba, J.: Japanese female facial expressions (JAFFE). Database of Digital Images (1997). http://www.kasrl.org/jaffe.html
Mao, X., Xue, Y., Li, Z., Huang, K., Lv, S.: Robust facial expression recognition based on RPCA and AdaBoost. In: 10th Workshop on Image Analysis for Multimedia Interactive Services, pp. 113–116, May 2009
Moore, S., Bowden, R.: Local binary patterns for multi-view facial expression recognition. Comput. Vis. Image Underst. 115(4), 541–558 (2011)
Towner, H., Slater, M.: Reconstruction and recognition of occluded facial expressions using PCA. In: Paiva, A.C.R., Prada, R., Picard, R.W. (eds.) ACII 2007. LNCS, vol. 4738, pp. 36–47. Springer, Heidelberg (2007). doi:10.1007/978-3-540-74889-2_4
Zhang, L., Tjondronegoro, D., Chandran, V.: Random Gabor based templates for facial expression recognition in images with facial occlusion. Neurocomputing 145, 451–464 (2014)
Zhang, S., Zhao, X., Lei, B.: Facial expression recognition using sparse representation. WSEAS Trans. Syst. Control 11(8), 440–441 (2012)
Acknowledgements
The authors are thankful to FAPESP (grants #2014/12236-1 and #2016/19947-6) and CNPq (grant #305169/2015-7) for their financial support.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Cornejo, J.Y.R., Pedrini, H. (2017). Emotion Recognition Based on Occluded Facial Expressions. In: Battiato, S., Gallo, G., Schettini, R., Stanco, F. (eds) Image Analysis and Processing - ICIAP 2017 . ICIAP 2017. Lecture Notes in Computer Science(), vol 10484. Springer, Cham. https://doi.org/10.1007/978-3-319-68560-1_28
Download citation
DOI: https://doi.org/10.1007/978-3-319-68560-1_28
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-68559-5
Online ISBN: 978-3-319-68560-1
eBook Packages: Computer ScienceComputer Science (R0)
