
Abstract
Shaky videos are visually unappealing to viewers. Digital video stabilization is a technique to compensate for unwanted camera motion and produce a video that looks relatively stable. In this paper, an approach for video stabilization is proposed which works by estimating a trajectory built by calculating motion between continuous frames using the Shi-Tomasi Corner Detection and Optical Flow algorithms for the entire length of the video. The trajectory is then smoothed using a moving average to give a stabilized output. A smoothing radius is defined, which determines the smoothness of the resulting video. Automatically deciding this parameter’s value is also discussed. The results of stabilization of the proposed approach are observed to be comparable with the state of the art YouTube stabilization.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
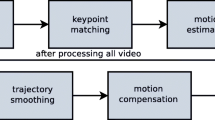
With advances in smart-phone technology and the ubiquity of these hand-held devices, every important moment of our lives is captured on video. But these videos are of often poor quality: lacking stabilizing equipment such as tripods, steady-cams, gimbals, etc. They are often shaky and unstable, especially when the videographer, the subject, or both are in motion. To deal with this, affordable techniques that do not require hardware to stabilize such videos are of the essence. Post-processing techniques that need no additional hardware are effective in removing the effects of jerky camera motion, and are independent of the device capturing the video and the subject of the video. The proposed approach is a five step sequential process that covers the different stages of video stabilization from feature extraction and tracking to camera motion estimation and compensation. This method is run on a set of videos and is compared to the state of the art YouTube video stabilizers.
Section 2 discusses the relevant work done in the field of video stabilization. The proposed video stabilization technique is discussed in detail in Sect. 3. Section 4 describes the experiments performed and results obtained. The paper concludes with Sect. 5 which gives the inferences made along with future directions.
2 Literature Survey
2D video stabilization methods perform three tasks - motion estimation, motion compensation, and image correction. Feature matching is done using Scale Invariant Feature Transform (SIFT) [1] or Oriented FAST and Rotated BRIEF (ORB) operators [12]. Robust feature trajectories [5] involve using features matched along with neighboring features information. It use SIFT or ORB descriptors to match features between frames to calculate feature trajectories, and then pruning and separating them into local and global motion. The motion inpainting algorithm, which fills frame’s unpainted regions by observing motion history [5], serves well for image correction. Another approach modified the optical flow algorithm [3, 8], where pixels were tracked to find which feature trajectories cross it [7]. The approach worked well with videos possessing large depth change, but failed in cases with dominant large foreground objects. Videos having large parallax or rolling shutter effects are challenging to stabilize. To tackle this, a bundle of trajectories were calculated for different subareas of the image and these were all processed together [6]. Applying L1-norm optimization [2] can generate camera paths that consist of only constant, linear and parabolic motions, which do follow cinematography rules. YouTube has since adopted this algorithm into their system.
Most of the approaches discussed here witness a significant difference in performance on videos with an object of interest and ones without, with the latter facing a dip. In this paper, an approach based on [10] is investigated whose performance does not change for videos with objects of interest or ones without.
3 Methodology
The proposed approach uses two structures - transform parameter and trajectory. The first holds the frame-to-frame transformation- dx, dy, da. Each represents changes in the x-coordinate, y-coordinate and rotational change respectively. The latter structure stores the positions and angle of the feature points, which together form the trajectory. Algorithm 1 shows the working of the proposed approach, given a smoothing radius.

Features points are found for each frame by using Shi-Tomasi Corner detection algorithm [4]. These feature points are used to obtain the corresponding matching features in the next consecutive frames using optical flow algorithm [3, 8]. Transformation matrix \(T_{original}^{(k)}\) is estimated from the feature points of frame k and frame \(k+1\), that encompasses the change between the two frames [11]. \(T_{original}^{(k)}\) provides the transform parameter values as:
These values are stored as a list,
where, \(\varDelta _{original}\) is then used to generate a single image trajectory, \( I_{original} \). First, trajectory point is initialized to x=0, y=0, a=0. Each point thereafter is updated by adding to it a transform parameter. The final list contains the image trajectory, \( I_{original} = \{ p^{(k)} \}\). Camera shake is removed in the third step. For this, a new smooth trajectory, \(I_{smooth}\) is computed using a sliding average window algorithm. This requires a parameter, namely the constant smoothing radius r. The value of r is the number of frames on either side of the current frame used for the sliding window.
Figure 1 depicts that, as smoothing radius increases, stability tends to increase. But having arbitrarily high values of smoothing radius can be detrimental. As smoothing radius increases, the absolute values of the transformations applied to the frames increases leading to more data being lost as shown in Fig. 2. Data loss can be quantitatively defined as the ratio of black data-void areas in the stabilized frame to the original frame area. An optimal smoothing radius is thus desired.
Let \(S_V(r)\) and \(D_V(r)\) represent the stability and data loss respectively in the video obtained by smoothing video V with a smoothing radius of r. Let \(s_V(r)\) and \(d_V(r)\) be the corresponding min-max normalized functions. As a high value of \(s_V(r)\) and a low value of \(d_V(r)\) is desirable, the goodness of a video is:
and the optimal smoothing radius is then given by

Effect of smoothing radii on goodness of a video, stability and data loss
To reduce the time taken for calculation, following constraints are introduced.
-
1.
\(0 < r \le R_{max}\): High radius causes high data loss and can be disregarded. The exact value of \(R_{max}\) is chosen empirically to be 40.
-
2.
\(D_V(r) < 0.1\): Fixing a range on just r is insufficient as the data loss function can ascend very quickly even within that range. Thus, to preclude that, a constraint on data loss is also introduced.
Having obtained the desired smooth trajectory, transform parameter values are required to transform every frame such that their old trajectory points are shifted to the ones in line with the smooth trajectory. For a particular frame, the distance between its \(I_{original}^{(k)}\) and \(I_{smooth}^{(k)}\) is calculated and added to the corresponding \(\varDelta _{original}^{(k)}\), to obtain a new transform parameter \(\delta _{smooth}^{(k)}\). In effect, a point from a previous frame is translated to the current point of current frame and then translated from there to the smooth point of the current frame. These calculated values are brought together into a sequence by \(\varDelta _{smooth} = \{\delta _{smooth}^{(k)}\} \). Subsequently, the transformation matrix for the new smoothened trajectory and transform parameter values are computed using \(\varDelta _{smooth}\), and applied to produce a stable video output. Suppose smooth transform for the \(k^{th}\) frame is \(st^{(k)}\), then the transformation matrix is given as,
This affine transformation matrix is calculated for every frame to obtain the required sequence of transformations by \(\varGamma = \{T_{smooth}^{(k)}\}\). Each transformation \(T_{smooth}^{(k)}\) is then applied on the corresponding frame k. The resultant sequence of frames is the stabilized video.

Effect of varying smoothing radius on data loss

Frequency domain representation of the X coordinate signal
4 Results and Comparison
The proposed approach is tested on videos with and without objects of interest. To assess the performance of the proposed method, two performance criteria - stability and distortion - suggested by [6] are used to compare the proposed method with the YouTube stabilizer [2], and non-stabilized videos. Distortion between two continuous frames is the sum of pixel-by-pixel difference in intensity. Overall distortion of a video is the average of the pairwise distortion between continuous frames over the length of the video. A lower average implies a less distorted video. Table 1 compares the result of the proposed method with the original video and YouTube stabilized video. In most cases distortion is relatively higher than YouTube using the proposed method.
Stability approximates how stable the video appears to a viewer. Quantitatively, a higher fraction of energy present in the low frequency region of the Fourier transform of the estimated motion implies higher stability. Figure 3 shows the frequency domain representation of the X-coordinate motion. Over a dataset of 11 videos, it is observed that the proposed method shows an average of 3.92% improvement in stability over the original video, while the YouTube stabilizer shows a 4.28% improvement. The proposed method outperforms the YouTube stabilizer in three out of eleven videos. The results of this metric on three videos are shown in Table 1. The stability of the proposed method is usually comparable with that of YouTube, and in a few cases outperforms it. The proposed method does not handle sudden jerks well. Its performance is however unaffected by the presence or absence of an object in focus, thus making it applicable to a large class of videos.
5 Conclusions and Future Work
In this paper an algorithm for video stabilization has been proposed. This was accomplished by obtaining a global 2-D motion estimate for the optical flow of the video in both the X and Y directions. The algorithm is simpler than most current implementations, and provides comparable accuracy with YouTube’s stabilizer. It also takes into account the image degradation to maintain optimal video quality. Taking into consideration multiple paths to estimate the motion [6] and motion inpainting [9] for image correction can improve the performance of this implementation. Future work can also include adaptively varying the smoothing radius over the video.
References
Battiato, S., Gallo, G., Puglisi, G., Scellato, S.: Sift features tracking for video stabilization. In: 14th International Conference on Image Analysis and Processing, ICIAP 2007, pp. 825–830. IEEE (2007)
Grundmann, M., Kwatra, V., Essa, I.: Auto-directed video stabilization with robust l1 optimal camera paths. In: 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 225–232. IEEE (2011)
Horn, B.K., Schunck, B.G.: Determining optical flow. Artif. Intell. 17(1–3), 185–203 (1981)
Jianbo, S., Carlo, T.: Good features to track. In: Proceedings of 1994 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 1994, pp. 593–600. IEEE (1994)
Lee, K.Y., Chuang, Y.Y., Chen, B.Y., Ouhyoung, M.: Video stabilization using robust feature trajectories. In: 2009 IEEE 12th International Conference on Computer Vision, pp. 1397–1404. IEEE (2009)
Liu, S., Yuan, L., Tan, P., Sun, J.: Bundled camera paths for video stabilization. ACM Trans. Graph. (TOG) 32(4), 78 (2013)
Liu, S., Yuan, L., Tan, P., Sun, J.: Steadyflow: spatially smooth optical flow for video stabilization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4209–4216 (2014)
Lucas, B.D., Kanade, T., et al.: An iterative image registration technique with an application to stereo vision. In: Proceedings DARPA Image Understanding Workshop, pp. 121–130 (1981)
Matsushita, Y., Ofek, E., Ge, W., Tang, X., Shum, H.Y.: Full-frame video stabilization with motion inpainting. IEEE Trans. Pattern Anal. Mach. Intell. 28(7), 1150–1163 (2006)
Nghia, H.: Simple video stabilisation using opencv (2014), http://nghiaho.com/?p=2093. Accessed 17 Mar 2017
Nghia, H.: Understanding opencv cv::estimaterigidtransform (2015), http://nghiaho.com/?p=2208. Accessed 15 Aug 2017
Rublee, E., Rabaud, V., Konolige, K., Bradski, G.: Orb: an efficient alternative to sift or surf. In: 2011 IEEE International Conference on Computer Vision (ICCV), pp. 2564–2571. IEEE (2011)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper

Cite this paper
Shagrithaya, K.S., Gurushankar, E., Srikanth, D., Ramteke, P.B., Koolagudi, S.G. (2017). Video Stabilization Using Sliding Frame Window. In: Shankar, B., Ghosh, K., Mandal, D., Ray, S., Zhang, D., Pal, S. (eds) Pattern Recognition and Machine Intelligence. PReMI 2017. Lecture Notes in Computer Science(), vol 10597. Springer, Cham. https://doi.org/10.1007/978-3-319-69900-4_29
Download citation
DOI: https://doi.org/10.1007/978-3-319-69900-4_29
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-69899-1
Online ISBN: 978-3-319-69900-4
eBook Packages: Computer ScienceComputer Science (R0)
