
Abstract
Thyroid cancer is one of the most prevalent cancers which affects a large population all over the world. To find effective therapeutic measures against thyroid cancer, it is necessary to identify potential genes which lead to this disease. In this paper, we consider an ensemble of structural, semantic and post translational modification (PTM) similarities based clustering of human genes using known thyroid cancer genes as seeds. Our purpose is to identify potential genes which may be responsible for thyroid cancer from the clusters.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others
Keywords
1 Introduction
Thyroid cancer is caused by malignancy of thyroid cells. Thyroid cancer is of the following types: Papillary thyroid cancer (PTC), Follicular thyroid cancer (FTC), Medullary thyroid cancer (MTC) and Anaplastic thyroid cancer (ATC). PTC is the most prevalent thyroid cancer which is seen in 75% to 85% cases. The number of people affected with thyroid cancer has significantly increased in the past few years (worldwide 213,000 people). Thus, it has become urgent to understand the mechanism behind the malignancy of thyroid cells to discover effective therapeutic measures. For this, we need to identify the genes responsible for this disease so that effective therapeutic measures can be adopted. For some cancer genes missense mutations based clustering is used to identify new candidates. Stehr et al. [9] and Ryslik et al. [8] used 3D structural information in missense mutations clustering to predict new cancer genes. In [6], Kurubanjerdjit et al. has proposed a clique percolation based clustering in identification of cancer associated proteins. In this paper, we present an ensemble of PTM, semantic and structural similarities based clustering of human genes using known thyroid cancer genes (CNC) as seeds and predict novel genes which may cause thyroid cancer.
2 Methodology
In this paper, we present an ensemble of similarities based clustering approach to predict potential thyroid cancer causing genes in Homo sapiens using the information of known thyroid cancer genes. We use PTM similarity, semantic similarity and structural similarity to assess the similarity of two genes.
2.1 PTM Similarity
To determine the PTM similarity, we first find the number of occurrences of interactions between different PTM types along with the particular residue at which the modification occurs. Then, for each protein pair we determine whether their respective PTM types together with the modified residues are present in the PTM interaction list. If present, we score (normalize in the range (0,1]) the PTM similarity of the protein pair with the occurrence of the PTM interaction.
2.2 Semantic Similarity
The semantic similarity between two proteins is estimated by considering the similarities between their all pairs of annotating Gene Ontology (GO) terms belonging to a particular ontology (molecular function (MF), biological process (BP), cellular component (CC)). Similarity between a pair of GO terms is assessed on the basis of topological properties of the GO graph and the average information content (IC) of the disjunctive common ancestors (DCAs) of the GO terms [3].
2.3 Structural Similarity
We use two scoring metrics, TM-score [12] and RMSD [5], to measure the structural similarity of two proteins. TM-score gives a value in the range (0, 1], where 1 indicates a perfect match in topological similarity of two protein structures. We use the TM align algorithm [12] for comparing the structures of two proteins. This algorithm identifies the best structural alignment between two proteins. After the optimal superposition, RMSD represents the root mean squared deviation of all the equivalent atom pairs of two protein structures. In general, lower RMSD indicates better superposition. A RMSD value 3Åindicates a high degree of structural similarity. However, a lower RMSD and higher TM-score indicates a better structural similarity, thus they are inversely related. Finally, we incorporate both the scoring metrics to quantify the structural similarity as,
Here we restrict the RMSD score up to 3Å for higher structural similarity. In Eq. 1, any RMSD value less than 3Å will contribute positively with TM-score. In addition, RMSD value 0 and TM-score 1 represents optimal structural similarity.
2.4 Cluster Ensembling
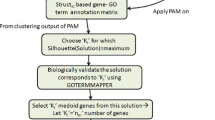
In this work, initially, clustering is performed using above three similarity metric at three different similarity thresholds (\(\theta _{PTM},\theta _{Semn},\theta _{Struct}\)). For a particular seed we ensemble all three cluster results and create a new set of cluster members for each seed. Finally, we consider each of the member of the new set as a member of the final cluster set if it is the member of at least 30% of the total clusters (seeds). The overall proposed procedure is shown in Fig. 1.

The basic workflow of clustering result ensembling technique.
3 Dataset Description
We download the genes involved in all types of thyroid cancer from the Thyroid Cancer and Disorder Gene Database (TCGDB) [1] and KEGG and Human Protein Atlas database (CNC genes) [11]. We download protein-protein interactions (PPIs) from the iRefWeb database [10]. From this, we consider only those interactions in which both the proteins are present in both reviewed Uniprot and Protein Data Bank (PDB). Finally, we obtain 4726 PPIs and 4492 unique proteins which is used for validation. For the test dataset, we consider all reviewed human proteins from Uniprot whose structure information are available in PDB. We finally obtain a total of 1321 proteins in the test dataset. Ontology data and GO annotations are downloaded from the Gene Ontology database [2]. The PTM data and PTM interaction data are collected from the HPRD database [7].

Heatmap of CNC occurrence percentage over the seed based clustering results of three datasets.

(a) Membership of the predicted target genes to 21 clusters. A colored box represents that the target gene belongs to the respective cluster. (b) Network of predicted genes and their direct interaction partner genes having CNC annotations. Red nodes represent the predicted genes and blue nodes represent the CNC annotated genes.
4 Experimental Results and Discussion
In this paper, we present a clustering, based on an ensemble of structural, semantic and PTM similarities, of genes using 26 known thyroid cancer genes selected as the seeds. The purpose of this clustering is utilize known thyroid genes to predict new genes which may be responsible for thyroid cancer. In this work, total 4492 genes are considered as target genes that includes 297 thyroid cancer genes taken from Human protein Atlas database. To choose the appropriate thresholds (\(\theta _{PTM},\theta _{Semn},\theta _{Struct}\)) for all three clustering, we further sub divide the target genes into three subsets. Each subset contains equal number of CNC genes and equal number of non-CNC genes. These thresholds are set at a value such that the final clustering result has only CNC genes in the clusters. Figure 2 shows the heatmap of the seed based clustering result and percentage of CNC genes obtained from three different sets. CNC percentage ranges from 0 to 1 where 1 implies that all the cluster members are CNC annotated and 0 implies that none of the members have CNC annotation.
Depending on this threshold, we apply this ensemble clustering method over 1350 test data consisting of genes which do not have any Thyroid cancer annotations and have structure information in the PDB database. Using this approach we retrieve 18 new target genes from 21 seeds (remaining 5 seed genes create empty clusters). Figure 3a shows occurrences of target genes over the clusters where colored box indicates that the target gene belongs to the corresponding cluster. To evaluate the effectiveness of the target genes we consider only 14 genes which belong to minimum 30% of the clusters. Using the interaction dataset from the String Database [4], we find that these 14 predicted genes have direct interaction with certain CNC genes, which have been shown in Fig. 3b Thus, these 14 predicted genes may have an important role in thyroid cancer.
5 Conclusion
In this paper, we present a clustering, based on an ensemble of structural, semantic and PTM similarities, of human genes with 26 known thyroid cancer genes as seeds. In this method, we first select appropriate thresholds for structural similarity, semantic similarity and PTM similarity based clustering separately. The thresholds are selected such that after applying this clustering method on the validation dataset, the clusters contain only CNC genes as members. We then use this ensemble clustering method to predict potential thyroid cancer genes. Our clustering result predicts 14 genes with no CNC annotations, but which have direct interactions with CNC annotated genes. From the results, we can summarise that these 14 predicted genes may be responsible for Thyroid cancer since they are directly associated with Thyroid cancer causing genes.
References
Bansal, A., Ramana, J.: TCGDB: a compendium of molecular signatures of thyroid cancer and disorders. J. Cancer Sci. Ther. 7, 198–201 (2015)
Gene Ontology Consortium, et al.: The gene ontology (GO) database and informatics resource. Nucleic Acids Res. 32(suppl 1), D258–D261 (2004)
Dutta, P., Basu, S., Kundu, M.: Assessment of semantic similarity between proteins using information content and topological properties of the gene ontology graph. IEEE/ACM Trans. Comput. Biol. Bioinform. (2017). doi:10.1109/TCBB.2017.2689762
Franceschini, A., Szklarczyk, D., Frankild, S., Kuhn, M., Simonovic, M., Roth, A., Lin, J., Minguez, P., Bork, P., Von Mering, C., et al.: String v9. 1: protein-protein interaction networks, with increased coverage and integration. Nucleic Acids Res. 41(D1), D808–D815 (2013)
Kabsch, W.: A discussion of the solution for the best rotation to relate two sets of vectors. Acta Crystallogr. Sect. A Crystal Phys. Diffr. Theor. Gen. Crystallogr. 34(5), 827–828 (1978)
Kurubanjerdjit, N., Huang, C.H., Ng, K.L.: Identification of lung cancer associated protein by clique percolation clustering analysis. In: 2013 13th International Symposium on Communications and Information Technologies (ISCIT), pp. 737–740. IEEE (2013)
Prasad, T.K., Goel, R., Kandasamy, K., Keerthikumar, S., Kumar, S., Mathivanan, S., Telikicherla, D., Raju, R., Shafreen, B., Venugopal, A., et al.: Human protein reference database2009 update. Nucleic Acids Res. 37(suppl 1), D767–D772 (2009)
Ryslik, G.A., Cheng, Y., Cheung, K.H., Bjornson, R.D., Zelterman, D., Modis, Y., Zhao, H.: A spatial simulation approach to account for protein structure when identifying non-random somatic mutations. BMC Bioinform. 15(1), 231 (2014)
Stehr, H., Jang, S.H.J., Duarte, J.M., Wierling, C., Lehrach, H., Lappe, M., Lange, B.M.: The structural impact of cancer-associated missense mutations in oncogenes and tumor suppressors. Mol. Cancer 10(1), 54 (2011)
Turner, B., Razick, S., Turinsky, A.L., Vlasblom, J., Crowdy, E.K., Cho, E., Morrison, K., Donaldson, I.M., Wodak, S.J.: iRefWeb: interactive analysis of consolidated protein interaction data and their supporting evidence. Database 2010, baq023 (2010)
Uhlén, M., Björling, E., Agaton, C., Szigyarto, C.A.K., Amini, B., Andersen, E., Andersson, A.C., Angelidou, P., Asplund, A., Asplund, C., et al.: A human protein atlas for normal and cancer tissues based on antibody proteomics. Mol. Cell. Proteomics 4(12), 1920–1932 (2005)
Zhang, Y., Skolnick, J.: TM-align: a protein structure alignment algorithm based on the TM-score. Nucleic Acids Res. 33(7), 2302–2309 (2005)
Acknowledgement
This project is partially supported by the CMATER research laboratory of the Computer Science and Engineering Department, Jadavpur University, India, PURSE-II and UPE-II project and Research Award (F.30-31/2016(SA-II)) from UGC, Government of India and Visvesvaraya PhD scheme for ELECTRONICS & IT from DeitY, Government of India.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper

Cite this paper
Halder, A.K., Dutta, P., Kundu, M., Nasipuri, M., Basu, S. (2017). Prediction of Thyroid Cancer Genes Using an Ensemble of Post Translational Modification, Semantic and Structural Similarity Based Clustering Results. In: Shankar, B., Ghosh, K., Mandal, D., Ray, S., Zhang, D., Pal, S. (eds) Pattern Recognition and Machine Intelligence. PReMI 2017. Lecture Notes in Computer Science(), vol 10597. Springer, Cham. https://doi.org/10.1007/978-3-319-69900-4_53
Download citation
DOI: https://doi.org/10.1007/978-3-319-69900-4_53
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-69899-1
Online ISBN: 978-3-319-69900-4
eBook Packages: Computer ScienceComputer Science (R0)
