
Abstract
Recently, Thailand has started initiating the Thailand open government data project that continuously triggers an increment in the number of open datasets. Open data is valuable when the data is reused, shared and integrated. Converting the existing datasets to the RDF format can increase the values of these datasets. In this paper, we present the architecture and processes for RDF dataset management for Data.go.th based on OAM Framework which supports the entire processes: RDF data publishing, and data querying. Our approach is different from other LOD platforms in that users do not require the knowledge of RDF and SPARQL. Our platform would facilitate data publishing and querying process for novice users and make it easier to use. This framework provides a common ontology-based search interface and RESTFul APIs constructed automatically for the datasets when they are published. With the provided services for the datasets, it can simplify the user’s tasks in publishing datasets and create applications for the datasets. In consuming the RDF data, we implemented a sample mash-up application which accessed the published weather and reservoir datasets from the Data.go.th website via RESTful APIs.
1 Introduction
Open Government Data initiatives are widely adopted in many countries in order to increase the transparency, public engagement and the channel of communication between government and their citizens. Each country has a different policy or strategy to publish their datasets. There are three main open data strategies including democratic representation, service provision and law enforcement [1]. For instance, the United States focuses on transparency strategy to increase democratic accountability and efficiency in government. The United Kingdom has promoted publishing open government data (OGD) datasets by law enforcement. UK government has a clear policy to make datasets in machine-readable formats and published under an open license [2, 3].
As of July 2015, there are over 150,000 datasets on Data.gov and over 25,000 datasets on Data.gov.uk. Although there are lots of datasets in several formats which are published on the web, only small proportion of these datasets are actually used [4]. One of the reasons is that most of datasets are published in various formats (e.g. XLS, CSV, HTML, PDF). Thus, it can be difficult for application developers to process varieties of file formats and spend more time to manage the updates of these datasets.
In Thailand, the government has promoted the initiative by issuing policies and regulations related to open data publishing and try to educate government sectors to understand about open government data. Data.go.th is the national open government data portal of Thailand, which started to publish several datasets in 2014. As of July 2015, there are several hundred datasets available on this portal in various formats (e.g. XLS, CSV, PDF) and users can download raw datasets from this web site. Data.go.th also promotes applications and innovations that are created based on the content published on the portal.
Based on the 5-star open data model [4], Resource Description Framework (RDF) is a standard data format that can support Linked open data. Consuming RDF data is usually achieved by querying via an SPARQL endpoint. SPARQL is a query language for RDF. RDF data is typically stored as linked structure as a “graph data” and represented in URI. Therefore, a developer who want to use the SPARQL endpoint must have the knowledge about SPARQL and RDF. Our work proposes that Web API is an easier way for retrieving RDF-based open data. There are several advantages including:
-
1.
Data as a service—developers who do not have background in RDF and SPARQL can query a dataset via a RESTFul API service.
-
2.
Standard data format—developers do not need to study a new data format, the query results will be returned in the standard JSON format.
In this paper, we develop a framework and a set of tools for data management based on RDF. The framework focuses on transforming the existing datasets into the RDF format and providing convenient way to access the published RDF datasets. Specifically, users who want to access the published datasets do not require knowledge about the underlying data formats or query language, i.e., RDF and SPARQL query. They can access the data in simple-to-use format via RESTFul APIs. We propose an architecture and processes for transforming and publishing RDF datasets from some existing datasets on Data.go.th and using the published data in applications. The framework is extended from the Ontology Application Management (OAM) framework [5]. The framework was used to support the entire process including RDF data publishing and consumption. To demonstrate an actual use case, we developed a demonstration application that mashed up two datasets from Data.go.th via the provided RESTFul APIs. Our approach is different from other LOD platforms in that users do not require the knowledge of RDF and SPARQL. This would facilitate the data publishing and querying process for typical users that can make it easier to use.
This paper is structured as follows. Section 2 introduces the overview about data catalogs and dataset management portal for open data and background of OAM Framework. Section 3 describes the architecture, design of the APIs and processes for converting and publishing the datasets. Section 4 describes a sample application to demonstrate use of the published RDF datasets. Section 5 provides a summary and discussion of some future directions.
2 Background
2.1 Data Catalogs and Dataset Management Systems for Linked Open Data
Public sector data and information are mostly scattered across many different websites and portals and are often collected in various formats. Many countries create online data catalogs as the central data repository where datasets can be found and accessed [6]. CKAN is the open data catalogs which allow data owners to upload the collections of data and provide information about the data. There are many countries using CKAN for storing open government datasets, such as the US’s data.gov, the UK’s data.gov.uk, and the European Union’s publicdata.eu.
The varieties of file formats of raw datasets are often inconvenient for some users or developers to use. Specifically, using proprietary formats can reduce the dataset accessibility. Based on the 5-star open data principle [4], improving quality of datasets for open data includes data conversion to an open standard format like RDF that provides better support for data sharing, reuse, integration and data querying. Therefore, RDF dataset management system should be provided to support RDF data publishing and provide the data querying service to users who want to access the published data. Unlike open data catalogs, the features of dataset management system for RDF-based open data should cover the processes for data conversion, data publishing and data querying.
There are several dataset management systems for Linked open data. Each system provides different tools for data conversion/creation, data publishing and data query/access. TWC LOD [2] is a portal for linked open government data supporting data conversion, publishing, and querying. They use open source tool named Csv2rdf4lodFootnote 1 to convert CSV files into Linked Open Government Data (LOGD) RDF files and then use OpenLink VirtuosoFootnote 2 for loading all metadata and converted files into their SPARQL endpoint. DaPaaS Platform [7] aims to provide a Data-and Platform-as-a-Service environment that support data importing/transforming, data publishing, and data querying. They use Linked Data manufacturing tool named GrafterFootnote 3 for converting tabular data to RDF format and publish the converted data on DaPaaS. Users can query the published data via SPARQL endpoint [8]. St. Petersburg’s LOD [9] is a project for publishing Russian open government data. In this project, the Information Workbench toolFootnote 4 is developed to support data storing, dataset converting to RDF format, providing SPARQL endpoint to access the data, and visualizing data in various formats (charts, tables, graphs, etc.). LGD Publishing Pipeline [10] is not a dataset management portal. The system provides the self-service approach to create Linked Government Data (LGD). This approach provides a publishing pipeline for users to convert a raw government data to LGD by themselves. The pipeline was based on the Google Refine (currently named “OpenRefineFootnote 5”).
Most LOD platforms focused on converting raw datasets to RDF to provide support for linked open data and to provide a data querying service via SPARQL endpoint. Thus, publishing and using linked open data normally requires knowledge about RDF and SPARQL query. Our approach is different from other LOD platforms in that the users do not require the knowledge of RDF and SPARQL. This would facilitate the data publishing and querying process for novice users that can make it easier to use. To simplify the task of consuming the RDF data, we design and develop the RESTFul APIs as a data querying service on top of SPARQL endpoint. Our RDF dataset management system is built based on the OAM Framework, which is a platform that simplifies development of ontology-based semantic web application [10]. We believe that the process simplification can help to promote more publication and usage of Linked open data.
2.2 Ontology Application Management (OAM) Framework
The Ontology Application Management (OAM) framework is a java-based web-application development platform which helps users to build a semantic web application with less programming skill required. The underlying technology of OAM is Apache Jena, D2RQ and RDF data storage [5]. OAM includes three main modules follows as:
-
Database-to-Ontology Mapping provides a user interface for mapping between an existing relational database schema and ontology file (OWL). This process helps users who not have a programming skill in mapping and converting relational database to RDF format.
-
Ontology-based Search Engine provides a Form-based SPARQL data querying service for users to query each dataset by defining search conditions.
-
Recommendation Rule System provides a simplified interface for rule management. Users can define a condition of rules that do not require knowledge of the rule syntax of reasoning engine.
In developing an RDF-based platform for the Thailand open data project, we adopted two primary features of OAM. First, the RDF data publishing function of OAM was extended to support multiple dataset services. The multi-dataset support is necessary for building a scalable open data portal. Second, we extended the ontology-based search engine by implementing RESTFul APIs as a dataset querying service on top of SPARQL endpoint. The design of the APIs includes the basic SPARQL querying operations such as filter, aggregate, order by, limit and offset. Figure 1 shows an example of using OAM for database-ontology mapping and publishing an RDF dataset from an existing weather statistics dataset.

An example of using OAM for database-ontology mapping and publishing an RDF dataset from an existing weather statistics dataset
3 RDF Dataset Management Processes for Data.go.th
Management of RDF Dataset is done after the raw datasets are published on the Data.go.th website. Specifically, data publishing workflow have two processes: raw dataset publishing on Data.go.th portal and RDF dataset publishing on a separate portal (http://demo-api.data.go.th). The data owners can publish their datasets on the data portal Data.go.th in various file formats. Basic functionality of this portal is to provide the interface for configuring metadata, uploading, and searching the datasets. Afterwards, the data owner has an option to import some selected datasets in tabular format, e.g. CSV or XLS, for RDF data transformation and publishing on the RDF dataset portal. The RDF dataset publishing has to be done separately because only well-structured datasets can be successfully transformed to RDF data. Thus, the data owner must be trained to prepare the datasets in proper forms, e.g. putting column names in the top rows, putting data in successive rows. Figure 2 shows the dataset publishing workflow.

Dataset publishing workflow
3.1 RDF Dataset Management Processes
RDF dataset management on the Demo-api.data.go.th portal has two main processes: publishing and querying, as shown in Fig. 3.

Overview of RDF dataset management processes
-
(1)
Publishing process. The steps for preparing and converting data to the RDF format are listed below:
-
Data preparing: Users need to prepare database and OWL ontology. First, user can fetch a raw dataset in tabular format from Data.go.th and import the tabular files to relational database. Second, creating OWL ontology which defines the dataset schema.
-
Data mapping: Using OAM framework, users can define database schema-to-ontology mapping. OAM provides the interface for schema mapping and vocabulary mapping between ontology file (OWL) and a relational database schema. After the mapping process, user can convert a dataset to RDF through interface. The converted dataset is ready to publish.
-
Dataset Publishing: Once the RDF files were successfully created. The RDF files will be published on the Demo-api.data.go.th portal.
-
-
(2)
Querying process. This steps for publishing and querying the RDF datasets are listed below:
-
Form-based SPARQL data querying: Ontology-based search engine of the OAM framework provides the form-based SPARQL data querying, which hides the syntax of SPARQL query. Users can choose any RDF dataset for data querying. Search interface for each dataset is formed based on ontology of the dataset. The search results are presented in table form and users can also export the results in JSON and CSV format.
-
RESTFul APIs: For each dataset, the data querying service is automatically provided as RESTFul API by means of the OAM framework. Application developers can query each dataset via APIs and the returned search results are provided in JSON format.
-
3.2 Design of Dataset APIs
Demo-api.data.go.th provides the data as a service through RESTFul APIs for every dataset which was converted in RDF format and published on this portal. Figure 4 shows the dataset provided as a service through RESTFul API.

Layers of Dataset Service API at Demo-api.data.go.th
In querying data, we design RESTFul APIs to cover most of the basic operations of SPARQL query such as filter, aggregation functions, order by, limit and offset. All datasets have the same patterns of querying APIs. Thus, it can help users to reduce a learning curve. In addition, the ontology-based search interface also provides a direct access to access the querying API as an alternative for writing the APIs directly. They can copy the API querying URL to use in their applications as shown in Fig. 5.

Access to the API via the ontology-based search interface
The APIs are provided for three main functions: getting all dataset names, getting description of the dataset and data querying by condition based on ontology. Examples of APIs of each function are provided as follows:
-
Get all dataset name:
-
Get description of the dataset such as concept, property, and operators:
http://demo-api.data.go.th/searching/api/dataset/get_info?dsname={datasetname}
-
Querying by conditions:
The parameters in querying API are based on the structure of the ontology of each dataset. There are two types of property with the supported querying operators as follows:
-
Datatype property: This type relates things to literal (e.g., String, Integer, Float etc.). Operators of literal value for querying API include ‘CONTAINS’ for string value and =, >, <, >=, <= for number value comparison.
-
Object property: This type relates individuals to individuals which refer to some particular class. Operator of querying API for object property is ‘IS-A’ operator, which supports ‘Subclass-of’ inferencing.
3.3 SPARQL Query Translation and Result Structure of APIs
In this section, we provide details and examples of SPARQL query translation for the dataset APIs. SPARQL queries and the results of each API function are described as follows.
-
1.
Get all dataset names: This API returns the list of dataset names; both short names and full names of datasets. The short name of a dataset is used to reference the dataset in other APIs.
-
URL: http://demo-api.data.go.th/searching/api/dataset/get_name
-
Result: list of dataset names (Fig. 6)
Fig. 6. 
Example JSON result for list of dataset names
-
-
2.
Get description of the dataset: This API returns description of the dataset including concept, property, and operators as shown in Fig. 7.
Fig. 7. 
Example of JSON result for description of the dataset
-
URL: http://demo-api.data.go.th/searching/api/dataset/info?dsname=thailand_location
-
Result: there are three parts in the description of the dataset as follows
-
(1)
Concept: the scope of concept or class of ontology.
-
(2)
Property: all properties of the concept that include list of property names and labels.
-
(3)
Operators: operators of literal value for querying API include ‘CONTAINS’ for string value and ‘EQUALS’ (=), ‘GT’ (>), ‘LT’ (<), ‘GE’ (>=), ‘LE’ (<=) for number value comparison. Operator of querying API for object property is ‘IS-A’ operator.
-
(1)
-
-
3.
Querying by conditions: This API allows users to submit the parameters for querying by conditions. Each query condition consists of property, operator and value. The property and operator are selected from those returned by the API to obtain description of the dataset.


For example, a sample query to get the names of all districts located in the northern region (“ภาคเหนือ”) that contain the string “Chiang” (“เชียง”) in province names from the “Thailand Location” dataset can be formed as (Fig. 8):

Example API for querying a dataset by search conditions
-
Pattern of SPARQL query: in the above example, the API for querying by search condition using “AND” condition to supports more than one condition. There are two steps for query translation including getting IDs for all subjects and then using these IDs to query property value data as shown in Figs. 9 and 10.
Fig. 9. 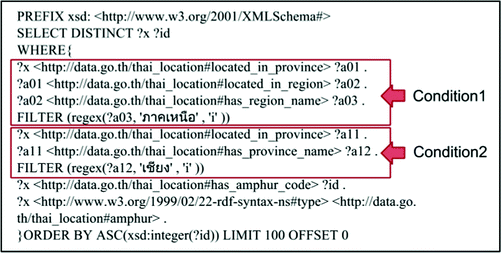
Example of SPARQL query for getting IDs of all results
Fig. 10. 
Example of SPARQL query to obtain all property values of the returned subjects


In Fig. 10, (1) specifies conditions of “FILTER” that use IDs returned from SPARQL query shown in Fig. 9 and (2) adds “OPTIONAL” clause in getting each property value.
4 Data Mashup
In this section, we present an implementation of dataset mashup in an application prototype, which consumes the data from the weather and reservoir statistics datasets via the provided APIs. In this application, the water volume levels in some selected dams are visualized together with the rainfall statistics of the same provinces. This application visualizes statistics data in various forms such as in google map, bar chart and table to allow the user to see the relations between rainfalls and water volume in reservoir. In consuming the data, we requested RESTFul APIs from Demo-api.data.go.th for two datasets: dam levels statistics (2011–2014) and rainfall statistics (2014). We manually obtained location information (latitude, longitude) of dams from Wikipedia. Figure 11 demonstrates the relationships between the user interface, APIs and data sources.

Sample application demonstrating the dataset mash-up
In terms of application development, accessing open data via RESTFul APIs is more convenient and more flexible comparing to manually collecting the full dataset files from Data.go.th. The query results from RESTFul APIs are in the more ready-to-use format. Developers also do not need to manually collect the data files. In terms of data mash-up, access to multiple datasets can be done in a uniform way through the RESTFul APIs, which allow the developers to programmatically combine the data from different datasets more conveniently.
5 Conclusion
In this paper, we present an RDF dataset management framework and system for publishing RDF datasets on Data.go.th based on the OAM framework. This system provides services such as database-to-ontology mapping and conversion of relational database to RDF/XML format. After publishing an RDF dataset on the portal, the system provides the form-based SPARQL and RESTFul APIs data querying services for each dataset automatically. Users who want to use the published data do not need to write SPARQL queries. With the uniform query pattern of the provided APIs, it can help users to reduce time in learning and developing an application from open government datasets comparing to using the dataset files. To demonstrate consuming the open data APIs, we implemented a sample mash-up application which utilized dataset querying APIs of multiple datasets from Demo-api.data.go.th. Our future work will extend the OAM framework to support namespace management of the datasets for better support of linked open data and to simplify the process of publishing RDF datasets on the portal.
Notes
- 1.
Csv2rdf4lod (http://data-gov.tw.rpi.edu/wiki/Csv2rdf4lod).
- 2.
OpenLink Virtuoso (http://virtuoso.openlinksw.com/).
- 3.
Grafter (http://grafter.org/).
- 4.
Information Workbench (http://www.fluidops.com/en/portfolio/information_workbench/).
- 5.
OpenRefine (http://openrefine.org/).
References
Huijboom, N., Van Den Broek, T.: Open data: an international comparison of strategies. Eur. J. ePract. 12, 1–13 (2011)
Ding, L., Lebo, T., Erickson, J.S., Difranzo, D., Williams, G.T., Li, X., Michaelis, J., Graves, A., Zheng, J.G., Shangguan, Z., Flores, J., McGuinness, D.L., Hendler, J.A.: TWC LOGD: a portal for linked open government data ecosystems. J. Web Semant. 9, 325–333 (2011)
Shadbolt, N., O’Hara, K., Berners-lee, T., Gibbins, N., Glaser, H., Hall, W., Schraefel, M.C.: Linked open government data: Lessons from data.gov.uk. IEEE Intell. Syst. 27, 16–24 (2012)
5 Star Open Data. http://5stardata.info/
Buranarach, M., Thein, Y.M., Supnithi, T.: A community-driven approach to development of an ontology-based application management framework. In: Lecture Notes Computing Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 7774, pp. 306–312 (2013)
About—PublicData.eu. http://publicdata.eu/about
DaPaaS|DaPaaS—a data-and-platform-as-a-service approach to efficient open data publication and consumption. http://project.dapaas.eu/
Kim, S., Kim, S., Berlocher, I., Lee, T.: RDF based linked open data management as a DaaS Platform LODaaS. In: The First International Conference on Big Data, Small Data, Linked Data and Open Data (2015)
Mouromtsev, D.I., Vlasov, V.V., Parkhimovich, O.V., Galkin, M., Knyazev, V.S.: Development of the St. Petersburg’s linked open data site using information workbench. In: 2013 14th Conference of Open Innovations Association (FRUCT), Espoo, pp. 77–82 (2013)
Maali, F., Cyganiak, R., Peristeras, V.: A publishing pipeline for linked government data. In: Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 7295, pp. 778–792 (2012)
Acknowledgments
This project was funded by the Electronic Government Agency (EGA) and the National Science and Technology Development Agency (NSTDA), Thailand.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG
About this paper

Cite this paper
Krataithong, P., Buranarach, M., Supnithi, T. (2018). RDF Dataset Management Framework for Data.go.th. In: Theeramunkong, T., Skulimowski, A., Yuizono, T., Kunifuji, S. (eds) Recent Advances and Future Prospects in Knowledge, Information and Creativity Support Systems. KICSS 2015. Advances in Intelligent Systems and Computing, vol 685. Springer, Cham. https://doi.org/10.1007/978-3-319-70019-9_4
Download citation
DOI: https://doi.org/10.1007/978-3-319-70019-9_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-70018-2
Online ISBN: 978-3-319-70019-9
eBook Packages: EngineeringEngineering (R0)