
Abstract
Image captioning has been a hot topic in computer vision and natural language processing. Recently, researchers have proposed many models for image captioning which can be classified into two classes: visual attention based models and semantic attributes based models. In this paper, we propose a novel image captioning system which models the relationship between semantic attributes and visual attention. Besides, different from the traditional attention models which don’t use object detectors and instead learn latent alignment between regions and words, we propose an object attention system which is capable to incorporate information output by object detectors and can better attend to objects when generating corresponding words. We evaluate our method on MS COCO dataset and our model outperforms many strong baselines.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
Thanks to the improvements on bandwidth of Internet and computation ability of computers, more and more data has been collected, and many advanced techniques for image understanding have been proposed. A fundamental problem that brings about development of these techniques is image classification whose target is to assign a label to each image. Further work have pushed its advances into progress on image captioning whose task is to not only identify objects in images, but also describe the relationship between them using language. Although image captioning has been studied for many years, the breakthrough comes from the encoder-decoder model in machine translation [4]. In machine translation, a RNN encodes a source sentence into feature vectors representation which is decoded into a target sentence by another RNN. Similarly, Vinyals et al. applies this philosophy to image captioning, an encoder CNN encodes an image into a feature representation while a decoder RNN decodes it into a sentence [18]. Further study on encoder and decoder model has branched into two directions: the visual attention based models [7, 21, 22] and the semantic based models [20, 24].
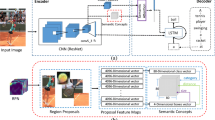
Despite the fact that rapid developments have been achieved these years, there still exists many problems. For example, as far as we are aware of, there is no research on how to combine visual attention with high level semantic information. In this paper, we propose a new image captioning system that combines object attention with attributes information. Figure 1 is a overview of our model. Our contributions are as follow: (i) We propose a new visual attention method: object attention. Different from Xu et al. [21] which attends to different position on CNN feature map, the attention of our model is shift among different objects in the images, which is more flexible and accurate. (ii) We propose a novel system that unifies object attention with attributes to guide image captioning. (iii) we reveal the effect of depth of LSTM on image captioning. (iv) We evaluate our method on MS COCO dataset [3] in offline and online manners. We show that our method outperforms many previous state of the art method [5, 18, 20, 21].

A overall architecture of our model. Our model contains three parts: attention layer, LSTM, probability output layer.
2 Related Work
Objects Detection: Recently, state of the art objects detection algorithm are based on region proposal and region based convolution network method [8, 13, 16]. Faster R-CNN one of the best objects detector won the MS COCO objects detection challenge in 2015. Its detection procedure contains two stages. Firstly, RPN regresses from anchors of different size and aspect ratio to region proposals and classify proposals into two class: foreground and background. Secondly, region based convolution neural network regresses from region proposals to bbox and tries to classify objects within it. In this paper, we use Faster R-CNN to detect objects in the images, and use the features vector, class label and position information of objects in images as input into our language model to generate caption.
Image Captioning: Recent state of the art method in image captioning is based on encoder-decoder model. The encoder is CNN while the decoder is LSTM in image captioning. Vinyals et al. [18] developed a simple encoder-decoder model. It encodes an image into a fixed-length feature vector representation which is fed into LSTM in the first step as initialization to decode it into image description. However, the image feature is only sent to LSTM in the first step and will gradually vanish as LSTM generates words. gLSTM overcomes this problem by sending guiding information to LSTM as it generates words [10]. After that, Xu et al. [21] proposed attention mechanism which was very popular in image captioning and visual question answering. In attention mechanism, each time before the LSTM generates a word, the attention layer will first predict likelihood of the CNN hidden state corresponding to the word. Then it is used as attention weight and the weighted sum over CNN feature maps is computed and sent to LSTM for generating words. The process doesn’t need any ground truth of attention weights and all need is images-sentence pairs. Fu et al. [7] also developed a visual attention algorithm which is based on region attention. Despite the effectiveness of attention mechanism, they don’t leverage high level semantic information such as attributes. To solve the problem, You et al. [24] developed an top down and bottom up approach to combine visual image features and high level semantic attributes information, Wu et al. [20] developed a region based multi-labels classification method to predict attributes which are fed info LSTM for caption generation. Recently, Yao et al. [23] tried to combine attributes information with image feature and devises five variants of structure by sending them in different placements and time moments. In this paper, we aim at combining two recently proposed and powerful methods in image captioning: visual attention and attributes. Our method fundamentally differs from [23] in the aspect that Yao proposed five variants of structure to model relationship between image feature and attributes while our method tries to incorporate visual attention and attributes into encoder-decoder models. What’s more, we devise a new visual attention method which is based on objects. Our attention method is fundamentally different from previous method [7, 21] in the way that the attention in our method are computed corresponding to a set of objects in images. We argue that our object attention method is better than former attention methods because attention weights in [21] are computed at fixed-size resolution and corresponding to pre-defined positions, which is not flexible and attention weights in [7] correspond to proposals which may don’t have explicit and meaningful information while our attention weights correspond to objects which are most salient parts of images and are of abundant information. What’s more, proposals don’t contain any class information which is very important to describe images while our models can utilize objects’ position and class information which are produced by Faster R-CNN. Besides, their method don’t incorporate semantic information into image captioning, while our method is able to employ attributes information to boost image captioning.
3 Model Description
Inspired by the recently popular attention method and attribute method in image captioning, we propose the object attention method and develop a new model to incorporate it and semantic attributes information into the encoder-decoder framework. The description generation process of our model shares similar spirits of human visual perception and can be divided into two phases. In the first phase, given a glimpse of the image, our model observes objects in the image and key words of it which are the most salient part of visual information and semantic information about the image respectively. In the second, our model attends to different objects while generating the sentence. We will first formulate image captioning problem, then describe each part of our model.
3.1 Problem Formulation
Image captioning is to describe an image I with a sentence S, where \( S=\{w_1,w_2\ldots w_n\} \) consisting of n words. The core idea of traditional CNN-RNN framework is to maximize the probability of generating the ground truth sentence. It can be formulated as follows:
where \( w_i \) is the \(i_{th}\) word of the sentence S, \( w_1,w_2\ldots w_{i-1} \) represent words from time step 1 till \(i-1\) and \( p(w_i|I,w_1,w_2\ldots w_{i-1}) \) is the probability of generating word \( w_i \) given previous words \( w_1,w_2\ldots w_{i-1} \).
We adapt the traditional CNN-RNN framework by guiding it with two additional information: high level image attributes information \( \mathbf A \in \mathbb {R}^{D_a} \) and attention context information \( C_t \in \mathbb {R}^{D_C} \). We formulate image captioning problem by maximizing the equation as follows:
To be specific, given an image I, we first represents it in a sequential manner \( seq(I)=\{O_1, O_2\ldots O_m\} \) where \( O_1 \text { to } O_{m-1} \) are object representations and \( O_m \) encodes global image information by sending whole image to CNN. Then our attention layer shifts attention among different objects \( \{O_1, O_2\ldots O_m\} \) and generates attention context information \( C_t\). Because object representations only contain local visual information and lack global semantic information of the image, we follow the weakly supervised multi-instance learning method used in [6] for semantic attributes \( \mathbf A \) detection. At last, both context \( C_t \) and \( \mathbf A \) are sent to LSTM and probability output layer for word generation. Our model can be seen in Fig. 1 and we will depict our attention layer, the structures of two kinds LSTM and probability output layer in Sects. 3.2, 3.3 and 3.4 respectively.
3.2 Object Attention Layer
Before generating word \( w_t \) at time step t, our attention layer attends to the object which corresponds to word \( w_t \) based on previous LSTM hidden state \( h_{t-1} \) which contains history information. Our object attention layer shares the similar spirit of soft attention in [1, 21]. However, our model is different from them. Attention weights in [21] are computed at fixed-size resolution and corresponding to pre-defined positions in an image while attention weights in our model correspond to objects, which is more flexible and accurate. Besides, Xu et al. [21] doesn’t use any semantic information while we leverage the global semantic attributes information A to help attention layer predict attention better. Suppose we have a sequence of object representations \( \{O_{1},O_{2}\ldots O_{m}\} \), image attributes \( \mathbf A \) and previous LSTM output \( h_{t-1} \), we adapt attention layer used in [21] to accept three inputs. It is formulated as follows:
where \( W_e\in \mathbb {R}^{1 \times d} \), \( W_{a}\in \mathbb {R}^{d \times d} \), \( W_{h}\in \mathbb {R}^{d \times d} \) and \( W_{o}\in \mathbb {R}^{d \times d} \) are parameters of the layer. According to (4), (5), our object attention layer first predicts all objects’ scores \( \alpha _{ti} \) which represents how much attention should been given to the object \( O_i \). Then the object attention layer output \( C_t \) which represents attention context vector used to generate the word.
3.3 LSTM Structures
Recurrent neural network (RNN) has been widely used in sequence to sequence learning, such as machine translation, speech recognition and image captioning. LSTM [9] is a kind of recurrent neural network with additional four gates which are aimed at solving gradients explosion and vanishing problem. Its update process can be formulated as follows:
where \( W_{tj}(t\in \{i,f,o,g\},j\in \{h,x\}) \) is the connection matrix; \( \sigma \) is the sigmoid non-linearity operator, and \( \phi \) is the hyperbolic tangent non-linearity operator; \( i _{t},f _{t},o _{t},g_{t}\) are input gate, forget gate, output gate and input modulation gate respectively; \( h_{t}, c_{t} \) are hidden state and memory cell; \( x_{t} \) is the input to LSTM unit; \( \odot \) is the element-wise dot product operator.
Different from traditional framework, we have tried two LSTM structures and studied their effects on image captioning. In this paper, we first use the basic LSTM namely LSTM-1. Then we try its deeper version: LSTM-2 which has two layers. The detailed structures of LSTM-1 and LSTM-2 will be described in the following section.
LSTM-1. In order to incorporate context \( C_t \), and attributes \( \mathbf A \) into LSTM, we design a basic LSTM structure: LSTM-1. Unlike LSTM in [18, 21], LSTM-1 can incorporate attributes into it. Unlike [23], LSTM-1 can make use of recently popular attention mechanism as an additional input. Here we give a detailed introduction of our basic LSTM model LSTM-1. It can be formulated as follows:
where \( \mathbf A , C_t, w_{t-1} \) are attributes, context, previous word respectively; \( U_i(i\in \{a,c,s\})\) is weight matrix of LSTM-1; f represents the LSTM unit in (6)–(11).
At each step, previous word \(w_{t-1} \), attributes A and context \( C_t \) are combined into a compact and abstract vector representation \( x_t \) which is sent to the LSTM unit as input to generate word \( w_t \) until an “END” is emitted. At the initial step, \(w_{0} \) is set to “START”, and the initial states of LSTM \( h_0,c_0\) are predicted by an average of objects representation fed through a multi-layers perceptron. It can be formulated as follows:
where \( f_{init,h},f_{init,c} \) are both multi-layers perceptron and are used to predict hidden state \( h_0 \) and memory cell \( c_0 \) of LSTM at initial time step.
LSTM-2 (Two Layers of LSTM). Generally speaking, deeper networks have better ability to fit and grasp pattern in training data and performs better on more complicate task. Inspired by this philosophy, we try a deeper version of LSTM-1: LSTM-2 which is a LSTM with two layers. The state update procedure is formulated as follows:
where \( \mathbf A , C_t, w_{t-1} \) are three inputs: attributes, context, previous generated word; \( f^1, f^2 \) are the first layer and second layer of LSTM; \( x_t^1 \) is a compact vector combing all the information of the three inputs and is fed into the first layer of LSTM; \( x_t^2 \) is the input into the second LSTM layer; \( h_t^1,h_t^2 \) are the hidden state of first LSTM and second LSTM units at time step t; \( W _{a},W _{c},w_{t-1}\) are embedding matrix of the LSTM-2.
3.4 Probability Output Layer
The word \( w_t \) to be generated at time step t is closely connected with history information about previous words and visual information about the image. So we design the probability output layer to incorporate information of attention context information \( C_t \), high level attributes A, previous word \( w_t \) and LSTM hidden state \( h_t \) to outputs probability \( P_t \) over words in vocabulary. It is represented as:
where \( f_P \) is a multilayer perceptron whose weights are randomly initialized.
4 Experiments
We test our models on the most widely used image captioning dataset MS COCO [3] and evaluate them in two ways: the offline evaluation and online evaluation. For offline evaluation, we follow the split used in [11] and report results. For online evaluation, we evaluate our method on the MS COCO 2014 test server and compare our method with previous state of the art methods.
4.1 Dataset
MS COCO dataset contains 160k images which are split into 80k training images, 40k validation images and 40k testing images. Each image in the MS COCO dataset has at least five sentences which are labelled by workers.
4.2 Experimental Settings
Data Processing. We follow the data splits in [11]. We convert all captions into lower case and discard words which appears less than five times. That results in a vocabulary of 8791 words.
Training Parameter Settings. We train our model with a batch size of 100 and early stop training to prevent Overfitting after about 40000 iterations which is about 50 epochs. Our learning rate is set to \(1 \times 10 ^{-4}\) and our optimization method is Adam [12].
Inference. We use beam search method in inference stage and find that performance is best when beam size is set to 4.
Evaluation Metric. We evaluate our model with four metrics BLEU@N [15], METEOR [2], ROUGE-L [14], CIDER [17]. All metrics are computed by the code https://github.com/tylin/coco-caption which is released by MS COCO server.

Some examples of aligning objects with words to be generated. Many words in sentence corresponds well to visual objects in the images. The brighter object mean more attention is being allocated to it. We also show the image’s attributes which is able to provide global semantic information to attention layer.

More cases of attention transitions during the sentence generation
4.3 Performance Comparison
We compare our method with previous state of the art method in offline and online ways. In offline evaluation manner, we compare our results with others’ in Table 1 and can conclude that our method outperforms previous state of the art method by a large margin. This proves the effectiveness of the combination of two powerful mechanisms: object attention and attributes. Object attention mechanism shifts attention among different objects in the image and provides salient visual information about the word to be generated. But attention mechanism focuses on local regions and lacks global semantic information. So we provide our model with additional input: attributes information. We have also compared two variants structure Attributes + attention + LSTM-1, Attributes + attention + LSTM-2. We are surprised to find that LSTM-1 outperforms its deeper version LSTM-2, which means that deeper LSTM structure are not necessarily beneficial for performance and in fact that deeper recurrent network is more difficult to train and loss drops slower. So in later online evaluation, we only report performance of our LSTM-1.
To better prove the effectiveness of our method, we have compared our method on MS COCO server and results are in Table 2. We can see that our method outperforms previous state of the art methods in many metrics especially in CIDEr [17] which is specially designed for image captioning and more convincing than other metrics which are designed for machine translation.
Results on online evaluation and offline evaluation prove the effectiveness of object attention and attribute. In fact, both the method can improve image captioning performance and unifying them can boost image captioning greatly.
4.4 Case Study and Visualization
To better show the effectiveness of our method. We have shown in Fig. 2 image attributes and the shift of attention in process of generating caption. From the first two rows, we can see that our model can align words to be generated and objects in images. Before generating words such as cat and standing, our model first attends to the region of cat in the images. While before generating words such as bottle and wine, our model attends to the region of bottle first. It has strongly proven the effectiveness of object attention method and cast light on what is happening when it generates caption. More cases of attention transitions in process of sentence generation can be seen in Fig. 3. Besides, we can also see that many words in attributes are used for captioning. Taking first image for example, many of its attributes such as cat, wine, bottle, standing appear in its final captioning. It has illustrated that attributes of images are beneficial to image captioning and some words in attributes may even be used in caption.
5 Conclusion
In this paper, we propose a new visual attention: object attention, and combine it with image attributes within two models. We compare our method with previous state of the art methods in online evaluation and offline evaluation manners. From Table 1, we can see that our method outperforms other previous state of the art method by a large margin in offline evaluation manner. From Table 2, we can see that our method achieves comparable results to other state of the art methods, and ranks top three when compared to other state of art method on all metrics. We conclude that attributes combined with object attention can greatly boost image captioning performance.
References
Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 (2014)
Banerjee, S., Lavie, A.: Meteor: an automatic metric for MT evaluation with improved correlation with human judgments. In: Proceedings of the ACL workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, vol. 29, pp. 65–72 (2005)
Chen, X., Fang, H., Lin, T.Y., Vedantam, R., Gupta, S., Dollár, P., Zitnick, C.L.: Microsoft coco captions: data collection and evaluation server. arXiv preprint arXiv:1504.00325 (2015)
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., Bengio, Y.: Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078 (2014)
Donahue, J., Anne Hendricks, L., Guadarrama, S., Rohrbach, M., Venugopalan, S., Saenko, K., Darrell, T.: Long-term recurrent convolutional networks for visual recognition and description. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2625–2634 (2015)
Fang, H., Gupta, S., Iandola, F., Srivastava, R.K., Deng, L., Dollár, P., Gao, J., He, X., Mitchell, M., Platt, J.C., et al.: From captions to visual concepts and back. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1473–1482 (2015)
Fu, K., Jin, J., Cui, R., Sha, F., Zhang, C.: Aligning where to see and what to tell: image captioning with region-based attention and scene-specific contexts. IEEE Trans. Pattern Anal. Mach. Intell. (2016)
Girshick, R.: Fast R-CNN. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1440–1448 (2015)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Jia, X., Gavves, E., Fernando, B., Tuytelaars, T.: Guiding the long-short term memory model for image caption generation. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2407–2415 (2015)
Karpathy, A., Fei-Fei, L.: Deep visual-semantic alignments for generating image descriptions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3128–3137 (2015)
Kingma, D., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Li, Y., He, K., Sun, J., et al.: R-FCN: object detection via region-based fully convolutional networks. In: Advances in Neural Information Processing Systems, pp. 379–387 (2016)
Lin, C.: Recall-oriented understudy for gisting evaluation (ROUGE), 20 August 2005
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: BLEU: a method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, pp. 311–318. Association for Computational Linguistics (2002)
Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: towards real-time object detection with region proposal networks. In: Advances in Neural Information Processing Systems, pp. 91–99 (2015)
Vedantam, R., Lawrence Zitnick, C., Parikh, D.: Cider: consensus-based image description evaluation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4566–4575 (2015)
Vinyals, O., Toshev, A., Bengio, S., Erhan, D.: Show and tell: a neural image caption generator. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3156–3164 (2015)
Wang, C., Yang, H., Bartz, C., Meinel, C.: Image captioning with deep bidirectional LSTMs. In: Proceedings of the 2016 ACM on Multimedia Conference, pp. 988–997. ACM (2016)
Wu, Q., Shen, C., Liu, L., Dick, A., van den Hengel, A.: What value do explicit high level concepts have in vision to language problems? In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 203–212 (2016)
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., Zemel, R., Bengio, Y.: Show, attend and tell: neural image caption generation with visual attention. In: International Conference on Machine Learning, pp. 2048–2057 (2015)
Yang, Z., Yuan, Y., Wu, Y., Cohen, W.W., Salakhutdinov, R.R.: Review networks for caption generation. In: Advances in Neural Information Processing Systems, pp. 2361–2369 (2016)
Yao, T., Pan, Y., Li, Y., Qiu, Z., Mei, T.: Boosting image captioning with attributes. arXiv preprint arXiv:1611.01646 (2016)
You, Q., Jin, H., Wang, Z., Fang, C., Luo, J.: Image captioning with semantic attention. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4651–4659 (2016)
Acknowledgement
This work was supported by the National Natural Science Foundation of China under Grant 61673234.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper

Cite this paper
Li, C., Chen, J., Wan, W., Li, T. (2017). Combining Object-Based Attention and Attributes for Image Captioning. In: Zhao, Y., Kong, X., Taubman, D. (eds) Image and Graphics. ICIG 2017. Lecture Notes in Computer Science(), vol 10666. Springer, Cham. https://doi.org/10.1007/978-3-319-71607-7_54
Download citation
DOI: https://doi.org/10.1007/978-3-319-71607-7_54
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-71606-0
Online ISBN: 978-3-319-71607-7
eBook Packages: Computer ScienceComputer Science (R0)
