
Abstract
The Classification and Regression Tree (CART) recursively partitions the measurement space, displaying the resulting partitions as decision tree. However, the performance of CART-based decision tree degrades while dealing with high-dimensional large data sets. This research work studies CART, based on Maximum Probabilistic-based Rough Set (MPBRS). The MPBRS has been used as a tool for insignificant data reduction without sacrificing information content. This paper also studies CART, based on Pawlak rough set and Bayesian Decision Theoretic Rough Set (BDTRS) for comparative analysis. Experimental results on three different data sets show that the MPBRS-based CART constructs improved decision tree for better classification efficiency.
Similar content being viewed by others
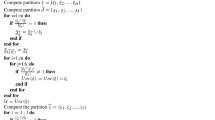


Keywords
1 Introduction
The CART [3, 10, 17] is a sophisticated Decision Tree [11, 12] algorithm. It is direct viewing, can extract knowledge rules preferably and suitable to deal with classification problems [21]. It outperforms several other popular decision tree algorithms with respect to simplicity, comprehensibility, classification accuracy and being able to handle mixed-type data. Moreover CART efficiently deals with missing values, uses cost-complexity pruning strategy and can handle outliers. But, when the data has large number of attributes and involves impurity, the decision tree constitutive property is poor and difficult to find some information that could have been found and be useful. Another problem with the CART cross validation method is that it can be computationally too expensive, because it requires the growing and pruning of auxiliary trees as well. In order to overcome these drawbacks, rough set based attribute reduction has been introduced. Ever since the introduction of rough set theory by Pawlak [9] in 1982, many extensions have been made [16, 19, 20, 22]. The MPBRS [7, 9] is an excellent rough set based tool for attribute reduction. The indiscernibility relation and set approximation remains unaltered before and after reduction. The positive region computed, involves maximum number of objects. As a result the reduced attribute set involves all the significant attributes eliminating all insignificant attributes. This paper also studies CART based on Pawlak rough set [9] and BDTRS [1, 2, 8] for attribute reduction. In this research work we have used R [4, 6, 13], version 3.2.2, for experimentation and implementation of MPBRS. Data sets have been taken from UCI Machine learning repository.
In Sect. 2, Pawlak rough set, BDTRS, MPBRS and CART are introduced. Section 3, discusses about processing steps, algorithm and execution process in R environment. Experimental results and concluding remarks are presented in Sects. 4 and 5 respectively.
2 Theoretical Background
2.1 Pawlak’s Rough Set Model [9, 13]
An information system is defined as: \( S = (U, At,\left\{ { V_{a } | a \in At} \right\}, \,\left\{ {I_{a} | a \in At} \right\}), \) where, \( U_{ } \) is a finite nonempty set of objects, \( At \) is a finite nonempty set of attributes, \( V_{a} \) is a nonempty set values of \( a \in At \) and \( I_{a} :U \to V_{a} \) is an information function that maps an object in \( U \) to exactly one value in \( V_{a} \). The approximations of \( X \subseteq U \) with respect of equivalence relation \( R \) can be defined according to its upper and lower approximations.
Positive region:
Negative region:
Boundary region:

2.2 Bayesian Decision Theoretic Rough Set [1, 2, 8, 15]
Let, \( D_{POS } \) denotes the positive region in BDTRS model. For an equivalence class, \( \left[ x \right]_{c} \in \pi_{A} \),
For equivalence classes \( \left[ x \right]_{c} \) and \( \left[ y \right]_{c} \) the elements of a positive decision-based discernibility matrix, \( M_{{D_{pos} }} \) is defined as follows.
A positive decision reduct is a prime implicant of the reduced disjunctive form of the discernibility function.
In order to derive the reduced disjunctive form, the discernibility function \( f\left( {M_{{D_{POS} }} } \right) \) is transformed by using the absorption and distributive laws. Accordingly, finding the set of reducts can be modeled based on the manipulation of a Boolean function.
2.3 Maximum Probabilistic Based Rough Set [7, 9, 18]
Maximum probabilistic based rough set is a stronger form of other rough set models.
The precision of an equivalence class \( \left[ x \right]_{c} \in \pi_{c} \) for predicting a decision class \( D_{i} \in \pi_{D} \) can be defined. We denote it by \( P_{max} (D_{i} ,\left[ x \right]_{c} ) \) and are defined as follows:
For a decision class, \( D_{i} \in \pi_{D} , \) the Maximum probabilistic based rough set lower and upper approximations with respect to a partition \( \pi_{c} \) can be defined as:
The positive, boundary and negative regions of \( D_{i} \in \pi_{D} \) with respect to \( \pi_{C} \) are defined by:
Attribute Significance [9].
The consistency factor is defined as \( \gamma \left( {C,D} \right) = \left| {POS_{C} \left( D \right)} \right|/\left| U \right| \). The decision table is consistent if \( \gamma \left( {C,D} \right) = 1 \). The significance, \( \sigma \left( a \right), \) of any attributes \( a, \) can be defined as:
Where, \( 0 \le \sigma \left( a \right) \le 1 \).
2.4 Decision Tree: CART [3, 10, 11, 17]
The CART algorithm starts with the initial decision table (data set) \( D, \) attribute set \( At \) and gini-index, as attribute selection method. Initially, it creates a node, \( N, \) which incorporates \( D. \) If all the objects of \( D \) belong to same class, node \( N \) is returned as leaf node. Otherwise, select a condition attribute (that maximizes the reduction in impurity of \( D \)) that divides \( D, \) in a manner such that height of the tree is as small as possible. The node \( N \) is labeled with the selected attribute. After that, branches are grown from \( N \) for each of the outcomes of the splitting attributes. The algorithm works recursively on each subset of \( D. \) Recursion may stop in one of these cases:
-
All the objects of a node belong to a particular class (same class).
-
There are no attributes left on which the objects may be further be separated.
-
There are no objects for a particular branch and a partition is empty.
Gini Index.
CART uses Gini-index for choosing the best attribute in the process of data partition. The Gini-index for a data set \( D, \) having \( m \) decision classes is calculated as:
Where p i is the probability that an object in \( D \), belongs to class \( C \). If a binary partition on condition attribute \( A, \) partitions \( D \) into subsets \( D_{1} \) and \( D_{2} \), the Gini-index, given that partitioning is:
For every attribute, all of the possible splits are calculated. For a particular attribute, the point producing the lowest Gini index is chosen as the split point. Reduction in impurity on a condition attribute \( A, \) is:
The condition attribute that results in maximum reduction of impurity is chosen as the splitting attribute.
3 Implementation of MPBRS-Based CART
3.1 Processing Steps
This section shows the implementation and execution procedure for MPBRS-based CART. Implementation of BDTRS is done in [8]. MPBRS-based decision tree induction is performed in two basic steps. First, attribute reduction and second, decision tree induction using the reduced information. Procedure for attribute reduction is shown in Algorithm-1(AttReduction ()). Case: 1, Case: 2 and Case: 3 represent MPBRS, BDTRS and Pawlak rough set respectively for attribute reduction. Based on rough set theory equivalent classes [9] are computed. Procedure for computation of positive region, discernibility matrix [15], discernibility function [19] and reduced attribute set are shown in Algorithm-1. The discernibility function is a conjunction over the disjunction of the matrix elements. The function can be transformed in to a reduced attribute set using absorption and distributive laws of Boolean algebra. The classical CART is implemented in package ‘rpart’ of R. Induction of decision tree using R commands has been shown in Sect. 3.3.
3.2 Algorithm

3.3 Execution of CART and MPBRS-Based CART in R Environment
Decision Tree Induction Using CART.
This section explains decision tree induction by taking housing [5] as example data set. Installation procedure of R and relevant packages (“RoughSets” [14], “rpart” etc.) are available in Comprehensive R Archive Network (CRAN). In order to perform attribute reduction, raw data (in .txt, .csv, .xlsx etc. format) is first converted into data frame object which is then converted into DecisionTable format. For this, functions like read.table(), SF.asDecisionTable() [14] may be used. The package “rpart” is installed using the R command: > library(rpart). Similarly other packages like “rattle”, “caret”, “RoughSets” etc. are also installed. The Decision Tree, T1 obtained from the following commands is shown in Fig. 1.

Decision Tree T1 using CART method (Left hand side), before attribute reduction and Decision Tree T2 using MPBRS-CART() method (Right hand side) after attribute reduction.

Decision Tree Induction Using MPBRS-Based CART.
MPBRS-based CART is inducted in two steps. Step 1: Performs data reduction by MPBRS. Step2: Decision Tree induction based on the output of Step 1. Following R commands are executed on housing data set (housing.csv format). Reduced attribute set is shown in Table 1.

The procedure for decision tree induction is same as CART and hence not repeated. The decision tree (T2) thus obtained is shown in Fig. 1.
4 Experimental Results and Discussion
The data sets used for experimentation are: Cervical Cancer (858 objects with 36 attributes) [23], Spambase (4601 objects with 57 attributes) [24] and housing (506 objects with 14 attributes). The housing data set is already introduced in the previous section. Each of these data sets has been studied by MPBRS, BDTRS and Pawlak rough set. For housing data, at first, we pre-processed the sample data (D) and filled in missing values using built in functions available in R. Next, we run the original algorithm CART, on D, to construct a Decision Tree T1 as shown in Fig. 1.
After that, we run Case: 1 of Algorithm-1 (attribute reduction by MPBRS) to reduce the insignificant attributes of D. We reduced the number of attributes down to 9, saved the new sample data set as D red . The deleted attributes are: ‘ZN’, ‘NOX’, ‘PTRATIO’ and ‘INDUS’. We computed attribute significance of all the attributes to show that deleted attributes have little effect on decision making. This is shown in Table 1. We further computed consistency factor (C.F) (shown in Table 2) which remains same (one) before and after attribute reduction. This ensures that the integrity of the data set remains unchanged after attribute reduction. Finally, we run CART on the reduced data set D red , to construct a simplified decision tree, T2 (Fig. 1). The above mentioned experimental procedure is repeated using the functions AttReduction() (Algorithm-1) and CART method for Cervical Cancer and Spambase data sets. The results obtained from the computations are shown in Table 2.
For housing data, tree T1, shows that the classification tree has 15 nodes (7 internal and 8 leaf nodes). On the other hand, Tree T2, of Fig. 1 shows that the classification tree has 11 nodes (5 internal and 6 leaf nodes). The domain of decision column (Minimum: 5 and Maximum: 50) is divided in to six equivalent classes: C1, C2, C3, C4, C5 and C6. There are eight (8) classification rules corresponding to the leaf nodes of T1 and six (6) rules corresponds to T2. For example, the classification rule: “If (RAD <= 3) and (B <= 300) and (LSTAT > 11.5) and (INDUS <= 9.7) then MEDV = C5”, corresponds to leaf node C5 of tree T1. Similar results obtained from the other two data sets and the comparison of CART, MPBRS-CART, BDTRS-CART and Pawlak-CART methods are shown in the Table 2. It can be observed from Table 2 that CART model deals with the original unreduced data set, whereas, other three approaches work on the reduced data set. The MPBRS method gives the best attribute reduction. As a result, number of nodes, number of leaf nodes, depth and average length of the classification rules has been decreased for all the three approaches except classical CART Model. This ultimately improves the classification accuracy of the decision trees as shown in Fig. 2.

Classification accuracy of CART, MPBRS-CART, BDTRS-CART and Pawlak based CART on Cervical Cancer, Spambase and housing data sets.
On the other hand, the rough set based decision tree approach suffers in terms of total execution time as it involves the attribute reduction phase also. The minimal increase of execution time is acceptable, keeping the classification accuracy and reduction of tree complexity (shown in Fig. 3) in mind. Tree complexity mainly depends on the average length of the decision rules which is lowest in case of MPBRS-based CART method for all data sets.

Complexity representation of CART, MPBRS-CART, BDTRS-CART and Pawlak based CART on Cervical Cancer, Spambase and housing data sets.
5 Conclusion
Efficiency of CART-based decision tree becomes an issue of concern to deal with high-dimensional large data sets. This study focuses on reducing number of insignificant attributes from the original data set before induction of CART-based decision tree. The reduced attribute set preserves the indiscernibility relation and set approximation. This is ensured by computing attribute significance and consistency factor. In this research work we have also implemented the MPBRS using R language in order to study the classical CART. The experimental results show that the decision tree induced by MPBRS-based CART is the simplest and most efficient in terms of depth, number of nodes, average rule length and classification accuracy compared to the other methods mentioned in this work.
References
Bhattacharya (Halder), S.: A study on Bayesian decision theoretic rough set. Int. J. Rough Sets Data Anal. (IJRSDA) 1(1), 1–14 (2014)
Bhattacharya (Halder), S., Debnath, K.: Attribute reduction using Bayesian decision theoretic rough set models. Int. J. Rough Sets Data Anal. (IJRSDA) 1(1), 15–31 (2014)
Breiman, L., Friedman, J.H., Olshen, R.A., Stone, C.J.: Classification and Regression Trees. Wadsworth & Brooks/Cole Advanced Books & Software, Monterey (1984). ISBN 978-0-412-04841-8
Ferraro, M.B., Giordani, P.: A toolbox for fuzzy clustering using the R programming language. Fuzzy Sets Syst. 279, 1–16 (2015). Elsevier
Harrison, D., Rubinfeld, D.L.: Hedonic prices and the demand for clean air. J. Environ. Econ. Manag. 5, 81–102 (1978)
Ihaka, R., Gentleman, R.: R: a language for data analysis and graphics. J. Comput. Graph. Stat. 5, 299–314 (1996)
Pal, U., Bhattacharya (Halder), S., Debnath, K.: A Study on Maximum Probabilistic Based Rough Set (MPBRS), Communicated
Pal, U., Bhattacharya (Halder), S., Debnath, K.: R implementation of bayesian decision theoretic rough set model for attribute reduction. In: Bhattacharyya, S., Sen, S., Dutta, M., Biswas, P., Chattopadhyay, H. (eds.) Industry Interactive Innovations in Science, Engineering and Technology. LNNS, vol. 11, pp. 459–466. Springer, Singapore (2018). https://doi.org/10.1007/978-981-10-3953-9_44
Pawlak, Z.: Rough sets. Int. J. Comput. Inform. Sci. 11, 341–356 (1982)
Questier, F., Put, R., Coomans, D., Walczak, B., Vander Heyden, Y.: The use of CART and multivariate regression trees for supervised and unsupervised feature selection. Chemometr. Intell. Lab. Syst. 76(1), 45–54 (2005). https://doi.org/10.1016/j.chemolab.2004.09.003. ISSN 0169-7439
Quinlan, J.R.: Induction of decision trees. Mach. Learn. 1, 81–106 (1986)
Quinlan, J.R.: Simplifying decision trees. Int. J. Man-Mach. Stud. 27, 221–234 (1987)
R Development Core Team: R: A Language and Environment for Statistical Computing. The R Foundation for Statistical Computing, Vienna (2011). http://www.R-project.org/. Accessed 08 June 2016. ISBN 3-900051-07-0
Riza, L.S., Janusz, A., Bergmeir, C., Cornelis, C., Herrera, F., Slezak, D., Benitez, J.M.: Implementing algorithms of rough set theory and fuzzy rough set theory in the R package ‘‘RoughSets’’. Inf. Sci. 287, 68–89 (2014). Elsevier
Skowron, A., Rauszer, C.: The discernibility matrices and functions in information systems. In: Slowiski, R. (ed.) Intelligent Decision Support. Handbook of Applications and Advances of the Rough Set Theory, pp. 311–362. Kluwer Academic Publishers, Dordrecht (1992)
Slezak, D., Ziarko, W.: Bayesian rough set model. In: Proceedings of the International Workshop on Foundation of Data mining, Japan, pp. 131–135 (2002)
Stuart, L.C.: Extensions to the CART algorithm. Int. J. Man-Mach. Stud. 31(2), 197–217 (1989). https://doi.org/10.1016/0020-7373(89). ISSN 0020-7373
Yao, Y.Y.: Generalized rough set models. In: Polkowski, L., Skowron, A. (eds.) Rough Sets in Knowledge Discovery, pp. 286–318. Physica-Verlag, Heidelberg (1998)
Yao, Y.Y.: Probabilistic approaches on rough sets. Expert Syst. 20, 287–297 (2003)
Yao, Y.Y., Wong, S.K., Lingras, P.: A decision theoretic rough set model. In: Ras, Z.W., Zemankova, M., Emrich, M.L. (eds.) Methodologies for Intelligent Systems, vol. 5, pp. 17–24. North Holland, New York (1990)
Zhiling, C., Qingmin, Z., Qinglian, Y.: A method based on rough set to construct decision tree. J. Nanjing Univ. Technol. 27, 80–83 (2005)
Ziarko, W.: Variable precision rough set model. J. Comput. Syst. Sci. 46, 39–59 (1993)
https://archive.ics.uci.edu/ml/datasets/Cervical+cancer+%28Risk+Factors%29. Accessed 21 June 2017
http://archive.ics.uci.edu/ml/datasets/Spambase. Accessed 21 June 2017
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper

Cite this paper
Pal, U., Bhattacharya (Halder), S., Debnath, K. (2017). A Study on CART Based on Maximum Probabilistic-Based Rough Set. In: Ghosh, A., Pal, R., Prasath, R. (eds) Mining Intelligence and Knowledge Exploration. MIKE 2017. Lecture Notes in Computer Science(), vol 10682. Springer, Cham. https://doi.org/10.1007/978-3-319-71928-3_39
Download citation
DOI: https://doi.org/10.1007/978-3-319-71928-3_39
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-71927-6
Online ISBN: 978-3-319-71928-3
eBook Packages: Computer ScienceComputer Science (R0)