
Abstract
Discovering of attributes is a challenging task in computer vision due to uncertainty about the attributes, which is caused mainly by the lack of semantic meaning in image parts. A usual scheme for facing attribute discovering is to divide the feature space using binary variables. Moreover, we can assume to know the attributes and by using expert information we can give a degree of attribute beyond only two values. Nonetheless, a binary variable could not be very informative, and we could not have access to expert information. In this work, we propose to discover linear regressive codes using image regions guided by a supervised criteria where the obtained codes obtain better generalization properties. We found that the discovered regressive codes can be successfully re-used in other visual datasets. As a future work, we plan to explore richer codification structures than lineal mapping considering efficient computation.
B. Peralta—This author was partially funded by FONDECYT Initiation grant 11140892.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
An important task in computer vision is the recognition of specific people considering semantic attributes. As an application, we could search for people with similar characteristics to a particular person, or we could find visual similarities between two people. An usual scheme is considering attributes as binary variables, where the attribute codes gives the answer to question: Has the image such attribute? On the other hand, we can consider multiple-valued attributes where they are more informative than binary attributes which should lead to better visual recognizers.

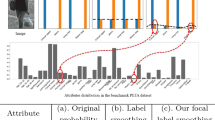
(a) DBC roughly divides data considering the presence of the attribute, which can be seen as “green-cloth”. (b) On the other hand, DRC estimates the degree of a particular objectness, in this case “green-cloth-ness” of image. Note that DRC codification is only guided by a joint optimization of codes, therefore it obtains a richer codification than the given by DBC.
For such reason, we propose to use a variation of relative attributes (Parikh and Grauman, [1]), where the attributes consider an order relationship instead of a binary criteria. In our work, we associate an arbitrary ordinal codification to the set of codes located on particular image regions; this codification implies that it exists a hidden and meaningful regressive localized relationship between classes. These ordinal codifications are not evident; but for example we can imagine a ‘t-shirt degree’ for the mid part of a clothed person. Our goal is learning pedestrian-specific mid-level features as regression codes. In contrast to Discriminative Binary Codes (DBC) [2], we associate the classifiers to some specific region of image and they are more expressive as we use real values to codes. On the other hand, [1] uses a attribute-labelled datasets and they use a discrete code based on ranks; in our case, we have not access to attribute information and we also obtain a more flexible codification than discrete codification. As we use regression in our proposed codification, we call our technique as Discriminative Regression Codes (DRC).
The attribute-based techniques show similarities to mid-level features based techniques, however, they are different in that while the first obtains a compressed coding of data, the second simultaneously obtains a classifier with a mid-level codification. For example, Lobel et al. [3] propose to jointly learn mid-level and top-level features and the classifier for object recognition tasks. Their optimization model is oriented to discriminate between different classes using mid-level features with a max-margin approach. In contrast, a standard attribute learning model is oriented to the discovery of attributes, where the codification of samples with the same class must be similar and the codification of samples with different classes must be different; that is, the class information is used laterally. Moreover, an image is codified using a fixed set of attributes, which is expected to be smaller than the original features sets.
The difference between DBC and DRC techniques can be visualized in Fig. 1. While DBC learns a binary code in a unsupervised fashion, we observe that it loses valuable information. On the other hand, DRC is designed to assign a code oriented to measure a particular attribute of an image. In the figure, this attribute is the “green-cloth-ness” degree. In this paper, we make the following contributions: (1) We present a method to learn unsupervised discriminative regressive codes (DRC); and (2) we apply our method in person re-identification problems considering a transfer learning approach.
2 Our Approach
2.1 Proposed Method
We assume a training set \({(x_i, y_i)}\) with N records where the index \(i \in {1, \ldots , N}\). Each training record is represented by a low-level d visual features, \(x_i \in \mathfrak {R}^d\), and the labels \(y_i \in {1, \ldots , C}\) where C is the number of classes. Our objective is to represent each low-level feature \(x_i\) by an intermediate attribute representation \(R^i = {[R^i_1, R^i_2, \ldots , R^i_K]}\) as we consider K regression codes with \(K \ll d\) which generates a compressed data representation. To train each k-th regression code, we need to learn the output for each training record. The output is given by the prediction of regression given by support vector machine (SVM) models over each training record. Our proposed method mainly comprehends two stages: (i) Attribute initial selection and (ii) Attribute training.
(i) Attribute initial selection
Initially, we consider a simple strategy that consists of randomly assigning regression codes for all training records, but we found that this method has poor results i.e. typically with less of \(5\%\) to \(10\%\) of accuracy respect to the best found method of initialization. This reveals that it is necessary a careful initialization in order to obtain an reliable model.
Our procedure assumes that the number of codes is L. First, we apply PCA to training dataset and store the L principal components. Then, we apply these components to data in order to obtain a codification with L components. Finally, we normalize the data considering the range \(\left[ 0,1\right] \). We believe that there are better ways to initialize the codes and we left them as future research avenues. It is relevant because the initialization appears to be a decisive factor of accuracy.
(ii) Attribute training
Considering as initial code values given by PCA procedure, we jointly train all them using the class information. This modelling is challenging because the attributes are expected to be interdependant. Particularly, we propose the following optimization based on max-margin models for regression SVMs:
In the previous equation appears some terms which will be explained as following. \(\sum _{c\in {1:C}}{\sum _{m,n\in {c}}{d(R_m,R_n)}}\) represents the intraclass mid-level regressive distance. The idea is that in the same group, the regression distance between mid-level codifications should be small. In the case of \(\sum _{s\in {1:K},i\in {1:N}}{\left( \xi _i^{s+} + \xi _i^{s-} \right) }\), it represents the slack from a typical max-margin regression model. The term \(\sum _{c'\in {1:C},p\in c'}{\sum _{c''\in {1:C},q\in c'',c' \ne c''}{d(R_p,R_q)}}\) measures the interclass mid-level distance i.e. this terms represents the discriminativeness of regressive attributes classifiers. The intuition is that records of different classes should have different codifications.
Finally, the variable \(Z_s \in \mathfrak {R}^d\) represents the region of data where the \(s-th\) attribute is localized. Z selects some of them by considering a binary vector with \(\gamma \) active features (\(\gamma < d\)). We use the diagonalization operation \(diag(Z_s)\) obtaining a matrix of dimensionality \(d * d\) in order to appropriately interact with \(w^s\) and \(x^i\) as they have dimensionalities \(1 * d\) and \(d * 1\), respectively. Given that the possible number of combinations to explore is exponential (\(d^{\gamma }\)), we consider a fixed set of regions.
For the optimization of variable R, we consider as metric the classic Euclidean distance. In this case, we also apply a stochastic gradient optimization over R. The algorithm firstly initializes the regressive codes R following the procedure given in previous Subsection. Then, we proceed by iterating sequentially the following three steps. First, we optimize R for fixed \(W_i\) and \(\xi _i^s\) using stochastic gradient descent; this step improves the code discriminativity considering separation between different classes and it is started with the current value of R. Second, we update \(W_i\) and \(\xi _i^s\) by fixing R and Z and training linear SVMs over them. Third, the resulting set of SVMs is used to predict an improved version of regressive codes R, and we continue this process until to reach convergence of resulting codifications or the energy function is not minimized.
While this optimization procedure does not guarantee cost function descent in each iteration due to non-convex nature, our experiments show that we get convergence of solutions in practice. Furthermore, we find that the accuracy in test set is typically increased with the number of iterations. We fix the parameters for all datasets; \(\lambda _1\) is setted to 1e−3, \(\lambda _2\) with \(\lambda _3\) are setted to 0.1 where \(\lambda _3\) is normalized for the size of categories.
3 Experiments
Our method is tested considering four public re-identification datasets and one new re-identification datasets, which corresponds to typical pedestrian datasets. The public pedestrian datasets are ETHZ, CAVIAR, ILIDS and VIPER datasets, while the private dataset is DCC. ETHZ dataset consists on 146 persons with an average of 30 images for person. CAVIAR dataset consists on 72 persons with an average of 10 images by person. ILIDS dataset consists on 119 persons with 3 images by person. Both, CAVIAR and ILIDS have image under multiple views. VIPER datasets consists on 632 persons with 2 images for person. Our own pedestrian dataset, DCC, is obtained from an indoor environment in an university campus and consists on 16 persons and an average of 30 images by person. Before to extract the feature, we rescale the images to dimensions \(128 \times 64\) in order to uniformize the analysis of images. We use CAFFE features [4] which are based on convolutional neural networks. In detail, we apply the public CAFFE feature extractor over the images and apply it over a sliding window with dimensions \(100\times 50\) and we use a grid of \(3\times 3\) overlapping regions obtaining L = 9 regions (Table 1).
3.1 Transfer Learning
Our main experiment is oriented to a transfer learning task, which consists on learning attributes from a known set of classes (training dataset), and then testing such learned attributes over a new set of a-priori unknown classes (testing dataset). We consider all datasets, except VIPER because it has only two images by class, therefore, is not feasible to follow the proposed evaluation scheme.
First, we assume the access to low-level feature dataset of N records, \(D=\left[ d_1,\ldots ,d_N\right] \) with \(d_i \in R^L\). In particular, we first divide the data using \(\tau _1 \%\) of classes for training dataset \(D_{tr}\) and \((1 - \tau _1) \%\) of classes for testing dataset \(D_{te}\). In this part, we sort each class according to number of samples where the most populated classes belongs to training set and the less populated to testing set. This is justified because the new classes (pedestrians) in operation can have few samples and we have no control over them. Then, we initialize DCR using a validation dataset. In this respect, we divide the original training dataset in two by using \(\tau _2 \%\) for a new training dataset \(D'_{tr}\) and the remaining \((1 - \tau _2) \%\) for a new validation dataset \(D'_{val}\) considering a stratified scheme, which means that we consider the class proportions. Note that in this case, this division does not consider class information, in contrast to the previous separation given by \(\tau _1\). We optionally also test the use of feature selection over initial codes given by PCA considering a method based on Random Forest [5]. Next, we optimize the regressive codes of DRC using the complete original training dataset \(D_{tr}\). We consider to use all available information in order to find generalizable regressive codes. Subsequently, we use the learned codes in the testing dataset \(D_{te}\).
We test both methods based on attributes, DBC and DRC; and a baseline based on SVM over original CAFFE features. Both methods are based on the automatic discovering of attributes, which is essentially hard because the attributes are not known in advance. The number of attributes for both algorithms is 128 as this value has obtained good results in previous experiments [2]. We test two sets of initial codes, one given by the first codes of PCA and the other by feature selection based on random forest [5]. In the case of SVM, we use all original features. Due to the good discriminativity of sparse CAFFE features, the results using full original features are better than DRC and DBC, however, the training and testing of this model requires the 36824 features and the attribute discovery models only 128 after lineal dimensionality reduction. The average test time for SVM over original features is five times slower than DRC in our experiments, which can be crucial in re-identification applications.
Table 2 shows the results for each dataset by comparing accuracies. Our technique is able to outperform the binary method DBC by an average of 6% considering 128 codes. We note that high values of variance correspond to datasets with few exemplars by individuals, mainly in ILIDS dataset which has variance over 4% and has three images by person. We also note the use of feature selection over initial codes also improves the results, for example, in ILIDS dataset the increasing is 3%. On the other hand, the original CAFFE features are very discriminative as we can see in the results; however, the use of full features requires much more computing processing (five times slower).
3.2 Pedestrian Re-identification
We apply our method in re-identification tasks assuming a transfer learning setting. For space reason, we show results in two public datasets, which are pedestrian datasets. These datasets are VIPER and ILIDS, where both datasets have been previously detailed. These datasets have the characteristic that have only few examples by person, therefore, are natural to be applied transfer learning considering other pedestrian datasets. Again, we use the CAFFE features over 9 overlapping regions given by a 3\(\times \)3 grid and obtain 36864 sparse features.
We compare our technique with some state-of-the-art methods considering transfer learning setting for pedestrian re-identification. We also add PCA-CAFFE features in order to slightly boost our method. Tables 3 and 4 show the results for datasets VIPER and ILIDS, respectively, by comparing rate recognition according CMC curves using 256 codes for DRC. Our technique is able to compete these methods although these methods usually use some information of test datasets. On the other hand, our method is simple and competitive because it is based on simple linear transformations that are ready to use in test settings. For example, [6] calibrates these models using small partitions of test datasets; furthermore, they use a convolutional neural network for re-identification problem that require specialized GPU hardware in order to learn model.
4 Conclusions
The discovering of attributes is an attractive area because it can help to automatic visual recognition by proposing new attributes. Moreover, the attributes are associated to semantic information therefore they can have good generalization properties. We proposed a method considering a different idea in relation to typical binary attribute: what happens if we want to learn a regression of t-shirts? We apply our method to re-identification problem with results which are competitive respect to state-of-the-art methods under the same setting. Five public datasets were tested to evaluate the performance of these codes. Extensive experiments show that the learned representations have good generalization. Although the results are encouraging, we think that the linear mapping restricts our model from finding more interesting patterns. As future work, we will explore richer codification structures than lineal mapping.
References
Parikh, D., Grauman, K.: Relative attributes. In: Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition, pp. 503–510 (2011)
Rastegari, M., Farhadi, A., Forsyth, D.: Attribute discovery via predictable discriminative binary codes. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) ECCV 2012. LNCS, vol. 7577, pp. 876–889. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-33783-3_63
Lobel, H., Vidal, R., Soto, A.: Hierarchical joint max-margin learning of mid and top level representations for visual recognition. In: Proceedings of International Conference on Computer Vision (2013)
Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R., Guadarrama, S., Darrell, T.: Caffe: convolutional architecture for fast feature embedding. In: Proceedings of the ACM International Conference on Multimedia, MM 2014, pp. 675–678. ACM, New York (2014)
Genuer, R., Poggi, J.M., Tuleau-Malot, C.: Variable selection using random forests. Pattern Recogn. Lett. 31(14), 2225–2236 (2010)
Hu, Y., Yi, D., Liao, S., Lei, Z., Li, S.Z.: Cross dataset person re-identification. In: Jawahar, C.V., Shan, S. (eds.) ACCV 2014. LNCS, vol. 9010, pp. 650–664. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-16634-6_47
Ma, A., Yuen, P., Li, J.: Domain transfer support vector ranking for person re-identification without target camera label information. In: Proceedings of International Conference on Computer Vision (2013)
Yi, D., Lei, Z., Li, S.: Deep metric learning for practical person re-identification. In: Proceedings of International Conference on Pattern Recognition (2014)
Globerson, A., Roweis, S.T.: Metric learning by collapsing classes. In: Advances in Neural Information Processing Systems (2005)
Weinberger, K.Q., Blitzer, J., Saul, L.K.: Distance metric learning for large margin nearest neighbor classification. In: Advances in Neural Information Processing Systems, pp. 1473–1480 (2005)
Xing, E., Ng, A., Jordan, M., Russell, S.: Distance metric learning, with application to clustering with side-information. In: Advances in Neural Information Processing Systems, vol. 15 (2003)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Peralta, B., Caro, L., Soto, A. (2018). Unsupervised Local Regressive Attributes for Pedestrian Re-identification. In: Mendoza, M., Velastín, S. (eds) Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications. CIARP 2017. Lecture Notes in Computer Science(), vol 10657. Springer, Cham. https://doi.org/10.1007/978-3-319-75193-1_62
Download citation
DOI: https://doi.org/10.1007/978-3-319-75193-1_62
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-75192-4
Online ISBN: 978-3-319-75193-1
eBook Packages: Computer ScienceComputer Science (R0)
