
Abstract
In this paper, we propose an efficient method for processing continuously range spatial keywords queries based on Word2Vec over moving objects. In particular, the paper addresses two problems of processing range spatial keyword queries over moving objects. Each moving object and query has own keywords and a spatial location information. (i) The likelihood of having similar meanings between the keywords is high, but the likelihood of being exactly the same is low. Therefore, we focus on not only exactly matching, but similarity between keywords through Word2Vec. (ii) Additionally, because the objects are moving, the central server needs to continuously monitor them. In traditional research, by constructing safe region, there are attempts to reduce inevitable communication between the objects and the server. However, the constructions of safe region are also costly. Therefore, in the paper, to decrease communication costs, and construction and maintenance costs, we introduce the concept of buffer region and the pruning rules. Moreover, the proposed method includes a spatial index structure, called the Partition Retrieved list whose role is to help the system quickly construct the safe region of each object. Through experimental evaluations, we verify the effectiveness and efficiency for processing range spatial keyword queries over moving objects.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
- Spatial databases
- Location-based services
- Spatial keyword queries
- Range queries
- Range monitoring queries
- Safe zone
- Word2Vec
1 Introduction
Recently, the rapid development in mobile computing and communication has changed a lot in our lives. Due to GPS-enabled mobile devices, people use their location to upload posts to social network services or to search for specific locations of interests based on their location. Likewise, the location-based services (LBSs) which is based on the location of users have great popularity not only in industry but also in academic communities. There are many different types of spatial queries in the research. Because the finding several nearby objects has more likely to match with the needs of the users than the finding only one optimized object, the most traditional researches have focused on the finding (all or some) nearby objects (e.g., range query [1, 2], nearest neighbor queries [3, 4], etc.). From among these, range query is the most important type of spatial queries used in LBSs, whose goal is finding all objects within a given (rectangular or circular) area. Also, as the data have not only spatial attributes but also textual attributes, the importance of spatial keyword query is also on the increasing.
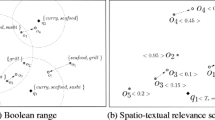
Figure 1 shows an example of the range spatial keyword query, where there are nine objects and three queries and each of them has own keywords. In Fig. 1, we assume that the all queries \( q_{1} , q_{2} ,\;{\text{and}}\; q_{3} \) find the objects that have similar interests with the query within given circular area. Even though the objects \( o_{1} \;{\text{and}}\;o_{2} \) has ‘noodle’ as keywords and they match the query \( q_{1} \) textually, but in perspective of spatial attributes, only the object \( o_{1} \) can be a result of the query \( q_{1} \), not \( o_{2} \). About the query \( q_{2} \), although the object \( o_{4} \) matches the query \( q_{2} \) spatially, as the object \( o_{4} \) does not have the exactly matched the keyword with the query \( q_{2} \), ‘Korean food’. However, since the keyword of the object \( o_{4} \), ‘bulgogi’ is included in ‘Korean food’ and there is a strong relationship between the keywords, the object \( o_{4} \) can be a result of the query \( q_{2} \). Similarly, the object \( o_{5} \,{\text{and}}\,o_{6} \) can be a result of the query \( q_{3} \). As the previous example, the data have been changing as geo-textual data.

An example of the range spatial keyword queries
Each moving object and query has own keywords and spatial location information. since the objects are moving, it is inevitable that the moving objects continuously communicate with the central server. However, whenever the objects move, reporting the new location to the server makes the server overloaded. To reduce the frequent and unnecessary checks for the current query results, the traditional researches have proposed a concept of safe region [5,6,7,8,9,10,11]. Safe region assigned to an object is the area such that the results of the queries in the system are not changed as long as the object moves within this area. However, the constructions of safe region are also costly. Therefore, we introduce pruning rules to decrease communication costs, and construction and maintenance costs of the safe regions.
In this paper, we propose a new algorithm for processing Continuous Range Spatial Keyword Queries based on Word2Vec (namely, CRSK-w2v queries) over moving objects in Euclidean space. In the traditional researches, there are key challenges: (i) an efficient method for quickly finding the result objects of the queries, (ii) an efficient communication between the moving objects and the central server without unnecessary re-computation, and (iii) how to analyze the relationship between the keywords. Therefore, in order to solve the above challenges, the proposed algorithm focuses on (i) obtaining the relationship between keywords based on Word2Vec and (ii) minimizing communication costs, and construction and maintenance costs of the safe regions. Moreover, in order to efficiently construct and maintain the safe regions, we introduce the variation of buffer region, which is proposed in [8] to reduce the unnecessary and frequent re-computations of the safe regions. In addition, we introduce the efficient pruning rules that use a spatial index structure, called Partition Retrieved list. With the partition retrieved list, the system can easily exclude the queries which do not match with the objects spatially.
The rest of the paper is organized as follows. In Sect. 2, the problem is formally defined. Then we review some related work in Sect. 3. In Sect. 4, the system overview is provided and the details of the proposed algorithms are presented in Sect. 5. In Sect. 6, the performance of the proposed algorithm on real data sets are presented. Finally, in Sect. 7, we present our conclusions.
2 Preliminary
2.1 Client-Server Model
In this section, we review the background of the client-server model. For continuously monitoring CRSK-w2v queries, we adopt the client-server model. In this model, there are a central server and two types of clients. Clients, a component of this model, consists of the query issuers and the moving objects. A query issuer issues the query to the central server, and receives the result objects from the server persistently each time the query results change. Whenever an object moves, it continuously communicates with the server to report its new location. Moreover, the object is evaluated whether it can be the result of a query or not. We assume that the moving object o has limited computational capacity. In other words, it cannot recognize all queries, and only several queries can be recognized according to capacity of the object. The concept of the maximal computational capacity is represented as o.cap, which indicates that o can track at most cap nearest neighbor queries and determine whether it is the result object of the queries.
In this model, the role of central server is critical, because the place to process CRSK-w2v queries is the server. The server receives information of location and the keywords from moving objects and the queries which are issued from the query issuers. At the same time, the server processes each query and sends the up-to-date results to the corresponding query issuer. In addition, the server continuously monitors the moving objects. Also, whenever the safe region needs to update, the server calculates the safe region of each object and sends it to the object. Let us consider a scenario where there is an Italian restaurant and a manager of restaurant wants to send e-coupon or promotion information to potential customers who have interests in Italian foods and they are nearby the restaurant. Then the restaurant manager issues a query which finds the potential customers, to a central server. Then the server finds customers who are matched with the query and continuously monitors customers to identify if they leave out their safe regions or not. Thus, the server is responsible for all the processing the queries. In this paper, in order to decrease the burden of the server, we assign the safe region to each moving object.
2.2 Word2Vec
The one-hot encoding method in the traditional Natural Language Processing (NLP), has a disadvantage in that the dimensionality increases and the relationship between the words is not reflected. In order to solve this problem, word embedding method of vectorizing the meanings of words in multidimensional space has been devised. If the meaning of a word is vectorized, the similarity between words can be measured, and since the meaning itself is numerically expressed as a vector, it can be deduced through vector operation. One of the methods, Word2Vec is an algorithm that implements the method proposed by Mikolov [12], which makes it possible to improve the precision in NLP compared to existing algorithms. Word2Vec is a technique that expresses each word as a vector in a space of about 200 dimensions. As in the following example, by adding or subtracting vectorized words, inference process can be easily implemented.

Similarly, vector(“King”) − vector(“Man”) + vector(“Woman”) results in a vector, which have closet meaning with Queen [13]. Mikolov [12] proposed two new model architectures: CBOW (Continuous Bag-of-Words) and Skip-gram. CBOW is a model for inferring words through the entire context, and Skip-gram model infers words that appear around a given word, as opposed to CBOW. When sampling the word, it applies the idea that the closer the word is, the more relevant. In this paper, in order to reflect the similar meanings between the keywords, we analyze the relationship between the keywords through Word2Vec.
2.3 Problem Statement
In this section, we formally define the problems of processing CRSK-w2v queries. Let O and Q denote a set of geo-textual objects and a set of CRSK-w2v queries in the proposed system, respectively. Each object \( o \in O \) is defined as a pair (o.pos, o.pre) that means a position of the object and a set of preferences, respectively. In particular, o.pos is represented in two-dimensional space and it has x-coordinate (o.posX) and y-coordinate (o.posY). Moreover, each element in the preferences set, o.pre means preference (keyword) of o and the number of keywords may be one or more. In this paper, we assume that the objects are moving, and then they dynamically change their location. On the contrary, we consider the queries are static and the query issuers issue a query to the central server. Additionally, each query \( q \in Q \) also contains its position and its set of preferences and they are denoted by q.pos and q.pre, respectively.
Given a query q and an object o, in this paper, we represent geo-textual relevance by using two concepts of distance; disS(q, o) and disT(q, o) as follow. disS(q, o) means a spatial distance between q.pos and o.pos, while disT(q, o) means a textual distance between q.pre and o.pre. The smaller of the distance disS(q, o), the higher the relation between q and o (disT(q, o) takes the same approach).
To compute disT(q, o), we use the textual similarity simT(q, o) and define the relationship between them as disT(q, o) = 1 − simT(q, o). If there are higher textual similarity between the query q and the object o, it means that between them, there is lower textual distance. In other words, if the object o has lower textual similarity with the query q, then it has higher textual distance. For obtaining the textual similarity simT(q, o), we use a modified function of the weighted Jaccard coefficient [14] as (2).
About each keyword k in q.pre, \( r(k)_{o} \) means a relation between the query q and the object o. Additionally, \( r(k)_{o} \) has a value [0, 1]. Moreover, if the common keyword exists between the object o and the query q, \( r(k)_{o} \) has the largest value relation (i.e., \( r(k)_{o} = 1 \)). However if not, based on Word2Vec, \( r(k)_{o} \) has the largest value among the similarity values (i.e., sim(k, t)) obtained by comparing the similarity with the keyword t in o.pre. Therefore, if the similarity between the keywords are not considered, we can redefine that simT(q, o) is the number of common keywords between q and o divided by the number of keywords of q, and its value lies between 0 and 1. Additionally, if the similarity between the keywords are considered, as \( r(k)_{o} \) has a value of 1 or less, and simT(q, o) is also normalized. By generalizing this, the textual similarity simT(q, o) is normalized without any normalization strategy and disT(q, o) is also normalized.
Moreover, for normalizing the spatial distance disS(q, o), we define R, system defined spatial distance and the reason will be explained below.
where \( \left\| {q.pos, o.pos} \right\| \) is the Euclidean distance between q.pos and o.pos.
In this paper, we represent geo-textual relevance by using a ranking score function as follow.
where α is a ranking parameter that shows the effect of the spatial distance and the textual distance on the query and it lies between 0 and 1. If the importance of the spatial distance is the same as the textual distance, α is 0.5. However, the issued query considers the spatial distance more important than the textual distance, α is greater than 0.5. Therefore, the parameter α is a system parameter which is determined depending on the preference of the query issuers.
Let consider an example, where there are two objects \( o_{1} \;{\text{and}}\; o_{2} \) and a query q. As the query issuer of the query q has a higher preference of textual distance than spatial distance, and then he sets the ranking parameter α is 0.3. We assume that each object and the query have five keywords, and also only exactly matched keywords are considered. The object \( o_{1} \) is 5 km from the query location and it has three common keywords with q. The object \( o_{2} \) is 4 km from the query location and it has only one common keyword with q. From these situations, we will find the \( disT(q, o_{1} ) \) is 0.4 and the \( disT(q, o_{2} ) \) is 0.8. Therefore, the ranking score of \( o_{1} \;{\text{and}}\; o_{2} \) is 1.78 and 1.76, respectively. Even though the preference of textual distance is higher than spatial distance, the ranking score of \( o_{2} \) is better than \( o_{1} \). It is happened as the textual distance is already normalized but the spatial distance is not normalized. That is the reason why both distance disS(q, o) and disT(q, o) need to be normalized to [0, 1].
Definition 1
(Continuous Range Spatial Keyword Queries based on Word2Vec, CRSK-w2v queries). Let O and Q be a set of geo-textual objects and a set of queries, respectively. The query q is represented by {pos, pre, TS}, where pos is the query location, pre is the query keywords set, and TS is the threshold score. The result \( RS_{q}^{ t} \) of q is a set of objects whose geo-textual relevance score is less than or equal to the threshold score of q, i.e., \( \forall o \in RS_{q}^{ t} , score\left( {q,o} \right) \le TS \).
We summarize the frequently used terms in Table 1.
3 Related Work
In this section, we review the related works with our proposed algorithm. First, in Sect. 3.1, we discuss a viewpoint on treating the queries and the objects adopted in this paper, and then we introduce processing of the continuously monitoring spatial in Sect. 3.2. Finally, in Sect. 3.3, we briefly review the related works for spatial keyword queries processing.
3.1 Viewpoint on Treating the Queries and the Objects
We discuss a viewpoint on treating the queries and the objects adopted in this paper. There are two viewpoints on spatial database. One of the viewpoint assume that the query points are stationary and the objects are moving [2, 8, 15]. The other point of view is that the query points are moving and the objects is stationary [6, 9]. In the both of viewpoints, the moving is indexed. This paper adopts the former viewpoint. Thus, from now, we only review the studies conducted continuous range monitoring queries matched our perspective. Indexing the query points instead of the objects is effective to reduce the computational cost for updating, because the objects are frequently moving, and the indexing of the objects remains valid for a short time than the queries. Prabhakar et al. [2] proposed two indexing technique: Query Indexing and Velocity Constrained Indexing (VCI) by using R-tree. In [15], a grid-index structure based on in-memory is more effective technique than any others. For processing these queries, in order to efficiently monitor the moving objects, it is inevitable that the moving objects continuously send their new location to the server. The objects should send periodically their new location to a central server. At the same time, the server receives those requests, processes the queries, and returns the results. However, the server may become overloaded due to the frequent and unnecessary checks for the current query results.
To solve the above problems, the traditional researches have proposed safe region method [5,6,7,8,9,10,11]. It helps to reduce the frequent and unnecessary checks for the current query results, since the safe region of an object o guarantees the results of the queries in the system are not affected as long as o remains inside this area. As the shape of safe region is arbitrary, it can be rectangle, circle or anything else. However, these constructions of safe region are also costly.
3.2 Continuous Monitoring Spatial Queries
In spatial database communities, early researches assumed a static dataset and focused on development efficient spatial access methods (e.g. R-tree [16]). Additionally, they treated the effective method of the processing snapshot queries like the range queries [1, 2] and the nearest neighbor queries [3, 4] used in LBSs as the most important types of queries. They focus on finding nearby objects, instead of finding only one optimized object. Because finding nearby objects has more likely to match with the needs of the users. However, recently, the environment is changing, where data objects or the queries move. In particular, researches on the continuously monitoring the spatial queries have been increasingly important, because of their use in a variety of areas. In [2], the Q-index is the first address the problem of monitoring the static range query over moving objects. Hu et al. proposed a framework to answer monitoring queries over moving objects, where mobile clients use safe regions to help reduce communication cost [14]. In this paper, we focus on the processing the continuously monitoring the range queries.
3.3 Spatial Keyword Queries
In this section, we briefly review the existing methods for spatial keyword queries processing. As the importance of processing queries considering both keywords and spatial attributes is emphasized, research on Spatial Keyword Queries is increasing. Most of the researches focus on top-k spatial keyword queries [5,6,7, 17], whose goal is finding k closest objects, and the objects possess similar keywords with the keywords of the queries. Although many researches have focused on processing top-k spatial keyword queries, some researchers have conducted range spatial keyword queries [8, 11], whose goal is finding all objects which have keywords of the queries in given (rectangular or circular) area. However, they adopted the simple pruning rules for reducing the construction costs of the safe regions. Additionally, they consider only when the keywords between the queries and the objects were exactly matched. In this paper, we introduce more complex pruning rules to effectively reduce the overhead of constructing the safe regions, based on the relationship between keywords.
4 System Overview
This section presents an overview of the system model. Unlike the traditional client-server model, in this paper, we separate clients as two types; query issuers and moving objects. The reason is that (i) a major role of clients is to issue queries and to get back the result and (ii) although moving clients are clients, it is emphasized that the role of data like location and keywords set rather than the role of clients. The query issuers, who issue the queries to the central server, are called queries in the remainder of this paper and the other is moving clients, called (moving) objects. Therefore, in this system, there are three components; moving objects, clients and a server. Figure 2 shows the proposed system architecture.

The system architecture
In this paper, we introduce an efficient method for processing CRSK-w2v queries over moving objects. For processing the queries, there are some challenges. When the objects move, the result sets of the queries are a possibility to change. Therefore, it is important to continuously monitor the objects and to identify whether the movement of the objects affects the result sets of the queries if not. In order to address these challenges, the concept of the safe region is proposed in [5,6,7,8,9,10,11]. Additionally, we introduce the variation of buffer region, which is proposed in [8] to reduce the unnecessary and frequent re-computations of the safe regions. Moreover, we present pruning rules to reduce overhead of the communication costs between the server and the objects, and efficiently construct the safe regions. The key idea of the proposed pruning rules is to find the spatial and textual upper bounds between the queries and the objects.
We describe our proposed system in the following subsections. Firstly, in Sect. 4.1, we present the concept of safe regions and next in Sect. 4.2, we present the concept of buffer regions. Finally, in Sect. 4.3, we present the pruning rules based on geo-textual proximity.
4.1 Safe Regions
In the client-server model, it is inevitable that whenever the moving objects move, they consistently communicate with the server to report their new location. However, since some of these communications are unnecessary, by decreasing them, we can reduce frequent and needless re-computation happened at the server. To reduce unnecessary communications, one of the methods is constructing the safe region. The safe region is an area such that the object cannot affect the results of the queries as long as it is moving within the area. The shape of the safe region can be rectangular or circular. In the many traditional studies, the shape of the safe regions is rectangular, because it is easier to consider pruning rules than the circular shape [6, 14]. On the contrary, this paper adopts circular as the shape of the safe region. In particular, instead of the traditional safe regions, we use an expanded concept. The expanded concept is explained later.
In order to efficiently process CRSK-w2v queries, we need a relation between the query and the result object of the query. Therefore, we have the following lemma.
Lemma 1.
Only object \( o \in O \) that satisfies the following relation \( disS(q,o) \le \frac{TS}{ \alpha } - \frac{{\left( {1{-}\alpha } \right)}}{ \alpha } \cdot disT(q,o) \) can be a result of CRSK-w2v query q.
Proof.
By the Definition 1, an object \( o \in O \) who is the result of CRSK-w2v query q satisfies score(q, o) ≤ TS, i.e., \( score(q,o)\, = \,\alpha \cdot disS(q,o) \, + \,(1{-} \alpha ) \cdot disT(q,o)\, \le \,TS \). From this function, we can get the following results, \( disS(q,o) \, \le \,\frac{TS}{ \alpha } - \frac{{\left( {1{-} \alpha } \right)}}{ \alpha } \cdot disT(q,o) \). Therefore, we prove Lemma 1.
With Lemma 1, we introduce a concept of the conditional circle \( CC_{q}^{o} \). The conditional circle is circular area where its center is the query location q.pos and its radius is the \( r_{q}^{o} \). From the Lemma 1, the radius is defined as following equation.
If an object o is within the conditional circle of a query q, o is a result of q; and if not, o is not the result of q. With the concept of the conditional circle, we introduce a concept of the conditional region. The conditional region is assigned area between one object o and one query q. It guarantees the results of q is not changed as long as o remains inside the region. Although the conditional region is the concept similar to the safe region, it is related to only one query, not all queries. Figure 3 show the different types of the conditional region. In Fig. 3(a), upper figure shows the situation when o is in the conditional circle of q (i.e., when o is the result of q), and lower figures show the opposite situation.

The conditional region (a) and the safe region (b and c)
In this paper, we utilize the expanded version of the safe regions. By expanding the existing concept, we re-define the safe regions as an intersection of all relevant the conditional regions. The three figures in Fig. 3(c) are, in turn, the conditional regions of the queries \( q_{1} \), \( q_{2} \), and \( q_{3} \) for o (shaded in gray). Moreover, we can find that the intersection of the three conditional regions in Fig. 3(c) is the safe region of o in Fig. 3(b) (shaded in gray).
The safe regions reduce the number of the communication between the server and the moving objects and it causes the re-computation cost reduction in the server. However, the construction cost of the safe regions is also costly. Hence, we introduce a concept called buffer region to reduce the cost in next section.
4.2 Buffer Regions
In this section, we present the concept of buffer regions proposed in [8] and the variation of buffer region, which has been changed according to our system. The buffer region (namely, BR) is calculated based on the maximal computational capability (denoted by o.cap) of the client mobile devices (i.e., the moving objects). Because of the limited computational capability of the object o, each object o cannot track all the queries registered in the server and o can only monitor the region as much as its computational capability at the same time. Therefore, the server needs to check several queries depending on capability, not all the queries. In [8], BR of an object o (\( BR_{o} \)) is defined as the area where its center is the location of objects o.pos and its radius is the Euclidean distance from o.pos to the o.cap − 1th nearest conditional circle. When an object o comes into the central server for the first time, the server assigns a Nearest query list (NQList) that stores the conditional circles of the relevant queries, and sends the safe region to the corresponding object. Then whenever o leaves its safe region, the server checks if o is within its \( BR_{o} \). If o leaves the \( BR_{o} \), the server re-compute the \( BR_{o} \); and if not, the server identifies the queries stored in the NQList and re-computes the safe region of o.
At the existing concept of the BR, because of the tracking the BR boundary, each moving object o can only monitor the boundary of o.cap − 1th nearest conditional circle and the size of \( NQList_{o} \) is one less than o.cap (i.e., \( \text{N}(NQList_{o} )\, = \,o.cap - 1) \). However, since o only needs to know the radius of \( BR_{o} \), the tracking of the BR is not necessary. Hence, from now, the size of the \( BR_{o} \) is o.cap. Figure 4 shows examples of the buffer region (depicted in bold dotted line). In these examples, we assume that the maximal computational capability of o, o.cap is three and all the registered query has same textual similarity with o. In each figure, the area shaded in gray means safe region at that time. Also, some queries in \( NQList_{o} \) are depicted in solid line and the other queries not in \( NQList_{o} \) are depicted in dotted line. From now on, we address the problem of the existing BR. The existing BR does not guarantee storing the most recent nearest query. Figure 4(a) and (b) show an existing buffer region of o at time t and at time t + 1, respectively. At time t, the queries \( q_{3} \), \( q_{4} \), and \( q_{5} \) are in \( NQList_{o} \) and the object o is the result of \( q_{3} \), \( q_{4} \); and at time t + 1, the object o moves to o*, and the nearest queries are changed to \( q_{2} \), \( q_{3} \), and \( q_{4} \). However, as the object o is in its \( BR_{o} \), the server does not check new \( NQList_{o} \) and consequently, it also does not verify that o is the result of \( q_{2} \).

The existing buffer region (a and b) and the variation of buffer region (c and d).
In this paper, in order to solve the above problem and efficiently reduce the re-computation costs in the server, we have made a variation in the existing way to construct buffer region. There are two variations. The first variation is that the object o can keep track of o.cap conditional circles, and the reason for this variation is mentioned above. The second variation is that in constructing the buffer region, the server uses o.cap + 1 nearest conditional circles instead of o.cap. In this paper, since the server assumes that there is no limitation of the computational capability unlike the objects, the server can keep track of o.cap + 1 nearest conditional circles. However, when constructing the safe region, the server still uses only o.cap nearest conditional circles, because the object can only track o.cap conditional circles according to its own computational capability. In this paper, since we assume that the central server has no limitation of the computational capability unlike the objects, the server can keep track of o.cap + 1 nearest conditional circles. Figure 4(c) and (d) show a variation version of the buffer region at time t and at time t + 1, respectively. At time t, the queries \( q_{2} \), \( q_{3} \), \( q_{4} \), and \( q_{5} \) are in \( NQList_{o} \) and the object o is the result of \( q_{3} \), \( q_{4} \); and at time t + 1, the object o moves to o*, and the object leaves out its \( BR_{o} \). Hence, the server should check \( NQList_{o} \) and consequently, in new updated \( NQList_{o} \), there are \( q_{1} \), \( q_{2} \), \( q_{3} \), and \( q_{4} \).
We summarize the two variations from the existing concept of buffer region.
-
Firstly, an object o can keep track of o.cap nearest conditional circles, and by using these, a central server constructs a safe region.
-
Secondly, when the server constructs buffer region, the server uses o.cap + 1 nearest conditional circles, which is one more than the existing, i.e., \( \text{N}(NQList_{o} )\, = \,o.cap\, + \,1 \).
From the buffer region, the objects need to know only the radius of buffer region. Therefore, we define a concept of end distance (denoted by ED) as follow and it is depicted in bold line in Fig. 4(c) and (d).
Definition 2
(End Distance, ED). Given a CRSK-w2v query q and a geo-textual object o, the end distance ED of o is the Euclidean distance from o.pos to the o.cap + 1th nearest conditional circle.
Additionally, \( NQList_{o} \) contains at most o.cap + 1 nearest neighbor queries. From the Definition 2, when the object o leaves out a circular space where its radius is ED and the center is o.pos, the \( NQList_{o} \) can be changed.
4.3 Pruning Rules
In this paper, there are two pruning rules based on geo-textual proximity. Because this paper is an extended paper based on [11], the pruning rules are similar to the existing ones. Since the proposed system is based on geo-textual proximity, there are two important factors: textual distance and spatial distance. Hence, we have created a pruning rule for each of the two factors. Firstly, there is a pruning rule about a textual distance. In order to consider only textual distance, assume that the spatial distance have minimum value, i.e., \( disS(q,o) = 0 \). Therefore, from (5) and Definition 1, we can define the upper bound of \( disT(q,o) \), \( UB_{o}^{q} \) as follow.
Lemma 2 (Pruning Rule 1).
The only object o that satisfies the following relation \( disT(q,o) \le \frac{TS}{(1 - \alpha )} = UB_{o}^{q} \) can be a result of CRSK-w2v query q.
Proof.
Let us assume an object o with \( disT(q,o) \) greater than \( UB_{o}^{q} \), i.e., \( disT(q,o) > UB_{o}^{q} \). Then since both α and \( disS(q,o) \) have not negative value, its score is over than threshold score, TS. By the Definition 1, the object o cannot be a result of a CRSK-w2v query q.
Before describing the second pruning rule, we explain index structures. In this paper, we use a grid-based data structure to index CRSK-w2v queries and an index structure: Partition Retrieved List (namely, PRList) like Fig. 5. In Fig. 5(a), the grid-based data structure consists of one root cell, intermediate cells and \( {\text{N}}^{ 2} \) grid cells [8]. In the system, the root and intermediate cells do not physically exist and each grid cell has one PRList, i.e., there are \( {\text{N}}^{ 2} \) PRLists. Every queries that issued in the system have their own border box as shown in Fig. 5(b). Each PRList contains all queries information whose largest conditional circle \( CC_{q}^{*} \) overlaps the partition of the grid cell. We will explain how to construct the index structures in Sect. 5.

\( {\text{N }} \times {\text{N}} \) grid-based data structure (a) and an example of pruning rule 2 (b)
Secondly, there is another pruning rule about a spatial distance. As with first pruning rule, in order to consider only spatial distance, assume that the textual distance have minimum value, \( disT(q,o) = 0 \). According to the previous assumption, Definition 1 and (5), we also define the upper bound of \( disS(q,o) \) as follow.
In the proposed system, the location information is more useful to prune than textual information. In addition, the above upper bound of \( disS(q,o) \) is too simple. Therefore, in this paper, other pruning rule is proposed that satisfies (8).
Lemma 3 (Pruning Rule 2).
The only object o that satisfies the following relation \( \exists \;partition p \in P_{ o}^{g} \cap P_{ q}^{g} \) can be a result of a CRSK-w2v query q.
Proof.
Let us assume a situation like Fig. 5(b). The object o is inside a grid cell \( g_{ 1} \) and third partition \( p_{ 3} \) is in \( P_{ o}^{{g_{1} }} \), i.e., \( P_{ o}^{{g_{1} }} = \left\{ {p_{3} } \right\} \). Also, both of the queries \( q_{1} \,{\text{and}}\,q_{2} \) overlap the grid cell \( g_{ 1} \). However each query has different overlapped, \( P_{{ q_{1} }}^{{g_{1} }} = \left\{ {p_{0} , p_{2} } \right\} \) and \( P_{{ q_{2} }}^{{g_{1} }} = \left\{ {p_{2} , p_{3} } \right\} \). Since there is no intersection of the overlapped partitions between o and \( {\text{q}}_{ 1} \), i.e., \( P_{ o}^{{g_{1} }} \cap P_{{ q_{1} }}^{{g_{1} }} = \emptyset \), o cannot be the result object of \( q_{1} \). On the other hand, since the partition \( p_{3} \) overlaps between o and \( q_{2} \), o can be the result object of \( q_{2} \). As the example in Fig. 5(b), if the object o is in the same partition p of a grid cell \( g \) with \( CC_{q}^{*} \), then o can be the result object of q. Moreover, since o is inside \( CC_{{q_{2} }}^{*} \), the distance between o and \( q_{2} \) is less than or equal \( r_{{ q_{ 2} }}^{*} \). By (6), this pruning rule also satisfies (8).
Lemma 4.
A partition g should be marked as overlapped partition with a query q, if a distance d between the query and a point that is the closest with the query in the partition g, is less than the radius \( r_{ q}^{*} \).
Proof.
Let assume that in a partition g, a point p is the closest with the query. If a distance d between a query q and the point p is greater than the radius \( r_{ q}^{*} \), i.e., \( d > r_{ q}^{*} \), then the point p is not inside \( CC_{ q}^{*} \). Since the point p is the closet point, the partition g cannot be marked as overlapped partition with the query q.
5 The Proposed Method
5.1 Framework
We discuss algorithms needed to construct a framework. As previously mentioned, we propose grid-based structure. Because the proposed system should track large amounts of data and will frequently update. it requires a data structure that can efficiently support these updates. The gird-based structure can support frequent location updates and give the better performance than the other index structure even if data are skewed [15]. The root and intermediated cells do not physically exist, therefore all data is stored in a grid cell, not root or intermediate cell. Each grid cell is divided into four parts again and each partition has unique ID from 0 to 3, as shown in the top of Fig. 6(a).

Partition information of the grid cells (a) and how to construct the border box (b)
Border Box.
In processing the CRSK-w2v queries, when a new query q is issued, a central server need to initialize the query. The Algorithm, InitializeQuery, which is an algorithm for initializing the query is proposed in [11]. Firstly, the server finds the distance to the left (L), right (R), Top (T) and Bottom (B) borders of the partition containing the query as shown in the bottom of Fig. 6(a). Then, by using a radius \( r_{q}^{*} \) of \( CC_{q}^{*} \), it computes how many partitions are needed to the each end and construct border box (BB). Finally, it calls an algorithm, IdentifyMarkDiagonal that identifies and marks the four diagonal direction: left-top (LT), right-top (RT), left-bottom (LB) and right-bottom (RB). Let assume an example of identifying LT diagonal direction like Fig. 6(b). There is a border box, as shown in the top of Fig. 6(b). A point q is the query location and another point p is one of the focused points. In identifying a diagonal direction, to efficiently adopt pruning rule 2, this paper focuses on some points inside the \( CC_{q}^{*} \).
By using the border box, we can get the focused point in a similar way to (9). Since the LT diagonal direction is checked in the example, the point p is shifted by x and y from the point q to the left (L) and upward (T), respectively.
Lemma 5.
In marking and identifying a left (or right) top (or bottom) diagonal direction, if a distance d between a query q and a point that is the closest with the query in the partition g, is less than the radius \( r_{ q}^{*} \), then right (or left) partition and bottom (or top) partition of g are also marked.
Proof.
Let consider the example above, continuously. If the distance d between the point p and the point q is less than radius r, by the Lemma 4, a partition g is marked. Then we can find α and β and define these as follows.
Where r is greater than d and θ is acute angle. Therefore, since \( (r - d) \), \( \sin (\theta ) \), and \( {\text{cos(}}\theta ) \) are positive, α and β are also positive. From this, the right partition and the bottom partition of g are also identified as overlapped partitions. As a similar way, the other diagonal ends can be identified.
5.2 CRSK-w2v Queries
In processing CRSK-w2v Queries, there are five major algorithms. Two algorithms are as mentioned in the previous Sect. 5.1, one of which is InitializeQuery for initializing a new issued query. Whenever a query is issued at a central server, the server performs InitializeQuery, and during this process, PRList are updated. Another one is IdentifyMarkDiagonal that identifies and marks four diagonal direction. To efficiently apply the pruning rule 2, we need to construct PRList. However, since constructing PRList is also costly, we need to use the technique to decrease unnecessary checking. By looking for the outermost overlapped partitions of the circle, the algorithm IdentifyMarkDiagonal helps to reduce unnecessary accesses.
The other two algorithms are about evaluating the objects. In the proposed system, all issued queries are indexed and static. On the contrary, the clients (i.e., the objects) are moving. Additionally, whenever a new object arrives at the server or whenever the object leaves out their BR, the server (re)evaluates the object, and (re)compute safe region of the object and (re)sends safe region to the object. In Table 2, an Algorithm 1, EvalObjects is a pseudocode of evaluating the objects, similar to that proposed in [8]. Firstly, when an object o comes to the central server, it forms an empty priority queue (line 1) and inserts root cell of the grid-based structure into the queue (line 2). Then, pull out the elements one by one from the queue, and repeat the evaluation process until NQList are formed or all the elements of the queue are verified (lines 3–21). More specifically, if the extracted element is an intermediate cell or a root cell, then put its sub cells back into the queue (lines 5–7). Else if the element is a grid cell, firstly, by calling a function FindQ(object, PRList) to apply pruning rule 2, find the candidate queries (line 9). Then about each candidate query, it gets similarity between query keywords and object keywords, and applies pruning rule 1 (lines 10–11). At this time, the similarity between the keywords are evaluated based on Word2Vec. Additionally, the server identifies if the object can be a result of the query, and puts the query back into the priority queue (lines 13–17). Else if the extracted element is a query, insert the query into NQList (lines 18–21). Finally, when NQList is completely constructed, it computes BR (line 22) of the object and sends \( BR_{o} \) to the corresponding object. Another algorithm is MonitorObjects and it is for continuously monitoring objects. When the object’s new location is in BR, the server checks only the queries in NQList. However, if the object leaves out BR, the server calls EvalObjects. Since the algorithm is too simple and similar to the algorithm proposed in [8], thus, the details in this paper are omitted.
Finally, an algorithm, IdentifySafeRegion is performed on the client-side. Each object has safe region information received from the server. Therefore, whenever the object moves, the object checks if it leaves out the safe region. If it is out of the safe region, the object informs the server and asks for updates. Then, the object receives new safe region information back. As these above algorithms are repeated continuously, CRSK-w2v queries are performed.
6 Performance Evaluation
6.1 Simulation Setup
Because this is the first work for processing CRSK Queries based on Word2Vec, we develop two naïve algorithms to compare with our proposed algorithm (Our). Firstly, a naïve algorithm (naïve-w/o) only considers the exactly matching between the keywords. Therefore, when an object arrives at the server, naïve-w/o algorithm evaluates the object without considering the relevance of the keywords. Another naïve algorithm (naïve-w2v) evaluates objects based on Word2Vec. But in naïve-w2v, there is no constructing PRList. Therefore, when a new query is issued to a central server and when a request from an objects arrives at the server, the server evaluates without PRList.
Dataset.
In the evaluation, a dataset is virtual, but it is based on the real world. In the dataset, each of data has own attributes: spatial attribute and textual attribute. Firstly, the spatial attribute is based on San Francisco and it is made from [18]. Another attribute, textual attribute consists of information from real stores in San Francisco, provided by Yelp. Through the data, we configure a dataset for processing CRSK-w2v queries and moving objects. CRSK-w2v queries dataset has default value, 10K, and it changes from 5K to 20K. Moving objects dataset has default value, 100K, and it changes from 50K to 200K. Additionally, all moving object data are tracked for 100 timestamps.
Parameter.
In the evaluations, each parameter has default value as shown in Table 3.
6.2 Simulation Result
In this section, we evaluate our algorithm for processing CRSK-w2v queries by comparing with two naïve algorithms: naïve-w/o and naïve-w2v. The performance metric is continuous time, which is the sum of times consumed each time the server is updated.
Effect of Using Word2Vec.
We evaluate the effects of using Word2Vec by comparing our with naïve-w/o. We vary the number of queries from 5K to 20K as shown in Fig. 7. Figure 7 shows the benefits of using Word2Vec. Firstly, since our checks not only the exactly matching but also the similarity, our can get more accurate results. Furthermore, since the query and the object keyword are highly likely to be associated with each other, the query result is maintained for a long time and thereby the total amount of computation is reduced. This is expected to be effective when the ranking score is obtained in (5), if the weight of textual attribute is set high (i.e., when α is small).

Effect of using Word2Vec
Effect of the Number of Queries and Objects.
We evaluate the effects of the numbers of queries and objects by comparing our with naïve-w2v. We vary the number of queries and objects from 5K to 20K and from 50K to 200K, respectively, as shown in Fig. 8. In Fig. 8, naïve-w2v has lower performance than our. Hence, the role of PRList to reduce total computation is significant.

Effect of the number of the queries (a) and the objects (b)
7 Conclusion
In this paper, we propose a new algorithm for processing Continuous Range Spatial Keyword Queries based on Word2Vec over moving objects in Euclidean space. The proposed algorithm emphasizes (i) obtaining the relationship between keywords based on Word2Vec and (ii) minimizing the communication costs, and construction and maintenance costs of the safe regions. However, the constructions of safe region are also costly. Therefore, in the paper, to decrease these costs, we introduce the concept of buffer region and the pruning rules. Moreover, the proposed method includes a spatial index structures, Partition Retrieved list whose role is to help the system quickly construct the safe region. Through experimental evaluations, we demonstrate the usefulness of using Word2Vec and effectiveness of constructing Partition Retrieved list. As for the future works, we plan to improve our work to support more complex situations where the keywords are changed, beyond the analysis of similarity between keywords.
References
Rathore, R.: Spatial Range Query
Prabhakar, S., Xia, Y., Kalashnikov, D.V., Aref, W.G., Hambrusch, S.E.: Query indexing and velocity constrained indexing: scalable techniques for continuous queries on moving objects. IEEE Trans. Comput. 51(10), 1124–1140 (2002)
Roussopoulos, N., Kelley, S., Vincent, F.: Nearest neighbor queries. ACM SIGMOD record 24(2), 71–79 (1995)
Papadias, D., Tao, Y., Mouratidis, K., Hui, C.K.: Aggregate nearest neighbor queries in spatial databases. ACM Trans. Database Syst. (TODS) 30(2), 529–576 (2005)
Guo, L., Shao, J., Aung, H.H., Tan, K.L.: Efficient continuous top-k spatial keyword queries on road networks. GeoInformatica 19(1), 29–60 (2015)
Huang, W., Li, G., Tan, K.L., Feng, J.: Efficient safe-region construction for moving top-k spatial keyword queries. In: Proceedings of the 21st ACM International Conference on Information and Knowledge Management, pp. 932–941. ACM (2012)
Wu, D., Yiu, M.L., Jensen, C.S., Cong, G.: Efficient continuously moving top-k spatial keyword query processing. In: 2011 IEEE 27th International Conference on Data Engineering (ICDE), pp. 541–552. IEEE (2011)
Salgado, C., Cheema, M.A., Ali, M.E.: Continuous monitoring of range spatial keyword query over moving objects. World Wide Web 21, 1–26 (2017)
Cheema, M.A., Brankovic, L., Lin, X., Zhang, W., Wang, W.: Multi-guarded safe zone: an effective technique to monitor moving circular range queries. In: 2010 IEEE 26th International Conference on Data Engineering (ICDE), pp. 189–200. IEEE (2010)
Hu, H., Liu, Y., Li, G., Feng, J., Tan, K.L.: A location-aware publish/subscribe framework for parameterized spatio-textual subscriptions. In: 2015 IEEE 31st International Conference on Data Engineering (ICDE), pp. 711–722. IEEE (2015)
Oh, S., Jung, H., Kim, U.M.: An efficient processing of range spatial keyword queries over moving objects. In: 2018 International Conference on Information Networking (ICOIN) (in press)
Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781 (2013)
Mikolov, T., Yih, W.T., Zweig, G.: Linguistic regularities in continuous space word representations. In: HLT-NAACL, vol. 13, pp. 746–751 (2013)
Cong, G., Jensen, C.S., Wu, D.: Efficient retrieval of the top-k most relevant spatial web objects. Proc. VLDB Endow. 2(1), 337–348 (2009)
Kalashnikov, D.V., Prabhakar, S., Hambrusch, S.E.: Main memory evaluation of monitoring queries over moving objects. Distrib. Parallel Databases 15(2), 117–135 (2004)
Guttman, A.: R-trees: a dynamic index structure for spatial searching. ACM SIGMOD Rec. 14(2), 47–57 (1984)
Hu, H., Xu, J., Lee, D.L.: A generic framework for monitoring continuous spatial queries over moving objects. In: Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, pp. 479–490. ACM (2005)
MNTG: Minnesota Web-based Traffic Generator. http://mntg.cs.umn.edu
Acknowledgement
This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF- 2015R1D1A1A01057238, NRF-2016R1D1A1B03931098).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Oh, S., Jung, H., Koo, J., Kim, UM. (2018). Efficient Method for Processing Range Spatial Keyword Queries Over Moving Objects Based on Word2Vec. In: Yamamoto, S., Mori, H. (eds) Human Interface and the Management of Information. Information in Applications and Services. HIMI 2018. Lecture Notes in Computer Science(), vol 10905. Springer, Cham. https://doi.org/10.1007/978-3-319-92046-7_51
Download citation
DOI: https://doi.org/10.1007/978-3-319-92046-7_51
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-92045-0
Online ISBN: 978-3-319-92046-7
eBook Packages: Computer ScienceComputer Science (R0)