
Abstract
Message-locked encryption (MLE) (formalized by Bellare et al. [5]) is an important cryptographic primitive that supports deduplication in the cloud. Updatable block-level message-locked encryption (UMLE) (formalized by Zhao and Chow [13]) adds the update functionality to the MLE. In this paper, we formalize and extensively study a new cryptographic primitive file-updatable message-locked encryption (FMLE). FMLE can be viewed as a generalization of the UMLE, in the sense that unlike the latter, the former does not require the existence of BL-MLE (block-level message-locked encryption). FMLE allows more flexibility and efficient methods for updating the ciphertext and tag.
Our second contribution is the design of two efficient FMLE constructions, namely, RevD-1 and RevD-2, whose design principles are inspired from the very unique reverse decryption functionality of the FP hash function (designed by Paul et al. [11]) and the APE authenticated encryption (designed by Andreeva et al. [2]). With respect to UMLE – which provides so far the most efficient update function – RevD-1 and RevD-2 reduce the total update time by at least 50%, on average. Additionally, our constructions are storage efficient. We also give extensive comparison between our and the existing constructions.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
- Message-locked Encryption (MLE)
- Deduplication
- Reverse Decoding
- Total Update Time
- Proof Of Ownership (PoW)
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
MLE. Message-locked encryption (MLE) is a special type of encryption, where the decryption key is derived from the message itself. The main application of MLE is in the secure deduplication of data in the cloud, where MLE removes the need for storing multiple copies of identical data, without compromising their privacy and, thereby, helps to reduce the storage costs. Given the cloud services being on the rise, this primitive is gaining importance.
The first attempt to solve the problem of deduplication was made in 2002 by Douceur et al. [8], who came up with the idea of Convergent Encryption (CE). Bellare et al. [5] studied this subject in a formal way and named it message-locked encryption (MLE). They also gave efficient constructions of MLE.
UMLE. As seen before, MLE does not inherently support the file-update and the proof of ownership functionalities in its definition. UMLE solves this issue by adding three functionalities – file-update, PoW algorithms for prover and verifier – to the existing definition of MLE. The main drawback of UMLE is that the functionalities are constructed from another cryptographic primitive, namely, BL-MLE, which is nothing but MLE executed on a fixed-sized block. Such a BL-MLE-based UMLE entails degradation of performance for encryption and decryption [13]. Another drawback of UMLE is that the update of file-tag is an expensive operation.
Motivation for studying FMLE. From the high level, both UMLE and FMLE have identical functionalities; the main difference, however, is that the former is necessarily based on BL-MLE, but the latter may or may not be. Therefore, the definition of FMLE can be viewed as a generalisation of UMLE, where we remove the constraint of using BL-MLE. The motivation for studying FMLE is clear from the drawbacks of UMLE mentioned above. These motivations are:
Does there exist an FMLE scheme which is not based on BL-MLE? If such a construction exists, is it more efficient than UMLE?
Studying FMLE is a futile exercise, if both the answers are in the negative. A moment’s reflection suggests that the answer to the first question is actually ‘Yes’. A trivial FMLE construction – not based on BL-MLE – always exists, where the file-update function is designed the following way: apply decryption to the ciphertext to recover the original plaintext; edit/modify the original message; and finally encrypt the updated message. Note that this trivial file-update function does not need any BL-MLE, therefore, it is an FMLE, but certainly not a UMLE scheme. The main drawback of this FMLE scheme is that this is several orders of magnitude slower than a UMLE scheme. Therefore, the main challenge is:
Does there exists an FMLE scheme more efficient than UMLE?
Searching for such a construction is the main motivation of this paper.
Our Contribution. Our first contribution is formalizing the new cryptographic notion file-updatable message-locked encryption (FMLE). We also propose two efficient FMLE constructions RevD-1 and RevD-2: their update functions are at least \(50\%\) faster (on average).Footnote 1 Also, our constructions are more space efficient than the so-far best MLE variants; in particular, the ciphertext expansion and tag storage in RevD-1 and RevD-2 are constant, while they are logarithmic and linear (or may be worse) for other similar time-efficient cases. In order to obtain this improvement in the performance, our constructions critically exploit a very unique feature – what we call reverse decryption – of the hash function FP and the authenticated encryption APE. We also present proofs of security of our constructions. Extensive comparison of our constructions with the others – in terms of time complexity, storage requirements and security properties – have also been provided (see Table 1). Being randomized, our constructions are secure against the dictionary attacks, however, they lack STC security, like all other randomized MLEs.
Related Work. We now describe various pieces of work done by several researchers that are related to FMLE. Douceur et al. are the first to come up with the idea of Convergent Encryption (CE) in 2002, where the key was calculated as a hash of the message, and then this key was used for encryption [8]. Bellare, Keelveedhi and Ristenpart formalized CE in the form of message-locked encryption (MLE) [5]. They also provided a systematic discussion of various MLE schemes. In a separate paper, these authors also designed a new system DupLESS that supports deduplication even if the message entropy is low [4].
Beelare and Keelveedhi extended message-locked encryption to interactive message-locked encryption, and have addressed the cases when the messages are correlated as well as dependent on the public parameters, leading to weakened privacy [3]. Abadi et al. gave two new constructions for the i-MLE; these fully randomized schemes also supported equality-testing algorithm for finding ciphertexts derived from identical messages [1]. Jiang et al. gave an efficient logarithmic-time deduplication scheme that substantially reduces the equality-testing in the i-MLE schemes [10].
Canard, Laguillaumie and Paindavoine introduced deduplication consistency – a new security property – that prevents the clients from bypassing the deduplication protocol. This is accomplished by introducing a new feature named verifiability (of the well-formation) of ciphertext at the server [6]. They also proposed a new ElGamal-based construction satisfying this property. Wang et al. proposed a stronger security notion PRV-CDA3 and showed that their new construction ME is secure in this model [12].
Chen et al. proposed the block-level message-locked encryption (BL-MLE), which is nothing but breaking a big message into smaller chunks – called blocks – and then applying MLE on the individual blocks [7]. Huang, Zhang and Wang showed how to integrate the functionality proof of storage (PoS) with MLE by using a new data structure Quadruple Tags [9]. Zhao and Chow proposed the use of BL-MLE to design Efficiently Updatable Block-Level Message-Locked Encryption (UMLE) scheme which has an additional functionality of updating the ciphertext that costs sub-linear time [13].
Organization of the paper. In Sect. 2, we discuss the preliminaries including the notation and basic definitions. Section 3 describes the deduplication protocol. In Sect. 4, we give the formal definition of FMLE. In Sect. 5, we construct the FMLE schemes by tweaking the existing MLE and UMLE schemes. In Sect. 6, we describe the two new efficient FMLE schemes and we compare them with the various FMLE schemes and conclude our paper in Sect. 7.
2 Preliminaries
2.1 Notation
The expression \(M :=x\) denotes that the value of x is assigned to M, and \(M :=\mathcal {D}(x)\) denotes that the value returned by function \(\mathcal {D}(\cdot )\), on input x, is assigned to M. \(M = x\) denotes the equality comparison of the two variables M and x, and \(M = \mathcal {D}(x)\) denotes the equality comparison of the variable M with the output of \(\mathcal {D}(\cdot )\), on input x. The XOR or \(\oplus \) denotes the bit-by-bit exclusive-or operation on two binary strings of same length. The concatenation operation of \(p \ge 1\) strings \(s_1, s_2, \cdots , s_p\) and assignment to the variable s is denoted by \(s :=s_1 || s_2 || \cdots || s_p\). The parsing of string s into \(p \ge 1\) strings \(s_1, s_2, \cdots , s_p\) is denoted by \(s_1 || s_2 || \cdots || s_p :=s\). The length of string M is denoted by |M|. The set of all binary strings of length \(\ell \) is denoted by \(\{0,1\}^{\ell }\). The set of all binary strings of any length is denoted by \(\{0,1\}^{*}\). A vector of strings is denoted by \(\varvec{M}\) and i-th string in \(\varvec{M}\) is denoted by \(\varvec{M}^{(i)}\). The number of strings in \(\varvec{M}\) is denoted by \(\Vert \varvec{M}\Vert \). The infinite set of all binary strings of any length is denoted by \(\{0,1\}^{**}\). The set of all Natural numbers is denoted by \(\mathbb {N}\). We denote that M is assigned a binary string of length k chosen randomly and uniformly by \(M {\mathop {\leftarrow }\limits ^{\$}} \{0,1\}^{k}\). To mark any invalid string (may be input string or output string), the symbol \(\perp \) is used. \((\varvec{M}, Z) {\mathop {\leftarrow }\limits ^{\$}} \mathcal {S}(1^{\lambda })\) denotes the assignment of outputs given randomly and uniformly by \(\mathcal {S}\) to M and Z.
2.2 Dictionary Attack
A dictionary attack is defined to be a brute-force attack, where the adversary first builds a dictionary off-line, and then processes every element of the dictionary to determine the correct solution against an online challenge. For example, suppose that the hash of a message is given as a challenge to the adversary for her to determine the correct message. If the entropy of the message is low, then the adversary generates the dictionary of all possible messages and their corresponding hash values off-line; and given the online challenge, she selects the message whose hash value matches the challenge. Any deterministic MLE with low message entropy is broken by dictionary attack.
2.3 Proof of Ownership
Proof-of-ownership (PoW) is an interactive protocol where the owner of file proves the ownership of a file to the cloud storage. This protocol assumes that the adversary does not have access to the entire ciphertext which was uploaded onto the cloud by some previous (or first) owner, but he may know the tag, which is a small fraction of the entire information. In this protocol, the cloud storage provider generates a challenge Q and sends it to the client, along with some other information. The client computes the proof P corresponding to the given challenge Q and sends it back to the cloud. The cloud verifies it and if the verification is successful, then the client is granted access, otherwise the access is denied.
2.4 Ideal Permutation
Let \(\pi / \pi ^{-1} :\{0,1\}^{n} \mapsto \{0,1\}^{n}\) be a pair of oracles. The pair \(\pi / \pi ^{-1}\) is called an ideal permutation if the following three properties are satisfied.
-
1.
\(\pi ^{-1}(\pi (x)) = x\) and \(\pi (\pi ^{-1} (x))=x\), for all \(x \in \{0,1\}^{n}\).
-
2.
Suppose, \(x_k\) is the k-th query (\(k \ge 1\)), submitted to the oracle \(\pi \), and \(y \in \{0,1\}^{n}\). Then, for the current query \(x_i\):
$$ \Pr \Big [\pi (x_i)=y \Big | \pi (x_1) = y_1, \pi (x_2) = y_2, \cdots , \pi (x_{i-1}) = y_{i-1}\Big ] $$$$\begin{aligned} = {\left\{ \begin{array}{ll} 1, &{} \text{ if }\,\, x_i = x_j, y = y_j, j<i. \\ 0, &{} \text{ if }\,\, x_i = x_j, y \ne y_j, j<i, \\ 0, &{} \text{ if }\,\, x_i \ne x_j, y = y_j, j<i, \\ \frac{1}{2^n-i+1}, &{} \text{ if }\,\, x_i \ne x_j, y \ne y_j, j<i. \end{array}\right. } \end{aligned}$$ -
3.
Suppose, \(y_k\) is the k-th query (\(k \ge 1\)), submitted to the oracle \(\pi ^{-1}\), and \(x \in \{0,1\}^{n}\). Then, for the current query \(y_i\):
$$ \Pr \Big [\pi ^{-1}(y_i)=x \Big | \pi ^{-1}(y_1) = x_1, \pi ^{-1}(y_2) = x_2, \cdots , \pi ^{-1}(y_{i-1}) = x_{i-1}\Big ] $$$$\begin{aligned} = {\left\{ \begin{array}{ll} 1, &{} \text{ if } y_i = y_j, x = x_j, j<i\text{. } \\ 0, &{} \text{ if } y_i = y_j, x \ne x_j, j<i\text{, } \\ 0, &{} \text{ if } y_i \ne y_j, x = x_j, j<i\text{, } \\ \frac{1}{2^n-i+1}, &{} \text{ if } y_i \ne y_j, x \ne x_j, j<i. \end{array}\right. } \end{aligned}$$
2.5 Other Definitions
Due to space constraints, the definitions of unpredictable sources, message-locked encryption (MLE), updatable block-level message-locked encryption (UMLE), hash function and one-time symmetric encryption will appear in the full version of the paper.
3 Deduplication: An Application of FMLE
Deduplication is a mechanism by which a protocol removes the requirement for storing multiple copies of an identical file in memory. This is highly beneficial for the better utilization of space in the cloud, where multiple users often store identical files. Loosely speaking, it does so, by identifying the identical files, removing all the copies except one, and then attaching a special file called the list of owners to it. In Fig. 1, we give the details of the deduplication protocol supporting file-update and proof of ownership (PoW) functionalities. Although, intuitively clear, we would like to point out that the authentication of users is not a part of this protocol; the system, otherwise, takes care of that through various well-known means such as password-based/bio-metric authentications, etc.
The deduplication protocol with file-update and PoW functionalities, has three functions: client uploading data to the server, as shown in Fig. 1(a); client downloading data from the server, as shown in Fig. 1(b); and client updating data to the server, as shown in Fig. 1(c). Due to space constraints, the textual description has been omitted and will appear in the full version of the paper.

Upload, download and update protocols in the deduplication protocol.
4 FMLE: A New Cryptographic Primitive
The File updatable Message-Locked Encryption (FMLE) is a generalisation of Efficiently Updatable Block-Level Message-Locked Encryption (UMLE) as given by Zhao and Chow [13]. The difference between the definitions of UMLE and FMLE is that the former requires the existence of a BL-MLE scheme, while the latter does not.Footnote 2 Therefore, any UMLE scheme can be viewed as an FMLE scheme too, not the other way round.
Below we elaborately discuss the syntax, correctness and security definition of the new notion FMLE.
4.1 Syntax
Suppose \(\lambda \in \mathbb {N}\) is the security parameter. An FMLE scheme 
 is five-tuple of algorithms over a PPT setup
is five-tuple of algorithms over a PPT setup  . \(\varPi \) satisfies the following conditions.
. \(\varPi \) satisfies the following conditions.
-
1.
The PPT setup algorithm
 outputs the parameter params and the sets \(\mathcal {K}\), \(\mathcal {M}\), \(\mathcal {C}\) and \(\mathcal {T}\), denoting the key, message, ciphertext and tag spaces respectively.
outputs the parameter params and the sets \(\mathcal {K}\), \(\mathcal {M}\), \(\mathcal {C}\) and \(\mathcal {T}\), denoting the key, message, ciphertext and tag spaces respectively. -
2.
The PPT encryption algorithm
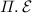 takes as inputs params and \(M \in \mathcal {M}\), and returns a 3-tuple
takes as inputs params and \(M \in \mathcal {M}\), and returns a 3-tuple  , where \(K \in \mathcal {K}\), \(C \in \mathcal {C}\) and \(T \in \mathcal {T}\).
, where \(K \in \mathcal {K}\), \(C \in \mathcal {C}\) and \(T \in \mathcal {T}\). -
3.
The decryption algorithm
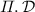 is a deterministic algorithm that takes as inputs params, \(K \in \mathcal {K}\), \(C \in \mathcal {C}\) and \(T \in \mathcal {T}\), and returns
is a deterministic algorithm that takes as inputs params, \(K \in \mathcal {K}\), \(C \in \mathcal {C}\) and \(T \in \mathcal {T}\), and returns 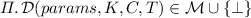 . The decryption algorithm \(\mathcal {D}\) returns \(\perp \) if the key K, ciphertext C and tag T are not generated from a valid message.
. The decryption algorithm \(\mathcal {D}\) returns \(\perp \) if the key K, ciphertext C and tag T are not generated from a valid message. -
4.
The PPT update algorithm
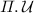 takes as inputs params, the index of starting and ending bits \(i_{st}\) and \(i_{end}\), new message bits \(M_{\text {new}} \in \mathcal {M}\), the decryption key \(K \in \mathcal {K}\), the ciphertext to be updated \(C \in \mathcal {C}\), the tag to be updated \(T \in \mathcal {T}\) and the bit \(app \in \{0,1\}^{}\) indicating change in length of new message, and returns a 3-tuple
takes as inputs params, the index of starting and ending bits \(i_{st}\) and \(i_{end}\), new message bits \(M_{\text {new}} \in \mathcal {M}\), the decryption key \(K \in \mathcal {K}\), the ciphertext to be updated \(C \in \mathcal {C}\), the tag to be updated \(T \in \mathcal {T}\) and the bit \(app \in \{0,1\}^{}\) indicating change in length of new message, and returns a 3-tuple 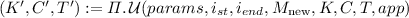 , where \(K' \in \mathcal {K}\), \(C' \in \mathcal {C}\) and \(T' \in \mathcal {T}\).
, where \(K' \in \mathcal {K}\), \(C' \in \mathcal {C}\) and \(T' \in \mathcal {T}\). -
5.
The PPT proof-of-ownership (PoW) algorithm for prover
 takes as inputs parameter params, challenge Q, a file \(M \in \mathcal {M}\), the decryption key \(K \in \mathcal {K}\), the ciphertext \(C \in \mathcal {C}\), the tag \(T \in \mathcal {T}\), and returns the proof
takes as inputs parameter params, challenge Q, a file \(M \in \mathcal {M}\), the decryption key \(K \in \mathcal {K}\), the ciphertext \(C \in \mathcal {C}\), the tag \(T \in \mathcal {T}\), and returns the proof 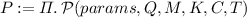 .
. -
6.
The PPT proof-of-ownership (PoW) algorithm for verifier
 takes as inputs parameter params, challenge Q, ciphertext \(C \in \mathcal {C}\), tag \(T \in \mathcal {T}\) and proof P, and returns the value
takes as inputs parameter params, challenge Q, ciphertext \(C \in \mathcal {C}\), tag \(T \in \mathcal {T}\) and proof P, and returns the value  , where \(val \in \{\textsf {TRUE},\textsf {FALSE}\}\).
, where \(val \in \{\textsf {TRUE},\textsf {FALSE}\}\). -
7.
We restrict |C| to be a linear function of |M|.
 outputs the parameter params and the sets
outputs the parameter params and the sets 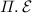 takes as inputs params and
takes as inputs params and  , where
, where 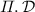 is a deterministic algorithm that takes as inputs params,
is a deterministic algorithm that takes as inputs params, 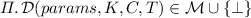 . The decryption algorithm
. The decryption algorithm 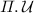 takes as inputs params, the index of starting and ending bits
takes as inputs params, the index of starting and ending bits 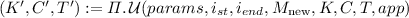 , where
, where  takes as inputs parameter params, challenge Q, a file
takes as inputs parameter params, challenge Q, a file 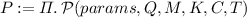 .
. takes as inputs parameter params, challenge Q, ciphertext
takes as inputs parameter params, challenge Q, ciphertext  , where
, where 4.2 Correctness
Key Correctness. Suppose  , and \((K',C',T')\)
, and \((K',C',T')\)  . Then key correctness of \(\varPi \) requires that if \(M=M'\), then \(K=K'\), for all \(\lambda \in \mathbb {N}\) and all \(M, M' \in \mathcal {M}\).
. Then key correctness of \(\varPi \) requires that if \(M=M'\), then \(K=K'\), for all \(\lambda \in \mathbb {N}\) and all \(M, M' \in \mathcal {M}\).
Decryption Correctness. Suppose  . Then decryption correctness of \(\varPi \) requires that
. Then decryption correctness of \(\varPi \) requires that  , for all \(\lambda \in \mathbb {N}\) and all \(M \in \mathcal {M}\).
, for all \(\lambda \in \mathbb {N}\) and all \(M \in \mathcal {M}\).
Tag Correctness. Suppose  , and \((K',C',T')\)
, and \((K',C',T')\)  . Then tag correctness of \(\varPi \) requires that if \(M=M'\), then \(T=T'\), for all \(\lambda \in \mathbb {N}\) and all \(M, M' \in \mathcal {M}\).
. Then tag correctness of \(\varPi \) requires that if \(M=M'\), then \(T=T'\), for all \(\lambda \in \mathbb {N}\) and all \(M, M' \in \mathcal {M}\).
Update Correctness. Suppose \(\ell = |M|\),  , and
, and  . Then update correctness of \(\varPi \) requires that, for all \(\lambda \in \mathbb {N}\), all \(M \in \mathcal {M}\), \(1 \le i_{st}\le \ell \) and \(i_{st} < i_{end}\):
. Then update correctness of \(\varPi \) requires that, for all \(\lambda \in \mathbb {N}\), all \(M \in \mathcal {M}\), \(1 \le i_{st}\le \ell \) and \(i_{st} < i_{end}\):
-
for \(app=1\),
 ||M[2] \(||\cdots ||\) \(M[i_{st}-1]\) \(||M_{\text {new}}\), and
||M[2] \(||\cdots ||\) \(M[i_{st}-1]\) \(||M_{\text {new}}\), and -
for \(app=0\),
 ||M[2] \(||\cdots ||\) \(M[i_{st}-1]\) \(||M_{\text {new}}\) \(||M[i_{end}+1]||M[i_{end}+2]||\cdots ||M[\ell ]\).
||M[2] \(||\cdots ||\) \(M[i_{st}-1]\) \(||M_{\text {new}}\) \(||M[i_{end}+1]||M[i_{end}+2]||\cdots ||M[\ell ]\).
 ||M[2]
||M[2]  ||M[2]
||M[2] PoW Correctness. Suppose  , Q is any challenge and
, Q is any challenge and  . Then PoW correctness of \(\varPi \) requires that
. Then PoW correctness of \(\varPi \) requires that  , for all \(\lambda \in \mathbb {N}\) and all \(M \in \mathcal {M}\).
, for all \(\lambda \in \mathbb {N}\) and all \(M \in \mathcal {M}\).
4.3 Security Definitions
Security definitions of FMLE are naturally adapted from those of UMLE. For the sake of completeness, we describe them below in full detail. As usual, all the games are written in the form of challenger-adversary framework.

Games defining PRV$-CDA, STC, TC, CXH and UNC-CDA security of FMLE scheme  . In CXH and UNC-CDA games, adversary \(\mathcal {A}=(\mathcal {A}_1,\mathcal {A}_2)\)
. In CXH and UNC-CDA games, adversary \(\mathcal {A}=(\mathcal {A}_1,\mathcal {A}_2)\)
Privacy. Let  be an FMLE scheme. Since, no MLE scheme can provide security for predictable messages, we are modelling the security based on the unpredictable message source
be an FMLE scheme. Since, no MLE scheme can provide security for predictable messages, we are modelling the security based on the unpredictable message source  . According to the PRV$-CDA game, as in Fig. 2, the challenger gets a vector of messages, \(\varvec{M}\) and the auxiliary information Z, from the source \(\mathcal {S}(\cdot )\). The challenger does the following operations: computes the decryption key \(\varvec{K}_1^{(i)}\), ciphertext \(\varvec{C}_1^{(i)}\) and tag \(\varvec{T}_1^{(i)}\) for each message string \(\varvec{M}^{(i)}\) using
. According to the PRV$-CDA game, as in Fig. 2, the challenger gets a vector of messages, \(\varvec{M}\) and the auxiliary information Z, from the source \(\mathcal {S}(\cdot )\). The challenger does the following operations: computes the decryption key \(\varvec{K}_1^{(i)}\), ciphertext \(\varvec{C}_1^{(i)}\) and tag \(\varvec{T}_1^{(i)}\) for each message string \(\varvec{M}^{(i)}\) using  , where \(i \in \{1,2,\cdots , m(1^{\lambda })\}\); computes the random strings \(\varvec{K}_0^{(i)}\), \(\varvec{C}_0^{(i)}\) and \(\varvec{T}_0^{(i)}\) of length \(|\varvec{K}_1^{(i)}|\), \(|\varvec{C}_1^{(i)}|\) and \(|\varvec{T}_1^{(i)}|\) respectively; and returns \((\varvec{C}_b, \varvec{T}_b, Z)\) to the adversary. The adversary has to return a bit \(b'\) indicating whether the ciphertext \(\varvec{C}_b\) and tag \(\varvec{T}_b\) corresponds to message \(\varvec{M}\) or is it a collection of random strings. If the values of b and \(b'\) coincide, then the adversary wins the game.
, where \(i \in \{1,2,\cdots , m(1^{\lambda })\}\); computes the random strings \(\varvec{K}_0^{(i)}\), \(\varvec{C}_0^{(i)}\) and \(\varvec{T}_0^{(i)}\) of length \(|\varvec{K}_1^{(i)}|\), \(|\varvec{C}_1^{(i)}|\) and \(|\varvec{T}_1^{(i)}|\) respectively; and returns \((\varvec{C}_b, \varvec{T}_b, Z)\) to the adversary. The adversary has to return a bit \(b'\) indicating whether the ciphertext \(\varvec{C}_b\) and tag \(\varvec{T}_b\) corresponds to message \(\varvec{M}\) or is it a collection of random strings. If the values of b and \(b'\) coincide, then the adversary wins the game.
We define the advantage of an PRV$-CDA adversary \(\mathcal {A}\) against \(\varPi \) for the message source \(\mathcal {S}(\cdot )\) as:
An FMLE scheme \(\varPi \) is said to be PRV$-CDA secure over a set of valid PT sources for FMLE scheme \(\varPi \), \(\overline{\mathcal {S}} = \{\mathcal {S}_1, \mathcal {S}_2, \cdots \}\), for all PT adversaries \(\mathcal {A}\) and for all \(\mathcal {S}_i \in \overline{\mathcal {S}}\), if \(Adv^{\textsf {PRV\$-CDA}}_{\varPi ,\mathcal {S}_i,\mathcal {A}} (\cdot )\) is negligible. An FMLE scheme \(\varPi \) is said to be PRV$-CDA secure, for all PT adversaries \(\mathcal {A}\), if \(Adv^{\textsf {PRV\$-CDA}}_{\varPi ,\mathcal {S},\mathcal {A}} (\cdot )\) is negligible, for all valid PT source \(\mathcal {S}\) for \(\varPi \).
Tag Consistency. Let  be an FMLE scheme. For an FMLE scheme, we have designed the STC and TC security games in Fig. 2, which aim to provide security against duplicate faking attacks. In addition, STC provides safeguards against erasure attack. In a duplicate faking attack, two unidentical messages – one fake message produced by an adversary and a legitimate one produced by an honest client – produce the same tag, thereby cause loss of message and hamper the integrity. In an erasure attack, the adversary replaces the ciphertext with a fake message that decrypts successfully.
be an FMLE scheme. For an FMLE scheme, we have designed the STC and TC security games in Fig. 2, which aim to provide security against duplicate faking attacks. In addition, STC provides safeguards against erasure attack. In a duplicate faking attack, two unidentical messages – one fake message produced by an adversary and a legitimate one produced by an honest client – produce the same tag, thereby cause loss of message and hamper the integrity. In an erasure attack, the adversary replaces the ciphertext with a fake message that decrypts successfully.
The adversary returns a message M, a ciphertext \(C'\) and a tag \(T'\). If the message or ciphertext is invalid, the adversary loses the game. Otherwise, the challenger computes decryption key \(K_D\), ciphertext C and tag T corresponding to message M, and computes the message \(M'\) corresponding to ciphertext \(C'\) and tag \(T'\) using key \(K_D\). If the two tags are equal, i.e. \(T=T'\), the message \(M'\) is valid, i.e. \(M' \ne \perp \), and the two messages are unequal, i.e. \(M \ne M'\), then the adversary wins.
Now, we define the advantage of a TC adversary \(\mathcal {A}\) against \(\varPi \) as:
Now, we define the advantage of an STC adversary \(\mathcal {A}\) against \(\varPi \) as:
An FMLE scheme \(\varPi \) is said to be TC (or STC) secure, for all PT adversaries \(\mathcal {A}\), if \(Adv^{\textsf {TC}}_{\varPi ,\mathcal {A}} (\cdot )\) (or \(Adv^{\textsf {STC}}_{\varPi ,\mathcal {A}} (\cdot )\)) is negligible.
Context Hiding. Let  be an FMLE scheme. For an FMLE, we have designed the CXH game in Fig. 2, which aims to provide security against distinguishing between an updated ciphertext and a ciphertext encrypted from scratch, to ensure that the level of privacy is not compromised during update process.
be an FMLE scheme. For an FMLE, we have designed the CXH game in Fig. 2, which aims to provide security against distinguishing between an updated ciphertext and a ciphertext encrypted from scratch, to ensure that the level of privacy is not compromised during update process.
According to the CXH game, as in Fig. 2, the adversary returns two messages \(M_0\) and \(M_1\) such that \(M_0\) and \(M_1\) are identical for all bits except \(\sigma \) bits. The challenger calculates the bit-positions \(i_1, i_2, \cdots , i_{\rho }\) where \(M_0\) and \(M_1\) differ, and the adversary loses if \(\rho > \sigma \). The challenger encrypts the two messages \(M_0\) and \(M_1\) to generate \((K_0,C_0,T_0)\) and \((K_1,C_1,T_1)\) and updates the \(C_1\) with \(M_0[i_1,i_1+1,\cdots ,i_{\rho }]\) to obtain \((K'_1,C'_1,T'_1)\). The challenger then sends either \(C_0\) or \(C'_1\), depending on the value of b, to the adversary. The adversary has to return a bit \(b'\) indicating whether the ciphertext is built from scratch or is an updated ciphertext. If the values of b and \(b'\) are equal, then the adversary wins the game.
Now, we define the advantage of a CXH adversary \(\mathcal {A}\) for \(\sigma \)-bit update in message, against \(\varPi \) as:
An FMLE scheme \(\varPi \) is said to be CXH secure, for \(\sigma \)-bit update in message, for all PT adversaries \(\mathcal {A}\), if \(Adv^{\textsf {CXH}}_{\varPi ,\mathcal {A}} (\cdot ,\cdot )\) is negligible.
Proof of ownership. Let  be an FMLE scheme. For an FMLE, we have designed the UNC-CDA game in Fig. 2, which aims to provide security against the adversary in proving that they possess the entire file when they actually have only a partial information about the file. This is to block the unauthorised ownership of the file.
be an FMLE scheme. For an FMLE, we have designed the UNC-CDA game in Fig. 2, which aims to provide security against the adversary in proving that they possess the entire file when they actually have only a partial information about the file. This is to block the unauthorised ownership of the file.
According to the UNC-CDA game, as in Fig. 2, the adversary returns an unpredictable message source  . The challenger gets a message M and the auxiliary information Z, from this source. The challenger then send the challenge Q and the auxiliary information Z to the adversary and the adversary returns a proof \(P^*\). The challenger generates the proof P for the same challenge. If \(P^*\) is successfully verified by the PoW verifier algorithm
. The challenger gets a message M and the auxiliary information Z, from this source. The challenger then send the challenge Q and the auxiliary information Z to the adversary and the adversary returns a proof \(P^*\). The challenger generates the proof P for the same challenge. If \(P^*\) is successfully verified by the PoW verifier algorithm  and P is different from \(P^*\), then the adversary wins the game.
and P is different from \(P^*\), then the adversary wins the game.
Now, we define the advantage of a UNC-CDA adversary \(\mathcal {A}\) against an uncheatable chosen distribution attack against \(\varPi \) for a message source source \(\mathcal {S}(\cdot )\) as:
An FMLE scheme \(\varPi \) is said to be UNC-CDA secure, for all PT adversaries \(\mathcal {A}\), if \(Adv^{\textsf {UNC-CDA}}_{\varPi ,\mathcal {A}} (\cdot )\) is negligible.
5 Practical FMLE Constructions from Existing MLE and UMLE Schemes
The description and security properties of F-CE, F-HCE2 & F-RCE and F-UMLE schemes will appear in the full version of the paper.
6 New Efficient FMLE Schemes
In this section we present the two new efficient constructions for FMLE – namely RevD-1 and RevD-2 – which are based on a \(2\lambda \)-bit easy-to-invert permutation \(\pi \). We assume that the length of message is a multiple of \(\lambda \); \(\lambda \) is the security parameter.
6.1 The RevD-1 Scheme
We describe our first FMLE scheme, namely, RevD-1. This construction is motivated by the design of the hash function mode of operation FP [11].
Description of RevD-1. The pictorial and algorithmic descriptions are given in Figs. 3 and 4; all wires are \(\lambda \)-bit long. Let M denote the message to be encrypted, M[i] denote the i-th block of message, and M[i][j] denote the j-th bit of i-th block of message. It is worth noting that the decryption is executed in the reverse direction of encryption. The detailed textual description of the 5-tuple of algorithms will appear in the full version of the paper.

Diagrammatic description of RevD-1.

Algorithmic description of the FMLE scheme RevD-1 for message \(\varvec{M}_{i}\).
Security of RevD-1. The details of the proofs for the PRV$-CDA, TC, CXH and UNC-CDA security of RevD-1 will appear in the full version.
6.2 The RevD-2 Scheme
We describe our second FMLE scheme, namely, RevD-2. This construction is motivated by the design of the authenticated encryption APE [2].
Description of RevD-2. The pictorial and algorithmic descriptions are given in Figs. 5 and 6; all wires are \(\lambda \)-bit long. Let M denote the message to be encrypted, M[i] denote the i-th block of message, and M[i][j] denote the j-th bit of i-th block of message. It is worth noting that the decryption is executed in the reverse direction of encryption. The detailed textual description of the 5-tuple of algorithms will appear in the full version of the paper.

Diagrammatic description of RevD-2.

Algorithmic description of the FMLE scheme RevD-2.
Security of RevD-2. The details of the proofs for the PRV$-CDA, TC, CXH and UNC-CDA security of RevD-2 will appear in the full version.
Resistance of RevD-1 and RevD-2 Against Dictionary Attack. Since, RevD-1 and RevD-2 have randomized encryption algorithms, they are not vulnerable to dictionary attacks (see Sect. 2.2 for a definition of dictionary attack).
6.3 Comparing RevD-1 and RevD-2 with the Other FMLE Schemes
In Table 1, we compare the RevD-1 and RevD-2 with the other FMLE constructions described in Sect. 5, on the basis of time and space complexities, and the security properties.
In summary, the FMLE schemes RevD-1 and RevD-2 possess the randomization property of MLE construction RCE, and the efficient update property of UMLE. It is also noted that it outperforms all the constructions in terms of the number of passes.
7 Conclusion
In this paper, we present a new cryptographic primitive FMLE and two new constructions of it: RevD-1 and RevD-2. We showed that these constructions perform better – both with respect to time and memory – than the existing constructions. The high performance is attributed to a unique property named reverse decryption of the FP hash function and the APE authenticated encryption, on which these new constructions are based. The only disadvantage is, perhaps, that these constructions are not STC secure. We leave as an open problem construction of an STC secure efficient FMLE.
Notes
- 1.
The term RevD is a shorthand for Reverse Decryption.
- 2.
A block-level message-locked encryption (BL-MLE) is an MLE that works on the fixed-sized messages, called blocks.
References
Abadi, M., Boneh, D., Mironov, I., Raghunathan, A., Segev, G.: Message-locked encryption for lock-dependent messages. In: Canetti, R., Garay, J.A. (eds.) CRYPTO 2013. LNCS, vol. 8042, pp. 374–391. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-40041-4_21
Andreeva, E., Bilgin, B., Bogdanov, A., Luykx, A., Mennink, B., Mouha, N., Yasuda, K.: APE: authenticated permutation-based encryption for lightweight cryptography. In: Cid, C., Rechberger, C. (eds.) FSE 2014. LNCS, vol. 8540, pp. 168–186. Springer, Heidelberg (2015). https://doi.org/10.1007/978-3-662-46706-0_9
Bellare, M., Keelveedhi, S.: Interactive message-locked encryption and secure deduplication. In: Katz, J. (ed.) PKC 2015. LNCS, vol. 9020, pp. 516–538. Springer, Heidelberg (2015). https://doi.org/10.1007/978-3-662-46447-2_23
Bellare, M., Keelveedhi, S., Ristenpart, T.: DupLESS: server-aided encryption for deduplicated storage. In: King, S. (ed.) USENIX 2013, pp. 179–194 (2013)
Bellare, M., Keelveedhi, S., Ristenpart, T.: Message-locked encryption and secure deduplication. In: Johansson, T., Nguyen, P.Q. (eds.) EUROCRYPT 2013. LNCS, vol. 7881, pp. 296–312. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-38348-9_18
Canard, S., Laguillaumie, F., Paindavoine, M.: Verifiable message-locked encryption. In: Foresti, S., Persiano, G. (eds.) CANS 2016. LNCS, vol. 10052, pp. 299–315. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-48965-0_18
Chen, R., Mu, Y., Yang, G., Guo, F.: BL-MLE: block-level message-locked encryption for secure large file deduplication. IEEE Trans. Inf. Forensics Secur. 10(12), 2643–2652 (2015). https://doi.org/10.1109/TIFS.2015.2470221
Douceur, J.R., Adya, A., Bolosky, W.J., Simon, D., Theimer, M.: Reclaiming space from duplicate files in a serverless distributed file system. In: ICDCS 2002, pp. 617–624 (2002). https://doi.org/10.1109/ICDCS.2002.1022312
Huang, K., Zhang, X., Wang, X.: Block-level message-locked encryption with polynomial commitment for IoT data. J. Inf. Sci. Eng. (JISE), 33(4), 891–905 (2017). http://jise.iis.sinica.edu.tw/JISESearch/pages/View/PaperView.jsf?keyId=157_2047
Jiang, T., Chen, X., Wu, Q., Ma, J., Susilo, W., Lou, W.: Towards efficient fully randomized message-locked encryption. In: Liu, J.K.K., Steinfeld, R. (eds.) ACISP 2016. LNCS, vol. 9722, pp. 361–375. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-40253-6_22
Paul, S., Homsirikamol, E., Gaj, K.: A novel permutation-based hash mode of operation FP and the hash function SAMOSA. In: Galbraith, S., Nandi, M. (eds.) INDOCRYPT 2012. LNCS, vol. 7668, pp. 509–527. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-34931-7_29
Wang, H., Chen, K., Qin, B., Lai, X., Wen, Y.: A new construction on randomized message-locked encryption in the standard model via UCEs. Sci. China Inf. Sci. 60(5), 052101 (2017). https://doi.org/10.1007/s11432-015-1037-2
Zhao, Y., Chow, S.S.M.: Updatable block-level message-locked encryption. In: Karri, R., Sinanoglu, O., Sadeghi, A., Yi, X. (eds.) Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, AsiaCCS 2017, Abu Dhabi, United Arab Emirates, 2–6 April 2017, pp. 449–460. ACM (2017). https://doi.org/10.1145/3052973.3053012
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Kandele, S., Paul, S. (2018). Message-Locked Encryption with File Update. In: Preneel, B., Vercauteren, F. (eds) Applied Cryptography and Network Security. ACNS 2018. Lecture Notes in Computer Science(), vol 10892. Springer, Cham. https://doi.org/10.1007/978-3-319-93387-0_35
Download citation
DOI: https://doi.org/10.1007/978-3-319-93387-0_35
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-93386-3
Online ISBN: 978-3-319-93387-0
eBook Packages: Computer ScienceComputer Science (R0)