
Abstract
Although the amount of RDF data has been steadily increasing over the years, the majority of information on the Web is still residing in other formats, and is often not accessible to Semantic Web services. A lot of this data is available through APIs serving JSON documents. In this work we propose a way of extending SPARQL with the option to consume JSON APIs and integrate the obtained information into SPARQL query answers, thus obtaining a query language allowing to bring data from the “traditional” Web to the Semantic Web. Looking to evaluate these queries as efficiently as possible, we show that the main bottleneck is the amount of API requests, and present an algorithm that produces “worst-case optimal” query plans that reduce the number of requests as much as possible. We also do a set of experiments that empirically confirm the optimality of our approach.
You have full access to this open access chapter, Download conference paper PDF
1 Introduction
The Semantic Web provides a platform for publishing data on the Web via the Resource Description Framework (RDF). Having a common format for data dissemination allows for applications of increasing complexity since it enables them to access data obtained from different sources, or describing different entities. The most common way of accessing this information is through SPARQL endpoints; SPARQL is the standard language for accessing data on the Semantic Web [20], and a SPARQL endpoint is a simple interface where users can obtain the RDF data available on the server by executing a SPARQL query.
In the Web context it is rarely the case that one can obtain all the needed information from a single data source, and therefore it is necessary to draw the data from multiple servers or endpoints. In order to address this, a specific operator that allows parts of the query to access different SPARQL endpoints, called SERVICE, was included into the latest version of the language [30].
However, the majority of the data available on the Web today is still not published as RDF, which makes it difficult to connect it to Semantic Web services. A huge amount of this data is made available through Web APIs which use a variety of different formats to provide data to the users. It is therefore important to make all of this data available to Semantic Web technologies, in order to create a truly connected Web. One way of achieving this is to extend the SERVICE operator of SPARQL with the ability to connect to Web APIs in the same way as it connects to other SPARQL endpoints. In this paper we make a first step in this direction by extending SERVICE with the option to connect to JSON APIs and incorporate their data into SPARQL query answers. We picked JSON because it is currently one of the most popular data formats used in Web APIs, but the results presented in the paper can easily be extended to any API format.
By allowing SPARQL to connect to an API we can extend the query answer with data obtained from a Web service, in real time and without any setup. Use cases for such an extension are numerous and can be particularly practical when the data obtained from the API changes very often (such as weather conditions, state of the traffic, etc.). To illustrate this let us consider the following example.
Example 1
We find ourselves in Scotland in order to do some hiking. We obtain a list of all Scottish mountains using the WikiData SPARQL endpoint, but we would prefer to hike in a place that is sunny. This information is not in WikiData, but is available through a weather service API called weather.api. This API implements HTTP requests, so for example to retrieve the weather on Ben Nevis, the highest mountain in the UK, we can issue a GET request with the IRI:

The API responds with a JSON document containing weather information, say of the form

Therefore, to obtain all Scottish mountains with a favourable weather all we need to do is call the API for each mountain on our list, keeping only those records where the weather condition is "clear sky". One can do this manually, but this quickly become cumbersome, particularly when the number of API calls is large. Instead, we propose to extend the functionality of SPARQL SERVICE, allowing it to communicate with JSON APIs such as the weather service above. For our example we can use the following (extended) query:

The first part of our query is meant to retrieve the IRI and label of the mountain in WikiData. The extended SERVICE operator then takes the (instantiated) URI template where the variable ?l is replaced with the label of the mountain, and upon executing the API call processes the received JSON document using an expression ["description"], which extracts from this document the value under the key description, and binds it to the variable ?d. Finally, we filter out those locations with undesirable weather conditions. \(\square \)
With the ability of querying endpoints and APIs in real time we face an even more challenging task: How do we evaluate such queries? Connecting to APIs poses an interesting new problem from a database perspective, as the bottleneck shifts from disk access to the amount of API calls. For example, when evaluating the query in Example 1, about \(80\%\) of the time is spent in API calls. This is mostly because HTTP requests are slower that disk access, something we cannot control. To gauge the time taken for APIs to respond to a GET request we did a quick study of five popular Web APIs. The results presented in Table 1 show us the minimum, the maximum, and the average time over our calls for each API.
Hence, to evaluate these queries efficiently we need to understand how to produce a query plan for them that minimizes the number of calls to the API.
Contributions. Our main contributions can be summarized as follows:
-
Formalization. We formalize the syntax and the semantics of the SERVICE extension which supports communication with JSON APIs. This is done in a modular way, similar to the SPARQL formalization of [28], making it easy to incorporate this extension into the language standard.
-
Implementation. We provide a fully functional implementation of the extended SERVICE operator within the Apache Jena framework, and test its functionality on a range of queries over real world and synthetic data sources. We also set up a demo at [2] for trying out the new functionality.
-
Optimization. Given that the most likely bottleneck for our queries is the number of API calls, we design, implement and test a series of optimizations based on the AGM bound [8, 27] for estimating the number of intermediate results in relational joins, resulting in a worst case optimal algorithm for evaluating a large fragment of SPARQL patterns that uses remote SERVICE calls.
Related Work. Standard SERVICE that connects to SPARQL endpoints has been extensively studied in the literature [5,6,7, 24, 25]. The main conclusions regarding efficiency in this context resonate with our argument that the amount of calls to external endpoints is the main bottleneck for evaluation. For standard SERVICE there are several techniques we can use to alleviate this issue (see e.g. [6, 7]), and for our implementation we opt for the one that minimizes the database load. In terms of bringing arbitrary API information into SPARQL most of the works [14, 23, 26, 31] are based on the idea of building RDF wrappers for other formats. This is somewhat orthogonal to our approach and can be prohibitively expensive when the API data changes often (like in Example 1). The most similar to our work are the approaches of [9, 15, 16] that incorporate API data directly into SPARQL, but do not provide a worst-case optimal implementation, nor formal semantics of the extended SERVICE operation. Our paper is a continuation of the demo presentation [22].
Organization. We recall standard notions in Sect. 2. The formal definition and examples of the extended SERVICE are given in Sect. 3. The worst-case optimal algorithm for evaluating queries that use SERVICE is presented in Sect. 4. Experimental evaluation is given in Sect. 5. For space reasons detailed proofs can be found in our online appendix [1], and further examples at [2].
2 Preliminaries
RDF Graphs. Let \(\mathbf I \), \(\mathbf{L}\), and \(\mathbf{B}\) be infinite disjoint sets of IRIs, literals, and blank nodes, respectively. The set of RDF terms \(\mathbf{T}\) is \(\mathbf I \cup \mathbf{L}\cup \mathbf{B}\). An RDF triple is a triple (s, p, o) from \(\mathbf{T}\times \mathbf I \times \mathbf{T}\), where s is called subject, p predicate, and o object. An (RDF) graph is a finite set of RDF triples. For simplicity we assume that RDF databases consist of a single RDF graph, although our proposal can easily be extended to deal with datasets with multiple graphs.
SPARQL Queries. We assume the reader is familiar with the syntax and semantics of \(\text {SPARQL} \) 1.1 query language [20], as well as the abstraction proposed in [28]. We use this abstraction for our theoretical work, but examples are stated in the standard syntax.
Following [28], we define queries via graph patterns. Graph patterns are defined over terms \(\mathbf{T}\) and an infinite set \(\mathbf{V}= \{?x, ?y, \ldots \}\) of variables. The basic graph pattern is called a triple pattern, and is a tuple \(t\in (\mathbf I \cup \mathbf{V})\times (\mathbf I \cup \mathbf{V})\times (\mathbf I \cup \mathbf{V}\cup \mathbf{L})\). All other graph patterns are defined recursively, using triple patterns, and operators AND, OPT, UNION, FILTER and SERVICE. We consider SERVICE patterns of the form \((P_1\ \texttt {SERVICE}\ a\ P_2)\), with \(a\in (\mathbf I \cup \mathbf{V})\) and \(P_1\), \(P_2\) graph patterns. If P is a graph pattern we denote the set of variables appearing in P by \(\text {var}(P)\). Finally, we define SPARQL queries as expressions of the form \(\texttt {SELECT}\ W\ \texttt {WHERE}\ \{\ P\ \}\), where P is a graph pattern, and W a set of variables.
We use the usual semantics of SPARQL, defined in terms of mappings [20, 28]; that is, partial functions from the set of variables \(\mathbf{V}\) to IRIs. The domain \(\mathsf {dom}(\mu )\) of a mapping \(\mu \) is the set of variables on which \(\mu \) is defined. Two mappings \(\mu _1\) and \(\mu _2\) are compatible (written as \(\mu _1 \sim \mu _2\)) if \(\mu _1(?x) = \mu _2(?x)\) for all variables ?x in \(\mathsf {dom}(\mu _1)\cap \mathsf {dom}(\mu _2)\). If \(\mu _1 \sim \mu _2\), then we write \(\mu _1 \cup \mu _2\) for the mapping obtained by extending \(\mu _1\) according to \(\mu _2\) on all the variables in \(\mathsf {dom}(\mu _2)\!{\setminus }\mathsf {dom}(\mu _1)\). Note that if two mappings \(\mu _1\) and \(\mu _2\) have no variables in common they are always compatible, and that the empty mapping \(\mu _{\emptyset }\) is compatible with any other mapping. For sets \(M_1\) and \(M_2\) of mappings we define their join as  . Given a graph G and a pattern P, we denote the evaluation of a graph pattern P over G as the set of mappings \(\llbracket P\rrbracket _{G}\). We refer to [20] for a full specification of the semantics.
. Given a graph G and a pattern P, we denote the evaluation of a graph pattern P over G as the set of mappings \(\llbracket P\rrbracket _{G}\). We refer to [20] for a full specification of the semantics.
3 Enabling SPARQL to Make JSON Calls
While theoretically one can use our ideas to connect SPARQL to any Web API, we concentrate on the so-called REST Web APIs, which communicate via HTTP requests, and we only consider requests of type GET. Of course, any implementation needs to take care of many other details when connecting to APIs (e.g. authentication). Our implementation takes this into consideration, but for space reasons here we just focus on the problem of evaluating these queries. An endpoint allowing the users to try the SERVICE-to-API functionality can be found at [2], and the source code of our implementation can be found at [3].
We assume that all API responses are JSON documents, and we use JSON navigation conditions to navigate and retrieve certain pieces of a JSON document, analogous to the way JSON documents are navigated in programming languages. For example, if we denote by J the JSON received in Example 1, we use \(J[\texttt {"temperature"}]\) to obtain the temperature and \(J[\texttt {"coord"}][\texttt {"lat"}]\) to obtain the latitude. We always assume that the general structure of the JSON response is known by users; this can be achieved, for example, by including the schema of the response in the documentation of the API (see e.g. [17, 29]). This is a common assumption when one works with Web APIs.
3.1 Syntax and Semantics of the Extended SERVICE Operator
A URI Template [21] is an URI in which the query part may contain substrings of the form \(\{?x\}\), for ?x in \(\mathbf{V}\). For example, the following is a URI template:

The elements inside brackets are replaced by concrete values in order to make a request. In what follows, we will refer to the variables in such substrings of a URI template \(U\) as the variables of \(U\), and denote them with \(\text {var}(U)\).
Here is how we propose to extend SERVICE to enable calls to APIs. Let \(P_1\) be a SPARQL pattern, \(U\) a URI template using only variables that appear in \(P_1\), \(?x_1,\ldots ,?x_m\) a sequence of pairwise distinct variables that do not appear in \(P_1\), and \(N_1,\ldots ,N_m\) a sequence of JSON navigation instructions. Then the following is a SPARQL pattern, that we call a SERVICE-to-API pattern:
The intuition behind the evaluation of this operator over a graph G is the following. For each mapping \(\mu \) in the evaluation \(\llbracket P_1\rrbracket _{G}\) we instantiate every variable ?y in the URI template \(U\) with the value \(\mu (?y)\), thus obtaining an IRI which is a valid API callFootnote 1. We call the API with this instantiated IRI, obtaining a JSON document, say J. We then apply the navigation instruction \(N_1\) to J and, assuming the instruction returns a basic JSON value, store this value into \(?x_1\). Similarly, the value of \(N_2\) applied to J is stored into \(?x_2\), and so on. The mapping \(\mu \) is then extended with the new variables \(?x_1,\ldots ,?x_m\), which have been assigned values according to J and \(N_i\). Notice that in (1) the pattern \(P_1\) can again be an overloaded SERVICE pattern connecting to another JSON API, thus allowing us to obtain results from one or more APIs inside a single query.
Semantics. The semantics of a SERVICE-to-API pattern is defined in terms of the instantiation of an URI template \(U\) with respect to a mapping \(\mu \) (denoted \(\mu (U)\)), which is simply the IRI that results by replacing each construct \(\{?x\}\) in \(U\) with \(\mu (?x)\). If there is some \(?x\in \text {var}(U)\) such that \(\mu (?x)\) is not defined, we define \(\mu (U)\) as an invalid IRI that will result in an error when invoked.
Thus, every mapping produces an IRI, which we then use to execute an HTTP request to the API in the body of the IRI. Formally, given an URI template \(U\) and a mapping \(\mu \), we denote by \(\text {call}(U,\mu )\) the result of the following process:
-
1.
Instantiate \(U\) with respect to \(\mu \), obtaining the IRI \(\mu (U)\).
-
2.
Produce a request to the API signed by \((\mu (U))\), obtaining either a JSON document (in case the call is successful) or an error.
Informally, we refer to this process as the call to \(U\) with respect to the mapping \(\mu \). We adopt the convention that HTTP requests that do not give back a JSON document result in an error, that is, \(\text {call}(U,\mu )= \texttt {error}\) whenever the request using U does not result in a valid JSON document.
For instance, if \(\mu \) is a mapping, such that \(\mu (?y)= \texttt {Ben\_Nevis}\), and \(U=\texttt {<http://weather.api/request?q=\{?y\}>}\) is a URI template, then \(\mu (U) = \texttt {<http://weather.api/request?q=Ben\_Nevis>}\). When this request is executed against the weather API in the IRI, the answer result is either a JSON document similar to the one from Example 1, or it is an error.
To define the evaluation we need some more notation. First, if ?x is a variable and \(t \in \mathbf{T}\), we use \(?x \mapsto t\) to denote the mapping that assigns t to ?x and does not assign values to any other variable. Next, given a JSON document J, a navigation expression N, and a variable ?x, we define the set \(M_{?x \mapsto J[N]}\) that contains the single mapping \(?x \mapsto J[N]\), when J[N] is a basic JSON value (integer, string, or boolean), and is equal to the empty set \(\emptyset \) otherwise. We also assume that \(M_{?x \mapsto J[N]} = \emptyset \) when J is not a valid JSON document, or \(J=\texttt {error}\).
The semantics of a SERVICE-to-API pattern P of the form (1) is then:

Therefore, a mapping in \(\llbracket P\rrbracket _G\) is obtained by extending a mapping \(\mu \in \llbracket P_1\rrbracket _G\) by binding each \(?x_i\) to \(\text {call}(U,\mu )[N_i]\). In the case that \(\text {call}(U,\mu )=\texttt {error}\) (e.g. when \(\mu (?x)\) is not defined for some \(?x\in \text {var}(U)\)), or that \(\text {call}(U,\mu )[N_i]\) is not a basic JSON value, the mapping \(\mu \) will not be extended to the variables \(?x_i\), and will not be part of \(\llbracket P\rrbracket _G\). This is consistent with the default behaviour of SPARQL SERVICE [30] which makes the entire query fail if the SERVICE call results in an error. In the case that we want to implement the SILENT option for SERVICE which makes the latter behave as an OPTIONAL (see [30]), we would need to change the \(\emptyset \) in the definition of \(M_{?x\mapsto J[N]}\) to the empty mapping \(\mu _\emptyset \), since this mapping can be joined with any other mapping.
For example, if \(P_1 = \texttt {\{?x wdt:P131 wd:Q22 . ?x rdfs:label ?y\}}\) is a pattern, and \(U=\texttt {<http://weather.api/request?q=\{?y\}>}\) a URI template. Let
be the pattern we are evaluating over some RDF graph G, and assume that \(\llbracket P_1\rrbracket _{G}\) contains the following mappings.

The evaluation of P over G is then obtained by extending mappings in \(\llbracket P_1\rrbracket _{G}\) using U. That is, we iterate over \(\mu \in \llbracket P_1\rrbracket _{G}\) one by one, execute the call \(\text {call}(U,\mu )\), and store the value \(\text {call}(U,\mu )[\texttt {"temperature"}]\) into the variable \(\texttt {?t}\), in case that the obtained JSON value is a string, a number, or a boolean value, and discard \(\mu \) otherwise. For example, if we assume that the calls are as follows,

then the evaluation \(\llbracket P\rrbracket _{G}\) will contain the following mapping

Since \(\text {call}(U,\mu _2)\) returns an error, the mapping \(\mu _2\) can not be extended, so it will not form a part of the output. In the case that the “SILENT semantic” is triggered, we would actually output \(\mu _2\) where ?t would not be bound.
3.2 A Basic Implementation
We propose a way to implement the overloaded SERVICE operation on top of any existing SPARQL engine without the need to modify its inner workings. To do so, we partition each query using this operator into smaller pieces, and evaluate these using the original engine whenever possible. More precisely, whenever we find a pattern of the form:
in our query, we process it over a local database G using the following algorithm:
-
1.
Compute \(\llbracket P_1\rrbracket _{G}\) (recursively if \(P_1\) contains a SERVICE-to-API pattern).
-
2.
Define \(M=\emptyset \).
-
3.
For each \(\mu \in \llbracket P_1\rrbracket _{G}\) do:
-
Execute \(\text {call}(U,\mu )\); if an error is returned, start step 3 with the next \(\mu \);
-
For \(1\le i \le m\), compute \(M_i = M_{?x_i\mapsto \text {call}(U,\mu )[N_i]}\); if there was an error, start step 3 with the next \(\mu \);
-
Let
 .
.
-
-
4.
Finally, to compute \(\llbracket P\rrbracket _{G}\), serialize the set of mappings M using the VALUES operator, as in [7], to allow it to be used by the next graph pattern inside the WHERE clause in which it appears.
 .
.Regarding the final step, the obtained mappings need to be serialized in case P is followed by another graph pattern \(P_2\). In particular, if we are processing a query of the form \(\texttt {SELECT * WHERE \{}P\ .\ P_2\texttt {\}}\), with P as above, then \(P_2\) needs to be able to access the values from the mappings matched to P.
With this implementation, the natural question is whether this basic implementation can be optimized. As we have mentioned, the bottleneck in our case is API calls, so if we want to evaluate queries as efficiently as possible we need to do the least amount of API calls as possible. There are a number of optimisations we can immediately implement in our basic implementation that will reduce the number of calls, and we try some of them in Sect. 5. However, next we consider a rather different question, for a broad subclass of patterns: Can we reformulate query plans to make sure we are making as few calls as possible?
4 A Worst-Case Optimal Algorithm
Our goal is to evaluate SERVICE-to-API queries as efficiently as possible, which implies minimising the number of API calls we issue when evaluating queries. This takes us to the following question: what is the minimal amount of API calls that need to be issued to answer a given query? Ideally, we would like to issue a number of calls that is linear in the size of the output of the query: for each tuple in the output we issue only those calls that are directly relevant for returning that particular tuple. But in general this is not possible. Consider the pattern
where \(U\) uses variables \(?x_1,\dots ,?x_m\). Then the number of calls we would need to issue could be of order \(|G|^m\) (e.g. when all triples in G are of the form (a, p, b)), but depending on the API data the output of this query may even be empty!
What we can do is aim to be optimal in the worst case, making sure that we do not make more calls than the number we would need in the worst case over all graphs and APIs of a given size. We can devise an algorithm that realises this bound if we focus on the smaller class of SPARQL queries made just from \(\mathbin {\mathsf {AND}}\), \(\mathbin {\mathsf {FILTER}}\) and SERVICE-to-API operators, which we denote as conjunctive patterns. This is the federated analogue of conjunctive queries, which amount to roughly two thirds of the queries issued on the most popular endpoints on the Web, according to [12].
As we shall see, bounding the number of API calls for this fragment is intimately related to bounding the number of tuples in the output of a relational query, a subject that has received considerable attention in the past few years in the database community (see e.g. [8, 18, 27]). To illustrate this, let P be a conjunctive SERVICE-to-API pattern of the form:
where each \(P_i\) is a SPARQL pattern (not using SERVICE) and each \(S_i\) is of the form \(\mathbin {\mathsf {SERVICE}}\ U\ \{(N_1, N_2,\ldots ,N_m)\ \mathop {\mathsf {AS}}\ (?x_1, ?x_2,\ldots ,?x_m)\}\), with U, m, and each of the \(N_j\)s and \(?x_j\)s possibly different for different \(S_i\).
We can now cast the problem of processing the query P over an RDF graph G as the problem of answering a join query over a relational database as follows. First, we simulate each SPARQL pattern \(P_i\) as a relation \(R_i\) with attributes corresponding to the variables of \(P_i\) (i.e. we project out the constants from each pattern in \(P_i\) since they do not contribute to an output). Second, we view an API U in each SERVICE call \(S_i\) described above as a relation \(T_i\) with access methods (see e.g. [10, 13]), that has output attributes \(?x_1,\dots ,?x_m\) and input attributes \(\text {var}(U)\). Intuitively, an access method prevents arbitrary access to a relation; the only way to retrieve the tuples of a relation T with input attributes \(A_1,\dots ,A_k\) is to provide appropriate values for \(A_1,\dots ,A_k\), after which we are given all the tuples in T that match these input values.
It is now easy to see that answering P over G is the same as answering the following relational queryFootnote 2:

over the relational instance that has the result of \(\llbracket P_i\rrbracket _G\) stored in \(R_i\), and the API data in \(T_i\), for \(i=1\ldots n\). Queries of the form (2) are known as join queries. Generally, join queries that do not use access methods are one of a few classes of queries for which we know tight bounds for the size of their outputs [8]. In what follows, we show that this bound can be extended even for queries that use access methods, such as (2), thus allowing us to solve the problem of evaluating SERVICE-to-API patterns.
We say that every action of matching values for the input attributes of one of the \(T_i\)’s is a call operation, and we are able to offer a tight bound on the number of calls needed to answer a join query with access method such as \(Q_P\). The main result we show in this section is the following. Take any feasibleFootnote 3 join query Q, and a database D. Denote by \(M_{Q,D}\) the maximum size of the projection of any relation appearing in Q over a single attribute in the database D. Furthermore, let \(2^{\rho ^*(Q,D)}\) be the AGM bound [8] of the query Q over D, i.e. the maximum size of the output of Q over any relational database having the same number of tuples in each relation as DFootnote 4. Then we can prove the following:
Theorem 1
Any feasible join query under access methods Q can be evaluated over any database instance D using a number of calls in
To show this proposition we provide an algorithm that, given a query \(Q_P\) obtained from a conjunctive SERVICE-to-API pattern as described above, constructs a query plan for \(Q_P\) that is guaranteed to make a number of calls satisfying the bound. We also show that this bound is tight: one can construct a family of patterns and instances of growing size where one actually needs that amount of API calls. We then show that the query plan for \(Q_P\) can be used to construct a query plan for P that is worst-case optimal.
4.1 API Calls as Relational Access Methods
Our shift into the relational setting is to facilitate the presentation when merging all the different data paradigms involved in the evaluation of SERVICE-to-API patterns. In the following we assume familiarity with relational databases and schemas, and relational algebra. For a quick reference see [4].
We denote access methods with the same symbol as relations, but making explicit which of the attributes are input attributes, and which are output attributes. For example, an access method for a relation R(A, B, C) with attributes A, B and C and where A and C are input attributes is denoted by \(R(A^i, B^o, C^i)\) (letter i is a shorthand for input and o for output).
Access methods impose a restriction on the way queries are to be evaluated, as there are queries that cannot be evaluated at all. To formalise the intuition that access methods impose a restriction on the way queries are to be evaluated, we say that a relation \(R_i\) in a join query  is covered if all of its input attributes appear as an output in any of the relations \(R_1,\dots ,R_{i-1}\). Then such a join query is said to be feasible when all its relations are covered. For example, consider a schema with relations \(R(A^i, B^o)\), \(S(A^o, B^o)\) and \(T(B^i, C^o)\). Then
is covered if all of its input attributes appear as an output in any of the relations \(R_1,\dots ,R_{i-1}\). Then such a join query is said to be feasible when all its relations are covered. For example, consider a schema with relations \(R(A^i, B^o)\), \(S(A^o, B^o)\) and \(T(B^i, C^o)\). Then  is feasible: the input for R is an output of S and likewise for T. But
is feasible: the input for R is an output of S and likewise for T. But  is not feasible, as we do not have a source for the input of R. Naturally, a join query can only be answered if it is equivalent to a feasible query, so without loss of generality we focus on feasible queries. This is also enough for our purposes, as all queries we produce out of conjunctive SERVICE-to-API patterns are feasible.
is not feasible, as we do not have a source for the input of R. Naturally, a join query can only be answered if it is equivalent to a feasible query, so without loss of generality we focus on feasible queries. This is also enough for our purposes, as all queries we produce out of conjunctive SERVICE-to-API patterns are feasible.
We adopt the convention that, for a relation T with input attributes \(A_1,\dots ,A_k\) and a set R of tuples having all attributes \(A_1,\dots ,A_k\), the number of calls required to answer  corresponds to the size of \(\pi _{A_1,\dots ,A_k} (R)\). Intuitively, this means that we answer
corresponds to the size of \(\pi _{A_1,\dots ,A_k} (R)\). Intuitively, this means that we answer  by selecting all different inputs coming from the tuples of R, and issue one call for each of these inputs.
by selecting all different inputs coming from the tuples of R, and issue one call for each of these inputs.
We can then analyse the number of calls for the naive left-deep join plan for  , which corresponds to setting \(\phi _1 = R_1\) and iteratively computing
, which corresponds to setting \(\phi _1 = R_1\) and iteratively computing  until we obtain \(\phi _n\), which corresponds to the answers of Q. How many calls do we issue? In the worst case where all except \(R_1\) are relations representing APIs, we would need to issue a number of calls corresponding to the sum of the tuples in \(R_1\),
until we obtain \(\phi _n\), which corresponds to the answers of Q. How many calls do we issue? In the worst case where all except \(R_1\) are relations representing APIs, we would need to issue a number of calls corresponding to the sum of the tuples in \(R_1\),  , and so on until
, and so on until  .
.
It turns out that we can provide a much better bound for the number of calls required, as well as an algorithm fulfilling this bound. In the following section we show an algorithm that produces a reformulation of Q whose left-deep plan issues a number of calls that agrees with the bound in Theorem 1. We also show that the algorithm is as good as it gets for arbitrary feasible join queries.
4.2 The Algorithm
Let  be a feasible join query under some access methods, and let \(A_1,\dots ,A_n\) be an enumeration of all attributes involved in Q, in order of their appearance. Without loss of generality, we assume that there is exactly one access method per relation in Q (if not one can construct two different relations, the worst case analysis does not change). We use \(\textit{Input}(R)\) to denote the set of all input attributes of the access method for R.
be a feasible join query under some access methods, and let \(A_1,\dots ,A_n\) be an enumeration of all attributes involved in Q, in order of their appearance. Without loss of generality, we assume that there is exactly one access method per relation in Q (if not one can construct two different relations, the worst case analysis does not change). We use \(\textit{Input}(R)\) to denote the set of all input attributes of the access method for R.
Our algorithm is inspired by the optimal plan exhibited in [8, 19] for conjunctive queries without access methods. Starting from Q, we construct a query \(Q^* =\varDelta _n\), where the sequence \(\varDelta _1,\ldots , \varDelta _n\) is defined as:
-
1.
For \(\varDelta _1\), let \(S^1_1,\dots ,S^1_{k_1}\) be all relations in \(\{R_1,\dots ,R_n\}\) whose set \(\textit{Input}(S^1_{\ell })\) of input attributes is contained in \(\{A_1\}\) (including relations with only output attributes). Then
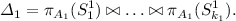
-
2.
For \(\varDelta _i\), let again \(S^i_1,\dots ,S^i_{k_i}\) be all relations such that \(\textit{Input}(S^i_{\ell })\) is contained in \(\{A_1,\dots ,A_i\}\). Then

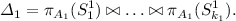

The feasibility of \(Q^*\) follows from the fact that Q is feasible, so every relation with inputs \(A_1,\dots ,A_i\) appears after all these attributes are outputs of previous relations, and we order attributes in the order of appearance. According to the construction above, we can write \(Q^*\) as a natural join  of expressions \(E_i\) which are join free. We then evaluate \(Q^*\) using a left-deep join plan: we start with the leftmost expression \(\phi _1 = E_1 = \pi _{A_1} (R)\) in \(Q^*\), where R is some relation, and then keep computing
of expressions \(E_i\) which are join free. We then evaluate \(Q^*\) using a left-deep join plan: we start with the leftmost expression \(\phi _1 = E_1 = \pi _{A_1} (R)\) in \(Q^*\), where R is some relation, and then keep computing  , for \(t = 2,\ldots ,r\). The relation \(\phi _r\) contains our output. Part of our plan involves caching the results of all relations R with \(\textit{Input}(R) \ne \emptyset \) the first time they are requested, and before we compute any projection over them. This only imposes a memory requirement that is at most as big as what we would need with the basic implementation.
, for \(t = 2,\ldots ,r\). The relation \(\phi _r\) contains our output. Part of our plan involves caching the results of all relations R with \(\textit{Input}(R) \ne \emptyset \) the first time they are requested, and before we compute any projection over them. This only imposes a memory requirement that is at most as big as what we would need with the basic implementation.
Analysis. Recall that for a query Q and instance D, \(M_{Q,D}\) is the maximum size of the projection of any relation in Q over a single attribute, and \(2^{\rho ^*(Q,D)}\) is the AGM bound of the query. Theorem 1 now follows from the following proposition.
Proposition 1
Let Q be a feasible join query over a schema with access methods and D a relational instance of this schema. Let \(Q^*\) be the query constructed from Q by the algorithm above. Then the number of calls required to evaluate \(Q^*\) over D using a left-deep plan is in
Let m be the number of relations in Q and n the total number of attributes. If we are considering combined complexity (i.e. Q is part of the input), the bound above raises to \(O(m\times M_{Q,D} \times 2^{\rho ^*(Q,D)})\) for the algorithm that does caching. Likewise, the number of calls is in \(O(n \times m\times M_{Q,D} \times 2^{\rho ^*(Q,D)})\) if we rule out the possibility of caching.
For the worst case optimality we show queries realising the upper bound.
Proposition 2
There is a schema \(\mathcal {S}\), a query Q and a family of instances \((D_n)_{n \ge 1}\) such that: (i) The maximum size of the projection of a relation in D over one attribute is n, (ii) The AGM bound is \(n^2\), and (iii) Any algorithm evaluating Q must make at least \(n^3\) calls to a relation with access methods.
SERVICE-to-API Patterns. To create optimal plans for SERVICE-to-API patterns, we need to show that (1) our translation from patterns to relational queries is sound and creates feasible queries, and (2) how to devise an optimal plan for the SERVICE pattern when given a plan for the relational query.
For (1), let P be a SERVICE-to-API pattern and \(Q_P\) the constructed join query, and consider an RDF graph G. Then the instance \(I_{P,G}\) in which \(Q_P\) should be evaluated is defined next, and the correctness lemma follows.
-
Each relation \(R_i\) in \(I_{P,G}\) with attributes \(?x_1,\dots ,?x_m\) contains the set of tuples \(\{(\mu (?x_1),\dots ,\mu (?x_n)) \mid \mu \in \llbracket P\rrbracket _{G}\}\).
-
Each relation \(T_i\) in \(I_{P,G}\) with input attributes \(?z_1,\dots ,?z_k\) and output attributes \(?y_1,\dots ,?y_p\) contains the set of tuples \(\{(\mu (?z_1),\dots ,\mu (?z_k),\mu (?y_1),\dots ,\mu (?y_p)) \mid \mu \in \llbracket P\rrbracket _{G}\}\).
Lemma 1
Let P be a conjunctive SERVICE-to-API pattern using variables \(\{?x_1,\dots ,?x_\ell \}\). A tuple \((a_1,\dots ,a_\ell )\) is in the evaluation of \(Q_P\) over \(I_{P,G}\) if and only if there is a mapping \(\mu \in \llbracket P\rrbracket _{G}\) such that \((a_1,\dots ,a_\ell ) = (\mu (?x_1),\dots ,\mu (?x_\ell ))\).
While not obvious, this lemma also shows that the query is feasible, as long as P is not trivially unanswerable (i.e., as long as there is a graph G for which \(\llbracket P\rrbracket _{G}\) is nonempty). Note that for finding the worst-case optimal plan for \(Q_P\) we do not need to construct the instance \(I_{P,G}\), as this would amount to pre-computing the answer \(\llbracket P\rrbracket _G\). Next, for (2): we show how the optimal plan for \(Q_P\) gives us an optimal plan for P:
Proposition 3
Let P be SERVICE-to-API pattern, G an RDF graph and \(Q_P\), \(I_{P,G}\) the corresponding relational query with access methods and instance as constructed above. Then any optimal query plan \(Q^*\) for \(Q_P\) over an instance \(I_{P,G}\) can be transformed (in polynomial time) into a query plan for P that evaluates P over G using the same amount of API calls as the evaluation of \(Q^*\).
Proof
The plan for P mimics step-by-step the plan for \(Q_P\). That is, assume that  is the reformulation of \(Q_P\) from Sect. 4.2. Starting with \(\phi _1 = E_1\), we iteratively compute the the set
is the reformulation of \(Q_P\) from Sect. 4.2. Starting with \(\phi _1 = E_1\), we iteratively compute the the set  of mappings for each \(i=2\cdots r\). This is done in the following way. Whenever \(E_i = \pi _{?x_1,\dots ,?x_p} R_i\), we evaluate the query \(\mathop {\mathsf {SELECT}}\ ?x_1,\dots ,?x_p\ \mathsf {WHERE}\ P_i\) over G. On the other hand, if \(E_i\) is a relation using \(T_j\) for the first time, we call the API (because \(Q_P\) is feasible we will have all the needed input parameters), cache all the API results and then only retrieve the attributes that are not projected out in \(E_i\). All subsequent appearances of \(T_j\) are evaluated directly on the cached JSON file. (If we are not using caching, then we need to call the API for each \(E_k\), where \(k>i\), that uses \(T_j\).) Since the query \(\phi _r\) is equivalent to \(Q^*\), it is also equivalent to \(Q_P\). Thus the output of this query plan correctly computes \(\llbracket P\rrbracket _G\) by Lemma 1. The number of calls is worst-case optimal by Propositions 1 and 2.
of mappings for each \(i=2\cdots r\). This is done in the following way. Whenever \(E_i = \pi _{?x_1,\dots ,?x_p} R_i\), we evaluate the query \(\mathop {\mathsf {SELECT}}\ ?x_1,\dots ,?x_p\ \mathsf {WHERE}\ P_i\) over G. On the other hand, if \(E_i\) is a relation using \(T_j\) for the first time, we call the API (because \(Q_P\) is feasible we will have all the needed input parameters), cache all the API results and then only retrieve the attributes that are not projected out in \(E_i\). All subsequent appearances of \(T_j\) are evaluated directly on the cached JSON file. (If we are not using caching, then we need to call the API for each \(E_k\), where \(k>i\), that uses \(T_j\).) Since the query \(\phi _r\) is equivalent to \(Q^*\), it is also equivalent to \(Q_P\). Thus the output of this query plan correctly computes \(\llbracket P\rrbracket _G\) by Lemma 1. The number of calls is worst-case optimal by Propositions 1 and 2.
5 Experiments
The goal of this section is to give empirical evidence that the worst-case optimal algorithm of Sect. 4 is indeed a superior evaluation strategy for executing queries that use API calls. We also constructed several real world use cases, for space reasons we defer them to the appendix [1] and the online demo [2].
Experimental Setup. To construct a benchmark for SERVICE-to-API patterns we reformulate the queries from the Berlin benchmark [11] by designating certain patterns in a query to act as an API call. We then run a battery of tests that simulate real-world APIs by sampling from the distributions of the response times presented in the introduction. The experiments where run on a 64-bit Windows 10 machine, with 8 GB of RAM, and Intel Core i5 7400 @ 3.0 GHz processor. Experiments were repeated five times, reporting the average value.
Adapting the Berlin Benchmark to Include API Calls. The Berlin benchmark dataset [11] is inspired by an e-commerce use case. It has products that are offered by vendors and are reviewed by users. Each one of those entities has properties related with them (such as labels, prices, etc.). The size of the dataset is specified by the user. To test our implementation we created a database of 5000 products consisting of 1959874 triples.
The benchmark itself is composed of 12 queries. Our adaptation consists of exposing the data of five recurrent patterns we find in the benchmark queries as APIs that return JSON documents. For instance, {?x bsbm:productPropertyNumericZ ?y} is one such pattern, where Z is a number between 1 and 5. This pattern is used to return the value of some numeric property of a product with the label ?x, so we created a (local) API route api/numeric-properties/{label}, that will give us all the values of numeric properties of an object. For instance, if a product with the IRI bsbm:Product1 has a label "Product 1", and its numerics properties are PropertyNumeric1 = 3, PropertyNumeric2 = 10, the request api/numeric-properties/Product_1 returns the JSON: "p1": 3, "p2": 10. The other API routes we implemented are similar (details can be found in [1]).
Next, we transform the original benchmark queries by replacing each pattern used when creating the APIs by a SERVICE call to the corresponding API. For instance, in the case of the “numeric properties API” described above, we replace each pattern of the form: {?product bsbm:productPropertyNumericX ?valueX}, by the following API call:

We did a similar transformation for each pattern including entities served by our APIs. We ran all the queries of the Berlin Benchmark except Q6, Q9, and Q11, because they were too short to include API calls in their patterns. Also, we change the OPTIONAL operator in each query by AND, because the two are the same in terms of worst case optimal analysis.
Implementation. Our implementation of SERVICE-to-API patterns is done on top of Jena TBD 3.4.0 using Java 8 update 144. We differentiate three evaluation algorithms for SERVICE-to-API patterns: (1) Vanilla, the base implementation described in Sect. 3; (2) Without duplicates, the base algorithm that uses caching to avoid doing the same API call more than once; and (3) WCO, the worst-case optimal algorithm of Sect. 4.
Results. The number of API calls done for each of the three versions of our algorithm are shown in Table 2. As we see, avoiding duplicate calls reduces the number of calls to some extent, but the best results are obtained when we use the worst-case optimal algorithm. We also measured the total time taken for the evaluation of these queries. Query times range from over 8000 s to just 0.7 s for the Vanilla version, and in average the use of WCO reduces by 40% the running times of the queries. Full details in [1].
6 Conclusion
In this paper we propose a way to allow SPARQL queries to connect to HTTP APIs returning JSON. We describe the syntax and the semantics of this extension, show how it can be implemented on top of existing SPARQL engines, provide a worst-case optimal algorithm for processing these queries, and demonstrate the usefulness of this algorithm both formally and in practice.
In future work, we plan to support formats other than JSON, and explore how to support it in public endpoints. It would be also interesting to test how issuing API calls in parallel affects the running times of different algorithms. Another line of work we plan to pursue is to support automatic entity resolution based on an API answer, thus allowing us to transform API information back into IRIs to be used again by SPARQL, instead of just literals.
Notes
- 1.
Note that replacing ?y in a URI template with \(\mu (?y)\) may result in a IRI, and not a URI, since some of the characters in \(\mu (?y)\) need not be ASCII. To stress this, we use the term IRI for any instantiation of the variables in a URI template.
- 2.
We abuse the notation and denote relational joins using the same symbol that we use for mappings; the two operators are always distinguished by the context.
- 3.
Some queries with access methods may not be answerable, e.g. a query with only input attributes. We call queries that can be answered feasible (see Subsect. 4.1).
- 4.
The bound is obtained by solving a specific linear program that depends on the query and the arity of the relations in D. We do not have space to formally state this result or this program, but refer to [19] for an excellent summary.
References
Online Appendix. http://dvrgoc.ing.puc.cl/APIs/SPARQLAPI.pdf
Online demo of SERVICE-to-API. http://67.205.159.121/query/#/
SERVICE-to-API implementation. http://67.205.159.121/query/code/
Abiteboul, S., Hull, R., Vianu, V.: Foundations of Databases. Addison-Wesley, Boston (1995)
Buil-Aranda, C., Arenas, M., Corcho, O.: Semantics and optimization of the SPARQL 1.1 federation extension. In: Antoniou, G., Grobelnik, M., Simperl, E., Parsia, B., Plexousakis, D., De Leenheer, P., Pan, J. (eds.) ESWC 2011. LNCS, vol. 6644, pp. 1–15. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-21064-8_1
Aranda, C.B., Arenas, M., Corcho, Ó., Polleres, A.: Federating queries in SPARQL 1.1: syntax, semantics and evaluation. J. Web Sem. 18(1), 1–17 (2013)
Buil-Aranda, C., Polleres, A., Umbrich, J.: Strategies for executing federated queries in SPARQL1.1. In: Mika, P., et al. (eds.) ISWC 2014. LNCS, vol. 8797, pp. 390–405. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-11915-1_25
Atserias, A., Grohe, M., Marx, D.: Size bounds and query plans for relational joins. SIAM J. Comput. 42(4), 1737–1767 (2013)
Battle, R., Benson, E.: Bridging the semantic web and web 2.0 with representational state transfer (REST). J. Web Sem. 6(1), 61–69 (2008)
Benedikt, M., Leblay, J., Tsamoura, E.: Querying with access patterns and integrity constraints. PVLDB 8(6), 690–701 (2015)
Bizer, C., Schultz, A.: The Berlin SPARQL benchmark. Int. J. Semant. Web Inf. Syst. 5(2), 1–24 (2009)
Bonifati, A., Martens, W., Timm, T.: An analytical study of large SPARQL query logs. CoRR, abs/1708.00363 (2017)
Calì, A., Martinenghi, D.: Querying data under access limitations. In: ICDE 2008, pp. 50–59 (2008)
Dimou, A., Sande, M.V., Colpaert, P., Verborgh, R., Mannens, E., de Walle, R.V.: RML: A generic language for integrated RDF mappings of heterogeneous data. In: LDOW (2014)
Fafalios, P., Tzitzikas, Y.: SPARQL-LD: a SPARQL extension for fetching and querying linked data. In: ISWC Demos (2015)
Fafalios, P., Yannakis, T., Tzitzikas, Y.: Querying the web of data with SPARQL-LD. In: Fuhr, N., Kovács, L., Risse, T., Nejdl, W. (eds.) TPDL 2016. LNCS, vol. 9819, pp. 175–187. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-43997-6_14
Galiegue, F., Zyp, K.: JSON schema: core definitions and terminology. Internet Eng. Task Force (IETF) (2013)
Gottlob, G., Lee, S.T., Valiant, G., Valiant, P.: Size and treewidth bounds for conjunctive queries. J. ACM 59(3), 16:1–16:35 (2012)
Grohe, M.: Bounds and algorithms for joins via fractional edge covers. In: Tannen, V., Wong, L., Libkin, L., Fan, W., Tan, W.-C., Fourman, M. (eds.) In Search of Elegance in the Theory and Practice of Computation. LNCS, vol. 8000, pp. 321–338. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-41660-6_17
Harris, S., Seaborne, A.: SPARQL 1.1 query language. W3C (2013)
IETF: URI Template (2012). https://tools.ietf.org/html/rfc6570
Junemann, M., Reutter, J.L., Soto, A., Vrgoč, D.: Incorporating API data into SPARQL query answers. In: ISWC 2016 Posters and Demos (2016)
Kobayashi, N., Ishii, M., Takahashi, S., Mochizuki, Y., Matsushima, A., Toyoda, T.: Semantic-JSON. Nucleic Acids Res. 39, 533–540 (2011)
Montoya, G., Vidal, M., Acosta, M.: A heuristic-based approach for planning federated SPARQL queries. In: COLD 2012 (2012)
Montoya, G., Vidal, M.-E., Corcho, O., Ruckhaus, E., Buil-Aranda, C.: Benchmarking federated SPARQL query engines: are existing testbeds enough? In: Cudré-Mauroux, P., et al. (eds.) ISWC 2012. LNCS, vol. 7650, pp. 313–324. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-35173-0_21
Müller, H., Cabral, L., Morshed, A., Shu, Y.: From restful to SPARQL: a case study on generating semantic sensor data. In: ISWC 2013, pp. 51–66 (2013)
Ngo, H.Q., Porat, E., Ré, C., Rudra, A.: Worst-case optimal join algorithms. In: PODS 2012, pp. 37–48 (2012)
Pérez, J., Arenas, M., Gutierrez, C.: nSPARQL: a navigational language for RDF. J. Web Sem. 8(4), 255–270 (2010)
Pezoa, F., Reutter, J.L., Suarez, F., Ugarte, M., Vrgoč, D.: Foundations of JSON Schema. In: WWW 2016, pp. 263–273 (2016)
Prud’hommeaux, E., Buil-Aranda, C.: SPARQL 1.1 Federated Query. W3C Recommendation, 21, 113 (2013)
Rietveld, L., Hoekstra, R.: YASGUI: not just another SPARQL client. In: Cimiano, P., Fernández, M., Lopez, V., Schlobach, S., Völker, J. (eds.) ESWC 2013. LNCS, vol. 7955, pp. 78–86. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-41242-4_7
Acknowledgements
Work funded by the Millennium Nucleus Center for Semantic Web Research under Grant NC120004.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Mosser, M., Pieressa, F., Reutter, J., Soto, A., Vrgoč, D. (2018). Querying APIs with SPARQL: Language and Worst-Case Optimal Algorithms. In: Gangemi, A., et al. The Semantic Web. ESWC 2018. Lecture Notes in Computer Science(), vol 10843. Springer, Cham. https://doi.org/10.1007/978-3-319-93417-4_41
Download citation
DOI: https://doi.org/10.1007/978-3-319-93417-4_41
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-93416-7
Online ISBN: 978-3-319-93417-4
eBook Packages: Computer ScienceComputer Science (R0)