
Abstract
Text data is one of the dominating data types in Big Data driven services and applications. The performance of text classification largely depends on the quality of feature extraction over the text corpus. For supervised learning over text documents, the TF-IDF (Term Frequency-Inverse Document Frequency) weighting factor is one of the most frequently used features in text classification. In this paper, we address two known limitations of TF-IDF based feature extraction method: First, the conventional TF-IDF weighting factor lacks of consideration about the synonymous relationship between feature terms. Second, for big corpus with large number of text documents and large number of feature terms, the computational complexity of text classification increases with the dimensionality of the feature space. We address these problems by introducing an optimization technique based on the Inter-Category Distributions (ICD) of terms and the Inter-Category Distributions of documents. We call this new weighting factor TF-IDF-ICD, namely TF-IDF with Inter-Category Distributions. To further enhance the effectiveness of our TF-IDF-ICD method, we describe a TF-IDF-ICD threshold based Dimensionality Reduction (DR) optimization. We test the text classifier with a corpus of 10, 000 articles. The evaluation results show that the proposed TF-IDF-ICD based text classification method outperforms the conventional TF-IDF based classification solution by \(7.84\%\) at only about \(43.19\%\) of the training time used by the conventional TF-IDF based text classification methods.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others
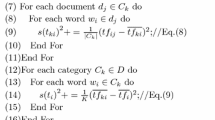


Keywords
- TF-IDF
- Feature extraction
- Text classification
- Inter-Category Distribution (ICD)
- Dimensionality reduction
1 Introduction
Text classification aims to categorize a document into one of the predefined class categories, denoted by \(\mathcal {Y}\), where a document is represented in the form of bag of words \(\mathcal {X}\), denoted as a feature vector \(x \in \mathbb {R}^{d \times 1}\) with d unique terms [1]. Text classification algorithms have been applied successfully in many big data driven text applications and services, such as spam filtering [2], tagging online news [3], social media analysis [4], bioscience [5] and chat bot [6]. Statistical learning based methods, such as Support Vector Machine (SVM) and its family of algorithms, are widely used for text classification [7,8,9].
The typical workflow of statistical learning based text classification system consists of four core components: text preprocessing, feature extraction, classifier training and classification [10]. Research [11] has shown that the sophistication of the feature selection process is critical to the effectiveness and efficiency of the text classifier.
Traditional text feature extraction methods use TF-IDF algorithm [12] to extract text features and transform the corpus of N text documents with a vocabulary of d terms into the d dimensional vector space of N TF-IDF feature vectors. By representing each text document as a feature vector in a high dimensional vector space, a statistical feature based classifier, such as SVM, can be used for text classification through supervised learning. Several known limitations exist for the TF-IDF based feature extraction method. For example, the conventional TF-IDF weighting factor pays no attention to synonyms and semantic relation between synonyms. Moreover, when dealing with large corpus with tens of thousands documents and terms, the feature vector space has very high dimensionality and is highly skewed and sparse. As a result, the computation complexity increases dramatically for large corpus.
To address these limitations, we propose an optimized feature extraction method for text classifications by defining a new weighting factor based on the Inter-Category Distribution of terms and documents, called TF-IDF-ICD. Based on this new weighting factor, we introduce a Dimensional Reduction (DR) technique based on TF-IDF-ICD weighting factor, which confines the dimensionality of the feature vector space by limiting the number of Feature Terms to only the most critical features, namely those term features with high TF-IDF-ICD values. Our TF-IDF-ICD optimized text classification system consists of three steps: (1) By combining with the text preprocessing, the synonym merging, and converging the statistic weight of synonym, the TF-IDF-ICD factors of all terms to every single document in the corpus are calculated and the result is represented as a team feature vector to represent the corresponding document. (2) By filtering out the low weight terms and selecting only those high weighted terms as the Feature Terms, we reduce the dimensions of the feature vector space for the given corpus. (3) After performing feature extraction in the first two steps, the resulting document feature vectors are fed into an SVM classifier to train the classifier. We evaluate the performance of the proposed optimization method for text classification using a well known corpus of 10, 000 text documents. The experimental results show that our approach outperforms the conventional TF-IDF solution by \(7.84\%\) at only about \(43.19\%\) of the original training time, demonstrating the effectiveness of the proposed method for achieving better trade-off between classification accuracy and computational complexity.
2 Related Work
Text data is one of the dominating data types in Big data driven applications and services. A wide variety of techniques have been designed and researched for text classification. Document representation and feature selection are two of the fundamental core tasks in text classification.
The TF-IDF based method is one of the most popular methods for document representation. Given a corpus of N documents with d terms as the vocabulary, we transform each document in the corpus into a d-dimensional feature vector x based on TF-IDF weighting factor. Many feature selection methods have been proposed and compared in [13]. An important function in feature selection is to reduce the dimensionality of the term feature space through feature transformation methods, which create a new and smaller set of features as a function of the original set of features. A typical example of such a feature transformation method is Latent Semantic Indexing (LSI), and its probabilistic variant PLSA [14]. Once the feature space is determined, the document vectors are fed into a chosen text classifier. As noted in [15], text data is ideally suited for SVM classification because of the sparse high-dimensional nature of text.
Most of the conventional TF-IDF based methods lack of consideration on semantic features, such as synonyms and their relations. Several independent research efforts have been engaged to involve semantic features. For example, Huang et al. [16] proposed an improved method based on the feature term vectors extracted from TF-IDF, and analyzed the semantic similarity of feature terms with external dictionaries. Zhu et al. [17] proposed a method using word2vec model to calculate the similarity between words and words, which solves the problem that low-frequency words with high class discrimination are ignored by statistical weights. Qu et al. [18] considered the relations between the feature and the class, showing the problem of the traditional TF-IDF algorithms that ignore the inter-category distribution of feature words.
Our approach is inspired by these existing efforts. Concretely, we propose three optimizations to enhance the efficiency of TF-IDF based feature extraction and text classification: (1) We propose to merge synonyms in text preprocessing step. (2) We propose to compute the inter-category distribution of terms and the inter-category distribution of documents and use the product of these two ICD vectors to define the TF-IDF-ICD weighting factor as an optimization for feature extraction. (3) We introduce a tunable threshold control knob to perform dimension reduction on the TF-IDF-ICD vector space. Our experiments show the effectiveness of our approach compared to the existing methods.
3 Feature Extraction Optimization
3.1 Text Preprocessing with Synonym Fusion
The text preprocessing is the first step. We remove the text format and symbols and perform word segmentation and semantic labeling of the text documents using the open source HanLP [19] tools. Less significant terms are then filtered out for simplicity and noise cancellation. In this work, adverbs, locative words, number words, and auxiliary words etc, are regarded as less significant terms. Even though some solutions [20] remove the name of persons, places and organizations during text preprocessing. We argue that the terms such as the name of person have strong reliance on categories, such as the relation between “Taylor Swift” and music category, between “Yao Ming” and the sports category. Thus, we keep such terms instead of removing them. Our experiments show that the classification accuracy is higher by retaining these special terms.
Synonyms may dilute the statistical feature of a document. We propose to combine synonyms as one term for feature calculation. Synonyms in the text documents are identified according to the dictionary, such as the “HIT-SCIR Synonym Dictionary (Extended Edition)” [21], which contains 77, 343 terms organized according to a five-level classification structure to form a tree structure, and each leaf node represents a group of terms. Three possible relationships are identified among these terms: “\(=\)” stands for synonym, “\(\#\)” stands for relevant terms and “@” stands for independent terms. We replace the terms marked with “\(=\)” with the first term of the group of terms and sum the term frequency so as to achieve the purpose of synonym fusion.
3.2 Text Feature Extraction with TF-IDF-ICD
In order to involve semantic features into the text classification, we advocate to use a new weighting factor, the TF-IDF with Inter-Category Distributions of both terms and documents, to replace the conventional TF-IDF.
Let \(\mathbb {D}=\{d_1, d_2, d_3,\cdots ,d_i,\cdots ,d_N\}\) be the corpus of N documents, where each document \(d_i\) belongs to a category \(C_j (j<m)\). m is the total number of categories. A document \(d_i=\{W_{i1}, W_{i2}, \cdots , W_{ik}\}\) has k terms, where \(W_{ik}\) is the k-th feature term of document \(d_i\). The TF-IDF-ICD weighting factor is calculated using Eq. 1.
where \(\alpha \) (\(\alpha \ge 0\)) is a weighting factor used to tune the weight ratio of the inter-category distributions to the inverse document frequency.
Let \(n_{d_i,W_{ik}}\) denote the raw count of term \(W_{ik}\) appearing in document \(d_i\) and \(D_{W_{ik}}\) denote the number of documents that contain term \(W_{ik}\) in the corpus. We define the term frequency adjusted by the document length and the inverse document frequency in Eqs. 2 and 3 respectively.
Before defining the extended weighting factor \(ICD(W_{ik})\), we first define two concepts: \(ICDT(W_{ik})\) and \(ICDD(W_{ik})\).
\(ICDT(W_{ik})\) describes the occurrence weight of term \(W_{ik}\). It represents the inter-category distribution for term \(W_{ik}\) and is defined in Eq. 4. A higher weight indicates that term \(W_{ik}\) has a higher category preference.
where \(n_{C_j,W_{ik}}\) is the raw count of term \(W_{ik}\) appearing in category \(C_j\) and \(n_{W_{ik}}\) is the raw count of term \(W_{ik}\) appearing in the corpus.
\(ICDD(W_{ik})\) describes the occurrence weight of documents in which the term \(W_{ik}\) appears. It is the inter-category distribution for a document and is defined in Eq. 5. Similarly, a higher weight indicates that term \(W_{ik}\) has a higher category preference.
where \(D_{C_j,W_{ik}}\) is the number of documents that contain term \(W_{ik}\) in category \(C_j\), and \(D_{W_{ik}}\) is the number of documents that contain term \(W_{ik}\) in the corpus.
The extended weighting factor \(ICD(W_{ik})\) is defined as a product of two inter-category distributions, the ICD for the term and the ICD for the document, in Eq. 6.
3.3 Dimensionality Reduction
After we transform all documents in the corpus into the feature vectors based on the new TF-IDF-ICD weighting factor, the next step is to perform the Dimensionality Reduction by limiting the number of Feature Terms to be used for text classification. Based on the TF-IDF-ICD value of every term in the text document and thus the corresponding feature vector, we only select the terms with the top \(\mu \%\) highest TF-IDF-ICD value as the critical Feature Terms. This operation reduces the dimensionality of the feature vectors of the document corpus. The union set of the selected Feature Terms from all the documents forms a feature vector space that represents the corpus. Consequently, the TF-IDF-ICD values of those critical Feature Terms of a document is used to represent the document. Our experiments show that adequate reduction of the number of Feature Terms has little effect on the accuracy of classification, while can significantly improve the time complexity of the text classification.
3.4 Text Classification with TF-IDF-ICD and DR Optimization
After the optimized feature extraction with TF-IDF-ICD and the ICD-based dimensionality reduction, we feed the optimized feature vector into the text classifier. We use the linear SVM algorithm to train the classifier, and use the K-fold cross validation to evaluate the classification performance.
4 Experimental Evaluation
The corpus used in this paper are labeled news reports. We collect 10000 articles from Sina News. The articles are labeled with 10 categories and 1000 news in each category. In the experiments, we uses 10-fold cross-validation to assess the classification results.
Recall Sect. 3.2 and Eq. 1, the parameter \(\alpha \) is used as the probability for contrasting ICD with TF-IDF. Another important parameter in our approach is the dimensionality reduction (DR) threshold parameter \(\mu \%\). Both \(\alpha \) and \(\mu \%\) are the tunable parameters in the experiments. To determine the best value of \(\alpha \), we fix \(\mu \%\) to \(20\%\) and vary \(\alpha \) from 0 to 4 by increasing 0.1 each time. The result is shown in Fig. 1. The overall trend of F-Measure increases as \(\alpha \) increases from 0 to 4. When \(\alpha \) increases to 1.4, F-Measure reaches the maximum value of 0.9490. As \(\alpha \) continues to increase from 1.5 to 4.0, F-Measure first experiences a slight decrease and then becomes relatively stable. In Sina News Corpus, when \(\alpha \) is 1.4, the F-measure accuracy is increased by 0.0237, compared to the conventional TD-IDF method without using ICD weighting factor (i.e., \(\alpha = 0\), F-Measure: 0.9253).
\(\mu \%\) represents the portion of Feature Terms. A higher \(\mu \%\) results in a larger dimension of feature space which results in higher computational complexity. We set the \(\alpha \) value by 1.4, which produces the best F-Measure as shown in the previous experiments, and report the F-measure results by varying \(\mu \%\) from \(5\%\) to \(100\%\) at \(5\%\) each time. Figure 2 shows the results.

F-Measure vs \(\alpha \) (\(\mu \%=20\%\)).

F-Measure vs \(\mu \%\) (\(\alpha =1.4\)).
We observe that the F-Measure increases very fast as \(\mu \%\) increases to \(20\%\). This is because the feature size increases exponentially with the growth of \(\mu \%\) and the increase ratio gets slower as \(\mu \%\) continues to increase. Hence, \(\mu \%\) is chosen to be \(20\%\) as a good trade-off setting between high accuracy and complexity.
We next compare the proposed TF-IDF-ICD method with and without DR (\(\alpha = 1.4\), \(\mu \% = 20\%\)) with the traditional TF-IDF based method. To be fair, we also use the Dimensionality Reduction (DR) based on TF-IDF (\(\mu \% = 20\%\)) when comparing with our approach with DR. Table 1 shows the experimental results.
As shown in the table, the proposed TF-IDF-ICD method has better accuracy performances than the traditional TF-IDF based method, no matter whether DR is used or not. Moreover, the accuracy performances of the proposed TF-IDF-ICD method is less affected by DR than the TF-IDF based method. In the case of using DR in both methods, the proposed method improves the F-Measure performance by \(7.84\%\) more than the TF-IDF based method does. The precision and recall performances are also improved by \(6.69\%\) and \(8.96\%\) respectively.
Using the dimension and training time of non-DR solution (i.e., \(\mu \%=100\%\)) as the baseline, we also investigate the relative dimension of the vector space and the relative training time of the classifier. Figure 3 shows that the relative dimension increases with \(\mu \) exponentially. When \(\mu \%=20\%\), the dimension is about \(\frac{1}{20}\) of the non-DR value. Figure 4 shows that the relative training time reduces significantly with a smaller \(\mu \). When \(\mu \%=20\%\), the text classification using TF-IDF-ICD with DR reduces the training time to \(43.19\%\) of the time in non-DR solution.

Relative dimension vs \(\mu \%\) (\(\alpha =1.4\), non-DR solution as baseline).

Relative training time vs \(\mu \%\) (\(\alpha =1.4\), non-DR solution as baseline).
It is worth noting that the ICD integration operation brings overhead of memory consumption and runtime increasing in document preprocessing. But based on our measurement in the experiment, the increased overhead is almost negligible compared to the original TF-IDF computation cost.
5 Conclusion
We have presented an efficient text classification scheme with three optimizations: (1) synonym fusion in the text preprocessing, (2) the enhanced feature extraction based on the Inter-Category Distributions (ICD) of both terms and documents, and (3) the dimensionality reduction based on the TF-IDF-ICD threshold based critical feature selection. We evaluate the performance of the proposed approach for text classification using a corpus of 10, 000 text documents. The experimental evaluation results (\(\alpha = 1.4\), \(\mu \% = 20\%\)) show that our method outperforms the conventional TF-IDF based solution by \(7.84\%\) and spends only about \(43.19\%\) of the training time required by the TF-IDF based method.
References
Joachims, T.: Learning to Classify Text Using Support Vector Machines: Methods, Theory and Algorithms, vol. 186. Kluwer Academic Publishers, Norwell (2002)
Almeida, T., Hidalgo, J.M.G., Silva, T.P.: Towards sms spam filtering: results under a new dataset. Int. J. Inf. Secur. Sci. 2(1), 1–18 (2013)
Liu, S., Huang, K., Chai, J.: Research of news tagging based on word frequency statistics and user information. In: 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), pp. 1–5. IEEE (2017)
Ali, K., Dong, H., Bouguettaya, A., Erradi, A., Hadjidj, R.: Sentiment analysis as a service: a social media based sentiment analysis framework. In: 2017 IEEE International Conference on Web Services (ICWS), pp. 660–667. IEEE (2017)
Ramani, R.G., Jacob, S.G.: Benchmarking classification models for cancer prediction from gene expression data: a novel approach and new findings. Stud. Inf. Control 22(2), 134–143 (2013)
Chu, Z., Gianvecchio, S., Wang, H., Jajodia, S.: Who is tweeting on Twitter: human, bot, or cyborg? In: Proceedings of the 26th Annual Computer Security Applications Conference, pp. 21–30. ACM (2010)
Yang, Y.: An evaluation of statistical approaches to text categorization. Inf. Retrieval 1(1), 69–90 (1999)
Sebastiani, F.: Machine learning in automated text categorization. ACM Comput. Surv. 34(1), 1–47 (2002)
Su, J.S., Bo-Feng, Z., Xin, X.: Advances in machine learning based text categorization. J. Softw. 7, 1848–1859 (2006)
Aggarwal, C.C., Zhai, C. (eds.): Mining Text Data, 1st edn. Springer, New York (2012). https://doi.org/10.1007/978-1-4614-3223-4
Mladenić, D., Brank, J., Grobelnik, M., Milic-Frayling, N.: Feature selection using linear classifier weights: interaction with classification models. In: Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2004, pp. 234–241. ACM, New York (2004)
Salton, G., Yu, C.T.: On the construction of effective vocabularies for information retrieval. SIGIR Forum 9(3), 48–60 (1973)
Yang, Y., Pedersen, J.O.: A comparative study on feature selection in text categorization. In: Proceedings of the Fourteenth International Conference on Machine Learning, ICML 1997, pp. 412–420. Morgan Kaufmann Publishers Inc., San Francisco (1997)
Hofmann, T.: Probabilistic latent semantic indexing. In: Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 1999, pp. 50–57. ACM, New York (1999)
Joachims, T.: A probabilistic analysis of the Rocchio algorithm with TFIDF for text categorization. In: Proceedings of the Fourteenth International Conference on Machine Learning, ICML 1997, pp. 143–151. Morgan Kaufmann Publishers Inc., San Francisco (1997)
Huang, C.H., Yin, J., Hou, F.: A text similarity measurement combining word semantic information with TF-IDF method. Chin. J. Comput. 34, 856–864 (2011)
Zhu, L., Wang, G., Zou, X.: Improved information gain feature selection method for Chinese text classification based on word embedding. In: Proceedings of the 6th International Conference on Software and Computer Applications, pp. 72–76. ACM (2017)
Qu, S., Wang, S., Zou, Y.: Improvement of text feature selection method based on TFIDF. In: International Seminar on Future Information Technology and Management Engineering, FITME 2008, pp. 79–81. IEEE (2008)
HanLP: Han Language Processing (2014). https://github.com/hankcs/HanLP
Hua, X.L., Zhu, Q.M., Li, P.F.: Chinese text similarity method research by combining semantic analysis with statistics. Jisuanji Yingyong Yanjiu 29(3), 833–836 (2012)
LTP-Cloud: Language Technology Platform Cloud (2017). https://www.ltp-cloud.com
Acknowledgement
The authors from Huazhong University of Science and Technology, Wuhan, China, are supported by the Chinese university Social sciences Data Center (CSDC) construction projects (2017–2018) from the Ministry of Education, China. The first author, Dr. Yuming Wang, is currently a visiting scholar at the School of Computer Science, Georgia Institute of Technology, funded by China Scholarship Council (CSC) for the visiting period of one year from December 2017 to December 2018. Prof. Ling Liu’s research is partially supported by the USA National Science Foundation CISE grant 1564097 and an IBM faculty award. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the funding agencies.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Wang, Y., Huang, J., Liu, Y., Tu, L., Liu, L. (2018). Inter-Category Distribution Enhanced Feature Extraction for Efficient Text Classification. In: Chin, F., Chen, C., Khan, L., Lee, K., Zhang, LJ. (eds) Big Data – BigData 2018. BIGDATA 2018. Lecture Notes in Computer Science(), vol 10968. Springer, Cham. https://doi.org/10.1007/978-3-319-94301-5_2
Download citation
DOI: https://doi.org/10.1007/978-3-319-94301-5_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-94300-8
Online ISBN: 978-3-319-94301-5
eBook Packages: Computer ScienceComputer Science (R0)