
Abstract
Modern compilers support OpenMP as a convenient way to introduce parallelism into sequential languages like C/C++ and Fortran, however, its use also introduces immediate drawbacks. In many implementations, due to early outlining and the indirection though the OpenMP runtime, the front-end creates optimization barriers that are impossible to overcome by standard middle-end compiler passes. As a consequence, the OpenMP-annotated program constructs prevent various classic compiler transformations like constant propagation and loop invariant code motion. In addition, analysis results, especially alias information, is severely degraded in the presence of OpenMP constructs which can severely hurt performance.
In this work we investigate to what degree OpenMP runtime aware compiler optimizations can mitigate these problems. We discuss several transformations that explicitly change the OpenMP enriched compiler intermediate representation. They act as stand-alone optimizations but also enable existing optimizations that were not applicable before. This is all done in the existing LLVM/Clang compiler toolchain without introducing a new parallel representation. Our optimizations do not only improve the execution time of OpenMP annotated programs but also help to determine the caveats for transformations on the current representation of OpenMP.
The U.S. government retains certain licensing rights. This is a U.S. government work and certain licensing rights apply
This is a preview of subscription content, log in via an institution.
Buying options
Tax calculation will be finalised at checkout
Purchases are for personal use only
Learn about institutional subscriptionsNotes
- 1.
A pointer is captured if a copy of it is made inside the callee that might outlive it.
- 2.
The kmpc OpenMP library used by LLVM/Clang communicates variables via variadic functions that require the arguments to be in integer registers. When a floating point variable is communicated by-value instead of by-reference we have to insert code that moves the value from a floating point register into an integer register prior to the runtime library call and back inside the parallel function.
- 3.
Communication through the runtime library involves multiple memory operations per variable and it is thereby easily more expensive than one addition for each thread.
- 4.
We need to ensure that
 is only executed under the condition
is only executed under the condition 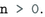
- 5.
The nodes for
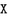 are omitted for space reasons. They would look similar to the ones for
are omitted for space reasons. They would look similar to the ones for  , though not only allow \(c_\omega \) flow to the sink but also into the incoming node of
, though not only allow \(c_\omega \) flow to the sink but also into the incoming node of  .
.
 is only executed under the condition
is only executed under the condition 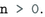
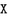 are omitted for space reasons. They would look similar to the ones for
are omitted for space reasons. They would look similar to the ones for  , though not only allow
, though not only allow  .
.References
Agarwal, S., Barik, R., Sarkar, V., Shyamasundar, R.K.: May-happen-in-parallel analysis of X10 programs. In: Proceedings of the 12th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, PPOPP 2007, San Jose, California, USA, 14–17 March 2007, pp. 183–193 (2007). https://doi.org/10.1145/1229428.1229471
Barik, R., Sarkar, V.: Interprocedural load elimination for dynamic optimization of parallel programs. In: Proceedings of the 18th International Conference on Parallel Architectures and Compilation Techniques, PACT 2009, 12–16 September 2009, Raleigh, North Carolina, USA, pp. 41–52 (2009). https://doi.org/10.1109/PACT.2009.32
Barik, R., Zhao, J., Sarkar, V.: Interprocedural strength reduction of critical sections in explicitly-parallel programs. In: Proceedings of the 22nd International Conference on Parallel Architectures and Compilation Techniques, Edinburgh, United Kingdom, 7–11 September 2013, pp. 29–40 (2013). https://doi.org/10.1109/PACT.2013.6618801
Che, S., et al.: Rodinia: a benchmark suite for heterogeneous computing. In: Proceedings of the 2009 IEEE International Symposium on Workload Characterization, IISWC 2009, 4–6 October 2009, Austin, TX, USA, pp. 44–54 (2009). https://doi.org/10.1109/IISWC.2009.5306797
Grunwald, D., Srinivasan, H.: Data flow equations for explicitly parallel programs. In: Proceedings of the Fourth ACM SIGPLAN Symposium on Principles & Practice of Parallel Programming (PPOPP), San Diego, California, USA, 19–22 May 1993, pp. 159–168 (1993). https://doi.org/10.1145/155332.155349
Jordan, H., Pellegrini, S., Thoman, P., Kofler, K., Fahringer, T.: INSPIRE: the insieme parallel intermediate representation. In: Proceedings of the 22nd International Conference on Parallel Architectures and Compilation Techniques, Edinburgh, United Kingdom, 7–11 September 2013, pp. 7–17 (2013). https://doi.org/10.1109/PACT.2013.6618799
Karlin, I., et al.: LULESH programming model and performance ports overview. Technical report LLNL-TR-608824, December 2012
Khaldi, D., Jouvelot, P., Irigoin, F., Ancourt, C., Chapman, B.M.: LLVM parallel intermediate representation: design and evaluation using OpenSHMEM communications. In: Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, LLVM 2015, Austin, Texas, USA, 15 November 2015, pp. 2:1–2:8 (2015). https://doi.org/10.1145/2833157.2833158
Lattner, C., Adve, V.S.: LLVM: a compilation framework for lifelong program analysis & transformation. In: 2nd IEEE/ACM International Symposium on Code Generation and Optimization (CGO 2004), 20–24 March 2004, San Jose, CA, USA, pp. 75–88 (2004). https://doi.org/10.1109/CGO.2004.1281665
Moll, S., Doerfert, J., Hack, S.: Input space splitting for OpenCL. In: Proceedings of the 25th International Conference on Compiler Construction, CC 2016, Barcelona, Spain, 12–18 March 2016, pp. 251–260 (2016). https://doi.org/10.1145/2892208.2892217
Schardl, T.B., Moses, W.S., Leiserson, C.E.: Tapir: embedding fork-join parallelism into LLVM’s intermediate representation. In: Proceedings of the 22nd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Austin, TX, USA, 4–8 February 2017, pp. 249–265 (2017). http://dl.acm.org/citation.cfm?id=3018758
Tian, X., Girkar, M., Bik, A.J.C., Saito, H.: Practical compiler techniques on efficient multithreaded code generation for OpenMP programs. Comput. J. 48(5), 588–601 (2005). https://doi.org/10.1093/comjnl/bxh109
Tian, X., Girkar, M., Shah, S., Armstrong, D., Su, E., Petersen, P.: Compiler and runtime support for running OpenMP programs on pentium-and itanium-architectures. In: Eighth International Workshop on High-Level Parallel Programming Models and Supportive Environments (HIPS 2003), 22 April 2003, Nice, France, pp. 47–55 (2003). https://doi.org/10.1109/HIPS.2003.1196494
Tian, X., et al.: LLVM framework and IR extensions for parallelization, SIMD vectorization and offloading. In: Third Workshop on the LLVM Compiler Infrastructure in HPC, LLVM-HPC@SC 2016, Salt Lake City, UT, USA, 14 November 2016, pp. 21–31 (2016). https://doi.org/10.1109/LLVM-HPC.2016.008
Zhao, J., Sarkar, V.: Intermediate language extensions for parallelism. In: Conference on Systems, Programming, and Applications: Software for Humanity, SPLASH 2011, Proceedings of the Compilation of the Co-located Workshops, DSM 2011, TMC 2011, AGERE! 2011, AOOPES 2011, NEAT 2011, and VMIL 2011, 22–27 October 2011, Portland, OR, USA, pp. 329–340 (2011). https://doi.org/10.1145/2095050.2095103
Acknowledgments
This research was supported by the Exascale Computing Project (17-SC-20-SC), a collaborative effort of two U.S. Department of Energy organizations (Office of Science and the National Nuclear Security Administration) responsible for the planning and preparation of a capable exascale ecosystem, including software, applications, hardware, advanced system engineering, and early testbed platforms, in support of the nation’s exascale computing imperative.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Doerfert, J., Finkel, H. (2018). Compiler Optimizations for OpenMP. In: de Supinski, B., Valero-Lara, P., Martorell, X., Mateo Bellido, S., Labarta, J. (eds) Evolving OpenMP for Evolving Architectures. IWOMP 2018. Lecture Notes in Computer Science(), vol 11128. Springer, Cham. https://doi.org/10.1007/978-3-319-98521-3_8
Download citation
DOI: https://doi.org/10.1007/978-3-319-98521-3_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-98520-6
Online ISBN: 978-3-319-98521-3
eBook Packages: Computer ScienceComputer Science (R0)