
Abstract
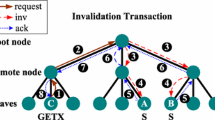
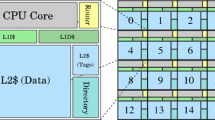
Increased device density and working set size are driving a rise in cache capacity, which comes at the cost of high access latency. Based on the characteristic of shared data, which is accessed frequently and consumes a little capacity, a novel two-level directory organization is proposed to minimize the cache access time in this paper. In this scheme, a small Fast Directory is used to offer fast hits for a great fraction of memory accesses. Detailed simulation results show that on a 16-core tiled chip multiprocessor, this approach reduces average access latency by 17.9% compared to the general cache organization, and improves the overall performance by 13.3% on average.
This work is supported by the Natural Science Foundation of China under Grant No. 60673145, No. 60773146 and No. 60833004.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

References
Briggs, F., et al.: Intel 870: A Building Block for Cost-Effective Scalable Servers. IEEE Micro., 36–47 (March-April 2002)
Chaiken, D., Fields, C., Kurihara, K., Agarwal, A.: Directory-based cache coherence in large-scale multiprocessors. IEEE Computer, 49–58 (June 1990)
Rusu, S., et al.: A Dual-Core Multi-Threaded Xeon Processor with 16MB L3 Cache. In: IEEE International Solid-State Circuits Conference Digest of Technical Papers (February 2006)
Wuu, J., Weiss, D., Morganti, C., Dreesen, M.: The Asynchronous 24MB On-Chip Level-3 Cache for a Dual-Core Itanium-Family Processor. In: IEEE International Solid-State Circuits Conference Digest of Technical Papers (February 2005)
Hardavellas, N., Pandis, I., Johnson, R., Mancheril, N., Ailamaki, A., Falsafi, B.: Database servers on chip multiprocessors: limitations and opportunities. In: CIDR (2007)
Zhang, M., Asanovic, K.: Victim Replication: Maximizing Capacity while Hiding Wire Delay in Tiled Chip Multiprocessors. In: Proc. of the 32nd International Symposium on Computer Architecture, June 2005, pp. 336–345 (2005)
Zhang, M., Asanovic, K.: Victim Migration: Dynamically Adapting between Private and Shared CMP Caches. MIT Technical Report MIT-CSAIL-TR-2005-064,MIT-LCS-TR-1006 (October 2005)
Beckmann, B.M., et al.: ASR: Adaptive Selective Replication for CMP Caches. In: Proc. of the 39th Annual IEEE/ACM International Symposium on Microarchitecture, December 2006, pp. 443–454 (2006)
Chang, J., et al.: Cooperative Caching for Chip Multiprocessors. In: Proc. of the 33rd Annual International Symposium on Computer Architecture, ISCA 2006, May 2006, pp. 264–276. IEEE, Los Alamitos (2006)
Eisley, N., Peh, L.-S., Shang, L.: Leveraging On-Chip Networks for Cache Migration in Chip Multiprocessors. In: Proceedings of 17th International Conference on Parallel Architectures and Compilation Techniques (PACT), Toronto, Canada (October 2008)
Michael, M.M., Nanda, A.K.: Design and Performance of Directory Caches for Scalable Shared Memory Multiprocessors. In: 5th Int’l. Symposium on High Performance Computer Architecture (January 1999)
Acacio, M.E., Gonzalez, J., Garcia, J.M., Duato, J.: A Two-Level Directory Architecture for Highly Scalable cc-NUMA Multiprocessors. IEEE Transactions on Parallel and Distributed Systems 16(1), 67–79 (2005)
Ros, A., Acacio, M.E., García, J.M.: A Novel Lightweight Directory Architecture for Scalable Shared-Memory Multiprocessors. In: Cunha, J.C., Medeiros, P.D. (eds.) Euro-Par 2005. LNCS, vol. 3648, pp. 582–591. Springer, Heidelberg (2005)
Acacio, M.E., Gonzalez, J., Garcia, J.M., Duato, J.: An Architecture for High-Performance Scalable Shared-Memory Multiprocessors Exploiting On-Chip Integration. IEEE Transactions on Parallel and Distributed Systems 15(8), 755–768 (2004)
Brown, J., Kumar, R., Tullsen, D.: Proximity-Aware Directory-based Coherence for Multi-core Processor Architectures. In: Proceedings of SPAA-19. ACM, New York (June 2007)
Lenoski, D., Laudon, J., Gharachorloo, K., Weber, W., Gupta, A., Henessy, J., Horowitz, M., Lam, M.: The stanford DASH multiprocessor. IEEE Computer (1992)
Virtutech AB. Simics Full System Simulator, http://www.simics.com/
Wisconsin Multifacet GEMS Simulator, http://www.cs.wisc.edu/gems/
Woo, S.C., Ohara, M., Torrie, E., Singh, J.P., Gupta, A.: The SPLASH-2 Programs: Characterization and Methodological Considerations. In: Proceedings of the 22nd Annual International Symposium on Computer Architecture, June 1995, pp. 24–37 (1995)
Wang, H., Wang, D., Li, P.: Exploit Temporal Locality of Shared Data in SRC enabled CMP. In: Li, K., Jesshope, C., Jin, H., Gaudiot, J.-L. (eds.) NPC 2007. LNCS, vol. 4672, pp. 384–393. Springer, Heidelberg (2007)
Beckmann, B.M., Wood, D.A.: Managing wire delay in large chip multiprocessor caches. Micro. 37 (December 2004)
Liu, C., Sivasubramaniam, A., Kandemir, M., Irwin, M.J.: Enhancing L2 organization for CMPs with a center cell. In: IPDPS 2006 (April 2006)
Guz, Z., Keidar, I., Kolodny, A., Weiser, U.C.: Utilizing shared data in chip multiprocessors with the Nahalal architecture. In: Proceedings of the 20th Annual ACM Symposium on Parallelism in Algorithms and Architectures (SPAA 2008), New York, NY, USA, pp. 1–10 (2008)
Azimi, M., Cherukuri, N., Jayasimha, D.N., Kumar, A., Kundu, P., Park, S., Schoinas, I., Vaidya, A.S.: Integration challenges and trade-offs for tera-scale architectures. Intel. Technology Journal (August 2007)
Haff, G.: Niagara2: More Heft in the Weft. Sun Analyst Research Reports (August 2007)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2009 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Zhang, X., Wang, D., Xue, Y., Wang, H., Wang, J. (2009). A Novel Cache Organization for Tiled Chip Multiprocessor. In: Dou, Y., Gruber, R., Joller, J.M. (eds) Advanced Parallel Processing Technologies. APPT 2009. Lecture Notes in Computer Science, vol 5737. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-03644-6_4
Download citation
DOI: https://doi.org/10.1007/978-3-642-03644-6_4
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-03643-9
Online ISBN: 978-3-642-03644-6
eBook Packages: Computer ScienceComputer Science (R0)