
Abstract
In this paper we have proposed human actions recognition methodology. The main novelty of this paper is application of neural network (NN) trained with the parallel stochastic gradient descent to perform classification task on multi-dimensional time-varying signal. The original motion-capture data consisted of 20 time-varying three-dimensional body joint coordinates acquired with Kinect controller is preprocessed to 9-dimensional angle-based time-varying features set. The data is resampled to the uniform length with cubic spline interpolation after which each action is represented by 60 samples and eventually 540 (60 × 9) variables are presented to input layer of NN. The dataset we used in our experiment consists of recordings for 14 participants that perform nine types of popular gym exercises (totally 770 actions samples). The averaged recognition rate in k-fold cross validation for different actions classes were between 95.6 % ± 9.5 % to even 100 %.
Similar content being viewed by others


Keywords
1 Introduction
Human actions recognition is among new and challenging tasks for pattern recognition. Due to the fact that in everyday life human behavior is observed by cameras connected to computer systems (for example public security monitoring or digital controllers of games consoles) there is a growing demand on reliable computer methods of human actions classification. In literature we can find many state-of-the-art methods that was applied to solve this task. Most of them uses well-established classifiers like neural networks (NN), support vector machines (SVM), random forests (RF), Hidden Markov Models (HMM) and others.
In [1] authors propose a heterogeneous multi-task learning framework for human pose estimation from monocular images using a deep convolutional neural network. Authors simultaneously learn a human pose regressor and sliding-window body-part and joint-point detectors in a deep network architecture. Paper [2] presents a novel approach for supervised codebook learning and optimization for bag-of words (BoW) models. In presented application, space-time interest points are calculated on each video, and discriminant and invariant features are calculated on a space-time cuboid around each interest point location. Initially, a video is therefore described as a collection of feature vectors. In traditional ways to translate this description into a BoW model, codebook creation and learning of the BoW models of the training set are treated as two different phases addressed with two different methods. Authors present a novel formulation as a single artificial NN. Study [3] proposes human action recognition method using regularized multi-task learning. First authors propose the part Bag-of-Words (PBoW) representation that completely represents the local visual characteristics of the human body structure. Each part can be viewed as a single task in a multi-task learning formulation. Further, they formulate the task of multi-view human action recognition as a learning problem penalized by a graph structure that is built according to the human body structure. Work [4] proposes the volume integral as a new descriptor for three-dimensional action recognition. The descriptor transforms the actor’s volumetric information into a two-dimensional representation by projecting the voxel data to a set of planes that maximize the discrimination of actions. Paper tests the volume integral using several Dimensionality Reduction techniques (namely PCA, 2D-PCA, LDA) and different Machine Learning approaches (namely Clustering, SVM and HMM) so as to determine the best combination of these for the action recognition task. In paper [5] authors propose a novel method for human action recognition based on boosted key-frame selection and correlated pyramidal motion feature representations. Instead of using an unsupervised method to detect interest points, a Pyramidal Motion Feature (PMF), which combines optical flow with a biologically inspired feature, is extracted from each frame of a video sequence. The AdaBoost learning algorithm is then applied to select the most discriminative frames from a large feature pool. In the classification phase, a SVM is adopted as the final classifier for human action recognition. Paper [6] addresses the multi-view action recognition problem with a local segment similarity voting scheme, upon which we build a novel multi-sensor fusion method. The random forests classifier is used to map the local segment features to their corresponding prediction histograms. In [7] BoW gives a first estimate of action classification from video sequences, by performing an image feature analysis. Those results are afterward passed to a common-sense reasoning system, which analyses, selects and corrects the initial estimation yielded by the machine learning algorithm. This second stage resorts to the knowledge implicit in the rationality that motivates human behavior. In paper [8] authors present feature descriptor for action recognition based on differences of skeleton joints, i.e., EigenJoints which combine action information including static posture, motion property, and overall dynamics. Accumulated Motion Energy (AME) is then proposed to perform informative frame selection, which is able to remove noisy frames and reduce computational cost. Authors employ non-parametric Naive-Bayes-Nearest-Neighbor (NBNN) to classify multiple actions. In work [9] authors propose an ensemble approach using a discriminative learning algorithm, where each base learner is a discriminative multi-kernel-learning classifier, trained to learn an optimal combination of joint-based features. In [10] authors propose a unsupervised learning method for automatic generation of knowledge base for syntactic Gesture Description Language (GDL) classifier [11] by analyzing unsegmented data recordings of gestures.
The up-to-date implementation of parallel stochastic gradient descent training method [12] allows to relatively quickly train NN that is dependent on hundreds of thousands synaptic weights. This enables faster development of action recognition methods that also requires less pre-processing of incoming signal taking nearly raw information that comes from motion capture hardware. The main novelty of this paper is application of NN trained with the parallel stochastic gradient descent to perform classification task on multi-dimensional time-varying signal. The original motion-capture data consisted of 20 time-varying three-dimensional body joint coordinates acquired with Kinect controller is preprocessed to 9-dimensional angle-based time-varying features set. The data is resampled to the uniform length with cubic spline interpolation after which each action is represented by 60 samples and eventually 540 (60 × 9) variables are presented to input layer of NN. The dataset we used in our experiment consists of recordings for 14 participants that perform nine types of popular gym exercises (totally 770 actions samples), the same large dataset as we used in [10]. In the following sections we will present the dataset we have used in our experiment, feature selection methodology and architecture of NN. We will also discuss the obtained results and present goals for future researches.
2 Material and Methods
In this section we will present the dataset we have used in our experiment, features selection procedure and architecture of NN we have used in our experiment.
2.1 Dataset and Features Selection
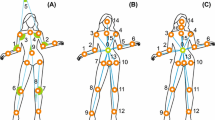
To gather the dataset for evaluation of proposed methodology we have utilized Microsoft Kinect. Despite the fact that Kinect was initially designed to be a game controller its potential as cheap general purpose depth camera was quickly noticed [13]. We have utilized Kinect SDK software library to segment and track 20 joints on human body with acquisition frequency of 30 Hz. The tracking was marker-less. Than we have changed original representation of motion capture data that is three-dimensional coordinates of 20 joints to angle-based representation. We did this because the original representation has two main drawbacks: it is dependent of relative position of user to camera leans and it is 60-dimensional (3 dimensions of Cartesian frame * 20 joints). The dependence from the camera position virtually prevents method from being usable in real-world scenario. In our angle-based representation (see Fig. 1 - left) the vertices of angles are positioned either in some important for movements analysis body joints (like elbows – angle 1 and 2, shoulders – angle 3 and 4, knees – angle 6 and 7) or angles measure position of limbs relatively to each other or relatively to torso. The second type of angles we utilized are angle defined between forearms (angle 5), angle between vector defined by joint between shoulders - joint between hips and thighs (angle 8 and 9). In the next step data is resampled to the uniform length with cubic spline interpolation after which each action is represented by 60 samples and eventually 540 (60 × 9) variables describe each action exemplar in our database. We have chosen 60-sample representation arbitrary.

In this figure on the left we present the positions of angles we used for angle-based representation of actions. In the right we present the schema of NN we used for classification task
We have used dataset that was previously used in our earlier work [10]. It consists of recordings for 14 participants, 4 women (W1-W4) and 10 men (M1-M10) – W means a woman, M – man, numbers defines id of a participant. The exercises that were performed were: body weight lunge left (bwll), body weight lunge right (bwlr), body weight squat (bws), dumbbell bicep curl (dbc), jumping jacks (jj), side lunges left (sll), side lunges right (slr), standing dumbbell upright row (sdur), tricep dumbbell kickback (tdk). In Table 1 we have presented quantities of gestures of a given type that was performed on a given SKL recording by each person. As can be seen not every person have performed each gesture, also the numbers of gestures are not equal. That is because that recordings were made in a certain period of time and not all users were asked to perform all gestures (for example in four recordings bws was skipped). Those lacks were then completed by recordings from other four persons in order to complete the dataset. Each person was asked to perform those exercises how many times he is capable to, but not more than 10 (in order not to get too tired for next exercises). There were some people who made those exercises more than 10 times (for example M1). For the other hand many participants, were getting tired more quickly and it was decided to reduce number of repetitions to 5 of each type. The participant M4 after performing slr was not capable to perform sll correctly.
In Fig. 2 we have presented visualization of 9-dimensional representation of exemplar body weight lunge left exercise before resampling.

This figure presents visualization of 9-dimensional representation of exemplar body weight lunge left exercise before resampling
2.2 Classification with NN
Multi-layer, feedforward neural networks consist of many layers of interconnected neuron units: beginning with an input layer to match the feature space followed by multiple layers of nonlinearity and terminating with a linear regression or classification layer to match the output space [14]. Each training example j the objective is to minimize a loss function \( L(W,B|j) \).
Here W is the collection \( \left\{ {w_{i} } \right\}_{1:N - 1} \), where W i denotes the weight matrix connecting layers i and i + 1 for a network of N layers; similarly B is the collection \( \left\{ b \right\}_{1:N - 1} \), where bi denotes the column vector of biases for layer i + 1. This basic framework of multi-layer neural networks can be used to accomplish deep learning tasks. Deep learning architectures are models of hierarchical feature extraction, typically involving multiple levels of nonlinearity. Such models are able to learn useful representations of raw data, and have exhibited high performance on complex data such as images, speech, and text [15]. The training of NN for classification task is based on minimization of cross-entropy loss function [14]:
Where \( o_{y}^{(j)} \) and \( t_{y}^{\left( j \right)} \) are the predicted (target) output and actual output, respectively, for training example j, and y denote the output units and O the output layer.
For minimization of (1) stochastic gradient descent (SGD) method can be used which is an iteration procedure for each training example i [16]:
Where \( w_{jk} \in W \) (weights), \( b_{jk} \in B \) (biases).
Lately the lock-free parallelization scheme for SGD called Hogwild has been published [12].
\( x_{i} \) and \( w_{i} \) denote the firing neuron’s input values and their weights, respectively; \( \alpha \) denotes the weighted combination.
The activation function in hidden layer might be a rectified linear function:
In our experiment we have utilized fully connected NN. Input layer had 540 neurons, hidden layer 50 neurons with rectified linear activation function (4) (number of neurons was arbitrary chosen) and output softmax layer with 9 neurons (the same as class number). The input data for network is standardize to \( N\left( {0,1} \right) \).
3 Results
We have implemented our approach in R language using “H2O” package [17] for neural network implementation and “signal” package for spline interpolation. Number of training epochs of NN was arbitrary set to 50. To validate our approach we used cross validation excluding actions of particular persons from training and making them target of NN prediction. The averaged values of recognition results of NN classifier from cross validation test plus/minus standard deviation are presented in Table 2.
In Fig. 3, we present visualization of results from Table 2.

This figure presents visualization of results from Table 2. Each bar represents averaged recognition rate of NN for single class. Black bars are plus/minus standard deviation
4 Discussion
As can be seen in Table 2 the initial experiment with NN that had most of parameters arbitrary fixed resulted in very good results. Most of the classes were 100 % correctly recognized. Two largest recognition errors were misclassification of sll as slr (2.0 ± 3.8 %) and slr as sll (3.0 ± 9.0 %). This situation happens because our representation of movements uses only information about values of angles between body joints without knowledge of movement direction. However the presence of error on such low level indicates that this is not very serious issue of our angle-based representation.
5 Conclusions
The representation of action to be recognized with angle-based features and resampling the multi-dimensional signal to the same length seems to be very promising approach for classification. Up-to-date implementation of state-of-the-art pattern recognition methods like H2O package for NN deals very well with large number of input features. There are however several open problems that have to be addressed in future research. The convenient method for selection of appropriate angles for features representation has to be established. Also the length of resampled data has to be related to characteristic of movement consisted in recording. We have also to evaluate our method on other actions datasets. What is more the evaluation should not be limited to proposed in this paper architecture of NN. The way to find optimal number of neurons and activation function would be valuable achievement. Also application of other classifiers like SVM and DF can result in even better classification results.
References
Li, S., Liu, Z.-Q., Chan, A.B.: Heterogeneous multi-task learning for human pose estimation with deep convolutional neural network. Int. J. Comput. Vis. 113, 19–36 (2015)
Jiu, M., Wolf, C., Garcia, C., Baskurt, A.: Supervised learning and codebook optimization for bag-of-words models. Cogn. Comput. 4, 409–419 (2012)
Guo, W., Chen, G.: Human action recognition via multi-task learning base on spatial–temporal feature. Inf. Sci. 320(1), 418–428 (2015)
Díaz-Más, L., Muñoz-Salinas, R., Madrid-Cuevas, F.J., Medina-Carnicer, R.: Three-dimensional action recognition using volume integrals. Pattern Anal. Appl. 15, 289–298 (2012)
Liu, L., Shao, L., Rockett, P.: Boosted key-frame selection and correlated pyramidal motion-feature representation for human action recognition. Pattern Recogn. 46, 1810–1818 (2013)
Zhu, F., Shao, L., Lin, M.: Multi-view action recognition using local similarity random forests and sensor fusion. Pattern Recogn. Lett. 34, 20–24 (2013)
del Rincón, J.M., Santofimia, M.J., Nebel, J.-C.: Common-sense reasoning for human action recognition. Pattern Recogn. Lett. 34, 1849–1860 (2013)
Yang, X., Tian, Y.: Effective 3D action recognition using EigenJoints. J. Vis. Commun. Image Represent. 25, 2–11 (2014)
Chen, G., Clarke, D., Giuliani, M., Gaschler, A., Knoll, A.: Combining unsupervised learning and discrimination for 3D action recognition. Sig. Process. 110, 67–81 (2015)
Hachaj, T., Ogiela, M.R.: Full body movements recognition – unsupervised learning approach with heuristic R-GDL method. Digit. Sig. Process. 46, 239–252 (2015)
Hachaj, T., Ogiela, M.R.: Rule-based approach to recognizing human body poses and gestures in real time. Multimedia Syst. 20, 81–99 (2014)
Recht, B., Re, C., Wright, S., Niu, F.: Hogwild: a lock-free approach to parallelizing stochastic gradient descent. In: Shawe-Taylor, J., Zemel, R.S., Bartlett, P., Pereira, F.C.N., Weinberger, K.Q. (eds.) Advances in Neural Information Processing Systems, vol. 24, pp. 693–701 (2011)
Hachaj, T., Ogiela, M.R., Koptyra, K.: Effectiveness comparison of Kinect and Kinect 2 for recognition of Oyama karate techniques. NBiS 2015 - The 18-th International Conference on Network-Based Information Systems (NBiS 2015), September 2–4, Taipei, Taiwan, pp. 332–337 (2015). doi:10.1109/NBiS.2015.51
Candel, A., Parmer, V.: Deep Learning with H2O, Published by H2O, (2015). http://leanpub.com/deeplearning. Accessed 8 August 2015
Bengio, Y.: Learning deep architectures for AI. Found. Trends® Mach. Learn. 2, 1–127 (2009). doi:10.1561/2200000006
LeCun, Y.A., Bottou, L., Orr, G.B., Müller, K.-R.: Efficient BackProp. In: Orr, G.B., Müller, K.-R. (eds.) NIPS-WS 1996. LNCS, vol. 1524, pp. 9–50. Springer, Heidelberg (1998)
Official website of H2O machine learning programming library. http://h2o.ai/. Accessed 8 August 2015
Acknowledgments
We kindly thank company NatuMed Sp. z o.o (Targowa 17a, 42-244 Wancerzow, Poland) for supplying us with SKL dataset that together with our own SKL recordings was used as training and validation dataset in this research.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer Science+Business Media Singapore
About this paper
Cite this paper
Hachaj, T., Ogiela, M.R. (2016). Application of Neural Network for Human Actions Recognition. In: Li, K., Li, J., Liu, Y., Castiglione, A. (eds) Computational Intelligence and Intelligent Systems. ISICA 2015. Communications in Computer and Information Science, vol 575. Springer, Singapore. https://doi.org/10.1007/978-981-10-0356-1_18
Download citation
DOI: https://doi.org/10.1007/978-981-10-0356-1_18
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-0355-4
Online ISBN: 978-981-10-0356-1
eBook Packages: Computer ScienceComputer Science (R0)