
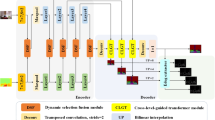
Abstract
The field of RGB-D semantic segmentation has attracted considerable interest in recent times. The challenge is to develop an effective method for combining RGB images, which capture colour variations, with depth images, which provide robust information about object geometry regardless of lighting conditions. Treating both image types equally through the same convolution operator fails to take into account their inherent differences. Thus, in this paper, we propose a novel approach that combines a geometry-aware convolution (GAConv) module and a multiscale fusion module (MFM) with the aim of enhancing the performance of RGB-D image segmentation. The GAConv module effectively captures fine-grained geometric details from depth images, while the MFM module enables efficient integration of multi-scale features, allowing the network to utilise both spatial and semantic information. Extensive experimentation was conducted on the NYUv2 and SUN RGB-D datasets, wherein our model demonstrated consistent superiority over existing state-of-the-art methods in terms of pixel accuracy and mean intersection over union (mIoU).







Similar content being viewed by others


Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.Availibility of Data and Materials
Data sharing not applicable.
Code Availability
Not applicable.
References
Sun Y, Zuo W, Yun P, Wang H, Liu M (2020) Fuseseg: Semantic segmentation of urban scenes based on rgb and thermal data fusion. IEEE Trans Automat Sci Eng 18(3):1000–1011
Sun Y, Liu M, Meng MQ-H (2019) Active perception for foreground segmentation: An rgb-d data-based background modeling method. IEEE Trans Automat Sci Eng 16(4):1596–1609
Zhao H, Shi J, Qi X, Wang X, Jia J (2017) Pyramid scene parsing network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 2881–2890
Badrinarayanan V, Kendall A, Cipolla R (2017) Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans Pattern Anal Mach Intell 39(12):2481–2495
Chen L-C, Papandreou G, Kokkinos I, Murphy K, Yuille AL (2014) Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv:1412.7062
Park S-J, Hong K-S, Lee S (2017) Rdfnet: Rgb-d multi-level residual feature fusion for indoor semantic segmentation. In: Proceedings of the IEEE International Conference on Computer Vision, pp 4980–4989
Giannone G, Chidlovskii B (2019) Learning common representation from rgb and depth images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp 0–0
Hu X, Yang K, Fei L, Wang K (2019) Acnet: Attention based network to exploit complementary features for rgbd semantic segmentation. In: 2019 IEEE International Conference on Image Processing (ICIP), pp 1440–1444 . IEEE
Bai L, Yang J, Tian C, Sun Y, Mao M, Xu Y, Xu W (2022) Dcanet: Differential convolution attention network for rgb-d semantic segmentation. arXiv:2210.06747
Yang J, Bai L, Sun Y, Tian C, Mao M, Wang G (2023) Pixel difference convolutional network for rgb-d semantic segmentation. IEEE Trans Circ Syst Video Technol, 1–1
Cao J, Leng H, Lischinski D, Cohen-Or D, Tu C, Li Y (2021) Shapeconv: Shape-aware convolutional layer for indoor rgb-d semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp 7088–7097
Zhang J, Liu H, Yang K, Hu X, Liu R, Stiefelhagen R (2022) Cmx: Cross-modal fusion for rgb-x semantic segmentation with transformers. arXiv:2203.04838
Silberman N, Hoiem D, Kohli P, Fergus R (2012) Indoor segmentation and support inference from rgbd images. In: Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7-13 October, 2012, Proceedings, Part V 12, pp 746–760 . Springer
Wang W, Neumann U (2018) Depth-aware cnn for rgb-d segmentation. In: Proceedings of the European Conference on Computer Vision (ECCV), pp 135–150
Chen X, Lin K-Y, Qian C, Zeng G, Li H (2020) 3d sketch-aware semantic scene completion via semi-supervised structure prior. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 4193–4202
Wang J, Wang Z, Tao D, See S, Wang G (2016) Learning common and specific features for rgb-d semantic segmentation with deconvolutional networks. In: Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11-14 October, 2016, Proceedings, Part V 14, pp 664–679. Springer
Schwarz M, Milan A, Periyasamy AS, Behnke S (2018) Rgb-d object detection and semantic segmentation for autonomous manipulation in clutter. The Int J Robot Res 37(4–5):437–451
Chen L-Z, Lin Z, Wang Z, Yang Y-L, Cheng M-M (2021) Spatial information guided convolution for real-time rgbd semantic segmentation. IEEE Trans Image Process 30:2313–2324
Lu Y, Yu H, Ni W, Song L (2023) 3d real-time human reconstruction with a single rgbd camera. Appl Intell 53(8):8735–8745
Yu L, Tian L, Du Q, Bhutto JA (2023) Multi-stream adaptive 3d attention graph convolution network for skeleton-based action recognition. Appl Intell 53(12):14838–14854
Chen S, Xu K, Zhu B, Jiang X, Sun T (2023) Deformable graph convolutional transformer for skeleton-based action recognition. Appl Intell 53(12):15390–15406
Gao T, Wei W, Cai Z, Fan Z, Xie SQ, Wang X, Yu Q (2022) Ci-net: A joint depth estimation and semantic segmentation network using contextual information. Appl Intell 52(15):18167–18186
Long J, Shelhamer E, Darrell T (2015) Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 3431–3440
Xie E, Wang W, Yu Z, Anandkumar A, Alvarez JM, Luo P (2021) Segformer: Simple and efficient design for semantic segmentation with transformers. Adv Neural Inf Process Syst 34:12077–12090
Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, Lin S, Guo B (2021) Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp 10012–10022
Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, Bernstein M, et al. (2015) Imagenet large scale visual recognition challenge. Int J Comput Vis 115:211–252
Gupta S, Girshick R, Arbeláez P, Malik J (2014) Learning rich features from rgb-d images for object detection and segmentation. In: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6-12 September, 2014, Proceedings, Part VII 13, pp 345–360. Springer
Li Z, Gan Y, Liang X, Yu Y, Cheng H, Lin L (2016) Lstm-cf: Unifying context modeling and fusion with lstms for rgb-d scene labeling. In: Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11-14 October, 2016, Proceedings, Part II 14, pp 541–557 . Springer
Cheng Y, Cai R, Li Z, Zhao X, Huang K (2017) Locality-sensitive deconvolution networks with gated fusion for rgb-d indoor semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 3029–3037
Liu S, Huang D, et al. (2018) Receptive field block net for accurate and fast object detection. In: Proceedings of the European Conference on Computer Vision (ECCV), pp 385–400
Lin T-Y, Dollár P, Girshick R, He K, Hariharan B, Belongie S (2017) Feature pyramid networks for object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 2117–2125
He K, Zhang X, Ren S, Sun J (2015) Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans Pattern Anal Mach Intell 37(9):1904–1916
Chen L-C, Zhu Y, Papandreou G, Schroff F, Adam H (2018) Encoder-decoder with atrous separable convolution for semantic image segmentation. In: Proceedings of the European Conference on Computer Vision (ECCV), pp 801–818
Chen L-C, Papandreou G, Kokkinos I, Murphy K, Yuille AL (2017) Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans Pattern Anal Mach Intell 40(4):834–848
Kingma DP, Ba J (2014) Adam: A method for stochastic optimization. arXiv:1412.6980
Song S, Lichtenberg SP, Xiao J (2015) Sun rgb-d: A rgb-d scene understanding benchmark suite. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 567–576
Zhang G, Xue J-H, Xie P, Yang S, Wang G (2021) Non-local aggregation for rgb-d semantic segmentation. IEEE Signal Process Lett 28:658–662
Ye H, Xu D (2022) Inverted pyramid multi-task transformer for dense scene understanding. In: European Conference on Computer Vision, pp 514–530 . Springer
Girdhar R, Singh M, Ravi N, Maaten L, Joulin A, Misra I (2022) Omnivore: A single model for many visual modalities. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 16102–16112
Pang Y, Zhao X, Zhang L, Lu H (2023) Comptr: Towards diverse bi-source dense prediction tasks via a simple yet general complementary transformer. arXiv:2307.12349
Xing Y, Wang J, Zeng G (2020) Malleable 2.5 d convolution: Learning receptive fields along the depth-axis for rgb-d scene parsing. In: European Conference on Computer Vision, pp 555–571 . Springer
Chen X, Lin K-Y, Wang J, Wu W, Qian C, Li H, Zeng G (2020) Bi-directional cross-modality feature propagation with separation-and-aggregation gate for rgb-d semantic segmentation. In: European Conference on Computer Vision, pp 561–577 . Springer
Borse S, Wang Y, Zhang Y, Porikli F (2021) Inverseform: A loss function for structured boundary-aware segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 5901–5911
Qi X, Liao R, Jia J, Fidler S, Urtasun R (2017) 3d graph neural networks for rgbd semantic segmentation. In: Proceedings of the IEEE International Conference on Computer Vision, pp 5199–5208
Lin D, Chen G, Cohen-Or D, Heng P-A, Huang H (2017) Cascaded feature network for semantic segmentation of rgb-d images. In: Proceedings of the IEEE International Conference on Computer Vision, pp 1311–1319
Seichter D, Köhler M, Lewandowski B, Wengefeld T, Gross H-M (2021) Efficient rgb-d semantic segmentation for indoor scene analysis. In: 2021 IEEE International Conference on Robotics and Automation (ICRA), pp 13525–13531 . IEEE
Zhou W, Yang E, Lei J, Wan J, Yu L (2022) Pgdenet: Progressive guided fusion and depth enhancement network for rgb-d indoor scene parsing. IEEE Trans Multimed, 1–1
Author information
Authors and Affiliations
Contributions
All authors contributed to the conception, design, and data analysis of this study. Author 1 contributed to the acquisition and interpretation of method and drafted the manuscript. Author 2 contributed to the design of the network, performed experimental analysis, and revised the manuscript. Author 3 contributed to the data collection, interpretation, and provided critical feedback on the manuscript. Author 4 contributed to the study design, data analysis, and revised the manuscript. Author 5 contributed to the interpretation of data and provided revisions to the manuscript. All authors approved the final version of the manuscript and agreed to be accountable for all aspects of the work, ensuring that any questions related to the accuracy or integrity of the study are appropriately addressed and resolved.
Corresponding author
Ethics declarations
Conflicts of Interest
The authors have no competing interests to declare that are relevant to the content of this article.
Ethics Approval
Not applicable.
Consent to Participate
Not applicable.
Consent for Publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Tian, C., Xu, W., Bai, L. et al. GANet: geometry-aware network for RGB-D semantic segmentation. Appl Intell 55, 454 (2025). https://doi.org/10.1007/s10489-025-06337-0
Accepted:
Published:
DOI: https://doi.org/10.1007/s10489-025-06337-0