
Abstract
Visual perception is a transformative technology that can recognize patterns from environments through visual inputs. Automatic surveillance of human activities has gained significant importance in both public and private spaces. It is often difficult to understand the complex dynamics of events in real-time scenarios due to camera movements, cluttered backgrounds, and occlusion. Existing anomaly detection systems are not efficient because of high intra-class variations and inter-class similarities existing among activities. Hence, there is a demand to explore different kinds of information extracted from surveillance videos to improve overall performance. This can be achieved by learning features from multiple forms (views) of the given raw input data. We propose two novel methods based on the multi-view representation learning framework. The first approach is a hybrid multi-view representation learning that combines deep features extracted from 3D spatiotemporal autoencoder (3D-STAE) and robust handcrafted features based on spatiotemporal autocorrelation of gradients. The second approach is a deep multi-view representation learning that combines deep features extracted from two-stream STAEs to detect anomalies. Results on three standard benchmark datasets, namely Avenue, Live Videos, and BEHAVE, show that the proposed multi-view representations modeled with one-class SVM perform significantly better than most of the recent state-of-the-art methods.
Similar content being viewed by others

1 Introduction
Visual perception helps in understanding patterns from environments through visual inputs. Video information processing is an essential step toward building applications for tasks such as video annotations [9, 20], facial expression recognition [35], and visual surveillance [2]. In recent times, automated video surveillance has gained significant interest in the field of computer vision [34, 42]. Extensive research in automated surveillance can drastically reduce the laborious responsibilities of manual supervision and thereby decrease the response time.
One such crucial task in video surveillance is detecting anomalous events [53]. The events which deviate from normal contextual behavior can be termed as anomalous events. Detecting such events can be challenging due to the presence of ambiguity in the formulation of anomalies, their unpredictable nature, high intra-class similarity, and inter-class variations leading to poor discrimination among normal and abnormal activities. The ambiguity in the formulation of anomaly is because of its dependence on the type of environment. To exemplify, running is considered a normal activity in a sports environment, whereas it will be considered as an abnormal event in an airport. Such context-based formulation intensifies the challenging nature of the task. Another kind of challenge is the external occlusion by mobile objects in crowded scenes and also internal occlusion by background objects. Variation in illumination, changes in viewpoint, and camera motions can induce unwanted effects, which makes it further challenging to capture patterns in videos.
In the case of real-time analysis of events, there is an imbalance in the type of available data, i.e., normal data are abundantly available when compared to abnormal data. Due to this imbalance, it is challenging to model anomalous behavior, and therefore learning the abnormal patterns completely is tedious. This problem can be handled using unsupervised learning methods, wherein abnormal events are treated as outliers that deviate significantly from normal events. Even after recognizing the presence of abnormal events in a video stream, the key factor is detecting and localizing these events, which contributes to an added complexity. The extraction of robust and discriminative features is of utmost importance to address these challenges in automated surveillance. These features can be obtained either by conventional handcrafted methods or deep learning techniques or both.
Ghrab et al. [14] used trajectory-based feature descriptors and performed hierarchical clustering to remove noise from the training data. The trajectory features of the test data were compared with the obtained cluster in order to classify them. Kaltsa et al. [19] extracted spatiotemporal cubes and obtained a merged feature vector comprising of histograms of oriented gradients (HOG) for the spatial information and histogram of oriented swarm acceleration (HOSA) to capture temporal dynamics. Unlike the above-mentioned handcrafted methods which extract only abstract details, deep networks can be used for the extraction of data-driven high-level descriptors. In Fang et al. [12], a combination of multi-scale histogram optical flow (MHOF) and saliency information (SI) was obtained for each frame and fed into a deep PCANet to extract high-level descriptors for the purpose of classification. In a work done by Hu et al. [17], a deep incremental slow feature analysis (D-IncSFA) was used as a pipeline network to extract features and detect anomalies.
The performance of anomaly detection approaches highly depends on the representations formed out of the raw input videos. Handcrafted or deep feature extraction techniques work reasonably well for this task. But most of these methods lack in its ability to capture the discriminative spatiotemporal patterns that exist in unconstrained real-time scenarios. Therefore, features obtained from different forms (views) of raw input video data can be used to form a composite representation where each input modality will complement each other. Multi-view representation learning [28, 52] is emerging to be an efficient approach for forming generalized representation obtained from different views of input. In this work, features from different views are extracted through a hybrid representation learning technique and also through two-stream deep feature extraction techniques. One-class SVM (OC-SVM) is used to discriminate between normal and abnormal events. The proposed approaches exploit the complementary information existing in multiple views to represent data comprehensively. Our contributions in this paper include:
-
A hybrid multi-view representation learning framework that combines STACOG (spatiotemporal autocorrelation of gradients)-based handcrafted features and deep features extracted from 3D-STAE (spatiotemporal autoencoder) with raw video segments as input.
-
A deep multi-view representation learning framework that combines deep features extracted from two-stream 3D-STAE with raw video segments and motion maps from raw video segments as two inputs separately.
2 Related Work
Due to the contextually varying characteristic of abnormal events, most of the approaches deal with anomaly by considering them as outliers by modeling the normality that persists in the training data. Zhang et al. [50] modeled normal activities using a locality sensitive hashing Function (LSH) to filter abnormal activities. Smeureanu et al. [38] used a simple but elegant method by feeding pre-trained CNN features into an OCSVM for modeling the normal behavior.
A two-stage algorithm based on K-means clustering and one-class SVM [18] was proposed to eliminate outliers by clustering the spatiotemporal cubes of normal activities. A generative model that captures temporal patterns was built using a fully connected autoencoder [16], which learns from local spatiotemporal features. Liu et al. [29] used a generative U-Net and an optical flow-net to predict the consecutive frame and thereby determine the anomaly by comparing it with the original frame. Luo et al. [32] used a temporal sparse coding (TSC) method when integrated with a stacked RNN leads in finding optimal parameters for anomaly detection.
Ravanbakhsh et al. [36] reconstructed appearance and motion representation using generative adversarial nets to localize the abnormal events in a video. Stacked denoising autoencoders were used by Xu et al. [47] to capture appearance and motion features and used a double fusion strategy for abnormal event detection. Sun et al. [41] introduced an online growing neural gas (GNG), which can update its learning parameters for each input training video. The behavioral pattern of the video which deviates from the model is flagged as anomalous. Similar to this, Dutta et al. [11] used an online unsupervised learning method by making use of an incremental coding length (ICL) which measures the entropy of the features by considering its frequency and its strength.
Sultani et al. [40] used multiple instance learning (MIL) on features learned from a 3D convolutional neural network over video segments from their own dataset. Kumaran et al. [24] proposed an anomaly detection method using a hybrid CNN and variational autoencoder (VAE) architecture. The idea proposed in Chu et al. [7] has used a deep three-dimensional convolutional network (C3D) to extract features. This unsupervised feature learning is guided by the sparse coding results of the handcrafted features extracted from the video clips. Discriminating anomalous events largely depends on the temporal ordering of its video structure. Del Giorno et al. [8] break this dependency by computing spatiotemporal descriptors, which are shuffled among several classifiers. The scores of these classifiers are aggregated to determine the anomaly score.
The localization of anomalies can be achieved by dividing the features into two sets: global and local. Li et al. [27] determined global anomaly by calculating the kinetic energy and its derivatives. The local anomaly was detected based on appearance, location, and velocity features. Another method that detects local and global anomalies simultaneously by Gaussian process regression is proposed in Cheng et al. [6]. This approach models a hierarchical feature representation of interaction templates. Recently, long short-term memory (LSTM) is used for addressing various tasks in the domains of speech recognition, natural language processing, and action recognition. The LSTM was introduced to overcome the vanishing gradient problem, a crucial issue faced all over the deep learning researcher’s community in the past. Sudhakaran and Lanz [39] used the convolutional long short-term memory, a variant of LSTM for aggregating frame-level features from a video to detect violent activities.
Tudor Ionescu et al. [44] proposed a framework that uses a binary classifier that is trained iteratively to differentiate between two continuous video segments and remove the most discriminative features. A real-time end-to-end trainable two-stream network [1] was proposed for action detection. In this approach, optical flow is computed using flownet, which is fed as input to the motion stream. Early fusion is applied by concatenating the activations from both streams, and the whole network is trained end to end.
A fast anomaly detection method was proposed by Sabokrou et al. [37], where a 3D autoencoder is used for identification of regions of interest in the form of cubic patches which are then evaluated using a deep 3D CNN. These two networks are divided into multiple cascaded classifiers to differentiate simple and complex patches. Gong et al. [15] introduced a memory-augmented autoencoder which updates memory elements representing the normal characteristics of the input data. The intuition behind this method is based on the fact that the model can sometimes learn to be more generalized and hence reconstruct abnormal segments significantly well. This will make the discrimination between normal and abnormal segments difficult in the testing phase.
On the other hand, Wang et al. [45] used an autoencoder for estimating the normality scores on a global scale. Then, the estimated normality scores are modeled using OC-SVM to further detect abnormality. Although a lot of work has been carried out for anomaly detection using traditional handcrafted features and deep feature learning techniques, there exists a lot of scope in combining and analyzing the complementary nature existing between them. Hence, we focus on a multi-view representation learning framework to learn robust and discriminative representations for activities in surveillance videos.
3 Multi-View Representation Learning for Video Anomaly Detection
Effective detection of anomalies highly depends on the representations derived from the input videos. Handcrafted and deep feature extraction techniques are traditional approaches which work reasonably well. But most of these methods lack in capturing the discriminative patterns that exist in unconstrained real-time scenarios. Combining the features obtained from these methods forms a composite representation where each input modality will complement each other. This complimentary characteristic of multi-view representation provided an inspiration toward building a framework for distinguishing normal and abnormal behavior based on their inter-class variations. We propose a common framework to obtain efficient representation for video segments, as shown in Fig. 1. In this framework, we propose (1) hybrid multi-view representations which combine both handcrafted and deep features, and (2) deep multi-view representations which solely utilize deep features from two-stream autoencoders.
3.1 Deep Feature Extraction using 3D Spatiotemporal Autoencoder
The aim is to extract spatiotemporal information from the input segments that can distinguish normal and abnormal behavior. We propose to use 3D spatiotemporal autoencoder (3D-STAE), which primarily consists of 3D convolutional and ConvLSTM layers to learn the intricate appearance and motion dynamics involved in training videos. Autoencoders [10] were initially used for dimensionality reduction tasks by transforming the input into a latent compressed representation. The various deep learning methods and nonlinear activation functions enable the autoencoders to effectively encode any given data distribution with minimal loss of information.

Overview of hybrid/deep multi-view representation learning framework
The autoencoder shown in Figs. 2 and 3 consists of 12 layers with 6 layers in the encoder and decoder part each. The encoder part comprises two 3D convolutional layers with 128 and 64 output channels, respectively. The kernel size and the number of strides used for first and second 3-D convolution layers are \((11\times 11\times 1), (5\times 5\times 1)\) and \((4\times 4\times 1), (2\times 2\times 1)\), respectively. Three ConvLSTM [46] layers are used in the encoder and decoder part of the 3D-STAE, each with 32, 16, and 4 output channels, respectively. The kernel size and the number of strides used for all the ConvLSTM layers are \((3\times 3)\) and \((1\times 1)\), respectively. Simple LSTMs cannot retain spatial information of video sequences. To deal with this problem, ConvLSTM was introduced where all the states are 3D tensors and can accommodate spatial dimensions. As provided in [46], ConvLSTM is given by:
At time step t, x is the input sequence, h is the hidden state, C is the cell output with gates i, f, o, and \(\star \) is the convolution operation, \(\circledcirc \) is the Hadamard product, W denotes the weight matrices, and bias vectors are given by b. The max pooling and the up-sampling layers act as the bridge between the encoder and decoder parts. Apart from the ConvLSTM layers, the decoder part consists of 3D deconvolutional layers [48], also known as the convolutional transpose layers for the purpose of reconstruction. The hyper-parameters such as kernel size, the number of kernels, and strides were determined empirically beforehand, while the kernel values are allowed to be initialized randomly. The training is performed based on the reconstruction loss:
where x is the input video sequence and \({\hat{x}}\) is the reconstructed video sequence. Video segments are given to the 3D-STAE from which deep features are learned while reconstructing the given input. The features are extracted from the intermediate Flatten layer, which unfolds the sequences from the ConvLSTM layer to vector form.
Existing methodologies follow end-to-end training [15, 16, 51] and thereby rule out the possibility of utilizing the features from the bottleneck layer. The bottleneck layer is the result of a nonlinear transformation of the input. This gives us a compact latent representation, which is then fed into a one-class SVM [5] for modeling normality. One-class SVM uses hyperspheres to model the normal class and effectively determine outlier data points as anomalous. When using end-to-end learning, a hard threshold should be used to set the level of normality, which is prone to false classification. One-class SVM alleviates this problem by estimating the normality of the input. It has an edge over other outlier detection techniques due to the fact that it is forced to learn tighter boundaries by eliminating a small fraction of data points as outliers.

Architecture of the proposed hybrid multi-view representation learning
3.2 Hybrid Multi-View Representation Learning
Handcrafted feature extraction methods have proved to be both simple and effective for tasks such as object recognition and video analysis [23, 30]. Due to its straightforward nature, it highly relies on the context in which it is applied, thus making it less generalized. Most of the handcrafted features work by imposing the desired constraints on the data rather than learning through heuristics. On the other hand, deep learning techniques have proved to work better in unconstrained and generalized environments. Being a data-driven method, they learn from the data and simultaneously optimize their learning path by backtracking. But, due to its complex nature, the feature learning process is highly uninterpretable. From this, it can be clearly inferred that some handcrafted and deep feature extraction techniques complement each other based on their characteristics. In the case of hybrid multi-view representation, handcrafted spatiotemporal autocorrelation of gradients [23] and deep features from 3D spatiotemporal autoencoder (3D-STAE) are used to form the hybrid multi-view representations as shown in Fig. 3.
Spatiotemporal autocorrelation of gradients: STACOG is a fast feature extraction technique that uses the auto-correlation derived from the space-time gradients to encode the motion information. Besides, the shift-invariance property of STACOG-based feature makes it suitable to recognize patterns from crowded scenes. For motion recognition, frame-based features are extracted from the subsequence of frames sampled at dense points along the time axis. The local relationship of activities corresponds to geometric features such as gradients and curvatures, which are fundamental properties of motion in spatiotemporal domain. The frame-based features are effective and fast due to the reduced computation time achieved by applying the histograms over a few sampling points placed along the time axis. When compared to more number of interest points in a standard bag of features technique, STACOG uses only a few sampled points to form the motion representation. The gradient vector is obtained from the (Ix, Iy, It) derivatives of motion volumes I(x, y, t) at each of the spatiotemporal points in a video. The gradient vectors can be geometrically represented by the magnitudes, spatial orientation, and temporal elevation along the time axis. The orientation of the gradients obtained from the magnitude information is coded into B orientation bins placed on a unit sphere by performing weighted voting to the nearest bins. Finally, the orientation is given by a B-dimensional vector h, which is termed as the “space-time orientation coding (STOC)” vector. The nth-order correlation for the space-time gradients defined in [23] is given as follows:
where \(d_{i}\) is the displacement vector with respect to the point \(r=(x,y,t)\), weighting function f and the tensor product of the vectors is denoted by \(\otimes \). For our hybrid representation, we use the first order of the STACOG features, simplified from Eq. (7) which is defined in [23] as
where \({\hat{F}}_{1}\) is the vectorized feature and min is used in place of the weight function f. Deep features are extracted from raw video segments using 3D-STAE, as described in Sect. 3.1. For example, the output vector dimension of a STACOG feature descriptor corresponding to a video segment is \(1\times 5754\). For the same input video segment, the vector dimension of deep features extracted by flattening the output of ConvLSTM layer in the last time step is \(1\times 4225\). These two vectorized forms of outputs are concatenated to form the hybrid multi-view representation of dimension \(1\times 9979\). This resultant representation is given to a one-class SVM for modeling and to detect abnormal segments as outliers.
3.3 Deep Multi-View Representation Learning
In this approach, we combine features extracted from deep models learned on different input modalities. Although deep learning methods have proved their efficiency in many areas, the interpretability of these methods is still a “black-box” and thereby increases unpredictability. So, there is a need to capture only the relevant and required information from these models. One way to achieve this is by transforming the input data into multiple modality spaces and combining the features extracted from them.

Architecture of the proposed deep multi-view representation learning
This approach replaces the STACOG features in hybrid multi-view representation by deep motion features extracted from 3D-STAE as given in Sect. 3.1 with motion maps as inputs. Deep MVR is formed by combining deep features from two-stream 3D spatiotemporal autoencoder models, as shown in Fig. 3. One autoencoder learns spatiotemporal information by training on the normal video segments, and the deep features are extracted from the flatten layer. Another form (view) of raw video input, namely optical flow images, also known as motion maps, is obtained for each frame in a video segment. Since we require robust motion maps, dense optical flow images [13] are extracted by considering a two-frame neighborhood. By estimating the displacement fields between the frames, a polynomial transform is performed to obtain the required grayscale optical flow image. These maps are grouped to form the segments of motion maps. Segmented motion maps are then given as input to the other 3D-STAE to learn and extract the finer details present in the motion maps. This autoencoder learns from the motion maps of normal videos, and the corresponding features are also extracted from the flatten layer. The features extracted from two different input views are concatenated similar to the hybrid MVR approach, in order to form a complete deep spatiotemporal multi-view representation, and a one-class SVM is used to detect the abnormal activities.
4 Experimental Studies
4.1 Datsasets Used
Experiments over the proposed methodology were carried out on three publicly available standard benchmark datasets, namely Avenue [31], Live Videos (LV) [26], and BEHAVE [4]. All these datasets were handled in an unsupervised fashion, i.e., the training data will contain only normal videos, while the testing data will contain both normal and abnormal videos.
CUHK Avenue: In Avenue dataset, there are a total of 16 training clips and 21 testing clips each of length not more than 2 min. The total frame count for training videos is 15,328, while that for testing is 15,324, with each frame of \(360 \times 640\) resolution and a frame rate of 25 frames per second. Some of the abnormal activities present in the testing videos include moving in the wrong direction, the presence of an abnormal object, and strange actions like running, throwing an object, etc. The ground truth for this dataset is provided as annotations for each frame at the pixel level.
Live Videos (LV): The LV dataset comprises realistic events and proves to be more challenging than other datasets due to its unpredictable nature. It consists of 30 videos in total each of which is a unique scenario containing both training/testing sequences. The frame rate varies from 7.5 to 30 frames per second, with a minimum resolution of \(176 \times 144\) and a maximum of \(1280 \times 720\). Some abnormal events include fighting, robbery, accidents, murder, kidnapping, illegal U-turn, etc. Each abnormal event highly depends on the nature of the environment in which it occurs. The abnormal events are localized by specifying the regions of interest in a separate sequence.
BEHAVE: In this dataset, various activities were simulated and captured at a rate of 25 frames per second with a resolution of \(640 \times 480\). Additionally, an annotation file contains the starting and ending frame numbers and a class label that describes the event occurring within the mentioned frames. Some of these events are InGroup, WalkTogether, Chase, Fight, etc.
4.2 Implementation
4.2.1 Preprocessing
The input videos are extracted frame-wise, and each frame is resized to \(227 \times 227\). A set of 25 consecutive frames are grouped together to form video segments with frame rate 25 fps, to maintain a constant frame rate and video length. These segments are normalized in the range [0–1] to help with the model convergence.
4.2.2 Training
The two-stream 3D-STAE is implemented using Keras deep learning framework. STACOG features for the hybrid multi-view representation and motion maps for deep multi-view representation approaches are extracted from raw video segments. The autoencoder is optimized with Adam optimizer [22], which is a simple and efficient approach. tanh activation was used in the 3D convolutional layers as tanh provides nonlinearity and effectively learns the underlying patterns. Sufficient dropout values were given in the ConvLSTM layers to avoid the problem of over-fitting. The flatten layer was introduced to get representations in a vector form. The up-sampling layer was used in the decoder part and treated as an approximate inverse of the max pooling layer used in the encoder. The model was trained batch-wise with a batch size of 16 and 100 epochs. To evaluate the performance of the proposed approach over the above-mentioned datasets, accuracy and its corresponding ROC-AUC were used.
4.2.3 Run-Time
With an NVIDIA QUADRO P5000 Graphics card, implementation of the proposed deep multi-view representation approach takes 0.03 s to extract representation of a frame. Our approach achieves 25 fps for detecting anomalies; this is faster than unmasking [44] method (20 fps) and is equal to the frame-pred [29] method. The total number of parameters used to train the proposed 3D-STAE is 5,48,001 only.
4.3 Performance Analysis
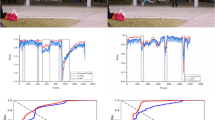
We have compared the performance of different baseline methods with our proposed approaches in Table 1 and Figs. 4, 5, and 6. These include methods that utilize only handcrafted features, namely HOF (histograms of optical flow) and STACOG. We have also attempted a variant of hybrid multi-view representation by fusing histogram of optical flow (HOF) and deep features extracted from 3D-STAE with edge maps as input. Further, experiments are conducted on single-stream architectures, and it was inferred that on conflating the complementary features, we could achieve better results.

Segment-wise ROC comparison for avenue dataset

Segment-wise ROC comparison for LV dataset

Segment wise ROC comparison for BEHAVE dataset
Comparisons are made between the existing state-of-the-art methods, and our proposed approaches are shown in Tables 2, 3, and 4, respectively. For Avenue dataset, Hasan et al. [16] have utilized an end-to-end framework that uses convolutional autoencoder with standard HOG, HOF, and raw videos as input to learn the temporal regularity in video sequences and the model is trained using the reconstruction loss. Del Giorno et al. [8] proposed a discriminative framework that uses spatiotemporal descriptors such as HOG, HOF, and MBH (motion boundary histograms) and one-class SVM (OC-SVM) to detect anomalies with least supervision. A convolutional winner-take-all autoencoder (CONV-WTA) that takes only optical flow sequences to model regular events was proposed by Tran and Hogg [43]. Instead of reconstruction loss, this approach utilizes OC-SVM to detect anomalies. The notable difference between this CONV-WTA\(+\)SVM [43] and the proposed deep multi-view representation approach is that we have used motion maps and the corresponding raw video segments separately as inputs to the two-stream autoencoders. As shown in Table 2, the proposed deep multi-view representation is comparable to [15, 45] and outperforms other state-of-the-art methods. There is a sharp increase in the detection performance of these methods due to the reason that these techniques are totally built under unsupervised conditions. There is no need to manually specify the normality for training, thus making these methods consider the whole spatiotemporal context for detecting abnormalities.
Even though the LV dataset is highly challenging due to its varying contextual nature, we have achieved significant improvement compared to other methods applied over this dataset, as shown in Table 3 and Fig. 5. Since each video contains different scenarios, it demands a generalized framework that can operate in a variety of environments. The hybrid multi-view representation significantly outperforms its HOF\(+\)Edge map variant, whereas the deep representation outperforms all the proposed variants and the state-of-the-art techniques. With the help of confusion matrices, it can be observed that the number of false negatives in the deep representation is comparatively less than that in the hybrid multi-view representation and the other variants.
When compared to other datasets, BEHAVE is a relatively small dataset and less complex in nature. Approaches like bag-of-words (BoW) [33], which combine local spatiotemporal descriptors, have shown some promising results. However, BoW highly depends on the spatiotemporal features and its discriminating ability. Motion-improved Weber local descriptor (MoIWLD) [49] captures the local motion information extended by the IWLD into a sparse representation model to exploit discriminative information. All these shortcomings are addressed with the help of a more discriminative feature set obtained through multi-view hybrid and deep representations. The proposed hybrid multi-view representation seems to work better on the BEHAVE dataset as it is less complex in nature. One possible justification for slightly degraded performance of the deep multi-view representation, as shown in Fig. 6, would be due to a smaller number of training examples present in the BEHAVE dataset. Even though our proposed methods give slightly lesser results than [45] in Avenue dataset, at least one of them outperforms existing state-of-the-art approaches in LV and BEHAVE datasets.
5 Conclusion
Recognizing abnormal human activities in surveillance videos is considered of core importance among all computer vision applications. Multi-view representation learning is becoming popular due to its capability to learn robust features from diverse input modalities. In this paper, we first propose a hybrid multi-view representation learning, which makes use of handcrafted spatiotemporal autocorrelation of gradient (STACOG)-based features and deep features learned from spatiotemporal autoencoders (STAE) with raw video segments as input to learn the normal patterns in surveillance videos. We have also proposed a deep multi-view representation learning framework that takes both motion maps and raw video segments to recognize abnormal activities. Two-stream STAE-based deep models for learning deep representations help in capturing the dependency of anomalies with their context, leading to better discrimination and overall performance. The proposed approaches produce better results than recent state-of-the-art methods consistently over all three standard benchmark datasets.
References
A. Ali, G.W. Taylor, Real-time end-to-end action detection with two-stream networks, in 2018 15th Conference on Computer and Robot Vision (CRV) (IEEE, 2018), pp. 31–38
A. Appathurai, R. Sundarasekar, C. Raja, E.J. Alex, C.A. Palagan, A. Nithya, An efficient optimal neural network-based moving vehicle detection in traffic video surveillance system. Circuits Syst. Signal Process. 39(2), 734–756 (2020)
S. Biswas, R. V. Babu, Real time anomaly detection in \(h\). 264 compressed videos, in 2013 Fourth National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG) (IEEE, 2013), pp. 1–4
S. Blunsden, R. Fisher, The BEHAVE video dataset: ground truthed video for multi-person behavior classification. Ann. BMVA 4(1–12), 4 (2010)
C.C. Chang, C.J. Lin, Libsvm: a library for support vector machines. ACM Trans. Intell. Syst. Technol. 2(3), 27 (2011)
K.W. Cheng, Y.T. Chen, W.H. Fang, Video anomaly detection and localization using hierarchical feature representation and gaussian process regression, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2015), pp. 2909–2917
W. Chu, H. Xue, C. Yao, D. Cai, Sparse coding guided spatiotemporal feature learning for abnormal event detection in large videos. IEEE Trans. Multimed. 21(1), 246–255 (2019)
A. Del Giorno, J.A. Bagnell, M. Hebert, A discriminative framework for anomaly detection in large videos, in European Conference on Computer Vision (Springer, 2016), pp. 334–349
A. Dilawari, M.U.G. Khan, ur Rehman Z, Awan KM, Mehmood I, Rho S, Toward generating human-centered video annotations. Circuits Syst. Signal Process. 39(2), 857–883 (2020)
G. Dong, G. Liao, H. Liu, G. Kuang, A review of the autoencoder and its variants: a comparative perspective from target recognition in synthetic-aperture radar images. IEEE Geosci. Remote Sens. Mag. 6(3), 44–68 (2018)
J.K. Dutta, B. Banerjee, Online detection of abnormal events using incremental coding length, in 29th AAAI Conference on Artificial Intelligence (2015)
Z. Fang, F. Fei, Y. Fang, C. Lee, N. Xiong, L. Shu, S. Chen, Abnormal event detection in crowded scenes based on deep learning. Multimed. Tools Appl. 75(22), 14617–14639 (2016)
G. Farnebäck, Two-frame motion estimation based on polynomial expansion, in Scandinavian Conference on Image Analysis (Springer, 2003), pp. 363–370
N.B. Ghrab, E. Fendri, M. Hammami, Abnormal events detection based on trajectory clustering, in 2016 13th International Conference on Computer Graphics (Imaging and Visualization (CGiV), IEEE, 2016), pp. 301–306
D. Gong, L. Liu, V. Le, B. Saha, M.R. Mansour, S. Venkatesh, A.V.D. Hengel, Memorizing normality to detect anomaly: memory-augmented deep autoencoder for unsupervised anomaly detection. ArXiv preprint arXiv:1904.02639 (2019)
M. Hasan, J. Choi, J. Neumann, A.K. Roy-Chowdhury, L.S. Davis, Learning temporal regularity in video sequences, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2016), pp. 733–742
X. Hu, S. Hu, Y. Huang, H. Zhang, H. Wu, Video anomaly detection using deep incremental slow feature analysis network. IET Comput. Vis. 10(4), 258–267 (2016)
R.T. Ionescu, S. Smeureanu, M. Popescu, B. Alexe, Detecting abnormal events in video using narrowed normality clusters, in 2019 IEEE Winter Conference on Applications of Computer Vision (WACV) (IEEE, 2019), pp. 1951–1960
V. Kaltsa, A. Briassouli, I. Kompatsiaris, M.G. Strintzis, Swarm-based motion features for anomaly detection in crowds, in 2014 IEEE International Conference on Image Processing (ICIP) (IEEE, 2014), pp. 2353–2357
A. Khamparia, B. Pandey, S. Tiwari, D. Gupta, A. Khanna, J.J. Rodrigues, An integrated hybrid CNN-RNN model for visual description and generation of captions. Circuits Syst. Signal Process. 39(2), 776–788 (2020)
M.U.K. Khan, H.S. Park, C.M. Kyung, Rejecting motion outliers for efficient crowd anomaly detection. IEEE Trans. Inf. Forensics Secur. 14(2), 541–556 (2018)
D.P. Kingma, J. Ba, Adam: a method for stochastic optimization. ArXiv preprint arXiv:1412.6980v9 (2014)
T. Kobayashi, N. Otsu, Motion recognition using local auto-correlation of space-time gradients. Pattern Recogn. Lett. 33(9), 1188–1195 (2012)
S.K. Kumaran, D.P. Dogra, P.P. Roy, A. Mitra, Video trajectory classification and anomaly detection using hybrid CNN-VAE. ArXiv preprint arXiv:1812.07203 (2018)
R. Leyva, V. Sanchez, C.T. Li, Abnormal event detection in videos using binary features, in 2017 40th International Conference on Telecommunications and Signal Processing (TSP) (IEEE, 2017), pp. 621–625
R. Leyva, V. Sanchez, C.T. Li, The LV dataset: a realistic surveillance video dataset for abnormal event detection, in 2017 5th International Workshop on Biometrics and Forensics (IWBF) (IEEE, 2017), pp. 1–6
Q. Li, W. Li, A novel framework for anomaly detection in video surveillance using multi-feature extraction, in 2016 9th International Symposium on Computational Intelligence and Design (ISCID), vol. 1 (IEEE, 2016), pp. 455–459
Y. Li, M. Yang, Z.M. Zhang, A survey of multi-view representation learning. IEEE Trans. Knowl. Data Eng. 31(10), 1863–1883 (2018)
W. Liu, W. Luo, D. Lian, S. Gao, Future frame prediction for anomaly detection—a new baseline, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018), pp. 6536–6545
D.G. Lowe et al., Object recognition from local scale-invariant features. ICCV 99, 1150–1157 (1999)
C. Lu, J. Shi, J. Jia, Abnormal event detection at 150 fps in matlab, in Proceedings of the IEEE International Conference on Computer Vision (2013), pp. 2720–2727
W. Luo, W. Liu, S. Gao, A revisit of sparse coding based anomaly detection in stacked rnn framework, in Proceedings of the IEEE International Conference on Computer Vision (2017), pp. 341–349
E.B. Nievas, O.D. Suarez, G.B. García, R. Sukthankar, Violence detection in video using computer vision techniques, in International Conference on Computer Analysis of Images and Patterns (Springer, 2011), pp. 332–339
N. Noceti, F. Odone, A. Sciutti, G. Sandini, Exploring biological motion regularities of human actions: a new perspective on video analysis. ACM Trans. Appl. Percept. 14(3), 21:1–21:20 (2017). https://doi.org/10.1145/3086591
R. Ramya, K. Mala, S.S. Nidhyananthan, 3D facial expression recognition using multi-channel deep learning framework. Circuits Syst. Signal Process. 39(2), 789–804 (2020)
M. Ravanbakhsh, M. Nabi, E. Sangineto, L. Marcenaro, C. Regazzoni, N. Sebe, Abnormal event detection in videos using generative adversarial nets, in 2017 IEEE International Conference on Image Processing (ICIP) (IEEE, 2017), pp. 1577–1581
M. Sabokrou, M. Fayyaz, M. Fathy, R. Klette, Deep-cascade: cascading 3D deep neural networks for fast anomaly detection and localization in crowded scenes. IEEE Trans. Image Process. 26(4), 1992–2004 (2017)
S. Smeureanu, R.T. Ionescu, M. Popescu, B. Alexe, Deep appearance features for abnormal behavior detection in video, in International Conference on Image Analysis and Processing (Springer, 2017), pp. 779–789
S. Sudhakaran, O. Lanz, Learning to detect violent videos using convolutional long short-term memory, in 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS) (IEEE, 2017), pp. 1–6
W. Sultani, C. Chen, M. Shah, Real-world anomaly detection in surveillance videos, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018), pp. 6479–6488
Q. Sun, H. Liu, T. Harada, Online growing neural gas for anomaly detection in changing surveillance scenes. Pattern Recogn. 64, 187–201 (2017)
T. Tadros, N.C. Cullen, M.R. Greene, E.A. Cooper, Assessing neural network scene classification from degraded images. ACM Trans. Appl. Percept. 16(4), 21:1–21:20 (2019). https://doi.org/10.1145/3342349
H.T. Tran, D. Hogg, Anomaly detection using a convolutional winner-take-all autoencoder, in Proceedings of the British Machine Vision Conference 2017 (British Machine Vision Association, 2017)
R. Tudor Ionescu, S. Smeureanu, B. Alexe, M. Popescu, Unmasking the abnormal events in video, in Proceedings of the IEEE International Conference on Computer Vision (2017), pp. 2895–2903
S. Wang, Y. Zeng, Q. Liu, C. Zhu, E. Zhu, J. Yin, Detecting abnormality without knowing normality, in ACM International Conference on Multimedia (ACM Press, 2018)
S. Xingjian, Z. Chen, H. Wang, D.Y. Yeung, W.K. Wong, W.C. Woo, Convolutional LSTM network: a machine learning approach for precipitation nowcasting, in Advances in Neural Information Processing Systems (2015), pp. 802–810
D. Xu, E. Ricci, Y. Yan, J. Song, N. Sebe, Learning deep representations of appearance and motion for anomalous event detection. ArXiv preprint arXiv:1510.01553 (2015)
M.D. Zeiler, D. Krishnan, G.W. Taylor, R. Fergus, Deconvolutional networks, in CVPR, vol. 10 (2010), p. 7
T. Zhang, W. Jia, X. He, J. Yang, Discriminative dictionary learning with motion weber local descriptor for violence detection. IEEE Trans. Circuits Syst. Video Technol. 27(3), 696–709 (2017)
Y. Zhang, H. Lu, L. Zhang, X. Ruan, S. Sakai, Video anomaly detection based on locality sensitive hashing filters. Pattern Recogn. 59, 302–311 (2016)
Y. Zhao, B. Deng, C. Shen, Y. Liu, H. Lu, X.S. Hua, Spatio-temporal autoencoder for video anomaly detection, in ACM Multimedia (2017)
J. Zhao, X. Xie, X. Xu, S. Sun, Multi-view learning overview: recent progress and new challenges. Inf. Fus. 38, 43–54 (2017)
J.T. Zhou, J. Du, H. Zhu, X. Peng, Y. Liu, R.S.M. Goh, Anomalynet: an anomaly detection network for video surveillance. IEEE Trans. Inf. Forensics Secur. 14(10), 2537–2550 (2019)
Acknowledgements
The authors would like to acknowledge the following funding agencies: “Council of Scientific and Industrial Research (CSIR)” (09/1095(0043)/19-EMR-I) and “Assistive speech” (No. DST/CSRI/2017/131(G)) project under the Cognitive Science Research Initiative (CSRI) sanctioned by the Department of Science and Technology, Government of India.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Data Availability Statement
The datasets used in the experiments, namely CUHK Avenue, Live Videos (LV), and BEHAVE, are publicly available. The code supporting this work is available from the corresponding author upon request.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Deepak, K., Srivathsan, G., Roshan, S. et al. Deep Multi-view Representation Learning for Video Anomaly Detection Using Spatiotemporal Autoencoders. Circuits Syst Signal Process 40, 1333–1349 (2021). https://doi.org/10.1007/s00034-020-01522-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-020-01522-7