
Abstract
We provide a provable-security treatment of “robust” encryption. Robustness means it is hard to produce a ciphertext that is valid for two different users. Robustness makes explicit a property that has been implicitly assumed in the past. We argue that it is an essential conjunct of anonymous encryption. We show that natural anonymity-preserving ways to achieve it, such as adding recipient identification information before encrypting, fail. We provide transforms that do achieve it, efficiently and provably. We assess the robustness of specific encryption schemes in the literature, providing simple patches for some that lack the property. We explain that robustness of the underlying anonymous IBE scheme is essential for public-key encryption with keyword search (PEKS) to be consistent (meaning, not have false positives), and our work provides the first generic conversions of anonymous IBE schemes to consistent (and secure) PEKS schemes. Overall, our work enables safer and simpler use of encryption.
Similar content being viewed by others



1 Introduction
This paper provides a provable-security treatment of encryption “robustness.” Robustness reflects the difficulty of producing a ciphertext valid under two different encryption keys. The value of robustness is conceptual, “naming” something that has been undefined yet at times implicitly (and incorrectly) assumed. Robustness helps make encryption more misuse resistant. We provide formal definitions of several variants of the goal; consider and dismiss natural approaches to achieve it; provide two general robustness-adding transforms; test robustness of existing schemes and patch the ones that fail; and discuss some applications.
The definitions. Both the PKE and the IBE settings are of interest, and the explication is simplified by unifying them as follows. Associate to each identity an encryption key, defined as the identity itself in the IBE case and its (honestly generated) public key in the PKE case. The adversary outputs a pair \( id _0, id _1\) of distinct identities. For strong robustness, it also outputs a ciphertext \(C^*\); for weak, it outputs a message \(M^*\), and \(C^*\) is defined as the encryption of \(M^*\) under the encryption key \( ek _1\) of \( id _1\). The adversary wins if the decryptions of \(C^*\) under the decryption keys \( dk _0, dk _1\) corresponding to \( ek _0, ek _1\) are both non-\(\bot \). Both weak and strong robustness can be considered under chosen-plaintext or chosen-ciphertext attacks, resulting in four notions (for each of PKE and IBE) that we denote \(\mathrm {WROB\text{- }CPA}\), \(\mathrm {WROB\text{- }CCA}\), \(\mathrm {SROB\text{- }CPA}\), \(\mathrm {SROB\text{- }CCA}\).
Why robustness? The primary security requirement for encryption is data privacy, as captured by notions \(\mathrm {IND\text{- }CPA}\) or \(\mathrm {IND\text{- }CCA}\) [13, 16, 29, 35, 45]. Increasingly, we are also seeing a market for anonymity, as captured by notions \(\mathrm {ANO\text{- }CPA}\) and \(\mathrm {ANO\text{- }CCA}\) [1, 7]. Anonymity asks that a ciphertext does not reveal the encryption key under which it was created.
Where you need anonymity, there is a good chance you need robustness too. Indeed, we would go so far as to say that robustness is an essential companion of anonymous encryption. The reason is that without it we would have security without basic communication correctness, likely upsetting our application. This is best illustrated by the following canonical application of anonymous encryption, but shows up also, in less direct but no less important ways, in other applications. A sender wants to send a message to a particular target recipient, but, to hide the identity of this target recipient, anonymously encrypts it under her key and broadcasts the ciphertext to a larger group. But as a member of this group I need, upon receiving a ciphertext, to know whether or not I am the target recipient. (The latter typically needs to act on the message.) Of course I can’t tell whether the ciphertext is for me just by looking at it since the encryption is anonymous, but decryption should divulge this information. It does, unambiguously, if the encryption is robust (the ciphertext is for me iff my decryption of it is not \(\bot \)) but otherwise I might accept a ciphertext (and some resulting message) of which I am not the target, creating mis-communication. Natural “solutions,” such as including the encryption key or identity of the target recipient in the plaintext before encryption and checking it upon decryption, are, in hindsight, just attempts to add robustness without violating anonymity and, as we will see, don’t work.
We were led to formulate robustness upon revisiting public-key encryption with keyword search (PEKS) [12]. In a clever usage of anonymity, Boneh, Di Crescenzo, Ostrovsky and Persiano (BDOP) [12] showed how this property in an IBE scheme allowed it to be turned into a privacy-respecting communications filter. But Abdalla et. al [1] noted that the BDOP filter could lack consistency, meaning turn up false positives. Their solution was to modify the construction. What we observe instead is that consistency would in fact be provided by the original construct if the IBE scheme was robust. PEKS consistency turns out to correspond exactly to communication correctness of the anonymous IBE scheme in the sense discussed above. (Because the PEKS messages in the BDOP scheme are the recipients identities from the IBE perspective.) Besides resurrecting the BDOP construct, the robustness approach allows us to obtain the first consistent \(\mathrm {IND\text{- }CCA}\)-secure PEKS without random oracles.
Sako’s auction protocol [47] uses anonymous PKE to hide the bids of losers. We present an attack on fairness whose cause is ultimately a lack of robustness in the anonymous encryption scheme.
All this underscores a number of the claims we are making about robustness: that it is of conceptual value; that it makes encryption more resistant to misuse; that it has been implicitly (and incorrectly) assumed; and that there is value to making it explicit, formally defining and provably achieving it.
Weak versus strong. The above-mentioned auction protocol fails because an adversary can create a ciphertext that decrypts correctly under any decryption key. Strong robustness is needed to prevent this. Weak robustness (of the underlying IBE) will yield PEKS consistency for honestly encrypted messages but may allow spammers to bypass all filters with a single ciphertext, something prevented by strong robustness. Strong robustness trumps weak for applications and goes farther toward making encryption misuse resistant. We have defined and considered the weaker version because it can be more efficiently achieved, because some existing schemes achieve it and because attaining it is a crucial first step in our method for attaining strong robustness.
Achieving robustness. As the reader has surely already noted, robustness (even strong) is trivially achieved by appending the encryption key to the ciphertext and checking for it upon decryption. The problem is that the resulting scheme is not anonymous and, as we have seen above, it is exactly for anonymous schemes that robustness is important. Of course, data privacy is important too. Letting \({\mathrm {AI\text{- }ATK}=\mathrm {ANO\text{- }ATK}+\mathrm {IND\text{- }ATK}}\) for \(\mathrm {ATK}\in \{\mathrm {CPA},\mathrm {CCA}\}\), the target notions of interest are \({\mathrm {AI\text{- }ATK}+\mathrm {XROB\text{- }ATK}}\) for \(\mathrm {ATK}\in \{\mathrm {CPA}, \mathrm {CCA}\}\) and \(\mathrm {X}\in \{\mathrm {W},\mathrm {S}\}\). Figure 1 shows the relations between these notions, which hold for both PKE and IBE. We note in particular that \(\mathrm {AI\text{- }CCA}\) does not imply any form of robustness, refuting the possible impression that CCA-security automatically provides robustness.

Relations between notions. An arrow \(\mathrm {A}\rightarrow \mathrm {B}\) is an implication, meaning every scheme that is \(\mathrm {A}\)-secure is also \(\mathrm {B}\)-secure, while a barred arrow \(\mathrm {A}\not \rightarrow \mathrm {B}\) is a separation, meaning that there is a \(\mathrm {A}\)-secure scheme that is not \(\mathrm {B}\)-secure (Assuming of course that there exists a \(\mathrm {A}\)-secure scheme in the first place)

Achieving Robustness. The first table summarizes our findings on the encryption with redundancy transform. “No” means the method fails to achieve the indicated robustness for all redundancy functions, while “yes” means there exists a redundancy function for which it works. The second table summarizes robustness results about some specific \(\mathrm {AI\text{- }CCA}\) schemes
Transforms. Toward achieving robustness, it is natural to begin by seeking a general transform that takes an arbitrary \({\mathrm {AI\text{- }ATK}}\) scheme and returns a \({\mathrm {AI\text{- }ATK}+\mathrm {XROB\text{- }ATK}}\) one. This allows us to exploit known constructions of \({\mathrm {AI\text{- }ATK}}\) schemes, supports modular protocol design and also helps understand robustness divorced from the algebra of specific schemes. Furthermore, there is a natural and promising transform to consider. Namely, before encrypting, append to the message some redundancy, such as the recipient encryption key, a constant, or even a hash of the message, and check for its presence upon decryption. (Adding the redundancy before encrypting rather than after preserves \({\mathrm {AI\text{- }ATK}}\).) Intuitively this should provide robustness because decryption with the “wrong” key will result, if not in rejection, then in recovery of a garbled plaintext, unlikely to possess the correct redundancy.
The truth is more complex. We consider two versions of the paradigm and summarize our findings in Fig. 2. In encryption with unkeyed redundancy, the redundancy is a function \({\mathsf {RC}}\) of the message and encryption key alone. In this case, we show that the method fails spectacularly, not providing even weak robustness regardless of the choice of the function \({\mathsf {RC}}\). In encryption with keyed redundancy, we allow \({\mathsf {RC}}\) to depend on a key K that is placed in the public parameters of the transformed scheme, out of direct reach of the algorithms of the original scheme. In this form, the method can easily provide weak robustness, and that too with a very simple redundancy function, namely the one that simply returns K.
But we show that even encryption with keyed redundancy fails to provide strong robustness. To achieve the latter we have to step outside the encryption with redundancy paradigm. We present a strong robustness conferring transform that uses a (non-interactive) commitment scheme. For subtle reasons, for this transform to work the starting scheme needs to already be weakly robust. If it isn’t already, we can make it so via our weak robustness transform.
In summary, on the positive side we provide a transform conferring weak robustness and another conferring strong robustness. Given any \({\mathrm {AI\text{- }ATK}}\) scheme the first transform returns a \({\mathrm {WROB\text{- }ATK}+\mathrm {AI\text{- }ATK}}\) one. Given any \({\mathrm {AI\text{- }ATK}+\mathrm {WROB\text{- }ATK}}\) scheme the second transform returns a \({\mathrm {SROB\text{- }ATK}+\mathrm {AI\text{- }ATK}}\) one. In both cases, it is for both \(\mathrm {ATK}=\mathrm {CPA}\) and \(\mathrm {ATK}=\mathrm {CCA}\) and in both cases the transform applies to what we call general encryption schemes, of which both PKE and IBE are special cases, so both are covered.
The Fujisaki–Okamoto (FO) transform [32] and the Canetti–Halevi–Katz (CHK) transform [9, 25] both confer \(\mathrm {IND\text{- }CCA}\), and a natural question is whether they confer robustness as well. It turns out that neither transform generically provides strong robustness (\(\mathrm {SROB\text{- }CCA}\)) and CHK does not provide weak (\(\mathrm {WROB\text{- }CCA}\)) either. We do not know whether or not FO provides \(\mathrm {WROB\text{- }CCA}\).
Robustness of specific schemes. The robustness of existing schemes is important because they might be in use. We ask which specific existing schemes are robust, and, for those that are not, whether they can be made so at a cost lower than that of applying one of our general transforms. The decryption algorithms of most \(\mathrm {AI\text{- }CPA}\) schemes never reject, which means these schemes are not robust, so we focus on schemes that are known to be \(\mathrm {AI\text{- }CCA}\). This narrows the field quite a bit. The main findings and results we discuss next are summarized in Fig. 2.
The Cramer–Shoup ( ) PKE scheme is known to be \(\mathrm {AI\text{- }CCA}\) in the standard model [7, 27]. We show that it is \(\mathrm {WROB\text{- }CCA}\) but not \(\mathrm {SROB\text{- }CCA}\), the latter because encryption with 0 randomness yields a ciphertext valid under any encryption key. We present a modified version
) PKE scheme is known to be \(\mathrm {AI\text{- }CCA}\) in the standard model [7, 27]. We show that it is \(\mathrm {WROB\text{- }CCA}\) but not \(\mathrm {SROB\text{- }CCA}\), the latter because encryption with 0 randomness yields a ciphertext valid under any encryption key. We present a modified version  of the scheme that disallows 0 randomness. It continues to be \(\mathrm {AI\text{- }CCA}\), and we show is \(\mathrm {SROB\text{- }CCA}\). Our proof that
of the scheme that disallows 0 randomness. It continues to be \(\mathrm {AI\text{- }CCA}\), and we show is \(\mathrm {SROB\text{- }CCA}\). Our proof that  is \(\mathrm {SROB\text{- }CCA}\) builds on the information-theoretic part of the proof of [27]. The result does not need to assume hardness of DDH. It relies instead on pre-image security of the underlying hash function for random range points, something not implied by collision resistance but seemingly possessed by candidate functions. The same approach does not easily extend to variants of the
is \(\mathrm {SROB\text{- }CCA}\) builds on the information-theoretic part of the proof of [27]. The result does not need to assume hardness of DDH. It relies instead on pre-image security of the underlying hash function for random range points, something not implied by collision resistance but seemingly possessed by candidate functions. The same approach does not easily extend to variants of the  scheme such as the hybrid Damgård–ElGamal scheme as proved secure by Kiltz et al. [41]. We leave their treatment to future work.
scheme such as the hybrid Damgård–ElGamal scheme as proved secure by Kiltz et al. [41]. We leave their treatment to future work.
In the IBE setting, the CCA version  of the RO model Boneh–Franklin scheme is \(\mathrm {AI\text{- }CCA}\) [1, 15], and we show it is \(\mathrm {SROB\text{- }CCA}\). The standard model Boyen–Waters scheme
of the RO model Boneh–Franklin scheme is \(\mathrm {AI\text{- }CCA}\) [1, 15], and we show it is \(\mathrm {SROB\text{- }CCA}\). The standard model Boyen–Waters scheme  is \(\mathrm {AI\text{- }CCA}\) [23], but we show it is neither \(\mathrm {WROB\text{- }CCA}\) nor \(\mathrm {SROB\text{- }CCA}\). Of course it can be made robust via our transforms. We note that the
is \(\mathrm {AI\text{- }CCA}\) [23], but we show it is neither \(\mathrm {WROB\text{- }CCA}\) nor \(\mathrm {SROB\text{- }CCA}\). Of course it can be made robust via our transforms. We note that the  scheme is obtained via the FO transform [32] and
scheme is obtained via the FO transform [32] and  via the CHK transform [9, 25]. As indicated above, neither transform generically provides strong robustness. This doesn’t say whether they do or not when applied to specific schemes, and indeed the first does for
via the CHK transform [9, 25]. As indicated above, neither transform generically provides strong robustness. This doesn’t say whether they do or not when applied to specific schemes, and indeed the first does for  and the second does not for
and the second does not for  .
.
 is a standardized, in-use PKE scheme due to [5], who show that it is \(\mathrm {AI\text{- }CCA}\). The situation for robustness is analogous to that for
is a standardized, in-use PKE scheme due to [5], who show that it is \(\mathrm {AI\text{- }CCA}\). The situation for robustness is analogous to that for  discussed above. Namely, we show
discussed above. Namely, we show  is \(\mathrm {WROB\text{- }CCA}\) but not \(\mathrm {SROB\text{- }CCA}\) (due to the possibility of the randomness in the asymmetric component being 0) and present a modified version
is \(\mathrm {WROB\text{- }CCA}\) but not \(\mathrm {SROB\text{- }CCA}\) (due to the possibility of the randomness in the asymmetric component being 0) and present a modified version  (it disallows 0 randomness and is still \(\mathrm {AI\text{- }CCA}\)) that we show is \(\mathrm {SROB\text{- }CCA}\). This result assumes (only) a form of collision resistance from the MAC.
(it disallows 0 randomness and is still \(\mathrm {AI\text{- }CCA}\)) that we show is \(\mathrm {SROB\text{- }CCA}\). This result assumes (only) a form of collision resistance from the MAC.
Our coverage is intended to be illustrative rather than exhaustive. There are many more specific schemes about whose robustness one may ask, and we leave these as open questions.
Summary. Protocol design suggests that designers have the intuition that robustness is naturally present. This seems to be more often right than wrong when considering weak robustness of specific \(\mathrm {AI\text{- }CCA}\) schemes. Prevailing intuition about generic ways to add even weak robustness is wrong, yet we show it can be done by an appropriate tweak of these ideas. Strong robustness is more likely to be absent than present in specific schemes, but important schemes can be patched. Strong robustness can also be added generically, but with more work.
Related work. There is growing recognition that robustness is important in applications and worth defining explicitly, supporting our own claims to this end. Thus, the strong correctness requirement for public-key encryption of [8] and the correctness requirement for hidden vector and predicate encryption of [24, 40] imply a form of weak robustness. In work that was concurrent to, and independent of, the preliminary version of our work [3], Hofheinz and Weinreb [38] introduced a notion of well-addressedness of IBE schemes that is just like weak robustness except that the adversary gets the IBE master secret key. These works do not consider or achieves strong robustness, and the last does not treat PKE. Well-addressedness of IBE implies \(\mathrm {WROB\text{- }CCA}\) but does not imply \(\mathrm {SROB\text{- }CCA}\) and, on the other hand, \(\mathrm {SROB\text{- }CCA}\) does not imply well-addressedness. Also in work that was concurrent to, and independent of, the preliminary version of our work [3], Canetti et al. [26] define wrong-key detection for symmetric encryption, which is a form of robustness. The term robustness is also used in multi-party computation to denote the property that corrupted parties cannot prevent honest parties from computing the correct protocol output [18, 36, 37]. This meaning is unrelated to our use of the word robustness.
Subsequent work. Since the publication of a preliminary version of our work in [2, 3], several extensions have appeared in the literature.
Mohassel [44] observes that weak robustness is needed to ensure the chosen-ciphertext security of hybrid constructions and provides several new robustness-adding transforms providing different trade-offs between ciphertext size and computational overhead. He also proposes a new relaxation of robustness, known as collision-freeness, which may already be sufficient for certain applications. Informally, collision-freeness states that a ciphertext should not decrypt to the same message under two different decryption keys.
Other security notions related to robustness have also been proposed in [11, 14]. While the notion of decryption verifiability in [14] can be interpreted as a weak form of robustness in the context of encryption schemes, the notion of unambiguity in [11] can be seen as an analogue of robustness for signatures.
Libert et al. [43] show that robustness is important when building anonymous broadcast encryption generically from identity-based encryption. In their construction, the correctness of the broadcast encryption crucially depends on the weak robustness of the underlying identity-based encryption scheme. The relation between robustness and anonymous broadcast encryption was also observed in an earlier work by Barth et al. [8].
Farshim et al. [31] introduce further notions of robustness including a strengthening and simplification of our strong robustness that they call complete robustness. They show that Sako’s protocol [47] is still vulnerable to attacks even if it uses a strongly robust encryption scheme, a gap addressed by complete robustness.
Boneh et al. [21] remark that our robustness conferring transforms also applies to function-private identity-based encryption schemes since they do not change the decryption keys and hence preserve function privacy.
Seurin and Treger [48] propose a variant of Schnorr-Signed ElGamal encryption [39, 50] and show that it is both \(\mathrm {AI\text{- }CCA}\) and \(\mathrm {SROB\text{- }CCA}\). While the proof of \(\mathrm {AI\text{- }CCA}\) relies on the hardness of DDH in the random oracle model, the proof of \(\mathrm {SROB\text{- }CCA}\) only assumes collision resistance security of the underlying hash function.
Versions of this paper. A preliminary version of this paper appeared at the Theory of Cryptography Conference 2010 [3]. This full version, apart from containing full proofs for all security statements, adds a discussion about the robustness of other schemes and transforms in Sects. 6 and 7, as well as more details about the application of our results to auctions and searchable encryption in Sects. 8 and 9.
2 Definitions

Game  defining \({\mathrm {AI\text{- }ATK}}\) security of general encryption scheme
defining \({\mathrm {AI\text{- }ATK}}\) security of general encryption scheme 
Notation and conventions. If x is a string then |x| denotes its length, and if S is a set then |S| denotes its size. The empty string is denoted \(\varepsilon \). By \(a_1\Vert \ldots \Vert a_n\), we denote a string encoding of \(a_1,\ldots ,a_n\) from which \(a_1,\ldots ,a_n\) are uniquely recoverable. (Usually, concatenation suffices.) By \(a_1\Vert \ldots \Vert a_n \leftarrow a\), we mean that a is parsed into its constituents \(a_1,\ldots , a_n\). Similarly, if \(a = (a_1,\ldots ,a_n)\), then \((a_1,\ldots ,a_n) \leftarrow a\) means we parse a as shown. Unless otherwise indicated, an algorithm may be randomized. By \(y \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}A(x_1,x_2,\ldots )\), we denote the operation of running A on inputs \(x_1,x_2,\ldots \) and fresh coins and letting y denote the output. We denote by \([A(x_1,x_2,\ldots )]\) the set of all possible outputs of A on inputs \(x_1,x_2,\ldots \). We assume that an algorithm returns \(\bot \) if any of its inputs is \(\bot \).
Games. Our definitions and proofs use code-based game playing [20]. Recall that a game—look at Fig. 3 for an example— has an Initialize procedure, procedures to respond to adversary oracle queries, and a Finalize procedure. A game  is executed with an adversary \(A\) as follows. First, Initialize executes and its outputs are the inputs to \(A\). Then \(A\) executes, its oracle queries being answered by the corresponding procedures of
is executed with an adversary \(A\) as follows. First, Initialize executes and its outputs are the inputs to \(A\). Then \(A\) executes, its oracle queries being answered by the corresponding procedures of  . When \(A\) terminates, its output becomes the input to the Finalize procedure. The output of the latter, denoted
. When \(A\) terminates, its output becomes the input to the Finalize procedure. The output of the latter, denoted  , is called the output of the game, and we let “
, is called the output of the game, and we let “ ” denote the event that this game output takes value \(\mathsf {true}\). Boolean flags are assumed initialized to \(\mathsf {false}\). Games
” denote the event that this game output takes value \(\mathsf {true}\). Boolean flags are assumed initialized to \(\mathsf {false}\). Games  are identical until \(\mathsf {bad}\) if their code differs only in statements that follow the setting of \(\mathsf {bad}\) to \(\mathsf {true}\). Our proofs will use the following.
are identical until \(\mathsf {bad}\) if their code differs only in statements that follow the setting of \(\mathsf {bad}\) to \(\mathsf {true}\). Our proofs will use the following.
Lemma 2.1
[20] Let  be identical until \(\mathsf {bad}\) games, and \(A\) an adversary. Then
be identical until \(\mathsf {bad}\) games, and \(A\) an adversary. Then

The running time of an adversary is the worst case time of the execution of the adversary with the game defining its security, so that the execution time of the called game procedures is included.
General encryption. We introduce and use general encryption schemes, of which both PKE and IBE are special cases. This allows us to avoid repeating similar definitions and proofs. A general encryption (GE) scheme is a tuple  of algorithms. The parameter generation algorithm \({\mathsf {PG}}\) takes no input and returns common parameter \( pars \) and a master secret key \( msk \). On input \( pars , msk , id \), the key generation algorithm \({\mathsf {KG}}\) produces an encryption key \( ek \) and decryption key \( dk \). On inputs \( pars , ek , M \), the encryption algorithm \({\mathsf {Enc}}\) produces a ciphertext C encrypting plaintext \( M \). On input \( pars , ek , dk , C \), the deterministic decryption algorithm \({\mathsf {Dec}}\) returns either a plaintext message \( M \) or \(\bot \) to indicate that it rejects. We say that
of algorithms. The parameter generation algorithm \({\mathsf {PG}}\) takes no input and returns common parameter \( pars \) and a master secret key \( msk \). On input \( pars , msk , id \), the key generation algorithm \({\mathsf {KG}}\) produces an encryption key \( ek \) and decryption key \( dk \). On inputs \( pars , ek , M \), the encryption algorithm \({\mathsf {Enc}}\) produces a ciphertext C encrypting plaintext \( M \). On input \( pars , ek , dk , C \), the deterministic decryption algorithm \({\mathsf {Dec}}\) returns either a plaintext message \( M \) or \(\bot \) to indicate that it rejects. We say that  is a public-key encryption (PKE) scheme if \( msk =\varepsilon \) and \({\mathsf {KG}}\) ignores its \( id \) input. To recover the usual syntax, we may in this case write the output of \({\mathsf {PG}}\) as \( pars \) rather than \(( pars , msk )\) and omit \( msk , id \) as inputs to \({\mathsf {KG}}\). We say that
is a public-key encryption (PKE) scheme if \( msk =\varepsilon \) and \({\mathsf {KG}}\) ignores its \( id \) input. To recover the usual syntax, we may in this case write the output of \({\mathsf {PG}}\) as \( pars \) rather than \(( pars , msk )\) and omit \( msk , id \) as inputs to \({\mathsf {KG}}\). We say that  is an identity-based encryption (IBE) scheme if the encryption key created by \({\mathsf {KG}}\) on inputs \( pars , msk , id \) only depends on \( pars \) and \( id \). To recover the usual syntax, we may in this case write the output of \({\mathsf {KG}}\) as \( dk \) rather than \(( ek , dk )\). It is easy to see that in this way we have recovered the usual primitives. But there are general encryption schemes that are neither PKE nor IBE schemes, meaning that the primitive is indeed more general.
is an identity-based encryption (IBE) scheme if the encryption key created by \({\mathsf {KG}}\) on inputs \( pars , msk , id \) only depends on \( pars \) and \( id \). To recover the usual syntax, we may in this case write the output of \({\mathsf {KG}}\) as \( dk \) rather than \(( ek , dk )\). It is easy to see that in this way we have recovered the usual primitives. But there are general encryption schemes that are neither PKE nor IBE schemes, meaning that the primitive is indeed more general.
Correctness. Correctness of a general encryption scheme  requires that, for all \(( pars , msk ) \in [{\mathsf {PG}}]\), all plaintexts \( M \) in the underlying message space associated with \( pars \), all identities \( id \), and all \(( ek , dk )\in [{\mathsf {KG}}( pars , msk , id )]\), we have \({\mathsf {Dec}}( pars , ek , dk , {\mathsf {Enc}}( pars , ek , M ))= M \) with probability one, where the probability is taken over the coins of \({\mathsf {Enc}}\).
requires that, for all \(( pars , msk ) \in [{\mathsf {PG}}]\), all plaintexts \( M \) in the underlying message space associated with \( pars \), all identities \( id \), and all \(( ek , dk )\in [{\mathsf {KG}}( pars , msk , id )]\), we have \({\mathsf {Dec}}( pars , ek , dk , {\mathsf {Enc}}( pars , ek , M ))= M \) with probability one, where the probability is taken over the coins of \({\mathsf {Enc}}\).

Games  and
and  defining \(\mathrm {WROB\text{- }ATK}\) and \(\mathrm {SROB\text{- }ATK}\) security (respectively) of general encryption scheme
defining \(\mathrm {WROB\text{- }ATK}\) and \(\mathrm {SROB\text{- }ATK}\) security (respectively) of general encryption scheme  . The procedures on the left are common to both games, which differ only in their \(\mathbf{Finalize }\) procedures
. The procedures on the left are common to both games, which differ only in their \(\mathbf{Finalize }\) procedures
\({\mathrm {AI\text{- }ATK}}\) security. Historically, definitions of data privacy (IND) [13, 16, 29, 35, 45] and anonymity (ANON) [1, 7] have been separate. We are interested in schemes that achieve both, so rather than use separate definitions we follow [17] and capture both simultaneously via game  of Fig. 3. A cpa adversary is one that makes no
of Fig. 3. A cpa adversary is one that makes no  queries, and a cca adversary is one that might make such queries. The ai-advantage of such an adversary, in either case, is
queries, and a cca adversary is one that might make such queries. The ai-advantage of such an adversary, in either case, is

We will assume an ai-adversary makes only one  query, since a hybrid argument shows that making q of them can increase its ai-advantage by a factor of at most q.
query, since a hybrid argument shows that making q of them can increase its ai-advantage by a factor of at most q.
Oracle  represents the IBE key extraction oracle [16]. In the PKE case, it is superfluous in the sense that removing it results in a definition that is equivalent up to a factor depending on the number of
represents the IBE key extraction oracle [16]. In the PKE case, it is superfluous in the sense that removing it results in a definition that is equivalent up to a factor depending on the number of  queries. That’s probably why the usual definition has no such oracle. But conceptually, if it is there for IBE, it ought to be there for PKE, and it does impact concrete security.
queries. That’s probably why the usual definition has no such oracle. But conceptually, if it is there for IBE, it ought to be there for PKE, and it does impact concrete security.
The traditional notions of data privacy (\(\mathrm {IND\text{- }ATK}\)) and anonymity (\(\mathrm {ANO\text{- }ATK}\)) are obtained by adding a restriction to the \({\mathrm {AI\text{- }ATK}}\) game in Fig. 3 so that a  query returns \(\bot \) whenever \( id ^*_0 \ne id ^*_1\) or \(M_0^* \ne M_1^*\), respectively. It is easy to see that \({\mathrm {ai}}\) security is implied by \(\mathrm {ind}\) security and \(\mathrm {ano}\) security, i.e., for each \({\mathrm {{\mathrm {ai}}\text{- }atk}}\) adversary \(A\), there exist an \({\mathrm {ind\text{- }atk}}\) adversary \(B_1\) and an \({\mathrm {\mathrm {ano}\text{- }atk}}\) adversary \(B_2\) such that
query returns \(\bot \) whenever \( id ^*_0 \ne id ^*_1\) or \(M_0^* \ne M_1^*\), respectively. It is easy to see that \({\mathrm {ai}}\) security is implied by \(\mathrm {ind}\) security and \(\mathrm {ano}\) security, i.e., for each \({\mathrm {{\mathrm {ai}}\text{- }atk}}\) adversary \(A\), there exist an \({\mathrm {ind\text{- }atk}}\) adversary \(B_1\) and an \({\mathrm {\mathrm {ano}\text{- }atk}}\) adversary \(B_2\) such that  .
.
Robustness. Associated with general encryption scheme  are games WROB, SROB of Fig. 4. As before, a cpa adversary is one that makes no
are games WROB, SROB of Fig. 4. As before, a cpa adversary is one that makes no  queries, and a cca adversary is one that might make such queries. The wrob and srob advantages of an adversary, in either case, are
queries, and a cca adversary is one that might make such queries. The wrob and srob advantages of an adversary, in either case, are

The difference between WROB and SROB is that in the former the adversary produces a message M, and C is its encryption under the encryption key of one of the given identities, while in the latter it produces C directly and may not obtain it as an honest encryption. It is worth clarifying that in the PKE case the adversary does not get to choose the encryption (public) keys of the identities it is targeting. These are honestly and independently chosen, in real life by the identities themselves and in our formalization by the games.
Relations between notions. Figure 1 shows implications and separations in the style of [13]. We consider each robustness notion in conjunction with the corresponding AI one since robustness is interesting only in this case. The implications are all trivial. The first separation shows that the strongest notion of privacy fails to imply even the weakest type of robustness. The second separation shows that weak robustness, even under \(\mathrm {CCA}\), doesn’t imply strong robustness. We stress that here an implication \(\mathrm {A}\rightarrow \mathrm {B}\) means that any \(\mathrm {A}\)-secure, unaltered, is \(\mathrm {B}\)-secure. Correspondingly, a non-implication \(\mathrm {A}\not \rightarrow \mathrm {B}\) means that there is an \(\mathrm {A}\)-secure that, unaltered, is not \(\mathrm {B}\)-secure. (It doesn’t mean that an \(\mathrm {A}\)-secure scheme can’t be transformed into a \(\mathrm {B}\)-secure one.) Only a minimal set of arrows and barred arrows is shown; others can be inferred. The picture is complete in the sense that it implies either an implication or a separation between any pair of notions.
3 Robustness Failures of Encryption with Redundancy
A natural privacy-and-anonymity-preserving approach to add robustness to an encryption scheme is to add redundancy before encrypting, and upon decryption reject if the redundancy is absent. Here we investigate the effectiveness of this encryption with redundancy approach, justifying the negative results discussed in Sect. 1 and summarized in the first table of Fig. 2.
Redundancy codes and the transform. A redundancy code  is a triple of algorithms. The redundancy key generation algorithm \({\mathsf {RKG}}\) generates a key K. On input K and data x the redundancy computation algorithm \({\mathsf {RC}}\) returns redundancy r. Given K, x, and claimed redundancy r, the deterministic redundancy verification algorithm \({\mathsf {RV}}\) returns 0 or 1. We say that
is a triple of algorithms. The redundancy key generation algorithm \({\mathsf {RKG}}\) generates a key K. On input K and data x the redundancy computation algorithm \({\mathsf {RC}}\) returns redundancy r. Given K, x, and claimed redundancy r, the deterministic redundancy verification algorithm \({\mathsf {RV}}\) returns 0 or 1. We say that  is unkeyed if the key K output by \({\mathsf {RKG}}\) is always equal to \(\varepsilon \), and keyed otherwise. The correctness condition is that for all x we have \({\mathsf {RV}}(K,x,{\mathsf {RC}}(K,x)) = 1\) with probability one, where the probability is taken over the coins of \({\mathsf {RKG}}\) and \({\mathsf {RC}}\). (We stress that the latter is allowed to be randomized.)
is unkeyed if the key K output by \({\mathsf {RKG}}\) is always equal to \(\varepsilon \), and keyed otherwise. The correctness condition is that for all x we have \({\mathsf {RV}}(K,x,{\mathsf {RC}}(K,x)) = 1\) with probability one, where the probability is taken over the coins of \({\mathsf {RKG}}\) and \({\mathsf {RC}}\). (We stress that the latter is allowed to be randomized.)

Examples of redundancy codes, where the data \( x \) is of the form \( ek \Vert M\). The first four are unkeyed and the last two are keyed
Given a general encryption scheme  and a redundancy code
and a redundancy code  , the encryption with redundancy transform associates to them the general encryption scheme
, the encryption with redundancy transform associates to them the general encryption scheme  whose algorithms are shown on the left side of Fig. 6. Note that the transform has the first of our desired properties, namely that it preserves \({\mathrm {AI\text{- }ATK}}\). Also if
whose algorithms are shown on the left side of Fig. 6. Note that the transform has the first of our desired properties, namely that it preserves \({\mathrm {AI\text{- }ATK}}\). Also if  is a PKE scheme then so is
is a PKE scheme then so is  , and if
, and if  is an IBE scheme then so is
is an IBE scheme then so is  , which means the results we obtain here apply to both settings.
, which means the results we obtain here apply to both settings.
Figure 5 shows example redundancy codes for the transform. With the first,  is identical to
is identical to  , so that the counterexample below shows that \(\mathrm {AI\text{- }CCA}\) does not imply \(\mathrm {WROB\text{- }CPA}\) , justifying the first separation of Fig. 1. The second and third rows show redundancy equal to a constant or the encryption key as examples of (unkeyed) redundancy codes. The fourth row shows a code that is randomized but still unkeyed. The hash function H could be a MAC or a collision-resistant function. The last two are keyed redundancy codes, the first the simple one that just always returns the key, and the second using a hash function. Obviously, there are many other examples.
, so that the counterexample below shows that \(\mathrm {AI\text{- }CCA}\) does not imply \(\mathrm {WROB\text{- }CPA}\) , justifying the first separation of Fig. 1. The second and third rows show redundancy equal to a constant or the encryption key as examples of (unkeyed) redundancy codes. The fourth row shows a code that is randomized but still unkeyed. The hash function H could be a MAC or a collision-resistant function. The last two are keyed redundancy codes, the first the simple one that just always returns the key, and the second using a hash function. Obviously, there are many other examples.

Left transformed scheme for the encryption with redundancy paradigm. Top right counterexample for WROB. Bottom right counterexample for SROB
SROB failure. We show that encryption with redundancy fails to provide strong robustness for all redundancy codes, whether keyed or not. More precisely, we show that for any redundancy code  and both \(\mathrm {ATK}\in \{\mathrm {CPA},\mathrm {CCA}\}\), there is an \({\mathrm {AI\text{- }ATK}}\) encryption scheme
and both \(\mathrm {ATK}\in \{\mathrm {CPA},\mathrm {CCA}\}\), there is an \({\mathrm {AI\text{- }ATK}}\) encryption scheme  such that the scheme
such that the scheme  resulting from the encryption-with-redundancy transform applied to
resulting from the encryption-with-redundancy transform applied to  is not \(\mathrm {SROB\text{- }CPA}\). We build
is not \(\mathrm {SROB\text{- }CPA}\). We build  by modifying a given \({\mathrm {AI\text{- }ATK}}\) encryption scheme
by modifying a given \({\mathrm {AI\text{- }ATK}}\) encryption scheme  . Let l be the number of coins used by \({\mathsf {RC}}\), and let \({\mathsf {RC}}(x;\omega )\) denote the result of executing \({\mathsf {RC}}\) on input x with coins \(\omega \in \{0,1\}^{l}\). Let \(M^*\) be a function that given \( pars \) returns a point in the message space associated with \( pars \) in
. Let l be the number of coins used by \({\mathsf {RC}}\), and let \({\mathsf {RC}}(x;\omega )\) denote the result of executing \({\mathsf {RC}}\) on input x with coins \(\omega \in \{0,1\}^{l}\). Let \(M^*\) be a function that given \( pars \) returns a point in the message space associated with \( pars \) in  . Then
. Then  where the new algorithms are shown on the bottom right side of Fig. 6. The reason we used \(0^{l}\) as coins for \({\mathsf {RC}}\) here is that \({\mathsf {Dec}}\) is required to be deterministic.
where the new algorithms are shown on the bottom right side of Fig. 6. The reason we used \(0^{l}\) as coins for \({\mathsf {RC}}\) here is that \({\mathsf {Dec}}\) is required to be deterministic.
Our first claim is that the assumption that  is \({\mathrm {AI\text{- }ATK}}\) implies that
is \({\mathrm {AI\text{- }ATK}}\) implies that  is too. Our second claim, that
is too. Our second claim, that  is not \(\mathrm {SROB\text{- }CPA}\), is demonstrated by the following attack. For a pair \( id _0, id _1\) of distinct identities of its choice, the adversary \(A\), on input \(( pars ,K)\), begins with queries
is not \(\mathrm {SROB\text{- }CPA}\), is demonstrated by the following attack. For a pair \( id _0, id _1\) of distinct identities of its choice, the adversary \(A\), on input \(( pars ,K)\), begins with queries  and
and  . It then creates ciphertext \( C \leftarrow 0{\,\Vert \,}K\) and returns \(( id _0, id _1,C)\). We claim that
. It then creates ciphertext \( C \leftarrow 0{\,\Vert \,}K\) and returns \(( id _0, id _1,C)\). We claim that  . Letting \( dk _0, dk _1\) denote the decryption keys corresponding to \( ek _0, ek _1\), respectively, the reason is the following. For both \(b\in \{0,1\}\), the output of \({\mathsf {Dec}}( pars , ek _b, dk _b, C )\) is \( M ^*( pars ) \Vert r_b( pars )\) where \(r_b( pars )={\mathsf {RC}}(K, ek _b\Vert M ^*( pars );0^{l})\). But the correctness of
. Letting \( dk _0, dk _1\) denote the decryption keys corresponding to \( ek _0, ek _1\), respectively, the reason is the following. For both \(b\in \{0,1\}\), the output of \({\mathsf {Dec}}( pars , ek _b, dk _b, C )\) is \( M ^*( pars ) \Vert r_b( pars )\) where \(r_b( pars )={\mathsf {RC}}(K, ek _b\Vert M ^*( pars );0^{l})\). But the correctness of  implies that \({\mathsf {RV}}(K, ek _b\Vert M ^*( pars ),r_b( pars ))=1\) and hence \(\overline{{\mathsf {Dec}}}(( pars ,K), ek _b, dk _b, C )\) returns \( M ^*( pars )\) rather than \(\bot \).
implies that \({\mathsf {RV}}(K, ek _b\Vert M ^*( pars ),r_b( pars ))=1\) and hence \(\overline{{\mathsf {Dec}}}(( pars ,K), ek _b, dk _b, C )\) returns \( M ^*( pars )\) rather than \(\bot \).
WROB failure. We show that encryption with redundancy fails to provide even weak robustness for all unkeyed redundancy codes. This is still a powerful negative result because many forms of redundancy that might intuitively work, such as the first four of Fig. 5, are included. More precisely, we claim that for any unkeyed redundancy code  and both \(\mathrm {ATK}\in \{\mathrm {CPA},\mathrm {CCA}\}\), there is an \({\mathrm {AI\text{- }ATK}}\) encryption scheme
and both \(\mathrm {ATK}\in \{\mathrm {CPA},\mathrm {CCA}\}\), there is an \({\mathrm {AI\text{- }ATK}}\) encryption scheme  such that the scheme
such that the scheme  resulting from the encryption-with-redundancy transform applied to
resulting from the encryption-with-redundancy transform applied to  and
and  is not \(\mathrm {WROB\text{- }CPA}\). We build
is not \(\mathrm {WROB\text{- }CPA}\). We build  by modifying a given
by modifying a given  encryption scheme
encryption scheme  . With notation as above, the new algorithms for the scheme
. With notation as above, the new algorithms for the scheme  are shown on the top right side of Fig. 6.
are shown on the top right side of Fig. 6.
Our first claim is that the assumption that  is \({\mathrm {AI\text{- }ATK}}\) implies that
is \({\mathrm {AI\text{- }ATK}}\) implies that  is too. Our second claim, that
is too. Our second claim, that  is not \(\mathrm {WROB\text{- }CPA}\), is demonstrated by the following attack. For a pair \( id _0, id _1\) of distinct identities of its choice, the adversary \(A\), on input \(( pars ,\varepsilon )\), makes queries
is not \(\mathrm {WROB\text{- }CPA}\), is demonstrated by the following attack. For a pair \( id _0, id _1\) of distinct identities of its choice, the adversary \(A\), on input \(( pars ,\varepsilon )\), makes queries  and
and  and returns \(( id _0, id _1,M)\), where M can be any message in the message space associated with pars. We claim that
and returns \(( id _0, id _1,M)\), where M can be any message in the message space associated with pars. We claim that  is high. Letting \( dk _1\) denote the decryption key corresponding to \( ek _1\), the reason is the following. Let \(r_0\mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {RC}}(\varepsilon , ek _0\Vert M)\) and \(C\mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {Enc}}( pars , ek _0,M\Vert r_0)\). The assumed \(\mathrm {WROB\text{- }CPA}\) security of
is high. Letting \( dk _1\) denote the decryption key corresponding to \( ek _1\), the reason is the following. Let \(r_0\mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {RC}}(\varepsilon , ek _0\Vert M)\) and \(C\mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {Enc}}( pars , ek _0,M\Vert r_0)\). The assumed \(\mathrm {WROB\text{- }CPA}\) security of  implies that \({\mathsf {Dec}}( pars , ek _1, dk _1, C )\) is most probably \( M ^*( pars ) \Vert r_1( pars )\) where \(r_1( pars )={\mathsf {RC}}(\varepsilon , ek _1\Vert M ^*( pars );0^{l})\). But the correctness of
implies that \({\mathsf {Dec}}( pars , ek _1, dk _1, C )\) is most probably \( M ^*( pars ) \Vert r_1( pars )\) where \(r_1( pars )={\mathsf {RC}}(\varepsilon , ek _1\Vert M ^*( pars );0^{l})\). But the correctness of  implies that \({\mathsf {RV}}(\varepsilon , ek _1\Vert M ^*( pars ),r_1( pars ))=1\) and hence \(\overline{{\mathsf {Dec}}}(( pars ,\varepsilon ), ek _1, dk _1, C )\) returns \( M ^*( pars )\) rather than \(\bot \).
implies that \({\mathsf {RV}}(\varepsilon , ek _1\Vert M ^*( pars ),r_1( pars ))=1\) and hence \(\overline{{\mathsf {Dec}}}(( pars ,\varepsilon ), ek _1, dk _1, C )\) returns \( M ^*( pars )\) rather than \(\bot \).
4 Transforms That Work
We present a transform that confers weak robustness and another that confers strong robustness. They preserve privacy and anonymity, work for PKE as well as IBE, and for \(\mathrm {CPA}\) as well as \(\mathrm {CCA}\). In both cases, the security proofs surface some delicate issues. Besides being useful in its own right, the weak robustness transform is a crucial step in obtaining strong robustness, so we begin there.
Weak robustness transform. We saw that encryption-with-redundancy fails to provide even weak robustness if the redundancy code is unkeyed. Here we show that if the redundancy code is keyed, even in the simplest possible way where the redundancy is just the key itself, the transform does provide weak robustness, turning any \({\mathrm {AI\text{- }ATK}}\) secure general encryption scheme into an \({\mathrm {AI\text{- }ATK}+\mathrm {WROB\text{- }ATK}}\) one, for both \(\mathrm {ATK}\in \{\mathrm {CPA},\mathrm {CCA}\}\).

General encryption scheme  resulting from applying our weak robustness transform to general encryption scheme
resulting from applying our weak robustness transform to general encryption scheme  and integer parameter k
and integer parameter k
The transformed scheme encrypts with the message a key K placed in the public parameters. In more detail, the weak robustness transform associates with a given general encryption scheme  and integer parameter k, representing the length of K, the general encryption scheme
and integer parameter k, representing the length of K, the general encryption scheme  whose algorithms are depicted in Fig. 7. Note that if
whose algorithms are depicted in Fig. 7. Note that if  is a PKE scheme then so is
is a PKE scheme then so is  and if
and if  is an IBE scheme then so is
is an IBE scheme then so is  , so that our results, captured by Theorem 4.1, cover both settings.
, so that our results, captured by Theorem 4.1, cover both settings.
The intuition for the weak robustness of  is that the
is that the  decryption under one key, of an encryption of \(\overline{ M }\Vert K\) created under another key, cannot, by the assumed \({\mathrm {AI\text{- }ATK}}\) security of
decryption under one key, of an encryption of \(\overline{ M }\Vert K\) created under another key, cannot, by the assumed \({\mathrm {AI\text{- }ATK}}\) security of  , reveal K, and hence the check will fail. This is pretty much right for PKE, but the delicate issue is that for IBE, information about K can enter via the identities, which in this case are the encryption keys and could be chosen by the adversary as a function of K. Indeed, the counterexample from Sect. 3 can be extended to work for any keyed redundancy code if the key can be encoded into the identity space. Namely, the adversary can encode the key K into the identity \( id _1 = ek _1\), while the counterexample decryption algorithm could decode K from its input \( ek \) and output \(M\leftarrow M ^*( pars ) \Vert {\mathsf {RC}}(K, ek \Vert M ^*( pars );0^{l})\) as a default message. We show, however, that this can be dealt with by making K sufficiently longer than the identities.
, reveal K, and hence the check will fail. This is pretty much right for PKE, but the delicate issue is that for IBE, information about K can enter via the identities, which in this case are the encryption keys and could be chosen by the adversary as a function of K. Indeed, the counterexample from Sect. 3 can be extended to work for any keyed redundancy code if the key can be encoded into the identity space. Namely, the adversary can encode the key K into the identity \( id _1 = ek _1\), while the counterexample decryption algorithm could decode K from its input \( ek \) and output \(M\leftarrow M ^*( pars ) \Vert {\mathsf {RC}}(K, ek \Vert M ^*( pars );0^{l})\) as a default message. We show, however, that this can be dealt with by making K sufficiently longer than the identities.
Theorem 4.1
Let  be a general encryption scheme with identity space \(\{0,1\}^n\), and let
be a general encryption scheme with identity space \(\{0,1\}^n\), and let  be the general encryption scheme resulting from applying the weak robustness transform to
be the general encryption scheme resulting from applying the weak robustness transform to  and integer parameter k. Then
and integer parameter k. Then
- 1.:
-
 : Let \(A\) be an ai-adversary against
: Let \(A\) be an ai-adversary against 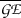 . Then there is an ai-adversary \(B\) against
. Then there is an ai-adversary \(B\) against  such that
such that 
Adversary \(B\) inherits the query profile of \(A\) and has the same running time as \(A\). If \(A\) is a cpa adversary, then so is \(B\).
- 2.:
-
 Let \(A\) be a wrob adversary against
Let \(A\) be a wrob adversary against  with running time t, and let \(\ell =2n+\lceil \log _2(t)\rceil \). Then there is an ai-adversary \(B\) against
with running time t, and let \(\ell =2n+\lceil \log _2(t)\rceil \). Then there is an ai-adversary \(B\) against  such that
such that 
Adversary \(B\) inherits the query profile of \(A\) and has the same running time as \(A\). If \(A\) is a cpa adversary, then so is \(B\).

 : Let
: Let 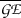 . Then there is an ai-adversary
. Then there is an ai-adversary  such that
such that 
 Let
Let  with running time t, and let
with running time t, and let  such that
such that 

The first part of the theorem implies that if  is \({\mathrm {AI\text{- }ATK}}\) then
is \({\mathrm {AI\text{- }ATK}}\) then  is \({\mathrm {AI\text{- }ATK}}\) as well. The second part of the theorem implies that if
is \({\mathrm {AI\text{- }ATK}}\) as well. The second part of the theorem implies that if  is \({\mathrm {AI\text{- }ATK}}\) and k is chosen sufficiently larger than \(2n+\lceil \log _2(t)\rceil \) then
is \({\mathrm {AI\text{- }ATK}}\) and k is chosen sufficiently larger than \(2n+\lceil \log _2(t)\rceil \) then  is \(\mathrm {WROB\text{- }ATK}\). In both cases, this is for both \(\mathrm {ATK}\in \{\mathrm {CPA},\mathrm {CCA}\}\). The theorem says it directly for \(\mathrm {CCA}\), and for \(\mathrm {CPA}\) by the fact that if \(A\) is a cpa adversary then so is \(B\). When we say that \(B\) inherits the query profile of \(A\) we mean that for every oracle that \(B\) has, if \(A\) has an oracle of the same name and makes q queries to it, then this is also the number \(B\) makes.
is \(\mathrm {WROB\text{- }ATK}\). In both cases, this is for both \(\mathrm {ATK}\in \{\mathrm {CPA},\mathrm {CCA}\}\). The theorem says it directly for \(\mathrm {CCA}\), and for \(\mathrm {CPA}\) by the fact that if \(A\) is a cpa adversary then so is \(B\). When we say that \(B\) inherits the query profile of \(A\) we mean that for every oracle that \(B\) has, if \(A\) has an oracle of the same name and makes q queries to it, then this is also the number \(B\) makes.
Proof of Theorem 4.1
The proof of Part 1 of Theorem 4.1 is straightforward and is omitted. The proof of Part 2 of Theorem 4.1 relies on the following information-theoretic lemma.
Lemma 4.2
Let \(\ell \le k\) be positive integers and let \(A_1,A_2\) be arbitrary algorithms with the length of the output of \(A_1\) always being \(\ell \). Let P denote the probability that \(A_2(A_1(K))=K\) where the probability is over K drawn at random from \(\{0,1\}^k\) and the coins of \(A_1,A_2\). Then \(P\le 2^{\ell -k}\).
Proof of Lemma 4.2
We may assume \(A_1,A_2\) are deterministic for, if not, we can hardwire a “best” choice of coins for each. For each \(\ell \)-bit string L let \(S_L =\{K \in \{0,1\}^k \,:\, A_1(K)=L\}\) and let \(s(L) = |S_L|\). Let \(\mathcal{L}\) be the set of all \(L\in \{0,1\}^{\ell }\) such that \(s(L)>0\). Then
which is at most \(2^{\ell -k}\) as claimed. 

Games for the proof of Part 2 of Theorem 4.1
Proof of Part 2 of Theorem 4.1
Games  of Fig. 8 differ only in their \(\mathbf{Finalize }\) procedures, with the message encrypted at line 04 to create ciphertext C in \(G_1\) being a constant rather than \(\overline{ M }_0\) in
of Fig. 8 differ only in their \(\mathbf{Finalize }\) procedures, with the message encrypted at line 04 to create ciphertext C in \(G_1\) being a constant rather than \(\overline{ M }_0\) in  . We have
. We have

we design \(B\) so that

On input \( pars \), adversary \(B\) executes lines 02,03 of \(\mathbf{Initialize }\) and runs \(A\) on input \(( pars ,K)\). It replies to  and
and  queries of \(A\) via its own oracles of the same name. When \(A\) halts with output \(M, id _0, id _1\), adversary \(B\) queries its
queries of \(A\) via its own oracles of the same name. When \(A\) halts with output \(M, id _0, id _1\), adversary \(B\) queries its  oracle with \( id _0, id _0,0^{|M|}\Vert 0^k, M\Vert K\) to get back a ciphertext C. It then makes query
oracle with \( id _0, id _0,0^{|M|}\Vert 0^k, M\Vert K\) to get back a ciphertext C. It then makes query  to get back \(\mathsf {DK}[ id _1]\). Note this is a legal query for \(B\) because \( id _1\) is not one of the challenge identities in its
to get back \(\mathsf {DK}[ id _1]\). Note this is a legal query for \(B\) because \( id _1\) is not one of the challenge identities in its  query, but it would not have been legal for \(A\). Now \(B\) executes lines 01–09 of the code of \(\mathbf{Finalize }\) of
query, but it would not have been legal for \(A\). Now \(B\) executes lines 01–09 of the code of \(\mathbf{Finalize }\) of  , except that it sets the value \( C \) on line 04 to be its own challenge ciphertext. If \(\overline{ M }_1\ne \bot \) it outputs 1, else 0.
, except that it sets the value \( C \) on line 04 to be its own challenge ciphertext. If \(\overline{ M }_1\ne \bot \) it outputs 1, else 0.
To complete the proof, we show that  . We observe that M as computed at line 05 of \(\mathbf{Finalize }\) in
. We observe that M as computed at line 05 of \(\mathbf{Finalize }\) in  depends only on \( pars ,\mathsf {EK}[ id _1],\mathsf {EK}[ id _0], \mathsf {DK}[ id _1], |\overline{ M }_0|,k\). We would have liked to say that none of these depend on K. This would mean that the probability that \(M\ne \bot \) and parses as \(\overline{ M }_1\Vert K\) is at most \(2^{-k}\), making
depends only on \( pars ,\mathsf {EK}[ id _1],\mathsf {EK}[ id _0], \mathsf {DK}[ id _1], |\overline{ M }_0|,k\). We would have liked to say that none of these depend on K. This would mean that the probability that \(M\ne \bot \) and parses as \(\overline{ M }_1\Vert K\) is at most \(2^{-k}\), making  . In the PKE case, what we desire is almost true because the only item in our list that can depend on K is \(|\overline{ M }_0|\), which can carry at most \(\log _2(t)\) bits of information about K. But \( id _0, id _1\) could depend on K so in general, and in the IBE case in particular, \(\mathsf {EK}[ id _0],\mathsf {EK}[ id _1], \mathsf {DK}[ id _1]\) could depend on K. However, we assumed that identities are n bits, so the total amount of information about K in the list \( pars , \mathsf {EK}[ id _1],\mathsf {EK}[ id _0],\mathsf {DK}[ id _1], |M_0|,k\) is at most \(2n+ \log _2(t)\) bits. We conclude by applying Lemma 4.2 with \(\ell =2n+\lceil \log _2(t)\rceil \).
. In the PKE case, what we desire is almost true because the only item in our list that can depend on K is \(|\overline{ M }_0|\), which can carry at most \(\log _2(t)\) bits of information about K. But \( id _0, id _1\) could depend on K so in general, and in the IBE case in particular, \(\mathsf {EK}[ id _0],\mathsf {EK}[ id _1], \mathsf {DK}[ id _1]\) could depend on K. However, we assumed that identities are n bits, so the total amount of information about K in the list \( pars , \mathsf {EK}[ id _1],\mathsf {EK}[ id _0],\mathsf {DK}[ id _1], |M_0|,k\) is at most \(2n+ \log _2(t)\) bits. We conclude by applying Lemma 4.2 with \(\ell =2n+\lceil \log _2(t)\rceil \). 
Arbitrary identities. Theorem 4.1 converts a scheme  with identity space \(\{0,1\}^n\) into a scheme
with identity space \(\{0,1\}^n\) into a scheme  with the same identity space \(\{0,1\}^n\). The condition that
with the same identity space \(\{0,1\}^n\). The condition that  has identity space \(\{0,1\}^n\) is not really a restriction, because any scheme with identity space \(\{0,1\}^*\) can be easily converted by restricting the identities to n-bit strings. At the same time, by hashing the identities with a collision-resistant hash function,
has identity space \(\{0,1\}^n\) is not really a restriction, because any scheme with identity space \(\{0,1\}^*\) can be easily converted by restricting the identities to n-bit strings. At the same time, by hashing the identities with a collision-resistant hash function,  can be made to handle arbitrary identities in \(\{0,1\}^*\). It is well known that collision-resistant hashing of identities preserves \({\mathrm {AI\text{- }ATK}}\) [6] and it’s also easy to see that it preserves \(\mathrm {WROB\text{- }ATK}\). Here, it is important that the transformed scheme calls the underlying encryption and decryption algorithms \({\mathsf {Enc}}\) and \({\mathsf {Dec}}\) of
can be made to handle arbitrary identities in \(\{0,1\}^*\). It is well known that collision-resistant hashing of identities preserves \({\mathrm {AI\text{- }ATK}}\) [6] and it’s also easy to see that it preserves \(\mathrm {WROB\text{- }ATK}\). Here, it is important that the transformed scheme calls the underlying encryption and decryption algorithms \({\mathsf {Enc}}\) and \({\mathsf {Dec}}\) of  with the hashed identities, not the full identities. In practice we might hash with SHA256 so that \(n=256\), and, assuming \(t\le 2^{128}\), setting \(k=768\) would make \(2^{\ell -k}=2^{-128}\).
with the hashed identities, not the full identities. In practice we might hash with SHA256 so that \(n=256\), and, assuming \(t\le 2^{128}\), setting \(k=768\) would make \(2^{\ell -k}=2^{-128}\).
Commitment schemes. Our strong robustness transform will use commitments. A commitment scheme is a 3-tuple  . The parameter generation algorithm \({\mathsf {CPG}}\) returns public parameters \( cpars \). The committal algorithm
. The parameter generation algorithm \({\mathsf {CPG}}\) returns public parameters \( cpars \). The committal algorithm  takes \( cpars \) and data \( x \) as input and returns a commitment \( com \) to \( x \) along with a decommittal key \( dec \). The deterministic verification algorithm \({\mathsf {Ver}}\) takes \( cpars , x , com , dec \) as input and returns 1 to indicate that accepts or 0 to indicate that it rejects. Correctness requires that, for any \( x \in \{0,1\}^*\), any \( cpars \in [{\mathsf {CPG}}]\), and any
takes \( cpars \) and data \( x \) as input and returns a commitment \( com \) to \( x \) along with a decommittal key \( dec \). The deterministic verification algorithm \({\mathsf {Ver}}\) takes \( cpars , x , com , dec \) as input and returns 1 to indicate that accepts or 0 to indicate that it rejects. Correctness requires that, for any \( x \in \{0,1\}^*\), any \( cpars \in [{\mathsf {CPG}}]\), and any  , we have that \({\mathsf {Ver}}( cpars , x , com , dec ) = 1\) with probability one, where the probability is taken over the coins of
, we have that \({\mathsf {Ver}}( cpars , x , com , dec ) = 1\) with probability one, where the probability is taken over the coins of  . We require the scheme to have the uniqueness property, which means that for any \( x \in \{0,1\}^*\), any \( cpars \in [{\mathsf {CPG}}]\), and any
. We require the scheme to have the uniqueness property, which means that for any \( x \in \{0,1\}^*\), any \( cpars \in [{\mathsf {CPG}}]\), and any  it is the case that \({\mathsf {Ver}}( cpars , x , com ^*, dec )=0\) for all \( com ^*\ne com \). In most schemes, the decommittal key is the randomness used by the committal algorithm and verification is by re-applying the committal function, which ensures uniqueness. The advantage measures
it is the case that \({\mathsf {Ver}}( cpars , x , com ^*, dec )=0\) for all \( com ^*\ne com \). In most schemes, the decommittal key is the randomness used by the committal algorithm and verification is by re-applying the committal function, which ensures uniqueness. The advantage measures

which refer to the games of Fig. 9, capture, respectively, the standard hiding and binding properties of a commitment scheme. We refer to the corresponding notions as \(\mathrm {HIDE}\) and \(\mathrm {BIND}\). We refer to the corresponding notions as \(\mathrm {HIDE}\) and \(\mathrm {BIND}\).

Game  (left) captures the hiding property, while Game
(left) captures the hiding property, while Game  (right) captures the binding property. The adversary may call
(right) captures the binding property. The adversary may call  only once
only once
The strong robustness transform. The idea is for the ciphertext to include a commitment to the encryption key. The commitment is not encrypted, but the decommittal key is. In detail, given a general encryption scheme  and a commitment scheme
and a commitment scheme  the strong robustness transform associates with them the general encryption scheme
the strong robustness transform associates with them the general encryption scheme  whose algorithms are depicted in Fig. 10. Note that if
whose algorithms are depicted in Fig. 10. Note that if  is a PKE scheme then so is
is a PKE scheme then so is  and if
and if  is an IBE scheme then so is
is an IBE scheme then so is  , so that our results, captured by the Theorem 4.3, cover both settings.
, so that our results, captured by the Theorem 4.3, cover both settings.

General encryption scheme  resulting from applying our strong robustness transform to general encryption scheme
resulting from applying our strong robustness transform to general encryption scheme  and commitment scheme
and commitment scheme 
In this case the delicate issue is not the robustness but the \({\mathrm {AI\text{- }ATK}}\) security of  in the \(\mathrm {CCA}\) case. Intuitively, the hiding security of the commitment scheme means that a
in the \(\mathrm {CCA}\) case. Intuitively, the hiding security of the commitment scheme means that a  ciphertext does not reveal the encryption key. As a result, we would expect \({\mathrm {AI\text{- }ATK}}\) security of
ciphertext does not reveal the encryption key. As a result, we would expect \({\mathrm {AI\text{- }ATK}}\) security of  to follow from the commitment hiding security and the assumed \({\mathrm {AI\text{- }ATK}}\) security of
to follow from the commitment hiding security and the assumed \({\mathrm {AI\text{- }ATK}}\) security of  . This turns out not to be true, and demonstrably so, meaning that there is a counterexample to this claim. (See below.) What we show is that the claim is true if
. This turns out not to be true, and demonstrably so, meaning that there is a counterexample to this claim. (See below.) What we show is that the claim is true if  is additionally \(\mathrm {WROB\text{- }ATK}\). This property, if not already present, can be conferred by first applying our weak robustness transform.
is additionally \(\mathrm {WROB\text{- }ATK}\). This property, if not already present, can be conferred by first applying our weak robustness transform.
Theorem 4.3
Let  be a general encryption scheme, and let
be a general encryption scheme, and let  be the general encryption scheme resulting from applying the strong robustness transform to
be the general encryption scheme resulting from applying the strong robustness transform to  and commitment scheme
and commitment scheme  . Then
. Then
- 1.:
-
\({\underline{\mathrm {AI\text{- }ATK}:}}\) Let \(A\) be an ai-adversary against
 . Then there is a wrob adversary \(W\) against
. Then there is a wrob adversary \(W\) against  , a hiding adversary \(H\) against
, a hiding adversary \(H\) against  and an ai-adversary \(B\) against
and an ai-adversary \(B\) against  such that
such that 
Adversaries \(W,B\) inherit the query profile of \(A\), and adversaries \(W,H,B\) have the same running time as \(A\). If \(A\) is a cpa adversary then so are \(W,B\).
- 2.:
-
\(\underline{\mathrm {SROB\text{- }ATK}:}\) Let \(A\) be a srob adversary against
 making q
making q  queries. Then there is a binding adversary \(B\) against
queries. Then there is a binding adversary \(B\) against  such that
such that 
Adversary \(B\) has the same running time as \(A\).

 . Then there is a wrob adversary
. Then there is a wrob adversary  , a hiding adversary
, a hiding adversary  and an ai-adversary
and an ai-adversary  such that
such that 
 making q
making q  queries. Then there is a binding adversary
queries. Then there is a binding adversary  such that
such that 

The first part of the theorem implies that if  is \({\mathrm {AI\text{- }ATK}}\) and \(\mathrm {WROB\text{- }ATK}\) and
is \({\mathrm {AI\text{- }ATK}}\) and \(\mathrm {WROB\text{- }ATK}\) and  is \(\mathrm {HIDE}\) then
is \(\mathrm {HIDE}\) then  is \({\mathrm {AI\text{- }ATK}}\), and the second part of the theorem implies that if
is \({\mathrm {AI\text{- }ATK}}\), and the second part of the theorem implies that if  is \(\mathrm {BIND}\) secure and
is \(\mathrm {BIND}\) secure and  has low encryption key collision probability then
has low encryption key collision probability then  is \(\mathrm {SROB\text{- }ATK}\). In both cases, this is for both \(\mathrm {ATK}\in \{\mathrm {CPA},\mathrm {CCA}\}\). We remark that the proof shows that in the \(\mathrm {CPA}\) case the \(\mathrm {WROB\text{- }ATK}\) assumption on
is \(\mathrm {SROB\text{- }ATK}\). In both cases, this is for both \(\mathrm {ATK}\in \{\mathrm {CPA},\mathrm {CCA}\}\). We remark that the proof shows that in the \(\mathrm {CPA}\) case the \(\mathrm {WROB\text{- }ATK}\) assumption on  in the first part is actually not needed. The encryption key collision probability
in the first part is actually not needed. The encryption key collision probability  of
of  is defined as the maximum probability that \( ek _0= ek _1\) in the experiment
is defined as the maximum probability that \( ek _0= ek _1\) in the experiment
where the maximum is over all distinct identities \( id _0, id _1\). It is easy to see that  being \(\mathrm {AI}\) implies
being \(\mathrm {AI}\) implies  is negligible, so asking for low encryption key collision probability is in fact not an extra assumption. (For a general encryption scheme, the adversary needs to have hardwired the identities that achieve the maximum, but this is not necessary for PKE because here the probability being maximized is the same for all pairs of distinct identities.) The reason we made the encryption key collision probability explicit is that for most schemes it is unconditionally low. For example, when
is negligible, so asking for low encryption key collision probability is in fact not an extra assumption. (For a general encryption scheme, the adversary needs to have hardwired the identities that achieve the maximum, but this is not necessary for PKE because here the probability being maximized is the same for all pairs of distinct identities.) The reason we made the encryption key collision probability explicit is that for most schemes it is unconditionally low. For example, when  is the ElGamal PKE scheme, it is \(1/|\mathbb {G}|\) where \(\mathbb {G}\) is the group being used.
is the ElGamal PKE scheme, it is \(1/|\mathbb {G}|\) where \(\mathbb {G}\) is the group being used.
Proof of Part 1 of Theorem 4.3
Game  of Fig. 11 is game
of Fig. 11 is game  tailored to the case that \(A\) makes only one
tailored to the case that \(A\) makes only one  query, an assumption we explained we can make. If we wish to exploit the assumed \({\mathrm {AI\text{- }ATK}}\) security of
query, an assumption we explained we can make. If we wish to exploit the assumed \({\mathrm {AI\text{- }ATK}}\) security of  , we need to be able to answer
, we need to be able to answer  queries of \(A\) using the
queries of \(A\) using the  oracle in game
oracle in game  . Thus, we would like to substitute the \({\mathsf {Dec}}( pars ,\mathsf {EK}[ id ],\mathsf {DK}[ id ],C)\) call in a
. Thus, we would like to substitute the \({\mathsf {Dec}}( pars ,\mathsf {EK}[ id ],\mathsf {DK}[ id ],C)\) call in a  query of
query of  with a
with a  call of an adversary \(B\) in
call of an adversary \(B\) in  . The difficulty is that C might equal \(C^*\) but \( com \ne com ^*\), so that the call is not legal for \(B\). To get around this, the first part of our proof will show that the decryption procedure of
. The difficulty is that C might equal \(C^*\) but \( com \ne com ^*\), so that the call is not legal for \(B\). To get around this, the first part of our proof will show that the decryption procedure of  can be replaced by the alternative one of
can be replaced by the alternative one of  , where this difficulty vanishes. This part exploits the uniqueness of the commitment scheme and the weak robustness of
, where this difficulty vanishes. This part exploits the uniqueness of the commitment scheme and the weak robustness of  . After that we will exploit the \({\mathrm {AI\text{- }ATK}}\) security of
. After that we will exploit the \({\mathrm {AI\text{- }ATK}}\) security of  to remove dependence on \( dec ^*\) in
to remove dependence on \( dec ^*\) in  , allowing us to exploit the \(\mathrm {HIDE}\) security of
, allowing us to exploit the \(\mathrm {HIDE}\) security of  to make the challenge commitment independent of \(\mathsf {EK}[ id _b^*]\). This allows us to conclude by again using the \({\mathrm {AI\text{- }ATK}}\) security of
to make the challenge commitment independent of \(\mathsf {EK}[ id _b^*]\). This allows us to conclude by again using the \({\mathrm {AI\text{- }ATK}}\) security of  . We proceed to the details.
. We proceed to the details.

Games for the proof of Part 1 of Theorem 4.3
In game  , if \(A\) makes a
, if \(A\) makes a  query with \( com \ne com ^*\) then the uniqueness of
query with \( com \ne com ^*\) then the uniqueness of  implies that the procedure in question will return \(\bot \). This means that line 02 of
implies that the procedure in question will return \(\bot \). This means that line 02 of  in
in  can be rewritten as line 02 of
can be rewritten as line 02 of  in
in  and the two procedures are equivalent. Procedure
and the two procedures are equivalent. Procedure  of
of  includes the boxed code and hence is equivalent to procedure
includes the boxed code and hence is equivalent to procedure  of
of  . Hence
. Hence

The inequality above is by Lemma 2.1 which applies because  are identical until \(\mathsf {bad}\). We design \(W\) so that
are identical until \(\mathsf {bad}\). We design \(W\) so that

On input \( pars \), adversary \(W\) executes lines 02,03,04,05 of \(\mathbf{Initialize }\) and runs \(A\) on input \(( pars , cpars )\). It replies to  queries of \(A\) via its own oracles of the same name, as per the code of
queries of \(A\) via its own oracles of the same name, as per the code of  . When \(A\) makes its
. When \(A\) makes its  query \( id ^*_0, id ^*_1, \overline{ M }^*_0, \overline{ M }^*_1\), adversary \(W\) executes lines 01,02,03 of the code of
query \( id ^*_0, id ^*_1, \overline{ M }^*_0, \overline{ M }^*_1\), adversary \(W\) executes lines 01,02,03 of the code of  of
of  . It then outputs \(\overline{ M }^*_b\Vert dec ^*, id _b^*, id _{1-b}^*\) and halts.
. It then outputs \(\overline{ M }^*_b\Vert dec ^*, id _b^*, id _{1-b}^*\) and halts.
Next we bound  . Procedure
. Procedure  of
of  results from simplifying the code of procedure
results from simplifying the code of procedure  of
of  , so
, so

The step from  to
to  modifies only
modifies only  , replacing \( dec ^*\) with a constant. We are assuming here that any decommitment key output by
, replacing \( dec ^*\) with a constant. We are assuming here that any decommitment key output by  , regardless of the inputs to the latter, has length d bits. We design \(B_1\) so that
, regardless of the inputs to the latter, has length d bits. We design \(B_1\) so that

On input \( pars \), adversary \(B_1\) executes lines 02,03,04,05 of \(\mathbf{Initialize }\) and runs \(A\) on input \(( pars , cpars )\). It replies to  queries of \(A\) via its own oracles of the same name, as per the code of
queries of \(A\) via its own oracles of the same name, as per the code of  . Here we make crucial use of the fact that the alternative decryption rule of
. Here we make crucial use of the fact that the alternative decryption rule of  of
of  allows \(B_1\) to respond to
allows \(B_1\) to respond to  queries of \(A\) without the need to query its own
queries of \(A\) without the need to query its own  oracle on \((C^*, id _0^*)\) or \((C^*, id _1^*)\). When \(A\) makes its
oracle on \((C^*, id _0^*)\) or \((C^*, id _1^*)\). When \(A\) makes its  query \( id ^*_0, id ^*_1, \overline{ M }^*_0, \overline{ M }^*_1\), adversary \(B_1\) executes lines 01,02,03 of the code of
query \( id ^*_0, id ^*_1, \overline{ M }^*_0, \overline{ M }^*_1\), adversary \(B_1\) executes lines 01,02,03 of the code of  of
of  . It then queries \( id _b^*, id _b^*,\overline{ M }_b^*\Vert 0^d,\overline{ M }^*_b\Vert dec ^*\) to its own
. It then queries \( id _b^*, id _b^*,\overline{ M }_b^*\Vert 0^d,\overline{ M }^*_b\Vert dec ^*\) to its own  oracle to get back a ciphertext \(C^*\), and returns \((C^*, com ^*)\) to \(A\). When \(A\) halts with output a bit \(b'\), adversary \(B_1\) outputs 1 if \(b=b'\) and 0 otherwise.
oracle to get back a ciphertext \(C^*\), and returns \((C^*, com ^*)\) to \(A\). When \(A\) halts with output a bit \(b'\), adversary \(B_1\) outputs 1 if \(b=b'\) and 0 otherwise.
Next we bound  . Procedure
. Procedure  of
of  uses a constant \(0^e\) rather than \(\mathsf {EK}[ id _b^*]\) as data for
uses a constant \(0^e\) rather than \(\mathsf {EK}[ id _b^*]\) as data for  at line 03. The value of e is arbitrary, and we can just let \(e=1\). Then
at line 03. The value of e is arbitrary, and we can just let \(e=1\). Then

We design \(H\) so that

On input \( cpars \), adversary \(H\) executes lines 01,03,04,05 of \(\mathbf{Initialize }\) and runs \(A\) on input \(( pars , cpars )\). It replies to  queries of \(A\) by direct execution of the code of these procedures in
queries of \(A\) by direct execution of the code of these procedures in  , possible since it knows \( msk \). When \(A\) makes its
, possible since it knows \( msk \). When \(A\) makes its  query \( id ^*_0, id ^*_1, \overline{ M }^*_0, \overline{ M }^*_1\), adversary \(H\) executes lines 01,02 of the code of
query \( id ^*_0, id ^*_1, \overline{ M }^*_0, \overline{ M }^*_1\), adversary \(H\) executes lines 01,02 of the code of  of
of  . It then queries \(0^e,\mathsf {EK}[ id _b^*]\) to its own
. It then queries \(0^e,\mathsf {EK}[ id _b^*]\) to its own  oracle to get back a commitment \( com ^*\). It executes line 04 of
oracle to get back a commitment \( com ^*\). It executes line 04 of  of
of  and returns \((C^*, com ^*)\) to \(A\). When \(A\) halts with output a bit \(b'\), adversary \(H\) returns 1 if \(b=b'\) and 0 otherwise.
and returns \((C^*, com ^*)\) to \(A\). When \(A\) halts with output a bit \(b'\), adversary \(H\) returns 1 if \(b=b'\) and 0 otherwise.
Finally we design \(B_2\) so that

On input \( pars \), adversary \(B_2\) executes lines 02,04,05 of \(\mathbf{Initialize }\) and runs \(A\) on input \(( pars , cpars )\). It replies to  queries of \(A\) via its own oracles of the same name, as per the code of
queries of \(A\) via its own oracles of the same name, as per the code of  . Again we make crucial use of the fact that the alternative decryption rule of
. Again we make crucial use of the fact that the alternative decryption rule of  of
of  allows \(B_2\) to respond to
allows \(B_2\) to respond to  queries of \(A\) without the need to query its own
queries of \(A\) without the need to query its own  oracle on \((C^*, id _0^*)\) or \((C^*, id _1^*)\). When \(A\) makes its
oracle on \((C^*, id _0^*)\) or \((C^*, id _1^*)\). When \(A\) makes its  query \( id ^*_0, id ^*_1, \overline{ M }^*_0, \overline{ M }^*_1\), adversary \(B_2\) executes lines 01,02,03 of the code of
query \( id ^*_0, id ^*_1, \overline{ M }^*_0, \overline{ M }^*_1\), adversary \(B_2\) executes lines 01,02,03 of the code of  of
of  . It then queries \( id _0^*, id _1^*,\overline{ M }_0^*\Vert 0^d,\overline{ M }^*_1\Vert dec ^*\) to its own
. It then queries \( id _0^*, id _1^*,\overline{ M }_0^*\Vert 0^d,\overline{ M }^*_1\Vert dec ^*\) to its own  oracle to get back a ciphertext \(C^*\), and returns \((C^*, com ^*)\) to \(A\). When \(A\) halts with output a bit \(b'\), adversary \(B_2\) outputs \(b'\).
oracle to get back a ciphertext \(C^*\), and returns \((C^*, com ^*)\) to \(A\). When \(A\) halts with output a bit \(b'\), adversary \(B_2\) outputs \(b'\).
Adversary \(B\) of the theorem statement runs \(B_1\) with probability 2 / 3 and \(B_2\) with probability 1 / 3. 
Proof of Part 2 of Theorem 4.3
In the execution of \(A\) with game  let \({\textsc {coll}}\) be the event that there exist distinct \( id _0, id _1\) queried by \(A\) to its
let \({\textsc {coll}}\) be the event that there exist distinct \( id _0, id _1\) queried by \(A\) to its  oracle such that the encryption keys returned in response are the same. Then
oracle such that the encryption keys returned in response are the same. Then

But

and we can design \(B\) such that

We omit the details. 
The need for weak robustness. As we said above, the \({\mathrm {AI\text{- }ATK}}\) security of  won’t be implied merely by that of
won’t be implied merely by that of  . (We had to additionally assume that
. (We had to additionally assume that  is \(\mathrm {WROB\text{- }ATK}\)). Here we justify this somewhat counterintuitive claim. This discussion is informal but can be turned into a formal counterexample. Imagine that the decryption algorithm of
is \(\mathrm {WROB\text{- }ATK}\)). Here we justify this somewhat counterintuitive claim. This discussion is informal but can be turned into a formal counterexample. Imagine that the decryption algorithm of  returns a fixed string of the form \((\hat{ M },\hat{ dec })\) whenever the wrong key is used to decrypt. Moreover, imagine
returns a fixed string of the form \((\hat{ M },\hat{ dec })\) whenever the wrong key is used to decrypt. Moreover, imagine  is such that it is easy, given \( cpars , x , dec \), to find \( com \) so that \({\mathsf {Ver}}( cpars , x , com , dec )=1\). (This is true for any commitment scheme where \( dec \) is the coins used by the
is such that it is easy, given \( cpars , x , dec \), to find \( com \) so that \({\mathsf {Ver}}( cpars , x , com , dec )=1\). (This is true for any commitment scheme where \( dec \) is the coins used by the  algorithm.) Consider then the \({\mathrm {AI\text{- }ATK}}\) adversary \(A\) against the transformed scheme that that receives a challenge ciphertext \((C^*, com ^*)\) where \(C^*\leftarrow {\mathsf {Enc}}( pars ,\mathsf {EK}[ id _b], M ^*\Vert dec ^*)\) for hidden bit \(b \in \{0,1\}\). It then creates a commitment \(\hat{ com }\) of \(\mathsf {EK}[ id _1]\) with opening information \(\hat{ dec }\), and queries \((C^*,\hat{ com })\) to be decrypted under \(\mathsf {DK}[id_0]\). If \(b=0\) this query will probably return \(\bot \) because \({\mathsf {Ver}}( cpars ,\mathsf {EK}[ id _0],\hat{ com }, dec ^*)\) is unlikely to be 1, but if \(b=1\) it returns \(\hat{ M }\), allowing \(A\) to determine the value of b. The weak robustness of
algorithm.) Consider then the \({\mathrm {AI\text{- }ATK}}\) adversary \(A\) against the transformed scheme that that receives a challenge ciphertext \((C^*, com ^*)\) where \(C^*\leftarrow {\mathsf {Enc}}( pars ,\mathsf {EK}[ id _b], M ^*\Vert dec ^*)\) for hidden bit \(b \in \{0,1\}\). It then creates a commitment \(\hat{ com }\) of \(\mathsf {EK}[ id _1]\) with opening information \(\hat{ dec }\), and queries \((C^*,\hat{ com })\) to be decrypted under \(\mathsf {DK}[id_0]\). If \(b=0\) this query will probably return \(\bot \) because \({\mathsf {Ver}}( cpars ,\mathsf {EK}[ id _0],\hat{ com }, dec ^*)\) is unlikely to be 1, but if \(b=1\) it returns \(\hat{ M }\), allowing \(A\) to determine the value of b. The weak robustness of  rules out such anomalies.
rules out such anomalies.
5 A \(\mathrm {SROB\text{- }CCA}\) Version of Cramer–Shoup
Let \(\mathbb {G}\) be a group of prime order p, and \(H{:\;\;}\mathsf {Keys}(H) \times \mathbb {G}^3 \rightarrow \mathbb {G}\) a family of functions. We assume \(\mathbb {G},p,H\) are fixed and known to all parties. Figure 12 shows the Cramer–Shoup (CS) scheme and the variant  scheme where \(\mathbf {1}\) denotes the identity element of \(\mathbb {G}\). The differences are boxed. Recall that the CS scheme was shown to be \(\mathrm {IND\text{- }CCA}\) in [27] and \(\mathrm {ANO\text{- }CCA}\) in [7]. However, for any message \( M \in \mathbb {G}\) the ciphertext \((\mathbf {1},\mathbf {1}, M , \mathbf {1})\) in the CS scheme decrypts to \( M \) under any \( pars , pk ,\) and \( sk \), meaning in particular that the scheme is not even \(\mathrm {SROB\text{- }CPA}\). The modified scheme
scheme where \(\mathbf {1}\) denotes the identity element of \(\mathbb {G}\). The differences are boxed. Recall that the CS scheme was shown to be \(\mathrm {IND\text{- }CCA}\) in [27] and \(\mathrm {ANO\text{- }CCA}\) in [7]. However, for any message \( M \in \mathbb {G}\) the ciphertext \((\mathbf {1},\mathbf {1}, M , \mathbf {1})\) in the CS scheme decrypts to \( M \) under any \( pars , pk ,\) and \( sk \), meaning in particular that the scheme is not even \(\mathrm {SROB\text{- }CPA}\). The modified scheme  —which continues to be \(\mathrm {IND\text{- }CCA}\) and \(\mathrm {ANO\text{- }CCA}\)— removes this pathological case by having \({\mathsf {Enc}}\) choose the randomness u to be nonzero —\({\mathsf {Enc}}\) draws u from \({{\mathbb Z}}_p^*\) while the CS scheme draws it from \({{\mathbb Z}}_p\)— and then having \({\mathsf {Dec}}\) reject \((a_1,a_2,c,d)\) if \(a_1 = \mathbf {1}\). This thwarts the attack, but is there any other attack? We show that there is not by proving that
—which continues to be \(\mathrm {IND\text{- }CCA}\) and \(\mathrm {ANO\text{- }CCA}\)— removes this pathological case by having \({\mathsf {Enc}}\) choose the randomness u to be nonzero —\({\mathsf {Enc}}\) draws u from \({{\mathbb Z}}_p^*\) while the CS scheme draws it from \({{\mathbb Z}}_p\)— and then having \({\mathsf {Dec}}\) reject \((a_1,a_2,c,d)\) if \(a_1 = \mathbf {1}\). This thwarts the attack, but is there any other attack? We show that there is not by proving that  is actually \(\mathrm {SROB\text{- }CCA}\). Our proof of robustness relies only on the security—specifically, pre-image resistance—of the hash family \(H\): it does not make the DDH assumption. Our proof uses ideas from the information-theoretic part of the proof of [27].
is actually \(\mathrm {SROB\text{- }CCA}\). Our proof of robustness relies only on the security—specifically, pre-image resistance—of the hash family \(H\): it does not make the DDH assumption. Our proof uses ideas from the information-theoretic part of the proof of [27].

Original CS scheme [27] does not contain the boxed code, while the variant  does. Although not shown above, the decryption algorithm in both versions always checks to ensure that the ciphertext \(C \in \mathbb {G}^4\). The message space is \(\mathbb {G}\)
does. Although not shown above, the decryption algorithm in both versions always checks to ensure that the ciphertext \(C \in \mathbb {G}^4\). The message space is \(\mathbb {G}\)
We say that a family \(H{:\;\;}\mathsf {Keys}(H) \times \mathsf {Dom}(H) \rightarrow \mathsf {Rng}(H)\) of functions is pre-image resistant if, given a key K and a random range element \(v^*\), it is computationally infeasible to find a pre-image of \(v^*\) under \(H(K,\cdot )\). The notion is captured formally by the following advantage measure for an adversary \(I\):
Pre-image resistance is not implied by the standard notion of one-wayness, since in the latter the target \(v^*\) is the image under \(H(K,\cdot )\) of a random domain point, which may not be a random range point. However, it seems like a fairly mild assumption on a practical cryptographic hash function and is implied by the notion of “everywhere pre-image resistance” of [46], the difference being that, for the latter, the advantage is the maximum probability over all \(v^* \in \mathsf {Rng}(H)\). We now claim the following.
Theorem 5.1
Let \(B\) be an adversary making two  queries, no
queries, no  queries and at most \(q-1\)
queries and at most \(q-1\)  queries, and having running time t. Then, we can construct an adversary \(I\) such that
queries, and having running time t. Then, we can construct an adversary \(I\) such that

Furthermore, the running time of \(I\) is \(t+q\cdot O(t_{\mathrm {exp}})\) where \(t_{\mathrm {exp}}\) denotes the time for one exponentiation in \(\mathbb {G}\).
Since  is a PKE scheme, the above automatically implies security even in the presence of multiple
is a PKE scheme, the above automatically implies security even in the presence of multiple  and
and  queries as required by game
queries as required by game  . Thus, the theorem implies that
. Thus, the theorem implies that  is \(\mathrm {SROB\text{- }CCA}\) if \(H\) is pre-image resistant. A detailed proof of Theorem 5.1 is below. We begin by sketching some intuition.
is \(\mathrm {SROB\text{- }CCA}\) if \(H\) is pre-image resistant. A detailed proof of Theorem 5.1 is below. We begin by sketching some intuition.
We begin by conveniently modifying the game interface. We replace \(B\) with an adversary \(A\) that gets input \((g_1,g_2,K),(e_0,f_0,h_0), (e_1,f_1,h_1)\) representing the parameters that would be input to \(B\) and the public keys returned in response to \(B\)’s two  queries. Let \((x_{01},x_{02},y_{01},y_{02},z_{01},z_{02})\) and \((x_{11},x_{12},y_{11},y_{12},z_{11},z_{12})\) be the corresponding secret keys. The decryption oracle takes (only) a ciphertext and returns its decryption under both secret keys, setting a \({\textsc {Win}}\) flag if these are both non-\(\bot \). Adversary \(A\) no longer needs an output, since it can win via a
queries. Let \((x_{01},x_{02},y_{01},y_{02},z_{01},z_{02})\) and \((x_{11},x_{12},y_{11},y_{12},z_{11},z_{12})\) be the corresponding secret keys. The decryption oracle takes (only) a ciphertext and returns its decryption under both secret keys, setting a \({\textsc {Win}}\) flag if these are both non-\(\bot \). Adversary \(A\) no longer needs an output, since it can win via a  query.
query.
Suppose \(A\) makes a  query \((a_1,a_2, c, d)\). Then the code of the decryption algorithm \({\mathsf {Dec}}\) from Fig. 12 tells us that, for this to be a winning query, it must be that
query \((a_1,a_2, c, d)\). Then the code of the decryption algorithm \({\mathsf {Dec}}\) from Fig. 12 tells us that, for this to be a winning query, it must be that
where \(v = H(K,(a_1,a_2,c))\). Letting \(u_1 = \log _{g_1}(a_1), u_2 = \log _{g_2}(a_2)\) and \(s = \log _{g_1}(d)\), we have
However, even acknowledging that \(A\) knows little about \(x_{b1}, x_{b2}, y_{b1}, y_{b2}\) (\(b \in \{0,1\}\)) through its  queries, it is unclear why (2) is prevented by pre-image resistance—or in fact any property short of being a random oracle—of the hash function \(H\). In particular, there seems no way to “plant” a target \(v^*\) as the value v of (2) since the adversary controls \(u_1\) and \(u_2\). However, suppose now that \(a_2 = a_1^w\). (We will discuss later why we can assume this.) This implies \(wu_2 = wu_1\) or \(u_2 = u_1\) since \(w \ne 0\). Now from (2) we have
queries, it is unclear why (2) is prevented by pre-image resistance—or in fact any property short of being a random oracle—of the hash function \(H\). In particular, there seems no way to “plant” a target \(v^*\) as the value v of (2) since the adversary controls \(u_1\) and \(u_2\). However, suppose now that \(a_2 = a_1^w\). (We will discuss later why we can assume this.) This implies \(wu_2 = wu_1\) or \(u_2 = u_1\) since \(w \ne 0\). Now from (2) we have
We now see the value of enforcing \(a_1 \ne 1\), since this implies \(u_1 \ne 0\). After canceling \(u_1\) and rearranging terms, we have
Given that \(x_{b1}, x_{b2}, y_{b1}, y_{b2}\) (\(b \in \{0,1\}\)) and w are chosen by the game, there is at most one solution v (modulo p) to (3). We would like now to design \(I\) so that on input \(K,v^*\) it chooses \(x_{b1}, x_{b2}, y_{b1}, y_{b2}\) (\(b \in \{0,1\}\)) so that the solution v to (3) is \(v^*\). Then \((a_1,a_2,c)\) will be a pre-image of \(v^*\) which \(I\) can output.

Games  , and
, and  for proof of Theorem 5.1.
for proof of Theorem 5.1.  includes the boxed code at line 116 but
includes the boxed code at line 116 but  does not
does not
To make all this work, we need to resolve two problems. The first is why we may assume \(a_2 = a_1^w\)—which is what enables (3)—given that \(a_1,a_2\) are chosen by \(A\). The second is to properly design \(I\) and show that it can simulate \(A\) correctly with high probability. To solve these problems, we consider, as in [27], a modified check under which decryption, rather than rejecting when \(d \ne a_1^{x_1+y_1v}a_2^{x_2+y_2v}\), rejects when \(a_2 \ne a_1^w\) or \(d \ne a_1^{x+yv}\), where \(x = x_1+wx_2\), \(y = y_1+wy_2\), \(v = H(K,(a_1,a_2,c))\) and \((a_1,a_2,c,d)\) is the ciphertext being decrypted. In our proof below, games  –
– move us toward this perspective. Then, we fork off two game chains. Games
move us toward this perspective. Then, we fork off two game chains. Games  –
– are used to show that the modified decryption rule increases the adversary’s advantage by at most 2q / p. Games
are used to show that the modified decryption rule increases the adversary’s advantage by at most 2q / p. Games  –
– show how to embed a target value \(v^*\) into the components of the secret key without significantly affecting the ability to answer
show how to embed a target value \(v^*\) into the components of the secret key without significantly affecting the ability to answer  queries. Based on the latter, we then construct \(I\) as shown below.
queries. Based on the latter, we then construct \(I\) as shown below.
proof of Theorem 5.1
The proof relies on Games  –
– of Figs. 13, 14 and 15 and the adversary \(I\) of Fig. 16.
of Figs. 13, 14 and 15 and the adversary \(I\) of Fig. 16.
We begin by transforming \(B\) into an adversary \(A\) such that

On input \((g_1,g_2,K),(e_0,f_0,h_0),(e_1,f_1,h_1)\), adversary \(A\) runs \(B\) on input \((g_1,g_2,K)\). Adversary \(A\) returns to \(B\) the public key \((e_0,f_0,h_0)\) in response to \(B\)’s first  query \( id _0\), and \((e_1,f_1,h_1)\) in response to its second
query \( id _0\), and \((e_1,f_1,h_1)\) in response to its second  query \( id _1\). When \(B\) makes a
query \( id _1\). When \(B\) makes a  query, which can be assumed to have the form \((a_1,a_2,c,d), id _b\) for some \(b\in \{0,1\}\), adversary \(A\) queries \((a_1,a_2,c,d)\) to its own
query, which can be assumed to have the form \((a_1,a_2,c,d), id _b\) for some \(b\in \{0,1\}\), adversary \(A\) queries \((a_1,a_2,c,d)\) to its own  oracle to get back \((M_0,M_1)\) and returns \(M_b\) to \(B\). When \(B\) halts, with output that can be assumed to have the form \(((a_1,a_2,c,d), id _0, id _1)\), adversary \(A\) makes a final query \((a_1,a_2,c,d)\) to its
oracle to get back \((M_0,M_1)\) and returns \(M_b\) to \(B\). When \(B\) halts, with output that can be assumed to have the form \(((a_1,a_2,c,d), id _0, id _1)\), adversary \(A\) makes a final query \((a_1,a_2,c,d)\) to its  oracle and also halts.
oracle and also halts.

Games  and
and  for proof of Theorem 5.1
for proof of Theorem 5.1

Games  –
– for proof of Theorem 5.1.
for proof of Theorem 5.1.  includes the boxed code at line 805 but
includes the boxed code at line 805 but  does not
does not

Adversary \(I\) for proof of Theorem 5.1
We assume that every  query \((a_1,a_2,c,d)\) of \(A\) satisfies \(a_1 \ne \mathbf {1}\). This is without loss of generality because the decryption algorithm rejects otherwise. This will be crucial below. Similarly, we assume \((a_1,a_2,c,d) \in \mathbb {G}^4\). We now proceed to the analysis.
query \((a_1,a_2,c,d)\) of \(A\) satisfies \(a_1 \ne \mathbf {1}\). This is without loss of generality because the decryption algorithm rejects otherwise. This will be crucial below. Similarly, we assume \((a_1,a_2,c,d) \in \mathbb {G}^4\). We now proceed to the analysis.
Games  start to move us to the alternative decryption rule. In
start to move us to the alternative decryption rule. In  , if \(a_2 = a_1^w\) and \(d = a_1^{x_b+y_bv}\) then \(d = a_1^{x_{b1}+y_{b1}v} a_2^{x_{b2}+y_{b2}v}\), so
, if \(a_2 = a_1^w\) and \(d = a_1^{x_b+y_bv}\) then \(d = a_1^{x_{b1}+y_{b1}v} a_2^{x_{b2}+y_{b2}v}\), so  in
in  returns the correct decryption, like in
returns the correct decryption, like in  . If \(a_2 \ne a_1^w\) or \(d \ne a_1^{x_b + y_bv}\) then, if \(d \ne a_1^{x_{b1}+y_{b1}v} \cdot a_2^{x_{b2}+y_{b2}v}\), then
. If \(a_2 \ne a_1^w\) or \(d \ne a_1^{x_b + y_bv}\) then, if \(d \ne a_1^{x_{b1}+y_{b1}v} \cdot a_2^{x_{b2}+y_{b2}v}\), then  in
in  returns \(\bot \), else it returns \(ca_1^{-z_{b1}}a_2^{-z_{b2}}\), so again is correct either way. Thus,
returns \(\bot \), else it returns \(ca_1^{-z_{b1}}a_2^{-z_{b2}}\), so again is correct either way. Thus,

where the last line is by Lemma 2.1 since  are identical until \(\mathsf {bad}\). We now fork off two game chains, one to bound each term above.
are identical until \(\mathsf {bad}\). We now fork off two game chains, one to bound each term above.
First, we will bound the second term in the right-hand side of Inequality (5). Our goal is to move the choices of \(x_{b1},x_{b2},y_{b1},y_{b2},z_{b1},z_{b2}\) (\(b = 0,1\)) and the setting of \(\mathsf {bad}\) into \(\mathbf{Finalize }\) while still being able to answer  queries. We will then be able to bound the probability that \(\mathsf {bad}\) is set by a static analysis. Consider Game
queries. We will then be able to bound the probability that \(\mathsf {bad}\) is set by a static analysis. Consider Game  . If \(a_2 \ne a_1^w\) and \(d = a_1^{x_{b1}+y_{b1}v}a_2^{x_{b2}+y_{b2}v}\) then \(\mathsf {bad}\) is set in
. If \(a_2 \ne a_1^w\) and \(d = a_1^{x_{b1}+y_{b1}v}a_2^{x_{b2}+y_{b2}v}\) then \(\mathsf {bad}\) is set in  . But \(a_2 = a_1^w\) and \(d \ne a_1^{x_{b}+y_{b}v}\) implies \(d \ne a_1^{x_{b1}+y_{b1}v}a_2^{x_{b2}+y_{b2}v}\), so \(\mathsf {bad}\) is not set in
. But \(a_2 = a_1^w\) and \(d \ne a_1^{x_{b}+y_{b}v}\) implies \(d \ne a_1^{x_{b1}+y_{b1}v}a_2^{x_{b2}+y_{b2}v}\), so \(\mathsf {bad}\) is not set in  . So,
. So,

Since we are only interested in the probability that  sets \(\mathsf {bad}\), we have it always return \(\mathsf {true}\). The flag \(\mathsf {bad}\) may be set at line 315, but is not used, so we move the setting of \(\mathsf {bad}\) into the \(\mathbf{Finalize }\) procedure in
sets \(\mathsf {bad}\), we have it always return \(\mathsf {true}\). The flag \(\mathsf {bad}\) may be set at line 315, but is not used, so we move the setting of \(\mathsf {bad}\) into the \(\mathbf{Finalize }\) procedure in  . This requires that
. This requires that  do some bookkeeping. We have also done some restructuring, moving some loop invariants out of the loop in
do some bookkeeping. We have also done some restructuring, moving some loop invariants out of the loop in  . We have
. We have

The choice of \(x_{b1},x_{b2},x_b\) at lines 404, 405 can equivalently be written as first choosing \(x_b\) and \(x_{b2}\) at random and then setting \(x_{b1} = x_b - wx_{b2}\). This is true because w is not equal to 0 modulo p. The same is true for \(y_{b1},y_{b2},y_b\). Once this is done, \(x_{b1},x_{b2},y_{b1},y_{b2}\) are not used until \(\mathbf{Finalize }\), so their choice can be delayed. Game  makes these changes, so we have
makes these changes, so we have

Game  simply writes the test of line 524 in terms of the exponents. Note that this game computes discrete logarithms, but it is only used in the analysis and does not have to be efficient. We have
simply writes the test of line 524 in terms of the exponents. Note that this game computes discrete logarithms, but it is only used in the analysis and does not have to be efficient. We have

We claim that

(Recall q is the number of  queries made by \(A\).) We now justify (10). By the time we reach \(\mathbf{Finalize }\) in
queries made by \(A\).) We now justify (10). By the time we reach \(\mathbf{Finalize }\) in  , we can consider the adversary coins, all random choices of \(\mathbf{Initialize }\), and all random choices of
, we can consider the adversary coins, all random choices of \(\mathbf{Initialize }\), and all random choices of  to be fixed. We will take probability only over the choice of \(x_{b2},y_{b2}\) made at line 621. Consider a particular \((a_1,a_2,c,d,v) \in S\). This is now fixed, and so are the quantities \(u_1,u_2,s,t_0,t_1,\alpha \) and \(\beta \) as computed at lines 624–626. So we want to bound the probability that \(\mathsf {bad}\) is set at line 627 when we regard \(t_b,\alpha ,\beta \) as fixed and take the probability over the random choices of \(x_{b2},y_{b2}\). The crucial fact is that \(u_2 \ne u_1\) because \((a_1,a_2,c,d,v) \in S\), and lines 612, 613 only put a tuple in S if \(a_2 \ne a_1^w\). So \(\alpha \) and \(\beta \) are not 0 modulo p, and the probability that \(t_b = \alpha x_{b2} + \beta y_{b2}\) is thus 1 / p. The size of S is at most q so line 627 is executed at most 2q times. (10) follows from the union bound.
to be fixed. We will take probability only over the choice of \(x_{b2},y_{b2}\) made at line 621. Consider a particular \((a_1,a_2,c,d,v) \in S\). This is now fixed, and so are the quantities \(u_1,u_2,s,t_0,t_1,\alpha \) and \(\beta \) as computed at lines 624–626. So we want to bound the probability that \(\mathsf {bad}\) is set at line 627 when we regard \(t_b,\alpha ,\beta \) as fixed and take the probability over the random choices of \(x_{b2},y_{b2}\). The crucial fact is that \(u_2 \ne u_1\) because \((a_1,a_2,c,d,v) \in S\), and lines 612, 613 only put a tuple in S if \(a_2 \ne a_1^w\). So \(\alpha \) and \(\beta \) are not 0 modulo p, and the probability that \(t_b = \alpha x_{b2} + \beta y_{b2}\) is thus 1 / p. The size of S is at most q so line 627 is executed at most 2q times. (10) follows from the union bound.
We now return to (5) to bound the first term. Game  removes from
removes from  code that does not affect outcome of the game. Once this is done, \(x_{b1},y_{b1},x_{b2},y_{b2}\) are used only to define \(x_b, y_b\), so
code that does not affect outcome of the game. Once this is done, \(x_{b1},y_{b1},x_{b2},y_{b2}\) are used only to define \(x_b, y_b\), so  picks only the latter. So we have
picks only the latter. So we have

Game  is the same as
is the same as  barring setting a flag that does not affect the game outcome, so
barring setting a flag that does not affect the game outcome, so


(13) is by Lemma 2.1 since  are identical until \(\mathsf {bad}\). The probability that
are identical until \(\mathsf {bad}\). The probability that  sets \(\mathsf {bad}\) is the probability that \(y_1 = y_0\) at line 805, and this is 1 / p since y is chosen at random from \({{\mathbb Z}}_p\), justifying (12). The distribution of \(y_1\) in
sets \(\mathsf {bad}\) is the probability that \(y_1 = y_0\) at line 805, and this is 1 / p since y is chosen at random from \({{\mathbb Z}}_p\), justifying (12). The distribution of \(y_1\) in  is always uniform over \({{\mathbb Z}}_q-\{y_0\}\), and the setting of \(\mathsf {bad}\) at line 805 does not affect the game outcome, so
is always uniform over \({{\mathbb Z}}_q-\{y_0\}\), and the setting of \(\mathsf {bad}\) at line 805 does not affect the game outcome, so

Game  picks \(x_b,y_b\) differently from
picks \(x_b,y_b\) differently from  , but since \(y_1-y_0 \ne 0\), the two ways induce the same distribution on \(x_0,x_1,y_0,y_1\). Thus,
, but since \(y_1-y_0 \ne 0\), the two ways induce the same distribution on \(x_0,x_1,y_0,y_1\). Thus,

We now claim that

where \(I\) is depicted in Fig. 16. To justify this, say that the \(A\) makes a  query \((a_1,a_2,c,d)\) which returns \(( M _0, M _1)\) with \( M _0\ne \bot \) and \( M _1\ne \bot \). This means we must have
query \((a_1,a_2,c,d)\) which returns \(( M _0, M _1)\) with \( M _0\ne \bot \) and \( M _1\ne \bot \). This means we must have
where \(v = H(K,(a_1,a_2,c))\). Let \(u_1 = \log _{g_1}(a_1)\) and \(s = \log _{g_1}(d)\). Now, the above implies \(u_1 (x_0+y_0v) = u_1 (x_1 + y_1v)\). But \((a_1,a_2,c,d)\) is a  query, and we know that \(a_1 \ne \mathbf {1}\), so \(u_1 \ne 0\). (This is a crucial point. Recall the reason we can without loss of generality assume \(a_1\ne \mathbf {1}\) is that the decryption algorithm of
query, and we know that \(a_1 \ne \mathbf {1}\), so \(u_1 \ne 0\). (This is a crucial point. Recall the reason we can without loss of generality assume \(a_1\ne \mathbf {1}\) is that the decryption algorithm of  rejects otherwise.) Dividing \(u_1\) out, we get \(x_0 + y_0v = x_1 + y_1v\). Rearranging terms, we get \((y_1 - y_0) v = x_0 - x_1\). However, we know that \(y_1\ne y_0\), so \(v = (y_1-y_0)^{-1}(x_0 - x_1)\). However, this is exactly the value \(v^*\) due to the way \(I\) and Game
rejects otherwise.) Dividing \(u_1\) out, we get \(x_0 + y_0v = x_1 + y_1v\). Rearranging terms, we get \((y_1 - y_0) v = x_0 - x_1\). However, we know that \(y_1\ne y_0\), so \(v = (y_1-y_0)^{-1}(x_0 - x_1)\). However, this is exactly the value \(v^*\) due to the way \(I\) and Game  define \(x_0,y_0,x_1,y_1\). Thus, we have \(H(K,(a_1,a_2,c)) = v^*\), meaning that \(I\) will be successful.
define \(x_0,y_0,x_1,y_1\). Thus, we have \(H(K,(a_1,a_2,c)) = v^*\), meaning that \(I\) will be successful.
Putting together Eqs. (4)–(11), (12)–(16) concludes the proof of Theorem 5.1. 
6 A \(\mathrm {SROB\text{- }CCA}\) Version of DHIES

Original  scheme [5] does not contain the boxed code while the variant
scheme [5] does not contain the boxed code while the variant  does
does

Games  (left) and
(left) and  (right) defining the strong unforgeability of MAC scheme
(right) defining the strong unforgeability of MAC scheme  with key length \( k_\mathrm {M} \) and the one-time security of symmetric encryption scheme
with key length \( k_\mathrm {M} \) and the one-time security of symmetric encryption scheme  with key length \( k_\mathrm {SE} \), respectively
with key length \( k_\mathrm {SE} \), respectively
Let \(\mathbb {G}\) be a group of prime order p, let  and
and  be a symmetric encryption and message authentication code (MAC) scheme with key lengths \( k_\mathrm {SE} \) and \( k_\mathrm {M} \), respectively, and let \(H: \mathbb {G}\mapsto \{0,1\}^{ k_\mathrm {SE} + k_\mathrm {M} }\) be a hash function. The
be a symmetric encryption and message authentication code (MAC) scheme with key lengths \( k_\mathrm {SE} \) and \( k_\mathrm {M} \), respectively, and let \(H: \mathbb {G}\mapsto \{0,1\}^{ k_\mathrm {SE} + k_\mathrm {M} }\) be a hash function. The  public-key encryption scheme depicted in Fig. 17 was shown to be \(\mathrm {IND\text{- }CCA}\) in [4] and, in Sect. 6.1, we show it to be \(\mathrm {ANO\text{- }CCA}\) as well. In terms of robustness, it suffers from a similar problem as the
public-key encryption scheme depicted in Fig. 17 was shown to be \(\mathrm {IND\text{- }CCA}\) in [4] and, in Sect. 6.1, we show it to be \(\mathrm {ANO\text{- }CCA}\) as well. In terms of robustness, it suffers from a similar problem as the  scheme: the ciphertext \((\mathbf {1}, \gamma ^*, \tau ^*)\) decrypts to \( M \) under any key \( sk \) for \( SK ^*\Vert MK ^* \leftarrow H(\mathbf {1})\), \( \gamma ^* \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {SEnc}}( SK ^*, M )\), and \( \tau ^* \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {Tag}}( MK ^*, \gamma ^*)\), meaning that it is not \(\mathrm {SROB\text{- }CPA}\). Similarly to the
scheme: the ciphertext \((\mathbf {1}, \gamma ^*, \tau ^*)\) decrypts to \( M \) under any key \( sk \) for \( SK ^*\Vert MK ^* \leftarrow H(\mathbf {1})\), \( \gamma ^* \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {SEnc}}( SK ^*, M )\), and \( \tau ^* \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {Tag}}( MK ^*, \gamma ^*)\), meaning that it is not \(\mathrm {SROB\text{- }CPA}\). Similarly to the  scheme, we show that a modified scheme
scheme, we show that a modified scheme  that excludes the zero randomness and rejects ciphertexts with \(\mathbf {1}\) as first component is \(\mathrm {SROB\text{- }CCA}\).
that excludes the zero randomness and rejects ciphertexts with \(\mathbf {1}\) as first component is \(\mathrm {SROB\text{- }CCA}\).
Symmetric encryption. A symmetric encryption scheme  consists of an encryption algorithm \({\mathsf {SEnc}}\) that, on input a \( k_\mathrm {SE} \)-bit key \( SK \) and a message \( M \), outputs a ciphertext \( \gamma \); and a decryption algorithm \({\mathsf {SDec}}\) that, on input a key \( SK \) and ciphertext \( \gamma \) outputs a message \( M \). Correctness requires that \({\mathsf {SDec}}( SK ,{\mathsf {SEnc}}( SK , M ))= M \) with probability one for all \( M \in \{0,1\}^*\) and all \( SK \in \{0,1\}^{ k_\mathrm {SE} }\). We require one-time encryption security (\(\mathrm {OTE}\)) for
consists of an encryption algorithm \({\mathsf {SEnc}}\) that, on input a \( k_\mathrm {SE} \)-bit key \( SK \) and a message \( M \), outputs a ciphertext \( \gamma \); and a decryption algorithm \({\mathsf {SDec}}\) that, on input a key \( SK \) and ciphertext \( \gamma \) outputs a message \( M \). Correctness requires that \({\mathsf {SDec}}( SK ,{\mathsf {SEnc}}( SK , M ))= M \) with probability one for all \( M \in \{0,1\}^*\) and all \( SK \in \{0,1\}^{ k_\mathrm {SE} }\). We require one-time encryption security (\(\mathrm {OTE}\)) for  as defined in Fig. 18.
as defined in Fig. 18.
Message authentication codes. A message authentication code  consists of a tagging algorithm \({\mathsf {Tag}}\) that, on input a \( k_\mathrm {M} \)-bit key \( MK \) and a message \( M \), outputs a tag \( \tau \); and a verification algorithm \({\mathsf {Vf}}\) that, on input a key \( MK \), a message \( M \), and a tag \( \tau \), outputs 0 or 1, indicating that the tag is invalid or valid, respectively. Correctness requires that \({\mathsf {Vf}}( MK , M , {\mathsf {Tag}}( MK , M , \tau ))=1\) for all \( M \in \{0,1\}^*\) and all \( MK \in \{0,1\}^{ k_\mathrm {M} }\).
consists of a tagging algorithm \({\mathsf {Tag}}\) that, on input a \( k_\mathrm {M} \)-bit key \( MK \) and a message \( M \), outputs a tag \( \tau \); and a verification algorithm \({\mathsf {Vf}}\) that, on input a key \( MK \), a message \( M \), and a tag \( \tau \), outputs 0 or 1, indicating that the tag is invalid or valid, respectively. Correctness requires that \({\mathsf {Vf}}( MK , M , {\mathsf {Tag}}( MK , M , \tau ))=1\) for all \( M \in \{0,1\}^*\) and all \( MK \in \{0,1\}^{ k_\mathrm {M} }\).
Apart from the strong unforgeability (\(\mathrm {SUF}\)) defined in Fig. 18, for robustness we also require collision resistance of the MAC scheme, in the sense that it be hard for an adversary to come up with two keys \( MK _0, MK _1\), a message \( M \), and a tag \( \tau \) that is valid under both keys, i.e., such that \({\mathsf {Vf}}( MK _0, M , \tau ) = {\mathsf {Vf}}( MK _1, M , \tau ) = 1\). Collision-resistant MAC schemes are easy to construct in the random oracle model and the HMAC scheme [10], where \({\mathsf {Tag}}( MK , M ) = H( MK \oplus \mathtt {opad}, H( MK \oplus \mathtt {ipad}, M ))\), naturally satisfies it if the underlying hash function \(H\) is collision resistant. We define the collision-finding advantage  of an adversary \(A\) for
of an adversary \(A\) for  as the probability that \(A\) outputs a collision as described above. Note that a proper definition of collision resistance would require MAC schemes to be chosen at random from a family, as is done when formally defining collision resistance for hash functions. We refrain from doing so to avoid overloading our notation.
as the probability that \(A\) outputs a collision as described above. Note that a proper definition of collision resistance would require MAC schemes to be chosen at random from a family, as is done when formally defining collision resistance for hash functions. We refrain from doing so to avoid overloading our notation.
Oracle diffie–hellman. We recall the oracle Diffie–Hellman (\(\mathrm {ODH}\)) problem from [4] in Fig. 19. The adversary’s goal is to distinguish the hash of a Diffie–Hellman solution from a random string when given access to an oracle that returns hash values of Diffie–Hellman solutions of any other group elements than the target group element. The advantage of an adversary \(A\) to solve the \(\mathrm {ODH}\) problem is defined as
The proof by [4] that  is \(\mathrm {IND\text{- }CCA}\) relies on the assumption that \(\mathrm {ODH}\) is hard; we use the same assumption here to prove that is also \(\mathrm {ANO\text{- }CCA}\).
is \(\mathrm {IND\text{- }CCA}\) relies on the assumption that \(\mathrm {ODH}\) is hard; we use the same assumption here to prove that is also \(\mathrm {ANO\text{- }CCA}\).

Games \(\mathrm {ODH}_{\mathbb {G},H}\) (left) and \(\mathrm {ODH2}_{\mathbb {G},H}\) (right) defining the oracle Diffie–Hellman (ODH) problem and the double ODH problem in \(\mathbb {G}\) with respect to hash function \(H: \mathbb {G}\mapsto \{0,1\}^\ell \), respectively
We also introduce a double-challenge variant of \(\mathrm {ODH}\) called \(\mathrm {ODH2}\) in Fig. 19 and its associated advantage as \(\mathbf {Adv}^{\mathrm {odh2}}_{\mathbb {G},H}(A) = 2 \cdot {\Pr \left[ \,{\mathrm {ODH2}_{\mathbb {G},H}^{A} \,{\Rightarrow }\,\mathsf {true}}\,\right] } - 1\). The following lemma shows that the hardness of the \(\mathrm {ODH2}\) problem is implied by that of the \(\mathrm {ODH}\) problem, but the \(\mathrm {ODH2}\) problem is easier to work within our proofs.
Lemma 6.1
Let \(A\) be an adversary with advantage \(\mathbf {Adv}^{\mathrm {odh2}}_{\mathbb {G},H}(A)\) in solving the \(\mathrm {ODH2}\) problem. Then there exists an adversary \(B\) such that \(\mathbf {Adv}^{\mathrm {odh2}}_{\mathbb {G},H}(A) \le 2 \cdot \mathbf {Adv}^{\mathrm {odh}}_{\mathbb {G},H}(B)\).

Games  ,
,  , and
, and  for the proof of Lemma 6.1
for the proof of Lemma 6.1
Proof
Consider the sequence of games  ,
,  , and
, and  in Fig. 20. Game
in Fig. 20. Game  is identical to the \(\mathrm {ODH2}_{\mathbb {G},H}\) game in the case that \(b=0\). Game
is identical to the \(\mathrm {ODH2}_{\mathbb {G},H}\) game in the case that \(b=0\). Game  is almost identical to \(\mathrm {ODH2}_{\mathbb {G},H}\) in the case that \(b=1\), except that it returns \(\mathsf {true}\) when \(\mathrm {ODH2}_{\mathbb {G},H}\) returns \(\mathsf {false}\) and vice versa. We therefore have that
is almost identical to \(\mathrm {ODH2}_{\mathbb {G},H}\) in the case that \(b=1\), except that it returns \(\mathsf {true}\) when \(\mathrm {ODH2}_{\mathbb {G},H}\) returns \(\mathsf {false}\) and vice versa. We therefore have that

Game  differs from
differs from  in that \(Z_0\) is chosen at random from \(\{0,1\}^\ell \), instead of computed as \(H(Y^{x_0})\). We claim that there exists an algorithm \(B_1\) such that
in that \(Z_0\) is chosen at random from \(\{0,1\}^\ell \), instead of computed as \(H(Y^{x_0})\). We claim that there exists an algorithm \(B_1\) such that

Namely, on initial input (g, X, Y, Z), \(B_1\) chooses \(x_1 \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{{\mathbb Z}}_p^*\) and sets \(X_0 \leftarrow X\), \(X_1 \leftarrow g^{x_1}\), \(Z_0 \leftarrow Z\), and \(Z_1 \leftarrow H(Y^{x_1})\). It then runs \(A\) on initial input \((g,X_0,X_1,Y,Z_0,Z_1)\), answering its  queries as
queries as  . When \(A\) outputs \(b'\), \(B_1\) also outputs \(b'\).
. When \(A\) outputs \(b'\), \(B_1\) also outputs \(b'\).
It is clear that \(B_1\) provides \(A\) with a perfect simulation of game  if the challenge bit b in \(B_1\)’s \(\mathrm {ODH2}_{\mathbb {G},H}\) game is zero, and of game
if the challenge bit b in \(B_1\)’s \(\mathrm {ODH2}_{\mathbb {G},H}\) game is zero, and of game  if \(b=1\). We therefore have that
if \(b=1\). We therefore have that

By a similar reasoning, there exists an algorithm \(B_2\) such that

Putting Eqs. (18), (19), and (20) together and letting \(B\) be the algorithm of \(B_1\) or \(B_2\) with the highest advantage yields the lemma statement. 
6.1 Anonymity of DHIES
The  scheme was already proved to be \(\mathrm {IND\text{- }CCA}\) secure [4], so to prove \(\mathrm {AI\text{- }CCA}\) security, we only have left to prove \(\mathrm {ANO\text{- }CCA}\) security. As mentioned in Sect. 2, the \(\mathrm {ANO\text{- }CCA}\) security game is the \(\mathrm {AI\text{- }CCA}\) game in Fig. 3 with an added restriction that two equal challenge messages \(M_0^* = M_1^*\) must be submitted to the
scheme was already proved to be \(\mathrm {IND\text{- }CCA}\) secure [4], so to prove \(\mathrm {AI\text{- }CCA}\) security, we only have left to prove \(\mathrm {ANO\text{- }CCA}\) security. As mentioned in Sect. 2, the \(\mathrm {ANO\text{- }CCA}\) security game is the \(\mathrm {AI\text{- }CCA}\) game in Fig. 3 with an added restriction that two equal challenge messages \(M_0^* = M_1^*\) must be submitted to the  oracle.
oracle.
Theorem 6.2
Let  be the general encryption scheme associated with group \(\mathbb {G}\), symmetric encryption scheme
be the general encryption scheme associated with group \(\mathbb {G}\), symmetric encryption scheme  , message authentication code
, message authentication code  , and hash function \(H: \mathbb {G}\mapsto \{0,1\}^{ k_\mathrm {SE} + k_\mathrm {M} }\) as per Fig. 17. Let \(A\) be an \({\mathrm {\mathrm {ano}\text{- }cca}}\) adversary against
, and hash function \(H: \mathbb {G}\mapsto \{0,1\}^{ k_\mathrm {SE} + k_\mathrm {M} }\) as per Fig. 17. Let \(A\) be an \({\mathrm {\mathrm {ano}\text{- }cca}}\) adversary against  that makes two
that makes two  queries, no
queries, no  queries and at most q
queries and at most q  queries. Then there exist an \(\mathrm {ODH2}\) adversary \(B\) against \(\mathbb {G}\) and an adversary \(C\) against the strong unforgeability of
queries. Then there exist an \(\mathrm {ODH2}\) adversary \(B\) against \(\mathbb {G}\) and an adversary \(C\) against the strong unforgeability of  such that
such that

Adversaries \(B,C\) have the same running time as \(A\), and adversary \(B\) makes q  queries.
queries.
Since  is a PKE scheme, the above implies security for multiple
is a PKE scheme, the above implies security for multiple  and
and  queries as required by the \(\mathrm {ANO\text{- }CCA}\) game. The above result easily extends to
queries as required by the \(\mathrm {ANO\text{- }CCA}\) game. The above result easily extends to  as well, because the exclusion of \(r=0\) from encryption and \(R = \mathbf {1}\) from decryption only affect the \(\mathrm {ANO\text{- }CCA}\) game if \(R^*=\mathbf {1}\) in the challenge ciphertext \(C^*\), which only happens with probability 1 / p.
as well, because the exclusion of \(r=0\) from encryption and \(R = \mathbf {1}\) from decryption only affect the \(\mathrm {ANO\text{- }CCA}\) game if \(R^*=\mathbf {1}\) in the challenge ciphertext \(C^*\), which only happens with probability 1 / p.

Games  and
and  for the proof of Theorem 6.2. Game
for the proof of Theorem 6.2. Game  includes the boxed code at line 009 but
includes the boxed code at line 009 but  does not
does not
Proof of Theorem 6.2
In Fig. 21, we depict Games  and
and  used in the proof. Game
used in the proof. Game  differs from the original \(\mathrm {ANO\text{- }CCA}\) game in that the challenge ciphertext uses symmetric encryption and MAC keys that are randomly chosen (in line 002) rather than computed as \( SK ^*\Vert MK ^* \leftarrow H(R^*)\). The changes to
differs from the original \(\mathrm {ANO\text{- }CCA}\) game in that the challenge ciphertext uses symmetric encryption and MAC keys that are randomly chosen (in line 002) rather than computed as \( SK ^*\Vert MK ^* \leftarrow H(R^*)\). The changes to  are purely cosmetic. We first show that for any \(\mathrm {ANO\text{- }CCA}\) adversary \(A\), there exists an \(\mathrm {ODH2}\) adversary \(B_2\) such that
are purely cosmetic. We first show that for any \(\mathrm {ANO\text{- }CCA}\) adversary \(A\), there exists an \(\mathrm {ODH2}\) adversary \(B_2\) such that

Namely, on initial input \((g, X_0, X_1, Y, Z_0, Z_1)\), adversary \(B_2\) chooses \(b \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}\{0,1\}\) and runs \(A\) on initial input g and returns \(X_0\) and \(X_1\) as the two public encryption keys of \(A\)’s  queries \( id _0\) and \( id _1\).
queries \( id _0\) and \( id _1\).
To simulate \(A\)’s  query, \(B_2\) sets \(R^* \leftarrow Y\), parses \(Z_b\) as \( SK ^*\Vert MK ^*\), and computes \( \gamma ^* \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {SEnc}}( SK ^*, M _b^*)\) and \( \tau ^* \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {Tag}}( MK ^*, \gamma ^*)\). It returns \(C^* = (R^*, \gamma ^*, \tau ^*)\) as the challenge ciphertext.
query, \(B_2\) sets \(R^* \leftarrow Y\), parses \(Z_b\) as \( SK ^*\Vert MK ^*\), and computes \( \gamma ^* \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {SEnc}}( SK ^*, M _b^*)\) and \( \tau ^* \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {Tag}}( MK ^*, \gamma ^*)\). It returns \(C^* = (R^*, \gamma ^*, \tau ^*)\) as the challenge ciphertext.
To answer \(A\)’s  queries, \(B_2\) proceeds as follows. If \(R \ne Y\), then \(B_2\) queries its \(\mathrm {ODH2}\) oracle to obtain \( SK \Vert MK \leftarrow \mathrm {ODH2}(R)\). If \(R = Y\), it parses \(Z_d\) as \( SK \Vert MK \). In both cases, it checks that \({\mathsf {Vf}}( MK , \gamma )=1\), and, if so, returns \( M \leftarrow {\mathsf {SDec}}( SK , \gamma )\). When \(A\) outputs its guess \(b'\), \(B_2\) outputs \((b=b')\).
queries, \(B_2\) proceeds as follows. If \(R \ne Y\), then \(B_2\) queries its \(\mathrm {ODH2}\) oracle to obtain \( SK \Vert MK \leftarrow \mathrm {ODH2}(R)\). If \(R = Y\), it parses \(Z_d\) as \( SK \Vert MK \). In both cases, it checks that \({\mathsf {Vf}}( MK , \gamma )=1\), and, if so, returns \( M \leftarrow {\mathsf {SDec}}( SK , \gamma )\). When \(A\) outputs its guess \(b'\), \(B_2\) outputs \((b=b')\).
Let \(b_2\) be the random bit chosen by \(B_2\)’s challenger in the \(\mathrm {ODH2}\) game that \(B_2\) has to guess. In the case that \(b_2=0\), we have that \(Z_0 = H(Y^{x_0})\) and \(Z_1 = H(Y^{x_1})\), so that all symmetric encryption and MAC keys that \(B_2\) used for the challenge ciphertext and to simulate \(A\)’s decryption queries are exactly as in the real  scheme. In the case that \(b_2=1\), \(Z_0\) and \(Z_1\) are random strings, so that the challenge ciphertext and decryption responses are exactly as in Game
scheme. In the case that \(b_2=1\), \(Z_0\) and \(Z_1\) are random strings, so that the challenge ciphertext and decryption responses are exactly as in Game  . We therefore have that
. We therefore have that

so that (21) follows.
Games  and
and  are identical until \(\mathsf {bad}\) on line 009 in Fig. 21, so by Lemma 2.1, we have that
are identical until \(\mathsf {bad}\) on line 009 in Fig. 21, so by Lemma 2.1, we have that

For any adversary \(A\) that makes Game  set \(\mathsf {bad}\), we construct an adversary \(C\) against the strong unforgeability of the MAC scheme so that
set \(\mathsf {bad}\), we construct an adversary \(C\) against the strong unforgeability of the MAC scheme so that

Namely, \(C\) chooses \(g,R^* \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}\mathbb {G}^*\), \( SK ^* \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}\{0,1\}^{ k_\mathrm {SE} }\), and \(b \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}\{0,1\}\) as in Game  , but rather than choosing a MAC key \( MK ^*\), it uses its
, but rather than choosing a MAC key \( MK ^*\), it uses its  and
and  oracles for all operations involving \( MK ^*\). More precisely, when answering \(A\)’s
oracles for all operations involving \( MK ^*\). More precisely, when answering \(A\)’s  query, it sets
query, it sets  . When \(A\) sets \(\mathsf {bad}\), i.e., makes a query
. When \(A\) sets \(\mathsf {bad}\), i.e., makes a query  with \(R=R^*\) and
with \(R=R^*\) and  , then \(C\) returns its forgery \(( \gamma , \tau )\). By line \(\small 006\), we have that \( C \ne (R^*, \gamma ^*, \tau ^*)\), so that \(( \gamma , \tau ) \ne ( \gamma ^*, \tau ^*)\) and therefore \(( \gamma , \tau )\) is a valid forgery.
, then \(C\) returns its forgery \(( \gamma , \tau )\). By line \(\small 006\), we have that \( C \ne (R^*, \gamma ^*, \tau ^*)\), so that \(( \gamma , \tau ) \ne ( \gamma ^*, \tau ^*)\) and therefore \(( \gamma , \tau )\) is a valid forgery.
Note that because \( M _0^*= M _1^*\), \(A\)’s view in Game  is independent of the bit b, hence
is independent of the bit b, hence

By the definition of \(\mathrm {ANO\text{- }CCA}\) advantage, we have

where the first step is due to (21), the second is by considering the \(\mathrm {ODH}\) adversary \(B\) from Lemma 6.1, and the third is due to (22), (23), and (24). 
6.2 Robustness of DHIES
Theorem 6.3
Let  be the general encryption scheme associated with group \(\mathbb {G}\), symmetric encryption scheme
be the general encryption scheme associated with group \(\mathbb {G}\), symmetric encryption scheme  , message authentication code
, message authentication code  , and hash function \(H: \mathbb {G}\mapsto \{0,1\}^{ k_\mathrm {SE} + k_\mathrm {M} }\) as per Fig. 17. Let \( H_\mathrm {M} : \mathbb {G}\mapsto \{0,1\}^{ k_\mathrm {M} }\) be the function that outputs the last \( k_\mathrm {M} \) bits of \(H(x)\) on input \(x \in \mathbb {G}\).
, and hash function \(H: \mathbb {G}\mapsto \{0,1\}^{ k_\mathrm {SE} + k_\mathrm {M} }\) as per Fig. 17. Let \( H_\mathrm {M} : \mathbb {G}\mapsto \{0,1\}^{ k_\mathrm {M} }\) be the function that outputs the last \( k_\mathrm {M} \) bits of \(H(x)\) on input \(x \in \mathbb {G}\).
Let \(A\) be an \({\mathrm {\mathrm {srob}\text{- }cca}}\) adversary against  , making at most
, making at most  queries to its
queries to its  oracle. Then there exist collision-finding adversaries \(B\) and \(C\) against \( H_\mathrm {M} \) and
oracle. Then there exist collision-finding adversaries \(B\) and \(C\) against \( H_\mathrm {M} \) and  , respectively, such that
, respectively, such that

Adversaries \(B\) and \(C\) have the same running time as \(A\).
The proof intuition for the strong robustness of  is quite straightforward. Let \((C, id _0, id _1)\) be the output of a \(\mathrm {SROB\text{- }CCA}\) adversary \(A\) where \(C= (R, \gamma , \tau )\) and \(( id _0, id _1)\) are the identities associated with two different public keys \(y_0=g^{x_0}\) and \(y_1=g^{x_1}\). Let \( SK _b\Vert MK _b \leftarrow H(y_b^r)\) for \(b\in \{0,1\}\). First, \(y_0^r \ne y_1^r\) since \(R\ne \mathbf {1}\) and \(y_0 \ne y_1 \ne \mathbf {1}\) with overwhelming probability. Second \( MK _0 \ne MK _1\) with all but negligible probability since the probability that \( H_\mathrm {M} (y_0^r) = H_\mathrm {M} (y_1^r)\) is negligible due to the collision resistance of \( H_\mathrm {M} \). Third, the probability that C is valid with respect to both \(y_0\) and \(y_1\) (i.e., \({\mathsf {Dec}}(g, y_0, x_0,C)\ne \bot \) and \({\mathsf {Dec}}(g, y_1, x_1,C)\ne \bot \)) is negligible since the probability that \({\mathsf {Vf}}( MK _0, \gamma , \tau )={\mathsf {Vf}}( MK _1, \gamma , \tau )=1\) is negligible due to the collision resistance of
is quite straightforward. Let \((C, id _0, id _1)\) be the output of a \(\mathrm {SROB\text{- }CCA}\) adversary \(A\) where \(C= (R, \gamma , \tau )\) and \(( id _0, id _1)\) are the identities associated with two different public keys \(y_0=g^{x_0}\) and \(y_1=g^{x_1}\). Let \( SK _b\Vert MK _b \leftarrow H(y_b^r)\) for \(b\in \{0,1\}\). First, \(y_0^r \ne y_1^r\) since \(R\ne \mathbf {1}\) and \(y_0 \ne y_1 \ne \mathbf {1}\) with overwhelming probability. Second \( MK _0 \ne MK _1\) with all but negligible probability since the probability that \( H_\mathrm {M} (y_0^r) = H_\mathrm {M} (y_1^r)\) is negligible due to the collision resistance of \( H_\mathrm {M} \). Third, the probability that C is valid with respect to both \(y_0\) and \(y_1\) (i.e., \({\mathsf {Dec}}(g, y_0, x_0,C)\ne \bot \) and \({\mathsf {Dec}}(g, y_1, x_1,C)\ne \bot \)) is negligible since the probability that \({\mathsf {Vf}}( MK _0, \gamma , \tau )={\mathsf {Vf}}( MK _1, \gamma , \tau )=1\) is negligible due to the collision resistance of  . Finally, the latter is true even when \(A\) knows the corresponding secret keys \(x_0\) and \(x_1\) associated with \(y_0\) and \(y_1\) so
. Finally, the latter is true even when \(A\) knows the corresponding secret keys \(x_0\) and \(x_1\) associated with \(y_0\) and \(y_1\) so  and
and  are of no help to \(A\).
are of no help to \(A\).
Proof of Theorem 6.3
In order to prove the strong robustness of  , we consider a \(\mathrm {SROB\text{- }CCA}\) adversary \(A\) that even knows the secret decryption key associated with each public key that it obtains via
, we consider a \(\mathrm {SROB\text{- }CCA}\) adversary \(A\) that even knows the secret decryption key associated with each public key that it obtains via  queries (and therefore can decrypt all the ciphertexts that it wants). That is, whenever \(A\) issues a
queries (and therefore can decrypt all the ciphertexts that it wants). That is, whenever \(A\) issues a  query \( id \), the challenger in the \(\mathrm {SROB\text{- }CCA}\) game runs the key generation algorithm \({\mathsf {KG}}(g)\) to obtain a fresh pair of secret and public keys \((x,y=g^x)\) for \( id \) and returns both values to \(A\). Hence, \(A\) can compute the answer to
query \( id \), the challenger in the \(\mathrm {SROB\text{- }CCA}\) game runs the key generation algorithm \({\mathsf {KG}}(g)\) to obtain a fresh pair of secret and public keys \((x,y=g^x)\) for \( id \) and returns both values to \(A\). Hence, \(A\) can compute the answer to  and
and  queries on its own.
queries on its own.
Let \((C, id _0, id _1)\) be the output of a \(\mathrm {SROB\text{- }CCA}\) adversary \(A\) where \(C= (R, \gamma , \tau )\) and \(( id _0, id _1)\) are the identities associated with two different public keys \(y_0=g^{x_0}\) and \(y_1=g^{x_1}\). Moreover, let \( MK _b \leftarrow H_\mathrm {M} (y_b^r)\) for \(b\in \{0,1\}\) denote the corresponding MAC keys. In order for \(A\) to be successful, one of the following cases needs to occur:
-
(1)
\(y_0=y_1\);
-
(2)
\( H_\mathrm {M} (y_0^r) = H_\mathrm {M} (y_1^r)\);
-
(3)
\({\mathsf {Vf}}( MK _0, \gamma , \tau )={\mathsf {Vf}}( MK _1, \gamma , \tau )=1\).
Since public keys are generated honestly, the probability that \(y_0=y_1\) (i.e., Case (1)) can be upper-bounded by the probability that  oracle generates the same public and secret keys for two different \( id \) values, which is at most
oracle generates the same public and secret keys for two different \( id \) values, which is at most  .
.
Assuming that \(y_0\ne y_1\) and since \(R\ne \mathbf {1}\), it is easy to construct a collision-finding adversary \(B\) against \( H_\mathrm {M} \) such that the probability that \( H_\mathrm {M} (y_0^r) = H_\mathrm {M} (y_1^r)\) (i.e., Case (2)) is at most \(\mathbf {Adv}^{\mathrm {coll}}_{ H_\mathrm {M} }(B)\). Adversary \(B\) works as follows. \(B\) starts by running \(A\), providing the latter with a generator g for the group \(\mathbb {G}\). Whenever \(A\) issues a  query \( id \), \(B\) runs the key generation algorithm \({\mathsf {KG}}(g)\) to obtain a fresh pair of secret and public keys \((x,y=g^x)\) for \( id \) and returns both values to \(A\). Finally, when \(A\) issues a \(\mathbf{Finalize }\) query \((C, id _0, id _1)\), where \(C= (R, \gamma , \tau )\), let \((x_b,y_b=g^{x_b})\) be the secret and public key pair associated with \( id _b\) for \(b\in \{0,1\}\). \(B\) simply outputs \(R^{x_0}\) and \(R^{x_1}\) as a collision for \( H_\mathrm {M} \). Clearly, \(B\) wins whenever \( H_\mathrm {M} (y_0^r) = H_\mathrm {M} (y_1^r)\). Hence, the probability that \( H_\mathrm {M} (y_0^r) = H_\mathrm {M} (y_1^r)\) is at most \(\mathbf {Adv}^{\mathrm {coll}}_{ H_\mathrm {M} }(B)\).
query \( id \), \(B\) runs the key generation algorithm \({\mathsf {KG}}(g)\) to obtain a fresh pair of secret and public keys \((x,y=g^x)\) for \( id \) and returns both values to \(A\). Finally, when \(A\) issues a \(\mathbf{Finalize }\) query \((C, id _0, id _1)\), where \(C= (R, \gamma , \tau )\), let \((x_b,y_b=g^{x_b})\) be the secret and public key pair associated with \( id _b\) for \(b\in \{0,1\}\). \(B\) simply outputs \(R^{x_0}\) and \(R^{x_1}\) as a collision for \( H_\mathrm {M} \). Clearly, \(B\) wins whenever \( H_\mathrm {M} (y_0^r) = H_\mathrm {M} (y_1^r)\). Hence, the probability that \( H_\mathrm {M} (y_0^r) = H_\mathrm {M} (y_1^r)\) is at most \(\mathbf {Adv}^{\mathrm {coll}}_{ H_\mathrm {M} }(B)\).
Finally, if we assume that \( H_\mathrm {M} (y_0^r) \ne H_\mathrm {M} (y_1^r)\), then it is easy to construct a collision-finding adversary \(C\) against  such that the probability that \({\mathsf {Vf}}( MK _0, \gamma , \tau )={\mathsf {Vf}}( MK _1, \gamma , \tau )=1\) (i.e., Case (3)) is at most
such that the probability that \({\mathsf {Vf}}( MK _0, \gamma , \tau )={\mathsf {Vf}}( MK _1, \gamma , \tau )=1\) (i.e., Case (3)) is at most  . Adversary \(C\) works as follows. \(C\) starts by running \(A\), providing the latter with a generator g for the group \(\mathbb {G}\). Whenever \(A\) issues a
. Adversary \(C\) works as follows. \(C\) starts by running \(A\), providing the latter with a generator g for the group \(\mathbb {G}\). Whenever \(A\) issues a  query \( id \), \(C\) runs the key generation algorithm \({\mathsf {KG}}(g)\) to obtain a fresh pair of secret and public keys \((x,y=g^x)\) for \( id \) and returns both values to \(A\). Finally, when \(A\) issues a \(\mathbf{Finalize }\) query \((C, id _0, id _1)\), where \(C= (R, \gamma , \tau )\), let \((x_b,y_b=g^{x_b})\) be the secret and public key pair associated with \( id _b\) and let \( MK _b \leftarrow H_\mathrm {M} (R^{x_b})\) for \(b\in \{0,1\}\). \(C\) simply outputs \(( MK _0, MK _1)\) as the two MAC keys, \( \gamma \) as the message, and \( \tau \) as the tag. Clearly, \(C\) wins whenever \({\mathsf {Vf}}( MK _0, \gamma , \tau )={\mathsf {Vf}}( MK _1, \gamma , \tau )=1\). Hence, the probability that \({\mathsf {Vf}}( MK _0, \gamma , \tau )={\mathsf {Vf}}( MK _1, \gamma , \tau )=1\) is at most
query \( id \), \(C\) runs the key generation algorithm \({\mathsf {KG}}(g)\) to obtain a fresh pair of secret and public keys \((x,y=g^x)\) for \( id \) and returns both values to \(A\). Finally, when \(A\) issues a \(\mathbf{Finalize }\) query \((C, id _0, id _1)\), where \(C= (R, \gamma , \tau )\), let \((x_b,y_b=g^{x_b})\) be the secret and public key pair associated with \( id _b\) and let \( MK _b \leftarrow H_\mathrm {M} (R^{x_b})\) for \(b\in \{0,1\}\). \(C\) simply outputs \(( MK _0, MK _1)\) as the two MAC keys, \( \gamma \) as the message, and \( \tau \) as the tag. Clearly, \(C\) wins whenever \({\mathsf {Vf}}( MK _0, \gamma , \tau )={\mathsf {Vf}}( MK _1, \gamma , \tau )=1\). Hence, the probability that \({\mathsf {Vf}}( MK _0, \gamma , \tau )={\mathsf {Vf}}( MK _1, \gamma , \tau )=1\) is at most  .
. 
7 Other Schemes and Transforms
In this section, we show that neither of two popular \(\mathrm {IND\text{- }CCA}\)-providing transforms, the Fujisaki–Okamoto (FO) transform [32] in the random oracle model and the Canetti–Halevi–Katz (CHK) transform [9, 25] in the standard model, yield robustness. Since the FO transform even provides the stronger notion of plaintext awareness [19], the counterexample below is at the same time a proof that even plaintext awareness does not suffice for robustness. The fact that neither of the transforms confer robustness generically does not exclude that they may still do so for certain specific schemes. We show that this is actually the case for the Boneh–Franklin IBE [15], which uses the FO transform to obtain \(\mathrm {IND\text{- }CCA}\) security, and that it is not the case for the Boyen–Waters IBE [23], which uses the CHK transform.
The FO transform. Given a public-key encryption scheme  the FO transform yields a PKE scheme
the FO transform yields a PKE scheme  where a message \( M \) is encrypted as
where a message \( M \) is encrypted as
where \(x \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}\{0,1\}^k\), where \(G(\cdot )\) and \(H(\cdot )\) are random oracles, and where \(H(x, M )\) is used as the random coins for the \({\mathsf {Enc}}\) algorithm. To decrypt a ciphertext \((C_1,C_2)\), one recovers x by decrypting \(C_1\), recovers \( M \leftarrow C_2 \oplus G(x)\), and checks that \({\mathsf {Enc}}( pars , pk , x ; H(x, M )) = C_1\). If this is the case then \( M \) is returned, otherwise \(\bot \) is returned.
Given a scheme  , we show how to build a scheme
, we show how to build a scheme  such that
such that  obtained by applying the FO transform to
obtained by applying the FO transform to  is not \(\mathrm {SROB\text{- }CPA}\). Namely, for some fixed \(x^* \in \{0,1\}^k\) and \( M ^*\), let encryption and decryption be given by
is not \(\mathrm {SROB\text{- }CPA}\). Namely, for some fixed \(x^* \in \{0,1\}^k\) and \( M ^*\), let encryption and decryption be given by

It is easy to see that if  is one-way (the notion required by the FO transform), then so is
is one-way (the notion required by the FO transform), then so is  , because for an honestly generated ciphertext the random coins \(H(x^*, M ^*)\) will hardly ever occur. Moreover, it is also straightforward to show that, if
, because for an honestly generated ciphertext the random coins \(H(x^*, M ^*)\) will hardly ever occur. Moreover, it is also straightforward to show that, if  is \(\gamma \)-uniform, then
is \(\gamma \)-uniform, then  is \(\gamma '\)-uniform for \(\gamma '=\max (\gamma ,1/2^{\ell })\), where \(\ell \) is the output length of H (please refer to [32] for the definition of \(\gamma \)-uniformity). It is also easy to see that the scheme
is \(\gamma '\)-uniform for \(\gamma '=\max (\gamma ,1/2^{\ell })\), where \(\ell \) is the output length of H (please refer to [32] for the definition of \(\gamma \)-uniformity). It is also easy to see that the scheme  obtained by applying the FO transform to
obtained by applying the FO transform to  is not robust: the ciphertext \(\overline{ C }= ( 0 \;,\; G(x^*)\oplus M ^*)\) decrypts correctly to \( M ^*\) under any public key.
is not robust: the ciphertext \(\overline{ C }= ( 0 \;,\; G(x^*)\oplus M ^*)\) decrypts correctly to \( M ^*\) under any public key.
The Boneh–Franklin IBE. Boneh and Franklin proposed the first truly practical provably secure IBE scheme in [15]. They also propose a variant that uses the FO transform to obtain provable \(\mathrm {IND\text{- }CCA}\) security in the random oracle model under the bilinear Diffie–Hellman (BDH) assumption; we refer to it as the BF-IBE scheme here. A straightforward modification of the proof can be used to show that BF-IBE is also \(\mathrm {ANO\text{- }CCA}\) in the random oracle model under the same assumption. We now give a proof sketch that BF-IBE is also (unconditionally) \(\mathrm {SROB\text{- }CCA}\) in the random oracle model.
Let \(e{:\;\;}\mathbb {G}_1 \times \mathbb {G}_1 \rightarrow \mathbb {G}_2\) be a non-degenerate bilinear map, where \(\mathbb {G}_1\) and \(\mathbb {G}_2\) are multiplicative cyclic groups of prime order p [15]. Let g be a generator of \(\mathbb {G}_1\). The master secret key of the BF-IBE scheme is an exponent \(s \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{{\mathbb Z}}_p^*\), the public parameters contain \(S \leftarrow g^s\). For random oracles \(H_1: \{0,1\}^* \rightarrow \mathbb {G}_1^*\), \(H_2: \mathbb {G}_2 \rightarrow \{0,1\}^k\), \(H_3: \{0,1\}^k \times \{0,1\}^\ell \rightarrow {{\mathbb Z}}_p^*\), and \(H_4: \{0,1\}^k \rightarrow \{0,1\}^\ell \), the encryption of a message \( M \) under identity \( id \) is a tuple
where \(x \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}\{0,1\}^k\) and \(r \leftarrow H_3(x, M )\). To decrypt a ciphertext \(( C _1, C _2, C _3)\), the user with identity \( id \) and decryption key \( dk = H_1( id )^s\) computes \(x \leftarrow C _2 \oplus H_2(e( C _1, dk ))\), \( M \leftarrow C _3 \oplus H_4(x)\), and \(r \leftarrow H_3(x, M )\). If \( C _1 \ne g^r\) he rejects, otherwise he outputs \( M \).
Let us now consider a \(\mathrm {SROB\text{- }CCA}\) adversary \(A\) that even knows the master secret s (and therefore can derive all keys and decrypt all ciphertexts that it wants). Since \(H_1\) maps into \(\mathbb {G}_1^*\), all its outputs are of full order p. The probability that \(A\) finds two identities \( id _1\) and \( id _2\) such that \(H_1( id ) = H_1( id _2)\) is negligible. Since \(S \in \mathbb {G}_1^*\) and the map is non-degenerate, we therefore have that \(g_{ id _1} = e(S,H_1( id _1))\) and \(g_{ id _2} = e(S,H_1( id _2))\) are different and of full order p. Since \(H_3\) maps into \({{\mathbb Z}}_p^*\), we have that \(r \ne 0\), and therefore that \(g_{ id _1}^r\) and \(g_{ id _2}^r\) are different. If the output of \(H_2\) is large enough to prevent collisions from being found, that also means that \(H_2(g_{ id _1}^r)\) and \(H_2(g_{ id _2}^r)\) are different. Decryption under both identities therefore yields two different values \(x_1 \ne x_2\), and possibly different messages \( M _1, M _2\). In order for the ciphertext to be valid for both identities, we need that \(r = H_3(x_1, M _1) = H_3(x_2, M _2)\), but the probability of this happening is again negligible in the random oracle model. As a result, it follows that the BF-IBE scheme is also \(\mathrm {SROB\text{- }CCA}\) in the random oracle model.
The Canetti–Halevi–Katz transform. The CHK transform turns an IBE scheme and a one-time signature scheme [30, 42] into a PKE scheme as follows. For each ciphertext, a fresh signature key pair \(( spk , ssk )\) is generated. The ciphertext is a tuple \(( C , spk , \sigma )\) where \( C \) is the encryption of \( M \) to identity \( spk \) and \(\sigma \) is a signature of \( C \) under \( ssk \). To decrypt, one verifies the signature \(\sigma \), derives the decryption key for identity \( spk \), and decrypts \( C \).
Given a scheme  , consider the scheme
, consider the scheme  where \({\mathsf {Enc}}( pars , id , M ) = 1\Vert {\mathsf {Enc}}^*( pars , id , M )\) and where \({\mathsf {Dec}}( pars , id , dk , b\Vert C ^*)\) returns \({\mathsf {Dec}}^*( pars , id , dk , C ^*)\) if \(b=1\) and simply returns \( C ^*\) if \(b=0\). This scheme clearly inherits the privacy and anonymity properties of
where \({\mathsf {Enc}}( pars , id , M ) = 1\Vert {\mathsf {Enc}}^*( pars , id , M )\) and where \({\mathsf {Dec}}( pars , id , dk , b\Vert C ^*)\) returns \({\mathsf {Dec}}^*( pars , id , dk , C ^*)\) if \(b=1\) and simply returns \( C ^*\) if \(b=0\). This scheme clearly inherits the privacy and anonymity properties of  . However, if
. However, if  is used in the CHK transformation, then one can easily generate a ciphertext \((0\Vert M , spk , \sigma )\) that validly decrypts to \( M \) under any parameters \( pars \) (which in the CHK transform serve as the user’s public key).
is used in the CHK transformation, then one can easily generate a ciphertext \((0\Vert M , spk , \sigma )\) that validly decrypts to \( M \) under any parameters \( pars \) (which in the CHK transform serve as the user’s public key).
An extension of the CHK transform turns any \(\mathrm {IND\text{- }CPA}\) secure \(\ell +1\)-level hierarchical IBE (HIBE) into an \(\mathrm {IND\text{- }CCA}\) secure \(\ell \)-level HIBE. It is easy to see that this transform does not confer robustness either.
The Boyen–Waters IBE. Boyen and Waters [23] proposed a HIBE scheme which is \(\mathrm {IND\text{- }CPA}\) and \(\mathrm {ANO\text{- }CPA}\) in the standard model, and a variant that uses the CHK transform to achieve \(\mathrm {IND\text{- }CCA}\) and \(\mathrm {ANO\text{- }CCA}\) security. Decryption in the \(\mathrm {IND\text{- }CPA}\) secure scheme never rejects, so it is definitely not \(\mathrm {WROB\text{- }CPA}\). Without going into details here, it is easy to see that the \(\mathrm {IND\text{- }CCA}\) variant is not \(\mathrm {WROB\text{- }CPA}\) either, because any ciphertext that is valid with respect to one identity will also be valid with respect to another identity, since the verification of the one-time signature does not depend on the identity of the recipient. (The natural fix to include the identity in the signed data may ruin anonymity.)
The \(\mathrm {IND\text{- }CCA}\)-secure variant of Gentry’s IBE scheme [34] falls to a similar robustness attack as the original Cramer–Shoup scheme, by choosing a random exponent \(r=0\). We did not check whether explicitly forbidding this choice restores robustness, however.
Composite-order pairing-based schemes. As mentioned in the introduction, a number of encryption schemes based on composite-order bilinear maps satisfy a variant of our weak robustness notion [24, 40]. They achieve this by restricting the message space to a negligible fraction of the group and by proving that decryption of a ciphertext with an incorrect secret key yields a message with a random component in one of the subgroups. This message has a negligible probability of falling within the valid message space. It is unclear whether the same approach can be used to satisfy our robustness notions or whether it extends to other schemes.
There is growing recognition that robustness is important in applications and worth defining explicitly, supporting our own claims to this end. In particular, the strong correctness requirement for public-key encryption [8] and the correctness requirement for hidden vector and predicate encryption [40, 41] imply a form of weak robustness. In work concurrent to, and independent of, ours, Hofheinz and Weinreb [38] introduced a notion of well-addressedness of IBE schemes that is just like weak robustness except that the adversary gets the IBE master secret key.
Neither of these works considers or achieves strong robustness, and neither treats PKE. Well-addressedness of IBE implies \(\mathrm {WROB\text{- }CCA}\) but does not imply \(\mathrm {SROB\text{- }CCA}\) and, on the other hand, \(\mathrm {SROB\text{- }CCA}\) does not imply well-addressedness. Note that the term robustness is also used in multi-party computation to denote the property that corrupted parties cannot prevent honest parties from computing the correct protocol output [18, 36, 37]. This meaning is unrelated to our use of the word robustness.
8 Application to Auctions
Robustness of ElGamal. The parameters of the ElGamal encryption scheme consist of the description of a group \(\mathbb {G}\) of prime order p with generator g. The secret key of a user is \(x \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{{\mathbb Z}}_p\), the corresponding public key is \(X = g^x\). The encryption of a message \( M \) is the pair \((g^r,X^r\cdot M )\) for \(r \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{{\mathbb Z}}_p\). A ciphertext (R, S) is decrypted as \( M \leftarrow R/S^x\). Since the decryption algorithm never returns \(\bot \), the ElGamal scheme is obviously not robust. Stronger even, the ciphertext \((1, M )\) decrypts to \( M \) under any secret key.
It is this strong failure of robustness that opens the way to attacks on applications like Sako’s auction protocol [47].
The protocol. Sako’s auction protocol [47] is important because it is the first truly practical one to hide the bids of losers. Let \(1,\ldots ,N\) be the range of possible bidding prices. In an initialization step, the auctioneer generates N ElGamal key pairs \((x_1,X_1),\ldots ,(x_N,X_N)\) and publishes \(g,X_1,\ldots , X_N\) and a fixed message \( M \in \mathbb {G}\). A bidder places a bid of value \(v \in \{1,\ldots ,N\}\) by encrypting \( M \) under \(X_v\) and posting the ciphertext. Note that the privacy of the bids is guaranteed by the anonymity of ElGamal encryption. The authority opens bids \( C _1 = (R_1,S_1), \ldots , C _n = (R_n,S_n)\) by decrypting all bids under secret keys \(x_N,\ldots ,x_1\), until the highest index w where one or more bids decrypt to \( M \). The auctioneer announces the identity of the winner(s), the price of the item w, and the secret key \(x_w\). All auctioneers can then check that \(S_i/R_i^{x_w}= M \) for all winners i.
An attack. Our attack permits a dishonest bidder and a colluding auctioneer to break the fairness of the protocol. (Security against colluding auctioneers was not considered in [47], so we do not disprove their results, but it is a property that one may expect the protocol to have.) Namely, a cheating bidder can place a bid \((1, M )\). If w is the highest honest bid, then the auctioneer can agree to open the corrupted bid to with \(x_{w+1}\), thereby winning the auction for the cheating bidder at one dollar more than the second-highest bidder.
Sako came close to preventing this attack with an “incompatible encryption” property that avoids choosing \(r=0\) at encryption. A dishonest bidder, however, may deviate from this encryption rule; the problem is that the decryption algorithm does not reject ciphertexts (R, S) when \(R=1\). While such a ciphertext would surely look suspicious to a human observing the network traffic, it will most likely go unnoticed to the users if the software doesn’t explicitly check for such ciphertexts. It is therefore up to the decryption algorithm to explicitly specify which cases need to be checked and up to the security proof to show that, if these cases are checked, the system indeed has the desired properties.
The attack above can easily be prevented by using any of our robust encryption schemes, so that decryption under any other secret key than the intended one results in \(\bot \) being returned. Note that for this application we really need the strong robustness notion with adversarially generated ciphertexts.
Though necessary, our notion of strong robustness may not be sufficient to guarantee the fairness of the protocol in the case where a dishonest bidder has access the secret key held by the colluding auctioneer or when the public key of the scheme is not honestly generated, as our notion does not take these settings into account. Hence, to achieve fairness in Sako’s auction protocol, it would be important to consider encryption schemes that achieve an even stronger notion of robustness in which public keys may be maliciously generated by the adversary [31]. Interestingly, as pointed out in their paper, our strong robustness transform in Sect. 4 already achieves this stronger notion.
It is worth noting that, to enforce that all bids are independent of each other even in the presence of a colluding auctioneer, all bidders would also need to commit to their sealed bids (using a non-malleable commitment scheme) during a first round of communication and only open their commitments once all commitments made public.
9 Applications to Searchable Encryption
Public-key encryption with keyword search. A public-key encryption with keyword search (PEKS) scheme [12] is a tuple  of algorithms. Via \(( pk , sk ) \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {KG}}\), the key generation algorithm produces a pair of public and private keys. Via \( C \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {PEKS}}( pk , w )\), the encryption algorithm encrypts a keyword \( w \) to get a ciphertext under the public key \( pk \). Via \( t _ w \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {Td}}( sk , w )\), the trapdoor extraction algorithm computes a trapdoor \( t _ w \) for keyword \( w \). The deterministic test algorithm \({\mathsf {Test}}( t _ w , C )\) returns 1 if \( C \) is an encryption of \( w \) and 0 otherwise.
of algorithms. Via \(( pk , sk ) \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {KG}}\), the key generation algorithm produces a pair of public and private keys. Via \( C \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {PEKS}}( pk , w )\), the encryption algorithm encrypts a keyword \( w \) to get a ciphertext under the public key \( pk \). Via \( t _ w \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {Td}}( sk , w )\), the trapdoor extraction algorithm computes a trapdoor \( t _ w \) for keyword \( w \). The deterministic test algorithm \({\mathsf {Test}}( t _ w , C )\) returns 1 if \( C \) is an encryption of \( w \) and 0 otherwise.
Privacy and consistency of PEKS schemes. We formulate privacy notions for PEKS using the games of Fig. 22. Let \(\mathrm {ATK}\in \{\mathrm {CPA},\mathrm {CCA}\}\). We define the advantage of an adversary \(A\) against the indistinguishability of  as follows:
as follows:

We re-formulate the consistency definition of PEKS schemes of [1] using the game of Fig. 22. We define the advantage of an adversary \(A\) against the consistency of  as follows:
as follows:

Furthermore, we also recall the advantage measure  , which captures the notion \(\mathrm {CONSIST}\) of computational consistency of PEKS scheme
, which captures the notion \(\mathrm {CONSIST}\) of computational consistency of PEKS scheme  .
.

 is a PEKS scheme. Games
is a PEKS scheme. Games  and
and  are on the left, where the latter omits procedure
are on the left, where the latter omits procedure  . The
. The  procedure may be called only once. Game
procedure may be called only once. Game  is on the right
is on the right
Transforming IBE to PEKS. The \(\mathsf {bdop\text{- }ibe\text{- }2\text{- }}\mathsf {peks}\) transform of [12] transforms an IBE scheme into a PEKS scheme. Given an IBE scheme  , the transform associates with it the PEKS scheme
, the transform associates with it the PEKS scheme  , where the key generation algorithm \({\mathsf {KG}}\) returns \(( pk , sk ) \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {Setup}}\); the encryption algorithm \({\mathsf {PEKS}}( pk , w )\) returns \(C \leftarrow {\mathsf {Enc}}( pk , w ,0^k)\); the trapdoor extraction algorithm \({\mathsf {Td}}( sk , w )\) returns \( t \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {Ext}}( pk , sk , w )\); the test algorithm \({\mathsf {Test}}( t , C )\) returns 1 if and only if \({\mathsf {Dec}}( pk , t ,C)=0^k\). Abdalla et al. [1] showed that this transform generally does not provide consistency and presented the consistency-providing \(\mathsf {new\text{- }ibe\text{- }2\text{- }peks}\) transform as an alternative. We now show that the original \(\mathsf {bdop\text{- }ibe\text{- }2\text{- }}\mathsf {peks}\) transform does yield a consistent PEKS if the underlying IBE scheme is robust. We also show that if the base IBE scheme is \(\mathrm {ANO\text{- }CCA}\), then the PEKS scheme is \(\mathrm {IND\text{- }CCA}\), thereby yielding the first \(\mathrm {IND\text{- }CCA}\)-secure PEKS schemes in the standard model, and the first consistent \(\mathrm {IND\text{- }CCA}\)-secure PEKS schemes in the RO model. (Non-consistent \(\mathrm {IND\text{- }CCA}\)-secure PEKS schemes in the RO model are easily derived from [33]).
, where the key generation algorithm \({\mathsf {KG}}\) returns \(( pk , sk ) \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {Setup}}\); the encryption algorithm \({\mathsf {PEKS}}( pk , w )\) returns \(C \leftarrow {\mathsf {Enc}}( pk , w ,0^k)\); the trapdoor extraction algorithm \({\mathsf {Td}}( sk , w )\) returns \( t \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}{\mathsf {Ext}}( pk , sk , w )\); the test algorithm \({\mathsf {Test}}( t , C )\) returns 1 if and only if \({\mathsf {Dec}}( pk , t ,C)=0^k\). Abdalla et al. [1] showed that this transform generally does not provide consistency and presented the consistency-providing \(\mathsf {new\text{- }ibe\text{- }2\text{- }peks}\) transform as an alternative. We now show that the original \(\mathsf {bdop\text{- }ibe\text{- }2\text{- }}\mathsf {peks}\) transform does yield a consistent PEKS if the underlying IBE scheme is robust. We also show that if the base IBE scheme is \(\mathrm {ANO\text{- }CCA}\), then the PEKS scheme is \(\mathrm {IND\text{- }CCA}\), thereby yielding the first \(\mathrm {IND\text{- }CCA}\)-secure PEKS schemes in the standard model, and the first consistent \(\mathrm {IND\text{- }CCA}\)-secure PEKS schemes in the RO model. (Non-consistent \(\mathrm {IND\text{- }CCA}\)-secure PEKS schemes in the RO model are easily derived from [33]).
Proposition 9.1
Let  be an IBE scheme, and let
be an IBE scheme, and let  be the PEKS scheme associated with it per the
be the PEKS scheme associated with it per the  transform. Given any adversary \(A\) running in time t, we can construct an adversary \(B\) running in time \(t + O(t)\) executions of the algorithms of
transform. Given any adversary \(A\) running in time t, we can construct an adversary \(B\) running in time \(t + O(t)\) executions of the algorithms of  such that
such that

To see why the first inequality is true, it suffices to consider the adversary \(B\) that on input \( pars \) runs \(( w , w ') \mathop {\leftarrow }\limits ^{{\scriptscriptstyle \$}}A( pars )\) and outputs these keywords along with the message \(0^k\). The proof of the second inequality is an easy adaptation of the proof of the \(\mathsf {new\text{- }ibe\text{- }2\text{- }peks}\) transform in [1], where \(B\) answers \(A\)’s  queries using its own
queries using its own  oracle.
oracle.
Securely combining PKE and PEKS. Searchable encryption by itself is only of limited use since it can only encrypt individual keywords, and since it does not allow decryption. Fuhr and Paillier [33] introduce a more flexible variant that allows decryption of the keyword. An even more powerful (and general) primitive can be obtained by combining PEKS with PKE to encrypt non-searchable but recoverable content. For example, one could encrypt the body of an email using a PKE scheme and append a list of PEKS-encrypted keywords. The straightforward approach of concatenating ciphertexts works fine for CPA security, but is insufficient for a strong, combined \(\mathrm {IND\text{- }CCA}\) security model where the adversary, in addition to the trapdoor oracle, has access to both a decryption oracle and a testing oracle. Earlier attempts to combine PKE and PEKS [22, 51] do not give the adversary access to the latter. A full \(\mathrm {IND\text{- }CCA}\)-secure PKE/PEKS scheme in the standard model can be obtained by combining the \(\mathrm {IND\text{- }CCA}\)-secure PEKS schemes obtained through our transformation with the techniques of [28]. Namely, one can consider label-based [49] variants of the PKE and PEKS primitives, tie the different components of a ciphertext together by using as a common label the verification key of a one-time signature scheme, and append to the ciphertext a signature of all components under the corresponding signing key. Though we omit the details, we note that the same techniques can be used to handle multiple encrypted keywords and avoid reordering attacks such as those mentioned by Boneh et al. [12].
References
M. Abdalla, M. Bellare, D. Catalano, E. Kiltz, T. Kohno, T. Lange, J. Malone-Lee, G. Neven, P. Paillier, H. Shi, Searchable encryption revisited: consistency properties, relation to anonymous IBE, and extensions. J. Cryptol. 21(3), 350–391 (2008)
M. Abdalla, M. Bellare, G. Neven, Robust encryption. Cryptology ePrint Archive, Report 2008/440 (2008). http://eprint.iacr.org/2008/440
M. Abdalla, M. Bellare, G. Neven, Robust encryption, in D. Micciancio (ed.) TCC 2010, volume 5978 of LNCS (Springer, Berlin, 2010), pp. 480–497
M. Abdalla, M. Bellare, P. Rogaway, DHIES: an encryption scheme based on the Diffie-Hellman problem. Contributions to IEEE P1363a (1998)
M. Abdalla, M. Bellare, P. Rogaway, The oracle Diffie-Hellman assumptions and an analysis of DHIES, in D. Naccache (ed.) CT-RSA 2001, volume 2020 LNCS (Springer, Berlin, 2001), pp. 143–158
D. Boneh, X. Boyen, Efficient selective-ID secure identity based encryption without random oracles, in C. Cachin, J. Camenisch (eds.) EUROCRYPT 2004, volume 3027 of LNCS (Springer, Berlin, 2004), pp. 223–238
M. Bellare, A. Boldyreva, A. Desai, D. Pointcheval, Key-privacy in public-key encryption, in C. Boyd (ed.) ASIACRYPT 2001, volume 2248 of LNCS (Springer, Berlin, 2001), pp. 566–582
A. Barth, D. Boneh, B. Waters, Privacy in encrypted content distribution using private broadcast encryption, in G. Di Crescenzo, A. Rubin (eds.) FC 2006, volume 4107 of LNCS (Springer, Berlin, 2006), pp. 52–64
D. Boneh, R. Canetti, S. Halevi, J. Katz, Chosen-ciphertext security from identity-based encryption. SIAM J. Comput. 36(5), 1301–1328 (2007)
M. Bellare, R. Canetti, H. Krawczyk, Keying hash functions for message authentication, in N. Koblitz (ed.) CRYPTO’96, volume 1109 of LNCS (Springer, Berlin, 1996), pp. 1–15
M. Bellare, S. Duan, Partial signatures and their applications. Cryptology ePrint Archive, Report 2009/336 (2009). http://eprint.iacr.org/2009/336
D. Boneh, G. Di Crescenzo, R. Ostrovsky, G. Persiano, Public key encryption with keyword search, in C. Cachin, J. Camenisch (eds.) EUROCRYPT 2004, volume 3027 of LNCS (Springer, Berlin, 2004), pp. 506–522
M. Bellare, A. Desai, D. Pointcheval, P. Rogaway, Relations among notions of security for public-key encryption schemes, in H. Krawczyk (ed.) CRYPTO’98, volume 1462 of LNCS (Springer, Berlin, 1998), pp. 26–45
M. Bellare, R. Dowsley, B. Waters, S. Yilek, Standard security does not imply security against selective-opening, in D. Pointcheval, T. Johansson (eds.) EUROCRYPT 2012, volume 7237 of LNCS (Springer, Berlin, 2012), pp. 645–662
D. Boneh, M.K. Franklin, Identity-based encryption from the Weil pairing, in J. Kilian (ed.) CRYPTO 2001 volume 2139 of LNCS (Springer, Berlin, 2001), pp. 213–229
D. Boneh, M.K. Franklin, Identity based encryption from the Weil pairing. SIAM J. Comput. 32(3), 586–615 (2003)
D. Boneh, C. Gentry, M. Hamburg, Space-efficient identity based encryption without pairings, in 48th FOCS (IEEE Computer Society Press, 2007), pp. 647–657
M. Ben-Or, S. Goldwasser, A. Wigderson, Completeness theorems for non-cryptographic fault-tolerant distributed computation (extended abstract), in 20th ACM STOC (ACM Press, 1988), pp. 1–10
M. Bellare, A. Palacio, Towards plaintext-aware public-key encryption without random oracles, in P.J. Lee (ed.) ASIACRYPT 2004, volume 3329 of LNCS (Springer, Berlin, 2004), pp. 48–62
M. Bellare, P. Rogaway, The security of triple encryption and a framework for code-based game-playing proofs, in S. Vaudenay (ed.) EUROCRYPT 2006, volume 4004 of LNCS (Springer, Berlin, 2006), pp. 409–426
D. Boneh, A. Raghunathan, G. Segev, Function-private identity-based encryption: hiding the function in functional encryption, in R. Canetti, J.A. Garay (eds.) CRYPTO 2013, Part II, volume 8043 of LNCS (Springer, Berlin, 2013), pp. 461–478
J. Baek, R. Safavi-Naini, W. Susilo, On the integration of public key data encryption and public key encryption with keyword search, in S.K. Katsikas, J. Lopez, M. Backes, St. Gritzalis, B. Preneel (eds.) ISC 2006, volume 4176 of LNCS (Springer, Berlin, 2006), pp. 217–232
X. Boyen, B. Waters, Anonymous hierarchical identity-based encryption (without random oracles), in C. Dwork (ed.) CRYPTO 2006, volume 4117 of LNCS (Springer, Berlin, 2006), pp. 290–307
D. Boneh, B. Waters, Conjunctive, subset, and range queries on encrypted data, in S.P. Vadhan (ed.) TCC 2007, volume 4392 of LNCS (Springer, Berlin, 2007), pp. 535–554
R. Canetti, S. Halevi, J. Katz, Chosen-ciphertext security from identity-based encryption, in C. Cachin, J. Camenisch (eds.) EUROCRYPT 2004, volume 3027 of LNCS, (Springer, Berlin, 2004), pp. 207–222
R. Canetti, Y.T. Kalai, M. Varia, D. Wichs, On symmetric encryption and point obfuscation, in D. Micciancio (ed.) TCC 2010, volume 5978 of LNCS (Springer, Berlin, 2010), pp. 52–71
R. Cramer, V. Shoup, Design and analysis of practical public-key encryption schemes secure against adaptive chosen ciphertext attack. SIAM J. Comput. 33(1), 167–226 (2003)
Y. Dodis, J. Katz, Chosen-ciphertext security of multiple encryption, in J. Kilian (ed.) TCC 2005, volume 3378 of LNCS, (Springer, Berlin, 2005), pp. 188–209
D. Dolev, C. Dwork, M. Naor, Nonmalleable cryptography. SIAM J. Comput. 30(2), 391–437 (2000)
S. Even, O. Goldreich, S. Micali, On-line/off-line digital signatures. J. Cryptol. 9(1), 35–67 (1996)
P. Farshim, B. Libert, K.G. Paterson, E.A. Quaglia, Robust encryption, revisited, in K. Kurosawa, G. Hanaoka (eds.) PKC 2013, volume 7778 of LNCS (Springer, Berlin, 2013), pp. 352–368
E. Fujisaki, T. Okamoto, Secure integration of asymmetric and symmetric encryption schemes, in M.J. Wiener (ed.) CRYPTO’99, volume 1666 of LNCS (Springer, Berlin, 1999), pp. 537–554
T. Fuhr, P. Paillier, Decryptable searchable encryption, in W. Susilo, J.K. Liu, Y. Mu (eds.) Provable Security, First International Conference, ProvSec 2007, volume 4784 of LNCS, Wollongong, Australia, November 1–2, 2007. (Springer, Berlin, 2007), pp. 228–236
C. Gentry, Practical identity-based encryption without random oracles, in S. Vaudenay (ed.) EUROCRYPT 2006, volume 4004 of LNCS (Springer, Berlin, 2006), pp. 445–464
S. Goldwasser, S. Micali, Probabilistic encryption. J. Comput. Syst. Sci. 28(2), 270–299 (1984)
O. Goldreich, S. Micali, A. Wigderson, How to play any mental game or a completeness theorem for protocols with honest majority, in A. Aho (ed.) 19th ACM STOC (ACM Press, 1987), pp. 218–229
M. Hirt, U.M. Maurer, Robustness for free in unconditional multi-party computation, in J. Kilian (ed.) CRYPTO 2001, volume 2139 of LNCS, (Springer, Berlin, 2001), pp. 101–118
D. Hofheinz, E. Weinreb, Searchable encryption with decryption in the standard model. Cryptology ePrint Archive, Report 2008/423 (2008). http://eprint.iacr.org/2008/423
M. Jakobsson, A practical mix, in K. Nyberg (ed.) EUROCRYPT’98, volume 1403 of LNCS (Springer, Berlin, 1998), pp. 448–461
J. Katz, A. Sahai, B. Waters, Predicate encryption supporting disjunctions, polynomial equations, and inner products, in N.P. Smart (ed.) EUROCRYPT 2008, volume 4965 of LNCS (Springer, Berlin, 2008), pp. 146–162
E. Kiltz, K. Pietrzak, M. Stam, M. Yung, A new randomness extraction paradigm for hybrid encryption, in A. Joux (ed.) EUROCRYPT 2009, volume 5479 of LNCS (Springer, Berlin, 2009), pp. 590–609
L. Lamport, Constructing digital signatures from a one-way function. Technical Report SRI-CSL-98, SRI International Computer Science Laboratory (1979)
B. Libert, K.G. Paterson, E.A. Quaglia, Anonymous broadcast encryption: adaptive security and efficient constructions in the standard model, in M. Fischlin, J. Buchmann, M. Manulis (eds.), PKC 2012, volume 7293 of LNCS (Springer, Berlin, 2012), pp. 206–224
P. Mohassel, A closer look at anonymity and robustness in encryption schemes, in M. Abe (ed.) ASIACRYPT 2010, volume 6477 of LNCS (Springer, Berlin, 2010), pp. 501–518
C. Rackoff, D.R. Simon, Non-interactive zero-knowledge proof of knowledge and chosen ciphertext attack, in J. Feigenbaum (ed.) CRYPTO’91, volume 576 of LNCS (Springer, Berlin, 1992), pp. 433–444
P. Rogaway, T. Shrimpton, Cryptographic hash-function basics: definitions, implications, and separations for preimage resistance, second-preimage resistance, and collision resistance, in B.K. Roy, W. Meier (eds.) FSE 2004, volume 3017 of LNCS (Springer, Berlin, 2004), pp. 371–388
K. Sako, An auction protocol which hides bids of losers, in H. Imai, Y. Zheng (eds.) PKC 2000, volume 1751 of LNCS (Springer, Berlin, 2000), pp. 422–432
Y. Seurin, J. Treger, A robust and plaintext-aware variant of signed ElGamal encryption, in E. Dawson (ed.) CT-RSA 2013, volume 7779 of LNCS (Springer, Berlin, 2013), pp. 68–83
V. Shoup, A proposal for an ISO standard for public key encryption. Cryptology ePrint Archive, Report 2001/112 (2001). http://eprint.iacr.org/2001/112
Y. Tsiounis, M. Yung, On the security of ElGamal based encryption, in H. Imai, Y. Zheng (eds.) PKC’98, volume 1431 of LNCS (Springer, Berlin, 1998), pp. 117–134
R. Zhang, H. Imai, Generic combination of public key encryption with keyword search and public key encryption, in F. Bao, S. Ling, T. Okamoto, H. Wang, C. Xing (eds.) CANS 07, volume 4856 of LNCS (Springer, Berlin, 2007), pp. 159–174
Acknowledgements
We thank Chanathip Namprempre, who declined our invitation to be a co-author, for her participation and contributions in the early stage of this work.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Paterson.
Michel Abdalla: Supported in part by the European Commission through the ICT Program under Contract ICT-2007-216676 ECRYPT II, the French ANR-07-SESU-008-01 Project PAMPA, and the French ANR-14-CE28-0003 Project EnBiD.
Mihir Bellare: Supported in part by NSF Grant CNS-1116800.
Gregory Neven: Supported in part by the European Commission through the ICT Program under Contract ICT-2007-216676 ECRYPT II, a Postdoctoral Fellowship from the Research Foundation – Flanders (FWO – Vlaanderen) and by the European Community’s Seventh Framework Programme project PrimeLife (Grant Agreement No. 216483) and PERCY (Grant Agreement No. 321310).
Rights and permissions
About this article

Cite this article
Abdalla, M., Bellare, M. & Neven, G. Robust Encryption. J Cryptol 31, 307–350 (2018). https://doi.org/10.1007/s00145-017-9258-8
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00145-017-9258-8