
Abstract
The properties of minimum \(K_{\phi }\)-divergence estimators for parametric multinomial populations are well-known when the assumed parametric model is true, namely, they are consistent and asymptotically normally distributed. Here we study these properties when the parametric model is not assumed to be correctly specified. Under certain conditions, these estimators are shown to converge to a well-defined limit and, suitably normalized, they are also asymptotically normal. Two applications of the results obtained are reported. First, two consistent bootstrap estimators of the null distribution of the test statistics in a certain class of goodness-of-fit tests are proposed and studied. Second, two methods for the model selection test problem based on \(K_{\phi }\)-divergence type statistics are proposed and studied. Both applications are illustrated with numerical examples.
Similar content being viewed by others


1 Introduction
Suppose that the outcomes of a random experiment can be classified into one of \(m\) possible classes or categories, \(C_1, C_2, \ldots , C_m\). Let \(X\) be a random variable taking the value \(X=i\) when the category \(C_i\) is observed, \(1\le i\le m\). Throughout this paper we will assume that the available data \(X_1,X_2, \ldots ,X_n\) is a random sample from \(X\), that is to say, the data consist of \(n\) independent and identically distributed (iid) random variables taking values in \(\Upsilon _m=\{1,2,\ldots ,m\}\) according to a common probability law \(\pi \in \varDelta _m=\{(\pi _1,\pi _2,\ldots , \pi _m)^t:\; \pi _i > 0, \; 1\le i \le m, \; \sum _{i=1}^m \pi _i=1\}\), where \(\pi _i=P(X=i), 1 \le i \le m\). In many instances, it is assumed that \(\pi \) is unknown, but belonging to a parametric family \(\pi \in \mathcal P =\{P(\theta )=(p_1(\theta ),p_2(\theta ), \ldots , p_m(\theta ))^t, \; \theta \in \varTheta \} \subset \varDelta _m\), where \(\varTheta \subseteq \mathbb R ^k, m-k-1>0\) and \(p_1(.), p_2(.)\), ..., \(p_m(.)\) are known real functions. In this setting, \(\pi \) is usually estimated through \(P(\hat{\theta })=(p_1(\hat{\theta }), p_2(\hat{\theta }), \ldots , p_m(\hat{\theta }) )^t\) for some estimator \(\hat{\theta }\) of \(\theta \). A common choice for \(\hat{\theta }\) is a maximum likelihood estimator (MLE). These estimators are known to have good asymptotic properties. Morales et al. (1995) and Basu and Sarkar (1994) have shown that these properties are shared by a larger class of estimators: the minimum \(\phi \)-divergence estimators, which contain as particular cases some well-known estimators as the MLE or that minimizing the \(\chi ^2\) statistic. The minimum \(\phi \)-divergence estimators compute \(\hat{\theta }\) through \(\arg \min _{\theta \in \varTheta } D(\hat{\pi },P(\theta ))\), where \(\hat{\pi }\) is the vector of relative frequencies and \(D\) is a \(\phi \)-divergence (Csiszár 1967). Instead of taking \(D\) a \(\phi \)-divergence between two elements of \(\varDelta _m, D\) could be taken in another class of divergence measures. For example, Pérez and Pardo (2004) have studied the properties of the resulting estimator when \(D\) is taken a \(K_{\phi }\)-divergence. This class of divergences was introduced in Burbea and Rao (1982). Specifically, Pérez and Pardo (2004) have shown that, under certain regularity conditions, the minimum \(K_{\phi }\)-divergence estimator (M\(K_{\phi }\)E), \(\hat{\theta }_{\phi }\), defined as
converges a.s. to the true parameter value, say \(\theta \), and that \(\sqrt{n}(\hat{\theta }-\theta )\) is asymptotically normal, where for arbitrary \(Q=(q_1, q_2,\ldots ., q_m)^t, P=(p_1, p_2, \ldots , p_m)^t \in \varDelta _m\), the \(K_{\phi }\)-divergence between \(Q\) and \(P\) is defined by
\(\phi \) being a real function satisfying certain properties that will be specified later. The consistency and the asymptotic normality of \(\hat{\theta }\) have been derived by assuming that the parametric model has been correctly specified, that is, that \(\pi \in \mathcal P \) is true.
When the parametric model \(\mathcal P \) is not assumed to be correctly specified and \(\varTheta \) is compact, the results in White (1982) say that the MLE of \(\theta \) converges to some \(\theta _1 \in \varTheta \) and that \(\sqrt{n}(\hat{\theta }-\theta _1)\) is asymptotically normal. Lindsay (1994) has shown the asymptotic normality of minimum \(\phi \)-divergence estimators for arbitrary \(\phi \). The results in Lindsay (1994) can be applied to discrete random variables taking an infinite number of values. Jiménez-Gamero et al. (2011) have shown that the conditions in Lindsay (1994) can be weakened when the sample space is finite. To our knowledge, no similar study has been done for M\(K_{\phi }\)Es. So, the aim of this paper is to study the properties of the M\(K_{\phi }\)E when the parametric model \(\mathcal P \) is not assumed to be correctly specified.
Two applications of the obtained results are studied. First, we consider the problem of testing goodness-of-fit to the parametric family \(\mathcal P , H_0: \, \pi \in \mathcal P \). Many tests for testing \(H_0\) are based on measuring discrepancies between two estimators of a function characterizing a probability law. A possible way of measuring such discrepancies is by considering \(T=K_{\phi }(\hat{\pi }, P(\hat{\theta }))\), for some \(\hat{\theta }\) consistent estimator of \(\theta \). Pérez and Pardo (2003a) have studied the test that rejects \(H_0\) for large values of \(T\). The resulting test is consistent against fixed alternatives. The main problem with this test is that, in general, it is not distribution free, even asymptotically. The results obtained on M\(K_{\phi }\)E lead us to propose two consistent bootstrap estimators of the null distribution of the test statistic \(T\). Two numerical examples illustrate the finite sample behaviour of the proposed estimators.
Second, we consider a very related problem: that of model selection, which consists on deciding what of a set of competing models is closest to the data. For this problem we propose and study two procedures, both based on \(K_{\phi }\)-divergences. The obtained results are applied to the classical problem of discriminating between the exponential and the log-normal distributions.
The paper is organized as follows. In Sect. 2 we study the strong consistency and the asymptotic normality of M\(K_{\phi }\)Es. In Sect. 3, as a first application of the results obtained, it is studied the consistency of two bootstrap null distribution estimators of certain class of test statistics for testing goodness-of-fit based on \(K_{\phi }\)-divergences. In Sect. 4, as a second application, we study the problem of model selection based on \(K_{\phi }\)-divergence statistics. Both applications are illustrated with numerical examples. All proofs are sketched in Sect. 5.
Before ending this section we introduce some notation: all limits in this paper are taken when \(n \rightarrow \infty \); \(\stackrel{\mathcal{L }}{\rightarrow }\) denotes convergence in distribution; \(\stackrel{P}{\rightarrow }\) denotes convergence in probability; \(\stackrel{a.s.}{\rightarrow }\) denotes the almost sure convergence; let \(\{A_n\}\) be a sequence of random variables and let \(\epsilon \in \mathbb R \), then \(A_n=O_P(n^{-\epsilon })\) means that \(n^{\epsilon }A_n\) is bounded in probability, \(A_n=o_P(n^{-\epsilon })\) means that \(n^{\epsilon }A_n\stackrel{P}{\rightarrow }0\) and \(A_n=o(n^{-\epsilon })\) means that \(n^{\epsilon }A_n\stackrel{a.s.}{\rightarrow }0\); \(N_k(\mu , \Sigma )\) denotes the \(k\)-variate normal law with mean \(\mu \) and variance matrix \(\Sigma \); in any testing setting, \(P_0\) denotes the probability under the null hypothesis; \(P_*\) denotes the conditional probability, given the data; all vectors are column vectors; the superscript \(^t\) denotes transpose; if \(x \in \mathbb R ^k\), with \(x^t=(x_1, \ldots , x_k)\), then \(Diag(x)\) is the \(k \times k\) diagonal matrix whose \((i,i)\) entry is \(x_i, 1\le i \le k\), and \(\Sigma _x=Diag(x)-xx^t; I_k\) denotes the \(k \times k\) identity matrix; to simplify notation, all 0’s appearing in the paper represent vectors of the appropriate dimension; if \(R \subset \mathbb R ^d\), for some \(d\in \mathbb N \), then \(intR\) denotes the interior of \(R, I_R(x)=1\) if \(x\in R\) and \(I_R(x)=0\) otherwise.
2 Properties of M\(K_{\phi }\)Es
Before stating the main result of this section, we first list some assumptions that will be used to derive it and do some comments on them.
Let \(\mathcal P \) be a parametric model satisfying Assumption 1 below.
Assumption 1
\(\mathcal P =\{P(\theta )=(p_1(\theta ),p_2(\theta ), \ldots , p_m(\theta ))^t, \; \theta \in \varTheta \} \subset \varDelta _m\), where \(\varTheta \subseteq \mathbb R ^k, m-k-1>0\) and \(p_1(.), p_2(.)\), ..., \(p_m(.):\varTheta \longrightarrow \mathbb R \) are known functions which are twice continuously differentiable in \(int \varTheta \).
For any \(\theta \in int \varTheta \), let \(D_1(P(\theta ))\) be the \(k \times m\) matrix of first order partial derivatives
and let \(D_2(P(\theta ))\) be \(k \times km\) matrix of second order partial derivatives
In addition to the above smoothness condition on the parametric model \(\mathcal P \), in order to avoid identifiability problems, we will also assume the following.
Assumption 2
If \(\theta _1,\, \theta _2 \in \varTheta \) are such that \(\theta _1 \ne \theta _2\), then \(P(\theta _1) \ne P(\theta _2)\).
Let \(Q=(q_1, q_2,\ldots ., q_m)^t, P=(p_1, p_2, \ldots , p_m)^t \in \varDelta _m\). From (2), the \(K_{\phi }\)-divergence between \(Q\) and \(P\) can be also defined as
where \(\varphi (x)=\phi (x)/x\). Now, from expression (3) it is clear that if \(\varphi \) is an increasing function, then \(K_{\phi }(Q,P)\ge 0, \forall \, P,Q \in \varDelta _m\); moreover, if \(\varphi \) is a strictly increasing function, then \(K_{\phi }(Q,P)\ge 0, \forall \, P,Q \in \varDelta _m\) with \(K_{\phi }(Q,P)= 0\) if and only if \(P=Q\).
Let \(\varDelta _{1m}\) be some subset of \(\varDelta _m\) and let \(P\in \varDelta _m\). Following Csiszár (1975) and Broniatowski and Keziou (2006), which gave a similar definition for \(\phi \)-divergences, the \(K_{\phi }\)-divergence between the set \(\varDelta _{1m}\) and \(P\), denoted by \(K_{\phi }(\varDelta _{1m},P)\), is defined as
Assume that \(K_{\phi }(\varDelta _{1m},P)<\infty \), then if \(Q_1\in \varDelta _{1m}\) is such that
then \(Q_1\) is called a \(K_{\phi }\)-projection of \(P\) on \(\varDelta _{1m}\). This projection may not exist, or may not be uniquely defined. If \(\phi \) is a strictly convex function and \(\varphi \) is a concave function (or \(\phi \) is convex and \(\varphi \) is strictly concave), then the function \(Q \in \varDelta _{1m} \rightarrow K_{\phi }(Q,P)\), for some fixed \(P\in \varDelta _m\), is strictly convex and thus, the projection of \(P\) on some convex set \(\varDelta _{1m} \subseteq \varDelta _{m}\) is uniquely defined, whenever it exists. Along this paper we will assume the following.
Assumption 3
\( K_{\phi }(P(\theta ),\pi )\) has a unique minimum at \(\theta _0 \in int \varTheta \).
Note that \(P(\theta _0)\), with \(\theta _0\) as defined in Assumption 3, is the \(K_{\phi }\)-projection of the population probability vector \(\pi \) on the parametric model \(\mathcal P \). Note that \(\theta _0=\theta _0(\pi ,\mathcal P ,\phi )\), but in order to keep the notation as simple as possible we have not included this dependence in the statement of Assumption 3, and it will be also skipped along the paper. Note also that, from Assumption 2, if \(\pi =P(\theta )\), for some \(\theta \in int \varTheta \), then \(\theta _0=\theta \) and \(\pi \) coincides with its \(K_{\phi }\)-projection on \(\mathcal P , \forall \phi \).
Before giving Assumption 3 we discussed some conditions for the uniqueness of the \(K_{\phi }\)-projection, whenever it exists. Note that the subset of \(\varDelta _{m} \) that we are considering is \(\varDelta _{1m}=\mathcal P \), which is given in a parametric form. In general, \(\mathcal P \) is not a convex set, and so the uniqueness of \(\theta _0\) in Assumption 3 is not guaranteed. It must be checked for each application, that is, for each particular family \(\mathcal P \). Next we give two examples.
Example 1
The parametric model
is convex, thus if \(Q \rightarrow K_{\phi }(Q,\pi )\) is strictly convex then the projection of \(\pi \) on \(\mathcal P \) is uniquely defined, whenever it exists. An important family of \(K_{\phi }\)-divergences, studied in Burbea and Rao (1982), is obtained by considering
If \(\phi \) is taken in this family, then \(Q \longrightarrow K_{\phi _{\tau }}(Q,\pi )\) is strictly convex for \(\tau \in [1,2]\). Clearly, if \(\pi \in \mathcal P \), then its \(K_{\phi _{\tau }}\)-projection is \(\pi \). If \(\pi =(\pi _1, \ldots , \pi _4)^t \notin \mathcal P \), then routine algebra shows that Assumption 3 holds \(\forall \tau \in [1,2)\), while for \(\tau =2\) Assumption 3 holds iff \(\pi _1+\pi _4-\pi _2-\pi _3>0\).
Example 2
Now let us consider the parametric model
This model is not convex, thus even if \(Q \rightarrow K_{\phi }(Q,\pi )\) is strictly convex, the uniqueness of the \(K_{\phi }\)-projection is not guaranteed. In fact, if \(\pi =(x,x,y,y,y,y)^t\), for some \(x,y>0\) with \(x+2y=0.5\), which clearly does not belong to the parametric model, and \(P(\theta _1,\theta _2)\) is a \(K_{\phi }\)-projection, then \(P(\theta _2,\theta _1)\) is also a \(K_{\phi }\)-projection, since \(K_{\phi }(P(\theta _1,\theta _2),\pi )=K_{\phi }(P(\theta _2,\theta _1),\pi )\). So, if \(x\) and \(y\) are such that \(\theta _1 \ne \theta _2\), there are two \(K_{\phi }\)-projections because in such a case \(P(\theta _1,\theta _2) \ne P(\theta _2,\theta _1)\). For example, for \(\pi =(0.4, 0.4, 0.05, 0.05, 0.05, 0.05)^t\) and \(\phi =\phi _2, P(\theta _1,\theta _2)\) with \(\theta _1=0.6382804\) and \(\theta _2=0.2274710\) is a \(K_{\phi }\)-projection; since \(\theta _1 \ne \theta _2\), it follows that \(P(\theta _2,\theta _1)\) is another \(K_{\phi }\)-projection.
Assumption 3 is usually assumed in papers on minimum \(\phi \)-divergence estimators. For example, it the analogue of Assumption A3(b) in White (1982), Assumptions 7 and 9 in Vuong and Wang (1993), Assumption 30 in Lindsay (1994) and Assumption (C.1) in Broniatowski and Keziou (2009). In the context of minimum \(K_{\phi }\)-divergence estimation, Assumption 3 is also implicitly assumed in Theorem 3.1 in Pérez and Pardo (2003a). Let \(\varDelta _m(\phi , \mathcal P )=\{\pi \in \varDelta _m\) such that Assumption 3 holds\(\}\).
Next assumption adds some smoothness requirements on \(\phi \) that will be used to derive the results.
Assumption 4
\(\phi :(0,1)\rightarrow \mathbb R \) is a twice continuously differentiable function, and it is such that \(\varphi (x)=\phi (x)/x\) is strictly increasing.
As in the Introduction, let \(X_1,X_2,\ldots ,X_n\) be \(n\) iid random variables taking values in \(\Upsilon _m\) according to a common probability law \(\pi \in \varDelta _m\). Let \(\hat{\pi }=(\hat{\pi }_1, \hat{\pi }_2,\ldots , \hat{\pi }_m)^t\) be the vector of relative frequencies,
Obviously, \(n=\sum _{i=1}^mN_i\). Thus, \((N_1, N_2, \ldots , N_m)\) has a multinomial distribution, \((N_1, N_2,\ldots , N_m) \sim \mathcal M (n;\pi )\).
Recall the definition (1) of M\(K_{\phi }\)E of \(\theta \). Next result gives some asymptotic properties of \(\hat{\theta }_{\phi }\). Specifically, it states that \(\hat{\theta }_{\phi }\) converges a.s. to \(\theta _0\) and that \(\sqrt{n}(\hat{\theta }_{\phi }-\theta _0)\) converges in law to a zero mean normal law. To derive these properties the model \(\mathcal P \) is not assumed to be correctly specified.
Theorem 1
Let \(\mathcal P \) be a parametric family satisfying Assumptions 1 and 2. Let \(\phi \) be a real function satisfying Assumption 4. Let \(X_1,X_2,\ldots ,X_n\) be iid random variables taking values in \(\Upsilon _m\) with common probability law \(\pi \in \varDelta _m(\phi ,\mathcal P )\). Let
where \(\mathbb D _2(\pi , P(\theta _0), \phi ) = \frac{\partial ^2}{\partial \theta ^2}K_{\phi }(\pi ,P(\theta _0)), w_2(\pi , P(\theta ), \phi )=(w_{21}(\pi , P(\theta ), \phi ),\) \( \ldots ,w_{2m}(\pi , P(\theta ), \phi ) )^t\),
and
Then,
-
(a)
For large \(n, \hat{\theta }_{\phi }\) exists, is unique and satisfies
$$\begin{aligned} \hat{\theta }_{\phi }=\theta _0+G(\pi , P(\theta _0), \phi )(\hat{\pi }-\pi )+o_P(n^{-1/2}). \end{aligned}$$ -
(b)
\(\hat{\theta }_{\phi } \stackrel{a.s.}{\longrightarrow } \theta _0\).
-
(c)
\(G(\hat{\pi }, P(\hat{\theta }_{\phi }), \phi ) \stackrel{a.s.}{\longrightarrow } G(\pi , P(\theta _0), \phi )\).
-
(d)
$$\begin{aligned} \sqrt{n}\left( \begin{array}{c} \hat{\pi }-\pi \\ \hat{\theta }_{\phi }-\theta _0 \end{array}\right) \stackrel{\mathcal{L }}{\longrightarrow }N_{m+k}(0, A \Sigma _{\pi } A^t), \end{aligned}$$
where \(A^t=A^t(\pi ,P(\theta _0), \phi )=(I_m, \; \;G(\pi ,P(\theta _0), \phi )^t)\). In particular,
$$\begin{aligned} \sqrt{n}( \hat{\theta }_{\phi }-\theta _0) \stackrel{\mathcal{L }}{\longrightarrow } N_{k}(0,G(\pi ,P(\theta _0), \phi )\Sigma _{\pi }G(\pi ,P(\theta _0), \phi )^t ) \end{aligned}$$(8) -
(e)
$$\begin{aligned} \sqrt{n}\left( \begin{array}{c} \hat{\pi }-\pi \\ P(\hat{\theta }_{\phi })-P(\theta _0) \end{array}\right) \stackrel{\mathcal{L }}{\longrightarrow }N_{2m}(0, B\Sigma _{\pi } B^t), \end{aligned}$$
where \(B^t=B^t(\pi ,P(\theta _0), \phi )=(I_m, \;\; G(\pi ,P(\theta _0), \phi )^tD_1(P(\theta _0)))\).
Remark 1
The statement in Theorem 1 does not assume that \(\pi \in \mathcal P \). Nevertheless, if \(\pi \in \mathcal P \), that is, if \(\pi =P(\theta _0)\), then the expression of \(G=G(\pi , P(\theta _0), \phi )\) simplifies to
where \(V=Diag(\varphi '(\pi _1), \ldots , \varphi '(\pi _m))\), and the results in Theorem 1 (a), (d) and (e) coincide with those in Theorems 1 and 2 and Corollary 1, respectively, in Pérez and Pardo (2004), which give the consistency and asymptotic normality of \(\hat{\theta }_{\phi }\) when \(\pi \in \mathcal P \).
Remark 2
Theorem 1 (a) states that the existence and uniqueness of \(\hat{\theta }_{\phi }\) is only ensured for large \(n\), even if the model \(\mathcal P \) is true. This is clear from Examples 1 and 2: (existence) Assume that \(\mathcal P \) is as defined in (4), \(\phi =\phi _2\) and \(\pi \) satisfies \(\pi _1+\pi _4-\pi _2-\pi _3>0\), which ensures that the \(\phi _2\) projection of \(\pi \) on \(\mathcal P \) exists and is unique; but \(\hat{\theta }_{\phi _2}\) only exists for those samples with \(\hat{\pi }_1+\hat{\pi }_4-\hat{\pi }_2-\hat{\pi }_3>0\), which can only ensured for large \(n\). (uniqueness) Assume that \(\mathcal P \) is as defined in (6), \(\phi =\phi _2\) and \(\pi =(1/6,\ldots ,1/6)^t \notin \mathcal P \). In this case there is a unique \(\phi \)-projection, \(P(1/3,1/3)\); but if \(\hat{\pi }=(0.4, 0.4, 0.05, 0.05, 0.05, 0.05)^t\), as we saw in Example 2, \(\hat{\theta }_{\phi }\) is not uniquely defined. The probability of obtaining this estimation for \(\pi \) goes to zero as the sample size increases.
As a consequence of Theorem 1, we give the following result, which states the asymptotic behaviour of \(K_{\phi _1}(\hat{\pi },P(\hat{\theta }_{\phi _2}))\), for arbitrary \(\phi _1\) and \(\phi _2\), that may be different.
Corollary 1
Let \(\mathcal P \) be a parametric family satisfying Assumptions 1 and 2. Let \(\phi _1\) and \(\phi _2\) be two real functions satisfying Assumption 4. Let \(X_1,X_2,\ldots ,X_n\) be iid random variables taking values in \(\Upsilon _m\) with common probability law \(\pi \in \varDelta _m(\phi _2,\mathcal P )\). Let
Then,
-
(a)
\(K_{\phi _1}(\hat{\pi },P(\hat{\theta }_{\phi _2})) \stackrel{a.s.}{\longrightarrow }K_{\phi _1}(\pi ,P(\theta _0))\).
-
(b)
For \(\pi =P(\theta _0) \in \mathcal P \),
$$\begin{aligned} n K_{\phi _1}(\hat{\pi },P(\hat{\theta }_{\phi _2})) \stackrel{\mathcal{L }}{\longrightarrow } \sum _{j=1}^{r} \lambda _{j} \chi ^2_{1j}, \end{aligned}$$where \(\chi ^2_{11}, \ldots , \chi ^2_{1r}\) are independent chi-square variates with one degree of freedom and the set \(\{\lambda _{j}\}\) are the eigenvalues of the matrix \(V_1\Sigma _1\), with
$$\begin{aligned} V_1&= Diag(\varphi _1'(\pi _1), \ldots , \varphi _1'(\pi _m))\\ \Sigma _1&= (I_m\,\, -I_m)B\Sigma _{\pi }B^t\left( \begin{array}{l} I_m\\ -I_m \end{array} \right) \end{aligned}$$and \(B^t=B^t(\pi ,P(\theta _0), \phi _2)\) is as defined in Theorem 1 (e).
-
(c)
For \(\pi \in \varDelta _m-\mathcal P \),
$$\begin{aligned} \sqrt{n}\{K_{\phi _1}(\hat{\pi },P(\hat{\theta }_{\phi _2}))- K_{\phi _1}(\pi ,P(\theta _{0}))\} \stackrel{\mathcal{L }}{\longrightarrow } N(0,\varrho ^2), \end{aligned}$$where \(\varrho ^2=a^t \Sigma _{\pi } a\), with \(a=a(\mathcal P ,\theta _0,\phi _1,\phi _2)\) defined as
$$\begin{aligned} a^t&= W_2^t\{I_m-D_1(P(\theta _0))^tG(\pi ,P(\theta _0),\phi _2)\}+\\&W_1^t\{V_1-V_2D_1(P(\theta _0))^tG(\pi ,P(\theta _0),\phi _2)\},\\ V_2&= Diag(\varphi _1'(p_1(\theta _0)), \ldots ,\varphi _1'(p_m(\theta _0))),\\ W_1&= \pi -P(\theta _0),\\ W_2^t&= (\varphi _1(\pi _1)-\varphi _1(p_1(\theta _0)), \ldots , \varphi _1(\pi _m)-\varphi _1(p_m(\theta _0))).\\ \end{aligned}$$
Remark 3
Part (b) of the above corollary has been previously proven in Pérez and Pardo (2003a). They have also shown that a similar result to that given in part (b) is also true when \(\theta \) is estimated through its maximum likelihood estimator. Moreover, they have shown that if \(\phi _1(x)=x \log x, \phi _1(x)=\phi _2(x)\) or \(\theta \) is estimated through its maximum likelihood estimator, and \(\pi =P(\theta _0) \in \mathcal P \), then \(D_{\phi _1}(\hat{\pi },P(\hat{\theta }_{\phi _2}))\stackrel{\mathcal{L }}{\longrightarrow } \chi ^2_{m-k-1}\), that is to say, \(T\) is asymptotically free distributed.
3 An application to testing goodness-of-fit
Now we consider the problem of testing goodness-of-fit to the parametric family \(\mathcal P \),
Many tests for testing \(H_0\) are based on measuring discrepancies between two estimators of a function characterizing a probability law. A possible way of measuring such discrepancies is by considering
for some functions \(\phi _1\) and \(\phi _2\) satisfying Assumption 4. Pérez and Pardo (2003a) have studied the test that rejects \(H_0\) for large values of \(T\). The resulting test is consistent against fixed alternatives. Corollary 1 (b) shows that this test statistic is not distribution free, even asymptotically. The results obtained on M\(K_{\phi }\)Es lead us to propose two consistent bootstrap estimators of the null distribution of the test statistic \(T\).
First, observe that the asymptotic null distribution of the test statistic \(T\) is unknown because the matrix \(V_1\Sigma _1\) is unknown, since it depends on \(\pi =P(\theta _0)\), which is unknown. Since, under certain conditions, the M\(K_{\phi }\)E converges to a well-defined limit, whether the model in \(H_0\) is true or not, we could estimate the asymptotic null distribution of \(T\) through the conditional distribution of \(\widetilde{T}=\sum _{j=1}^r\hat{\lambda }_j \chi ^2_{1j}\), given \(X_1,\ldots ,X_n\), where the set \(\{\hat{\lambda }_{j}\}\) are the eigenvalues of the matrix \(\hat{V}_1\hat{\Sigma }_1\), which is defined as \(V_1\Sigma _1\) by replacing \(\theta \) and \(\pi \) by \(\hat{\theta }_{\phi }\) and \(P(\hat{\theta }_{\phi })\), respectively. This way of estimating the null distribution of a statistic it is usually called a bootstrap in the limit estimation, since following the philosophy of the bootstrap method, which basically consists of replacing all unknowns by suitable estimators, we have replaced the unknown quantities in the asymptotic null distribution of \(T\) by consistent estimators. Next we study the consistency of this null distribution estimator.
Theorem 2
Under conditions in Corollary 1,
where \(T_0=\sum _{j=1}^{r}\lambda _{0j} \chi ^2_{1k}, \chi ^2_{11}, \chi ^2_{12}, \ldots ,\chi ^2_{1r}\) are independent chi-square variates with \(1\) degree of freedom, \(\lambda _{01}, \lambda _{02}, \ldots , \lambda _{0r}\) are the non-zero eigenvalues of \({V}_{01}{\Sigma }_{01}\), which is defined as \(V_1\Sigma _1\) by replacing \(\theta \) and \(\pi \) by \({\theta }_{0}\) and \(P({\theta }_{0})\), respectively.
The result in Theorem 2 is true whether or not \(H_0\) is true. If \(H_0\) is indeed true then \(\lambda _{0j}=\lambda _{j}, 1 \le k \le j \), and thus by Corollary 1 (b), \(\widetilde{T}\) estimates consistently the null distribution of \(T\). The next corollary states this result.
Corollary 2
Under conditions in Corollary 1, if \(H_0\) is true,
Let \(0<\alpha <1\). As a consequence of Corollary 2, the test
where \(\tilde{t}_{\alpha }\) is the upper \(\alpha \) percentile point of the conditional distribution of \(\widetilde{T}\), given the data, is asymptotically correct for testing \(H_0\) in the sense that asymptotically it has the desired level.
In practice, since the distribution of a linear combination of \(\chi ^2\) variates is unknown, the conditional distribution of \(\widetilde{T}\) must be approximated either by simulation or by some numerical method (see for example Kotz et al. 1967; Castaño-Martínez and López-Blázquez 2005).
Another way of approximating the null distribution of \(T\) is through its null bootstrap distribution, which is the conditional distribution of \(T^*= K_{\phi _1}(\hat{\pi }^*, P(\hat{\theta }_{\phi _2}^*))\), given \(X_1, \ldots , X_n\), where \(\hat{\pi }^*\) is defined as \(\hat{\pi }\) with \(X_1, X_2,\ldots , X_n \) replaced by \(X_1^*, X_2^*,\ldots ,X_n^*\), which are iid random variables taking values in \(\Upsilon _m\) with common probability law \(P(\hat{\theta }_{\phi _2})\) and \(\hat{\theta }_{\phi _2}^*=\arg \min _{\theta } K_{\phi _2}(\hat{\pi }^*,P({\theta }))\). The next theorem states that \(\widetilde{T}\) and \(T^*\) both have the same weak limit, and therefore, similar consequences to those derived from Theorem 2 can be given now for \(T^*\).
Theorem 3
Under conditions in Corollary 1,
where \(T_0\) is as defined in Theorem 2.
Corollary 3
Under conditions in Corollary 1, if \(H_0\) is true,
Let \(0<\alpha <1\). As a consequence of Corollary 3, the test
where \(\tilde{t}^*_{\alpha }\) is the upper \(\alpha \) percentile point of the conditional distribution of \({T}^*\), given the data, is asymptotically correct for testing \(H_0\) in the sense that asymptotically it has the desired level.
In practice, the null bootstrap distribution of \(T\) must be approximated by simulation.
Remark 4
The results in this section assume that the parameter \(\theta \) is estimated through its M\(K_{\phi }\)E. Nevertheless, the results continue to be true, in the sense that both bootstrap distribution estimators provide a consistent null distribution estimator of \(T=K_{\phi _1}(\hat{\pi }, P(\hat{\theta })) \), if \(\theta \) is estimated through any other estimator \(\hat{\theta }\) satisfying similar properties to those of the M\(K_{\phi }\)E: \(\hat{\theta }\) converges to a well defined limit \(\theta _0\) and, under \(H_0, \sqrt{n}(\hat{\theta }-\theta _0)\) is asymptotically normal with variance matrix continuous as a function of the parameter. For example, if \(\theta \) is estimated by means of its maximum likelihood estimator (see for example Jiménez-Gamero et al. 2011).
Remark 5
As an application of the results in Sect. 2, this section proposes two bootstrap methods (a bootstrap in the limit estimator and a parametric bootstrap estimator) to consistently estimate the null distribution of the test statistic \(T\). Other bootstrap methods have been proposed in the statistical literature such as the weighted bootstrap (see Bouzebda and Cherfi 2012 for a recent application). The results in Sect. 2 could be used to propose consistent null distribution estimators based on other bootstrap procedures.
3.1 A numerical example
The results in Theorems 2 and 3 tell us that the conditional distribution of both \(\widetilde{T}\) and \(T^*\), given the data, consistently approximates the null distribution of \(T\), that is to say, they are asymptotically equivalent. In order to try to answer which estimator should be used in a practical situation, that is to say, for a finite sample size, we have conducted a simulation experiment. Next we briefly describe it and display the obtained results. All computations in this paper have been performed using programs written in the R language. We have generated \(10{,}000\) samples of size \(n=50\) from the null model (4), all of them with \(\theta =\theta _0=0.5\). So, in this case \(m=4\) and \(k=1\). For each sample, that is, for \(s=1,2,\ldots ,10{,}000\), we have done the following:
1. We have calculated the statistics
where \(\hat{\pi }(s)\) is the vector of relative frequencies for the \(s\)th sample, \(\phi _1(x)\) and \(\phi _2(x)\) are as defined in (5) and \(\hat{\theta }_{ML}\) is the maximum likelihood estimator of \(\theta \). As noted in Remark 3, the asymptotic null distribution of \(T_1\) is \(\chi ^2_{2}\), that is, \(T_1\) is asymptotically distribution free. By contrast, the asymptotic null distribution of the test statistics \(T_2\) and \(T_3\) is that of a linear combination of \(\chi ^2\) variates.
To define \(K_{\phi }(P, Q)\) in the introduction we assumed that \(P, Q \in \varDelta _m\), which implies that \(p_{i}, q_{i} >0, i=1,2,\ldots m\). Since \(n\hat{\pi } \sim \mathcal M (n; \pi )\), where \(\pi \) is the common probability law generating the data, some components of \(\hat{\pi }\) may be equal to 0 with a positive probability. Hence, in practice, one must define \(\frac{\phi (x)}{x}\) when \(x=0\). If \(\phi =\phi _2\) then \(\frac{\phi _2(x)}{x}=x-1\), that is a function well defined at \(x=0\). If \(\phi =\phi _1\) then \(\frac{\phi _2(x)}{x}=\log x\). In this case we have taken \(0 \log 0=0\) and \(x\log 0 =-10^6, \forall x \in (0,1)\).
2. We have calculated the asymptotic approximation to the true \(p\)-value of the observed test statistic \(T_1\) as follows
where \(Y \sim \chi ^2_{2}\); for \(T_2\) and \(T_3\) we have approximated the bootstrap in the limit estimator to the true p-value as follows: we have approximated the distribution of \(\sum _{i=1}^{r}\hat{\lambda }_j \chi ^2_{1j}\) by that of (see Rao and Scott 1981):
-
(a)
\(Y_a=\hat{\lambda } \chi _r^2\), where \(\hat{\lambda }=\sum _{j=1}^{r}{\lambda _j(\hat{\theta })}/r\),
-
(b)
\(Y_b=\lambda _{(1)}(\hat{\theta }) \chi _r^2\), where \(\lambda _{(1)}(\hat{\theta }) \ge \lambda _{(2)}(\hat{\theta }) \ge \cdots \ge \lambda _{(r)}(\hat{\theta })\),
-
(c)
\(Y_c=\hat{\lambda }(1+\xi ^2) \chi _{\nu }^2\) where \(\nu =r/(1+\xi ^2)\) and \(\xi ^2=\sum _{j=1}^r(\hat{\lambda }_{j}(\hat{\theta })-\hat{\lambda })^2/r\hat{\lambda }\).
In this way we have obtained the following three estimators the true \(p\)-value of \(T_2(s)\):
We have also approximated it by simulation, denoting by \(p_{2, asym}(s)\) the resulting approximation. Analogously, we have also calculated \(p_{3, asym, a}(s), p_{3, asym, b}(s),\) \( p_{3, asym, c}(s)\) and \(p_{3, asym}(s)\) for \(T_3\).
3. We have computed the bootstrap \(p\)-value for each observed test statistic
where \(T_i^*\) is the bootstrap version of \(T_i, i=1,2,3\). To approximate \(\hat{p}_{i, boot}(s)\) we have generated \(B=\hbox {1,000}\) bootstrap samples, that is, we have generated \(B\) independent samples from the model \(P(\hat{\theta }(s))\), with \(\hat{\theta }=\hat{\theta }_{ML}\) for statistics \(T_1\) and \(T_2\) and \(\hat{\theta }=\hat{\theta }_{\phi _2}\) for \(T_3\). Then we have calculated the test statistic \(T_i\) for each bootstrap sample obtaining \(T^{*1}_{i},T^{*2}_{i},\ldots T^{*B}_{i}, i=1,2,3\). Finally, we have taken
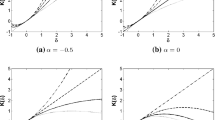
If the considered approximations were exact, then the calculated \(p\)-values would be a random sample from a uniform distribution on the interval (0,1). So, to measure the performance of the considered approximations, we have calculated the Kolmogorov–Smirnov test statistic of uniformity (KS) for each set of 10,000 values obtained in each approximation and for each test statistic. We have repeated the above experiment for sample sizes \(n=100\) and \(n=200\), and for the null model in (6) with \(\theta _0=(1/3, 1/3)\). For this second model, \(m=6\) and \(k=2\). Table 1 displays the \(p\)-values of the observed values of the KS test statistic. Figures 1 and 2 display the histogram of the \(p\)-values for models (4) and (6), respectively, both with \(n=200\).

Histograms of the \(p\)-values of \(T_1, T_2\) and \(T_3\) (from top to bottom) for model (4) with \(n=200\)

Histograms of the \(p\)-values of \(T_1, T_2\) and \(T_3\) (from top to bottom) for model (6) with \(n=200\)
Looking at Table 1 we see that the bootstrap approximation is much better than the bootstrap in the limit approximation to the null distribution of the considered test statistics, for all the considered sample sizes and all the considered null models. For the cases where it is not possible to exactly calculate the asymptotic null distribution of the test statistics, that is, for \(T_2\) and \(T_3\), we see that, in general, the approximations in Rao and Scott (1981) do not work satisfactorily, since they are rather far from the true asymptotic null distribution. All these assertions can be better seen by looking at Figs. 1 and 2.
Remark 6
Section 3 proposes two consistent estimators of the null distribution of the test statistic \(T\). Section 3.1 tries to answer the question of which estimator could be used in practice. The numerical results in Sect. 3.1 tell us that the bootstrap gives better results than the bootstrap in the limit estimator, at least for small to moderate sample sizes. Another question of great practical interest is that of the choice of the \(K_{\phi }\)-divergence. This topic has been numerically studied in Pérez and Pardo (2003b).
4 An application to model selection
Now we consider an application to the model selection problem, which is quite related to that of goodness-of-fit. Given a set of models, the model selection problem consists of deciding which model best fits the data. In the goodness-of-fit setting, given a model, one must decide if the data comes from this model or not; by contrast, in model selection, the problem is that of deciding which model is closest to the data, even if such model does not fit the data. In the statistical literature there is two main approaches to deal with the model selection problem: one of them is based on choosing that model optimizing certain criterion -usually the criterion employed is some sort of goodness-of-fit statistic plus a penalization term for model complexity-; and the other one, introduced by Vuong (1989), is based on testing. There are many papers giving arguments in favor of each of these approaches. Here we are not going to discuss which of the approaches is better, but only to show the applicability of our results in Sect. 2 to this problem. Specifically, we will consider the approach based on testing.
Here we consider the case where the data are discrete or grouped with a finite number of cases or groups. For this case, Vuong and Wang (1993) studied a class of tests for model selection based on chi-square type statistics. The chi-square discrepancy between two probability vectors is a particular case of the divergence measures considered in this paper when \(\phi =\phi _2\) and one of the arguments of the \(K_{\phi }\)-divergence is \(\pi _0=(1/m, \ldots ,1/m)^t\) (see Remark 2.2 in Pérez and Pardo 2006). Because of this fact, the results in Vuong and Wang (1993) could be extended by considering as closeness measure any \(K_{\phi }\)-divergence as follows.
For simplicity in exposition and notation we will only consider the case of two competing models. The case of three or more competing models can be dealt by following the approach in Shimodaira (1998) as described in Jiménez-Gamero et al. (2011). Suppose that there are two possibly misspecified parametric families \(\mathcal P =\{P(\theta )=(p_1(\theta ),p_2(\theta ), \ldots , p_m(\theta ))^t, \; \theta \in \varTheta \} \subset \varDelta _m\), where \(\varTheta \subseteq \mathbb R ^k, m-k-1>0\) and \(p_1(.), p_2(.)\), ..., \(p_m(.)\) are known real functions, and \(\mathcal Q =\{Q(\gamma )=(q_1(\gamma ),q_2(\gamma ), \ldots , q_m(\gamma ))^t, \; \gamma \in \Gamma \} \subset \varDelta _m\), where \(\Gamma \subseteq \mathbb R ^r, m-r-1>0\) and \(q_1(.), q_2(.)\), ..., \(q_m(.)\) are known real functions. Let \(\phi , \phi _1\) and \(\phi _2\) be three possibly different real functions satisfying Assumption 4. Let \({\theta }_{0}=\arg \min _{\theta } K_{\phi _1}({\pi },P(\theta ))\) and \({\gamma }_{0}=\arg \min _{\gamma } K_{\phi _2}({\pi },Q(\gamma ))\). The problem is that of constructing a test for \(H_{01}: \; K_{\phi }({\pi },P(\theta _0))=K_{\phi }({\pi },Q(\gamma _0))\) against the alternatives \(H_{P1}:\; K_{\phi }({\pi },P(\theta _0)) < K_{\phi }({\pi },Q(\gamma _0))\) or \(H_{Q1}:\; K_{\phi }({\pi },P(\theta _0))> K_{\phi }({\pi },Q(\gamma _0))\). Such a test is of practical interest since rejection of \(H_0\) in favor of \(H_P\) (\(H_Q\)) would indicate that \(P(\theta _0) (Q(\gamma _0))\) is a better approximation to the true distribution \(\pi \).
The quantity \(K_{\phi }({\pi },P(\theta _0))-K_{\phi }({\pi },Q(\gamma _0))\) is unknown, but from Corollary 1 (a), it can be consistently estimated through \(T=K_{\phi }(\hat{\pi },P(\hat{\theta }_{\phi _1}))-K_{\phi }(\hat{\pi },Q(\hat{\gamma }_{\phi _2}))\). This difference converges to 0 under the null hypothesis \(H_0\), but it converges to a strictly negative or positive constant under alternatives. Thus, the null hypothesis \(H_{01}\) should be rejected for “large” or “small” values of \(T\). In order to decide what is “large” or “small” we must calculate the null distribution of \(T\), or al least a consistent approximation to it. Since the exact null distribution of \(T\) is clearly unknown, we approximate it trough its asymptotic null distribution. The next result gives it as well as the behaviour of \(T\) under the alternatives for large samples.
Theorem 4
Let \(\mathcal P \) and \(\mathcal Q \) be two parametric families satisfying Assumption 1, such that \(\mathcal P \cap \mathcal Q =\emptyset \). Let \(\phi , \phi _1\) and \(\phi _2\) be real functions satisfying Assumption 4. Let \(X_1,X_2,\ldots ,X_n\) be iid random variables taking values in \(\Upsilon _m\) with common probability law \(\pi \in \varDelta _m(\phi _1,\mathcal P )\cap \varDelta _m(\phi _2,\mathcal Q )\). Let
where \(\hat{\sigma }_1^2=\{a(\phi ,\phi _1,\hat{\pi },P(\hat{\theta }_{\phi _1}))- a(\phi ,\phi _2,\hat{\pi },Q(\hat{\gamma }_{\phi _2}))\}^t\Sigma _{\hat{\pi }}\{a(\phi ,\phi _1,\hat{\pi },P(\hat{\theta }_{\phi _1}))- a(\phi ,\phi _2,\hat{\pi },Q(\hat{\gamma }_{\phi _2}))\},\)
and \(a(\phi ,\phi _2,\hat{\pi },Q(\hat{\gamma }_{\phi _2}))\) is analogously defined. Then,
-
(a)
Under \(H_{01}, K\stackrel{\mathcal{L }}{\longrightarrow } N(0,1).\)
-
(b)
Under \(H_{P1}, K\stackrel{a.s.}{\longrightarrow } -\infty .\)
-
(c)
Under \(H_{Q1}, K\stackrel{a.s.}{\longrightarrow } +\infty .\)
Thus, according to the result in Theorem 4, for fixed \(\alpha \in (0,1)\), the decision rule is
-
if \(K<-Z_{1-\alpha /2}\) then select model \(\mathcal P \),
-
if \(K>Z_{1-\alpha /2}\) then select model \(\mathcal Q \),
-
if \(|K|\le Z_{1-\alpha /2}\) then conclude that there is not sufficient evidence to discriminate between the competing models \(\mathcal P \) and \(\mathcal Q \),
where \(\Phi (Z_{1-\alpha /2})={1-\alpha /2}, \Phi \) being the distribution function of a univariate normal standard distribution, \(N(0,1)\).
Remark 7
To prove the convergence to a normal law of the test statistic \(K\) when \(H_{01}\) is true, we have assumed that \(\mathcal P \cap \mathcal Q =\emptyset \). This let us ensure that the asymptotic variance of \(\,T=K_{\phi }(\hat{\pi },P(\hat{\theta }_{\phi _1}))-K_{\phi }(\hat{\pi },Q(\hat{\gamma }_{\phi _2}))\) is positive. Otherwise, such a variance can be null and in this case \(\sqrt{n}D\) is not asymptotically normally distributed.
When the population generating the data is continuous the above procedure requires two choices: the number of intervals or categories and the intervals themselves. In order to reduce the arbitrariness due to these two choices, we can proceed as suggested in the paper by de la Horra (2008), which consist of first applying the integral transformation to the original data; then compare the relative frequencies of the number of observations in each interval \(u_i=(\frac{i-1}{m},\frac{i}{m}], 1\le i \le m\), to \(\pi _{0m}=(1/m,\ldots , 1/m)^t\), for some fixed \(m\); and finally select the model which is closest to \(\pi _{0m}\). To measure the closeness, de la Horra (2008) considers the chi-square discrepancy. As observed before, this is a particular case of the divergence measures considered in this paper, and thus the above procedure could be extended by considering as a closeness measure any \(K_{\phi }\)-divergence. A main difference between the approach de la Horra (2008) and the one in this paper is that the model selection problem is studied in de la Horra (2008) from a Bayesian point of view, while our study adopts a frequentist point of view.
Now we describe in detail the above procedure. Suppose that there are two possibly misspecified parametric families \(\mathcal P =\{F(x;\theta ), \; \theta \in \varTheta \}\), where \(\varTheta \subseteq \mathbb R ^k\), and \(\mathcal Q =\{G(x;\gamma ), \; \gamma \in \Gamma \}\), where \(\Gamma \subseteq \mathbb R ^r\), where \(F(\cdot ;\theta ), \; G(\cdot ;\theta ):\mathbb R \rightarrow [0,1]\) are continuous cumulative distribution functions (cdf). Let \(X_1,\ldots ,X_n\) denote the available data, which are assumed to be iid from a continuous population with unknown cdf \(H\). Let \(\hat{\theta }=\hat{\theta }(X_1,\ldots ,X_n)\) and \(\hat{\gamma }=\hat{\gamma }(X_1,\ldots ,X_n)\) be such that \(\sqrt{n}(\hat{\theta }-\theta )=O_P(1)\) and \(\sqrt{n}(\hat{\gamma }-\gamma )=O_P(1)\), for some \(\theta \in \varTheta , \gamma \in \Gamma \). Let
\(\hat{\pi }_{P}(\hat{\theta })=(\hat{\pi }_{P1}(\hat{\theta }), \ldots , \hat{\pi }_{Pm}(\hat{\theta }))^t, \hat{\pi }_{Q}(\hat{\gamma })=(\hat{\pi }_{Q1}(\hat{\gamma }), \ldots , \hat{\pi }_{Qm}(\hat{\gamma }))^t\), with
\(1\le i \le m\). Let \(\phi \) a function satisfying Assumption 4. For the problem of testing \(H_{02}: K_{\phi }({\pi }_{P}({\theta }), \pi _{0m})\,{=}\,K_{\phi }({\pi }_{Q}({\gamma }), \pi _{0m})\) against the alternatives \(H_{P2}: K_{\phi }({\pi }_{P}({\theta }), \pi _{0m})<K_{\phi }({\pi }_{Q}({\gamma }), \pi _{0m})\) or \(H_{Q2}: K_{\phi }({\pi }_{P}({\theta }), \pi _{0m})>K_{\phi }({\pi }_{Q}({\gamma }), \pi _{0m})\), we consider the statistic \(S=K_{\phi }(\hat{\pi }_{P}(\hat{\theta }), \pi _{0m})-K_{\phi }(\hat{\pi }_{Q}(\hat{\gamma }), \pi _{0m})\). In order to justify \(S\) as a test statistic for the above testing problem, the next result gives some properties of \(S\).
Theorem 5
Let \(X_1,\ldots ,X_n\) be iid from a continuous population. Let \(\mathcal P =\{F(x;\theta ), \; \theta =(\theta _1, \ldots , \theta _k)^t \in \varTheta \}, \varTheta \subseteq \mathbb R ^k\), and \(\mathcal Q =\{G(x;\gamma ), \; \gamma =(\gamma _1,\ldots , \gamma _r)^t \in \Gamma \}, \Gamma \subseteq \mathbb R ^r\), where \(F(\cdot ;\theta ), \; G(\cdot ;\theta ):\mathbb R \rightarrow [0,1]\) are continuous cdf. Assume that \(\mathcal P \cap \mathcal Q =\emptyset \). Let \(\phi \) a function satisfying Assumption 4. Let \(\hat{\theta }=\hat{\theta }(X_1,\ldots ,X_n)\) and \(\hat{\gamma }=\hat{\gamma }(X_1,\ldots ,X_n)\) be such that
for some \(\theta \in \varTheta , \gamma \in \Gamma \), where \({\pi }_{P}(\theta )=E\{\hat{\pi }_{P}(\theta )\}\) and \({\pi }_{Q}(\gamma )=E\{\hat{\pi }_{Q}(\gamma )\}\). Let \(Z= \sqrt{n}\{K_{\phi }(\hat{\pi }_{P}(\hat{\theta }), \pi _{0m})-K_{\phi }(\hat{\pi }_{Q}(\hat{\gamma }), \pi _{0m})-K_{\phi }({\pi }_{P}({\theta }), \pi _{0m})+K_{\phi }({\pi }_{Q}({\gamma }), \pi _{0m})\}\), then
where
\(c^t=(a^t, -b^t), a^t=(a_1, \ldots , a_m), b^t=(b_1, \ldots , b_m)\),
\(1\le i \le m\), and \(D\) is the following \(2m \times (k+r)\)-matrix
Remark 8
Note that
\(1\le i\le m\), where \(H\) is the true cdf of the data \(X_1,\ldots , X_n\).
Corollary 4
Under the assumptions in Theorem 5, if \(\hat{\sigma }_2^2\) is a consistent estimator of \(\sigma ^2_2\) and
then
-
(a)
Under \(H_{02}, W\stackrel{\mathcal{L }}{\longrightarrow } N(0,1).\)
-
(b)
Under \(H_{P2}, W\stackrel{P}{\longrightarrow } -\infty .\)
-
(c)
Under \(H_{Q2}, W\stackrel{P}{\longrightarrow } +\infty .\)
Therefore, according to the result in the above corollary, a decision rule similar to that given previously, could be given based on the statistic \(W\). A similar observation to that done in Remark 7 can be done on the assumption \(\mathcal P \cap \mathcal Q =\emptyset \) for this procedure.
Finally, in order to apply the result in Corollary 4 we need a consistent estimator of \(\sigma ^2_2\). For example, \(\hat{\sigma }_2^2\) can be obtained from \(\sigma ^2_2\) by replacing the unknown quantities, \(\theta , \gamma \) and \(H\), by suitable estimators such as \(\hat{\theta }, \hat{\gamma }\) and \(H_n\), the empirical distribution function of the available data, respectively.
4.1 A numerical example
To illustrate the two proposed methods, we consider the classical problem of choosing between a log-normal model, with density
and an exponential model, with density,
The interest in this problem stems from the fact that both models are quite close, and thus it is hard to discriminate between them.
This problem has been studied by many authors. Among them, we cite Vuong and Wang (1993) and Jiménez-Gamero et al. (2011) since their approach to model selection is, in a certain sense, close to that studied in this paper. Specifically, Vuong and Wang (1993) have used the \(\chi ^2\) statistic, and Jiménez-Gamero et al. (2011) have considered several test statistics based on \(\phi \)-divergences, which contain the \(\chi ^2\) statistic as a particular case. Here we follow similar steps to those in these two papers. The main difference is that here we consider the two approaches described above, both based on \(K_{\phi }\)-divergences. For the first approach, the real line is partitioned into 4 intervals \(\{ (c_{i-1}, c_i], \;i=1,\ldots ,4\}\), with \(c_0=0, c_1=0.1, c_2=1, c_3=3\) and \(c_4=\infty \). \(\theta =(\mu , \varsigma )\) and \(\gamma \) are estimated by their minimum \(K_{\phi _2}\)-divergence estimators. For the second approach, the parameters in each model are estimated through their maximum likelihood estimates for the original -not grouped- data, that is, \(\hat{\gamma }_{ML}=\bar{X}, \hat{\mu }_{ML}=\bar{Y}\) y \(\hat{\varsigma }^2_{ML}=S^2_Y\), with \(Y_i=\ln X_i, 1\le i \le n\), and the interval [0,1] was divided into \(m=4,10,15,20\) equal length intervals. For each approach, we considered the test statistics \(K\) and \(W\) with \(\phi (x)=\phi _{\tau }(x)\) as defined in (5), for \(\tau \in \{1,\, 1.1,\, 1.2,\, 1.3,\, 1.4,\, 1.5,\, 1.6,\, 1.7,\, 1.8,\, 1.9,\, 2\}\). To study the finite sample behaviour of these procedures, we carried out the following simulations. We generated 10,000 samples of size \(n\in \{100, 250,500, \hbox {1,000}\}\) from
for some fixed \(\epsilon \in [0,1]\). For these choices of \(\gamma , \mu \) and \(\varsigma \) both populations, the exponential and the log-normal, have the same means and variances. For each sample, we calculated the test statistics \(K\) and \(W\), defined in (9) and (10), respectively, for each value of \(\tau \) and \(m\). Finally we computed the percentage of times selecting each possible decision (log-normal, exponential, no discrimination), for \(\alpha =0.05\). The experiment was done for \(\epsilon \in \{0, 0.25, 0.5, 0.75, 1\}\). Tables 2, 3, 4 and 5 display the results obtained. Table 6 displays the true population values of the quotient \(C_1=[K_{\phi _{\tau }}(\pi , P(\theta _0))-K_{\phi _{\tau }}(\pi , Q(\gamma _0))]/\sigma _1\), where \(\theta _0\) and \(\gamma _0\) minimize \(K_{\phi _2}(\pi ,P(\theta ))\) and \(D_{\phi _2}(\pi ,Q(\gamma ))\), respectively, which according to Corollary 1 (a), is the a.s. limit of \(K/\sqrt{n}\). Table 7 displays the analogue quantities for the second procedure, that is, \(C_2=[K_{\phi }({\pi }_{P}({\theta }), \pi _{0m})-K_{\phi }({\pi }_{Q}({\gamma }), \pi _{0m})]/\sigma _2\). These theoretical values will help us to interpret the simulation results. Looking at Tables 2, 3, 4 and 5 we see that the first method gave best results, in terms of giving a higher percentage of correct classifications. As the sample size increases the percentage of correct classifications increase, decreasing the number of no decisions. Since there is small differences in the values in Tables 6 and 7, it seems that the speed of convergence to the normal law is highest for the first method than for the second one. Next we comment on the first method: for the exponential law the results seem almost no sensitive to the choice of the function \(\phi \) in the \(K_{\phi }\)-divergence, while for the log normal model best results are obtained for \(\tau \ge 1.6\). This observation was also given in a paper (Pérez and Pardo 2003b) for testing goodness-of-fit for the single null hypothesis \(H_0:\;\pi =\pi _0=(1/m,\ldots ,1/m)\), where the power for \(\tau =1.8\) was as efficient as the \(\phi \)-divergence for \(\lambda =2/3\), the Cressie–Read statistic.
As we told before, Jiménez-Gamero et al. (2011) carried out a similar experiment based on \(\phi \)-divergences. So it is natural to wonder whether the use of \(K_{\phi }\)-divergencies has some advantage over the use of \({\phi }\)-divergencies. The best percentages of correct classifications when \(\epsilon =0,1\) are quite similar for both methods. The main difference resides in the intermediate cases, that is, for \(\epsilon =0.25, 0.5, 0.75\), where better results were obtained by using \(K_{\phi }\)-divergences.
5 Proofs
Before proving the main results in the previous sections we introduce some additional notation and give a preliminary lemma.
Note that if Assumptions 1 and 4 hold, then Assumption 3 implies that
and that the \(k \times k\) matrix
is positive definite,
where \(\otimes \) denotes the Kronecker product,
with \(\varphi '(x)=\frac{\partial }{\partial x}\varphi (x)\) and
with \(\varphi ''(x)=\frac{\partial ^2}{\partial x^2}\varphi (x)\).
Lemma 1
Let \(\mathcal P \) be a parametric family satisfying Assumption 1. Let \(\phi \) be a real function satisfying Assumption 4. Let \(X_1,X_2,\ldots ,X_n\) be iid random variables taking values in \(\Upsilon _m\) with common probability law \(\pi \in \varDelta _m(\phi ,\mathcal P )\). Then, there exists an open neighborhood \(U\) of \(\pi \) and there exist \(k\) unique functions, \(g_i:U \rightarrow \mathbb R , 1 \le i \le k\), such that
-
(a)
\(\hat{\theta }_{\phi }=(g_1(\hat{\pi }),g_2(\hat{\pi }),\ldots , g_k(\hat{\pi }))^t, \forall \; n \ge n_0\), for some \(n_0 \in \mathbb N \).
-
(b)
\(\theta _0=(g_1(\pi ),g_2(\pi ),\ldots ,g_k(\pi ))^t\).
-
(c)
\(g=(g_1, g_2,\ldots , g_k)^t\) is continuously differentiable in \(U\) and the \(k \times m\) Jacobian matrix of \(g\) at \(\pi \) is given by \(G=G(\pi , P(\theta _0), \phi )\) as defined in Theorem 1, and \(G(x, P(\theta _0), \phi )=(G_{ij}(x))\) with \(G_{ij}(x)=\frac{\partial }{\partial x_j}g_i(x), 1 \le i\le k, 1 \le j\le m, \forall x=(x_1, x_2, \ldots , x_{m})^t\in U\).
Proof
Let \(F: \varDelta _m \times int\varTheta \longrightarrow \mathbb R ^k\) be defined by
From (11), \(F(\pi ,\theta _0)=0\), and from (12), \(\det (\frac{\partial }{\partial \theta }F(\pi , \theta _0))>0\). Thus, by the Implicit Function Theorem (see for example Dieudonne 1969, p. 272) there exists an open neighborhood \(U\) of \(\pi \) and \(k\) unique functions, \(g_i:U \rightarrow \mathbb R , 1 \le i \le k\), satisfying (b) and (c), such that \(F(p,g(p))=0, \forall p \in U\). By the strong law of large numbers (SLLN, Theorem 1.8B in Serfling 1980), \(\hat{\pi }=\pi +o(1)\), therefore \(\hat{\pi }\in U, \forall \; n \ge n_0\), for some \(n_0 \in \mathbb N \), which proves (a). Note that \(n_0\) depends on the sequence \(\omega =(X_1, X_2, \ldots ), n_0=n_0(\omega )\). \(\square \)
Proof of Theorem
1 Part (a) follows from Lemma 1 and the asymptotic normality of \(\sqrt{n}( \hat{\pi }-\pi )\) (Theorem 2.7 in Serfling 1980). Parts (b) and (c) follow from Lemma 1 and the SLLN. Parts (d) and (e) follow from part (a), Delta method (Theorem 3.3A in Serfling 1980) and the asymptotic normality of \(\sqrt{n}( \hat{\pi }-\pi )\). \(\square \)
Proof of Corollary
1 Part (a) follows from Theorem 1 (b) and the SLLN for \(\pi \). Parts (b) and (c) follow from Theorem 1 (e) and Taylor expansion. \(\square \)
Proof of Theorem
2 The theorem follows from the fact that the eigenvalues of \(\hat{V}_1\hat{\Sigma }_1\) converge in probability to those of \({V}_{01}{\Sigma }_{01}\) (see for example Lemma 1 in Fujikoshi 1977). \(\square \)
Before demonstrating Theorem 3, we give the following preliminary result.
Lemma 2
Let \(\mathcal P \) be a parametric family satisfying Assumptions 1 and 2. Let \(\phi \) be a real function satisfying Assumption 4. Let \(X_1,X_2,\ldots ,X_n\) be iid random variables taking values in \(\Upsilon _m\) with common probability law \(\pi \in \varDelta _m(\phi ,\mathcal P )\). Let \(\theta _0=\arg \min _{\theta } K_{\phi }(\pi ,P({\theta }))\). Then,
-
(a)
$$\begin{aligned} \sup _{x} \left| P_*\left\{ \sqrt{n}(\hat{\pi }^*-P(\hat{\theta }_{ \phi }))\le x \right\} - P(Z_1 \le x)\right| \stackrel{P}{\longrightarrow } 0, \end{aligned}$$
where \(Z_1 \sim N_{m}(0, \Sigma _{\pi _0})\) with \(\pi _0=P(\theta _0)\).
-
(b)
$$\begin{aligned} \sup _{x} \left| P_*\left\{ \sqrt{n} \left( \begin{array}{c} \hat{\pi }^*-P(\hat{\theta }_{\phi })\\ P(\hat{\theta }^*_{\phi })-P(\hat{\theta }_{\phi }) \end{array}\right) \le x \right\} - P(Z_2 \le x)\right| \stackrel{P}{\longrightarrow } 0, \end{aligned}$$
where \(Z_2 \sim N_{2m}(0, B_0\Sigma _{\pi _0} B_0^t), B_0=B(P(\theta _0),P(\theta _0), \phi )\) with \(B\) as defined in Theorem 1.
Proof
(a) The proof of this part is quite similar to that of Lemma 2 in Jiménez-Gamero et al. (2011), so we omit it. (b) Let \(U\) be the neighborhood of \(\pi _0\) in Lemma 1 and let \(\pi _n=P(\hat{\theta }_{\phi })\). Note that \(\hat{\pi }^*-\pi _0=\hat{\pi }^*-\pi _n+\pi _n-\pi _0\). From part (a), \(\hat{\pi }^*-\pi _n=O_{P_*}(n^{-1/2})\) in probability (\(P\)); from Theorem 1, \(\hat{\pi }_n-\pi _0=O_{P}(n^{-1/2})\). Thus, \(P(|\hat{\pi }^*-\pi _0|>\varepsilon ) \rightarrow 0, \forall \varepsilon >0\), which implies that \(\hat{\pi }^* \in U\) with probability tending to 1. Now, if \(\hat{\pi }^*, \pi _n \in U\), then by Lemma 1 and part (a) we get
with \(r^*_1=o_{P_*}(n^{-1/2})\), where \(G\) is as defined in Theorem 1. Now, from Assumption 1 and the above expression we get
with \(r^*_2=o_{P_*}(n^{-1/2})\), where \(M(\pi _n)=D_1(\pi _n) G(\pi _n,\pi _n, \phi )\). Since \(M(\pi _n)\stackrel{a.s.}{\rightarrow }M(\pi _0)\), the result follows from (13) and part (a). \(\square \)
Proof of Theorem
3 By Taylor expansion and Lemma 2 we get
with \(r^*=o_{P_*}(n^{-1/2})\), in probability (P). From Theorem 1,
The result follows from (14), (15) and Lemma 2(b). \(\square \)
Proof of Theorem
4 (a) By Taylor expansion
with \(r_n=o_P(n^{1/2})\). Therefore the result follows from the above expression and the asymptotic normality of \(\sqrt{n}(\hat{\pi }-\pi )\). The statements in parts (b) and (c) follow from Corollary 1 (a). \(\square \)
Before demonstrating Theorem 5, we state the following preliminary result.
Lemma 3
Let \(X_1, \ldots , X_n\) iid from a continuous population. Let \(\mathcal P = \{F(x;\theta ), \theta =(\theta _1, \ldots , \theta _k)^t \in \varTheta \}, \varTheta \subseteq \mathbb R ^k\), and \(\mathcal Q =\{G(x;\gamma ), \; \gamma =(\gamma _1,\ldots , \gamma _r)^t \in \Gamma \}, \Gamma \subseteq \mathbb R ^r\), where \(F(\cdot ;\theta ), \; Q(\cdot ;\theta ):\mathbb R \rightarrow [0,1]\) are continuous cdf. Let \(\hat{\theta }=\hat{\theta }(X_1,\ldots ,X_n)\) and \(\hat{\gamma }=\hat{\gamma }(X_1,\ldots ,X_n)\) be such that
for some \(\theta \in \varTheta , \gamma \in \Gamma \), where \({\pi }_{P}(\theta )=E\{\hat{\pi }_{P}(\theta )\}\) and \({\pi }_{Q}(\gamma )=E\{\hat{\pi }_{Q}(\gamma )\}\). Then
where
and the \(2m \times (k+r)\)-matrix \(D\) is as defined in Theorem 5.
Proof
Let us consider the following partition of \(\Sigma \),
where \(\Sigma _{\pi }\) is the \(2m \times 2m\) variance matrix of the vector \(\hat{\pi }\) obtained by stacking \(\hat{\pi }_P({\theta })\) and \(\hat{\pi }_Q({\gamma }), \Sigma _{\pi ,2}\) is the \(2m \times (k+r)\) covariance matrix of \(\hat{\pi }\) and \((\hat{\theta }^t,\hat{\gamma }^t )^t\) and \(\Sigma _{2}\) is the \((k+r) \times (k+r)\) variance matrix of \((\hat{\theta }^t,\hat{\gamma }^t )^t\). Let \(v^t=(v_1^t,v_2^t)\), with \(v_1, v_2\in \mathbb R ^{m}\), be fixed but arbitrary. Let \(U_v(\theta , \gamma )=v_1^t\hat{\pi }_P(\theta )+ v_2^t\hat{\pi }_Q(\gamma )\), then
with
From Theorem 2.13 in Randles (1982),
Finally, since \(v\) is arbitrary we get the result.\(\square \)
Proof of Theorem
5 From Taylor expansion we get
The result follows from the above expansion and Lemma 3. \(\square \)
References
Basu A, Sarkar S (1994) On disparity based goodness-of-fit tests for multinomial models. Stat Probab Lett 19:307–312
Bouzebda S, Cherfi M (2012) General bootstrap for dual \(\phi \)-divergence estimates. J Probab Stat. doi: 10.1155/2012/834107
Broniatowski M, Keziou A (2006) Minimization of \(\phi \)-divergences on sets of signes measures. Studia Sci Math Hungar 43:403–442
Broniatowski M, Keziou A (2009) Parametric estimation and testing through divergences and the duality technique. J Multivar Anal 100:16–36
Burbea J, Rao CR (1982) On the convexity of some divergence measures based on entropy functions. IEEE Trans Inform Theory 28:489–495
Castaño-Martínez A, López-Blázquez F (2005) Distribution od a sum of weighted central chi-square variables. Comm Statist Theory Methods 34:515–524
Csiszár I (1967) Information type measures of difference of probability distributions and indirect observations. Studia Sci Math Hungar 2:299–318
Csiszár I (1975) \(I\)-divegence geometry of probability distributions and minimization problems. Ann Probab 3:146–158
de la Horra J (2008) Bayesian model selection: measuring the \(\chi ^2\) discrepancy with the uniform distribution. Comm Stat Theory Methods 37:1412–1424
Dieudonne J (1969) Foundations of modern analysis. Academic Press, London
Fujikoshi Y (1977) An asymptotic expansion for the distributions of the latent roots of the wishart matrix with multiple population roots. Ann Inst Stat Math 29:379–387
Jiménez-Gamero MD, Pino-Mejías R, Alba-Fernández V, Moreno Rebollo JL (2011) Minimum \(\phi \)-divergence estimation in misspecified multinomial models. Comput Stat Data Anal 55:3365–3378
Kotz S, Johnson NL, Boyd DW (1967) Series representations of quadratic forms in normal variables. I. Central case. Ann Math Stat 38:823–837
Lindsay BG (1994) Efficiency versus robustness: the case for minimum Hellinger distance and related methods. Ann Stat 22:1081–1114
Morales D, Pardo L, Vajda I (1995) Asymptotic divergence of estimates of discrete distributions. J Stat Plan Inference 48:347–369
Pérez T, Pardo JA (2003a) Goodness-of-fit tests based on \(K_{\phi }\)-divergence. Kybernetika 39:739–752
Pérez T, Pardo JA (2003b) On choosing a goodness-of-fit test for discrete multivariate. Kybernetes 32:1405–1424
Pérez T, Pardo JA (2004) Minimun \(K_{\phi }\)-divergence estimator. Appl Math Lett 17:367–374
Pérez T, Pardo JA (2006) The \(K_\phi \) divergence statistic for categorical data problems. Metrika 63:355–369
Randles RH (1982) On the asymptotic normality of statistics with estimated parameters. Ann Stat 10: 462–474
Rao JNK, Scott AJ (1981) The analysis of categorical data from complex sample surveys: chi-squared tests for goodness of fit and independence in two-way tables. J Am Stat Assoc 76:221–230
Serfling R (1980) Approximation theorems of mathematical statistics. Wiley, New York
Shimodaira H (1998) An application of multiple comparison techniques to model selection. Ann Inst Stat Math 50:1–13
Vuong QH (1989) Likelihood ratio tests for model selection and non-nested hypotheses. Econometrica 57:257–306
Vuong QH, Wang W (1993) Minimum chi-square estimation and tests for model selection. J Econom 56:141–168
White H (1982) Maximum likelihood estimation of misspecified models. Econometrica 50:1–25
Acknowledgments
The authors thank the anonymous referees for their constructive comments and suggestions which helped to improve the presentation. A. Rufián-Lizana is partially supported by Grant MTM2010-15383 (Spain).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Jiménez-Gamero, M.D., Pino-Mejías, R. & Rufián-Lizana, A. Minimum \(K_{\phi }\)-divergence estimators for multinomial models and applications. Comput Stat 29, 363–401 (2014). https://doi.org/10.1007/s00180-013-0452-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00180-013-0452-3