
Abstract
This article presents two generalized nonparametric methods for estimating multiple, possibly like, densities. The first generalization contains the Nadaraya–Watson estimator, the Jones et al. (Biometrika 82(2):327–338, 1995) bias reduction estimator, and Ker (Stat Probab Lett 117:23–30, 2016) possibly similar estimator as special cases. The second generalization contains the Nadaraya–Watson estimator, Ker (2016) possibly similar estimator, and the conditional density estimator of Hall et al. (J Am Stat Assoc 99(468):1015–1026, 2004) as special cases. The generalizations do not require knowledge of the form or extent of likeness between the unknown densities; an attractive feature in empirical applications. Numerical simulations demonstrate that the two proposed generalizations lead to significant efficiency gains.


Similar content being viewed by others

Notes
The proposed estimators can handle an unbalanced design where the number of realizations per unit are not equal. For notational convenience and without loss of generality we assume a balanced design.
This approach was used by Racine and Ker (2006) to improve the rating of crop insurance contracts in the U.S. crop insurance program.
The nine densities are: f1: N(0, 1), f2: \(\frac{1}{5}N(0,1)+\frac{1}{5}N(\frac{1}{2},(\frac{2}{3})^2+\frac{3}{5}N(\frac{13}{12},(\frac{5}{9})^2)\), f3: \(\sum _{l=0}^{7} \frac{1}{8}N(3[(\frac{2}{3})^l-1], (\frac{2}{3})^{2l})\), f4: \(\frac{2}{3} N(0,1) + \frac{1}{3} N(0,(\frac{1}{10})^2)\), f5 : \(\frac{1}{10} N(0,1) + \frac{9}{10} N(0,(\frac{1}{10})^2)\), f6 : \(\frac{1}{2} N(-1,(\frac{2}{3})^2) + \frac{1}{2} N(1,(\frac{2}{3})^2)\), f7 : \(\frac{1}{2} N(-\frac{3}{2},(\frac{1}{2})^2) + \frac{1}{2} N(\frac{3}{2},(\frac{1}{2})^2)\), f8 : \(\frac{3}{4} N(0,1) + \frac{1}{4} N(\frac{3}{2},(\frac{1}{3})^2)\), and f9 : \(\frac{9}{20}N(-\frac{6}{5},(\frac{3}{5})^2)+ \frac{9}{20}N(\frac{6}{5},(\frac{3}{5})^2)+ \frac{1}{10}N(0,(\frac{1}{4})^2)\).
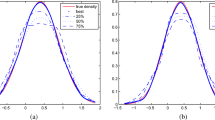
The five densities are f1: N(0, 1), f2: \( 0.95 N(0, 1) + 0.05 N(-2, 0.5^2) \), f3: \( 0.90 N(0, 1) + 0.10 N(-2, 0.5^2) \), f4: \( 0.85 N(0, 1) + 0.15 N(-2, 0.5^2)\), and f5: \( 0.80 N(0, 1) + 0.20 N(-2, 0.5^2)\).
References
Hall P, Racine J, Li Q (2004) Cross-validation and the estimation of conditional probability densities. J Am Stat Assoc 99(468):1015–1026
Hjort NL, Glad IK (1995) Nonparametric density estimation with a parametric start. Ann Stat 23(3):882–904
Jones M, Linton O, Nielsen J (1995) A simple bias reduction method for density estimation. Biometrika 82(2):327–338
Ker A, Liu Y (2017) Bayesian model averaging of possibly similar nonparametric densities. Comput Stat 32(1):349–365
Ker AP (2016) Nonparametric estimation of possibly similar densities. Stat Probab Lett 117:23–30
Ker AP, Ergün AT (2005) Empirical bayes nonparametric kernel density estimation. Stat Probab Lett 75(4):315–324
Marron JS, Wand MP (1992) Exact mean integrated squared error. Ann Stat 20(2):712–736
Racine J, Ker AP (2006) Rating crop insurance policies with efficient nonparametric estimators that admit mixed data types. J Agric Resour Econ 31(1):27–39
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix: proofs
Appendix: proofs
Throughout the proofs, we let \(X_l^j\) denote the realizations from the unit of interest while \(X_l^{-j}\) denote the realizations from the other or extraneous units.
Theorem 1
The NW, JLN and Ker estimators are special cases of the G1 estimator.
Lemma 1
If \(h_p\rightarrow \infty \), then \(\hat{f}_{G1}(x)=\hat{f}_{NW}(x)\).
Proof
If \(h_p\rightarrow \infty \), then
and
thus, \(\hat{g}_{G1}(x)\) is approximately uniform. Hence,
\(\square \)
Lemma 2
If \(\lambda =0\) then \(\hat{f}_{G1}(x)=\hat{f}_{JLN}(x)\).
Proof
If \(\lambda =0\), then \( K^d(l,j)=0^{I(l,j)}1^{1-I(l,j)}= 1\) if \(l=j \) and 0 otherwise.
Note,
and thus
\(\square \)
Lemma 3
If \(\lambda =\frac{Q-1}{Q}\) then \(\hat{f}_{G1}(x)=\hat{f}_K(x)\).
Proof
If \(\lambda =\frac{Q-1}{Q}\), then \(\frac{\lambda }{Q-1}=1-\lambda =\frac{1}{Q}\), \(K^d(l,j)=\frac{1}{Q}^{I(l,j)} \frac{1}{Q}^{1-I(l,j)}= \frac{1}{Q} \; \forall \; l,j \) thus
and thus
\(\square \)
Theorem 2
The NW, HRL and Ker estimators are special cases of the G2 estimator.
Lemma 4
If \(h_p \rightarrow \infty \), \(\lambda =0\) then \(\hat{f}_{G2}(x)=\hat{f}_{NW}(x)\).
Proof
If \(h_g \rightarrow \infty \), then
and
thus \(\hat{g}_{G2}(x)\) and is approximately uniform. Then
and
If \(\lambda =0\), then \(K^d(l,j)=0^{I(l,j)} 1^{1-I(l,j)} = 1 \) if \(l=j\) and 0 otherwise.
\(\square \)
Lemma 5
If \(h_p \rightarrow \infty \) then \(\hat{f}_{G2}(x)=\hat{f}_{HRL}(x)\).
Proof
If \(h_p \rightarrow \infty \), then
and
thus \(\hat{g}_{G2}(x)\) is approximately uniform then
and
\(\square \)
Lemma 6
If \(\lambda =0\) then \(\hat{f}_{G2}(x)=\hat{f}_{K}(x)\).
Proof
If \(\lambda =0\), then \(K^d(l,j)=0^{I(l,j)} 1^{1-I(l,j)} = 1\) if \(l = j\) and 0 otherwise.
and then
\(\square \)
Rights and permissions
About this article

Cite this article
Shang, Z., Ker, A. Two generalized nonparametric methods for estimating like densities. Comput Stat 36, 113–126 (2021). https://doi.org/10.1007/s00180-020-01007-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00180-020-01007-w