
Abstract
Recently, a subcopula-based asymmetric association measure was developed for the variables in two-way contingency tables. Here, we develop a fully Bayesian method to implement this measure, and examine its performance using simulation data and several real data sets of colorectal cancer. We use coverage probabilities and lengths of the interval estimators to compare the Bayesian approach and a large-sample method of analysis. In simulation studies, we find that the Bayesian method outperforms the large-sample method on average, and provides either similar or improved results for the real data analyses.


Similar content being viewed by others

References
Agresti A (2010) Analysis of ordinal categorical data, vol 656. John Wiley & Sons
Agresti A, Hitchcock DB (2005) Bayesian inference for categorical data analysis. Stat Methods Appl 14(3):297–330
Agresti A, Kateri M (2011) Categorical data analysis. Springer
Agresti A, Min Y (2005) Frequentist performance of Bayesian confidence intervals for comparing proportions in 2\(\times \)2 contingency tables. Biometrics 61(2):515–523
Baker SG (1994) The multinomial-Poisson transformation. J Roy Stat Soc Ser D 43(4):495–504
Beh EJ, Lombardo R (2014) Correspondence analysis: theory. John Wiley & Sons, Practice and new strategies
Beh EJ, Simonetti B, D’Ambra L (2007) Partitioning a non-symmetric measure of association for three-way contingency tables. J Multivar Anal 98(7):1391–1411
Bové DS, Held L (2011) Hyper-\( g \) priors for generalized linear models. Bayesian Anal 6(3):387–410
Choi L, Blume JD, Dupont WD (2015) Elucidating the foundations of statistical inference with 2 x 2 tables. PLOS ONE 10(4):e0121263
Dellaportas P, Forster JJ (1999) Markov chain Monte Carlo model determination for hierarchical and graphical log-linear models. Biometrika 86(3):615–633
D’Ambra L, Lauro NC (1992) Non symmetrical exploratory data analysis. Statistica Applicata 4(4):511–529
Forster JJ (2010) Bayesian inference for Poisson and multinomial log-linear models. Stat Methodol 7(3):210–224
Gamerman D (1997) Sampling from the posterior distribution in generalized linear mixed models. Stat Comput 7(1):57–68
Gelman A, Carlin JB, Stern HS, Dunson DB, Vehtari A, Rubin DB (2013) Bayesian data analysis. CRC Press
Geweke J (1992) Evaluating the accuracy of sampling-based approaches to the calculation of posterior moments. In: Bernardo JM, Berger JO, Dawid AP, Smith AFM (eds) Bayesian statistics, vol 4. Oxford University Press, Oxford, pp 169–193
Ghosh M, Zhang L, Mukherjee B (2006) Equivalence of posteriors in the Bayesian analysis of the multinomial-Poisson transformation. Metron Int J Stat 1(64):19–28
Goodman LA, Kruskal WH (1954) Measures of association for cross classifications. J Am Stat Assoc 49(268):732–764
Kass RE, Wasserman L (1996) The selection of prior distributions by formal rules. J Am Stat Assoc 91(435):1343–1370
Kawasaki T, Ohnishi M, Nosho K, Suemoto Y, Kirkner GJ, Meyerhardt JA, Fuchs CS, Ogino S (2008) CpG island methylator phenotype-low (CIMP-low) colorectal cancer shows not only few methylated CIMP-high-specific CpG islands, but also low-level methylation at individual loci. Modern Pathol 21(3):245
Larntz K (1978) Small-sample comparisons of exact levels for chi-squared goodness-of-fit statistics. J Am Stat Assoc 73:253–263
Margolin AA, Nemenman I, Basso K, Wiggins C, Stolovitzky G, Dalla Favera R, Califano A (2006) ARACNE: an algorithm for the reconstruction of gene regulatory networks in a mammalian cellular context. BMC Bioinform 7(Suppl 1):S7
Mukerjee R, Reid N (2001) Comparison of test statistics via expected lengths of associated confidence intervals. J Stat Plan Infer 97:141–151
Nasierowska-Guttmejer A, Trzeciak L, Nowacki MP, Ostrowski J (2000) p53 protein accumulation and p53 gene mutation in colorectal cancer. Pathol Oncol Res 6(4):275–279
Nelsen R (2006) An introduction to copulas, 2nd edn. Springer, New York
Newcombe RG (2011) Measures of location for confidence intervals for proportions. Commun Stat Theory Methods 40(10):1743–1767
Ntzoufras I, Dellaportas P, Forster JJ (2003) Bayesian variable and link determination for generalised linear models. J Stat Plan Infer 111(1–2):165–180
Ogino S, Kawasaki T, Kirkner GJ, Loda M, Fuchs CS (2006) CpG island methylator phenotype-low (CIMP-low) in colorectal cancer: possible associations with male sex and KRAS mutations. J Mol Diag 8(5):582–588
Overstall AM, King R (2014a) conting: An R package for Bayesian analysis of complete and incomplete contingency tables. J Stat Softw 58(7):1–27
Overstall AM, King R (2014b) A default prior distribution for contingency tables with dependent factor levels. Stat Methodol 16:90–99
Overstall AM, King R, Bird SM, Hutchinson SJ, Hay G (2014) Incomplete contingency tables with censored cells with application to estimating the number of people who inject drugs in Scotland. Stat Med 33(9):1564–1579
Park H, Leemis LM (2019) Ensemble confidence intervals for binomial proportions. Stat Med 38:3460–3475
Poole D, Raftery AE (2000) Inference for deterministic simulation models: the Bayesian melding approach. J Am Stat Assoc 95:1244–1255
R Core Team (2020) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/
Raftery AE (1996) Approximate Bayes factors and accounting for model uncertainty in generalised linear models. Biometrika 83(2):251–266
Rambau PF, Odida M, Wabinga H (2008) p53 expression in colorectal carcinoma in relation to histopathological features in Ugandan patients. Afr Health Sci 8(4):234–238
Sklar M (1959) Fonctions de répartition à n dimensions et leurs marges. Université Paris 8:229–231
van Someren EP, Wessels LFA, Backer E, Reinders MJT (2002) Genetic network modeling. Pharmacogenomics 3(4):507–525
Theil H (1970) On the estimation of relationships involving qualitative variables. Am J Sociol 76(1):103–154
Wei Z, Kim D (2017) Subcopula-based measure of asymmetric association for contingency tables. Stat Med 36(24):3875–3894
Zhang Y, Song M (2013) Deciphering interactions in causal networks without parametric assumptions. arXiv preprint http://arxiv.org/abs/1311.2707
Zhong H, Song M (2019) A fast exact functional test for directional association and cancer biology applications. IEEE/ACM Trans Comput Biol Bioinform 16(3):818–826
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Appendix
Appendix
1.1 1 Asymptotic distribution of the subcopula-based asymmetric association measures
The asymptotic distributions of the estimators for the subcopula-based asymmetric association measures provided in Eqs. (4) and (5) are developed in the following theorem.
Theorem 1
(Wei and Kim 2017) Let \({\hat{\rho }}^{2}_{_{({X \rightarrow Y})}}\) be the estimator for the asymmetric measure \({\rho }^{2}_{_{({X \rightarrow Y})}}\) defined in Eq. (4). Then,
where \({\varvec{p}}\,=\,(p_{11}, p_{12},\ldots , {p}_{I(J-1)}, {p_{IJ}})^T\),
\(\nabla h_1({\varvec{p}}) {=} \begin{bmatrix} \frac{\partial {{\rho }^{2}_{_{({X \rightarrow Y})}}}}{\partial p_{11}} , \frac{\partial {{\rho }^{2}_{_{({X \rightarrow Y})}}}}{\partial p_{12}} , \,\ldots \, ,\frac{\partial {{\rho }^{2}_{_{({X \rightarrow Y})}}}}{\partial p_{IJ}} \end{bmatrix}^{T}\), and \(\frac{\partial {\rho }^{2}_{_{({X \rightarrow Y})}}}{\partial p_{st}}\) is given in Eq. (A.4)–(A.8) in Wei and Kim (2017), for \(s=1,\ldots ,I,\) and \(t=1,\ldots ,J\). Let \(\nabla h_2({\varvec{p}}) = \begin{bmatrix} \frac{\partial {{\rho }^{2}_{_{({Y \rightarrow X})}}}}{\partial p_{11}} , \frac{\partial {{\rho }^{2}_{_{({Y \rightarrow X})}}}}{\partial p_{12}} , \,\ldots \, ,\frac{\partial {{\rho }^{2}_{_{({Y \rightarrow X})}}}}{\partial p_{IJ}} \end{bmatrix}^{T}\), and \(\frac{\partial {\rho }^{2}_{_{({Y \rightarrow X})}}}{\partial p_{st}}\) is given in Eq. (A.9)–(A.14) in Wei and Kim (2017). Then, the asymptotic distribution of \({\hat{\rho }}^{2}_{_{({Y \rightarrow X})}}\) can be obtained by substituting \(\nabla h_2({\varvec{p}}) \) for \(\nabla h_1({\varvec{p}}) \) in Equation (17).
Based on Theorem 1, the following corollary is derived for the asymptotic distribution of the difference between the estimators of the asymmetric measures, (\({\hat{\rho }}^{2}_{_{({X \rightarrow Y})}}-{\hat{\rho }}^{2}_{_{({Y \rightarrow X})}}\)):
Corollary 1
Let \({\hat{\rho }}^{2}_{_{({X \rightarrow Y})}}\) and \({\hat{\rho }}^{2}_{_{({Y \rightarrow X})}}\) be the estimators for the asymmetric measures \({\rho }^{2}_{_{({X \rightarrow Y})}}\) and \({\rho }^{2}_{_{({Y \rightarrow X})}}\) defined in Eq. (4) and (5). Then,
where \({\varvec{p}}\), \(\nabla h_1({\varvec{p}})\), and \(\nabla h_2({\varvec{p}})\) are given in Theorem 1.
From the Theorem 1 and Corollary 1, the large-sample confidence intervals for \(\rho ^{2}_{_{({X \rightarrow Y})}}\), \(\rho ^{2}_{_{({Y \rightarrow X})}}\), and (\(\rho ^{2}_{_{({X \rightarrow Y})}} - \rho ^{2}_{_{({Y \rightarrow X})}}\)) can be obtained.

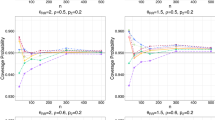
\(\hat{p}_{_{BCI}}\)(square), \(\hat{p}_{_{HPD}}\)(dot), \(\hat{p}_{_{WKI}}\)(triangle) and the associated \(95\%\) confidence intervals for \(\hat{p}_{_{BCI}}\)(dotted lines), \(\hat{p}_{_{HPD}}\)(solid lines) and \(\hat{p}_{_{WKI}}\)(dashed lines) for \(3\times 2\) table (top panel), \(2\times 3\) table (middle panel), and \(3\times 3\) table (bottom panel), with \(\sigma ^2=0.1\) and sample size \(n=200\), 400, 800, and 1600 under weak, moderate and strong association

\(\hat{p}_{_{BCI}}\)(square), \(\hat{p}_{_{HPD}}\)(dot), \(\hat{p}_{_{WKI}}\)(triangle) and the associated \(95\%\) confidence intervals for \(\hat{p}_{_{BCI}}\)(dotted lines), \(\hat{p}_{_{HPD}}\)(solid lines) and \(\hat{p}_{_{WKI}}\)(dashed lines) for \(3\times 2\) table (top panel), \(2\times 3\) table (middle panel), and \(3\times 3\) table (bottom panel), with \(\sigma ^2=10^6\) and sample size \(n=200\), 400, 800, and 1600 under weak, moderate and strong association
1.2 2 Sensitivity analysis results
The following are figures for the results of the sensitivity analysis in Sect. 4.2 (see Figs. 3 and 4).
1.3 3 Diagnostic Plots
Here, we provide history plots, autocorrelation function and partial autocorrelation function plots for select parameters in both the simulation studies and real data studies (Figs. 5, 6, 7). See Sect. 3.4 for details. Plots for additional parameters are provided in Section S2 of the Supplementary Material.

History plots for select parameters of simulation studies and real data analysis. a–c is for simulation data and \(\sigma ^2 = 1\): a \({\hat{\rho }}^{2}_{_{({X \rightarrow Y})}}\) for n=200, \(3\times 2\) table, weak association. b \({\hat{\rho }}^{2}_{_{({X \rightarrow Y})}}\) for n=400, \(2\times 3\) table, moderate association. c \({\hat{\rho }}^{2}_{_{({X \rightarrow Y})}}\) for n=1600, \(3\times 3\) table, strong association. d–f is for real data: d \({\hat{\rho }}^2_{({\text {CIMP}} \rightarrow {\text {BRAF}})}\). e \({\hat{\rho }}^2_{({\text {KRAS}} \rightarrow {\text {CIMP}})}\). f \({\hat{\rho }}^2_{(p53 \rightarrow {\text {CIMP}})}\)

Autocorrelation Plots and Partial Autocorrelation Plots for select parameters of the simulation studies. a \({\hat{\rho }}^{2}_{_{({X \rightarrow Y})}}\) for n=200, \(3\times 2\) table, weak association. b \({\hat{\rho }}^{2}_{_{({X \rightarrow Y})}}\) for n=400, \(2\times 3\) table, moderate association. c \({\hat{\rho }}^{2}_{_{({X \rightarrow Y})}}\) for n=1600, \(3\times 3\) table, strong association

Autocorrelation Plots and Partial Autocorrelation Plots for select parameters of the real data analysis. a \({\hat{\rho }}^2_{({\text {CIMP}} \rightarrow {\text {BRAF}})}\). b \({\hat{\rho }}^2_{({\text {KRAS}} \rightarrow {\text {CIMP}})}\). c \({\hat{\rho }}^2_{(p53 \rightarrow {\text {CIMP}})}\)
Rights and permissions
About this article

Cite this article
Wei, Z., Kim, D. & Conlon, E.M. A Bayesian approach to the analysis of asymmetric association for two-way contingency tables. Comput Stat 37, 1311–1338 (2022). https://doi.org/10.1007/s00180-021-01161-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00180-021-01161-9