
Abstract
For several reinforcement learning models in strategic-form games, convergence to action profiles that are not Nash equilibria may occur with positive probability under certain conditions on the payoff function. In this paper, we explore how an alternative reinforcement learning model, where the strategy of each agent is perturbed by a strategy-dependent perturbation (or mutations) function, may exclude convergence to non-Nash pure strategy profiles. This approach extends prior analysis on reinforcement learning in games that addresses the issue of convergence to saddle boundary points. It further provides a framework under which the effect of mutations can be analyzed in the context of reinforcement learning.




Similar content being viewed by others

Notes
The notation \(-i\) denotes the complementary set \(\mathcal {I}\backslash {i}\). We will often write \(\alpha _{-i}\) and \(\sigma _{-i}\) to denote the action and strategy profile of all agents in \(-i\), respectively. The set of action profiles in \(-i\) will be denoted \(\mathcal {A}_{-i}\). We will also split the argument of a function in this way, e.g., \(F(\alpha )\,=\,F(\alpha _i,\alpha _{-i})\) or \(F(\sigma ) = F(\sigma _i,\sigma _{-i})\).
The condition follows from Raabe’s convergence criterion.
If \(\{x(t):t\ge {0}\}\) denotes the solution of the ODE (16), then a set \(A\subset \varvec{\Delta }\) is a locally asymptotically stable set in the sense of Lyapunov for the ODE (16) if a) for each \(\varepsilon >0\), there exists \(\delta =\delta (\varepsilon )>0\) such that \(\mathrm{dist}(x(0),A)<\delta \) implies \(\mathrm{dist}(x(t),A)<\varepsilon \) for all \(t\ge {0}\), and b) there exists \(\delta >0\) such that \(\mathrm{dist}(x(0),A)<\delta \) implies \(\lim _{t\rightarrow \infty }\mathrm{dist}(x(t),A)=0\).
References
Altman E, Hayel Y, Kameda H (2007) Evolutionary dynamics and potential games in non-cooperative routing. In: WiOpt 2007, Limassol
Arthur WB (1993) On designing economic agents that behave like human agents. J Evol Econ 3:1–22
Beggs A (2005) On the convergence of reinforcement learning. J Econ Theory 122:1–36
Bergin J, Lipman BL (1996) Evolution with state-dependent mutations. Econometrica 64(4):943–956
Bonacich P, Liggett T (2003) Asymptotics of a matrix-valued markov chain arising in sociology. Stoch Process Appl 104:155–171
Börgers T, Sarin R (1997) Learning through reinforcement and replicator dynamics. J Econ Theory 77(1):1–14
Bush R, Mosteller F (1955) Stochastic models of learning. Wiley, New York
Chasparis G, Shamma J (2012) Distributed dynamic reinforcement of efficient outcomes in multiagent coordination and network formation. Dyn Games Appl 2(1):18–50
Cho IK, Matsui A (2005) Learning aspiration in repeated games. J Econ Theory 124:171–201
Erev I, Roth A (1998) Predicting how people play games: reinforcement learning in experimental games with unique, mixed strategy equilibria. Am Econ Rev 88:848–881
Hofbauer J, Sigmund K (1998) Evolution games and population dynamics. Cambridge University Press, Cambridge
Hopkins E, Posch M (2005) Attainability of boundary points under reinforcement learning. Games Econ Behav 53:110–125
Kushner HJ, Yin GG (2003) Stochastic approximation and recursive algorithms and applications, 2nd edn. Springer-Verlag, New York
Leslie D (2004) Reinforcement learning in games. Ph.D. thesis, School of Mathematics, University of Bristol
Marden J, Arslan G, Shamma J (2009) Cooperative control and potential games. IEEE Trans Syst Man Cybern B 39(6):1393–1407
Monderer D, Shapley L (1996) Potential games. Games Econ Behav 14:124–143
Narendra K, Thathachar M (1989) Learning automata: an introduction. Prentice-Hall, Upper Saddle River
Nevelson MB, Hasminskii RZ (1976) Stochastic approximation and recursive. American Mathematical Society, Providence
Norman MF (1968) On linear models with two absorbing states. J Math Psychol 5:225–241
Pemantle R (1990) Nonconvergence to unstable points in urn models and stochastic approximations. Ann Probab 18(2):698–712
Posch M (1997) Cycling in a stochastic learning algorithm for normal form games. Evolut Econ 7:193–207
Rosenthal R (1973) A class of games possessing pure-strategy Nash equilibria. Int J Game Theory 2(1):65–67
Rudin W (1964) Principles of mathematical analysis. McGraw-Hill Book Company, New York
Sandholm W (2001) Potential games with continuous player sets. J EconTheory 97:81–108
Sandholm WH (2010) Population games and evolutionary dynamics. The MIT Press, Cambridge
Savla K, Frazzoli E (2010) Game-theoretic learning algorithm for a spatial coverage problem. In: 47th annual allerton conference on communication, control and computing, Allerton
Shapiro IJ, Narendra KS (1969) Use of stochastic automata for parameter self-organization with multi-modal performance criteria. IEEE Transac Syst Sci Cybern 5:352–360
Skyrms B, Pemantle R (2000) A dynamic model of social network formation. Proceedings of the national academy of sciences of the USA 97, 9340–9346
Smith JM (1982) Evolution and the theory of games. Cambridge University Press, Cambridge
Weibull J (1997) Evolutionary game theory. MIT Press, Cambridge
Acknowledgments
This work was supported by the Swedish Research Council through the Linnaeus Center LCCC and the AFOSR MURI project #FA9550-09-1-0538.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: Proof of proposition 2
We first define the canonical path space \(\varOmega \) generated by the reinforcement learning process, as discussed in the beginning of Sect. 5. We denote \(\mathbb {P}\) the probability operator and we implicitly assume that computation of probabilities is performed in an appropriately generated \(\sigma \)-algebra.
Let us assume that action profile \(\alpha =(\alpha _1,\ldots \alpha _n)\in \mathcal {A}\) has been selected at time \(k=0\). This implies that \(x_{i\alpha _i}(0)>0\), since actions are selected according to the strategy distribution \(\sigma _i(0)=x_i(0)\). The corresponding payoff profile will be \(R(\alpha )=(R_1(\alpha ),\ldots ,R_n(\alpha ))\), where according to Assumption 1, \(R_i(\alpha )>0\) for all \(i\in \mathcal {I}\). Let us define the following event:
\(\tau = 1,2,\ldots \). Thus, \(A_\tau \) corresponds to the case where the same action profile has been performed for all times \(k\le \tau \). Note that the sequence of events \(\{A_\tau \}\) is decreasing, since \(A_\tau \supseteq A_{\tau +1}\) for all \(\tau =1,2,\ldots \). Define also the event
Therefore, from continuity from above, we have:
The above upper bound \(\chi (\alpha )\) is non-zero if and only if
Let us define the new variable \(y_i(k)\triangleq 1-x_{i\alpha _i}(k) = \sum _{j\in \mathcal {A}_i\backslash {\alpha _i}}x_{ij}(k),\) which corresponds to the probability of agent \(i\) selecting any action other than \(\alpha _i\). Condition (25) is equivalent to
We also have that
for some finite \(\rho >0\), since \(0\le y_i(k) \le 1\). Thus, from the limit comparison test, we conclude that condition (26) holds, if and only if \(\sum _{k=1}^{\infty }y_i(k) < \infty ,\) for each \(i\in \mathcal {I}.\) Since \(\epsilon (k)=1/(k^\nu +1)\), for \(1/2<\nu \le {1}\), we have:
By Raabe’s criterion, the series \(\sum _{k=0}^{\infty }y_i(k)\) is convergent if
Since
we conclude that the series \(\sum _{k=0}^{\infty }y_i(k)\) is convergent if \(R_i(\alpha )>1\) for each \(i\in \mathcal {I}\). In other words, the action profile \(\alpha \) will be performed for all future times with positive probability if \(R_i(\alpha )>1\) for all \(i\in \mathcal {I}\). Furthermore, if \(R_i(\alpha )>1\) for all \(i\in \mathcal {I}\) and for all \(\alpha \in \mathcal {A}\), then the probability that the same action profile will be played for all future times is uniformly bounded away from zero over all initial conditions.
Appendix 2: Proof of proposition 2
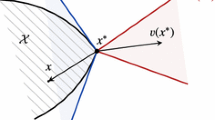
For any agent \(i\in \mathcal {I}\) and any action \(s\in \mathcal {A}_i\), the corresponding entry of the vector field of ODE (16), evaluated at strategy \(\tilde{x}\), is
where \(\zeta _i=\zeta _i(\tilde{x}_i,\lambda )\). Consider any pure strategy profile \(x^{*}\), and take \(\tilde{x}=x^{*} + {\nu }\), for some \(\nu =(\nu _1,\nu _2,\ldots ,\nu _n)\in \mathbb {R}^{\left| \mathcal {A}_1 \right| }\times \ldots \times \mathbb {R}^{\left| \mathcal {A}_n \right| }\) such that \(\nu _i\in \mathrm{null}\{\mathbf {1}^{\mathrm T}\}\) and \(\tilde{x}_i=x^*_i+\nu _i \in \varDelta (\left| \mathcal {A}_i \right| )\) for all \(i\in \mathcal {I}\). Substituting \(\tilde{x}\) into (27), yields
where \(\zeta _i=\zeta _i(x_i^*+\nu _i,\lambda )\).
Due to property (4) of Assumption 2, the perturbation function satisfies
Furthermore, \(\overline{g}_{is}^{\lambda }(0,0)=0\), since \(x^*\) is a stationary point of the unperturbed dynamics. Thus, the partial derivatives of \(\overline{g}_{is}^{\lambda }\) evaluated at \((0,0)\) are:
Note also that for any \(\ell \in \mathcal {I}\backslash {i}\) and \(m\in \mathcal {A}_{\ell }\), we have
Since \(x^*\) corresponds to a pure strategy state, for each \(i\in \mathcal {I}\) there exists \(j^*=j^*(i)\) such that \(x_i^*=e_{j^*}\), i.e., \(x_{ij^*}=1\) and \(x_{is}^*=0\) for all \(s\ne j^*\). For this pure strategy state and for any \(s\in \mathcal {A}_i\backslash {j^*}\) we have
and
Given that \(\nu _i\in \mathrm{null}\{\mathbf {1}^{\mathrm T}\}\) and \(\partial {\overline{g}_{is}^{\lambda }(\nu ,\lambda )}/\partial {\nu _{ij^*}}=0\) for all \(s\ne j^*\), the behavior of \(\overline{g}^{\lambda }(\cdot ,\cdot )\) with respect to \(\nu \) about the point \((0,0)\) is described by the following Jacobian matrix:
The above Jacobian matrix has full rank if for each \(i\in \mathcal {I}\)
In this case, by the implicit function theorem, there exists a neighborhood \(D\) of \(\lambda =0\) and a unique differentiable function \(\nu ^*:D\rightarrow \mathbb {R}^{\left| \mathcal {A} \right| }\) such that \(\nu ^*(0)=0\) and \(\overline{g}^{\lambda }(\nu ^*(\lambda ),\lambda )=0,\) for any \(\lambda \in {D}\).
To characterize exactly the stationary points for small values of \(\lambda \), we need to also compute the gradient of the mean-field with respect to the perturbation parameter \(\lambda \). Note that:
since the partial derivative of \(\zeta _i\) with respect to \(\lambda \) when evaluated at \((0,0)\) is 1. Thus,
Again, by implicit function theorem, we have that
which implies that for any \(i\in \mathcal {I}\) and for any \(s\ne j^*\)
Since \(\nu _{is}^*(0)=0\) and \(x_{is}^*=0\), in order for the solution \(\tilde{x}=x^*+\nu ^*(\lambda )\) to be in \(\varvec{\Delta }^o\), we also need the condition \(d\nu _{is}^*(\lambda )/d\lambda |_{\lambda =0}>0\) to be satisfied for all \(s\ne j^*\). Since \(U_{is}(x^*)>0\) by Assumption 1, this condition is equivalent to
for all \(i\in \mathcal {I}\) and any \(s\ne j^*\). This is also equivalent to \(x^*\) being a strict Nash equilibrium. Thus, the conclusion follows.
If \(x^*\) corresponds to an action profile which is not a Nash equilibrium, then there exist \(i\in \mathcal {I}\) and \(s\ne j^*\) such that \(U_{is}(x^*)-U_{ij^*}(x^*)>{0}\). For any \(\beta \in (0,1)\) which is sufficiently close to one, there exist \(\delta _0=\delta _0(\beta )\) such that \(\zeta _i(x_i,\lambda )\equiv {0}\), \(i\in \mathcal {I}\), for any \(x\in \varvec{\Delta }\backslash \mathcal {B}_{\delta }(x^*)\), \(\lambda >0\) and \(\delta \ge \delta _0\). For any \(x\in \mathcal {B}_{\delta }(x^*)\), \(\delta \ge \delta _0\), the vector field becomes
plus higher order terms of \(\lambda \) and \(\delta \), for all \(s\ne j^*\). Since the Nash condition is violated in the direction of \(s\), \(U_{is}(x)-U_{ij^*}(x)=c+O(\delta )\), for some \(c>{0}\), where \(O(\delta )\) denotes a quantity of order of \(\delta \). Furthermore, by Assumption 1 of strictly positive rewards, \(U_{is}(x)>0\) for all \(s\in \mathcal {A}_i\) and \(x\in \mathcal {B}_{\delta }(x^*)\). Therefore, for any \(\delta \ge \delta _0\) and for sufficiently small \(\lambda >0\), the vector field \(\overline{g}_{is}^{\lambda }(x)>0\) for any \(x\in \mathcal {B}_{\delta }(x^*)\), which implies that there is no stationary point of the vector field in \(\mathcal {B}_{\delta }(x^*)\).
Rights and permissions
About this article

Cite this article
Chasparis, G.C., Shamma, J.S. & Rantzer, A. Nonconvergence to saddle boundary points under perturbed reinforcement learning. Int J Game Theory 44, 667–699 (2015). https://doi.org/10.1007/s00182-014-0449-3
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00182-014-0449-3