
Abstract
The ISI impact factor is widely accepted as a possible measurement of academic journal quality. However, much debate has recently surrounded this use, and several complex alternative journal impact indicators have been reported. To avoid the bias which may be caused by using a single quality indicator, ensemble of multiple indicators is a promising method for producing a more robust quality estimation. In this paper, an approach based on links between journals is proposed for the capturing and fusion of impact indicators. In particular, a number of popular indicators are combined and transformed to fused-links between academic journals, and two distance metrics: Euclidean distance and Manhattan distance are utilised to support the development and analysis of the fused-links. The approach is applied to both supervised and unsupervised learning, in an effort to estimate the impact and therefore the ranking of journals. Results of systematic experimental evaluation demonstrate that by exploiting the fused-links, simple algorithms such as K-Nearest Neighbours and K-means can perform as well as advanced techniques like support vector machines, in terms of accuracy and within-1 accuracy, while exhibiting the advantage of being more intuitive and interpretable.




Similar content being viewed by others
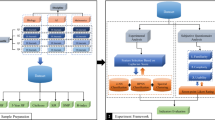
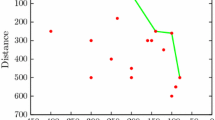
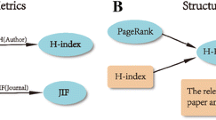
References
Aggarwal C, Hinneburg A, Keim D (2001) On the surprising behavior of distance metrics in high dimensional space. In: Database Theory–ICDT 2001. Springer, Heidelberg, pp 420–434
Anderberg MR (1973) Cluster analysis for applications. Academic Press, Inc., New York
Beliakov G, James S (2011) Citation-based journal ranks: the use of fuzzy measures. Fuzzy Sets Syst 167(1):101–119
Bengio Y, Grandvalet Y (2005) Bias in estimating the variance of K-fold cross-validation. In: Statistical modeling and analysis for complex data problems. Springer, Berlin, pp 75–95
Bennett KP, Campbell C (2000) Support vector machines: hype or hallelujah? ACM SIGKDD Explor Newslett 2(2):1–13
Bergstrom CT (2007) Eigenfactor: measuring the value and prestige of scholarly journals. Coll Res Libr News 68(5):314–316
Bergstrom CT, West JD (2008) Asessing citations with the eigenfactor metrics. Neurology 71(23):1850–1851
Bhagat S, Rozenbaum I, Cormode G (2007) Applying link-based classification to label blogs. In: Proceedings of the 9th WebKDD and 1st SNA-KDD 2007 workshop on web mining and social network analysis, pp 92–101
Bollen J, de Sompel H, Smith J, Luce RT (2005) Alternative metrics of journal impact: a comparison of download and citation data. Info Process Manag 41(6):1419–1440
Boongoen T, Shang C, Iam-on N, Shen Q (2011) Extending data reliability measure to a filter approach for soft subspace clustering. IEEE Trans Syst Man Cybern Part B Cybern 41(6):1705–1714
Boongoen T, Shen Q (2010) Nearest-neighbor guided evaluation of data reliability and its application. IEEE Trans Syst Man Cybern Part B Cybern 40(6):1622–1633
Brin S, Page L (1998) The anatomy of a large-scale hypertextual Web search engine. Comput Netw ISDN Syst 30(1):107–117
Chakrabarti S, Dom B, Indyk P (1998) Enhanced hypertext categorization using hyperlinks. In: SIGMOD international conference on management of data, pp 307–318
Cooper S, Poletti A (2011) The new ERA of journal ranking: the consequences of Australia fraught encounter with ‘quality’. Aust Univ Rev 53(1):57–65
Cover T, Hart P (1967) Nearest neighbor pattern classification. IEEE Trans Inf Theory 13(1):21–27
Dietterich TG (1998) Approximate statistical tests for comparing supervised classification learning algorithms. Neural Comput 10(7):1895–1923
Drucker H, Wu D, Vapnik V (1999) Support vector machines for spam categorization. IEEE Trans Neural Netw 10:1048–1054
Dudani SA (1976) The distance-weighted k-nearest-neighbor rule. IEEE Trans Syst Man Cybern SMC-6(4):323–327
Eigenfactor.org (2012) Eigenfactor score and article influence score: Detailed methods. [Online]. Available: http://www.eigenfactor.org/methods.pdf
Fu X, Shen Q (2010) Fuzzy compositional modeling. IEEE Trans Fuzz Syst 18(4):823–840
Furey T, Cristianini N, Duffy N, Bednarski D, Schummer M, Haussler D (2000) Support vector machine classification and validation of cancer tissue samples using microarray expression data. Bioinformatics 16:906–914
Garfeild E (2006) The history and meaning of the journal impact factor. J Am Med Assoc 295(1):90–93
Getoor L, Diehl CP (2005) Link mining: a survey. ACM SIGKDD Explor Newslett 7(2):3–12
Giles CL, Bollacker KD, Lawrence S (1998) CiteSeer: an automatic citation indexing system. In: Proceedings of the third ACM conference on Digital libraries, pp 89–98
Górriz JM, Ramírez J, Lang EW, Puntonet CG (2005) Hard C-means clustering for voice activity detection. Speech Commun 48(12):1638–1649
Holsapple CW (2009) A new map for knowledge dissemination channels. Commun ACM 52(3):117–125
Jain AK, Murty MN, Flynn PJ (1999) Data clustering: a review. ACM Comput Surv 31(3):264–423
Kohavi R (1995) A study of cross-validation and bootstrap for accuracy estimation and model selection. In: Proceedings of the international joint conference on artificial intelligence (IJCAI 1995). Lawrence Erlbaum Associates Ltd, Hillsdale, pp 1137–1143
Lafferty J, McCallum A, Pereira F (2001) Conditional random felds: probabilistic models for segmenting and labeling sequence data. In: International conference on machine learning, pp 282–289
Ley M (2002) The DBLP computer science bibliography: evolution, research issues, perspectives. In: String processing and information retrieval. Springer, Berlin, pp 481–486
Lu Q, Getoor L (2003) Link-based classification. Int Conf Mach Learn 20(2):496–503
Oh HJ, Myaeng SH, Lee M-H (2000) A practical hypertext catergorization method using links and incrementally available class information. In: International ACM SIGIR conference on research and development in information retrieval, pp 264–271
Pena JM, Lozano JA, Larranaga P (1999) An empirical comparison of four initialization methods for the K-means algorithm. Pattern Recognit Lett 20(10):1027–1040
Perlibakas V (2004) Distance measures for PCA-based face recognition. Pattern Recognit Lett 25(6):711–724
Rousseau R (2002) Journal evaluation: techinical and pratical issues. Libr Trends 50(3):418–439
Salton G (1991) Developments in automatic text retrieval. Science 253(5023):974–980
Shen Q, Diao R, Su P (2012) Feature selection ensemble. In: Proceedings of the Alan Turing centenary conference, pp 289–306
Shen Q, Boongoen T (2012) Fuzzy orders-of-magnitude based link analysis for qualitative alias detection. IEEE Trans Knowl Data Eng 24(4):649–664
Stegmann J (1997) How to evaluate journal impact factors. Nature 390(11):550
Stegmann J, Grohmann G (2001) Citation rates, knowledge export and international visibility of dermatology journals listed and not listed in the journal citation reports. Scientometrics 50(3):483–502
Su P, Li Y, Li Y, Shiu SC (2012) An auto-adaptive convex map generating path-finding algorithm: genetic convex A*. Int J Mach Learn Cybern. doi:10.1007/s13042-012-0120-x
Weinberger KQ, Saul LK (2009) Distance metric learning for large margin nearest neighbor classification. J Mach Learn Res 10:207–244
Witten IH, Frank E (2005) Data mining: practical machine learning tools and techniques (2e). Morgan Kaufmann, San Francisco
(2012) The Excellence in Research for Australia (ERA) Initiative website. [Online]. Available: http://www.arc.gov.au/era/
(2014) The Research Excellence Framework website. [Online]. Available: http://www.ref.ac.uk/
Acknowledgments
The authors are grateful to the comments provided by the reviewers which have helped revise this work. The first author is grateful to Aberystwyth University for providing a full-fees PhD scholarship in support of this research.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by G. Acampora.
Rights and permissions
About this article
Cite this article
Su, P., Shang, C. & Shen, Q. Link-based approach for bibliometric journal ranking. Soft Comput 17, 2399–2410 (2013). https://doi.org/10.1007/s00500-013-1052-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-013-1052-4