
Abstract
During the software development process, prediction of the number of faults in software modules can be more helpful instead of predicting the modules being faulty or non-faulty. Such an approach may help in more focused software testing process and may enhance the reliability of the software system. Most of the earlier works on software fault prediction have used classification techniques for classifying software modules into faulty or non-faulty categories. The techniques such as Poisson regression, negative binomial regression, genetic programming, decision tree regression, and multilayer perceptron can be used for the prediction of the number of faults. In this paper, we present an experimental study to evaluate and compare the capability of six fault prediction techniques such as genetic programming, multilayer perceptron, linear regression, decision tree regression, zero-inflated Poisson regression, and negative binomial regression for the prediction of number of faults. The experimental investigation is carried out for eighteen software project datasets collected from the PROMISE data repository. The results of the investigation are evaluated using average absolute error, average relative error, measure of completeness, and prediction at level l measures. We also perform Kruskal–Wallis test and Dunn’s multiple comparison test to compare the relative performance of the considered fault prediction techniques.




Similar content being viewed by others
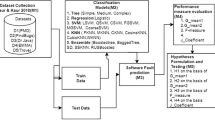

Notes
Number of faults and fault counts both are same term. We used them interchangeably in this paper.
Stata: Data Analysis and Statistical Software. http://www.stata.com/.
Weka Data Mining Tool. http://www.cs.waikato.ac.nz/ml/weka/.
PROMISE data repository. http://openscience.us/repo/defect/.
Eclipse data repository. https://www.st.cs.uni-saarland.de/softevo/bug-data/eclipse/.
References
Afzal W, Torkar R, Feldt R (2008) prediction of fault count data using genetic programming. In: IEEE International conference on Multitopic, INMIC’08, pp 349–356
Bacchelli A, DAmbros, M, Lanza M (2010) Are popular classes more defect prone?. In: Fundamental approaches to software engineering, Springer, pp 59–73
Basili V, Briand L, Melo W (1993) Object-oriented metrics that predict maintainability. J Syst Soft 23(2):111–122
Bland JM, Altman DG (1995) Multiple significance tests: the bonferroni method. BMJ 310(6973):170
Briand L, Jurgen W (2002) Empirical studies of quality models in object-oriented systems. Adv Comput J 56:97–166
Cameron AC, Trivedi PK (2013) Regression analysis of count. Cambridge University Press, Cambridge
Casella G (2008) Statistical design. Springer, New York
Catal C (2011) Software fault prediction: a literature review and current trends. Expert Syst Appl J 38(4):4626–4636
Chen M, Yutao M (2015) An empirical study on predicting defect numbers. In: Proceedings of software engineering and knowledge engineering conference, SEKE’15, 2015, pp 397–402
Cohen J, Cohen P, West SG, Aiken LS (2002) Applied multiple regression and correlation analysis for the behavioral sciences, 3rd edn. Routledge, London
Conte SD, Dunsmore HE, Shen VY (1986) Software engineering metrics and models. Benjamin-Cummings Publishing Co. Inc, Redwood City
Draper NR, Smith H (1998) Applied regression analysis, 3rd edn. Wiley, Hoboken
Elish MO, Aljamaan H, Ahmad I (2015) Three empirical studies on predicting software maintainability using ensemble methods. Soft Comput J 19(9):1–14
Gao K, Khoshgoftaar TM (2007) A comprehensive empirical study of count models for software fault prediction. IEEE Trans Softw Eng 50(2):223–237
Goldberg DE (1989) Genetic algorithms in search optimization and machine learning, 1st edn. Addison-Wesley Longman Publishing Co.Inc, Boston
Graves T, Karr A, Marron J, Siy H (2000) Predicting fault incidence using software change history. IEEE Trans Softw Eng 26(7):653–661
Greene WH (2011) Econometric analysis. 7th edn. Pearson, New York
Hilbe JM (2012) Negative binomial regression, 2nd edn. Jet Propulsion Laboratory California Institute of Technology and Arizona State University, California
Janes A, Scotto M, Pedrycz W, Russo B, Stefanovic M, Succi G (2006) Identification of defect-prone classes in telecommunication software systems using design metrics. Inf Sci J 176(24):3711–3734
Jureczko M (2011) Significance of different software metrics in defect prediction. Softw Eng Int J 1(1):86–95
Juristo N, Moreno AM (2013) Basics of software engineering experimentation. Springer, New York
Khoshgoftaar T, Pandya A, More H (1992a) A neural network approach for predicting software development faults. In: Third international symposium on software reliability engineering, pp 83–89
Khoshgoftaar TM, Munson JC, Bhattacharya BB, Richardson GD (1992b) Predictive modeling techniques of software quality from software measures. IEEE Trans Softw Eng 18(11):979–987
Khoshgoftaar TM, Ganesan K, Allen BE, Ross DF, Munikoti R, Goel N, Nandi A (1997) Predicting fault-prone modules with case-based reasoning. In: Proceedings of the eighth international symposium on software reliability engineering, ISSRE ’97. IEEE computer society
Khoshgoftaar TM, Gao K (2007) Count models for software quality estimation. IEEE Trans Reliab 56(2):212–222
Kohavi R et al (1995) A study of cross-validation and bootstrap for accuracy estimation and model selection. IJCAI 14:1137–1145
Kotsiantis SB (2007) Supervised machine learning: a review of classification techniques. In: Proceedings of the 2007 conference on emerging artificial intelligence applications in computer engineering: real word AI systems with applications in e health, HCI, Information Retrieval and Pervasive Technologies, The Netherlands, pp 3–24
Kpodjedo S, Ricca F, Antoniol G, Galinier P (2009) Evolution and search based metrics to improve defects prediction. In: 1st International symposium on search based software engineering, 2009, pp 23–32
Lambert D (1992) Zero-inflated poisson regression, with an application to defects in manufacturing. Technom J 34(1):1–14
Liguo Y (2012) Using negative binomial regression analysis to predict software faults: a study of apache ant. Inf Technol Comput Sci J 4(8):63–70
Marinescu C (2014) How good is genetic programming at predicting changes and defects?. In: 2014 16th International symposium on symbolic and numeric algorithms for scientific computing, IEEE, pp 544–548
Menzies T, Milton Z, Burak T, Cukic B, Jiang Y, Bener A (2010) Defect prediction from static code features: current results, limitations, new approaches. Autom Softw Eng J 17(4):375–407
Menzies T, Krishna R, Pryor D (2016) The promise repository of empirical software engineering data. North Carolina State University. http://openscience.us/repo
Ostrand TJ, Weyuker EJ, Bell RM (2004) Where the bugs are. In: Proceedings of 2004 international symposium on software testing and analysis, pp 86–96
Ostrand TJ, Weyuker EJ, Bell RM (2005a) Predicting the location and number of faults in large software systems. IEEE Trans Softw Eng 31(4):340–355
Ostrand TJ, Weyuker EJ, Bell RM (2005b) Predicting the location and number of faults in large software systems. IEEE Trans Softw Eng 31(4):340–355
Quinlan JR et al. (1992) Learning with continuous classes. In: 5th Australian joint conference on artificial intelligence, vol 92, pp 343–348
Rathore SS, Kumar S (2015a) Predicting number of faults in software system using genetic programming. In: 2015 International conference on soft computing and software engineering, pp 52–59
Rathore SS, Kumar S (2015b) Comparative analysis of neural network and genetic programming for number of software faults prediction. In: Presented in 2015 national conference on recent advances in electronics and computer engineering (RAECE’15) held at IIT Roorkee, India
Rathore SS, Kumar S (2016a) A decision tree logic based recommendation system to select software fault prediction techniques. Computing, 1–31. doi:10.1007/s00607-016-0489-6
Rathore SS, Kumar S (2016b) A decision tree regression based approach for the number of software faults prediction. ACM SIGSOFT Softw Eng Notes 41(1):1–6
Scanniello G, Gravino C, Marcus A, Menzies T (2013) Class level fault prediction using software clustering. In: 2013 IEEE/ACM 28th international conference on automated software engineering, IEEE, pp 640–645
Smith SF (1980) A learning system based on genetic adaptive algorithms. PhD thesis, Pittsburgh, PA, USA. AAI8112638
Strutz T (2011) Data fitting and uncertainty. Vieweg and Teubner Verlag Springer, New York
Venkata UB, Bastani BF, Yen IL (2006) A unified framework for defect data analysis using the mbr technique. In: Proceeding of 18th IEEE international conference on tools with artificial intelligence, ICTAI ’06, 2006, pp 39–46
Veryard R (2014) The economics of information systems and software. Elsevier Science, Amsterdam
Wang S, Yao X (2013) Using class imbalance learning for software defect prediction. IEEE Trans Reliab 62(2):434–443
Witten IH, Frank E (2005) Data mining: practical machine learning tools and techniques. Morgan Kaufmann, Burlington
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed consent
This article does not contain any studies with human participants.
Additional information
Communicated by V. Loia.
Rights and permissions
About this article

Cite this article
Rathore, S.S., Kumar, S. An empirical study of some software fault prediction techniques for the number of faults prediction. Soft Comput 21, 7417–7434 (2017). https://doi.org/10.1007/s00500-016-2284-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-016-2284-x