
Abstract
Most deep learning methods have inherent defects and are rarely applied in the classification task of small-sized imbalanced datasets. On the one hand, data imbalance causes the classification results of the model to be biased toward the majority class. On the other hand, limited training data results in over-fitting. Deep forest (DF) is an interesting deep learning model that can perfectly work on small-sized datasets, and its performance is highly competitive with deep neural networks. In the present study, a variant of the DF called the imbalanced deep forest (IMDF) is proposed to effectively improve the classification performance of the minority class. It aims to explore the application of deep learning on small-sized imbalanced datasets. The IMDF is the cascade of multiple layers, where each layer is the ensemble of multiple units. The main idea behind the proposed method is to enable each unit of the IMDF to handle imbalanced data so that the classification results of the entire IMDF are biased toward minority class. Performed experiments demonstrate the effectiveness of the proposed method.


















Similar content being viewed by others

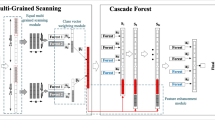
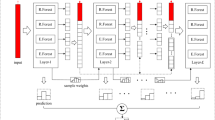
References
Anand R, Mehrotra KG, Mohan CK, Ranka S (1993) An improved algorithm for neural network classification of imbalanced training sets. IEEE Trans Neural Netw 4:962–969. https://doi.org/10.1109/72.286891
Bache K, Lichman M (2013) UCI machine learning repository. School of Information and Computer Sciences, University of California, Irvine. [Online]. http://archive.ics.uci.edu/ml
Branco P, Torgo L, Ribeiro RP (2016) A survey of predictive modeling on imbalanced domains. ACM Comput Surv 49:1–50. https://doi.org/10.1145/2907070
Chang C-C, Lin C-J (2011) LIBSVM: a library for support vector machines. ACM Trans Intell Syst Technol. https://doi.org/10.1145/1961189.1961199
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP (2002) SMOTE: synthetic minority over-sampling technique. J Artif Intell Res 16:321–357. https://doi.org/10.1613/jair.953
Chawla NV, Lazarevic A, Hall LO, Bowyer KW (2003) SMOTEBoost: improving prediction of the minority class in boosting. Eur Conf Princ Data Min Knowl Discov. https://doi.org/10.1007/978-3-540-39804-2_12
Dai Q, Ye R, Liu Z (2017) Considering diversity and accuracy simultaneously for ensemble pruning. Appl Soft Comput 58:75–91. https://doi.org/10.1016/j.asoc.2017.04.058
Demsar J (2006) Statistical comparisons of classifiers over multiple data sets. J Mach Learn Res 7:1–30
Drucker H (1997) Improving regressors using boosting techniques. In: Proceedings of the fourteenth international conference on machine learning, pp 107–115
Fernandez A, GarcIa S, Herrera F (2018) SMOTE for learning from imbalanced data: progress and challenges. J Artif Intell Res 61:863–905. https://doi.org/10.1613/jair.1.11192
Freund Y, Schapire R (1996) Experiments with a new boosting algorithm. In: Proceedings of the thirteenth international conference on machine learning
Haixiang G, Yijing L, Shang J, Mingyun G, Yuanyue H, Bing G (2017) Learning from class-imbalanced data: review of methods and applications. Expert Syst Appl 73:220–239. https://doi.org/10.1016/j.eswa.2016.12.035
Jiang L, Li C, Wang S, Zhang L (2016) Deep feature weighting for naive Bayes and its application to text classification. Eng Appl Artif Intell 52:26–39. https://doi.org/10.1016/j.engappai.2016.02.002
Johnson JM, Khoshgoftaar TM (2019) Survey on deep learning with class imbalance. J Big Data 6:27. https://doi.org/10.1186/s40537-019-0192-5
Lecun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 11:2278–2324. https://doi.org/10.1109/5.726791
Lemaitre G, Nogueira F, Oliveira D, Aridas C (2017) Imbalanced-learn: a python toolbox to tackle the curse of imbalanced datasets in machine learning. J Mach Learn Res 18:1–5
Loyola-González O, Martínez-Trinidad JF, Carrasco-Ochoa JA, García-Borroto M (2016) Study of the impact of resampling methods for contrast pattern based classifiers in imbalanced databases. Neurocomputing 175:935–947. https://doi.org/10.1016/j.neucom.2015.04.120
Loyola-González O, Medina-Pérez MA, Martínez-Trinidad JF, Carrasco-Ochoa JA, Monroy R, García-Borroto M (2017) PBC4cip: a new contrast pattern-based classifier for class imbalance problems. Knowl-Based Syst 115:100–109. https://doi.org/10.1016/j.knosys.2016.10.018
Maher Maalouf TBT (2011) Robust weighted kernel logistic regression in imbalanced and rare events data. Comput Stat Data Anal 55:168–183. https://doi.org/10.1016/j.csda.2010.06.014
Nie G, Rowe W, Zhang L, Tian Y, Shi Y (2011) Credit card churn forecasting by logistic regression and decision tree. Expert Syst Appl 38:15273–15285. https://doi.org/10.1016/j.eswa.2011.06.028
Pang M, Ting K-M, Zhao P, Zhou Z-H (2018) Improving deep forest by confidence screening. In: 18th IEEE international conference on data mining, pp 1194–1199. https://doi.org/10.1109/ICDM.2018.00158
Seiffert C, Khoshgoftaar TM, Van Hulse J, Napolitano A (2010) RUSBoost: a hybrid approach to alleviating class imbalance. IEEE Trans Syst Man Cybern Part A-Syst Hum 40:185–197. https://doi.org/10.1109/TSMCA.2009.2029559
Siddique K, Akhtar Z, Khan FA, Kim Y (2019) KDD Cup 99 data sets: a perspective on the role of data sets in network intrusion detection research. Computer 52:41–51. https://doi.org/10.1109/MC.2018.2888764
Su J, Vargas DV, Sakurai K (2019) One pixel attack for fooling deep neural networks. IEEE Trans Evol Comput 23:828–841. https://doi.org/10.1109/TEVC.2019.2890858
Utkin L (2019) An imprecise deep forest for classification. Expert Syst Appl. https://doi.org/10.1016/j.eswa.2019.112978
Utkin L, Ryabinin MA (2018) A siamese deep forest. Knowl Based Syst 139:13–22. https://doi.org/10.1016/j.knosys.2017.10.006
Utkin L, Kovalev MS, Meldo AA (2019) A deep forest classifier with weights of class probability distribution subsets. Knowl Based Syst 173:15–27. https://doi.org/10.1016/j.knosys.2019.02.022
Zhou Z-H, Feng J (2017) Deep forest: towards an alternative to deep neural networks. In: Proceedings of the twenty-sixth international joint conference on artificial intelligence, pp 3553–3559. https://doi.org/10.24963/ijcai.2017/497
Zhou Z-H, Feng J (2019) Deep forest. Natl Sci Rev 6:74–86. https://doi.org/10.1093/nsr/nwy108
Zhu J, Zou H, Rosset S, Hastie T (2009) Multi-class AdaBoost. Stat Interface 2:349–360. https://doi.org/10.4310/SII.2009.v2.n3.a8
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Nos. 61772023, 61502402) and the Fundamental Research Funds for the Central Universities (No. 20720180073).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Human and animals rights
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Communicated by V. Loia.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Gao, J., Liu, K., Wang, B. et al. An improved deep forest for alleviating the data imbalance problem. Soft Comput 25, 2085–2101 (2021). https://doi.org/10.1007/s00500-020-05279-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-020-05279-8