
Abstract
Most of the cost functions used for blind equalization are nonconvex and nonlinear functions of tap weights, when implemented using linear transversal filter structures. Therefore, a blind equalization scheme with a nonlinear structure that can form nonconvex decision regions is desirable. The efficacy of complex-valued feedforward neural networks for blind equalization of linear and nonlinear communication channels has been confirmed by many studies. In this paper we present a complex valued neural network for blind equalization with M-ary phase shift keying (PSK) signals. The complex nonlinear activation functions used in the neural network are especially defined for handling the M-ary PSK signals. The training algorithm based on constant modulus algorithm (CMA) cost function is derived. The improved performance of the proposed neural network in both, stationary and nonstationary environments, is confirmed through computer simulations.










Similar content being viewed by others
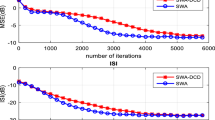

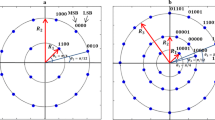
References
Amari SI, Cichocki A (1998) Adaptive blind signal processing–Neural network approaches. Proc IEEE 86(10):2026–2048
Chen S, Gibson GJ, Cowan CFN, Grant PM (1990) Adaptive equalization of finite nonlinear channels using multilayer perceptrons. Signal Process 20:107–109
Chow TWS, Fang Y (2001) Neural blind deconvolution of MIMO noisy channels. IEEE T Circuits Syst-I 48(1):116–120
Lin H, Amin M (2003) A dual mode technique for improved blind equalization for QAM signals. IEEE Signal Process Lett 10(2):29–31
Thirion MN, Moreau E (2002) Generalized criterion for blind multivariate signal equalization. IEEE Signal Process Lett 9(2):72–74
Destro Filho JB, Favier G, Travassos Romano JM (1996) Neural networks for blind equalization. Proc IEEE Int Conf Globcom 1:196–200
Fang Y, Chow TWS, Ng KT (1999) Linear neural network based blind equalization. Signal Process 76(1):37–42
Feng CC, Chi CY (1999) Performance of cumulant based inverse filters for blind deconvolution. IEEE Trans Signal Proces 47(7):1922–1935
Choi S, Cichocki A (1998) Cascade neural networks for multichannel blind deconvolution. Electron Lett 34(12):1186–1187
Kechriotis G, Zervas E, Manolakos ES (1994) Using recurrent neural networks for adaptive communication channel equalization. IEEE T Neural Networ 5(2):267–278
Haykin S (1994) Blind deconvolution. Prentice-Hall, Englewood Cliffs
Haykin S (1996) Adaptive filter theory, 3rd edn. Prentice Hall, Upper Saddel River
You C, Hong D (1998) Nonlinear blind equalization schemes using complex valued multilayer feedforward neural networks. IEEE T Neural Networ 9(6):1442–1455
Haykin S (1994) Neural networks: a comprehensive foundation. Prentice Hall, Upper Saddle River
Haykin S (1996) Neural networks expand SP’s horizons. IEEE Signal Process Mag, pp 24–49
Luo FL, Unbehauen R (1997) Applied neural networks for signal processing. Cambridge University Press, UK
Cichocki A, Unbehauen R (1994) Neural networks for optimization and signal processing. Wiley, Chichester
Benvenuto N, Piazza F (1992) On the complex backpropagation algorithm. IEEE T Signal Proces 40:967–969
Johnson CR et al (1998) Blind equalization using the constant modulus criterion : a review. Proc IEEE 86(10):1927–1950
Schniter P, Johnson CR Jr (1999) Dithered signed error CMA: robust, computationally efficient blind adaptive equalization. IEEE T Signal Proces 47(6):1592–1603
Jalon NK (1992) Joint blind equalization, carrier recovery and timing recovery for high order QAM constellations. IEEE T Signal Proces 40:1383–1398
Pandey R (2001) Blind equalization and signal separation using neural networks. PhD. thesis, I.I.T. Roorkee, India
Liavas AP, Regalia PA, Delmas JP (1999) Blind channel approximation: effective channel order determination. IEEE T Signal Proces 47(12):3336–3344
Vesin JM, Gruter R (1999) Model selection using a simplex reproduction genetic algorithm. Signal Proces 78:321–327
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
The CMA cost function is expressed as
where
Using the gradient descent technique, the weights of the neural network can be updated as
and
where η is the learning rate parameter and the terms \(\nabla_{{w^{(2)}_{k}}} J(n)\) and \(\nabla _{{w^{(1)}_{{kl}}}} J(n)\) represent the gradients of the cost function J(n) defined by (25) with respect to the weights w(2) k and w(1) kl , respectively.
Since the activation function of the output layer neuron for M-ary PSK signal is defined in terms of modulus and angle of the activation sum, the gradient of the CMA cost function with respect to the output layer weight w(2) k (n) is expressed as
To obtain an expression for the partial derivative of (28), we use the relationship
On differentiating (29) with respect to w(2) k , we get
On substituting (30) in (28), the expression for the gradient becomes
where
Substitution of (31) in (26) along with (32) gives the update equation (17) with (18) for M-ary PSK signal.
In order to obtain the update equation for the weights {w(1) kl }, we need the following gradient
The partial derivative terms in (33) can be obtained by using (29)
where
and
Now the substitution of (35) and (36) in (34) and some simplification lead to
Finally, by substituting (37) in (33), we get
where
Using (38) and (27), we get the update rule of (19) for M-ary PSK signal.
Rights and permissions
About this article
Cite this article
Pandey, R. Feedforward neural network for blind equalization with PSK signals. Neural Comput & Applic 14, 290–298 (2005). https://doi.org/10.1007/s00521-004-0465-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-004-0465-5