
Abstract
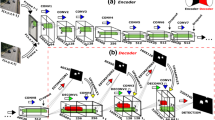
A video segmentation algorithm that takes advantage of using a background subtraction (BS) model with low learning rate (LLR) or a BS model with high learning rate (HLR) depending on the video scene dynamics is presented in this paper. These BS models are based on a neural network architecture, the self-organized map (SOM), and the algorithm is termed temporal modular self-adaptive SOM, TMSA_SOM. Depending on the type of scenario, the TMSA_SOM automatically classifies and processes each video into one of four different specialized modules based on an initial sequence analysis. This approach is convenient because unlike state-of-the-art (SoA) models, our proposed model solves different situations that may occur in the video scene (severe dynamic background, initial frames with dynamic objects, static background, stationary objects, etc.) with a specialized module. Furthermore, TMSA_SOM automatically identifies whether the scene has drastically changed (e.g., stationary objects of interest become dynamic or drastic illumination changes have occurred) and automatically detects when the scene has become stable again and uses this information to update the background model in a fast way. The proposed model was validated with three different video databases: Change Detection, BMC, and Wallflower. Findings showed a very competitive performance considering metrics commonly used in the literature to compare SoA models. TMSA_SOM also achieved the best results on two perceptual metrics, Ssim and D-Score, and obtained the best performance on the global quality measure, FSD (based on F-Measure, Ssim, and D-Score), demonstrating its robustness with different and complicated non-controlled scenarios. TMSA_SOM was also compared against SoA neural network approaches obtaining the best average performance on Re, Pr, and F-Measure.









Similar content being viewed by others

Abbreviations
- F :
-
Foreground
- B :
-
Background
- t :
-
Time
- BS:
-
Background subtraction
- LLR :
-
Low learning rate variable, initial value 0.002
- HLR :
-
High learning rate variable, initial value 0.008
- BS LLR :
-
BS model with slow adaptation to changes
- BS HLR :
-
BS model with high adaptation to changes
- Th LLR :
-
Threshold value on the BS LLR model equal to 0.2 for t ≤ 40; 0.12 for t > 40; it changes as the analysis continues
- Th HLR :
-
Threshold value on the BS HLR model equal to 0.2 for t ≤ 40 and 0.26 for t > 40
- F LLR :
-
F output of the BS LLR model
- \(I_{{F_{LLR} }}\) :
-
F LLR filtered
- F HLR :
-
F output of the BS HLR model
- \(I_{{F_{HLR} }}\) :
-
F HLR filtered
- F o :
-
Final F output
- M:
-
Specialized modules
- p :
-
Pixel representation
- W :
-
Neural weight representation
- e pw :
-
Euclidean distance between a pixel and a neural weight
- \(\widetilde{{F_{p} }}\) :
-
A feature used to classify the video in any of the M modules
- Matrix_Cont Mn :
-
Counter matrix, whose values increment in relation to the F detection, implemented on M2, M3, and M4, n = 2, 3, and 4 for t > 41
- Matrix_Cont M3_ND :
-
Counter matrix implemented on M3 for t > 100
- Th M2 :
-
Threshold value within M2 equal to 100
- Th M3 :
-
Threshold value within M3 equal to 200
- Th M4 :
-
Threshold value within M4 equal to 200
- Th G1 :
-
Threshold that defines a possible ghost issue on F o equal to 5
- Th G2 :
-
Threshold that defines a possible ghost issue on F o equal to 4
- Th DCh :
-
Threshold that defines a drastic change in the scene equal to 0.26 for M1, M2, and M3; equal to 0.32 for M4
- Th Stable :
-
Threshold that defines a stable scene equal to 0.0015
References
Seungwoo Y, Changick K (2013) Background subtraction using hybrid feature coding in the bag-of-features framework. Pattern Recognit Lett 34:2086–2093
Seidel F, Hage C, Kleinsteuber M (2013) pROST: a smoothed \(\ell_{p}\)-norm robust online subspace tracking method for background subtraction in video. Mach Vis Appl 25(5):1227–1240. doi:10.1007/s00138-013-0555-4
Romanoni A, Matteucci M, Sorrenti DG (2013) Background subtraction by combining temporal and Spatio–Temporal histograms in the presence of camera movement. Mach Vis Appl 25(6):1573–1584. doi:10.1007/s00138-013-0587-9
Elguebaly T, Bouguila N (2013) Finite asymmetric generalized Gaussian mixture models learning for infrared object detection. Comput Vis Image Underst 117:1659–1671
Park D, Byun H (2013) A unified approach to background adaptation and initialization in public scenes. Pattern Recognit 46:1985–1997
Ngan KN, Li H (2011) Video segmentation and its applications. Springer, New York
Chang J, Wei D, Fisher JW (2013) A video representation using temporal super pixels. In: Computer vision and pattern recognition (CVPR), 2013 IEEE conference on, Portland, OR, pp 2051–2058
Ma Z et al (2013) Complex event detection via multi-source video attributes. In: Computer vision and pattern recognition (CVPR), 2013 IEEE conference on, Portland, OR, pp 2627–2633
Ren X, Han TX, He Z (2013) Ensemble video object cut in highly dynamic scenes. In: Computer vision and pattern recognition (CVPR), 2013 IEEE conference on, Portland, OR, pp 1947–1954
Revaud J, Douze M, Schmid C, Jegou H (2013) Event retrieval in large video collections with circulant temporal encoding. In: Computer vision and pattern recognition (CVPR), 2013 IEEE conference on, Portland, OR, pp 2459–2466
Guo X, Cao X, Chen X, Ma Y (2013) Video editing with temporal, spatial and appearance consistency. In: Computer vision and pattern recognition (CVPR), 2013 IEEE conference on, Portland, OR, pp 2283–2290
Zhang D, Javed O, Shah M (2013) Video object segmentation through spatially accurate and temporally dense extraction of primary object regions. In: Computer vision and pattern recognition (CVPR), 2013 IEEE conference on, Portland, OR, pp 628–635
Chen Y-L, Bing-Fei W, Huang Hao-Yu, Fan C-J (2011) A real-time vision system for nighttime vehicle detection and traffic surveillance. Ind Electron IEEE Trans 58(5):2030–2044
Ari C, Aksoy S (2014) Detection of compound structures using a Gaussian mixture model with spectral and spatial constraints. Geosci Remote Sens IEEE Trans 9:1–12
Stauffer C, Grimson WEL (1999) Adaptive background mixture models for real-time tracking. In: Computer vision and pattern recognition, 1999. IEEE computer society conference on, vol 2, Fort Collins, CO
Heras R, Sikora T (2011) Complementary background models for the detection of static and moving objects in crowded environments. In: Advanced video and signal-based surveillance (AVSS), 2011 8th IEEE international conference on, Klagenfurt, pp 71–76
Haines TSF, Xiang T (2012) Background subtraction with dirichlet processes. Lecture notes in computer science. Computer vision—ECCV 2012, 7575:99–113, 2012
Zhang S, Yao H, Liu S (2008) Dynamic background modeling and subtraction using spatio-temporal local binary patterns. In: Image processing, 2008, ICIP 2008. 15th IEEE international conference on, San Diego, CA, pp 1556–1559
Hofmann M, Tiefenbacher P, Rigoll G (2012) Background segmentation with feedback: the pixel-based adaptive segmenter. In: Computer vision and pattern recognition workshops (CVPRW), 2012 IEEE computer society conference on, Providence, RI, pp 38–43
Culibrk D, Marques O, Socek D, Kalva H, Furht B (2007) Neural network approach to background modeling for video object segmentation. IEEE Trans Neural Netw 18(6):1614–1627
Luque R, Lopez-Rodriguez D, Merida-Casermeiro M, Palomo EJ (2008) Video object segmentation with multivalued neural networks. In: IEEE international conference on hybrid intelligent systems, HIS 2008, pp 613–618
Luque R, Ortiz J, Lopez E, Domínguez E, Palomo E (2013) A competitive neural network for multiple object tracking in video sequence analysis. Neural Process Lett 37(1):47–67
Chacon-Murguia M, Urias-Zavala D (2014) A DTCNN approach on video analysis: dynamic and static object segmentation. In: Castillo O, Melin P, Pedrycz W, Kacprzyk J (eds) Recent advances on hybrid approaches for designing intelligent systems, vol 547. Springer, Switzerland, pp 315–336
Ramirez-Quintana J, Chacon-Murguia M (2014) An adaptive unsupervised neural network based on perceptual mechanism for dynamic object detection in videos with real scenarios. Neural Process Lett 1–25. doi:10.1007/s11063-014-9380-7
Chacon-Murguia M, Gonzalez-Duarte S (2011) An adaptive neural-fuzzy approach for object detection in dynamic backgrounds for surveillance systems. IEEE Trans Ind Electron 59(8):3286–3298
Gregorio M, Giordano M (2014) Change detection with weightless neural networks. In: IEEE change detection workshop, CDW 2014
Maddalena L, Petrosino A (2012) The SOBS algorithm: What are the limits? In: Computer vision and pattern recognition workshops (CVPRW), 2012 IEEE computer society conference on, Providence, RI, pp 21–26
Maddalena L, Petrosino A (2013) Stopped object detection by learning foreground model in videos. Neural Netw Learn Syst IEEE Trans 24(5):723–735
Sobral A, Vacavant A (2014) A comprehensive review of background subtraction algorithms evaluated with synthetic and real videos. Comput Vis Image Underst 122:4–21
Chacon-Murguia MI, Ramirez-Alonso G, Gonzalez-Duarte S (2013) Improvement of a neural–fuzzy motion detection vision model for complex scenario conditions. In: The 2013 international joint conference on neural networks (IJCNN), Dallas, TX, pp 1–8. doi:10.1109/IJCNN.2013.6706734
Goyette N, Jodoin P-M, Porikli F, Konrad J, Ishwar P (2012) Changedetection.net: a new change detection benchmark dataset. In: Computer vision and pattern recognition workshops (CVPRW), 2012 IEEE computer society conference on, Providence, RI, pp 1–8
Vacavant A, Chateau T, Wilhelm A, Lequièvre L (2012) A benchmark dataset for outdoor foreground/background extraction. In: Park J-I, Kim J (eds) Computer Vision—ACCV 2012 Workshops, vol 7728. Springer, Heidelberg, pp 291–300
Toyama K, Krumn J, Brumitt B, Meyers B (1999) Wallflower: principles and practice of background maintenance. In: IEEE international conference on computer vision, 1999
Sedky M (2011) Object segmentation using full-spectrum matching of albedo derived from colour images. UK 0822953.6 16.12.2008 GB, 2008, PCT/GB2009/002829, EP2374109, US 2374109 12.10.2011, 2008/2009/2011
Lallier C, Reynaud E, Robinault L, Tougne L (2011) A testing framework for background subtraction algorithms comparison in intrusion detection context. In: Advanced video and signal-based surveillance (AVSS), 2011 8th IEEE international conference on, Klagenfurt, pp 314–319
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. Image process IEEE Trans 13(4):600–612
Li L, Huang W, Gu IY-H, Tian Q (2004) Statistical modeling of complex backgrounds for foreground object detection. IEEE Trans Image Process 13(11):1459–1472
Bouwmans T, Zahzah E (2014) Robust PCA via principal component pursuit: a review for a comparative evaluation in video surveillance. Comput Vis Image Underst 122:22–34. doi:10.1016/j.cviu.2013.11.009
Acknowledgments
This work was supported by Fondo Mixto de Fomento a la Investigacion Cientifica y Tecnologica CONACYT- Gobierno del Estado de Chihuahua and TNM under Grants CHIH-2012-C03-193760 and CHI-IET-2012-105, and CHI-MCIET-2013-230.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Ramirez-Alonso, G., Chacon-Murguia, M.I. Object detection in video sequences by a temporal modular self-adaptive SOM. Neural Comput & Applic 27, 411–430 (2016). https://doi.org/10.1007/s00521-015-1859-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-015-1859-2