
Abstract
The requirements for automatic document summarization that can be applied to practical applications are increasing rapidly. As a general sentence regression architecture, extractive text summarization captures sentences from a document by leveraging externally related information. However, existing sentence regression approaches have not employed features that mine the contextual information and relations among sentences. To alleviate this problem, we present a neural network model, namely the Contextualized-Representation Hierarchical-Attention Summarization (CRHASum), that uses the contextual information and relations among sentences to improve the sentence regression performance for extractive text summarization. This framework makes the most of their advantages. One advantage is that the contextual representation is allowed to vary across linguistic context information, and the other advantage is that the hierarchical attention mechanism is able to capture the contextual relations from the word-level and sentence-level by using the Bi-GRU. With this design, the CRHASum model is capable of paying attention to the important context in the surrounding context of a given sentence for extractive text summarization. We carry out extensive experiments on three benchmark datasets. CRHASum alone can achieve comparable performance to the state-of-the-art approach. Meanwhile, our method significantly outperforms the state-of-the-art baselines in terms of multiple ROUNG metrics and includes a few basic useful features.



Similar content being viewed by others
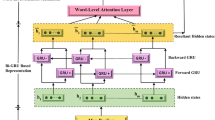

Notes
ROUGE-1.5.5 with options: −n 2 –m –u –c 95 –x –r 1000 –f A –p 0.5 –t 0.
References
Chopra S, Auli M, Rush AM (2016) Abstractive sentence summarization with attentive recurrent neural networks. In: Proceedings of the 2016 conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp 93–98
Takase S, Suzuki J, Okazaki N et al (2016) Neural headline generation on abstract meaning representation. In: Proceedings of the 2016 conference on empirical methods in natural language processing, pp 1054–1059
Cao Z, Wei F, Li S, Li W, Zhou M, Wang H (2015) Learning summary prior representation for extractive summarization. In: ACL
Wan X, Cao Z, Wei F, Li S, Zhou M (2015) Multi-document summarization via discriminative summary reranking. CoRR
Feng C, Cai F, Chen H et al (2018) Attentive encoder-based extractive text summarization. In: Proceedings of the 27th ACM International conference on information and knowledge management. ACM, pp 1499–1502
Ren P, Chen Z, Ren Z et al (2017) Leveraging contextual sentence relations for extractive summarization using a neural attention model. In: Proceedings of the 40th international ACM SIGIR conference on research and development in information retrieval. ACM, pp 95–104
Ren P, Wei F, Chen Z, Ma J, Zhou M (2016) A redundancy-aware sentence regression framework for extractive summarization. In: COLING
Wan X, Zhang J (2014) CTSUM: extracting more certain summaries for news articles. In: SIGIR
Isonuma M, Fujino T, Mori J et al (2017) Extractive summarization using multi-task learning with document classification. In: Proceedings of the 2017 Conference on empirical methods in natural language processing, pp 2101–2110
Radev DR, Jing H, Budzikowska M (2000) Centroid-based summarization of multiple documents: sentence extraction, utility-based evaluation, and user studies. In: NAACL-ANLP
Mihalcea R (2004) Graph-based ranking algorithms for sentence extraction, applied to text summarization. In: ACL
Mihalcea R, Tarau P (2004) TextRank: bringing order into texts. In: EMNLP
Erkan G, Radev DR (2004) LexRank: graph-based lexical centrality as salience in text summarization. JAIR 22(1):457–479
Wan X, Yang J (2008) Multi-document summarization using cluster-based link analysis. In: SIGIR
Goldstein J, Mittal V, Carbonell J, Kantrowitz M (2000) Multi-document summarization by sentence extraction. In: NAACL-ANLP
Lin H, Bilmes J (2011) A class of submodular functions for document summarization. In: NAACL-HLT
Kupiec J, Pedersen J, Chen F (1995) A trainable document summarizer. In: SIGIR
Li S, Ouyang Y, Wang W, Sun B (2007) Multi-document summarization using support vector regression. In: DUC
Hu Y, Wan X (2015) PPSGen: learning-based presentation slides generation for academic papers. TKDE 27(4):1085–1097
Gillick D, Favre B (2009) A scalable global model for summarization. In: ILP-NLP
Kobayashi H, Noguchi M, Yatsuka T (2015) Summarization based on embedding distributions. In: EMNLP
Yin W, Pei Y (2015) Optimizing sentence modeling and selection for document summarization. In: IJCAI
Bahdanau D, Cho K, Bengio Y (2014) Neural machine translation by jointly learning to align and translate. Comput Sci
Shen T, Zhou T, Long G et al (2018) Disan: directional self-attention network for rnn/cnn-free language understanding. In: AAAI
Du J, Xu R, He Y et al (2017) Stance classification with target-specific neural attention. In: Twenty-sixth international joint conference on artificial intelligence, pp 3988–3994
Gui L, Hu J, He Y et al (2017) A question answering approach to emotion cause extraction. arXiv:1708.05482
Lu J, Yang J, Batra D et al (2016) Hierarchical question-image co-attention for visual question answering. In: Advances in neural information processing systems, pp 289–297
Kim J, Kong D, Lee JH (2018) Self-attention-based message-relevant response generation for neural conversation model. arXiv:1805.08983
Fan A, Lewis M, Dauphin Y (2018) Hierarchical neural story generation. arXiv:1805.04833
Mikolov T, Chen K, Corrado G et al (2013) Efficient estimation of word representations in vector space. In: Proceedings of ICLR:1301.3781
Pennington J, Socher R, Manning C (2014) Glove: global vectors for word representation. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pp 1532–1543
Peters ME, Neumann M, Iyyer M et al (2018) Deep contextualized word representations
Chung J, Gulcehre C, Cho KH et al (2014) Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv:1412.3555
Zhang H, Li J, Ji Y et al (2017) Understanding subtitles by character-level sequence-to-sequence learning. IEEE Trans Ind Inf 13(2):616–624
Zhang H, Wang S, Mingbo Z et al (2018) Locality reconstruction models for book representation. IEEE Trans Knowl Data Eng 99:1
Rankel PA, Conroy JM, Dang HT, Nenkova A (2013) A decade of automatic content evaluation of news summaries: reassessing the state of the art. In: ACL
Lin C-Y (2004) Rouge: a package for automatic evaluation of summaries. In: ACL
Owczarzak K, Conroy JM, Dang HT, Nenkova A (2012) An assessment of the accuracy of automatic evaluation in summarization. In: NAACL-HLT
Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R (2014) Dropout: a simple way to prevent neural networks from overing. JMLR 15(1):1929–1958
Duchi J, Hazan E, Singer Y (2011) Adaptive subgradient methods for online learning and stochastic optimization. JMLR 12:2121–2159
Acknowledgements
This work is partially supported by grant from the Natural Science Foundation of China (Nos. 61632011, 61572102, 61702080, 61602079, 61806038), the Ministry of Education Humanities and Social Science Project (No. 16YJCZH12), the Fundamental Research Funds for the Central Universities (DUT18ZD102, DUT19RC(4)016), the National Key Research Development Program of China (No. 2018YFC0832101) and China Postdoctoral Science Foundation (No. 2018M631788).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Human and animal rights
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Diao, Y., Lin, H., Yang, L. et al. CRHASum: extractive text summarization with contextualized-representation hierarchical-attention summarization network. Neural Comput & Applic 32, 11491–11503 (2020). https://doi.org/10.1007/s00521-019-04638-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-019-04638-3